
Redes neurais em trading: modelo de difusão adaptativa em grafos (SAGDFN)

Introdução
Séries temporais multivariadas não se caracterizam apenas pela dependência temporal habitual, como tendências, sazonalidade e picos repentinos de atividade, mas também pela correlação espacial, que é muito mais traiçoeira. Ela descreve como mudanças em uma sequência influenciam as demais. E essas relações têm vida própria: surgem e desaparecem, mudam de intensidade e direção conforme notícias globais, alterações na política monetária dos países, crises políticas ou avanços tecnológicos. Por exemplo, a cotação do EURUSD pode variar sob influência de mudanças nos preços do gás na Europa devido a choques energéticos, enquanto ações de fabricantes de chips podem reagir à situação nas fábricas asiáticas.
Modelos tradicionais, como ARIMA ou VAR, lidavam razoavelmente bem com séries temporais isoladas, mas começavam a patinar assim que entravam em cena centenas de instrumentos. Métodos de aprendizado de máquina da geração seguinte, como máquinas de vetores de suporte e processos gaussianos, ampliaram os horizontes da análise, mas suas arquiteturas raramente levavam em conta o rico tecido das correlações cruzadas. Mesmo redes neurais recorrentes (RNN) e transformers modernos, que demonstraram resultados impressionantes no processamento de sequências, mostraram-se limitados no contexto multivariado: não tinham uma arquitetura suficientemente adequada para lidar com redes dinâmicas de correlações.
Nesse contexto, surgiram as redes neurais de grafos (GNN), originalmente criadas para tarefas com uma estrutura de grafo bem definida, como redes de transporte, interações sociais e cadeias de suprimentos. No mundo financeiro, porém, construir esse grafo é uma tarefa quase artística. Duas empresas do mesmo setor podem se comportar de maneira diametralmente oposta, enquanto dois mercados distantes, como Estados Unidos e Japão, podem reagir de forma sincronizada aos mesmos estímulos macroeconômicos.
A resposta veio com as redes neurais em grafos com pesos adaptativos (adaptive-weight-GNN), que constroem o grafo diretamente a partir dos dados, e não de pressupostos. Elas estimam a matriz de relações entre ativos, identificando correlações efetivas e não relações meramente formais. Um exemplo clássico são o ouro e o iene japonês, que frequentemente se comportam como ativos de proteção. Em períodos normais, essa relação pode não ser evidente, mas em momentos de turbulência global o modelo captura a sincronização de seus movimentos e ajusta a previsão.
Ainda assim, esses métodos também não estão livres de limitações. A primeira é a escalabilidade: uma matriz de correlações N×N para uma grande quantidade de ativos se transforma em um monstro voraz, capaz de travar até aceleradores gráficos potentes ao sobrecarregar sua memória com cálculos intermediários. A segunda são as conexões falsas. Muitos algoritmos adaptativos pressupõem que todos os nós estão, em alguma medida, conectados entre si, mas não é assim. Em previsões financeiras, uma ação pouco relevante de um mercado local não deve exercer influência significativa sobre previsões globais.
Para resolver esses problemas, foi desenvolvida uma nova abordagem baseada na difusão em grafos e no princípio da esparsidade espacial. A ideia central é não tentar analisar todas as conexões possíveis, mas destacar os nós-chave, uma espécie de âncoras de influência que dão o tom de todo o sistema. No contexto financeiro, esses nós podem ser representados pelo dólar americano, pelo euro, pelo petróleo, pelo ouro e por índices acionários como S&P 500 e Nikkei 225.
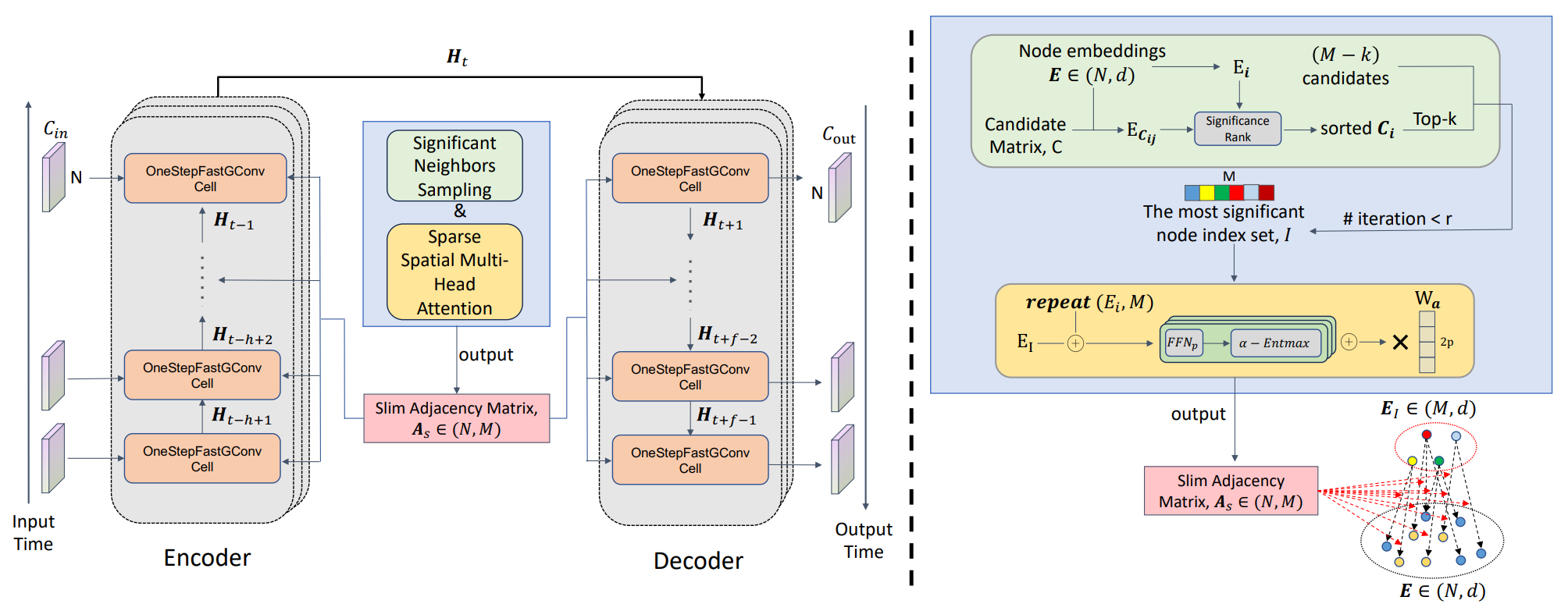
Entre algoritmos desse tipo, destaca-se o framework SAGDFN, apresentado no trabalho "SAGDFN: A Scalable Adaptive Graph Diffusion Forecasting Network for Multivariate Time Series Forecasting". Os autores do framework propõem selecionar os nós mais significativos por meio do algoritmo Significant Nodes Sampling. Já o refinamento posterior das interdependências fica a cargo do módulo Sparse Spatial Multi-Head Attention. Como resultado, forma-se uma matriz compacta N×M, em que M é muitas vezes menor que N.
O uso da abordagem proposta reduz a complexidade computacional de N² para MN e, ao mesmo tempo, diminui o consumo de memória. Ela permite gerar previsões para enormes volumes de dados sem sobrecarregar os recursos computacionais e torna o sistema mais robusto ao ruído. Isso se torna especialmente importante em períodos de turbulência de mercado provocados por decisões inesperadas dos bancos centrais e por oscilações bruscas nos preços de commodities.
As consequências práticas são evidentes. Grandes fundos de investimento ganham uma ferramenta para rebalancear carteiras com maior precisão. Hedge funds obtêm uma base para estratégias que levam em conta não apenas a dinâmica de ativos isolados, mas também a dança complexa das interconexões globais. Traders algorítmicos passam a ter a possibilidade de trabalhar com um grande número de instrumentos sem atrasos críticos na tomada de decisão.
Algoritmo SAGDFN
Scalable Adaptive Graph Diffusion Forecasting Network (SAGDFN) é um algoritmo moderno desenvolvido para tornar a previsão de séries temporais mais flexível, escalável e eficiente, mesmo em cenários com grafos extremamente grandes. A ideia central é reduzir de forma significativa a carga computacional e os requisitos de memória sem comprometer a precisão das previsões. Em vez de processar mecanicamente toda a estrutura do grafo, o modelo se concentra nos elementos e nas conexões mais significativos, que exercem influência real sobre o resultado final. Essa abordagem não apenas elimina o ruído excessivo, como também permite gerar previsões de maneira mais rápida, econômica e precisa.
A função α-Entmax desempenha um papel fundamental no funcionamento do SAGDFN. Ela atua como uma espécie de filtro, ajudando o modelo a destacar correlações espaciais realmente importantes entre os nós do grafo e a ignorar conexões secundárias. Isso é especialmente valioso em condições nas quais os dados têm uma estrutura complexa e dinâmica, como ocorre, por exemplo, nos mercados financeiros ou em sistemas de transporte urbano. Com base nas conexões selecionadas, forma-se uma matriz de adjacência compacta, que não é definida manualmente, mas criada durante o treinamento. Essa montagem dinâmica torna o algoritmo mais flexível e capaz de se adaptar a novas condições sem exigir uma reconfiguração completa.
A arquitetura SAGDFN se apoia no esquema codificador-decodificador, já consagrado, mas não exige conhecimento prévio sobre as relações espaciais. Isso confere universalidade ao modelo e permite sua aplicação nas mais diversas áreas: desde a análise de oscilações financeiras, em que é importante capturar interdependências entre múltiplos ativos, até a previsão de fluxos de energia, rotas logísticas e cadeias produtivas. O modelo identifica sequencialmente os vizinhos mais significativos de cada nó, combina-os com as informações originais e forma uma matriz de adjacência densa, que depois é usada na análise espaço-temporal.
A particularidade do SAGDFN é que o treinamento de todos os componentes-chave ocorre de forma síncrona e coordenada. Em um único laço, são otimizados os índices dos nós significativos, seus embeddings, os parâmetros de atenção e a matriz de adjacência final. Para a calibração, é usada a função de perda L1, que permite alcançar um equilíbrio entre a precisão da previsão e a robustez ao ruído nos dados. Essa abordagem garante que, com o tempo, o modelo não apenas melhore a qualidade das previsões, como também se adapte a mudanças na estrutura do sistema analisado.
Assim, o SAGDFN resolve um dos problemas antigos das redes neurais de grafos: como preservar alta precisão preditiva evitando complexidade excessiva e custos computacionais excessivos.
Os autores do framework SAGDFN atribuíram a seleção dos nós mais significativos ao módulo Significant Neighbors Sampling (SNS), uma abordagem metodológica voltada à otimização do processamento computacional em redes neurais em grafo (GNN) quando se trata de prever séries temporais com uma grande quantidade de elementos interconectados.
Implementações tradicionais de modelos de grafos constroem uma matriz de adjacência completa de tamanho N×N e a utilizam na convolução em grafos subsequente para identificar correlações espaciais entre todos os nós do grafo analisado. No entanto, essa abordagem apresenta complexidade computacional quadrática, o que a torna extremamente custosa em termos de recursos. Isso é especialmente verdadeiro quando o número de nós ultrapassa 2.000, uma situação frequente em aplicações reais, seja em mercados financeiros, redes de transporte ou sistemas industriais de monitoramento.
A ideia central do SNS é repensar a importância das conexões: nem todo nó exerce influência significativa sobre o estado de um determinado elemento do grafo. Para uma previsão de qualidade, basta considerar apenas um pequeno subconjunto dos vizinhos mais relevantes, que contribuem de forma decisiva para a dinâmica do sistema. O método propõe selecionar dinamicamente esses vizinhos significativos entre todos os N nós, criando uma matriz de adjacência compacta de tamanho N×M, em que M é substancialmente menor que N. Isso reduz a carga sobre os recursos computacionais e acelera o processamento dos dados, preservando ao mesmo tempo a capacidade do modelo de representar adequadamente as dependências internas do sistema.
O funcionamento do SNS começa com a inicialização da matriz de embeddings dos nós E ∈ RN×d, em que cada linha de Ei é uma representação vetorial do i-ésimo nó e contém informações sobre suas características e interconexões. Em paralelo, é formada a matriz de candidatos C ∈ {1,…,N}N×M, em que cada linha define um conjunto de vizinhos potencialmente significativos para o nó correspondente. Nessa etapa, ainda não está definido quais vizinhos serão de fato os mais importantes: a seleção é feita mais adiante, levando em conta as características espaciais e contextuais dos dados.
Em seguida, o algoritmo SNS ordena os M candidatos de cada nó por relevância, usando uma medida de proximidade entre os embeddings, geralmente a distância euclidiana, embora outras métricas também possam ser aplicadas. Quanto menor a distância entre as representações vetoriais de dois nós, maior a probabilidade de que sua relação reflita uma influência efetiva de um sobre o outro. Depois disso, é formado o conjunto final dos K vizinhos mais significativos, que servem como núcleo da matriz de adjacência. As M−K posições restantes podem ser preenchidas com elementos selecionados aleatoriamente para aumentar a diversidade das conexões e melhorar a robustez do modelo a oscilações locais nos dados. Essa abordagem combinada evita uma rigidez excessiva da estrutura e previne o sobreajuste, que muitas vezes surge quando as conexões são fixadas de forma estática.
Na saída, o método gera uma amostra indexada I de nós significativos, a partir da qual o método constrói uma matriz de adjacência compacta As de tamanho N×M. Essa solução reduz significativamente a complexidade computacional, aproximando-a de um comportamento linear em comparação com a implementação quadrática tradicional O(N²). E faz isso sem sacrificar a qualidade da previsão. Como resultado, o SNS abre caminho para a aplicação de redes neurais de grafos em áreas nas quais antes esses métodos eram considerados excessivamente custosos em termos de recursos: isso viabiliza previsões em tempo real de oscilações de mercado, a distribuição dos fluxos de transporte, mudanças no consumo de energia e outros processos nos quais a interconexão entre os elementos desempenha um papel decisivo.
Assim, Significant Neighbors Sampling não apenas economiza recursos: ele permite repensar a própria lógica de trabalho com grafos de grande porte. Ao substituir o processamento global de todas as conexões por uma análise dinâmica e seletiva, é possível construir modelos preditivos mais flexíveis e adaptativos, que aprendem a se concentrar no que realmente importa, em vez de se afogar em dados excessivos.
O módulo de atenção espacial esparsa multicabeça (Sparse Spatial Multi-Head Attention) no SAGDFN é o núcleo que transforma os nós vizinhos significativos selecionados em uma matriz compacta de conexões As de tamanho N×M, determinando quanta informação deve fluir de cada um dos M nós para um nó específico i durante a convolução em grafos. Diferentemente das abordagens baseadas em informações prévias sobre a topologia, o módulo SS-MHA é construído inteiramente a partir dos dados. Ele não utiliza estruturas externas e não fica sujeito a representações equivocadas ou desatualizadas das relações espaciais. Isso torna o modelo universal e aplicável à resolução de diferentes tarefas nos mercados financeiros, em redes de energia ou em fluxos de transporte, nos quais as dependências entre componentes mudam ao longo do tempo e não se prestam a uma modelagem manual simples.
Tecnicamente, o módulo combina duas ideias centrais. Em primeiro lugar, o produto interno de vetores permite avaliar de forma eficiente e paralela uma medida básica de semelhança entre os nós: o vetor do nó i é transformado em uma matriz de tamanho M×d, pela repetição dessa representação em linha e sua concatenação com os embeddings de seus M vizinhos significativos. Isso forma uma matriz que contém simultaneamente informações sobre o contexto local do nó e seus vizinhos candidatos, abrindo caminho para operações matriciais rápidas em plataformas modernas de diferenciação automática.
Em segundo lugar, os autores do framework SAGDFN abandonam uma abordagem puramente linear e aprendem uma medida não linear de correlação por meio de pequenos blocos neurais feed-forward (FFN). Para cada nó e cada cabeça de atenção, esses FFN transformam as representações concatenadas em uma matriz de pontuações Y, na qual duas colunas são interpretadas, respectivamente, como correlações prováveis e menos prováveis. Nesse ponto, a arquitetura multicabeça lembra a atuação de um grupo de especialistas que observa o mesmo conjunto de dados sob diferentes ângulos: uma cabeça identifica relações sazonais, outra detecta reações a notícias, uma terceira identifica marcadores latentes de risco.
A etapa-chave é a normalização das pontuações. Em vez do SoftMax padrão, que dilui os pesos por todo o conjunto e muitas vezes cria várias conexões pequenas e irrelevantes, os autores do framework propõem usar a função α-Entmax. Ela gera distribuições de atenção esparsas, mas informativas: valores altos são reforçados, enquanto os fracos são suprimidos até zero. Em aplicações financeiras, isso é crítico: no mercado, apenas poucos instrumentos realmente definem a direção em um dado momento, como uma moeda de reserva, um grande índice ou uma commodity-chave. A α-Entmax atua como uma lente, focando nos sinais mais fortes e eliminando o ruído de fundo. O parâmetro α confere flexibilidade: ao variar do SoftMax (α=1) ao SparseMax (α=2), permite selecionar o grau ideal de esparsidade para cada domínio de dados.
Na prática, para cada cabeça de atenção são formadas pontuações normalizadas Zp, que são combinadas em um tensor multidimensional Zi para o nó i. Em seguida, para todos os nós, é formado um tensor Z de tamanho N×M×(2P) e, por meio de uma transformação linear com pesos Wa, ele é convertido na matriz final As de tamanho N×M. Essa matriz já não representa um grafo denso N×N; em vez disso, seleciona cuidadosamente, para cada nó, apenas os M sinais que realmente influenciam a convolução em grafos subsequente.
Essa abordagem é especialmente eficaz para mercados financeiros, nos quais os instrumentos que influenciam o movimento do preço hoje podem deixar de influenciar amanhã. Por exemplo, em períodos de pânico, ouro e iene podem passar a liderar; em uma fase de crescimento econômico, esse papel pode caber ao índice S&P 500 e às ações de tecnologia; em um choque energético, aos preços do petróleo e às moedas de países exportadores de energia. O módulo permite identificar esses líderes visíveis e ocultos, excluindo correlações aleatórias capazes de distorcer a previsão.
Além de melhorar a precisão das previsões, a α-Entmax traz outras vantagens: as pontuações esparsas reduzem o número de operações desnecessárias na convolução em grafos, tornando o modelo mais interpretável; o analista consegue ver quais M nós realmente influenciaram a previsão de um instrumento específico. A combinação do preenchimento aleatório na seleção dos vizinhos com a normalização esparsa garante a atualização dos embeddings em toda a rede, sem deixar variáveis importantes de fora.
A implementação técnica leva em conta o uso eficiente da GPU e de frameworks de diferenciação automática: concatenação e processamento em lote, FFN compactas para cada cabeça, transformação linear do último tensor Z em As para uma parametrização mais fina da influência de cada cabeça e de cada canal.
Em conjunto, o Sparse Spatial Multi-Head Attention oferece um compromisso prático entre precisão e eficiência no uso de recursos: sensibilidade aos sinais mais importantes, adaptação a condições variáveis e escalabilidade para milhares de séries temporais.
A previsão baseada na arquitetura codificador-decodificador no framework SAGDFN é a culminação de todas as etapas anteriores. Aqui, os vizinhos significativos já selecionados, a atenção espacial esparsa multicabeça e a convolução em grafos eficiente são combinados com um modelo sequencial robusto, capaz de levar em conta a dinâmica temporal. Diferentemente de abordagens simples, que se concentram nas dependências espaciais ou no aspecto temporal, a abordagem proposta pelos autores do framework permite descrever e usar as duas dimensões em conjunto. Isso gera previsões mais precisas e robustas para séries temporais multivariadas.
Intuitivamente, o funcionamento do codificador-decodificador pode ser descrito da seguinte forma. O codificador concentra as informações da sequência histórica, acumulando padrões espaço-temporais em uma representação compacta de estados ocultos. Em seguida, o decodificador gera previsões passo a passo, usando a representação obtida e os valores previstos recebidos a cada etapa.
Neste caso, o componente crítico é o mecanismo rápido de difusão em grafos, baseado na matriz de adjacência compacta As, que garante a transferência de informações relevantes entre os nós do grafo a cada iteração temporal.
A convolução em grafos em múltiplas etapas, que implementa a difusão de informações pelos vizinhos, é definida pela expressão:
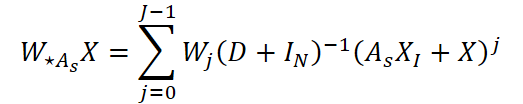
em que D é a matriz diagonal de graus de As, IN é a matriz identidade de dimensão N, e XI é a matriz dos dados originais, agregados pelos M vizinhos selecionados, com indexação por I.
Esse operador preserva as informações sobre o próprio estado do nó, representadas pelo termo X, e acumula o sinal dos vizinhos significativos, representado por AsXI; em seguida, normaliza esses sinais pela soma dos graus e os passa por filtros lineares Wj. O benefício prático é a possibilidade de controlar o raio de propagação das informações por meio do parâmetro J: um J pequeno restringe a propagação às relações locais, enquanto um J maior permite considerar influências mais distantes.
Em seguida, os autores do framework SAGDFN integram essa operação em grafos a uma etapa semelhante a uma GRU, substituindo a multiplicação matricial padrão pela convolução em grafos. Assim surge o OneStepFastGConv, uma iteração de uma única etapa que combina agregação espacial e recorrência temporal:
![]()
![]()
![]()
![]()
![]()
Aqui, a concatenação ⊕ combina a observação atual e o estado oculto anterior, enquanto as operações ⊙ e σ mantêm seu significado habitual. Essa etapa garante que, antes da atualização do estado oculto, cada nó leve em conta seus próprios atributos e o sinal de seus vizinhos mais relevantes no grafo. Isso é especialmente importante em finanças: ao formar a previsão do preço de uma ação, considera-se não apenas seu próprio histórico, mas também os movimentos dos principais instrumentos relacionados, como moedas, commodities e índices.
A previsão ocorre em duas etapas: codificador e decodificador. No codificador, executamos o OneStepFastGConv em uma janela histórica de comprimento h, obtendo ao final uma representação Ht0-1 que acumula as informações espaço-temporais de toda a janela de dados analisada.
Em seguida, o decodificador parte do estado inicial Ht0-1 e da observação no passo t0, gerando sequencialmente o número especificado de passos à frente.
O treinamento ocorre por retropropagação ponta a ponta: os gradientes em relação a Θ, incluindo embeddings, parâmetros das FFN no módulo de atenção, pesos da convolução em grafos e parâmetros da GRU, são calculados e usados para atualizar o modelo. Vale destacar que, como os embeddings participam da seleção dos vizinhos e do cálculo de As, a estrutura do grafo também se altera ao longo do treinamento. Isso confere capacidade adaptativa ao sistema, permitindo que ele identifique novas conexões significativas à medida que o mercado muda.
O codificador-decodificador, combinado com o OneStepFastGConv e a estrutura adaptativa As, cria uma plataforma poderosa e flexível para previsão espaço-temporal. Ela combina interpretabilidade, graças à matriz esparsa de conexões e à visualização dos vizinhos relevantes; capacidade adaptativa, com a atualização dinâmica dos embeddings e da estrutura do grafo; e escalabilidade prática, o que a torna uma ferramenta especialmente valiosa para análise e tomada de decisões nos mercados financeiros.
A visualização do framework SAGDFN apresentada pelos autores é mostrada abaixo.
Implementação em MQL5
Após a análise detalhada da parte teórica do framework SAGDFN, passamos à implementação prática das abordagens propostas. Aqui, mostraremos uma das formas práticas de levar as ideias dos autores do framework para o ambiente MQL5. Ao longo do trabalho, examinaremos os seguintes pontos:
- preparação dos dados;
- armazenamento e atualização dos embeddings;
- amostragem dos vizinhos significativos;
- mecanismo de atenção esparsa;
- integração da convolução em grafos rápida à lógica recorrente.
Nosso objetivo é uma implementação funcional, reproduzível e, acima de tudo, prática, adequada para uso real.
O módulo Significant Neighbors Sampling cuida de uma tarefa simples, mas extremamente importante: ele é responsável por selecionar justamente aqueles líderes que de fato moldam a estrutura informacional da rede. A seleção correta dos vizinhos determina quais sinais serão reforçados e quais permanecerão como ruído de fundo.
Aqui vale dizer que os autores do framework SAGDFN propuseram ordenar os M vizinhos mais significativos obtidos na etapa anterior, formando um conjunto dos K elementos mais próximos, que servem como núcleo da matriz de adjacência. As M−K posições restantes são preenchidas com elementos selecionados aleatoriamente para aumentar a diversidade das conexões. Em nossa implementação, decidimos ir além e adicionar o ranqueamento paralelo da amostra aleatória.
A ideia é simples e, ao mesmo tempo, eficiente: em vez de primeiro selecionar os K candidatos mais próximos e depois completá-los com elementos aleatórios, formamos dois pools, um de candidatos pré-selecionados e outro de candidatos aleatórios. Em seguida, avaliamos todos simultaneamente. Entram na amostra final os nós realmente mais próximos com base no embedding dentro do pool combinado, independentemente de terem sido escolhidos por heurística ou de forma aleatória. Essa combinação de intensificação e diversificação dá ao modelo estabilidade e flexibilidade ao mesmo tempo: ele preserva líderes já comprovados, mas não perde a chance de detectar novos centros de influência do mercado.
Vamos portar a implementação desse algoritmo para o contexto OpenCL. Para isso, criaremos o kernel SignificantNeighborsSampling.
__kernel void SignificantNeighborsSampling(__global const float *data, __global const float *candidates, __global const float *random_cands, __global float *neighbors, const int dimension ) { const size_t main = get_global_id(0); const size_t slave = get_local_id(1); const int total_main = (int)get_global_size(0); const int total_slave = (int)get_local_size(1);
O kernel começa com a declaração da assinatura. Ele recebe como entrada os arrays globais data, candidates e random_cands, destinados ao armazenamento dos embeddings das séries e dos dois pools de candidatos. O array neighbors é usado para gravar os resultados. Já o inteiro dimension indica o tamanho do embedding. A assinatura define a distribuição da execução: um work-item global processa um nó principal (main), enquanto o conjunto de work-items locais dentro do grupo fica responsável pelo processamento dos candidatos.
Em seguida, são extraídos os identificadores do contexto de execução, declarados os arrays locais e calculado o local work size.
__local int Idx[LOCAL_ARRAY_SIZE]; __local float Temp[LOCAL_ARRAY_SIZE]; const int ls = min(total_slave, (int)LOCAL_ARRAY_SIZE);
A memória local é uma ferramenta poderosa de aceleração: aqui, ela é usada como buffer para o armazenamento temporário dos índices e das distâncias dentro do subgrupo.
No bloco seguinte, definimos os deslocamentos nos arrays planos dos dados originais para acessar os elementos necessários da sequência.
const int shift_main = RCtoFlat(main, 0, total_main, dimension, 0); int cand = (int)candidates[slave]; int rand_cand = (int)random_cands[slave];
Depois, vale observar que, para buscar os vizinhos mais próximos, usamos dois pools, um deles gerado por amostragem aleatória. Nesse caso, é bastante provável que um ou mais elementos da sequência apareçam nas duas amostras. Por isso, o próximo bloco realiza uma verificação simples de duplicatas. Isso evita que o mesmo índice seja analisado novamente, o que é lógico e economiza cálculos. Na primeira etapa, verificamos a presença de duplicatas dentro da thread atual.
//--- duplicate check if(rand_cand == cand) rand_cand = -1;
Em seguida, verificamos a presença de duplicatas no pool de vizinhos previamente selecionados.
//--- Look in candidates for(int l = 0; l < total_slave; l += ls) { if(slave >= l && slave < (l + ls)) Idx[slave - l] = cand; BarrierLoc; for(int i = 0; i < ls; i++) { if(i >= (slave - l)) continue; if(cand == Idx[i]) cand = -1; if(rand_cand == Idx[i]) rand_cand = -1; } BarrierLoc; }
Aqui, gravamos os índices dos candidatos em lotes no array local de dados e, depois, cada thread compara seus índices com os elementos desse array.
Observe que, para garantir a preservação de uma única cópia de cada elemento, verificamos duplicidade apenas nos índices das threads anteriores. Assim, somente os elementos das threads posteriores são excluídos, preservando a primeira ocorrência do elemento.
Em seguida, realizamos a verificação de forma análoga no pool da amostra aleatória de candidatos.
//--- Look in random candidates for(int l = 0; l < total_slave; l += ls) { if(slave >= l && slave < (l + ls)) Idx[slave - l] = rand_cand; BarrierLoc; for(int i = 0; i < ls; i++) { if(i >= (slave - l)) continue; if(cand == Idx[i]) cand = -1; if(rand_cand == Idx[i]) rand_cand = -1; } BarrierLoc; }
Quando os candidatos passam pela verificação de unicidade dentro do grupo local, calculamos os deslocamentos planos shift_cand e shift_rand_cand para obter o início do embedding de cada candidato no array data.
const int shift_cand = RCtoFlat(cand, 0, total_main, dimension, 0); const int shift_rand_cand = RCtoFlat(rand_cand, 0, total_main, dimension, 0);
Em seguida, tem início o cálculo da distância euclidiana. Primeiro, as variáveis locais que armazenam as distâncias dos candidatos dos dois pools são inicializadas com valores zero.
//--- calc distance float dist_cand = 0; float dist_rand_cand = 0; for(int d = 0; d < dimension; d++) { float value = IsNaNOrInf(data[shift_main + d], 0); if(main != cand && cand >= 0) dist_cand += pow(value - IsNaNOrInf(data[shift_cand + d], 0), 2.0f); if(main != rand_cand && rand_cand >= 0) dist_rand_cand += pow(value - IsNaNOrInf(data[shift_rand_cand + d], 0), 2.0f); }
Depois, em um laço pela dimensionalidade dos embeddings, são extraídos os valores do embedding-alvo e dos candidatos. Para determinar a distância, as variáveis locais acumulam os quadrados das diferenças entre o elemento-alvo e o candidato correspondente.
Vale observar que os cálculos são executados apenas para os elementos não excluídos.
Após o cálculo das distâncias, vem a preparação para o ordenamento das posições. Primeiro, inicializamos as variáveis locais cand_position e rand_position com valores zero, o que corresponde ao primeiro elemento do array. No entanto, verificamos a igualdade entre as distâncias dos elementos do pool previamente selecionado e do pool aleatório. Quando as distâncias são idênticas, damos preferência ao pool de candidatos previamente selecionados e incrementamos o valor de rand_position.
//--- calc position int cand_position = 0; int rand_position = (int)(dist_cand >= dist_rand_cand);
Em seguida, começa uma série de blocos em que as distâncias atuais são reunidas em blocos da memória local Temp, e conta-se quantos elementos da amostra local têm distância menor que a do elemento analisado. A primeira série copia as distâncias do pool de candidatos previamente selecionados ou grava -1 para os elementos ausentes.
//--- by candidates for(int l = 0; l < total_slave; l += ls) { if(slave >= l && slave < (l + ls)) Temp[slave - l] = (cand >= 0 ? IsNaNOrInf(dist_cand, -1) : -1); BarrierLoc; for(int i = 0; i < ls; i++) { if(i == (slave - l)) continue; if(Temp[i] < 0) continue; if(cand >= 0) { if(Temp[i] < dist_cand) cand_position++; else if(Temp[i] < dist_cand && i < (slave - l)) cand_position++; } if(rand_cand >= 0) { if(Temp[i] < dist_rand_cand) rand_position++; else if(Temp[i] < dist_rand_cand && i < (slave - l)) rand_position++; } } BarrierLoc; }
Cada thread do grupo percorre os elementos de Temp, incrementando cand_position e rand_position conforme as distâncias menores encontradas. Aqui é usada uma lógica refinada de desempate (tie-breaking): se duas distâncias forem iguais, a ordem é determinada pelo índice, o que garante determinismo no ordenamento em caso de distâncias iguais. As barreiras garantem que Temp seja preenchido corretamente antes da leitura e limpo em seguida.
Uma segunda série semelhante repete a mesma operação, mas transfere para Temp as distâncias dos elementos da amostra aleatória e ajusta novamente as posições, levando em conta o restante do subgrupo local.
//--- by random candidates for(int l = 0; l < total_slave; l += ls) { if(slave >= l && slave < (l + ls)) Temp[slave - l] = (rand_cand >= 0 ? IsNaNOrInf(dist_rand_cand, -1) : -1); BarrierLoc; for(int i = 0; i < ls; i++) { if(i == (slave - l)) continue; if(Temp[i] < 0) continue; if(cand >= 0) { if(Temp[i] < dist_cand) cand_position++; else if(Temp[i] < dist_cand && i < (slave - l)) cand_position++; } if(rand_cand >= 0) { if(Temp[i] < dist_rand_cand) rand_position++; else if(Temp[i] < dist_rand_cand && i < (slave - l)) rand_position++; } } BarrierLoc; }
Entender essa parte é importante: o algoritmo implementa uma contagem distribuída da posição, em que cada slave calcula independentemente em que posição ficará na lista local do grupo ordenada por distância. Isso nos dá um ordenamento sem classificação global, totalmente local, economizando memória e tempo.
A etapa final é a gravação do resultado. Se o candidato existir e sua posição for menor que o número total de vizinhos buscados, o índice de deslocamento é calculado e o índice do candidato é gravado na célula correspondente do array neighbors.
//--- result if(cand >= 0 && cand_position < total_slave) { const int shift_dist_cand = RCtoFlat(main, cand_position, total_main, total_slave, 0); neighbors[shift_dist_cand] = cand; } if(rand_cand >= 0 && rand_position < total_slave) { const int shift_dist_cand = RCtoFlat(main, rand_position, total_main, total_slave, 0); neighbors[shift_dist_cand] = rand_cand; } }
O algoritmo apresentado realiza a avaliação paralela de candidatos determinísticos e aleatórios, elimina duplicatas localmente, calcula as distâncias e ordena os candidatos por posição na subamostra local, sem classificação global.
Hoje avançamos bastante e cobrimos muitos pontos importantes, e o artigo já ficou bastante sólido. Agora é um bom momento para fazer uma pausa, deixar as ideias amadurecerem e olhar para o que foi feito com uma nova perspectiva. No próximo artigo, voltaremos ao tema com energia renovada e continuaremos esse caminho, avançando passo a passo.
Conclusão
Neste artigo, analisamos o framework SAGDFN, que se destaca entre soluções semelhantes por sua escalabilidade, pela capacidade de trabalhar de forma eficiente com grafos de grande porte e por minimizar os custos computacionais sem perda de precisão. Sua abordagem adaptativa para selecionar conexões significativas entre os nós permite preservar informações essenciais e, ao mesmo tempo, evitar que o modelo seja sobrecarregado com dados desnecessários.
No bloco teórico, examinamos detalhadamente as principais características e os mecanismos internos do framework. Explicamos os princípios de funcionamento do algoritmo e, em seguida, demos o primeiro passo rumo à sua implementação prática. Foi dada atenção especial ao módulo Significant Neighbors Sampling, que desempenha um papel importante na otimização computacional e na redução dos custos em grafos de grande porte. Ao mesmo tempo, introduzimos uma série de melhorias, tornando a seleção dos vizinhos mais flexível e adaptativa.
Este estudo representou uma etapa importante no caminho para a criação de uma ferramenta preditiva completa, capaz de processar grandes volumes de dados com eficiência e extrair deles dependências espaço-temporais úteis. No próximo artigo, continuaremos essa linha, ampliando a arquitetura com novos componentes e nos aproximando gradualmente do teste abrangente de todo o sistema em dados históricos reais.
Referências
- SAGDFN: A Scalable Adaptive Graph Diffusion Forecasting Network for Multivariate Time Series Forecasting
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA para treinamento offline de modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA para treinamento online de modelos |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classes | Estrutura para descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classes | Biblioteca de classes para criação de uma rede neural |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19323
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso