
Del básico al intermedio: Estructuras (V)

Introducción
En el artículo anterior, "Del básico al intermedio: Estructuras (IV)", empezamos a hablar más en serio y de forma más aplicada de la programación orientada a crear un código estructurado. Este tipo de cosas puede parecer tonta y sin un objetivo práctico para muchos, ya que prácticamente solo se habla de programación orientada a objetos. Lo que muchos no saben es que la programación orientada a objetos no surgió de la noche a la mañana. Es el resultado de mucha investigación y debate por parte de toda una comunidad de programadores y solo surgió cuando se percibieron las limitaciones de la programación estructural.
Sin embargo, a diferencia de la programación convencional, en la que declaramos variables, funciones y procedimientos para resolver un problema concreto, la programación estructural busca implementar un enfoque con el que podemos resolver no solo un problema, sino toda una gama de problemas relacionados entre sí.
Sé que muchos de ustedes, sobre todo los principiantes, deben estar pensando: «Compadre, yo no quiero aprender a hacer esto. Lo que quiero es aprender a crear un asesor experto o un indicador. Aprender a implementar soluciones que ni siquiera voy a utilizar no es lo mío». De acuerdo, tienes derecho a pensar así, querido lector. Pero, si no entiendes cómo implementar soluciones que no tienen nada que ver con lo que podría ser un indicador o incluso un fragmento de código de un asesor experto, acabarás en un callejón sin salida antes de lo que crees. Precisamente por no entender cómo implementar soluciones que no son obvias ni sencillas de idear.
Para poder solucionar cualquier problema que te pueda surgir, es necesario entender cómo piensa un programador. Y uno de estos problemas es precisamente el hecho de que, hasta el momento, no se ha explicado cómo ampliar la programación estructural para resolver cuestiones más amplias. Es decir, si implementamos un código para solucionar un problema con tipos enteros, ¿cómo podemos implantar la solución para datos de punto flotante sin tener que codificar todo de nuevo? Esta es una cuestión muy interesante que, al mismo tiempo, puede resultar muy confusa, ya que existen diversas formas de hacer lo mismo.
Voy a intentar explicar al menos dos formas diferentes de hacer este tipo de cosas. La segunda forma implica manipular la memoria y no sé si estás preparado para ver eso. De cualquier forma, vamos a comenzar por la manera más simple. Así podrás hacerte una idea básica de cómo abordar el problema. Así que es hora de dejar las distracciones, buscar un ambiente tranquilo y sereno y prestar atención a lo que se explica en este artículo. Ahora la cosa se va a poner interesante y divertida.
Cómo usar plantillas en estructuras
Aquí veremos la primera forma de usar plantillas en estructuras de datos, que es la manera más sencilla de entender cómo se sobrecargan las estructuras. Recordemos que lo que se mostrará aquí tiene como único objetivo la didáctica. En ningún caso debe considerarse un código final que pueda utilizarse sin las debidas precauciones.
Para comenzar, vamos a tomar prestado el código que se muestra en el artículo anterior, ya que tiene algo que, en mi opinión, es bastante práctico y fácil de entender en relación con lo que se hará aquí. La versión que utilizaremos se muestra justo debajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. double Average(void) 20. { 21. double sum = 0; 22. 23. for (uint c = 0; c < Values.Size(); c++) 24. sum += Values[c]; 25. 26. return sum / Values.Size(); 27. } 28. //+----------------+ 29. double Median(void) 30. { 31. double Tmp[]; 32. 33. ArrayCopy(Tmp, Values); 34. ArraySort(Tmp); 35. if (!(Tmp.Size() & 1)) 36. { 37. int i = (int)MathFloor(Tmp.Size() / 2); 38. 39. return (Tmp[i] + Tmp[i - 1]) / 2.0; 40. } 41. return Tmp[Tmp.Size() / 2]; 42. } 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
Código 01
Al ejecutar este código 01 en la plataforma MetaTrader 5, obtendremos el resultado que se muestra en la siguiente imagen.

Imagen 01
Hasta aquí, nada fuera de lo común. Pero piensa en la siguiente situación: este código 01 se está implementando para que nos diga dos cosas: el promedio y la mediana de un array de valores. Sin embargo, solo puede hacer esto con valores de punto flotante, concretamente con valores double, ya que no entiende valores float, aunque este también sea un tipo de dato de punto flotante. Y ni hablemos de valores enteros.
En este caso, a pesar de su aparente utilidad y practicidad, el código 01 es bastante inútil para una gran cantidad de cosas, ya que para poder lidiar con otros tipos de datos numéricos que no sean de punto flotante, tendremos que implementar la estructura una y otra vez hasta cubrir todos los tipos de datos numéricos.
A este tipo de cosa se le conoce como sobrecarga. Sin embargo, la sobrecarga de estructuras no funciona de la misma forma que la de funciones y procedimientos. En este caso, al realizar la sobrecarga, tendríamos que cambiar el nombre de la estructura, es decir, la información que se está procesando en la línea cuatro del código 01.
Y hacer esto terminaría creando una serie de nuevas estructuras, con un mismo objetivo, contexto y datos encapsulados, pero con un nombre completamente diferente una de otra. Es decir, un caos completo y un trabajazo tremendo.
Los programadores, y hablo por experiencia propia, no somos muy aficionados al trabajo innecesario. Si tenemos que repetir un código más de una vez, empezamos a aburrirnos y a desmotivarnos. Lo que nos gusta es pensar en cómo solucionar un problema. Pero repetir código solo para cambiar un detalle no va con nosotros. Definitivamente, odio hacer esto. Y, al igual que yo, otros programadores también pensaron en una forma de resolver este tipo de problema y crearon un mecanismo que nos permitiera crear una sobrecarga de algo que no puede ser sobrecargado. Así nació la idea de usar plantillas de estructura.
Las plantillas se explicaron de manera básica en una pequeña secuencia de cinco artículos, siendo el primero "Del básico al intermedio: Plantilla y Typename (I)" Así, es fundamental que hayas comprendido muy bien todo el conocimiento y los conceptos explicados allí para que puedas entender lo que se hará ahora. Esto se debe a que, sin entender lo que se ha explicado antes. Lo que vamos a hacer ahora no tendrá ningún sentido.
Sin embargo, lo que se mostrará es la forma más simple y fácil de trabajar con sobrecarga de estructuras, aunque existan otras formas, mucho más complejas y con objetivos muy específicos. Voy a pensar si vale o no la pena crear un artículo para mostrar otras formas de hacer esto. De cualquier manera, la forma más simple será usando una plantilla.
Por tanto, daremos un paso atrás, ya que antes de ver cómo se aplica una plantilla de estructura a una implementación estructurada, debemos ver cómo se aplica a una estructura más genérica. En otras palabras, necesitamos ver cómo se utiliza una plantilla de estructura en un código convencional. Para ello, modificaremos el código 01 para que deje de ser estructural y pase a ser convencional. El resultado final será el código que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. double Values[]; 07. }; 08. //+------------------------------------------------------------------+ 09. double Average(const st_Data &arg) 10. { 11. double sum = 0; 12. 13. for (uint c = 0; c < arg.Values.Size(); c++) 14. sum += arg.Values[c]; 15. 16. return sum / arg.Values.Size(); 17. } 18. //+------------------------------------------------------------------+ 19. double Median(const st_Data &arg) 20. { 21. double Tmp[]; 22. 23. ArrayCopy(Tmp, arg.Values); 24. ArraySort(Tmp); 25. if (!(Tmp.Size() & 1)) 26. { 27. int i = (int)MathFloor(Tmp.Size() / 2); 28. 29. return (Tmp[i] + Tmp[i - 1]) / 2.0; 30. } 31. return Tmp[Tmp.Size() / 2]; 32. } 33. //+------------------------------------------------------------------+ 34. #define PrintX(X) Print(#X, " => ", X) 35. //+------------------------------------------------------------------+ 36. void OnStart(void) 37. { 38. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 39. const double K[] = {12, 4, 7, 23, 38}; 40. 41. st_Data Info_1, 42. Info_2; 43. 44. ArrayCopy(Info_1.Values, H); 45. PrintX(Average(Info_1)); 46. 47. ArrayCopy(Info_2.Values, K); 48. PrintX(Median(Info_2)); 49. } 50. //+------------------------------------------------------------------+
Código 02
De acuerdo, este código 02 ahora está en su formato convencional. Al ejecutarlo en MetaTrader 5, obtendremos el resultado que se muestra a continuación.

Imagen 02
Bien, con todo lo que se ha explicado hasta ahora, estoy seguro de que puedes entender fácilmente qué hace este código 02 y cómo funciona. Del mismo modo que podemos lidiar con el tipo de punto flotante, podemos implementar aquí plantillas de función y procedimiento. Así, este código 02 se convertirá en el código que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. double Values[]; 08. }; 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. double Average(const st_Data <T> &arg) 12. { 13. T sum = 0; 14. 15. for (uint c = 0; c < arg.Values.Size(); c++) 16. sum += arg.Values[c]; 17. 18. return sum / arg.Values.Size(); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. double Median(const st_Data <T> &arg) 23. { 24. T Tmp[]; 25. 26. ArrayCopy(Tmp, arg.Values); 27. ArraySort(Tmp); 28. if (!(Tmp.Size() & 1)) 29. { 30. int i = (int)MathFloor(Tmp.Size() / 2); 31. 32. return (Tmp[i] + Tmp[i - 1]) / 2.0; 33. } 34. return Tmp[Tmp.Size() / 2]; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uchar K[] = {12, 4, 7, 23, 38}; 43. 44. st_Data <double> Info_1; 45. st_Data <uchar> Info_2; 46. 47. ArrayCopy(Info_1.Values, H); 48. PrintX(Average(Info_1)); 49. 50. ArrayCopy(Info_2.Values, K); 51. PrintX(Median(Info_2)); 52. } 53. //+------------------------------------------------------------------+
Código 03
Qué complicación cósmica. Compadre, ¿qué código más loco e insano es este? ¿Será necesario pasar por esto? Calma, mi querido lector, este código no es tan descabellado y loco como el que utiliza la manipulación de memoria. Por eso, voy a pensar si muestro o no cómo implementar la sobrecarga de estructuras mediante manipulación de memoria. De cualquier forma, gran parte de este código 03 ya te resultará bastante familiar y fácil de entender. Tal vez las líneas 44 y 45 sean las únicas que puedan generar algún tipo de sorpresa.
Sin embargo, este tipo de cosa se explicó en el artículo "Del básico al intermedio: Plantilla y Typename (IV)", aunque no en lo que se refiere al uso de estructuras, sino al de uniones. En cualquier caso, el concepto y principio adoptado es el mismo. Y, como se explicó allí, no veo la necesidad de volver a explicar ese mismo concepto, sobre todo teniendo en cuenta que ya fue necesario hacerlo en dos artículos.
Por eso, si no consigues entender lo que ocurre en este código 03, te sugiero que vuelvas a los artículos anteriores y los estudies. Como he venido diciendo, el conocimiento se va acumulando con el tiempo. Intentar saltarse etapas, creyendo que se va a lograr entender algo más elaborado sin antes comprender los conceptos básicos, no suele salir bien.
Muy bien, pero aquí tenemos un pequeño detalle que, a primera vista, no parece molesto: el tipo de dato que será retornado por la mediana. El problema aquí se debe al hecho de que, si el array contiene un número par de elementos, la prueba de la línea 28 cambiará el flujo para que se ejecute la línea 32. Sin embargo, si el número de elementos es impar, se ejecutará la línea 34, lo que hará que el resultado difiera del esperado en muchos casos.
Esto ocurre porque un array con elementos enteros no debería, al menos en principio, devolver un valor de tipo punto flotante, como ocurre aquí. Por esta razón, el resultado mostrado en el terminal no coincide exactamente con los valores del array declarado en la línea 42, ya que este tiene elementos enteros y el valor de retorno es de tipo punto flotante. Sin embargo, como el código es meramente didáctico, prefiero mantener esta pequeña inconsistencia en lugar de mostrar un resultado completamente incorrecto.
Así pues, al observar este código 03 y considerar cómo transformarlo en algo similar al código 01, que cuenta con una implementación estructural, resulta sencillo descubrir la forma adecuada de proceder, ya que basta con modificar el código 01 para que la declaración de plantilla, vista en el código 03, se lleve a cabo.
Pero tal vez estés preocupado por el hecho de que, en el código 03, tuvimos que implementar las funciones como plantilla. Entonces, ¿es necesario hacer lo mismo con el código 01 para que la implementación estructural funcione correctamente y el compilador sepa cómo sobrecargar la estructura? Bueno, en este caso, no será necesario, mi querido lector, ya que el propio contexto es bastante simple y no hay muchas cosas que agregar.
Sin embargo, a diferencia de lo que ocurre con el código 03, en el que pasamos los valores de la estructura mediante paso por referencia, en el código 01 no es posible hacerlo. El motivo se explicó en el artículo anterior, donde se abordó la cuestión del contexto junto con el tema del encapsulamiento de los datos. La única forma de ingresar nuevos valores es mediante el procedimiento Set, presente en el código 01. Por tanto, este será uno de los pocos puntos en los que necesitaremos implementar algo diferente a lo que existe originalmente en el código 01. De esta forma, el nuevo código 01, ya pensando en la sobrecarga de estructura, se muestra implementado justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. double Average(void) 21. { 22. double sum = 0; 23. 24. for (uint c = 0; c < Values.Size(); c++) 25. sum += Values[c]; 26. 27. return sum / Values.Size(); 28. } 29. //+----------------+ 30. double Median(void) 31. { 32. T Tmp[]; 33. 34. ArrayCopy(Tmp, Values); 35. ArraySort(Tmp); 36. if (!(Tmp.Size() & 1)) 37. { 38. int i = (int)MathFloor(Tmp.Size() / 2); 39. 40. return (Tmp[i] + Tmp[i - 1]) / 2.0; 41. } 42. return (double) Tmp[Tmp.Size() / 2]; 43. } 44. //+----------------+ 45. }; 46. //+------------------------------------------------------------------+ 47. #define PrintX(X) Print(#X, " => ", X) 48. //+------------------------------------------------------------------+ 49. void OnStart(void) 50. { 51. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 52. const char K[] = {12, 4, 7, 23, 38}; 53. 54. st_Data <double> Info_1; 55. st_Data <char> Info_2; 56. 57. Info_1.Set(H); 58. PrintX(Info_1.Average()); 59. PrintX(Info_1.Median()); 60. 61. Info_2.Set(K); 62. PrintX(Info_2.Average()); 63. PrintX(Info_2.Median()); 64. } 65. //+------------------------------------------------------------------+
Código 04
Observa que es bastante sencillo convertir el código 01 en un código capaz de crear una sobrecarga de estructura para obtener, en última instancia, un código completamente estructural. Como las funciones y los procedimientos se declaran dentro del contexto de la estructura, heredan su propia declaración. Esto ocurre cuando el compilador pasa a implementar la sobrecarga de la propia estructura.
Como se ha mencionado, tenemos el problema de los retornos debido precisamente al hecho de que, en algunos momentos, convertiremos valores enteros en valores de punto flotante, concretamente del tipo double, lo cual puede ser un problema en algunos casos. Esto se puede observar en las líneas 20 y 30 de este código 04. Pero espera un momento. No entendí por qué sería un problema. Y, siendo así, ¿habría alguna manera de superarlo con el fin de evitar riesgos innecesarios?
Bueno, mi querido lector, para entender esto, necesitamos primero ver cuál sería el resultado de la ejecución del código 04. Esto puede verse justo abajo.
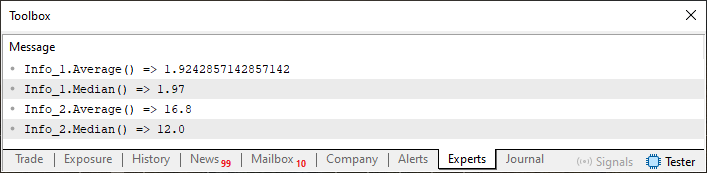
Imagen 03
Ahora, presta atención a un detalle presente en la imagen 03. Observa que el retorno de Info_2.Median es un valor de punto flotante, pero Info_2, cuando se declara en el código, es de tipo entero, como se puede ver en la línea 55. El problema aquí es que la estructura no está logrando lidiar adecuadamente con este tipo de situaciones, en las que, cuando pedimos que devuelva un valor mediano que se encuentra presente en la propia estructura de datos, el sistema termina retornando un tipo diferente. Lo correcto sería devolver un valor entero, pero se está devolviendo un valor de punto flotante.
Este tipo de cuestiones, que aparentemente son fáciles de resolver, se vuelven mucho más complicadas y difíciles de solucionar en la práctica y con códigos reales. Sin embargo, básicamente, lo que muchos programadores —y esto lo digo de manera genérica— hacen es adoptar una metodología en la que se añaden más y más funciones y procedimientos con el fin de resolver algún tipo de problema interno de la propia estructura. Esto, en la mayoría de los casos, resuelve el problema, aunque suele generar soluciones o implementaciones que, en principio, no tienen mucho sentido para otros programadores. La razón es simple: la mejor forma de resolver un problema no es resolverlo, sino proporcionar los mecanismos necesarios para poder pensar en él en términos de partes más pequeñas.
¿Pero cómo así? Ahora estoy confundido. Para entenderlo, necesitamos usar este código 04 como mecanismo de aprendizaje. Primer punto: ¿por qué necesitamos devolver un valor medio directamente a través de una función? Bueno, puedes responder que, al hacer eso, el código resultaría más sencillo al usar la propia estructura. De hecho, sería un buen argumento.
Pero volvamos al caso de los números enteros, como ocurre en la declaración de la línea 55. El valor medio de los elementos que estamos colocando allí, es decir, en la línea 61, es, de hecho, un valor de punto flotante, en este caso, 16,8. Sin embargo, piensa en alguna situación en la que necesitemos un valor medio que deba ser entero. En ese caso, sería necesario hacer un redondeo. Existen reglas de redondeo para este tipo de escenarios, pero este no es el caso.
El objetivo es que el programador que utilice la estructura sepa cómo, cuándo y por qué efectuar el redondeo del valor. El objetivo es obtener un valor entero.
Para hacer esto, necesitamos cambiar el contexto de lo que se está implementando en la estructura. A menudo, no eliminamos partes, sino que añadimos nuevas partes al código, creando así bloques más pequeños y específicos. Para entenderlo mejor, veamos un ejemplo práctico. Puedes observar que en la línea 20 del código 04 tenemos una función que calcula la media de los valores de la propia estructura. Hasta aquí, nada extraordinario.
Pero fíjate que para obtener esta media necesitamos hacer dos cosas: la primera es saber cuál es la suma de los elementos y la segunda, cuántos elementos hay. En este momento, puedes estar pensando: «Cierto, ¿y entonces?» Que si, en lugar de hacer esto directamente en la función Average, creas otras dos funciones, puedes permitir que el usuario de la estructura elija cómo, dónde y por qué redondear los valores del promedio de los elementos de la estructura.
No sé si lograste captar la idea, querido lector, pero veamos cómo se haría en la práctica. Para ello, utilizaremos el código que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Sum(void) 21. { 22. T sum = 0; 23. 24. for (uint c = 0; c < NumberOfElements(); c++) 25. sum += Values[c]; 26. 27. return sum; 28. } 29. //+----------------+ 30. uint NumberOfElements(void) 31. { 32. return Values.Size(); 33. } 34. //+----------------+ 35. double Average(void) 36. { 37. return ((double)Sum() / NumberOfElements()); 38. } 39. //+----------------+ 40. double Median(void) 41. { 42. T Tmp[]; 43. 44. ArrayCopy(Tmp, Values); 45. ArraySort(Tmp); 46. if (!(Tmp.Size() & 1)) 47. { 48. int i = (int)MathFloor(Tmp.Size() / 2); 49. 50. return (Tmp[i] + Tmp[i - 1]) / 2.0; 51. } 52. return (double) Tmp[Tmp.Size() / 2]; 53. } 54. //+----------------+ 55. }; 56. //+------------------------------------------------------------------+ 57. #define PrintX(X) Print(#X, " => ", X) 58. //+------------------------------------------------------------------+ 59. void OnStart(void) 60. { 61. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 62. const char K[] = {12, 4, 7, 23, 38}; 63. 64. st_Data <double> Info_1; 65. st_Data <char> Info_2; 66. 67. Info_1.Set(H); 68. PrintX(Info_1.Average()); 69. PrintX(Info_1.Median()); 70. 71. Info_2.Set(K); 72. PrintX(Info_2.Average()); 73. PrintX(Info_2.Sum()); 74. PrintX(Info_2.NumberOfElements()); 75. PrintX(Info_2.Sum() / Info_2.NumberOfElements()); 76. PrintX(Info_2.Median()); 77. } 78. //+------------------------------------------------------------------+
Código 05
Muy bien, en este código 05 estamos modelando algo que muchos pueden pensar que solo ocurre cuando trabajamos con programación orientada a objetos, pero que nació con la programación estructural, que consiste en dividir el código en pequeños bloques. Fíjate en que ahora tenemos, en la línea 20 de este código, una función cuyo propósito es devolvernos el valor de la suma de todos los elementos de la estructura. El tipo de valor que retornamos depende del tipo de dato que se encuentra en la propia estructura. Presta atención a esto, pues es información importante. También tenemos otra función, que se encuentra en la línea 30 y cuyo objetivo es devolver el número de elementos de la propia estructura.
Ahora viene la parte realmente interesante. Como el promedio se calcula dividiendo estos dos valores que estamos calculando en las funciones mencionadas anteriormente, en la línea 37 tenemos un cálculo enfocado en el contexto de la estructura. Pero este es el punto principal. Observa que le estamos indicando al compilador que convierta el resultado de la función Sum en un tipo double. ¿Por qué estamos haciendo esto? La respuesta puede verse en la imagen de la ejecución de este código 05. Esta imagen se puede observar justo abajo.
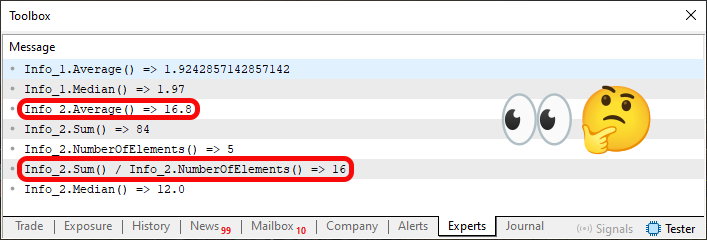
Imagen 04
En esta imagen, se destacan dos informaciones: una corresponde a la ejecución de la línea 72 y la otra, a la línea 75. Sin embargo, observa que ambos datos impresos son de tipo diferente. Una es de punto flotante y la otra, de entero. A continuación, explico por qué se convierte el resultado de la función Sum en double en la línea 37. Observa que el mismo cálculo que se hace en la línea 37 se repite en la línea 75, pero en un caso se convierte el valor 84, que sería el resultado de la suma de los elementos de la línea 62, a double, y en el otro caso no. Por esta razón, aunque el contexto nos permita calcular el promedio directamente en la estructura, como se está haciendo en la línea 37, también podremos hacerlo fuera de ella. Precisamente por esta razón, podemos controlar cómo será el resultado en términos del tipo de dato que se utilizará.
Puede parecer absurdo, pero fíjate que, sin cambiar la forma de estructurar las cosas, hemos dado al programador medios para controlar, ajustar e incluso elegir cómo se representa el resultado, cosa que de otra manera sería mucho más difícil y laboriosa. Todo esto se logró simplemente moviendo el cálculo que antes se efectuaba en una función a más de una función accesible fuera del cuerpo de la estructura. Sin embargo, incluso haciendo esto, todavía conseguimos mantener el contexto de la propia estructura, ya que, al observar la línea 75, podemos entender qué tipo de información estamos buscando.
Si estudias este tipo de cosas, mi querido lector, te darás cuenta de que, en la mayoría de los casos, cuando hablamos de clases y programación orientada a objetos nos referimos a esto. Sin embargo, con este sencillo código, hemos demostrado que este concepto existe con independencia de la programación orientada a objetos. Así, cuando se explique este modelo de programación en el futuro, ya tendrás una buena base, ya que habrás visto que la programación orientada a objetos busca precisamente suplir algo que no se puede hacer mediante programación estructurada.
Muy bien, esto ha sido divertido, pero ¿podríamos hacer algo más sin complicar demasiado las cosas? Sí, mi querido lector. Existe un concepto, aunque no es necesariamente un concepto, sino una técnica que diversos programadores utilizan en sus códigos para simplificar gran parte de lo que se ha visto aquí. Sin embargo, si no se entiende lo que se ha explicado aquí, resulta confuso comprender lo que podemos hacer para crear una sobrecarga de estructura. Cabe recordar que la sobrecarga a la que me refiero busca crear una estructura más genérica, pero con un contexto muy definido.
Como aún tenemos un poco de tiempo, puedo dar una breve introducción sobre en qué consistiría la maniobra mencionada anteriormente. Pero para ello necesitamos parar y pensar en algunas cosas. En primer lugar, observa que en las líneas 64 y 65 del código 05 hay una declaración cuyo propósito es mantener datos discretos. Es decir, valores que pueden ser enteros o de punto flotante. Sin embargo, si te paras a pensarlo, las uniones y las estructuras también son formas de datos, por lo que también podrían declararse como un tipo de dato que se usará en la estructura cuyo código se sobrecargará, con el fin de construir un modelo adecuado a ese tipo de dato específico.
Creo que has entendido esto y has practicado este tipo de cosas en los artículos en los que hablamos sobre cómo se produce la sobrecarga y el uso de plantillas en los códigos. Pero, a diferencia de los tipos discretos de datos, los tipos como uniones y estructuras son más complejos, ya que pueden contener diversas cosas dentro de sí. Toma, por ejemplo, la estructura MqlRates. En ella se definen varias cosas, como el precio de apertura, el precio de cierre, el spread, el volumen, etc. Por tanto, aunque en principio podamos declarar una plantilla de estructura capaz de recibir cualquier tipo de información, ya sean valores complejos o discretos, existen agravantes que nos impiden —aunque esta no sea la palabra más adecuada— definir tipos complejos en un lugar donde se esperaban tipos discretos. Sin embargo, esto no nos impide crear ciertos mecanismos necesarios para resolver de manera menos costosa ciertos problemas específicos.
Entonces, querido lector, quiero que pienses en cómo podríamos utilizar datos como uniones o estructuras dentro de un código como el del código 05 para poder generalizar, en diversos aspectos, la sobrecarga de una estructura y construir así un código completamente estructural. Sé que esta no es una de las tareas más sencillas de comprender y ejecutar. Sin embargo, quiero que reflexiones sobre ello, pues en el próximo artículo vamos a tratar precisamente algo relacionado con esto.
Consideraciones finales
En este artículo, he intentado explicar cómo se hace la sobrecarga de un código estructural de la manera más simple, didáctica y práctica posible. Sé que esto es bastante difícil de entender al principio, sobre todo si es la primera vez que ves esto. Es muy importante que asimiles estos conceptos y entiendas muy bien lo que sucede aquí antes de intentar aventurarte en cosas más complicadas y elaboradas.
En el anexo encontrarás los códigos vistos aquí para que puedas estudiarlos y practicarlos con calma. En el próximo artículo, subiremos aún más el nivel llevando este tipo de implementación para lograr cubrir casos en los que podemos utilizar cualquier tipo de dato en la propia sobrecarga de estructura, algo que muchos imaginan que solo es posible mediante programación orientada a objetos. Pero verás que aún no necesitamos la programación orientada a objetos para implementar ciertos tipos de solución. Así que, ¡buenos estudios! Nos vemos pronto.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15869
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso