
Do básico ao intermediário: Estruturas (V)

Introdução
No artigo anterior Do básico ao intermediário: Estruturas (IV), começamos a falar de forma mais séria e aplicada, o que seria de fato uma programação visando criar um código estruturado. Este tipo de coisa que está sendo vista, pode parecer para muitos algo tolo e sem um objetivo prático. Já que praticamente só se ouve falar, sobre programação orientada em objetos. Porém, o que muitos não sabem, ou ignoram, é que a programação orientada em objetos, não nasceu de um dia para outro. Ela é o resultado de muita pesquisa e debate por parte de uma comunidade inteira de programadores. Sendo que ela só veio a surgir de fato, quando se percebeu limitações no que seria a programação estrutural.
No entanto, diferente da programação convencional, onde declaramos variáveis, funções e procedimentos, visando resolver um determinado tipo de problema. Uma programação estrutural, procura implementar um tipo de abordagem em que podemos resolver, não apenas um, mas toda uma gama de problemas, que de alguma maneira está correlacionada entre si.
Sei que muitos de vocês, principalmente os iniciantes, devem estar pensando: Cara, eu não quero aprender a fazer isto. Quero aprender a criar um Expert Advisor ou um indicador. Esta coisa de aprender como implementar soluções que eu nem irei utilizar, não é minha praia. Ok, você tem o direito de pensar assim, meu caro leitor. Porém, sem entender como implementar coisas, aparentemente sem conexão alguma com o que poderia ser um indicador ou mesmo um trecho de código de um Expert Advisor. Você irá mais hora ou menos hora, acabando em um beco sem saída. Justamente por não entender como implementar soluções que não são obvias e simples de serem pensada.
É preciso entender como a mente de um programador age, para conseguir entender como solucionar qualquer tipo de problema que você possa vir a enfrentar. E um destes problemas é justamente o fato de que, até o momento não foi explicado como expandir a programação estrutural, a fim de resolver questões mais abrangentes. Ou seja, se viermos a implementar um código, para solucionar um problema de tipos inteiros, como podemos, sem precisar codificar tudo de novo, implantar a solução para dados do tipo ponto flutuante? Esta é uma questão muito interessante, e que ao mesmo tempo, pode ser muito confusa. Já que existem diversas formas de se fazer este mesmo tipo de coisa.
Irei tentar explicar, pelo menos duas formas diferentes de se fazer este tipo de coisa. Apesar de que, a segunda forma, envolve manipulação da memória e não sei se você está preparado para ver isto. De qualquer forma, iremos começar pela maneira mais simples primeiro. Isto para que você, meu caro leitor, possa vir a ter uma noção básica de como pensar no problema. Então chegou a hora de dar um tempo, nas distrações. Aconchegar em um ambiente tranquilo e sereno e prestar atenção ao que será explicado neste artigo. Pois agora a coisa irá de fato ficar bem interessante e divertida.
Usando templates em estruturadas
Aqui iremos ver a primeira das maneiras de se fazer uso de templates em estruturas de dados. Sendo está a maneira mais simples e fácil de entender como sobrecarregar estruturas. Lembrando mais uma vez que, o que será visto aqui, tem apenas como objetivo a didática. De modo algum deve ser encarado como um código final e que possa ser utilizado sem os devidos cuidados.
Para começar, vamos pegar emprestado o código visto no artigo anterior. Isto por que ele já tem algo que ao meu ver é bastante prático e fácil de entender o que será feito aqui. A versão que iremos utilizar é vista logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. double Average(void) 20. { 21. double sum = 0; 22. 23. for (uint c = 0; c < Values.Size(); c++) 24. sum += Values[c]; 25. 26. return sum / Values.Size(); 27. } 28. //+----------------+ 29. double Median(void) 30. { 31. double Tmp[]; 32. 33. ArrayCopy(Tmp, Values); 34. ArraySort(Tmp); 35. if (!(Tmp.Size() & 1)) 36. { 37. int i = (int)MathFloor(Tmp.Size() / 2); 38. 39. return (Tmp[i] + Tmp[i - 1]) / 2.0; 40. } 41. return Tmp[Tmp.Size() / 2]; 42. } 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
Código 01
Quando este código 01 vier a ser executado no terminal do MetaTrader 5, iremos ter como resultado o que é mostrado na imagem logo na sequência.

Imagem 01
Até neste ponto, nada de tão grandioso e espetacular. Mas pense um pouco na seguinte situação. Este código 01, está sendo implementado de forma a conseguir nos dizer duas informações. Uma que seria a média e a outra a mediana de um array de valores. Porém, toda via e, entretanto, ele somente pode fazer isto para valores do tipo ponto flutuante. E mais precisamente, valores do tipo double. Não sendo capaz de conseguir entender valores do tipo float, mesmo que este também seja um tipo de dado ponto flutuante. E o que dirá a respeito de valores do tipo inteiro.
Neste caso este código 01, apesar de sua aparente utilidade e praticidade, é bastante inútil para uma ampla e enorme gama de coisas. Já que, para conseguir lidar com estes demais tipos de dados numéricos, que não sejam do tipo ponto flutuante, precisaremos implementar a estrutura de novo e de novo, até cobrir cada um dos tipos de dados numéricos.
Este tipo de coisa é conhecida como sobrecarga. Porém, a sobrecarga de estruturas, não funciona da mesma forma que seria a sobrecarga de funções e procedimentos. Neste caso, ao fazemos a sobrecarga, precisaríamos mudar o nome da estrutura. Justamente aquela informação que está sendo feita na linha quatro do código 01.
E fazer isto, acabaria criando uma série de novas estruturas, com um mesmo objetivo, contexto e dados encapsulados. Mas com um nome completamente diferente um do outro. Ou seja, um caos completo e uma baita de uma trabalheira.
Programadores, e digo isto por também ser um, não gostam muito de trabalheira. Se precisamos repetir um código, mais de uma vez, já começamos a nos sentir entediados e desmotivados. Gostamos sim, de pensar em como solucionar um problema. Esta coisa se ficar repetindo código, apenas para mudar um simples detalhe neles. Não é conosco. Definitivamente odeio fazer isto. E assim como eu, outros programadores também pensaram em uma forma de se resolver este tipo de problema. Criando assim, algum mecanismo que nos permitisse criar uma sobrecarga, de algo que não pode ser sobrecarregado. Daí nasceu a ideia de se utilizar templates de uma estrutura.
Templates foram explicados de maneira básica em uma pequena sequência de cinco artigos, sendo o primeiro Do básico ao intermediário: Template e Typename (I). Assim sendo, todo aquele conhecimento e conceitos explicados ali, precisam de fato terem sido muito bem compreendidos para que você consiga entender o que será feito agora. Isto por que, sem entender aquilo que foi explicado antes. O que iremos fazer neste momento, não fará sentido algum.
No entanto, o que será visto, é a forma mais simples e fácil de se trabalhar com sobrecarga de estruturas. Apesar de existirem outras formas, bem mais complexas e com objetivos muito específicos. Vou pensar se vale ou não criar um artigo para mostrar outras formas de se fazer isto. De qualquer maneira, a forma mais simples será usando um template.
Sendo assim, vamos dar um passo para trás. Isto por que, antes de vermos como um template é aplicado a uma implementação estruturada. Precisamos ver ele sendo aplicado a uma estrutura mais genérica. Ou seja, precisamos ver como usar um template de estrutura em um código convencional. Para isto, iremos modificar o código 01, de forma que ele deixe de ser um código estrutural e passe a ser um código convencional. Isto é feito, de forma que no final teremos o código mostrado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. double Values[]; 07. }; 08. //+------------------------------------------------------------------+ 09. double Average(const st_Data &arg) 10. { 11. double sum = 0; 12. 13. for (uint c = 0; c < arg.Values.Size(); c++) 14. sum += arg.Values[c]; 15. 16. return sum / arg.Values.Size(); 17. } 18. //+------------------------------------------------------------------+ 19. double Median(const st_Data &arg) 20. { 21. double Tmp[]; 22. 23. ArrayCopy(Tmp, arg.Values); 24. ArraySort(Tmp); 25. if (!(Tmp.Size() & 1)) 26. { 27. int i = (int)MathFloor(Tmp.Size() / 2); 28. 29. return (Tmp[i] + Tmp[i - 1]) / 2.0; 30. } 31. return Tmp[Tmp.Size() / 2]; 32. } 33. //+------------------------------------------------------------------+ 34. #define PrintX(X) Print(#X, " => ", X) 35. //+------------------------------------------------------------------+ 36. void OnStart(void) 37. { 38. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 39. const double K[] = {12, 4, 7, 23, 38}; 40. 41. st_Data Info_1, 42. Info_2; 43. 44. ArrayCopy(Info_1.Values, H); 45. PrintX(Average(Info_1)); 46. 47. ArrayCopy(Info_2.Values, K); 48. PrintX(Median(Info_2)); 49. } 50. //+------------------------------------------------------------------+
Código 02
Ok, este código 02, agora está em seu formato convencional. Ao executarmos ele no MetaTrader 5, obteremos o resultado que é visto logo abaixo.

Imagem 02
Bem, com tudo que já foi explicado até este momento, tenho certeza que, você meu caro leitor, consegue entender de maneira muito fácil o que este código 02 está fazendo e como ele trabalha. Mas da mesma forma, que podemos lidar com o tipo ponto flutuante, podemos implementar templates de função e procedimento aqui. Assim este código 02 irá mudar para o código visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. double Values[]; 08. }; 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. double Average(const st_Data <T> &arg) 12. { 13. T sum = 0; 14. 15. for (uint c = 0; c < arg.Values.Size(); c++) 16. sum += arg.Values[c]; 17. 18. return sum / arg.Values.Size(); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. double Median(const st_Data <T> &arg) 23. { 24. T Tmp[]; 25. 26. ArrayCopy(Tmp, arg.Values); 27. ArraySort(Tmp); 28. if (!(Tmp.Size() & 1)) 29. { 30. int i = (int)MathFloor(Tmp.Size() / 2); 31. 32. return (Tmp[i] + Tmp[i - 1]) / 2.0; 33. } 34. return Tmp[Tmp.Size() / 2]; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uchar K[] = {12, 4, 7, 23, 38}; 43. 44. st_Data <double> Info_1; 45. st_Data <uchar> Info_2; 46. 47. ArrayCopy(Info_1.Values, H); 48. PrintX(Average(Info_1)); 49. 50. ArrayCopy(Info_2.Values, K); 51. PrintX(Median(Info_2)); 52. } 53. //+------------------------------------------------------------------+
Código 03
Santa complicação cósmica. Cara que código mais maluco e insano é este? Será que precisamos passar por isto? Calma meu caro leitor, este código não é assim tão insano e maluco. Não como o código que utiliza a manipulação de memória pode ser. Por isto vou pensar, se mostro ou não como implementar a sobrecarga de estruturas via manipulação da memória. De qualquer forma, grande parte deste código 03, já lhe deve ser bastante familiar e fácil de entender. Talvez a única parte que possa estar gerando algum tipo de surpresa, são as linhas 44 e 45.
No entanto, no artigo Do básico ao intermediário: Template e Typename (IV), este tipo de coisa foi explicada. Mas não no que se refere à utilização de estruturas, mas sim na utilização de uniões. De qualquer maneira o conceito e princípio adotado é o mesmo. E como foi explicado lá, não vejo necessidade de explicar novamente aquele mesmo conceito. Ainda mais por ter sido necessário fazer isto em dois artigos.
Por isto, se você, meu caro e estimado leitor, não está conseguindo entender o que está acontecendo neste código 03. Sugiro que volte nos artigos anteriores e procure estudar os mesmos. Como venho falando, o conhecimento vai se acumulando com o tempo. Tentar queimar etapas, acreditando que irá conseguir entender algo mais elaborado, sem ao menos entender conceitos básicos, não vai dar muito certo.
Muito bem, mas aqui temos um pequeno detalhe, que a princípio não parece ser algo incomodo. Que é justamente o tipo de dado que será retornado pela mediana. O problema aqui, se deve ao fato de que, se o array contiver um número par de elementos, teremos o teste da linha 28 mudando o fluxo para que a linha 32 seja executada. Mas se o número de elementos for ímpar, a linha 34 será executada, tornando o retorno um tanto quanto diferente do esperado em muitos dos casos.
Isto por que, um array com elementos inteiros, não deveria, pelo menos a princípio retornar um valor do tipo ponto flutuante. Como o que está acontecendo aqui. Por isto, o resultado mostrado no terminal, não consiste exatamente dos valores vistos no array declarado na linha 42. Já que no array temos elementos do tipo inteiro. E o valor de retorno é do tipo ponto flutuante. Mas como o código aqui é didático, prefiro manter esta pequena inconsistência, a lançar mão de um retorno completamente incorreto.
Ok, então olhando para este código 03 e pensando em como transformar ele em algo parecido com o código 01, onde temos uma implementação estrutural. Fica fácil encontrar a maneira correta de se fazer isto. Pois basta, modificar o código 01, de modo que a declaração de template, vista no código 03, venha a ser feita.
Mas, você talvez possa estar preocupado com o fato de que no código 03, tivemos a necessidade de implementar as funções como template. Então, será que precisamos fazer isto também no que ser refere ao código 01? Isto para que a implementação estrutural, venha a conseguir trabalhar de maneira correta, e o compilador saiba como sobrecarregar a estrutura? Bem, neste caso isto não será necessário, meu caro leitor. Visto que o próprio contexto é bastante simples e sem muitas coisas a serem adicionadas.
No entanto, diferente deste código 03, onde passamos os valores da estrutura via passagem por referência. No código 01, não temos como fazer isto. E o motivo foi visto no artigo anterior. Onde expliquei a questão do contexto, junto com a questão do encapsulamento dos dados. Sendo que a única forma de entrar com novos valores, é via procedimento Set, presente no código 01. Então este será um dos poucos pontos em que precisamos de fato implementar algo um pouco diferente do que existe originalmente no código 01. Desta forma o novo código 01, agora já pensando na sobrecarga de estrutura, é visto sendo implementado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. double Average(void) 21. { 22. double sum = 0; 23. 24. for (uint c = 0; c < Values.Size(); c++) 25. sum += Values[c]; 26. 27. return sum / Values.Size(); 28. } 29. //+----------------+ 30. double Median(void) 31. { 32. T Tmp[]; 33. 34. ArrayCopy(Tmp, Values); 35. ArraySort(Tmp); 36. if (!(Tmp.Size() & 1)) 37. { 38. int i = (int)MathFloor(Tmp.Size() / 2); 39. 40. return (Tmp[i] + Tmp[i - 1]) / 2.0; 41. } 42. return (double) Tmp[Tmp.Size() / 2]; 43. } 44. //+----------------+ 45. }; 46. //+------------------------------------------------------------------+ 47. #define PrintX(X) Print(#X, " => ", X) 48. //+------------------------------------------------------------------+ 49. void OnStart(void) 50. { 51. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 52. const char K[] = {12, 4, 7, 23, 38}; 53. 54. st_Data <double> Info_1; 55. st_Data <char> Info_2; 56. 57. Info_1.Set(H); 58. PrintX(Info_1.Average()); 59. PrintX(Info_1.Median()); 60. 61. Info_2.Set(K); 62. PrintX(Info_2.Average()); 63. PrintX(Info_2.Median()); 64. } 65. //+------------------------------------------------------------------+
Código 04
Observe que é bem simples tornar o código 01 em um código capaz de criar uma sobrecarga de estrutura. Isto a fim de obter no final, um código completamente estrutural. Como as funções e procedimentos estão todos sendo declarados dentro do contexto da estrutura. Elas de certa maneira herdam por assim dizer, a própria declaração da estrutura. Isto no momento em que o compilador vier a fazer a implementação do que seria a sobrecarga da própria estrutura.
Como foi dito, temos o problema dos retornos, devido justamente ao fato de que estaremos tornando, em alguns momentos, valores do tipo inteiro como sendo valores do tipo ponto flutuante. E para ser mais preciso do tipo ponto flutuante double. O que pode ser um problema em alguns casos. Você pode ver isto sendo feito, nas linhas 20 e 30 deste código 04. Mas espere um pouco aí. Não entendi por que isto seria um problema? E sendo assim, haveria alguma maneira de suplantarmos o mesmo? Isto a fim de que não venhamos a correr riscos desnecessários?
Bem, meu caro leitor, para entender isto, precisamos primeiramente ver o que seria o resultado da execução do código 04. Isto pode ser visto logo abaixo.
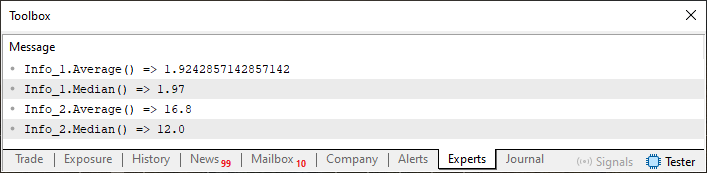
Imagem 03
Agora preste atenção a um detalhe presente nesta imagem 03. Note que o retorno de Info_2.Median é um valor do tipo ponto flutuante. Mas, Info_2 quando declarado no código é do tipo inteiro, como você pode observar na linha 55. O problema aqui, é que a estrutura, não está conseguindo lidar adequadamente com este tipo de situação. Onde, no momento em que pedimos para que ela retorne um valor mediano, e este se encontra presente na própria estrutura de dados. O sistema acaba retornando um tipo diferente. O correto seria retornar um valor do tipo inteiro. Porém estamos retornando um valor do tipo ponto flutuante.
Este tipo de questão, que aparentemente é simples de ser resolvido. Na prática e em códigos reais, se torna algo muito mais complicado e difícil de se resolver. No entanto, basicamente o que muitos programadores, e isto estou dizendo de uma maneira genérica, é adotar uma metodologia, onde adicionamos mais e mais funções e procedimentos a fim de resolver algum tipo de pendencia interna, da própria estrutura. Isto na maior parte das vezes resolve o problema. Porém, costuma gerar soluções, ou implementações, que a princípio não fazem muito sentido, pelo ponto de vista de outros programadores. E o motivo é simples: A melhor forma de resolver um problema, é não resolvendo o problema. Mas, fornecendo os mecanismos necessários para que o problema possa ser pensado em termos de partes menores.
Mas como assim? Agora fiquei confuso. Para entender isto, precisamos vamos usar este código 04 como mecanismo de aprendizagem. Primeiro ponto: Por que precisamos retornar um valor médio diretamente via função? Bem, você pode responder isto, dizendo que ao fazermos isto, tornaríamos o código mais simples, no momento de utilizar a própria estrutura. De fato, seria um bom argumento.
Porém, vamos voltar ao caso de estarmos utilizando números inteiros, como acontece na declaração da linha 55. O valor médio dos elementos que estamos colocando ali, e isto na linha 61, é de fato um valor do tipo ponto flutuante. No caso 16.8. Porém, pense em alguma situação, onde precisamos de um valor médio que precise ser inteiro. No caso, seria necessário fazer um arredondamento. Existem regras de arredondamento para este tipo de cenário. Mas este não é o caso aqui.
O objetivo é entender como poderíamos dar ao programador, que venha a utilizar a estrutura, os mecanismos necessários para que ele saiba como, quando e por que efetuar o arredondamento do valor. Isto a fim de no final conseguir um valor do tipo inteiro.
Bem, para fazer isto, precisamos mudar o contexto do que seria e deveria estar sendo implementado na estrutura. Muitas vezes, não removemos partes, mas sim adicionamos novas partes ao código. Criando desta maneira blocos menores e com um proposito bem mais específico. Ok, para tornar isto mais claro e palatável, vamos ver um exemplo disto sendo aplicado na prática. Você pode observar que na linha 20 do código 04, temos uma função cujo objetivo seria gerar uma média dos valores da própria estrutura. Até aí nada de tão extraordinário.
Mas, observe que para gerar esta média, precisamos efetuar duas coisas. A primeira é saber qual o valor da soma dos elementos, e a segunda é saber quantos elementos existem. Neste momento, você pode estar pensando. Certo. Mas e daí? Daí que se você, ao invés de fazer isto diretamente na função Average, criar duas outras funções, pode vir a permitir que o usuário da estrutura, possa escolher como, onde e por que arredondar os valores da média dos elementos da estrutura.
Não sei se você conseguiu captar a ideia, meu caro leitor. Mas vamos ver como isto seria feito na prática. Para isto, vamos utilizar o código visto logo na sequência.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Sum(void) 21. { 22. T sum = 0; 23. 24. for (uint c = 0; c < NumberOfElements(); c++) 25. sum += Values[c]; 26. 27. return sum; 28. } 29. //+----------------+ 30. uint NumberOfElements(void) 31. { 32. return Values.Size(); 33. } 34. //+----------------+ 35. double Average(void) 36. { 37. return ((double)Sum() / NumberOfElements()); 38. } 39. //+----------------+ 40. double Median(void) 41. { 42. T Tmp[]; 43. 44. ArrayCopy(Tmp, Values); 45. ArraySort(Tmp); 46. if (!(Tmp.Size() & 1)) 47. { 48. int i = (int)MathFloor(Tmp.Size() / 2); 49. 50. return (Tmp[i] + Tmp[i - 1]) / 2.0; 51. } 52. return (double) Tmp[Tmp.Size() / 2]; 53. } 54. //+----------------+ 55. }; 56. //+------------------------------------------------------------------+ 57. #define PrintX(X) Print(#X, " => ", X) 58. //+------------------------------------------------------------------+ 59. void OnStart(void) 60. { 61. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 62. const char K[] = {12, 4, 7, 23, 38}; 63. 64. st_Data <double> Info_1; 65. st_Data <char> Info_2; 66. 67. Info_1.Set(H); 68. PrintX(Info_1.Average()); 69. PrintX(Info_1.Median()); 70. 71. Info_2.Set(K); 72. PrintX(Info_2.Average()); 73. PrintX(Info_2.Sum()); 74. PrintX(Info_2.NumberOfElements()); 75. PrintX(Info_2.Sum() / Info_2.NumberOfElements()); 76. PrintX(Info_2.Median()); 77. } 78. //+------------------------------------------------------------------+
Código 05
Muito bem, neste código 05 estamos modelando o que seria algo que você, e tantos outros podem achar que só acontece quando estamos trabalhando com programação orientada em objetos. Mas que de fato, nasceu com o advento da programação estrutural. Que é a divisão do código em pequenos blocos. Note que agora, temos na linha 20 deste código 05 uma função, cujo propósito é nos dizer o valor da soma de todos os elementos presentes na estrutura. O tipo deste valor que estaremos retornando, depende do tipo de dado que se encontra na própria estrutura. Preste atenção a isto, pois esta informação é importante. Ok, temos também uma outra função, que no caso se encontra na linha 30, cujo objetivo é retornar o número de elementos presentes na própria estrutura.
Agora vem a parte de fato interessante. Como a média é calculada pela divisão destes dois valores, que estamos calculando nestas funções mencionadas acima, temos na linha 37 um cálculo focado no contexto da estrutura. Mas, é este é o ponto principal. Note que estamos dizendo ao compilador para converter o resultado da função Sum em um tipo double. Por que estamos fazendo isto? O motivo pode ser visto observando a imagem da execução deste código 05. Esta imagem pode ser observada logo abaixo.
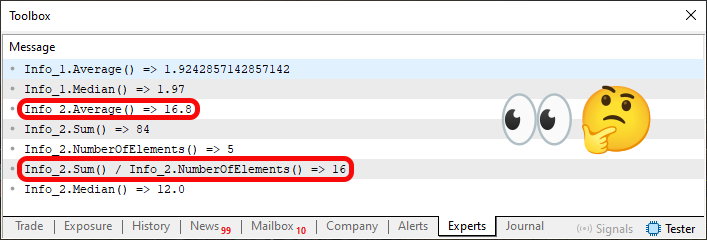
Imagem 04
Note que nesta imagem, estou destacando duas informações. Uma que representa a execução da linha 72 e a outra da linha 75. No entanto, note que ambas informações impressas são de tipos diferentes. Uma é do tipo ponto flutuante enquanto a outra é do tipo inteira. Agora vem a explicação do por que converter o resultado da função Sum para o tipo double na linha 37. Note que o mesmo calculo que estamos fazendo na linha 37, também está sendo repetido na linha 75. Porém, em um caso estamos convertendo o valor 84, que seria o resultado da soma dos elementos da linha 62, em double e no outro caso não. Por isto, apesar do contexto nos permitir calcular a média diretamente na estrutura, como está sendo feito na linha 37. Também poderemos fazer isto, fora da estrutura. E justamente por conta disto, podemos controlar como será o resultado em termos de tipo de dado a ser utilizado.
Parece um tanto quanto bobagem fazer isto. Mas note que, sem afetar em absolutamente nada a forma de fatorar as coisas. Demos ao programador, meios de controlar, ajustar e até mesmo escolher como o resultado seria representado. Coisa que de outra maneira seria muito mais difícil e trabalhosa de ser feita. Tudo isto, foi conseguido, pelo simples fato de termos removido o cálculo que antes era efetuado em uma função e o colocado em mais de uma função acessível fora do corpo da estrutura. No entanto, mesmo fazendo isto, ainda assim conseguimos manter o contexto da própria estrutura. Já que, o simples fato de observar a linha 75, conseguimos entender que tipo de informação estamos buscando na estrutura.
Se você, meu caro leitor, procurar estudar este tipo de coisa, irá encontrar isto, na maior parte das vezes, quando falamos de classes e programação orientada em objetos. No entanto, com este simples código, acabamos de mostrar que este conceito, vem muito antes da necessidade da programação orientada em objetos. Assim, quando tal modelo de programação vier a ser explicada no futuro, você já terá uma boa base formada. Tendo visto que a programação orientada em objetos, visa suprir justamente algo que não podemos fazer via programação estruturada.
Muito bem, isto foi divertido. Mas será que podemos fazer ainda mais? Isto sem ter de tornar as coisas demasiadamente confusas e difíceis de entender? Sim, meu caro leitor. Existe um conceito, se bem que não seja necessariamente um conceito, e sim uma manobra que diversos programadores criam em seus códigos. Cujo objetivo é tornar grande parte do que foi visto aqui, em algo muito mais simples. Porém sem entender isto que foi explicado aqui. Fica um tanto quanto confuso entender o que podemos fazer. Isto a fim de criar uma sobrecarga de estrutura. Lembrando que a sobrecarga da qual estou me referindo, visa criar uma estrutura com um objetivo mais genérico, porém tendo um contexto muito bem definido.
Como ainda temos um pouco de tempo, neste artigo. Posso dar uma leve introdução, no que seria constituída esta tal manobra mencionada acima. Mas para isto, precisamos parar e pensar sobre algumas coisas. Primeiro, observe que na linha 64 e 65 do código 05, temos uma declaração, cujo propósito é manter dados do tipo discreto. Ou seja, valores que podem ser do tipo inteiro ou do tipo ponto flutuante. Porém, se você parar e pensar um pouco, uniões e até mesmo estruturas também são formas de dados. Portanto, também poderiam ser, a princípio, declaradas como um tipo a ser usado na estrutura cujo código será sobrecarregado a fim de construir um modelo adequado aquele tipo de dado específico.
Acredito que você, tenha entendido isto, e praticado este tipo de coisa, durante os artigos em que falamos sobre como a sobrecarga acontece e o uso de template em códigos. Porém diferente dos tipos discretos de dados, tipos como uniões e estruturas, são mais complexos. Já que podem conter diversas coisas dentro de si. Pegue por exemplo a estrutura MqlRates. Dentro dela, temos diversas coisas sendo definidas, como preço de abertura, preço de fechamento, spread, volume entre outras informações. Então apesar de, a princípio, podermos declarar um template de estrutura, podendo receber qualquer tipo de informação. Seja valores complexo ou discretos. Existem agravantes que nos impede, se bem que esta não seja a palavra mais adequada, em definir tipos complexos em um local onde tipos discretos seriam esperados. No entanto, isto não nos proíbe de criar certos tipos de aparatos, necessários para resolver de maneira menos onerosa e custosa certos problemas específicos.
Então meu caro leitor, quero que você procure pensar, em como poderíamos vir a utilizar, dados como uniões ou estruturas dentro de um código como o visto em código 05. Isto a fim de podermos generalizar em diversos aspectos a sobrecarga de uma estrutura a fim de construir um código completamente estrutural. Sei que isto, não é uma das tarefas mais simples de ser compreendida e efetuada. No entanto, quero que você pense a este respeito. Pois no próximo artigo iremos tratar justamente de algo relacionado a isto.
Considerações finais
Neste artigo, tentei da maneira mais simples, didática e prática, mostrar como poderíamos e como é feita a sobrecarga de um código estrutural. Sei que isto, é um tanto quanto difícil de entender no começo. Principalmente se você está vendo isto pela primeira vez. Porém, é muito importante que você procure assimilar estes conceitos e entender muito bem o que se passa aqui, antes de procurar se aventurar em coisas ainda mais complicadas e elaboradas.
No anexo, você terá os códigos vistos aqui, para que possa estudar e praticar com calma. E no próximo artigo, iremos subir ainda mais a régua, jogando este tipo de implementação, para conseguir cobrir casos em que podemos utilizar qualquer tipo de dado na própria sobrecarga de estrutura. Algo que muitos imaginam ser possível fazer apenas via programação orientada em objetos. Mas você verá que não precisamos ainda, da programação orientada em objetos para conseguir implementar certos tipos de solução. Então bons estudos e nos vemos em breve.
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso