
Do básico ao intermediário: Estruturas (IV)

Introdução
No artigo anterior Do básico ao intermediário: Estruturas (III), começamos a lidar com um assunto que gera uma tremenda de uma confusão na cabeça de muito iniciante. Que é justamente a diferença entre um código estruturado e um código bem organizado. Muitos confundem o fato de um código está devidamente organizado, com um código que esteja de fato estruturado. Apesar de aparentemente serem a mesma coisa. Isto não é de fato verdade. Mas aquele artigo anterior, serve apenas como porta de entrada para algo ainda mais elaborado, belo e divertido, dentro do que seria uma programação estruturada.
Como existem diversos conceitos que podem ser mais ou menos complexos de serem entendidos, dependendo da quantidade de prática que cada um já tem. Irei na medida do possível, tentar mostrar cada conceito de maneira bem clara e objetiva. Isto para que você, meu caro leitor, de fato consiga compreender, da forma correta, o que seria um código estruturado. E como podemos trabalhar com ele a fim de construir quase qualquer tipo de coisa. Digo quase, pois existe uma limitação no que rege um código estruturado. Quando estivermos próximos de atingir esta limitação, será necessário, introduzir um outro conceito, que seria o conceito de classes. Neste ponto, sairemos do que seria uma programação estruturada, e passaremos a trabalhar no que é conhecida como programação orientada em objetos. Mas até lá, podermos explorar diversas coisas e nos divertir bastante, criando vários exemplos de código estruturado. A fim de realmente conseguir compreender conceitos e limitações de uma programação estruturada.
Bem, então vamos continuar de onde paramos no artigo anterior. Que foi justamente no momento em que menciono e mostro a clausula public e private, sendo utilizada. Apesar de não ter sido explicado, por que de se fazer aquilo. Então este será o ponto de partida.
Clausula private em uma estrutura
Como por padrão, todo e qualquer elemento definido em uma estrutura, será do tipo público. Não vejo muito sentido em explicar a clausula public. Já que a mesma não precisa de fato ser declarada no código. Ficando assim implícita, no que ser refere a declaração em uma estrutura. Porém, toda via e, entretanto, o mesmo não acontece com a clausula private. Neste caso, a clausula precisa estar explicita no código. Mas isto traz algumas consequências ao código, e na forma de lidar com o mesmo. Então vamos começar com algo bem simples e fácil de entender. E como o objetivo é a didática. Quero que você, meu caro leitor, não procure uma lógica no porque implementar o código, desta ou daquela forma. Tente entender o conceito, pois é isto que realmente importa para nós.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. double Values[]; 08. //+----------------+ 09. void Set(const double &arg[]) 10. { 11. ArrayCopy(Values, arg); 12. } 13. //+----------------+ 14. double Average(void) 15. { 16. double sum = 0; 17. 18. for (uint c = 0; c < Values.Size(); c++) 19. sum += Values[c]; 20. 21. return sum / Values.Size(); 22. } 23. //+----------------+ 24. double Median(void) 25. { 26. double Tmp[]; 27. 28. ArrayCopy(Tmp, Values); 29. ArraySort(Tmp); 30. if (!(Tmp.Size() & 1)) 31. { 32. int i = (int)MathFloor(Tmp.Size() / 2); 33. 34. return (Tmp[i] + Tmp[i - 1]) / 2.0; 35. } 36. return Tmp[Tmp.Size() / 2]; 37. } 38. //+----------------+ 39. }; 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. st_Data Info; 47. 48. Info.Set(H); 49. PrintX(Info.Average()); 50. PrintX(Info.Median()); 51. } 52. //+------------------------------------------------------------------+
Código 01
Este código 01, faz algo, que é muito simples, prático e fácil de entender. A ideia aqui, é criar um código completamente estruturado. Para fazer isto, primeiro precisamos definir a nossa própria estrutura. Isto é feito na linha quatro. Agora preste atenção. Normalmente, e naturalmente, a única coisa que você faria dentro desta estrutura, seria o de declarar a linha sete. Isto por que, foi justamente o que foi explicado e explorado nos artigos onde falei sobre estruturas. No entanto, no artigo anterior, começamos a falar de código estruturado. E para conseguir isto, adicionamos mais coisas a estrutura. No caso, iremos adicionar funções e ou procedimentos. Simplificando: Rotinas internas, irão surgir na estrutura. Sendo isto o que define um código estruturado.
Porém estas rotinas, sejam elas funções ou procedimentos, precisam fazer parte de um contexto. E este contexto tem tudo a ver com as variáveis presentes na estrutura. Ou o objetivo para o qual a estrutura está sendo pensada e implementada. Até neste ponto, acredito que você tenha conseguido compreender. Então, uma vez definida a estrutura, podemos começar a fazer uso da mesma. Para exemplificar, a utilização desta estrutura em particular, usaremos o que se encontra dentro do procedimento OnStart, presente na linha 43.
Primeiro definimos um array de constantes numéricas. Isto na linha 45, não importa o que estes valores representam, apenas precisamos que eles existam. Agora na linha 46, declaramos, ou melhor dizendo, definimos uma variável para podemos acessar a estrutura que foi definida na linha quatro. Uma vez feito isto, temos dois caminhos que podemos seguir. O primeiro é utilizar o que é visto na linha 48, o segundo caminho iremos ver depois. Uma vez que esta linha 48 tenha sido executada, temos na estrutura, o array declarado na linha sete, valores que nos interessa neste exato momento. Agora é que a coisa começa de fato a ficar interessante.
Acompanhe o raciocínio para entender, como um código estruturado torna muito mais fácil entender o propósito de uma variável. Quando declaramos Info, na linha 46, não sabemos ao certo, qual seria o objetivo da própria declaração. Apenas precisávamos de uma variável com aquele tipo específico. No entanto, como a estrutura contém funções e procedimentos internos, que dá contexto, as valores presentes nela. Sabemos que tipo de atividade poderemos adotar ao utilizar a estrutura. Sem que estas funções e procedimentos fossem declarados. A nossa estrutura, poderia servir para qualquer objetivo. E ainda continua servindo. Isto justamente devido a uma questão que ainda está em aberto. No entanto, quando olhamos as linhas 49 e 50, conseguimos entender, que a nossa estrutura tem como objetivo, calcular a média de valores e a mediana presente nos próprios dados que estamos colocando na estrutura.
Este tipo de coisa, cria o que conhecemos como contexto. Ou seja, uma coisa só tem sentido, quando entendendo o motivo pelo qual ela existe. Sem isto, qualquer variável, função ou procedimento, pode significar qualquer coisa e ter qualquer objetivo. Assim, ao executarmos este código 01, o resultado a ser mostrado é visto logo abaixo.
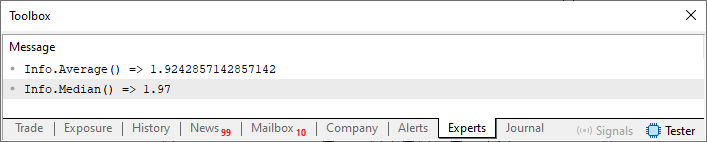
Imagem 01
Ou seja, não nos importa o que os valores declarados na linha 45, significam ou qual a ligação deles com o mundo real. Porém, podemos afirmar que dentro do contexto proposto pela estrutura dos valores o resultado obtido é o que podemos ver na imagem 01. Este tipo de coisa pode ser estendida de diversas maneiras. Pois sempre que, precisamos de algo relacionado aos dados dentro de uma estrutura, podemos usar o contexto, a fim de dar ênfase e simplificar o entendimento do próprio resultado. Já que a própria estrutura nos garante um contexto, para aquele tipo de informação.
Note, que poderíamos criar o mesmo código, com um mesmo objetivo. Porém, não teríamos um contexto real, ligando os dados presentes na estrutura com uma resposta que seria gerada. Mas agora vem a parte, que muitos iniciantes, costumam penar para conseguir entender. Observe que pelo fato de, dentro da estrutura, nenhuma clausula de acesso estar sendo declarada. Tudo que está ali, é considerado público. Ou seja, podemos manipular as informações de maneira completamente arbitrária. Para mostrar isto, e para que você possa compreender como isto é complicado. Vamos mudar o código conforme mostrado logo abaixo.
. . . 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. const double K[] = {12, 4, 7, 23, 38}; 47. 48. st_Data Info; 49. 50. Info.Set(H); 51. PrintX(Info.Average()); 52. 53. ArrayPrint(Info.Values, 2); 54. ZeroMemory(Info); 55. ArrayCopy(Info.Values, K); 56. 57. PrintX(Info.Median()); 58. 59. ArrayPrint(Info.Values, 2); 60. } 61. //+------------------------------------------------------------------+
Código 02
Aqui, neste código 02, que na verdade é apenas um fragmento do código completo. O mesmo estará no anexo. Podemos ver que apenas a parte referente ao procedimento OnStart foi modificado. No entanto, esta modificação, apesar de não ter modificado o contexto da estrutura. Acabou destruindo completamente qualquer expectativa de obtermos valores adequados. Isto porque, está sendo permitido modificar, ou melhor dizendo, acessar a variável interna de entro da estrutura. Isto é algo realmente muito dramático e perigoso. Mas você pode estar pensando: Mas é claro que os valores, quando executarmos este código, serão diferentes. Isto é obvio. Já que estamos atribuindo na linha 55, novos valores a variável definida na linha quatro. Que por sua vez está dentro da estrutura.
Não sei qual o real problema aqui. Já que claramente conseguimos notar o que está acontecendo. Isto é verdade meu caro leitor, porém, devo lembrar, que estes códigos são didáticos. E por conta disto, encontra uma falha é simples. Em um código real, você iria sofre bastante para conseguir fazer isto. Já que o contexto a ser utilizado, se mantem e está presente dentro da estrutura. Porém o fato de que na linha 55 estamos forçando com que uma variável presente dentro da estrutura, venha a ser modificada, sem que a estrutura de fato esteja ciente disto. Torna tudo muito mais complicado e difícil e entender por que os resultados estão errados. Não estão coerentes com aquilo que era esperado.
Este tipo de falha tem um nome, que é uma falha de encapsulamento. Já que um código, que não deveria ver algo, está vendo isto. Ou pior, está conseguindo modificar uma variável que não deveria ser modificada. No entanto, o problema é ainda maior. Para entender isto, é preciso entender o resultado da execução deste código 02. Isto pode ser visto logo abaixo.
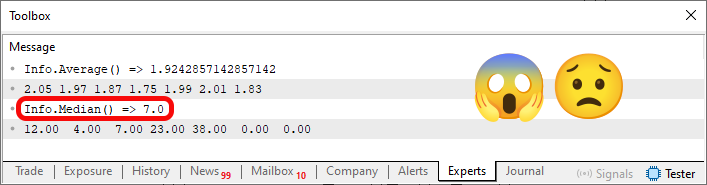
Imagem 02
Preste atenção, pois isto, é motivo de reprovação em um teste para programador, onde o contratante que perceber seu nível de conhecimento sobre possíveis falhas em códigos. Quando a linha 50 é executada, iremos alocar memória suficiente para conter os valores presentes na linha 45. Até aí tudo certo. Por conta disto, no momento em que a linha 53 é executada, podemos ver os valores que estão sendo declarados na linha 45. Ou seja, de fato o código funciona como esperado. A estrutura está sendo definida corretamente. Porém, toda via e, entretanto, no momento em que a linha 54 é executada. Toda e qualquer variável ou elemento variável, presente na estrutura, será zerado. Isto não é um erro. Na verdade, em muitos casos, este tipo de coisa é até aceitável e desejável. Já que, podemos ter diversas coisas previamente definidas em uma estrutura e queremos destruir todas elas.
No entanto, quando a linha 55 é executada, temos um erro sendo implantando no código. Isto por que, a memória alocada NÃO FOI LIBERDA, ela apenas foi zerada. Assim, o real conteúdo da memória é mostrado pela linha 59. Com isto a mediana de K, que é mostrada em destaque na imagem 02, está errada. Mas por que está errada? Não entendi. Bem, para entender isto, é preciso você saber qual seria a mediana de K. E ao olha o código 02, caso você saiba como encontrar a mediana, irá notar que o valor correto seria doze e não sete. E o motivo do valor está errado é justamente os zeros, ou elementos que se encontra na estrutura, e que podem ser vistos devido a linha 59. Que NÃO DEVERIAM ESTAR ALI.
Justamente por causa desde detalhe, é que precisamos fazer uso da clausula private. E assim, finalmente chegamos ao ponto que originou este tópico. Entender por que e quanto utilizar a clausula private. Mas você pode estar pensando: Cara, mas e se por um acaso, ao invés de usar as coisas como mostrado neste código 02. Eu tivesse repetido a linha 50, na linha 55, só que trocando o H pelo K. Será que isto não resolveria o problema? Neste caso não meu caro leitor. Isto por que o código da estrutura contém uma pequena falha. Mas já vamos chegar lá. No caso, a ideia aqui, é justamente mostrar que podemos acabar cometendo certos erros sem percebermos. Mas se fizermos uso dos conceitos adequados, com toda a certeza, tais erros seriam evitados e o código seria corrigido muito mais facilmente.
Assim, para resolver esta primeira falha, que é o fato de podermos acessar diretamente a variável declarada dentro da estrutura. Precisamos mudar o código como mostrado abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayCopy(Values, arg); 16. } 17. //+----------------+ 18. double Average(void) 19. { 20. double sum = 0; 21. 22. for (uint c = 0; c < Values.Size(); c++) 23. sum += Values[c]; 24. 25. return sum / Values.Size(); 26. } 27. //+----------------+ 28. double Median(void) 29. { 30. double Tmp[]; 31. 32. ArrayCopy(Tmp, Values); 33. ArraySort(Tmp); 34. if (!(Tmp.Size() & 1)) 35. { 36. int i = (int)MathFloor(Tmp.Size() / 2); 37. 38. return (Tmp[i] + Tmp[i - 1]) / 2.0; 39. } 40. return Tmp[Tmp.Size() / 2]; 41. } 42. //+----------------+ 43. }; 44. //+------------------------------------------------------------------+ 45. #define PrintX(X) Print(#X, " => ", X) 46. //+------------------------------------------------------------------+ 47. void OnStart(void) 48. { 49. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 50. const double K[] = {12, 4, 7, 23, 38}; 51. 52. st_Data Info; 53. 54. Info.Set(H); 55. PrintX(Info.Average()); 56. 57. ArrayPrint(Info.Values, 2); 58. ZeroMemory(Info); 59. ArrayCopy(Info.Values, K); 60. 61. PrintX(Info.Median()); 62. 63. ArrayPrint(Info.Values, 2); 64. } 65. //+------------------------------------------------------------------+
Código 03
Agora preste muita, mas muita atenção. Pois muitos programadores, não usam a clausula private em estruturas, justamente por conta do que irá acontecer neste exato momento.
Lembra que eu disse, que o problema todo era causado, por conta da linha 59? Porém, agora neste código 03, estamos dizendo ao compilador que a variável declarada dentro da estrutura é do tipo privativa, ou seja, ela NÃO SERÁ MAIS VISIVEL, FORA DO CORPO DA ESTRUTURA. Isto justamente devido a linha sete. Porém precisamos da linha 11, para permitir que outras coisas possam ser acessadas fora do corpo da estrutura. No caso, funções e procedimentos. Sem isto, a estrutura passaria a ser completamente inútil.
Pois bem, quando você tentar compilar este código 03, irá receber mensagens de aviso do compilador, dizendo que existem coisas erradas no código. Ok, faz parte, já que mudamos a forma de utilizar a estrutura. Estes erros podem ser vistos logo abaixo.
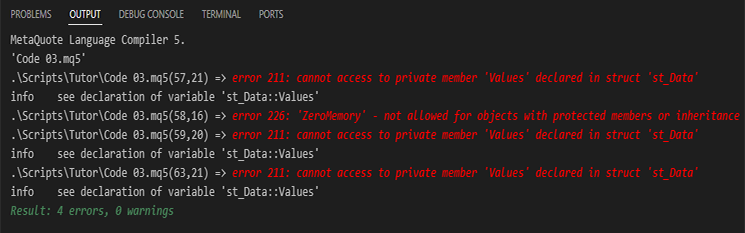
Imagem 03
Obviamente você esperaria que o erro, apenas acontecesse na linha 59 do código 03. Já que ali estamos atribuindo algo a variável. No entanto, foram gerados quatro erros. Por que? Bem, o motivo para isto ter ocorrido é simples. Os erros das linhas 57, 59 e 63, que você pode ver nesta imagem 03. São justamente por conta do fato de estarmos tentando acessar algo que não podemos mais acessar. Já que a variável, é agora privada da estrutura. Sendo assim só poderá ser acessada dentro da estrutura, onde ela está sendo declarada. Criando e mantendo assim, todo um contexto para a existência da estrutura e da própria variável.
Mas e o erro da linha 58? Que é justamente onde estamos usando a função de biblioteca ZeroMemory, para limpar completamente os dados da estrutura. Por que este erro agora existe? O motivo, é justamente pelo fato de estarmos criando um contexto para a estrutura e os dados presentes nela.
Quando fazemos isto, já não podemos mais acessar, ou modificar diretamente nada dentro, do que seria a estrutura de dados. Já que isto quebraria o tal encapsulamento, e poderia violar o próprio contexto dos dados presentes internamente na estrutura. Tais conceitos, que são o encapsulamento e o contexto, é que nos dão garantia de que, dados dentro de uma estrutura, irão se manter íntegros e seguros durante todo o tempo. Isto nos força a de fato, implementarmos toda uma gama de soluções nova para manter tais conceitos sendo aplicados. Desta forma é que uma programação completamente estruturada irá realmente começar a ser construída.
Mas espere um pouco. Se não podemos fazer as coisas como estávamos fazendo antes. Como vamos manter este código realmente funcionando? Esta coisa de encapsulamento e contexto, parece que vieram apenas para atrapalhar e complicar a nossa vida. Prefiro programar a moda antiga. Pois é bem mais fácil e simples. Bem, meu caro leitor, em parte concordo com você, assim como diversos programadores que no começo e ao primeiro contato com algo novo, acabam pensando da mesma maneira. Eu mesmo, quando comecei, pensava assim. E odiava precisar criar códigos estruturados, já que não via muito sentido em fazer isto. Já que eles muitas das vezes nos força a pensar e detalhar como as coisas de fato precisam funcionar. Mas com o tempo, você se acostuma, ainda mais conforme seus códigos forem ficando cada vez mais complexos e elaborados. Neste ponto, é que você percebe que uma programação estruturada, de fato faz toda a diferença.
Mas vamos voltar a questão do código. Como este código 03, não será capaz de gerar um executável. Precisamos corrigir ele, a fim de conseguirmos de fato fazer com que ele funcione. Para isto, iremos mudar novamente o mesmo, como mostrado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ . . . 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
Código 04
Aqui neste código 04, temos uma das possíveis propostas, para implementar a mesma coisa que era feito antes. Isto lá no código 02. Onde queríamos gerar a média de valores em H e depois gerar uma mediana dos valores de K. Mas note que não estamos interessados em olhar o conteúdo interno da estrutura. Já que sabemos que valores realmente estarão sendo utilizados para o estudo. No entanto, note a linha 15, neste código 04. Ali estamos corrigindo a falha que existia, ao tentarmos atribuir novos valores internos a estrutura. Por isto estou dizendo que esta é uma das possíveis propostas de solução. Já que, dependendo de cada caso específico, você pode desejar fazer esta limpeza de outra maneira.
Por exemplo: Supondo que você precise que o código execute exatamente o que era feito no código 02. Ou seja, limpamos os valores da estrutura, como foi feito na linha 54 do código 02. Assim como também, possamos imprimir o conteúdo presente nas variáveis, ou variável no caso. Como poderíamos resolver esta questão? Isto de forma a manter o conceito de encapsulamento e contexto? Bem, para fazer isto, uma das possíveis propostas pode ser vista logo abaixo. Sendo está a parte divertida da brincadeira, já que cada programador, pode imaginar e elaborar diferentes formas de se resolver o mesmo problema.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ZeroMemory(void) 20. { 21. Print(__FUNCTION__); 22. ArrayFree(Values); 23. } 24. //+----------------+ 25. void ArrayPrint(void) 26. { 27. Print(__FUNCTION__); 28. ArrayPrint(Values, 2); 29. } 30. //+----------------+ 31. double Average(void) 32. { 33. double sum = 0; 34. 35. for (uint c = 0; c < Values.Size(); c++) 36. sum += Values[c]; 37. 38. return sum / Values.Size(); 39. } 40. //+----------------+ 41. double Median(void) 42. { 43. double Tmp[]; 44. 45. ArrayCopy(Tmp, Values); 46. ArraySort(Tmp); 47. if (!(Tmp.Size() & 1)) 48. { 49. int i = (int)MathFloor(Tmp.Size() / 2); 50. 51. return (Tmp[i] + Tmp[i - 1]) / 2.0; 52. } 53. return Tmp[Tmp.Size() / 2]; 54. } 55. //+----------------+ 56. }; 57. //+------------------------------------------------------------------+ 58. #define PrintX(X) Print(#X, " => ", X) 59. //+------------------------------------------------------------------+ 60. void OnStart(void) 61. { 62. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 63. const double K[] = {12, 4, 7, 23, 38}; 64. 65. st_Data Info; 66. 67. Info.Set(H); 68. Info.ArrayPrint(); 69. PrintX(Info.Average()); 70. Info.ZeroMemory(); 71. 72. Info.Set(K); 73. PrintX(Info.Median()); 74. Info.ArrayPrint(); 75. } 76. //+------------------------------------------------------------------+
Código 05
Agora, quando este código 05 é executado no MetaTrader 5, o resultado é o que podemos ver na imagem logo na sequência.
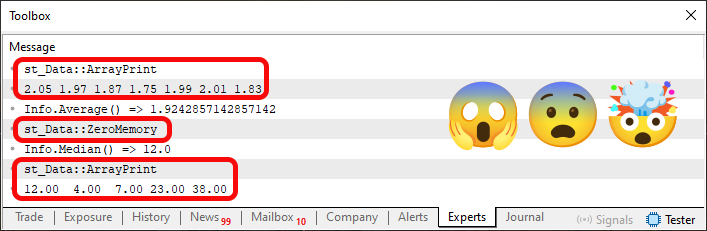
Imagem 04
Note que aqui nesta imagem 04 estou dando destaque a algumas coisas. Mas você pode estar se perguntando: Mas por que motivo você está dando destaque a estas coisas? O motivo pode ser visto no código 05. Observe as linhas 19 e 25. O que? Mas que coisa de maluco é esta que você está fazendo aqui? Isto pode ser feito?
Como eu disse a pouco, a parte divertida é justamente o fato de que cada programador, pode elaborar formas diferentes de resolver o mesmo problema. Dentro do que seria uma programação estruturada, você meu caro leitor, pode fazer uso de nomes de funções ou procedimentos de biblioteca sem problema. Da mesma maneira que estou fazendo aqui no código 05. Porém, toda via e, entretanto, você precisa tomar cuidado para não gerar uma chamada recursiva sem perceber. Como aqui, estamos criando uma sobrecarga do que seria as funções da biblioteca padrão do MQL5.
E estamos fazendo isto dentro de um contexto, presente na estrutura. Tal construção não irá nos gerar nenhum tipo de problema. Mesmo por que, você pode notar que nas linhas 68, 70 e 74, o código é muito mais simples de ser entendido do que se fosse criado um rotulo exclusivo. Já que claramente você consegue notar o que cada procedimento ou função deveria efetuar. Só que tem um pequeno detalhe aqui. Como foi dito, você precisa tomar cuidado ao implementar as coisas desta maneira. Para mostrar como isto funciona na prática, adicionei as linhas 21 e 27 ao código. Assim, você consegue acompanhar o fluxo de execução, e percebendo que não estaremos usando as chamadas da biblioteca padrão logo de início. Primeiro o compilador fará uso das rotinas declaradas na estrutura, para somente depois tomar outras providencias.
No caso das chamadas a ArrayPrint. Primeiro o compilador irá usar o que está declarado na estrutura. Isto por que, nas linhas 68 e 74, estamos dizendo a ele, que o código a ser executado se encontra na estrutura. Somente depois de resolver esta questão, é que o compilador irá resolver a outra questão, que é a chamada da linha 28. Esta sim é a chamada que irá direcionar o fluxo de execução para o código presente na biblioteca padrão do MQL5.
Perceba que mesmo se não viermos a declarar a clausula private, tornando a variável declarada na linha nove, como exclusiva da estrutura e oculta de todo o restante do código. Poderíamos sem muita dificuldade transformar o código 05 no código 02. Já que basicamente, precisaríamos apenas de um pouco de edição a fim de fazer isto. A mesma coisa, pode ser feita no sentido oposto, onde podemos tornar o código 02 no que seria o código 05. Mas neste caso a transformação não seria muito suave, justamente por conta da linha 55 presente no código 02. Mas, se mesmo assim, você não se importar com o problema que existe na execução do código 02. Pode implementar uma solução que seria 100% fiel ao que o código 02 está fazendo. Isto dentro do que seria uma programação cem porcento estrutural. Para conseguir isto, tudo que precisaríamos fazer é mostrado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ArrayCopy(const double &arg[]) 20. { 21. ArrayCopy(Values, arg); 22. } 23. //+----------------+ 24. void ZeroMemory(void) 25. { 26. ZeroMemory(Values); 27. } 28. //+----------------+ 29. void ArrayPrint(void) 30. { 31. ArrayPrint(Values, 2); 32. } 33. //+----------------+ 34. double Average(void) 35. { 36. double sum = 0; 37. 38. for (uint c = 0; c < Values.Size(); c++) 39. sum += Values[c]; 40. 41. return sum / Values.Size(); 42. } 43. //+----------------+ 44. double Median(void) 45. { 46. double Tmp[]; 47. 48. ArrayCopy(Tmp, Values); 49. ArraySort(Tmp); 50. if (!(Tmp.Size() & 1)) 51. { 52. int i = (int)MathFloor(Tmp.Size() / 2); 53. 54. return (Tmp[i] + Tmp[i - 1]) / 2.0; 55. } 56. return Tmp[Tmp.Size() / 2]; 57. } 58. //+----------------+ 59. }; 60. //+------------------------------------------------------------------+ 61. #define PrintX(X) Print(#X, " => ", X) 62. //+------------------------------------------------------------------+ 63. void OnStart(void) 64. { 65. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 66. const double K[] = {12, 4, 7, 23, 38}; 67. 68. st_Data Info; 69. 70. Info.Set(H); 71. PrintX(Info.Average()); 72. Info.ArrayPrint(); 73. 74. Info.ZeroMemory(); 75. Info.ArrayCopy(K); 76. 77. PrintX(Info.Median()); 78. Info.ArrayPrint(); 79. } 80. //+------------------------------------------------------------------+
Código 06
Este código 06, quando executado, irá gerar exatamente a mesma saída que podemos observar na imagem 02. Mas preste atenção em como este código 06 é diferente do código 02.
Primeiro, o código 02 não está de fato respeitando o encapsulamento e por conta disto o contexto acaba ficando em uma situação um tanto quanto complicada. Já que em algum momento poderemos estar correndo o risco de mudar o conteúdo interno da estrutura sem que ela de fato esteja ciente disto.
Segundo, devido ao fato de que este código 06, está sendo fazendo uso completo do que seria um código estruturado. Qualquer tipo de problema ou falha, não pode ser de modo algum atribuído a uma simples distração. Já que durante o processo de criação das rotinas presentes na estrutura, estamos cientes do que estaremos criando. Assim, se acontece uma falha, ela acontece justamente por conta de um mal uso, ou tentativa de mudar o contexto da estrutura sem ao menos entender o objetivo inicial da própria estrutura.
Este tipo de coisa gera uma grande e enorme confusão quando saímos da programação estruturada e entramos na programação orientada em objetos. Já que ali, muitas das vezes, podemos mudar completamente o significado de um objeto, que em tese seria uma estrutura, para algo que não tem absolutamente nada a ver com o objeto original. Futuramente quando formos falar sobre programação orientada em objetos, iremos voltar a esta questão do contexto novamente.
Por isto, que é muito importante, não queimar etapas, ou quer ir com muita cede ao pote. Tentar entender algo, sem antes entender outras coisas, mais simples e que originaram um tipo de implementação mais elaborada, não irá de fato lhe ajudar. No que se refere a programação. Quando melhor um conceito for de fato compreendido, mais fácil será entender como aplicar o mesmo nas mais diversas situações.
Ok, acho que estou começando a entender, para que serve esta coisa de programação estruturada. Basicamente, ela serve para nos ajudar a criar códigos que possam ser mais simples, seguros e eficientes. Mas estou curioso com relação a uma questão. Tudo que fizemos até este momento, precisou ser feito na mão. Ou seja, não estamos de fato contando muito com a ajuda do compilador, no que se refere a algumas questões. Como as que foram vistas, quando foi explicado sobre a sobrecarga e o uso de templates de funções e procedimentos. Será que neste tipo de programação, visando a criação de um código estruturado, não podemos gerar, ou pedir para o compilador, nos auxiliar na geração de sobrecarga e no uso de templates de funções e procedimentos? Isto dentro do que seria uma programação estrutural?
Está com toda a certeza é uma excelente e maravilhosa pergunta, meu caro leitor. Porém, vou deixar você se roendo de vontade de saber como fazer isto. Pelo menos até que o próximo artigo venha a ser publicado.
Considerações finais
Neste artigo, vimos como produzir o chamado código estrutural. Onde colocamos dentro de uma estrutura, todo o contexto e formas de manipular variáveis e informações, a fim de gerar um contexto adequado para implementação de um código qualquer. Vimos a necessidade de se fazer uso da clausula private, a fim de separar o que é ou não público. Fazendo assim com que a regra do encapsulamento seja respeitada e que o contexto pelo qual uma estrutura de dados tenha sido criada. Venha a se manter integra, segura e confiável, durante todo o tempo. Também vimos que, mesmo dentro de um código estruturado, podemos vir a cometer, ou melhor dizendo, iniciar uma avalanche de falhas, justamente devido ao fato de implementar funções ou procedimentos que fazem o contexto pensado de maneira inicial seja quebrado. Tornando assim, o que seria um código simples e de fácil entendimento, em algo complexo e difícil de ser mantido e utilizado.
Mas também foi levantada a questão de uso de templates neste tipo de implementação. Mas como isto é um assunto relativamente bem mais complicado. E você, já tem bastante coisa para entender e praticar neste artigo. Este tema sobre templates em um código estrutural, irá começar a ser abordado no próximo artigo. Mas você pode começar a atentar fazer isto, com estes códigos mostrados aqui. Isto irá lhe ajudar a colocar em pratica a hipótese de utilização de conceitos, para algo não pensado e não explorado ainda.
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso