
Desenvolvendo um EA multimoeda (Parte 11): Início da automação do processo de otimização
Introdução
No artigo anterior artigo, estabelecemos a base para o uso fácil dos resultados obtidos durante a otimização para criar um EA com várias instâncias de estratégias de trading trabalhando em conjunto. Agora, não precisaremos mais configurar manualmente no código ou nas variáveis de entrada do EA os parâmetros de todas as instâncias usadas. Será suficiente salvar a string de inicialização em um formato específico em um arquivo, ou inseri-la como texto no código-fonte, para que o EA possa utilizá-la.
Até agora, a formação da string de inicialização era feita manualmente. Agora, chegou finalmente o momento de realizar o processo de criação automática da string de inicialização do EA com base nos resultados da otimização. É bem possível que, neste artigo, ainda não consigamos uma solução totalmente automatizada, mas, pelo menos, devemos avançar significativamente na direção pretendida.
Definição do problema
De modo geral, nossos objetivos podem ser formulados da seguinte forma: queremos um EA que seja executado no terminal e realize a otimização de um EA com uma instância de estratégia de trading em vários símbolos e timeframes. Que sejam os símbolos EURGBP, EURUSD, GBPUSD e os timeframes H1, M30, M15. Precisamos ter a possibilidade de escolher, a partir dos resultados salvos no banco de dados para cada otimização, aqueles que se referem a um símbolo e timeframe específicos (e, no futuro, a outras combinações de parâmetros de teste).
De cada grupo de resultados para uma combinação de símbolo e timeframe, escolheremos os melhores com base em diferentes critérios. Todas as instâncias selecionadas serão colocadas em um único (por enquanto, único) grupo de instâncias. Em seguida, será necessário definir um multiplicador para o grupo. Isso será feito futuramente por um EA separado, mas, por enquanto, podemos realizar essa operação manualmente.
Com base no grupo selecionado e no multiplicador, formaremos a string de inicialização que será usada no EA final.
Conceitos
Para uso futuro, introduzimos alguns conceitos adicionais:
- EA Universal — é um EA ao qual passamos a string de inicialização, e então ele está pronto para operar na conta de trading. Pode-se fazer com que ele leia a string de inicialização a partir de um arquivo, com o nome especificado nas variáveis de entrada, ou obtê-la de um banco de dados com o nome e a versão do projeto.
- EA Otimizador — é um EA que será responsável por executar todas as ações de otimização dos projetos. Quando executado no gráfico, ele encontrará no banco de dados as informações necessárias sobre as ações de otimização e as executará sequencialmente. O resultado do seu trabalho será uma string de inicialização salva para o EA Universal.
- EAs de Etapas — são EAs que serão diretamente otimizados no testador. Haverá vários, conforme o número de etapas realizadas. O EA Otimizador executará a otimização desses EAs e monitorará sua conclusão.
Nesta parte do artigo, vamos nos limitar a uma única etapa — a otimização dos parâmetros de uma instância de estratégia de trading. A segunda etapa — combinar várias das melhores instâncias em um grupo e sua normalização — será feita manualmente por enquanto.
Como EA Universal, por enquanto faremos um EA que poderá construir a string de inicialização por conta própria, escolhendo do banco de dados as informações sobre boas instâncias de estratégias de trading.
As informações sobre as ações de otimização necessárias devem ser armazenadas no banco de dados de forma conveniente. Precisamos ter a capacidade de criar essas informações de forma relativamente simples. Vamos deixar de lado, por enquanto, a questão de como essas informações irão para o banco de dados. Uma interface conveniente pode ser implementada mais tarde. Agora, o mais importante é entender a estrutura dessas informações e criar a estrutura adequada de tabelas no banco de dados.
Começaremos com a identificação de entidades mais gerais, e gradualmente nos aprofundaremos em entidades mais simples. No final, chegaremos à entidade já criada anteriormente, que representa as informações de uma única passagem do testador.
Projeto
No nível mais alto, teremos a entidade "Projeto". Essa é uma entidade composta: um projeto consistirá em várias etapas. A entidade "Etapa" será discutida mais adiante. O projeto é caracterizado por um nome e uma versão. Pode ter alguma descrição. Um projeto pode estar em vários estados: "criado", "colocado na fila para execução", "executado" e "concluído". Também faz sentido armazenar nessa entidade a string de inicialização gerada após a conclusão do projeto para o EA Universal.
Para facilitar o uso das informações do banco de dados em programas MQL5, implementaremos uma ORM simples no futuro, ou seja, criaremos classes em MQL5 que representarão todas as entidades que vamos armazenar no banco de dados.
Nos objetos da classe para a entidade "Projeto", no banco de dados, serão armazenados:
- id_project — identificador do projeto.
- name — nome do projeto, que será usado no EA Universal para buscar a string de inicialização.
- version — versão do projeto, que será determinada, por exemplo, com base nas versões das instâncias de estratégias de trading.
- description — descrição do projeto, texto livre contendo detalhes importantes sobre o projeto. Pode ser vazio.
- params — string de inicialização para o EA Universal, que será preenchida após a conclusão do projeto. Inicialmente será vazio.
- status — status (estado) do projeto, que pode ter quatro valores possíveis: Created, Queued, Processing, Done. Inicialmente, o projeto é criado com o status Created.
Esse conjunto de campos pode ser expandido no futuro, mas, por enquanto, será suficiente.
Quando o projeto está pronto para ser executado, ele é alterado para o estado Queued. Essa mudança, por enquanto, será feita manualmente. Nosso EA de otimização procurará projetos com esse status e os mudará para o status Processing.
Ao iniciar e concluir qualquer etapa, verificaremos a necessidade de atualizar o status do projeto. Se a primeira etapa for iniciada, o projeto mudará para o estado Processing. Quando a última etapa for concluída, o projeto será alterado para o estado Done. Nesse momento, o valor do campo *params* será preenchido, ou seja, ao término do projeto, obteremos a string de inicialização, que poderá ser passada para o EA Universal.
Etapa
Como mencionado anteriormente, a execução de cada projeto é dividida em várias etapas. A principal característica de uma etapa é o EA que será executado durante essa fase para otimização no testador (EA da etapa). Também será definido o intervalo de teste para a etapa. Esse intervalo será o mesmo para todas as otimizações realizadas nessa etapa. Vamos prever o armazenamento de outras informações de otimização (depósito inicial, modo de simulação de ticks, etc.).
Uma etapa pode ter uma etapa anterior (parent). Nesse caso, a execução da etapa só começará após a conclusão da etapa anterior.
Nos objetos dessa classe no banco de dados serão armazenados:
- id_stage — identificador da etapa.
- id_project — identificador do projeto ao qual a etapa pertence.
- id_parent_stage — identificador da etapa anterior (parent).
- name — nome da etapa.
- expert — nome do EA a ser executado na otimização desta etapa.
- from_date — data de início do período de otimização.
- to_date — data de término do período de otimização.
- forward_date — data de início do período forward de otimização. Pode estar vazio, caso em que o modo forward não será usado.
- outros campos com parâmetros de otimização (depósito inicial, modo de simulação de ticks, etc.), que terão valores padrão e não exigirão mudanças geralmente.
- status — status (estado) da etapa, que pode ter três valores possíveis: Queued, Processing, Done. Inicialmente, a etapa é criada com o status Queued.
Cada etapa, por sua vez, consiste em uma ou mais tarefas (jobs). Quando a primeira tarefa for iniciada, a etapa passará para o estado Processing. Quando todas as tarefas forem concluídas, a etapa mudará para o estado Done.
Tarefa
A execução de cada etapa consiste na execução sequencial de todas as tarefas incluídas nela. As principais características de uma tarefa serão o símbolo, o timeframe e os parâmetros de entrada do EA que está sendo otimizado na etapa que contém essa tarefa.
Nos objetos dessa classe no banco de dados serão armazenados:
- id_job — identificador da tarefa.
- id_stage — identificador da etapa à qual a tarefa pertence.
- symbol — símbolo (ativo de negociação) de teste.
- period — timeframe de teste.
- tester_inputs — configurações dos parâmetros de entrada do EA para otimização.
- status — status (estado) da tarefa, que pode ter três valores possíveis: Queued, Processing, Done. Inicialmente, o trabalho é criado com o status "Queued".
Cada trabalho consistirá em uma ou várias tarefas de otimização. Quando a primeira tarefa de otimização é iniciada, o trabalho passa para o estado "Processing". Após a conclusão de todas as tarefas de otimização, o trabalho muda para o estado "Done".
Tarefa de otimização
A execução de cada trabalho consiste na execução sequencial de todas as tarefas incluídas. A principal característica da tarefa será o critério de otimização. As demais configurações para o testador serão herdadas do trabalho.
Nos objetos desse tipo, no banco de dados, serão armazenados:
- id_task – identificador da tarefa.
- id_job – identificador do trabalho no qual essa tarefa está inserida.
- optimization_criterion – critério de otimização para essa tarefa.
- start_date – data de início da tarefa de otimização.
- finish_date – data de conclusão da tarefa de otimização.
- status – status da tarefa de otimização, que pode ter três estados possíveis: Queued, Processing, Done. Inicialmente, a tarefa de otimização é criada com o status "Queued".
Cada tarefa consistirá em vários passes de otimização. Ao iniciar o primeiro passe de otimização, a tarefa passa para o estado "Processing". Quando todos os passes de otimização forem concluídos, a tarefa mudará para o estado "Done".
Passe de otimização
Já nos familiarizamos com eles no artigo anterior, no qual adicionamos a salvaguarda automática dos resultados de todos os passes durante a otimização no testador de estratégias. Agora, vamos adicionar à entidade "Passe de otimização" um novo campo contendo o identificador da tarefa à qual esse passe pertence.
Assim, nos objetos desse tipo, no banco de dados, serão armazenados:
- id_pass – identificador do passe.
- id_task – identificador da tarefa à qual pertence o passe.
- campos de resultados do passe – grupo de campos para todas as estatísticas disponíveis do passe (número do passe, número de transações, fator de lucro, etc.).
- params – string de inicialização com os parâmetros das instâncias de estratégias usadas nesse passe.
- inputs – valores dos parâmetros de entrada do passe.
- pass_date – data de conclusão do passe.
Em comparação com a implementação anterior, modificamos o conjunto de informações salvas sobre os parâmetros das estratégias usadas em cada passe. De maneira mais geral, precisaremos salvar informações sobre um grupo de estratégias. Portanto, faremos com que, mesmo para uma única estratégia, seja salvo um grupo de estratégias que inclui uma única estratégia.
Não haverá campo de status para o passe, pois os registros nesta tabela só serão adicionados após a conclusão do passe. Portanto, a própria existência de um registro já indica que esse passe foi concluído.
Como nosso banco de dados já enriqueceu consideravelmente sua estrutura, faremos alterações no código que lida com a criação e o gerenciamento do banco de dados.
Criação e gerenciamento do banco de dados
Durante o processo de desenvolvimento, precisaremos recriar o banco de dados com uma estrutura atualizada várias vezes. Portanto, criaremos um script auxiliar simples que realizará apenas uma ação: recriar o banco de dados e preenchê-lo com os dados iniciais necessários. Quais dados iniciais devemos preencher na base de dados ainda será discutido posteriormente.
#include "Database.mqh" int OnStart() { DB::Open(); // Open the database // Execute requests for table creation and filling initial data DB::Create(); DB::Close(); // Close the database return INIT_SUCCEEDED; }
Vamos salvar este código no arquivo CleanDatabase.mq5 na pasta atual.
O método de criação de tabelas CDatabase::Create() anteriormente continha um array de strings com consultas SQL que recriavam uma única tabela. Agora que teremos mais tabelas, manter as consultas SQL diretamente no código-fonte se tornará inconveniente. Vamos mover o texto de todas as consultas SQL para um arquivo separado, de onde serão carregadas para execução dentro do método Create().
Para isso, precisaremos de um método que leia todas as consultas a partir de um arquivo, dado o nome do arquivo, e as execute:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: ... // Make a request to the database from the file static bool ExecuteFile(string p_fileName); }; ... //+------------------------------------------------------------------+ //| Making a request to the database from the file | //+------------------------------------------------------------------+ bool CDatabase::ExecuteFile(string p_fileName) { // Array for reading characters from the file uchar bytes[]; // Number of characters read long len = 0; // If the file exists in the data folder, then if(FileIsExist(p_fileName)) { // load it from there len = FileLoad(p_fileName, bytes); } else if(FileIsExist(p_fileName, FILE_COMMON)) { // otherwise, if it is in the common data folder, load it from there len = FileLoad(p_fileName, bytes, FILE_COMMON); } else { PrintFormat(__FUNCTION__" | ERROR: File %s is not exists", p_fileName); } // If the file has been loaded, then if(len > 0) { // Convert the array to a query string string query = CharArrayToString(bytes); // Return the query execution result return Execute(query); } return false; }
Agora, vamos fazer alterações no método Create(). Convencionamos que o arquivo com o esquema do banco de dados e dados iniciais terá um nome fixo: ao nome do banco de dados será adicionada a string ".schema.sql".
//+------------------------------------------------------------------+ //| Create an empty DB | //+------------------------------------------------------------------+ void CDatabase::Create() { string schemaFileName = s_fileName + ".schema.sql"; bool res = ExecuteFile(schemaFileName); if(res) { PrintFormat(__FUNCTION__" | Database successfully created from %s", schemaFileName); } }
Agora podemos usar qualquer ambiente de trabalho com bancos de dados SQLite para criar todas as tabelas e preenchê-las com dados iniciais. Depois disso, podemos exportar o banco de dados resultante como um conjunto de consultas SQL para um arquivo e usá-lo em nossos programas MQL5.
A última alteração que precisaremos fazer neste estágio no classe CDatabase está relacionada à necessidade de executar consultas não apenas para inserir dados, mas também para obter dados das tabelas. No futuro, todo o código responsável pela obtenção de dados deve ser distribuído entre classes separadas, que trabalharão com as diferentes entidades armazenadas no banco de dados. Mas, por enquanto, como ainda não temos essas classes, recorreremos a medidas temporárias.
A leitura de dados com os recursos fornecidos pelo MQL5 é uma tarefa mais complexa do que a inserção. Para obter as linhas dos resultados da consulta, precisaremos criar um novo tipo de dado (estrutura) em MQL5, projetada especificamente para armazenar os dados retornados por uma consulta específica. Depois, será necessário enviar a consulta e obter um handle para o resultado. Com esse handle, podemos iterar sobre os resultados em um loop, armazenando cada linha da consulta na estrutura previamente criada.
Portanto, dentro da classe CDababase, a implementação de um método universal para ler os resultados de consultas arbitrárias não é simples. Por isso, vamos optar por uma abordagem mais simples: em vez de escrever essa implementação, deixaremos isso para o nível superior. Para isso, só precisaremos fornecer o handle da conexão com o banco de dados, armazenado no campo s_db, para o nível superior:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: static int Id(); // Database connection handle ... }; ... //+------------------------------------------------------------------+ //| Database connection handle | //+------------------------------------------------------------------+ int CDatabase::Id() { return s_db; }
Vamos salvar o código gerado no arquivo Database.mqh na pasta atual.
EA Otimizador
Agora podemos começar a criar o EA Otimizador. Primeiramente, precisaremos de uma biblioteca para trabalhar com o testador do fxsaber, mais especificamente este arquivo incluído:
#include <fxsaber/MultiTester/MTTester.mqh> // https://www.mql5.com/ru/code/26132
O EA Otimizador realizará a maioria de seu trabalho periodicamente, usando um temporizador. Portanto, na função de inicialização, criaremos o temporizador e lançaremos seu handler para execução imediatamente. Como as tarefas de otimização geralmente levam dezenas de minutos, um intervalo de cinco segundos para a ativação do temporizador parece ser mais do que suficiente:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Create the timer and start its handler EventSetTimer(5); OnTimer(); return(INIT_SUCCEEDED); }
No handler do temporizador, verificaremos se o testador está disponível no momento. Se sim, e se houver uma tarefa sendo executada, devemos realizar as ações para concluí-la. Em seguida, obtemos do banco de dados o identificador e os parâmetros de entrada da próxima tarefa de otimização e a iniciamos, chamando a função StartTask():
//+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { PrintFormat(__FUNCTION__" | Current Task ID = %d", currentTaskId); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the tester is not in use if (MTTESTER::IsReady()) { // If the current task is not empty, if(currentTaskId) { // Complete the current task FinishTask(currentTaskId); } // Get the number of tasks in the queue totalTasks = TotalTasks(); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task currentTaskId = GetNextTask(currentSetting); // Launch the current task StartTask(currentTaskId, currentSetting); Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, currentTaskId)); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
Na função de inicialização da tarefa, utilizaremos os métodos da classe MTTESTER para carregar os parâmetros de entrada no testador e iniciar o testador no modo de otimização. Também atualizaremos as informações no banco de dados, salvando o horário de início da tarefa atual e seu status:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", taskId, setting); // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Open(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
A função que obtém a próxima tarefa do banco de dados é bastante simples. Basicamente, ela executa uma consulta SQL e obtém os resultados. Observe que o identificador da próxima tarefa é retornado como resultado da função, enquanto a string com os parâmetros de entrada da otimização é gravada na variável setting, que é passada como argumento por referência para a função:
//+------------------------------------------------------------------+ //| Get the next optimization task from the queue | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT s.expert," " s.from_date," " s.to_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status = 'Queued'" " ORDER BY s.id_stage, j.id_job LIMIT 1;"; // Open the database DB::Open(); if(DB::IsOpen()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string expert; string from_date; string to_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=Articles\\2024-04-15.14741\\%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=2\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=0\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d||0||0||0||N\r\n" "%s\r\n", row.expert, row.symbol, row.period, row.from_date, row.to_date, row.optimization_criterion, row.id_task, row.tester_inputs ); res = row.id_task; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } return res; }
Alguns valores de parâmetros de entrada de otimização, por enquanto, foram diretamente especificados no código para simplificação. Por exemplo, o depósito será sempre de $10.000, com alavancagem de 1:200, moeda USD, etc. No futuro, se necessário, esses valores também poderão ser obtidos do banco de dados.
O código da função TotalTasks(), que retorna o número de tarefas na fila, é muito semelhante ao da função anterior, por isso não o incluiremos aqui.
Vamos salvar o código gerado no arquivo Optimization.mq5 na pasta atual. Agora precisamos fazer mais algumas pequenas correções nos arquivos criados anteriormente para termos um sistema minimamente autossuficiente.
CVirtualStrategy e CSimpleVolumesStrategy
Nestes classes, removeremos a capacidade de definir o valor do saldo normalizado da estratégia, e faremos com que ele tenha sempre o valor inicial de 10.000. Esse valor só será alterado quando a estratégia for incluída em um grupo com o multiplicador de normalização especificado. Mesmo que queiramos executar uma única instância da estratégia, teremos que adicioná-la a um grupo.
Portanto, definiremos o novo valor no construtor de objetos da classe CVirtualStrategy:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualStrategy::CVirtualStrategy() : m_fittedBalance(10000), m_fixedLot(0.01), m_ordersTotal(0) {}
Agora, removeremos a leitura do último parâmetro da string de inicialização no construtor da classe CSimpleVolumesStrategy:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { // Save the initialization string m_params = p_params; // Read the parameters from the initialization string m_symbol = ReadString(p_params); m_timeframe = (ENUM_TIMEFRAMES) ReadLong(p_params); m_signalPeriod = (int) ReadLong(p_params); m_signalDeviation = ReadDouble(p_params); m_signaAddlDeviation = ReadDouble(p_params); m_openDistance = (int) ReadLong(p_params); m_stopLevel = ReadDouble(p_params); m_takeLevel = ReadDouble(p_params); m_ordersExpiration = (int) ReadLong(p_params); m_maxCountOfOrders = (int) ReadLong(p_params); m_fittedBalance = ReadDouble(p_params); // If there are no read errors, if(IsValid()) { ... } }
Vamos salvar as alterações feitas nos arquivos VirtualStrategy.mqh e CSimpleVolumesStrategy.mqh na pasta atual.
CVirtualStrategyGroup
Nesta classe, adicionamos um novo método que retorna a string de inicialização do grupo atual com um novo valor para o multiplicador de normalização. Esse valor será determinado apenas após a conclusão do passe do testador, então não podemos criar o grupo com o multiplicador correto imediatamente. Basicamente, apenas inserimos o valor fornecido como argumento na string de inicialização, antes da chave de fechamento:
//+------------------------------------------------------------------+ //| Class of trading strategies group(s) | //+------------------------------------------------------------------+ class CVirtualStrategyGroup : public CFactorable { ... public: ... string ToStringNorm(double p_scale); }; ... //+------------------------------------------------------------------+ //| Convert an object to a string with normalization | //+------------------------------------------------------------------+ string CVirtualStrategyGroup::ToStringNorm(double p_scale) { return StringFormat("%s([%s],%f)", typename(this), ReadArrayString(m_params), p_scale); }Vamos salvar as alterações feitas no arquivo VirtualStrategyGroup.mqh na pasta atual.
CTesterHandler
Na classe que salva os resultados dos passes de otimização, adicionaremos uma propriedade estática s_idTask, à qual será atribuído o identificador da tarefa de otimização atual. No método de processamento dos frames de dados recebidos, vamos adicioná-lo ao conjunto de valores passados na consulta SQL para salvar os resultados no banco de dados:
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { ... public: ... static ulong s_idTask; }; ... ulong CTesterHandler::s_idTask = 0; ... //+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Open the database DB::Open(); ... // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { ... // Form an SQL query from the received data query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %d, %s,\n'%s',\n'%s');", s_idTask, pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Add it to the SQL query array APPEND(queries, query); } // Execute all requests DB::ExecuteTransaction(queries); ... }
Vamos salvar o código gerado no arquivo TesterHandler.mqh na pasta atual.
CVirtualAdvisor
E, finalmente, a última correção. Na classe do expert, adicionaremos a normalização automática da estratégia ou do grupo de estratégias utilizadas no EA durante o passe de otimização atual. Para isso, recriamos o grupo de estratégias utilizadas a partir da string de inicialização do EA e, em seguida, formamos a string de inicialização desse grupo com um novo multiplicador de normalização, calculado com base nos resultados do rebaixamento atual do passe:
//+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Re-create the group of used strategies for subsequent normalization CVirtualStrategyGroup* group = NEW(ReadObject(m_params)); // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, // Normalized profit group.ToStringNorm(coeff) // Normalized group initialization string ); delete group; return fittedProfit; }
Vamos salvar as alterações no arquivo VirtualAdvisor.mqh na pasta atual.
Execução da otimização
Tudo está pronto para iniciar a otimização. No banco de dados, criamos um total de 81 tarefas (3 símbolos * 3 timeframes * 9 critérios). Primeiro, escolhemos um intervalo de otimização curto, de apenas 5 meses, e poucas combinações possíveis de parâmetros otimizáveis, pois estávamos mais interessados em testar a funcionalidade do processo de teste automatizado do que nos próprios resultados, como as combinações encontradas de parâmetros de entrada das instâncias das estratégias de trabalho. Após realizar alguns testes e corrigir pequenas falhas encontradas, obtivemos o resultado desejado. A tabela passes foi preenchida com todos os resultados dos passes, incluindo strings de inicialização de grupos normalizados com uma única instância de estratégias.
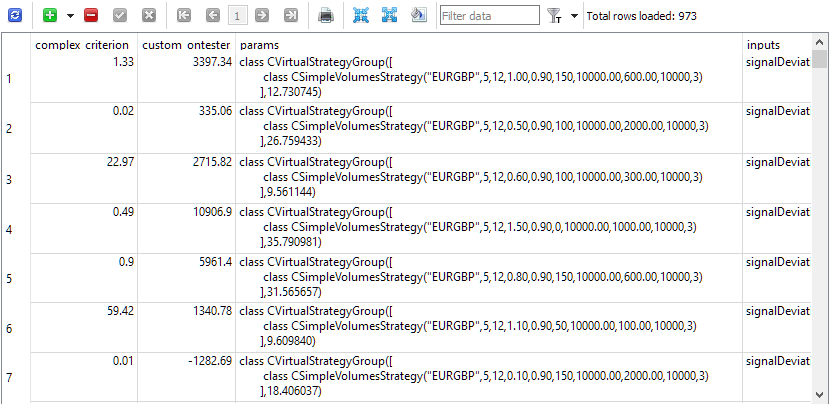
Fig. 1. Tabela passes com os resultados dos passes.
Quando o esquema confirmou sua funcionalidade, já podemos definir uma tarefa mais complexa para ele. Vamos executar as mesmas 81 tarefas em um intervalo mais longo e com um número significativamente maior de combinações de parâmetros. Nesse caso, precisaremos esperar algum tempo: 20 agentes executam uma tarefa de otimização em aproximadamente uma hora. Portanto, com trabalho contínuo, serão necessários cerca de 3 dias para concluir todas as tarefas.
Após isso, faremos manualmente a seleção dos melhores passes entre os milhares obtidos, formulando a consulta SQL adequada para selecionar esses passes. Por enquanto, a seleção será feita apenas com base no coeficiente de Sharpe, que deverá exceder o valor 5. Em seguida, criaremos um novo EA, que, nesta fase, servirá como um EA universal. A parte principal dele será a função de inicialização. Nessa função, extraímos do banco de dados os parâmetros dos melhores passes selecionados, formamos a partir deles a string de inicialização do expert e o criamos.
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" sinput double expectedDrawdown_ = 10; // - Maximum risk (%) sinput double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency sinput double scale_ = 1.00; // - Group scaling multiplier input group "::: Selection for the group" input int count_ = 1000; // - Number of strategies in the group input group "::: Other parameters" sinput ulong magic_ = 27183; // - Magic input bool useOnlyNewBars_ = true; // - Work only at bar opening CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); string query = StringFormat( "SELECT DISTINCT p.custom_ontester, p.params, j.id_job " " FROM passes p JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE p.custom_ontester > 0 AND " " trades > 20 AND " " p.sharpe_ratio > 5" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC LIMIT %d;", count_); DB::Open(); int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return 0; } struct Row { double custom_ontester; string params; int id_job; } row; string strategiesParams = ""; while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Para a otimização, escolhemos um intervalo que inclui dois anos completos: 2021 e 2022. Portanto, vamos ver como se comporta o resultado do EA universal nesse intervalo. Para que o rebaixamento máximo corresponda ao valor de 10%, ajustaremos o valor adequado do multiplicador scale_. Os resultados do teste do EA universal nesse intervalo foram os seguintes:
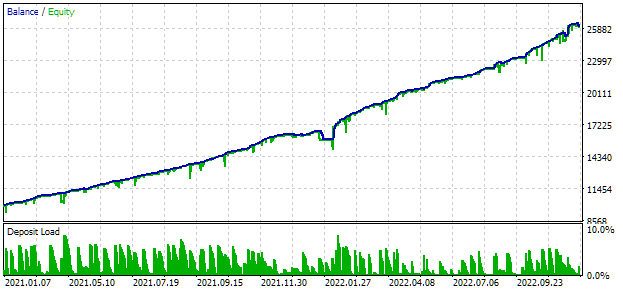
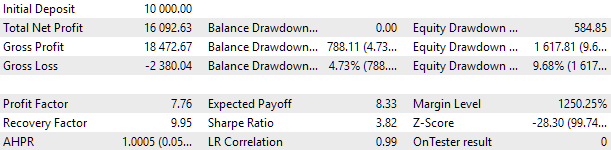
Fig. 2. Resultados do teste do EA universal para 2021-2022 (scale_ = 2).
Cerca de mil instâncias de estratégias participaram do trabalho desse EA. Esses resultados devem ser considerados apenas como intermediários, pois ainda não realizamos muitas das ações voltadas para melhorar o desempenho, que já foram discutidas anteriormente. Em particular, o número de instâncias de estratégias para EURUSD foi significativamente maior do que para EURGBP, o que fez com que as vantagens da abordagem multimoeda ainda não fossem totalmente aproveitadas. Portanto, há esperança de que ainda exista potencial para melhorias. É justamente na realização desse potencial que vamos trabalhar futuramente.
Considerações finais
Assim, foi dado mais um passo importante em direção ao objetivo estabelecido. Agora, temos a capacidade de automatizar o processo de otimização de instâncias de estratégias de trading em diferentes símbolos, timeframes e outros parâmetros. Não é mais necessário monitorar o término de um processo de otimização iniciado para, em seguida, alterar os parâmetros e iniciar o próximo.
O salvamento de todos os resultados no banco de dados nos permite não nos preocupar com possíveis reinicializações do EA otimizador. Se, por algum motivo, o EA otimizador interromper seu trabalho, ao ser reiniciado, ele continuará de onde parou, começando pela próxima tarefa na fila. Além disso, temos uma visão completa de todos os passes do testador durante o processo de otimização.
No entanto, ainda há muito trabalho a ser feito. Ainda não implementamos a atualização dos status das etapas e projetos; somente os status das tarefas estão sendo atualizados. A otimização de projetos compostos por várias etapas ainda não foi considerada. Também não está claro como seria melhor implementar o processamento intermediário de dados das etapas, caso fosse necessário, por exemplo, fazer a clusterização dos dados. Tentaremos abordar esses tópicos nos próximos artigos.
Obrigado a todos que leram até o final, até a próxima!
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14741
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Sim, eu também não esperava que fosse tão simples. No início, estudei o Validate e pensei que teria que escrever algo próprio com base nele, mas depois percebi que poderia fazer isso com uma implementação mais simples.
Mais uma vez, obrigado por essa excelente biblioteca!
Olá, Yuriy,
Estou tentando reproduzir a Parte 11. Criei um SQL com CleanDatabase que o criou em User\Roaming\AppData... No entanto, quando tentei usar o Optimizer, recebi o erro: IPC server not started: O servidor IPC não foi iniciado. Você, ou alguém, pode fornecer uma referência fácil para iniciá-lo?
Além disso, eu uso a opção /portable no Terminal e no MetaEditor com todas as minhas instalações MQL localizadas em C:\"Arquivos de Programas Forex", isso causará algum problema?
Durante meu desenvolvimento do MQ4 e teste de EAs, criei diretórios para todos os pares que eu estava interessado em testar. Usei o comando JOIN para redirecionar os subdiretórios apropriados de cada diretório de teste para o meu diretório comum para iniciar os programas e receber dados de cotação para garantir que todos os testes separados estivessem usando os mesmos dados e executáveis. Além disso, cada teste escreveu um arquivo CVS para cada execução e usei uma versão das funções File para ler os arquivos CVS de cada diretório Files e consolidá-los em um arquivo CVS comum. Se isso for de seu interesse no uso de arquivos CVS em vez do acesso ao SQL, entre em contato.
Nesse ínterim, vou baixar a Parte 20 e me debruçar sobre os exemplos.
CapeCoddah