Discussão do artigo "Desenvolvendo um EA multimoeda (Parte 19): Criando etapas implementadas em Python"
Olá,
iniciamos o Python executando o comando shell neste código:
//+------------------------------------------------------------------+ //| Iniciar uma tarefa| //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // Se essa for uma tarefa de otimização do EA if(m_type == TASK_TYPE_EX5) { // Iniciar uma nova tarefa de otimização no testador MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Atualizar o status da tarefa no banco de dados DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // Se for uma tarefa para executar o programa Python } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Chamar a função do sistema operacional (Windows) para executar o comando do shell ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
Onde:
- m_pythonPath é um caminho para o Python no computador atual;
- m_setting é uma string com o nome do programa Python executado e seus argumentos de linha de comando
Olá
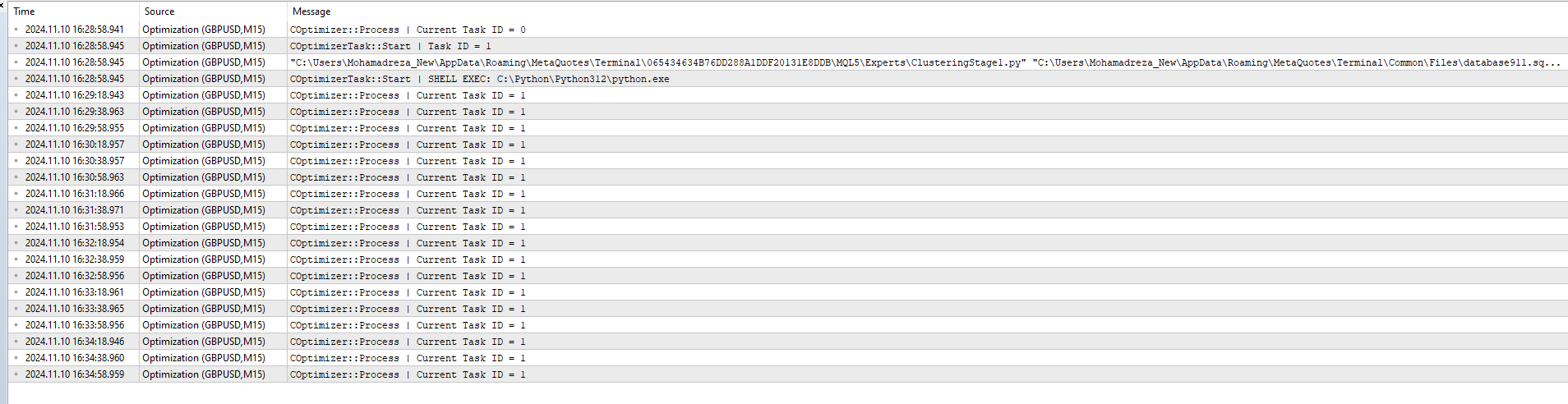
primeiro otimizei o estágio 1 e concluí
depois adicionei o ClusteringStage1.py e a tarefa e o trabalho ao banco de dados e otimizei novamente, mas não funcionou, apenas esta mensagem:
2024.11.10 16:35:18.952 Otimização ( GBPUSD , M15) COptimizer::Process | Current Task ID = 1
{kind=link}
Olá
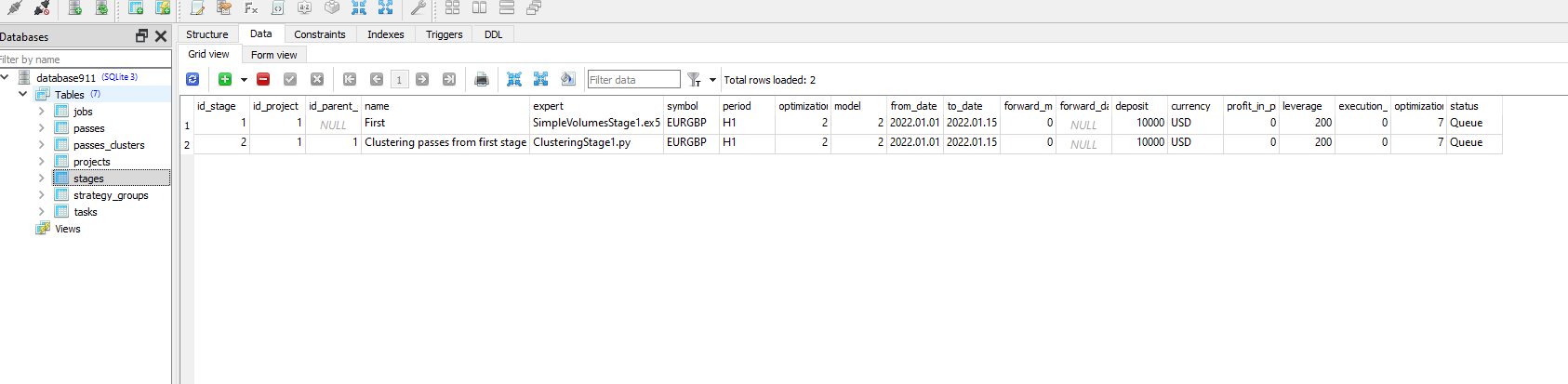
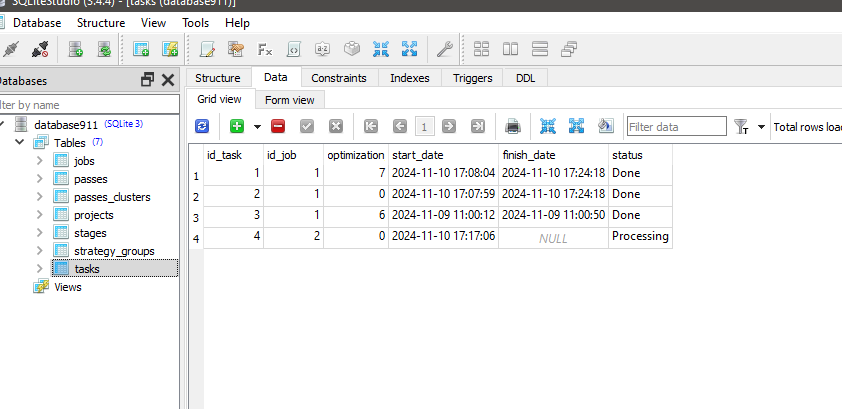
Parece que a execução do programa Python não altera o status da tarefa com id_task=1.
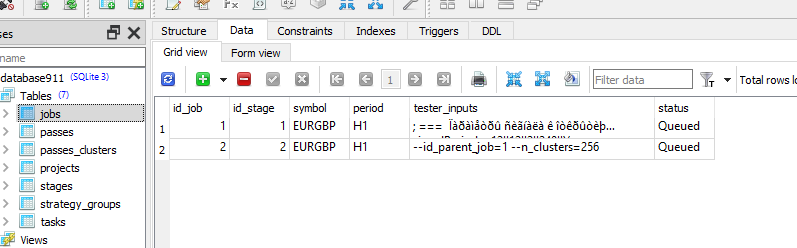
Verifique se no trabalho para essa tarefa você tem os valores corretos na coluna [tester_inputs]. São eles:
--id_parent_job=1 --n_clusters=256
onde 1 é id_job para o trabalho do primeiro estágio. No seu caso, pode ser outro valor numérico.
Você também pode tentar executar o programa Python com parâmetros reais manualmente na linha de comando e, assim, poderá ver as possíveis mensagens de erro
Olá
Parece que a execução do programa Python não altera o status da tarefa com id_task =1.
Verifique se no trabalho para essa tarefa você tem os valores corretos na coluna [tester_inputs]. São eles:
onde 1 é id_job para o trabalho do primeiro estágio. No seu caso, pode ser outro valor numérico.
Você também pode tentar executar o programa Python com parâmetros reais manualmente na linha de comando e, assim, poderá ver as possíveis mensagens de erro
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
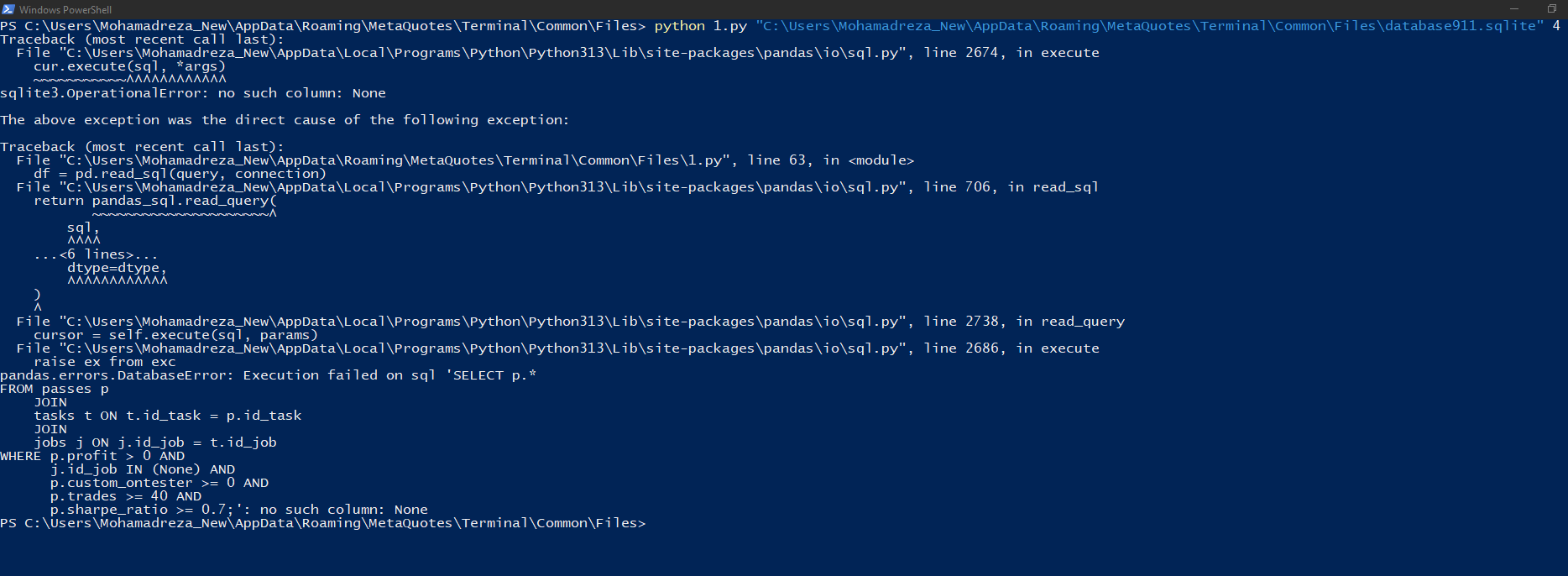
Executo no powershell e vejo o seguinte
Tente executá-lo desta forma:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" usage: ClusteringStage1.py [-h] [--id_parent_job ID_PARENT_JOB] [--n_clusters N_CLUSTERS] [--min_custom_ontester MIN_CUSTOM_ONTESTER] [--min_trades MIN_TRADES] [--min_sharpe_ratio MIN_SHARPE_RATIO] db_path id_task ClusteringStage1.py: error: the following arguments are required: db_path, id_task
Precisamos definir os argumentos: db_path, id_task. Em seguida, recebemos a mensagem de erro que você postou:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 Traceback (most recent call last): File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2674, in execute cur.execute(sql, *args) sqlite3.OperationalError: no such column: None The above exception was the direct cause of the following exception: Traceback (most recent call last): ... File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2686, in execute raise ex from exc pandas.errors.DatabaseError: Execution failed on sql 'SELECT p.* FROM passes p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job WHERE p.profit > 0 AND j.id_job IN (None) AND p.custom_ontester >= 0 AND p.trades >= 40 AND p.sharpe_ratio >= 0.7;': no such column: None
Precisamos também definir dois argumentos: --id_parent_job=1 --n_clusters=256
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
O que você obterá?
Executo o seguinte
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1. py.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
e recebo este erro
ValueError: n_samples=150 deveria ser >= n_clusters=256.
Em seguida, altero n_clusters=150 e executo
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
e acho que funcionou. mas no banco de dados não houve nenhuma alteração
Depois disso, tentei otimizar com n_samples=150, mas não funcionou
Artigo interessante! Vou ler a série inteira, então.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
Por que eles abandonaram a funcionalidade da biblioteca AlgLib?
#include <Math\Alglib\alglib.mqh> Menos apenas em velocidade, mas principalmente porque o python paraleliza os cálculos em todos os núcleos.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo Desenvolvendo um EA multimoeda (Parte 19): Criando etapas implementadas em Python foi publicado:
Para realizar a clusterização, usamos a biblioteca scikit-learn para Python, mais precisamente a implementação do algoritmo K-Means. Embora esse não seja o único algoritmo de clusterização, analisar outras opções, compará-las e escolher a melhor para essa tarefa fugiria ao escopo aceitável. Por isso, escolhemos o primeiro algoritmo disponível, e os resultados obtidos com ele foram suficientemente bons.
No entanto, a execução de um pequeno programa em Python era exigida para usar essa implementação específica. Quando a maior parte das operações ainda era feita manualmente, isso não causava problema. Mas agora que avançamos bastante na automação de todo o processo de teste e seleção de bons grupos de instâncias individuais de estratégias de negociação, mesmo uma operação simples acionada manualmente no meio do pipeline de tarefas sequenciais de otimização parece fora de lugar.
Para corrigir esse inconveniente, podemos seguir dois caminhos. O primeiro consiste em encontrar uma implementação pronta do algoritmo de clusterização escrita em MQL5 ou escrevê-la nós mesmos, caso a busca não seja bem-sucedida. O segundo caminho envolve adicionar a possibilidade de executar, nas etapas necessárias do processo de otimização automática, não apenas EAs escritos em MQL5, mas também programas em Python.
Autor: Yuriy Bykov