
От начального до среднего уровня: Struct (V)

Введение
В предыдущей статье, "От начального до среднего уровня : Struct (IV)", мы начали более серьезно и в более прикладном ключе говорить о программировании для создания структурированного кода. Многим такие моменты могут показаться глупыми и не имеющими практического смысла, ведь речь идет практически только об объектно-ориентированном программировании. И многие не понимают, что ООП появилось не в одночасье. Оно является результатом долгих исследований и дебатов целого сообщества программистов и оно появилось только тогда, когда были осознаны ограничения структурного программирования.
Но, в отличие от обычного программирования, где мы объявляем переменные, функции и процедуры для решения конкретной задачи, структурное программирование стремится реализовать подход, при котором мы можем решить не только одну задачу, но и целый ряд связанных между собой проблем.
Я знаю, что многие из вас (особенно новички) наверняка задумываются: «Друг, я не хочу учиться этому. Я хочу научиться создавать советник или индикатор. Учиться внедрять решения, которые я даже не собираюсь использовать, - просто не мое». Ладно, вы имеете право так думать. Но если не понимать, как реализовать решения, не имеющие ничего общего с индикатором или даже фрагментом кода советника, вы окажетесь в тупике раньше, чем думаете. Это происходит в связи с тем, что вы не понимаете, как реализовать решения, которые не являются ни очевидными, ни простыми.
Для того, чтобы уметь решать любые возникающие проблемы, необходимо иметь мышление программиста. И одна из этих проблем заключается как раз в том, что до сих пор не было объяснено: как расширить структурное программирование для решения более широких задач. Иными словами, если мы создаем код для решения проблемы с целочисленными типами, как мы можем реализовать решение для данных с плавающей точкой, не переделывая всё заново? Это очень интересный вопрос, но в то же время он может быть и очень запутанным, поскольку существуют разные способы сделать одно и то же.
Я постараюсь объяснить, по крайней мере, два разных способа сделать это. Второй способ связан с манипуляциями памяти, и я не знаю, готовы ли вы к этому. Однако, начнем с самого простого. Это даст вам общее представление о том, как подойти к решению проблемы. Так что пора сосредоточиться на том, о чем рассказывается в этой статье. Теперь будет интересно.
Как использовать шаблоны в структурах
Здесь мы проанализируем первый способ использования шаблонов в структурах данных, который является самым простым способом понять, как перегружаются структуры. Помните, что всё, что здесь будет показано, предназначено только для образовательных целей. Ни в коем случае нельзя рассматривать этот материал как окончательный код, который можно использовать без должных предосторожностей.
Для начала возьмем код из предыдущей статьи, поскольку в нем есть то, что, на мой взгляд, довольно практично и легко понять применительно к тому, что мы будем делать здесь. Версию, которую мы будем использовать, показываем ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. double Average(void) 20. { 21. double sum = 0; 22. 23. for (uint c = 0; c < Values.Size(); c++) 24. sum += Values[c]; 25. 26. return sum / Values.Size(); 27. } 28. //+----------------+ 29. double Median(void) 30. { 31. double Tmp[]; 32. 33. ArrayCopy(Tmp, Values); 34. ArraySort(Tmp); 35. if (!(Tmp.Size() & 1)) 36. { 37. int i = (int)MathFloor(Tmp.Size() / 2); 38. 39. return (Tmp[i] + Tmp[i - 1]) / 2.0; 40. } 41. return Tmp[Tmp.Size() / 2]; 42. } 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
Код 01
Выполнив код 01 в платформе MetaTrader 5, мы получим следующий результат:

Изображение 01
Пока ничего особого. Но подумайте о следующей ситуации: код 01 реализован для того, чтобы сообщить нам две вещи: среднее значение и медиану массива значений. Однако он может делать это только со значениями с плавающей точкой, а именно со значениями double, поскольку он не понимает значения float, хотя это тоже тип данных с плавающей точкой. Не говоря уже о целочисленных значениях.
В данном случае, несмотря на кажущуюся практичность, код 01 во многом бесполезен, поскольку для работы с числовыми типами данных, отличными от плавающей точки, нам придется реализовывать структуру снова и снова, пока не будут охвачены все числовые типы данных.
Подобные ситуации известны как перегрузка. Однако перегрузка структур работает не так, как перегрузка функций и процедур. В данном случае при выполнении перегрузки нам придется изменить имя структуры, то есть информацию, обрабатываемую в строке 04 из кода 01.
И в результате мы создадим серию новых структур с тем же назначением, контекстом и инкапсулированными данными, но с совершенно отличными друг от друга именами. Иными словами, полный хаос и огромное количество работы.
Программисты, и я говорю об этом на собственном опыте, не любят лишнюю работу. Если нам приходится повторять код более одного раза, мы начинаем скучать и теряем интерес. Мы любим думать о решении проблем. Но продублировать код только для того, чтобы изменить одну деталь, нам не по душе. Я определенно ненавижу это делать. Другие программисты, также, как и я, тоже придумали, как решить подобную проблему и создали механизм, который позволяет создавать перегрузку того, что не может быть перегружено. Так и родилась идея использовать шаблоны структур.
В их базовом варианте, мы уже объяснили шаблоны в короткой серии из пяти статей, первая из которых - "От начального до среднего уровня: Шаблон и Typename (I)". Итак, очень важно, чтобы вы хорошо усвоили все знания и концепции, которые были там объяснены, чтобы вы могли понять то, что будет сделано сейчас. Это происходит, потому что осталось непонятным то, что объяснялось выше. То, что мы собираемся сделать сейчас, не имеет никакого смысла.
Но то, что будет покажем, - это самый простой и легкий способ работы с перегрузкой структуры, хотя существуют и другие способы, гораздо сложнее и с очень специфическими целями. Я подумаю, стоит ли создавать статью, чтобы показать другие способы. В любом случае, самым простым способом будет использование шаблона.
Поэтому давайте сделаем шаг назад, ведь прежде, чем рассматривать применение шаблона структуры к структурированной реализации, мы должны посмотреть, как он применяется к более общей структуре. Другими словами, нам нужно рассмотреть, как шаблон структуры используется в обычном коде. Для этого мы изменим код 01 со структурного на обычный. Конечный результат будет таким:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. double Values[]; 07. }; 08. //+------------------------------------------------------------------+ 09. double Average(const st_Data &arg) 10. { 11. double sum = 0; 12. 13. for (uint c = 0; c < arg.Values.Size(); c++) 14. sum += arg.Values[c]; 15. 16. return sum / arg.Values.Size(); 17. } 18. //+------------------------------------------------------------------+ 19. double Median(const st_Data &arg) 20. { 21. double Tmp[]; 22. 23. ArrayCopy(Tmp, arg.Values); 24. ArraySort(Tmp); 25. if (!(Tmp.Size() & 1)) 26. { 27. int i = (int)MathFloor(Tmp.Size() / 2); 28. 29. return (Tmp[i] + Tmp[i - 1]) / 2.0; 30. } 31. return Tmp[Tmp.Size() / 2]; 32. } 33. //+------------------------------------------------------------------+ 34. #define PrintX(X) Print(#X, " => ", X) 35. //+------------------------------------------------------------------+ 36. void OnStart(void) 37. { 38. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 39. const double K[] = {12, 4, 7, 23, 38}; 40. 41. st_Data Info_1, 42. Info_2; 43. 44. ArrayCopy(Info_1.Values, H); 45. PrintX(Average(Info_1)); 46. 47. ArrayCopy(Info_2.Values, K); 48. PrintX(Median(Info_2)); 49. } 50. //+------------------------------------------------------------------+
Код 02
Хорошо, теперь код 02 имеет обычный формат. При выполнении в MetaTrader 5 мы получим такой результат:

Изображение 02
Ну что ж, учитывая всё, что рассказывалось до этого момента, я уверен, что вы легко поймете, что делает и как работает код 02. Точно так же, как мы можем работать с типом с плавающей точкой, мы можем реализовать здесь шаблоны функций и процедур. Таким образом, код 02 станет таким:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. double Values[]; 08. }; 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. double Average(const st_Data <T> &arg) 12. { 13. T sum = 0; 14. 15. for (uint c = 0; c < arg.Values.Size(); c++) 16. sum += arg.Values[c]; 17. 18. return sum / arg.Values.Size(); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. double Median(const st_Data <T> &arg) 23. { 24. T Tmp[]; 25. 26. ArrayCopy(Tmp, arg.Values); 27. ArraySort(Tmp); 28. if (!(Tmp.Size() & 1)) 29. { 30. int i = (int)MathFloor(Tmp.Size() / 2); 31. 32. return (Tmp[i] + Tmp[i - 1]) / 2.0; 33. } 34. return Tmp[Tmp.Size() / 2]; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uchar K[] = {12, 4, 7, 23, 38}; 43. 44. st_Data <double> Info_1; 45. st_Data <uchar> Info_2; 46. 47. ArrayCopy(Info_1.Values, H); 48. PrintX(Average(Info_1)); 49. 50. ArrayCopy(Info_2.Values, K); 51. PrintX(Median(Info_2)); 52. } 53. //+------------------------------------------------------------------+
Код 03
«Какое космическое осложнение. Друг, что это за безумный и безумный код? Нужно ли проходить через это?» Успокойся, этот код не такой безумный, как тот, что использует манипуляции с памятью. Поэтому я подумаю, стоит ли показывать, как реализовать перегрузку структуры через манипуляции с памятью. Однако многое из кода 03 уже будет вам знакомо и понятно. Пожалуй, строки 44 и 45 - единственные, которые могут преподнести какой-то сюрприз.
Впрочем, о подобном рассказывали в статье "От начального до среднего уровня: Шаблон и Typename (IV)", но не в отношении использования структур, а в отношении использования объединений. В любом случае, принципы работы одинаковы. И, так как уже объяснили всё там, я не вижу необходимости объяснять ту же самую концепцию снова, тем более, что это было необходимо сделать уже в двух статьях.
Так что, если вы не понимаете, что происходит в коде 03, я советую вам вернуться к предыдущим статьям. Как я уже говорил, знания накапливаются со временем. Попытка пропустить этапы, полагая, что можно понять что-то более сложное, не разобравшись предварительно в базовых понятиях, редко приводит к хорошему результату.
Хорошо, но здесь есть небольшая деталь, которая, на первый взгляд, не вызывает раздражения: тип данных, которые будет возвращать медиана. Проблема здесь связана с тем, что если массив содержит четное количество элементов, тест в строке 28 изменит поток таким образом, что будет выполнена строка 32. Но если количество элементов нечетное, будет выполнена строка 34, что во многих случаях приведет к тому, что результат будет отличаться от ожидаемого.
Так происходит, потому что массив с целочисленными элементами не должен, в принципе, возвращать значение с плавающей точкой, как это происходит в данном случае. Поэтому результат, выводимый на терминал, не совсем соответствует значениям массива, объявленного в строке 42, так как массив имеет целочисленные элементы, а возвращаемое значение - тип с плавающей точкой. Но поскольку код носит чисто образовательный характер, я предпочитаю оставить это небольшое несоответствие, а не показывать полностью неверный результат.
Таким образом, взглянув на код 03 и подумав, как преобразовать его в нечто подобное коду 01, имеющему структурную реализацию, легко обнаружить правильный путь, поскольку достаточно изменить код 01, чтобы объявление шаблона, показанное в коде 03, выполнилось.
Но вас может беспокоить тот факт, что в коде 03 мы должны были реализовать функции в виде шаблона. «Так нужно ли делать то же самое с кодом 01, чтобы структурная реализация работала правильно и компилятор знал, как перегружать структуру? Что ж, в данном случае это не понадобится, поскольку сам контекст довольно прост и добавить к нему особо нечего.
Однако, в отличие от кода 03, где мы передаем значения структуры по ссылке, в коде 01 это невозможно. Причина этого мы уже объяснили в предыдущей статье, где вопрос контекста рассматривался вместе с вопросом инкапсуляции данных. Единственный способ ввести новые значения - это процедура Set, которая присутствует в коде 01. Поэтому этот пункт будет один из немногих, где нам придется реализовать что-то отличное от того, что изначально существует в коде 01. Таким образом, ниже показываем новый код 01, уже учитывающий перегрузку структур.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. double Average(void) 21. { 22. double sum = 0; 23. 24. for (uint c = 0; c < Values.Size(); c++) 25. sum += Values[c]; 26. 27. return sum / Values.Size(); 28. } 29. //+----------------+ 30. double Median(void) 31. { 32. T Tmp[]; 33. 34. ArrayCopy(Tmp, Values); 35. ArraySort(Tmp); 36. if (!(Tmp.Size() & 1)) 37. { 38. int i = (int)MathFloor(Tmp.Size() / 2); 39. 40. return (Tmp[i] + Tmp[i - 1]) / 2.0; 41. } 42. return (double) Tmp[Tmp.Size() / 2]; 43. } 44. //+----------------+ 45. }; 46. //+------------------------------------------------------------------+ 47. #define PrintX(X) Print(#X, " => ", X) 48. //+------------------------------------------------------------------+ 49. void OnStart(void) 50. { 51. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 52. const char K[] = {12, 4, 7, 23, 38}; 53. 54. st_Data <double> Info_1; 55. st_Data <char> Info_2; 56. 57. Info_1.Set(H); 58. PrintX(Info_1.Average()); 59. PrintX(Info_1.Median()); 60. 61. Info_2.Set(K); 62. PrintX(Info_2.Average()); 63. PrintX(Info_2.Median()); 64. } 65. //+------------------------------------------------------------------+
Код 04
Прошу заметить, как просто преобразовать код 01 в код, способный создавать структурные перегрузки, чтобы в итоге получить полностью структурный код. Так как функции и процедуры объявляются в контексте структуры, они наследуют свое собственное объявление. Это происходит, когда компилятор переходит к реализации перегрузки самой структуры.
Как уже упоминалось, проблема возвратов возникает именно из-за того, что в некоторых моментах мы будем преобразовывать целочисленные значения в значения с плавающей точкой, а именно типа double, что в некоторых случаях может стать проблемой. Это можно увидеть в строках 20 и 30 из кода 04. «Но подождите секундочку. Я не понимаю, почему это может быть проблемой. И если да, то есть ли способ преодолеть её, чтобы избежать ненужных рисков?»
Ну что ж, чтобы понять это, нам сначала нужно посмотреть, каким будет результат выполнения кода 04. Смотрим ниже:
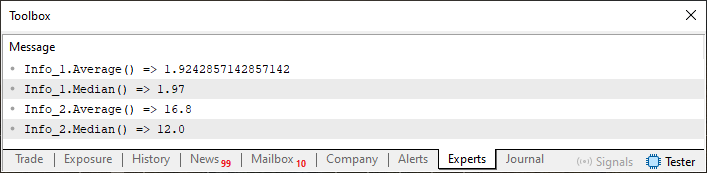
Изображение 03
Теперь обратите внимание на деталь, присутствующую на изображении 03. Обратите внимание, что возвращаемое значение Info_2.Median - это значение с плавающей точкой, но у Info_2, когда оно объявлено в коде, тип integer, как видно из строки 55. Проблема заключается в том, что структура не справляется с подобной ситуацией, когда мы просим её вернуть значение медианы, присутствующее в самой структуре данных, и в итоге система возвращает другой тип. Правильнее было бы вернуть целочисленное значение, но мы возвращаем значение с плавающей точкой.
Подобные вопросы, которые, казалось бы, легко решить, на практике и в реальных кодах оказываются гораздо сложнее. Однако, в основном многие программисты (и я говорю это в общем смысле) используют методологию, в которую добавляют всё больше и больше функций и процедур, чтобы решить какую-то внутреннюю проблему самой структуры. В большинстве случаев это решает проблему, хотя часто порождает решения или реализации, которые в принципе не имеют большого смысла для других программистов. Причина проста: лучший способ решить проблему - это не решить её, а предоставить механизмы, позволяющие думать о ней в терминах более мелких частей.
«Но как же так? Кажется, есть какое-то противоречие». Чтобы понять это, нам нужно использовать код 04 в качестве обучающего механизма. «Первый момент: зачем нам нужно возвращать среднее значение непосредственно через функцию?» На это можно ответить, что код будет проще за счет использования самой структуры. На самом деле, это было бы хорошим аргументом.
Но давайте вернемся к случаю целых чисел, как в операторе в строке 55. Среднее значение элементов, которые мы помещаем туда, то есть в строку 61, на самом деле является значением с плавающей точкой, в данном случае 16.8. Но подумайте о ситуации, когда нам нужно среднее значение, которое должно быть целым. В этом случае потребуется округление. Для таких ситуаций существуют правила округления, но это не тот случай.
Цель состоит в том, чтобы программист, использующий данную структуру, знал, как, когда и почему округлять значение. Задача состоит в том, чтобы получить целое значение.
Для этого нам нужно изменить контекст того, что внедряем в структуру. Часто мы не удаляем части кода, а добавляем в него новые, создавая тем самым более мелкие и точные блоки. Чтобы лучше понять это, давайте рассмотрим практический пример. Как можно видеть, в строке 20 кода 04 у нас есть функция, которая вычисляет среднее значение значений самой структуры. Пока ничего экстраординарного.
Однако, обратите внимание, что для получения этого среднего нам нужно сделать две вещи: во-первых, узнать сумму элементов, а во-вторых, узнать, сколько всего элементов. Сейчас вы, возможно, подумаете: «Верно, а что дальше?» Если вместо того, чтобы делать это непосредственно в функции Average, создать две другие функции, то можно позволить пользователю структуры выбирать, как, где и почему округлять средние значения элементов структуры.
Не знаю, уловили ли вы идею, дорогие читатели, но давайте посмотрим, как это будет сделано на практике. Для этого мы используем следующий код.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Sum(void) 21. { 22. T sum = 0; 23. 24. for (uint c = 0; c < NumberOfElements(); c++) 25. sum += Values[c]; 26. 27. return sum; 28. } 29. //+----------------+ 30. uint NumberOfElements(void) 31. { 32. return Values.Size(); 33. } 34. //+----------------+ 35. double Average(void) 36. { 37. return ((double)Sum() / NumberOfElements()); 38. } 39. //+----------------+ 40. double Median(void) 41. { 42. T Tmp[]; 43. 44. ArrayCopy(Tmp, Values); 45. ArraySort(Tmp); 46. if (!(Tmp.Size() & 1)) 47. { 48. int i = (int)MathFloor(Tmp.Size() / 2); 49. 50. return (Tmp[i] + Tmp[i - 1]) / 2.0; 51. } 52. return (double) Tmp[Tmp.Size() / 2]; 53. } 54. //+----------------+ 55. }; 56. //+------------------------------------------------------------------+ 57. #define PrintX(X) Print(#X, " => ", X) 58. //+------------------------------------------------------------------+ 59. void OnStart(void) 60. { 61. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 62. const char K[] = {12, 4, 7, 23, 38}; 63. 64. st_Data <double> Info_1; 65. st_Data <char> Info_2; 66. 67. Info_1.Set(H); 68. PrintX(Info_1.Average()); 69. PrintX(Info_1.Median()); 70. 71. Info_2.Set(K); 72. PrintX(Info_2.Average()); 73. PrintX(Info_2.Sum()); 74. PrintX(Info_2.NumberOfElements()); 75. PrintX(Info_2.Sum() / Info_2.NumberOfElements()); 76. PrintX(Info_2.Median()); 77. } 78. //+------------------------------------------------------------------+
Код 05
Итак, в коде 05 мы моделируем то, что, как многие думают, происходит только при работе с ООП, но это родилось в структурном программировании, которое заключается в разделении кода на небольшие блоки. Прошу заметить, что в строке 20 этого кода у нас теперь есть функция, цель которой - вернуть значение суммы всех элементов структуры. Тип возвращаемого значения зависит от вида данных, содержащихся в самой структуре. Обратите на это внимание, так как это важно. Также у нас есть еще одна функция, расположенная в строке 30, цель которой - вернуть количество элементов самой структуры.
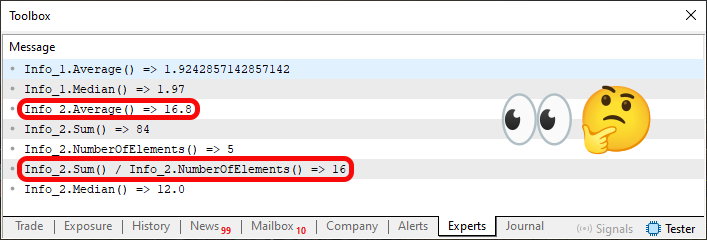
Теперь начинается самое интересное. Поскольку среднее значение рассчитывается делением этих двух величин, которые мы вычисляем в функциях, упомянутых выше, в строке 37 у нас расчет, ориентированный на контекст структуры. Но это главный момент. Прошу заметить, что мы указываем компилятору преобразовать результат функции Sum к типу double. Зачем это делать? Ответ можно увидеть на изображении выполнения кода 05. Вот оно:
Изображение 04
На этом изображении выделяются два фрагмента информации: один соответствует выполнению строки 72, а другой - строки 75. Тем не менее, прошу заметить, что эти два вида представленных данных относятся к разным типам. Один из них - с плавающей запятой, а другой - целочисленный. Ниже мы объясняем, почему результат функции Sum преобразуется в double в строке 37. Обратите внимание, что то же самое вычисление, которое выполняется в строке 37, повторяется в строке 75, но в одном случае значение 84, которое было бы результатом суммы элементов в строке 62, преобразуется в double, а в другом - нет. Поэтому, хотя контекст позволяет нам вычислять среднее непосредственно в структуре, как это делается в строке 37, мы также сможем делать это вне структуры. Именно поэтому мы можем контролировать, как будет выглядеть результат с точки зрения типа используемых данных.
Это может показаться абсурдным, но заметьте, что, не меняя структуры вещей, мы дали программисту возможность контролировать, настраивать и даже выбирать способ представления результата, что иначе было бы гораздо сложнее и требовало бы много времени. Всё это было достигнуто простым перемещением вычислений (которые ранее выполнялись в одной функции) в несколько функций, доступных вне тела структуры. Однако и в этом случае нам удается сохранить контекст самой структуры, поскольку, взглянув на строку 75, мы понимаем, какого рода информация нам нужна.
Если вы изучите подобные вещи, то поймете, что в большинстве случаев именно это мы имеем в виду, когда говорим о классах и объектно-ориентированном программировании. Однако с помощью этого простого кода мы показали, что данная концепция существует независимо от ООП. Таким образом, когда в будущем вам будут рассказывать об этой модели программирования, у вас уже будет хорошая основа, поскольку вы увидите, что ООП направлено именно на то, чтобы восполнить то, что не может сделать структурированное программирование.
«Ладно, это было интересно, но не могли бы мы сделать что-нибудь ещё, не слишком усложняя ситуацию?» Да, мой дорогой читатель. Существует концепция, хотя это не обязательно концепция, а техника, которую различные программисты используют в своем коде, чтобы упростить многое из того, что мы видели здесь. Но если вы не понимаете, о чем говорилось здесь, вам будет трудно понять, что мы можем сделать, чтобы создать структурную перегрузку. Стоит помнить, что перегрузка, о которой мы рассуждали, направлена на создание более общей структуры, но с очень определенным контекстом.
Так как у нас ещё есть немного времени, я могу вкратце рассказать, в чем будет заключаться вышеупомянутый маневр. Но для этого нам нужно остановиться и подумать о некоторых моментах. Во-первых, обратите внимание, что в строках 64 и 65 кода 05 есть оператор, назначение которого - хранить дискретные данные. Т.е. значения, которые могут быть целочисленными или с плавающей точкой. Однако, если задуматься, объединения и структуры - это тоже формы данных, поэтому их также можно объявить как тип данных, который будет использоваться в структуре, чей код будет перегружен, чтобы построить модель, подходящую для этого конкретного типа данных.
Думаю, вы уже поняли это и скорее всего практиковались в статьях, где мы рассказывали о том, как происходит перегрузка и использование шаблонов в коде. Однако, в отличие от дискретных типов данных, такие типы, как объединения и структуры, более сложны, так как могут содержать в себе самые разные вещи. Возьмем, к примеру, структуру MqlRates. В ней определяются некоторые элементы, такие как цена открытия, цена закрытия, спред, объем и так далее. Поэтому, хотя в принципе мы можем объявить шаблон структуры способным принимать любой тип информации, будь то комплексные или дискретные значения, существуют усложняющие факторы, которые не позволяют нам (хотя это не самое подходящее слово) определять комплексные типы там, где ожидались дискретные типы. Но это не мешает нам создавать определенные механизмы, необходимые для решения конкретных задач менее затратным способом.
Итак, я хочу, чтобы вы подумали, как мы могли бы использовать такие данные, как объединения или структуры в коде, подобном тому, что приведен в коде 05, чтобы обобщить, различными способами, перегрузку структуры и таким образом построить полностью структурный код. Я знаю, что это не самая простая задача, но я хочу, чтобы вы задумались над этим, потому что в следующей статье мы рассмотрим именно то, что с этим связано.
Заключительные идеи
В этой статье мы постарались объяснить, как перегрузить структурный код наиболее простым, дидактическим и практичным способом. Я знаю, что сначала это довольно сложно для понимания, особенно если увидеть это впервые. Очень важно, чтобы вы усвоили эти понятия и хорошо поняли их, прежде чем пытаться вникать в более сложные и проработанные вещи.
В приложении вы найдете коды для изучения и практики. В следующей статье мы поднимем планку ещё выше, расширив этот тип реализации в случаях, когда мы можем использовать любой тип данных в самой перегрузке структуры, что, по мнению многих, возможно только в ООП. Но вы увидите, что для реализации некоторых типов решений нам по-прежнему не нужно ООП. Итак, успехов вам в учебе! До скорой встречи.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15869
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования