
Do básico ao intermediário: Template e Typename (V)

Introdução
No artigo anterior Do básico ao intermediário: Template e Typename (IV), expliquei da maneira que fosse a mais didática e simples, quanto foi possível ser feita, como poderíamos criar um template, a fim de generalizar um tipo de modelagem. Criando assim o que poderia ser considerado, uma sobrecarga de tipos de dados. Porém no final daquele artigo, apresentei algo que para muitos, pode ser muito difícil de entender. Que era justamente a transferência dos dados para dentro de uma função ou procedimento, que estivesse sendo implementado também como template. Justamente, pelo fato, de aquilo que foi apresentado, exigir uma explicação melhor, que deixei para fazer isto neste artigo. Além do mais, precisamos falar de uma outra coisa, que tem tudo a ver com este tema. Onde a utilização de templates pode ser a diferença entre conseguir ou não implementar algo.
Assim para começarmos de maneira adequada este artigo. Vamos iniciar um novo tópico para explicar por que aquele último código, visto no artigo anterior funciona.
Expandindo a mente
No artigo anterior, implementados algo que tem uma aparência, bastante incomum. Já que acredito que muitos de vocês ainda não haviam visto algo do tipo. Para podermos explicar adequadamente o que tudo aquilo significa. Precisamos rever o código que foi utilizado. Este pode ser observado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. Swap(info); 20. PrintFormat("After modification : 0x%I64X", info.value); 21. } 22. 23. { 24. un_01 <ushort> info; 25. 26. info.value = 0xCADA; 27. PrintFormat("The region is composed of %d bytes", sizeof(info)); 28. PrintFormat("Before modification: 0x%I64X", info.value); 29. Swap(info); 30. PrintFormat("After modification : 0x%I64X", info.value); 31. } 32. } 33. //+------------------------------------------------------------------+ 34. template <typename T> 35. void Swap(un_01 <T> &arg) 36. { 37. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 38. { 39. tmp = arg.u8_bits[i]; 40. arg.u8_bits[i] = arg.u8_bits[j]; 41. arg.u8_bits[j] = tmp; 42. } 43. } 44. //+------------------------------------------------------------------+
Código 01
Muito bem, dado o fato de que você deve ter experimentado bastante o que foi visto no artigo anterior. Este código 01, deve de fato ter lhe chamado a atenção. Isto por conta justamente da forma como o procedimento da linha 35 está sendo declarado. Certo, para entender o que, mas principalmente por que, precisamos declarar as coisas como está sendo feito neste código 01.
Primeiro precisamos entender que este procedimento da linha 35, é um procedimento que estará sendo sobrecarregado pelo compilador. Isto durante o processo de criação do código executável. Pois bem, como foi dito no artigo anterior. Lancei o desafio, para você, meu caro e estimado leitor e iniciante em programação. Criar um código que efetuasse o mesmo trabalho do código 01, porém se fazer uso da sobrecarga via template. Isto para o procedimento que se encontra implementado na linha 35. Tendo este exercício, o objetivo, de tornar claro, por que o procedimento precisa ser declarado daquela maneira.
Como em teoria, este exercício é simples, mas na prática pode ser um tanto quanto complicado. Vamos então fazer isto juntos. Assim, você poderá entender o motivo pelo qual a declaração precisa ser feita daquela maneira, como pode ser visualizado no código 01.
Não irei mexer em todo o código, apenas no procedimento. Desta maneira, podermos então focar no fragmento visto logo abaixo.
. . . 33. //+------------------------------------------------------------------+ 34. void Swap(un_01 <ulong> &arg) 35. { 36. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 37. { 38. tmp = arg.u8_bits[i]; 39. arg.u8_bits[i] = arg.u8_bits[j]; 40. arg.u8_bits[j] = tmp; 41. } 42. } 43. //+------------------------------------------------------------------+ 44. void Swap(un_01 <ushort> &arg) 45. { 46. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 47. { 48. tmp = arg.u8_bits[i]; 49. arg.u8_bits[i] = arg.u8_bits[j]; 50. arg.u8_bits[j] = tmp; 51. } 52. } 53. //+------------------------------------------------------------------+
Fragmento 01
Este fragmento 01, substitui o procedimento que existe na linha 35. Mas preste atenção. O que este fragmento 01 contém, é EXATAMENTE aquilo que o compilador irá criar quando traduzir e fizer a sobrecarga do procedimento visto no código 01. Sendo assim, aqui, neste fragmento 01, apenas os tipos ulong e ushort é que estão sendo cobertos. Diferente do que é visto no código 01. Onde todos os tipos primários estão sendo cobertos.
Mas então, por que precisamos declarar as coisas desta forma como é visto no fragmento 01? O motivo, acredito eu, agora está de fato bem mais claro. Se você entendeu o que foi explicado no artigo anterior, deve ter percebido o motivo pelo qual precisamos que as linhas 14 e 24, vistas no código 01, venham a ser declaradas daquela forma. E pelo mesmo motivo, também precisamos que as linhas 34 e 44, vistas neste fragmento 01, sejam declaradas de uma forma semelhante.
Lembre-se do seguinte fato, que foi visto lá nos primeiros artigos, quando falarmos sobre passagem de valor ou passagem por referência. Ao declararmos uma variável, precisamos dizer o tipo da mesma assim como precisamos dar um nome a ela. E dentro da declaração de uma função ou procedimento, estamos sim, declarando ali, uma variável, que pode ou não ser uma constante, dependendo de cada caso específico.
Ok, quanto a questão da declaração das variáveis para tratar um procedimento, a coisa aparentemente é simples. Mas ainda estou com uma dúvida. Quando você falou sobre variáveis especiais, disse que uma função seria um destes tipos de variáveis. Porém, neste tipo de situação, como a que estamos lidando neste momento. Como poderíamos utilizar uma função para cobrir o código. E assim implementar o que precisamos?
Bem, está de fato é uma excelente pergunta, meu caro leitor. Isto por que, de fato, para conseguirmos retornar valores, precisamos de utilizar uma declaração diferente da que estamos fazendo quando utilizamos procedimentos. No entanto, o conceito adotado é bem parecido com o que foi visto até o momento. Lembre-se de que, quando retornamos algo, este retorno é um tipo de variável. Como se estivéssemos declarando uma variável, cujo nome é o nome da função. Assim sendo, podemos muito bem, levar a cabo o conceito básico e criar o nosso código da forma adequada.
Então, antes de vermos a forma generalizada, vamos ver uma maneira parecida com a que pode ser vista no fragmento 01. No entanto, devido ao fato de que funções tem como objetivo, trabalharem de uma maneira diferente de um procedimento, vamos também mudar o código 01. Assim surge o que pode ser visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. PrintFormat("After modification : 0x%I64X", Swap(info).value); 20. } 21. 22. { 23. un_01 <ushort> info; 24. 25. info.value = 0xCADA; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. PrintFormat("After modification : 0x%I64X", Swap(info).value); 29. } 30. } 31. //+------------------------------------------------------------------+ 32. un_01 <ulong> Swap(const un_01 <ulong> &arg) 33. { 34. un_01 <ulong> local; 35. 36. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 37. { 38. tmp = arg.u8_bits[i]; 39. local.u8_bits[i] = arg.u8_bits[j]; 40. local.u8_bits[j] = tmp; 41. } 42. 43. return local; 44. } 45. //+------------------------------------------------------------------+ 46. un_01 <ushort> Swap(const un_01 <ushort> &arg) 47. { 48. un_01 <ushort> local; 49. 50. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 51. { 52. tmp = arg.u8_bits[i]; 53. local.u8_bits[i] = arg.u8_bits[j]; 54. local.u8_bits[j] = tmp; 55. } 56. 57. return local; 58. } 59. //+------------------------------------------------------------------+
Código 02
Note que agora, este código 02, é um pouco diferente do que pode ser observado no código 01. Porém, apesar destas pequenas diferenças. Ele ainda assim, produz o mesmo resultado. Ou seja, quando você compilar este código 02, e o executar no terminal do MetaTrader 5, irá ter o que pode ser visto na imagem logo abaixo.
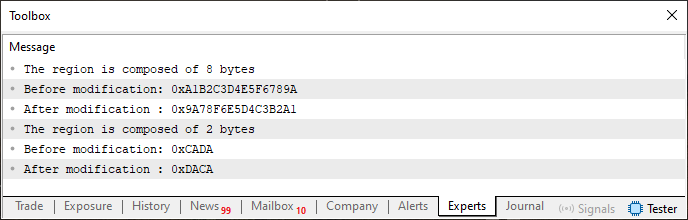
Imagem 01
Observe que é exatamente o mesmo tipo de resposta, que será obtida ao executar o código 01. Mesmo depois de o ter mudado, para fazer uso do fragmento 01. Porém, da mesma forma que o fragmento 01, limita as opções de tipo de dados que o compilador irá poder utilizar, quando estivermos tentando utilizar a união un_01. A
qui, neste código 02, temos esta mesma limitação. No entanto, quero que você observe o fato de como o fragmento 01, foi traduzido de maneira a podermos utilizar funções, no lugar de procedimentos. Observem também as linhas 19 e 28 deste código 02. Pois é ali, onde fazemos a utilização do que seria a variável especial, chamada Swap. Que na verdade é uma função. Mas com um objetivo nobre de ser utilizada como uma variável apenas de leitura.
Muito legal, este tipo de coisa. Não é mesmo? Mas, da mesma forma que o fragmento 01, estaria mostrando o que o procedimento visto no código 01 estaria fazendo. Podemos transformar estas funções vista no código 02 em um template. Desta maneira, deixaríamos o código, tendo o mesmo comportamento e liberdade de escolha de tipos, que está sendo oferecido ao código 01. Para fazer isto, basta que venhamos a transformar, os pontos comuns, vistos nas funções do código 02 em um ponto que o compilador, posa atuar de alguma forma. Isto para que ele, o compilador, consiga trocar o tipo de dado, sempre que for necessário fazer isto. Entendendo este conceito, podemos transcrever o código 02, para o código 03, visto logo na sequência.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. { 14. un_01 <ulong> info; 15. 16. info.value = 0xA1B2C3D4E5F6789A; 17. PrintFormat("The region is composed of %d bytes", sizeof(info)); 18. PrintFormat("Before modification: 0x%I64X", info.value); 19. PrintFormat("After modification : 0x%I64X", Swap(info).value); 20. } 21. 22. { 23. un_01 <ushort> info; 24. 25. info.value = 0xCADA; 26. PrintFormat("The region is composed of %d bytes", sizeof(info)); 27. PrintFormat("Before modification: 0x%I64X", info.value); 28. PrintFormat("After modification : 0x%I64X", Swap(info).value); 29. } 30. } 31. //+------------------------------------------------------------------+ 32. template <typename T> 33. un_01 <T> Swap(const un_01 <T> &arg) 34. { 35. un_01 <T> local; 36. 37. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 38. { 39. tmp = arg.u8_bits[i]; 40. local.u8_bits[i] = arg.u8_bits[j]; 41. local.u8_bits[j] = tmp; 42. } 43. 44. return local; 45. } 46. //+------------------------------------------------------------------+
Código 03
E este código 03 é o aperfeiçoamento do que seria o código 02. Já que agora temos a possibilidade de utilizar qualquer tipo de dado que desejarmos. E o compilador irá conseguir entender, e assim criar todas as sobrecargas necessárias para que nossa aplicação seja criada com sucesso.
Com isto, o que antes pareceria algo extremamente complexo, e difícil de entender, passou a ser simples e trivial. Sendo que qualquer iniciante agora consegue lidar com o uso de templates. Notaram como as vezes achamos algo complicado, mas se entendermos de fato os conceitos adotados, conseguimos implementar qualquer coisa com facilidade? E por isto, que estou dizendo, para você praticar o que está sendo mostrado. Não para decorar forma se codificar as coisas. Mas sim, entender como os conceitos estão sendo explorados e aplicados em cada situação especifica.
Ok, está de fato é a parte que muitos poderiam dizer se de nível intermediário ou avançado. Mas ao meu ver, isto que foi mostrado aqui, é apenas o básico. Porém ainda precisamos falar um pouco mais sobre o que estamos fazendo aqui. Já que até o momento, não foi mencionado, o motivo pelo qual sempre temos esta palavra reservada typename, sendo utilizada.
No entanto, esta explicação exige que venhamos a entrar em um novo tópico. Isto para que tudo seja devidamente separado e estudado com calma e atenção. Então vamos fazer isto. Criando assim um novo tópico.
Typename. Para que isto serve de fato?
Uma dúvida que é muito justa e que de fato merece uma explicação adequada é: O que seria typename? E para que ela nos serviria em um código real? Bem, meu caro leitor, entender isto pode lhe ajudar a implementar alguns tipos de código bem interessantes. Se bem, que na maior parte das vezes typename é utilizada apenas para fins bem específicos e voltados a algum tipo de atividade de testagem.
Raramente, pelo menos, até onde sei, typename será utilizada para outra coisa, se não o de averiguar e assegurar que uma função ou procedimento que esteja sendo sobrecarregado pelo compilador, venha a sair do controle. Isto por que, não é raro, implementarmos algo como sendo um template, e ao utilizar, esta função ou procedimento. Tenhamos resultados incoerentes justamente devido ao fato de que este ou aquele tipo, não estaria de fato sendo implementado corretamente pelo nosso template.
Outras vezes, podemos desejar, que ao utilizarmos um tipo de dado, venhamos a ter um determinado comportamento, de uma função ou procedimento sobrecarregado pelo compilador. E em outro tipo de dado, que o comportamento venha a ser outro. Isto para a mesma função ou procedimento. Pode parecer um tanto quanto confuso, falar e mencionar este tipo de coisa. Porém na prática, isto as vezes se faz necessário. Então entender como typename funciona. Pode e irá lhe ajudar a lidar com este tipo de situação.
Para demonstrar isto, vamos tentar criar uma aplicação que seja pelo menos divertida. Já que demonstrar como trabalhar com typename é algo muito específico, o que torna as coisas um pouco chatas. Mas vamos ver se conseguimos deixar as coisas menos chatas. Para isto, vamos tentar utilizar o código que é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 41. { 42. tmp = arg.u8_bits[i]; 43. local.u8_bits[i] = arg.u8_bits[j]; 44. local.u8_bits[j] = tmp; 45. } 46. 47. return local; 48. } 49. //+------------------------------------------------------------------+
Código 04
Neste código 04, estamos tentando brincar com tudo que foi visto e explicado até este momento. Isto com o objetivo de entender como typename pode vier a ser utilizada em um código real. O objetivo aqui, é espelhar toda informação que esteja presente na memória, ou no caso, uma variável. De forma que a metade da direita vá para a esquerda. Ao mesmo tempo que a metade da esquerda troque de lugar com a metade da direita. Simples assim.
Olhando o código 04, você claramente nota que ele é quase que uma simples modificação do que estamos vendo até o momento. E isto está sendo feito de maneira completamente intencional. Já que assim podemos focar no que realmente é novidade e precisa ser compreendido.
Quando este código 04 é executado no MetaTrader 5, temos como resposta o que é visto logo abaixo.
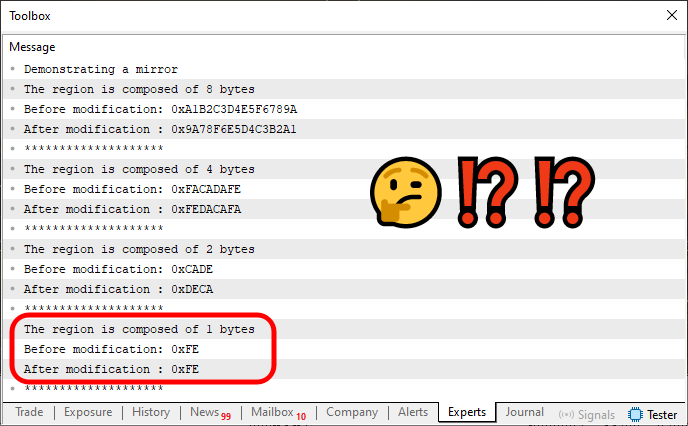
Imagem 02
Note que estou destacando um dos valores. E o motivo para isto é simples: Ele NÃO ESTÁ SENDO ESPELHADO. Já que o lado direito, NÃO ESTÁ sendo trocado com o lado esquerdo. No entanto, para todos os demais valores o espelhamento está ocorrendo. Sendo assim, o problema está no fato de que quando usamos um tipo que tem um byte. Perdemos a capacidade de espelhar o lado direito no esquerdo, e vice versa.
Porém, toda via e, entretanto, sabemos que no MQL5, temos apenas um tipo que escapa, ou melhor atende, ao critério de um byte. E este é o tipo uchar, quando temos não temos um valor com sinal. E o tipo char, quando temos um valor com sinal. No entanto, implementar uma chamada sobrecarregada para lidar com estes tipos é um tanto quanto inconveniente. Isto por que, perdemos a isonomia da operação se fizermos este tipo de abordagem. O ideal é de fato continuar a utilizar a função Mirror, que está sendo implementada na linha 36 para conseguir fazer isto.
Bem, mas agora vem a pergunta chave: Como podemos saber, ou melhor, como podemos dizer ao compilador, como lidar com o tipo uchar ou char. Isto a fim de conseguir o espelhamento dos valores?
Bem, meu caro leitor, existem muitas formas de se fazer isto. Uma das que ao meu entender seria a mais prática e simples, seria ler bit a bit, os alternar. Entre os bits da direita e o da esquerda. Assim, não precisaríamos utilizar uma sobrecarga de funções ou procedimentos, da forma como iremos fazer. Porém, o objetivo aqui, não é este, ficando assim como dever de casa, você meu caro leitor, tentar implementar este tipo de solução, onde fazemos o espelhamento, trocando bit a bit, os valores presentes na informação de entrada. Isto irá lhe ajudar a fixar melhor alguns conceitos e até mesmo, pensar como um programador.
Mas, e para nós neste momento. Como podemos resolver isto? Bem, meu caro leitor, esta é a parte onde as coisas ficam um tanto quanto interessantes. Isto por que, typename, pode literalmente nos dizer o nome do tipo de dado que está chegando. Ou para deixar mais claro, podemos perguntar a typename, qual é o tipo de dado que estamos recebendo, ou está sendo utilizado por uma variável. Para tornar isto palatável e para que você entenda o que estaremos fazendo. Vamos criar uma pequena modificação no código 04. Esta pode ser vista no código logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. PrintFormat("Type is: [%s] or variable route is: {%s}", typename(T), typename(arg)); 41. for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = arg.u8_bits[i]; 44. local.u8_bits[i] = arg.u8_bits[j]; 45. local.u8_bits[j] = tmp; 46. } 47. 48. return local; 49. } 50. //+------------------------------------------------------------------+
Código 05
Quando você executar este código 05, irá ver algo muito parecido com a imagem que podemos observar logo abaixo
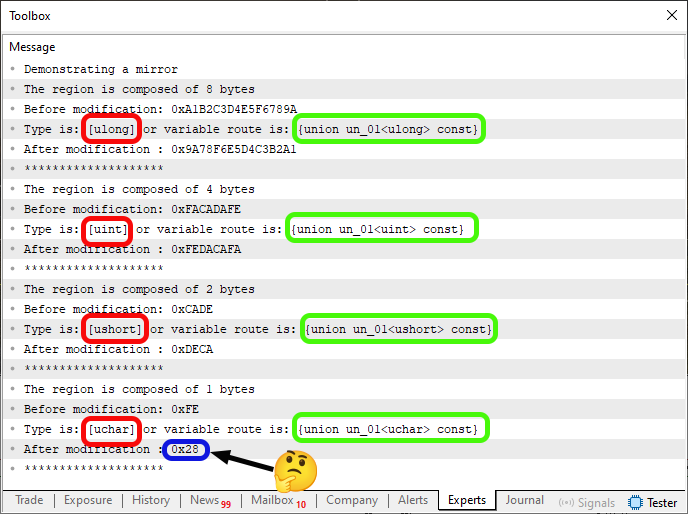
Imagem 03
Aqui nesta imagem 03, surgiu uma coisa da qual eu não entendi. Já que NÃO FAZ o menor sentido isto ter surgido. Tanto que está sendo destacada em AZUL. BIZARRO. Mas não é este o ponto aqui. O que realmente nos interessa são as partes nesta imagem 03, que estão sendo destacadas em vermelho e verde. Mas de onde veio estas informações? Bem, meu caro leitor, estas informações foram impressas devido a linha 40 no código 05. Agora preste atenção, pois isto é muito, mais muito importante ser muito bem compreendido. Caso contrário, você poderá vir a ter problemas no futuro, ao tentar utilizar tais informações que estão sendo destacadas em vermelho e verde na imagem 03.
TODAS A MARCAÇÕES EM VERMELHO, se referem ao fato de estarmos pedido ao compilador, que nos diga, QUAL É O TIPO PRIMITIVO de dado que está sendo utilizado pela função. Já AS MARCAÇÕES EM VERDE, se referem a resposta do compilador, ao nosso pedido, para que ele nos informe o TIPO DE DADO QUE ESTÁ SENDO UTILIZADO PELA VARIÁVEL. Note que existe uma diferença muito sutil na nossa pergunta. Porém a resposta pode ser completamente diferente.
Normalmente, e muito provavelmente você, meu caro leitor, irá ver, muitos programadores pedindo para o compilador dizer, qual o tipo de dado da variável. No entanto, isto nem sempre irá nos dar a resposta correta, ou melhor dizendo, a resposta que esperamos obter. Isto por que, pode ser que estejamos em uma situação muito parecida com a que é mostrada logo acima. Onde o tipo primitivo de dado é um, e o tipo de dado utilizado pela variável é um tipo mais complexo. Porém ligado de alguma maneira ao tipo mais primitivo de dado.
Porém, não precisa ficar afoito, pensando como vai fazer para verificar isto. No anexo, estes códigos estarão disponíveis a ponto de que você possa estudar e praticar este tipo de coisa com calma. Mas voltando a nossa questão, o que nos interessa, é a informação que se encontra destacada em vermelho na imagem 03. E notem que todas estão sendo escritas da mesma maneira que declaramos isto durante a fase de implementação do código. Porém, quero chamar a sua atenção, meu caro e estimado leitor, ao fato de que, estes valores são strings. Ou seja, podemos comparar eles com outras strings, durante a fase de execução do código. E é justamente esta a parte que nos interessa de fato.
Beleza, agora já temos um ponto de apoio. Falta fazer um pequeno teste a fim de isolar o tipo uchar ou char, que são os tipos que possuem um único byte, a fim de fazermos o espelhamento adequado dos valores. Para isto, precisaremos implementar uma pequena modificação. Mas desta vez iremos retornar ao código original. Ou seja, o código 04, a fim de gerar a modificação necessária. Tal modificação pode ser observada no código logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. if (StringFind(typename(T), "char") > 0) local.value = (arg.value << 4) | (arg.value >> 4); 41. else for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = arg.u8_bits[i]; 44. local.u8_bits[i] = arg.u8_bits[j]; 45. local.u8_bits[j] = tmp; 46. } 47. 48. return local; 49. } 50. //+------------------------------------------------------------------+
Código 06
Agora preste atenção meu caro leitor. O que estou fazendo aqui, pode ser feito de diversas maneiras diferentes. Cada uma tem suas vantagens e desvantagens. Podendo ser mais ou menos simples de entender o que estará sendo feito, e como as coisas estarão de fato ocorrendo. Se você por ventura, não estiver entendendo muito bem este código 06. Não tem problema, você irá ter acesso a ele no anexo, e poderá modificar o mesmo a fim de que venha a conseguir entender o que está acontecendo ali.
Porém, antes de fazer isto, é bom você primeiro compreender o que eu implementei e como será o resultado final, quando este código vier a ser executado. Caso contrário, você pode modificar algo, e ter um resultado diferente do que seria o esperado e visto no código, e achar que tudo está ocorrendo perfeitamente bem.
Então vamos lá. Primeiramente, vamos ver qual o resultado da execução, quando olhamos o terminal do MetaTrader 5. Este resultado pode ser observado na imagem logo abaixo.
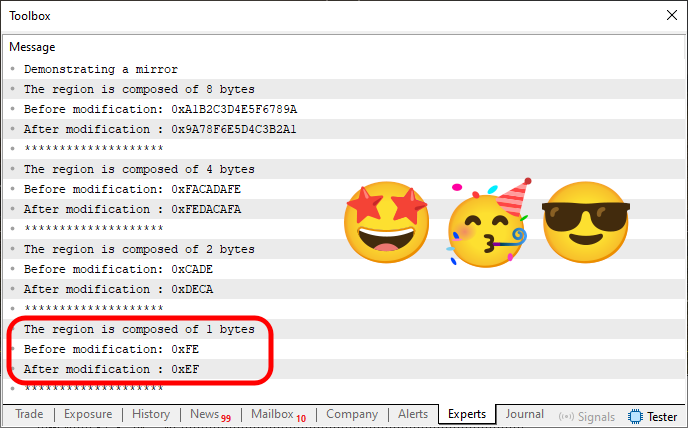
Imagem 04
Simplesmente maravilhoso. O código de fato conseguiu cumprir seu objetivo que era o de espelhar os valores de cada variável, de forma que a metade a direita fosse trocada com a metade a esquerda. Da forma como era estimado e esperado. Mas note que para fazer isto, com base no código 04, tudo que foi adicionado ao código 06, foi a linha 40. Claro que precisamos fazer um pequeno ajuste na linha 41. Mas isto não é a parte que quero chamar a sua atenção. Mas sim para a função que estou usando para testar se iremos usar um ou outro método para fazer o espelhamento.
Esta função da biblioteca padrão do MQL5, StringFind irá nos permitir procurar um fragmento específico dentro da string que typename estiver retornando. Isto é importante para nós. Justamente pelo motivo de que, INDEPENDENTEMENTE de estarmos usando o tipo utilizado pela variável, ou o tipo primitivo que o compilador utilizou. Poderemos ter a incidência do fragmento procurado. Mas, e é este o motivo de eu estar utilizando justamente esta função em especial. StringFind, irá conseguir tanto nos dar um resultado quando uchar for retornada, quanto também char. Isto por que, a diferença entre ambas é justamente, e exclusivamente o u, que está presente em uchar, porém não está presente em char. De qualquer forma, teremos o teste sendo feito, e um resultado sendo reportado.
Porém, toda via e, entretanto, cada caso é um caso. Dependendo do tipo de coisa que você venha a desejar construir em seu código. Esta pequena diferença entre os nomes dos tipos, com a mesma largura de bytes. Pode afetar o resultado final. Isto por que, em um caso podemos ter valores negativos e em outro não. Apesar de que a resolução explicita de tipo, pode ser aplicada a fim de corrigir este tipo de inconveniente. É bom ficar atento, quando for realmente implementar um código que estejamos interessados em usar uma informação que o compilador possa ter criado.
Agora vem a parte engraçada. Você pode ter notado, que sem mais nem menos o resultado está de fato correto, na imagem 04. Mas ainda assim, aquele resultado visto na imagem 03, precisa ser levado em consideração. Não sei exatamente por que o compilador resolveu fazer uma pegadinha do malandro conosco. Isto porque se modificarmos o código 06, a ponto de que venhamos a visualizar o mesmo tipo de informação que o código 05, estaria imprimindo, o resultado fica correto. Porém, algo BIZARRO ocorreu no momento em que fui compilar o código 05, e que fatalmente estava gerando um resultado estranho como pode ser visto na imagem 03.
Para comprovar isto, o código modificado, do qual estou me referindo é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. union un_01 06. { 07. T value; 08. uchar u8_bits[sizeof(T)]; 09. }; 10. //+------------------------------------------------------------------+ 11. void OnStart(void) 12. { 13. Print("Demonstrating a mirror"); 14. 15. Check((ulong)0xA1B2C3D4E5F6789A); 16. Check((uint)0xFACADAFE); 17. Check((ushort)0xCADE); 18. Check((uchar)0xFE); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. void Check(const T arg) 23. { 24. un_01 <T> local; 25. string sz; 26. 27. local.value = arg; 28. PrintFormat("The region is composed of %d bytes", sizeof(local)); 29. PrintFormat("Before modification: 0x%I64X", local.value); 30. PrintFormat("After modification : 0x%I64X", Mirror(local).value); 31. StringInit(sz, 20, '*'); 32. Print(sz); 33. } 34. //+------------------------------------------------------------------+ 35. template <typename T> 36. un_01 <T> Mirror(const un_01 <T> &arg) 37. { 38. un_01 <T> local; 39. 40. PrintFormat("Type is: [%s] or variable route is: {%s}", typename(T), typename(arg)); 41. if (StringFind(typename(T), "char") > 0) local.value = (arg.value << 4) | (arg.value >> 4); 42. else for (uchar i = 0, j = sizeof(arg) - 1, tmp; i < j; i++, j--) 43. { 44. tmp = arg.u8_bits[i]; 45. local.u8_bits[i] = arg.u8_bits[j]; 46. local.u8_bits[j] = tmp; 47. } 48. 49. return local; 50. } 51. //+------------------------------------------------------------------+
Código 07
Note que este código 07, é uma composição entre o código 05 e o código 06. E quando o executamos, iremos poder visualizar o que é mostrado na imagem logo abaixo.
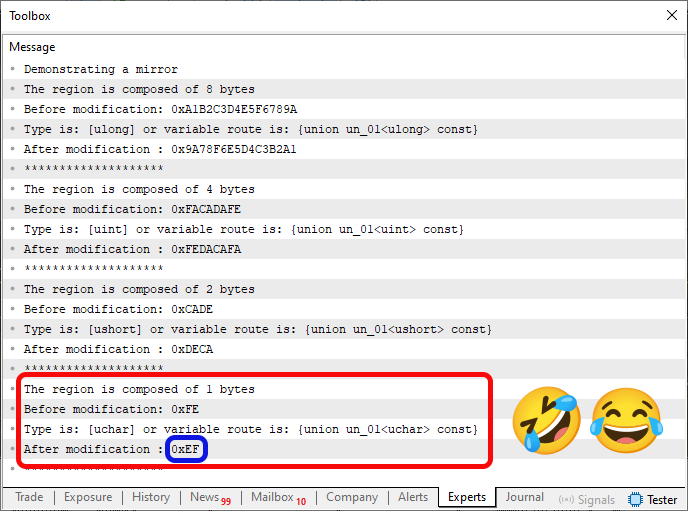
Imagem 05
É ou não é uma piada? Vai entender o que pode ter acontecido no momento em que o código 05 foi compilado, ou mesmo durante a execução do mesmo. Ainda bem estamos aqui, fazendo coisas que não necessitam de precisão e um ou outro pequeno deslise pode ser tolerado. Mas ainda assim, não deixa de ser engraçado.
Considerações finais
Neste artigo, finalizamos o que seria a explicação e o treinamento necessário para que você, meu caro e estimado leitor, que está iniciando no ramo da programação. Pudesse de fato, vir a aprender o que seria uma sobrecarga de função ou procedimento. Isto a fim e conseguir fazer com que um mesma função ou procedimento, pudesse utilizar o mesmo nome, porém utilizando dados de tipos diferentes.
Começamos todo este processo, vendo casos simples como o que foi visto em Do básico ao intermediário: Sobrecarga, e passamos para casos cada vez mais elaborados. Construindo assim templates de funções e procedimentos. Porém, como este tipo de conceito, se estende além do que pode ser compreendido como sendo funções e procedimentos. Passamos a adotar o mecanismo de criação de template, para nos permitir passar menos tempo programando. Porém, ao utilizarmos templates, em nossas implementações, começamos de fato a jogar o trabalho, de criação da sobrecarga de funções e procedimentos para o compilador. Isto a fim de simplificar a nossa vida como programadores.
Porém, toda via e, entretanto, podemos expandir o conceito de template para outros cenários. Como por exemplo, a criação e manipulação de tipos complexos de dados. No caso, como apenas falei de uniões, restringimos todos os conceitos e aplicações a este tipo de modelagem. Assim, tornou-se possível, que fosse experimentado, a possibilidade de implementar a sobrecarga de tipos. E isto, nos abriu diversas portas, tornando possível fazer ainda mais coisas, com muito menos código. Já que a responsabilidade de ajustar e manter tudo dentro dos conformes, passou a ser do compilador. A nós, ficou a responsabilidade, de dizer ao compilador, qual tipo de dado primitivo, que deveria ser utilizado.
No entanto, as possibilidades, poderiam ainda ser aumentadas, nos permitindo, manipular de maneira controlada, as coisas. Isto quando um ou outro tipo primitivo de dado, fosse utilizado em nosso código. Para fazer este controle, passamos a utilizar typename, que nos permite saber o nome do tipo utilizado. Seja pelo compilador, seja pela variável que estamos querendo manipular.
Sei que muitos de vocês, principalmente iniciantes, podem estar achando tudo isto, muito complicado e confuso. Porém, vale lembrar que ainda estamos no nível que eu considero ser o mais básico e simples possível. Por isto, aconselho a você, meu caro e estimado leitor, que procure estudar e praticar o que tem sido mostrado. Principalmente foque em estudar cada ponto que foi explicado nestes artigos até o momento. Pois a coisa daqui para frente, só tende a se tornar cada dia mais complicada e interessante. E para aqueles que de fato gostam de programar. Estamos prestes a entrar em um novo parque de diversões, chamado MQL5.
Então nós vemos no próximo artigo. Onde começaremos a abordar um tema ainda mais interessante e divertido.
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso