
Falácias, Parte 2. A estatística é uma pseudociência ou uma crônica sobre a queda de uma fatia de pão com manteiga

Introdução
A primeira parte do cabeçalho do artigo é uma citação da postagem por SergNF com data de 17 de abril de 2008 14:04, https://www.mql5.com/ru/forum/108164. Bem, até a matemática mais rígida vira pseudociência quando usada por um "pesquisador" que decide brincar com fórmulas atrativas sem nenhuma aplicação prática.
O ceticismo do autor da citação, mesmo moderada com três "sorrisos", é óbvio. As razões para tal são bastante claras: as inúmeras tentativas de aplicar métodos estatísticos à realidade objetiva, ou seja, a séries financeiras, falham quando encontramos os processos não estacionários, "mentiras" sobre acompanhar a distribuição de probabilidade e volume insuficiente de dados financeiros. Nenhum dos modelos de mercado existentes pode ser reconhecido como suficientemente adequado à realidade. E até mesmo se conseguirmos encontrar algumas regularidades estatísticas, os resultados da sua utilização parecem ser desproporcionais aos esforços investidos no seu ensino.
Nessa publicação tentarei me referir não às séries financeiras como tal, mas sim as suas apresentações subjetivas - nesse caso, à forma que um trade tenta prender as séries, ou seja, ao sistema de trading. O ensino das regularidades estatísticas processo de resultados de trading é uma tarefa atraente. Em alguns casos, conclusões bastante verdadeiras sobre o modelo desse processo podem ser feitas e elas podem ser aplicadas ao sistema de trading.
Peço desculpas aos leitores que não têm contato com a matemática, pela complexidade da exposição, mas, obviamente, é a sequência inevitável dos conteúdos do artigo. Parece que a promessa feita no final do meu artigo anterior não foi cumprida. Então, vamos começar nossa busca.
No artigo conseguimos construir um exemplo artificial que nos mostra vividamente um estratégia lucrativa com o gerenciamento de dinheiro (MM)rule "lot=0.1" que se torna um prejuízo em um MM geométrico. Uma sequência muito regular de trades lucrativos e prejudiciais foi usada e dificilmente pode ser encontrada na realidade: P L P L P L P L P L P L ... A primeira pergunta é: Porque eu analiso exatamente as sequências "regulares"?
Séries prejudiciais: Breve visão geral
A razão é simples; está especificada no artigo Meu primeiro "Graal":
Ao mesmo tempo, nunca podemos prever exatamente como as ordens prejudiciais serão distribuídas entre as lucrativas. Essa distribuição é predominantemente de natureza aleatória.
P P P L P P P L P P P L P P P L P P P L P P P L P P P L ...
B. Abaixo está um exemplo das situações mais prováveis da distribuição não uniforme de trades lucrativos e prejudiciais durante o trading real:
P P P P P P P P P P P P P P P L L L L P P P L P P P L ...
Uma série de 5 perdas consecutivas é mostrada acima, embora tais séries podem ser ainda maiores. Deve-se notar que, nesse caso, a razão entre as ordens lucrativas e prejudiciais é mantida em 3: 1.
Assim, a alternação "regular" entre trades lucrativos e prejudiciais é ideal em termos de baixa mínima (e máximo fator de recuperação). E se, como no artigo anterior, conseguirmos mostrar que mesmo nesse caso ideal (quando os trades lucrativos e prejudiciais se alternam) o sistema se torna um prejuízo em um MM geométrico, com os mesmo valores da expectativa matemática de negócios lucrativos e prejudiciais, então é certo de ser ainda pior em um distribuição não regular de resultados de trade.
Observação: Suponha que a razão entre os trades lucrativos e prejudiciais seja igual a 14:9. Como iriamos distribuir os trades em séries para ter baixas mínimas? Essa não é uma questão fácil, até se considerarmos o MM rule "lot=0.1" e tentarmos provar que as séries serão ótimas. Fica praticamente claro que as perdas deveriam ser distribuídas "de forma igual" nas séries - digamos, dessa forma:
P L P L P P L P P L P P L P L P L P P L P P L...
Essa é uma "série elementar" que consiste em 23 trades, 14 deles sendo lucrativos. Depois disso, essa série se repete. Fica claro que tal série tem baixas muitos mais graves em ambos os tipos de MM, por exemplo, este:
P P P P P P P P P P P P P P L L L L L L L L L…
Fica especialmente vívido com MM geométricos (as razões foram explicadas no artigo Entretanto, até mesmo essa série prejudicial ("cluster prejudicial") não é o limite. Para entender isso, vamos rever a base da teoria da probabilidade. Mas, primeiro vamos definir alguns termos.
Terminologia
Esse artigo contem muito termos conectados às series Bernoulli e histogramas que visualizam várias distribuições de probabilidade. Para combiná-los, vamos definir a terminologia. Então:
- Uma série completa de trades será chamada aqui simplesmente de uma série. Esse termo refere-se a ambas as séries obtidas durante o processamento dos resultados de um único teste real e às séries obtidas sinteticamente durante a geração de uma série de Bernoulli. Se o comprimento da série precisar ser indicado, iremos denotá-lo assim: 3457-series (um série contendo 3457 trades).
- Uma sequência de trades sucessivos da mesmo sinal dentro de uma série (trades lucrativos ou prejudiciais, ou "sucessos" ou "fracassos") aqui será chamada um cluster. Se o comprimento tiver que ser indicado, será chamado, por exemplo, um 7-cluster (um cluster de comprimento 7).
- Um grande número de séries (nesse contexto, falaremos principalmente sobre séries sintéticas) será chamado um arranjo de séries O número também pode ser denotado: 65000-array of 5049-series (série de Bernoulli 65000, cada uma com 5009 de comprimento).
- Ao construir histogramas, às vezes precisamos levar em conta os clusters que pertencem não somente a séries específicas, mas também ao arranjo inteiro de séries. O nome do histograma corresponde ao parâmetro, a distribuição dele é visualizada. Em vez de escrever "Histograma de distribuição de clusters com o comprimento 4 em uma arranjo de série 5000 cada uma com 3174 de comprimento" iremos denotar assim: "4-clusters in 5000-array of 3174-series».
Esquema de Bernoulli: O básico
Com muito frequência, muitas tarefas práticas, nas quais uma sequência de eventos é considerada, podem ser reduzidas ao seguinte esquema:
- Cada evento tem apenas dois resultados - "sucesso" e "fracasso" ("ganho" e "prejuízo"). A probabilidade de "sucesso" é pe a de "fracasso" é q = 1-p.
- A probabilidade do resultado do evento não depende do histórico dos eventos que o antecedem.
Isso é chamado de Esquema de Bernoulli (ou) Tentativas de Bernoulli). Nossa sequência codificada colorida poderia ser considerada um esquema de Bernoulli se estivéssemos certos do segundo critério da definição dada acima.
O autor pensa ser verdade para a maioria do sistemas de trading. Aqui estão algumas provas indiretas:
- Qualquer informação sobre um sistema da conta-Z, de acordo com a opinião daqueles que tentaram aplicá-lo para a otimização MM, parece ser inútil ao tentar calcular a probabilidade de um certo trade – até mesmo quando a probabilidade de ganho é mais do que 90%:
- A eficiência de vários esquemas de martingale, para todas as aparências, também é igual a zero ou até mesmo negativa, enquanto leva a baixas inadmissíveis.
É por isso que agora seria ilógico aceitar, para a maioria dos sistemas de trading, uma série de seus trades sucessivos que corresponde ao critério do esquema de Bernoulli. Tal hipótese leva a consequências bastante graves.
A fórmula clássica para a probabilidade de k ganha (a propósito, podemos nos referir aqui à trades prejudiciais também) na série de n testes no esquema de Bernoulli é o seguinte (a probabilidade de ganho é igual a p):
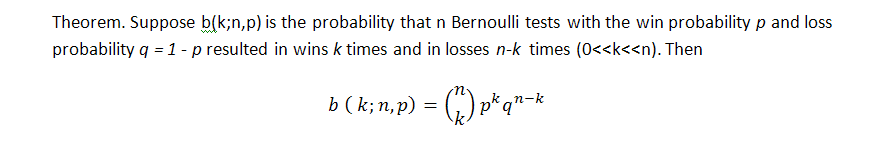
Essa fórmula mostra alguns parâmetros de série integrais, números de ganhos, mas não diz nada sobre como esses ganhos são distribuídos, ou seja, não sabemos nada sobre o comprimento de possíveis clusters. A busca do comprimento de possíveis clusters prejudiciais na série de Bernoulli é uma tarefa muito mais difícil; a solução é descrita por Feller [1]. Abaixo estão fórmulas para a expectativa matemática de uma série de teste e sua dispersão com os parâmetros configurados como p (probabilidade de ganho, q (probabilidade de prejuízo), r (comprimento de cluster de ganho) - contanto que tenhamos um série de testes que combina com o esquema de Bernoulli: a expectativa matemática e a dispersão do tempo de retorno para a série de ganho do comprimento r são correspondentemente iguais a
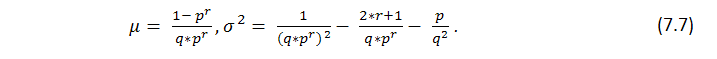
Segue a partir do teorema que com um grande n o número ![]() de r longas séries obtidas em n testes tem aproximadamente uma distribuição normal, ou seja, fixo
de r longas séries obtidas em n testes tem aproximadamente uma distribuição normal, ou seja, fixo ![]() com a probabilidade da inequação
com a probabilidade da inequação
tende a
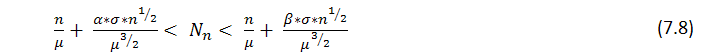
A tabela contém expectativas matemáticas para um número de tempo de retorno típico.
| Comprimento de série, r | p = 0,6 | p=0,5 (moeda) | p=1/6 (dado) |
|---|---|---|---|
| 5 | 30,7 seg. | 1 min. | 2,6 horas |
| 10 | 6,9 min. | 34,1 min. | 28,0 meses |
| 15 | 1,5 horas | 18,2 horas | 18 098 anos |
| 20 | 19 horas | 25,3 dias | 140,7 milhões de anos |
Tabela 1. Tempo de retorno médio para séries de ganho (é realizado um testo por segundo).
Consequência 2: Limitação, desaceleração considerável ou, ao contrário, excesso substancial do cluster prejudicial dependendo do comprimento da série de teste pode apontar para o fato de que o sistema de trading não satisfaz o esquema de Bernoulli. Por exemplo, se no pré-atribuído
Consequência 3: se a hipótese do “Esquema de Bernoulli for verdadeira, tal estratégia não difere do esquema de jogar uma moeda assimétrica com probabilidades correspondentes iguais a p, q = 1-p (ou jogar para cima uma fatia de pão com manteiga).
Agora, vamos analisar algumas estratégias "interessantes" a partir desse ponto de vista.
Scalping (especulação): “Lucky”, Parte 1
Todos, ou quase todos os sistemas de scalping, possuem um número de características comuns:
- SL é muito mais do que TP (valores típicos – 20 e 2; os valores de ponto correspondem às cotações de 4 dígitos de EURUSD);
- p é muito mais do que q (a possibilidade de um trade lucrativo é acima de 80%, às vezes até 99%);
- o número de trades é muito grande e pode somar até dez milhões em um período de um ano.
Não iremos tratar desse terceiro ponto - sendo possível em centros de negociação ou não. Esse tópico é discutido no artigo mencionado acima SK., bem como no fórum. Devemos presumir que um centro de negociação não impede os traders por cotarem novamente, derraparem, intenso MODO_STOPLEVEL e assim por diante.
Um trader que criou um sistema de trading por scalping (TS) está muito frequentemente enganado sobre a frequência dos trades prejudiciais. As raízes dessa ilusão vêm da ideia sobre as características Wiener dos processos de fechamento de preço e a verdadeira característica da fórmula de Einstein para o movimento Browniano: “se estabelecermos SL=20, TP=2, a possibilidade de ativar o stop-loss é (20/2)^2=100 mais baixa do que a possibilidade de atingir TP; portanto tal TS deve ser lucrativo". A ilusão dessa concepção está no fato de que esse processo não é o processo Wiener e as possibilidades correspondentes realmente diferem em muito menos do que 100 vezes.
Exatamente nesse caso, a hipótese do "Esquema de Bernoulli" é bastante provável - apenas porque as estratégias de trading por scalping geralmente tentar usar peculiaridades do processo e do seu filtro aceito em alguns centros de negociação específicos.
Agora vamos tomar os parâmetros da estratégia de trading conhecido por nós sob o nome de "lucky" (https://www.mql5.com/pt/code/7464). Na sua forma original (na mesma seção, Lucky_new.mq4) esse EA é somente um brinquedo, pois dificilmente um centro de negociação aceita a abertura de várias centenas de trades por dia com a expectativa matemática de pontos lucrativos de um rodada one-two Entretanto, você pode simplesmente modificar o código e configurar exigências mais rígidas para o nível TP e ainda, algumas vezes, obter curvas de equilíbrio bastante satisfatórias. O código do EA modificado (levando em conta as restrições no número de trades abertos ao mesmo tempo, que é, no caso, igual a 1; ver explicações abaixo) está anexado a esse artigo.
A vantagem principal desse EA é que ele executa uma quantidade enorme de trades e fornece um material rico para estatísticas - isso será provado adiante. Agora, queremos apenas encontrar evidências que confirmem ou refutem a hipótese: "os resultados de trade concordam com o "Esquema de Bernoulli". Para aqueles que gostam de argumentar sobre a característica não aleatória dos movimentos de mercado, vou especificar: Duvido que os movimentos da cotação sejam sempre aleatórios. Não vou assimilar o mercado (exatamente, mercado!) à moeda girando a la Bachelier; estou interessando apenas na estatística dos resultados de trade - e nada mais. Adiante você verá que algumas configurações de parâmetros externos são intencionalmente escolhidas como "prejudiciais" - apenas para verificar a hipótese afirmada.
Aqui estão os resultados do primeiro teste:
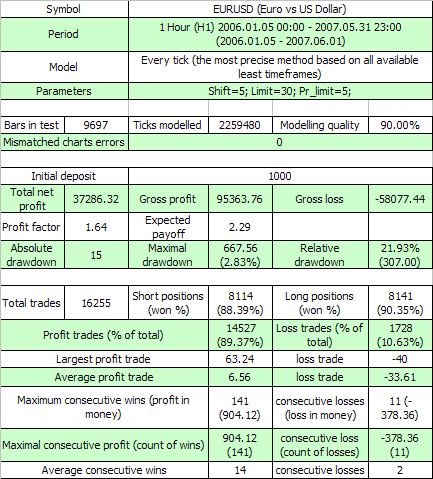
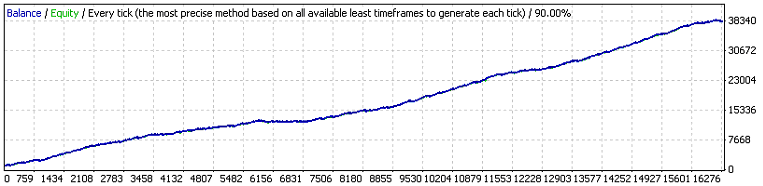
As duas primeiras variáveis externas tem o mesmo significado como no código original, a terceira é um valor de lucros em pontos, que uma ordem deveria exceder para iniciar o evento take profit. Vamos estimar, de acordo com (7,7), a expectativa matemática da série de teste mínima necessária para encontrar os 11 clusters de prejuízos (p=0.8937, q=0.1063, r_loss=11):
N_loss = 1 / (p * q^r_loss) – 1 / p ~ 57 140 275 804
Aqui está a estimativa análoga para a expectativa matemática da série de teste para encontrar os 141 clusters lucrativos:
N_profit = 1 / (q * p^r_profit) – 1 / q ~ 71 685 085
Bem... Como sabemos, o comprimento real da série é igual a somente 16255 trades e não dezenas de bilhões ou milhões. Tal excesso da série real é o sinal de que para esse TS a hipótese do esquema de Bernoulli dificilmente funciona diretamente. Talvez aqui esteja uma influência de um fator que não levamos em conta?
Esquema de Bernoulli: Um resultado interessante
Há um certo fator: um expert adviser (EA) pode abrir muito mais do que um trade por vez: na segunda centena de trades (ordens 158...163) ele abriu 6 trades seguidos (e os fecha em "pilhas" também)! Esse “fator de multiplicação” provavelmente é responsável pelo aumento substancial dos comprimentos de cluster se comparado com os esperados; se o mercado está parado com um volume substancial, o EA começa a abrir muitos trades quase que a cada tick. Entretanto, devido a sua característica de trabalho, por causa do mercado parado e o do tamanho pequeno do take-profit se comparado com o stop-loss, a maioria deles, se não todos, serão fechados como lucrativos. Por outro lado, se um movimento direcionado forte começa, o EA irá abrir muitos trades unidirecionais na direção oposta ao movimento do mercado - e finalmente a maioria deles será fechada como prejuízos e também "massivamente".
Vamos conduzir computações simples. Pegamos ambas as fórmulas para expectativas matemáticas do comprimento das séries de teste completas do parágrafo anterior. Aqui r_loss_real, r_profit_real são os comprimentos reais dos clusters lucrativos e prejudiciais máximos correspondentes. Enquanto os valores N_xxxx obtidos são bem maiores, decepar os segundos termos (1/p e 1/q) não irá praticamente causar nenhum erro, se dividirmos essas igualdades umas pelas outras em relação aos termos:
N_loss / N_profit = q * p ^ r_profit_real / ( p * q ^ r_loss_real ) =
p ^ ( r_profit_real – 1) / q ^ (r_loss_real – 1)
Vamos encontrar o logaritmo e simplificar:
ln( N_loss / N_profit ) = ( r_profit_real – 1 ) * ln( p ) - ( r_loss_real – 1 ) * ln( q )
Agora vamos marcar que, se os testes forem governados pelo esquema de Bernoulli e os comprimentos dos maiores clusters e ambas as possibilidades p e q não forem muito pequenos, N_loss e N_profit valores devem ser aproximadamente iguais. Então, obtemos uma correlação aproximada interessante:
( r_profit_real – 1 ) / ( r_loss_real – 1 ) * ln( p ) / ln( q ) ~ 1 (*)
E se reescrevermos de outra forma:
p ^ ( r_profit_real – 1 ) ~ q ^ ( r_loss_real – 1 )
o significado da correlação (*) se torna claro: no TS Bernoulli (em possibilidades de uma série de teste bem longa e não tão pequena p e q ) as possibilidades de dois clusters com o maior comprimento ("ganhos" e "prejuízos") são praticamente iguais. Na verdade, esse princípio pode ser aplicado a qualquer outro TS que seja não-Bernoulli, mas a forma da correlação (*) é específica para o esquema de Bernoulli. Essa correlação pode ser chamada de um teste duro de uma TS para "bernoullity".
Scalping: "Lucky", Parte 2
Vamos excluir o fator de multiplicação: configure a limitação para o número de ordens abertas ao mesmo tempo para 1. Enquanto o número de ordens é diminuído várias vezes para o mesmo período, iremos estender a faixa de teste e configurá-la a partir de )1 de janeiro de 2004 até) 4 de abril de 2008. Abaixo está a tabela de resultados e alguns cálculos (BS é uma forma abreviada de 'Esquema de Bernoulli (veja análise abaixo); o primeiro + denota uma boa correspondência com o esquema de Bernoulli para clusters lucrativos, o segundo para clusters prejudiciais, "-" é uma hipótese refutada "O sistema satisfaz o BS", ")" significa dúvidas na sua correção):
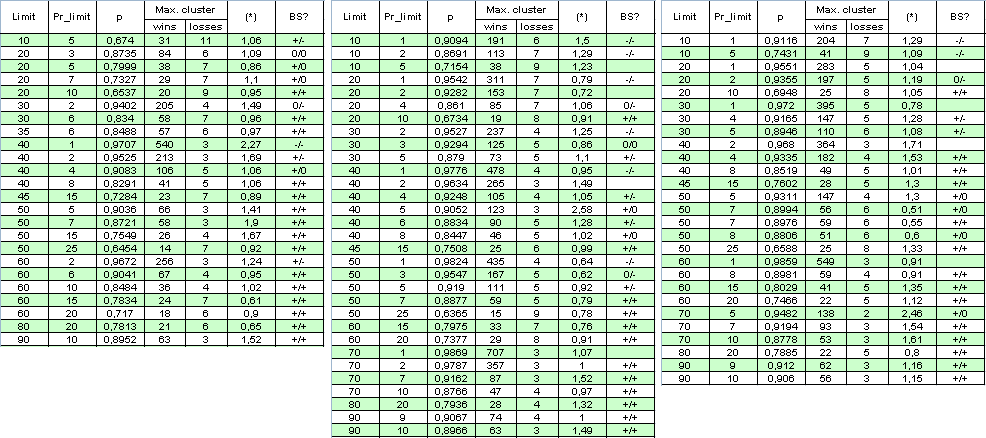
O autor se desculpa pela tamanho grande da tabela, para conseguir a foto completa. O parâmetro (*) parece ser insuficiente para decidir na "bernoullity" do sistema, pois às vezes, até mesmo quando está próximo a 1, o sistema pode ser dificilmente referido ao esquema de Bernoulli.
P.S. Apesar dos fatos de que os multiplicadores em (*) às vezes desviam bastante de 1, os valores (*) ainda estão próximo a 1. Por exemplo, se Limit = 40 e Pr_limit = 1 na segunda coluna, temos:
( * ) = ( 478 - 1 ) / ( 4 - 1 ) * ln( 0.9776 ) / ln( 0,0224 ) ~
477 / 3 * ( -0,02265 ) / ( - 3,7987 ) ~ 0,95
Esse fato, a propósito, nos faz conhecer outra conjetura: até mesmo se a hipótese de Bernoullity do sistema for deferida, a dependência dos trades aqui é "quase a mesma" para lucrativos e prejudiciais.
Critérios de correspondência de um sistema de trading para o esquema de Bernoulli.
Descrição da operação de script
Como podemos dividir mais confiavelmente os resultados dos testes em dois grupos - esquemas Bernoulli e "esquemas não-Bernoulli"? Podemos tentar vários métodos, mas o mais simples, na minha opinião, é o seguinte: se gerarmos várias séries Bernoulli com parâmetros correspondentes àqueles realmente detectados durante o teste, no caso da "Bernoullity" dos sistemas, a probabilidade da função de distribuição (p.d.f) do comprimento do cluster deveria permanecer pouco modificado. Esse fato obviamente resulta da suposição sobre a invariabilidade da probabilidade de ganho e a independência de trades.
Infelizmente, a função teórica de distribuição dos clusters de ganho/prejuízo de acordo com seu comprimento é desconhecida para mim. Acima, incluí algumas fórmulas que permitem estimar a expectativa matemática do número de ganho do cluster na série de teste dependendo do seu comprimento e probabilidade de ganho (veja (7,8) acima). Para esse propósito, Feller ([1]) oferece um método especial que segue a teoria dos eventos recorrentes, aos quais os clusters pertencem. À primeira vista, esse método não se adequa totalmente ao entendimento de um trader do termo "séries de ganho", mas esse método simplifica substancialmente a própria teoria, tanto que a identificação do evento "registro do r-cluster" não depende do futuro ([1], página 302):
Séries de ganho em testes de Bernoulli. O termo "séries de ganho do comprimento r " foi definido por vários métodos. A questão de se a sequência de três ganhos sucessivos deveria ser considerada como contendo 0, 1 ou 2 séries de comprimento 2 é principalmente a questão de conveniência e por vários propósitos aceitamos várias denotações. Entretanto, se quisermos aplicar a teoria dos eventos recorrentes, o significado das séries longas r deveriam ser definidos para que, depois do final das séries, o processo comece novamente a cada vez. Isso significa que deveríamos aceitar a seguinte definição: A sequência n de letras W e L contém tantas r séries longas quanto contém subsequências contínuas, cada uma das quais consistindo em r letras W que ficam juntas. Na sequência de testes Bernoulli, como o resultado de teste n-um novo resultado aparece, iremos dizer que essa série aparece no teste com o número n.
Assim, na sequência WWW|WL|WWW|WWW, há três séries de comprimento 3 que apareceram nos testes 3, 8 e 11; a mesma sequência contém cinco séries de comprimento 2; elas aparecem nos testes 2, 4, 7, 9 e 11. Essa definição simplifica substancialmente a teoria, pois as séries de comprimento fixo se tornam eventos recorrentes. É equivalente à contagem de sequências feitas de pelo menos r ganhos sequenciais com a reserva que 2*r dos ganhos sequenciais são considerados como duas séries, e assim por diante.
Por outro lado, para um trader, os número de clusters de ganho (séries de ganho" por Feller) na fila indicada (WWWWLWWWWWW) será a seguinte: os primeiros cluster-4 de ganhos, então, depois de um prejuízo, cluster-6 de ganhos. Não há clusters "completos" de comprimento 1, 2, 3 e 5 para um trader, embora existam de acordo com Feller. Esse extrato de [1] é publicado aqui somente para indicar a dificuldade do problema. Assim, iremos apenas gerar um número grande de séries Bernoulli e detectar séries nelas, as quais correspondem ao entendimento delas por um trader (15 ganhos em seguida finalizando com um prejuízo não 15 registros de cluster-1 ou 5 registros de clusters-3, de acordo com Feller, mas é apenas um registro de um cluster-15 "verdadeiro". Para verificar a série para "bernoullity", 1000 séries Bernoulli são suficientes.
De acordo com essa ideia, primeiro um script foi escrito, permitindo carregar a sequência de resultados de trades reais em um arranjo e então obtém dados para elaborar um histograma de comprimento de cluster no MS Excel. Esse script também contém as funções que geram séries Bernoulli e preparam os dados para fazer histogramas no MS Excel. Não gostaria de inserir o código de script nesse artigo; em vez disso, farei comentários gerais para o código. O script está anexado abaixo. O arquivo de relatório do testador deveria ser o primeiro posicionado nas sequências dos\arquivos\dos experts\, e seu nome deveria ser movido para os parâmetros do script externo.
No início, na base do arquivo de relatório do testador, com a ajuda da função readIntoArray() os resultados binários de trades (1 or -1) são inseridos em um arranjo global _res[]. Para entender a operação, vamos ilustrar nossas explicações usando um pequeno arranjo. A operação dessa função finalmente resulta no, por exemplo, seguinte arranjo _res[] (o número de trades, ou seja, o comprimento de série, é 50):
1,1,-1,-1,1,1,1,1,1,-1,1,1,1,1,1,1,1,-1,1,1,-1,-1,-1,-1,1,1,1,-1,1,1,1,1,-1,1,-1,1,-1,-1,-1,1, 1,-1,1,1,1,1,1,1,1,1
Depois que a função formClustersArray( int results[], int& sequences[], int& h, int nr ) calcula os comprimentos de clusters e então, dependendo do parâmetro global _what, que define o que estamos interessados - lucros ou prejuízos, escreve comprimentos de séries no arranjo sequences[] (na verdade no arranjo global _seq[]). Vamos contar clusters nesse arranjo:
2,-2,5,-1,7,-1,2,-4,3,-1,4,-1,1,-1,1,-3,2,-1,8
Valores negativos se referem aos clusters prejudiciais. Fica claro que a soma de todos os valores absolutos dos números é igual ao comprimento de série, 50. Suponha que estejamos interessados em prejuízos, ou seja _what = -1. Então, o arranjo _seq[] irá armazenar somente valores negativos, mas com o sinal de "mais":
2,1,1,4,1,1,1,3,1
Depois disso, o arranjo _seq[] é processado com o propósito de construir o arranjo _histogramReal[]. Agora, precisamos apenas calcular as quantidades de clusters-1, -2, -3, etc. e escrevê-los em uma sequência no arranjo. Como resultado, o arranjo _histogramReal[] irá conter os seguintes valores:
6,1,1,1
Isso significa que nossa série contém 6 clusters-1 prejudiciais, 1 cluster-2 prejudicial, 1 cluster-3 prejudicial e 1 cluster-4 prejudicial. Adicionalmente, o último arranjo é escrito no arquivo de saída. O arquivo não é fechado, pois precisamos escrever em "histogramas" análogos de séries sintéticas de testes de acordo com o esquema de Bernoulli.
Ao formar "sintéticas", a função chave é o gerador de um único teste de acordo com o esquema Bernoulli. Apesar desse simples código, ela opera bem: nenhum "efeito de borda" responsável pela distorção da distribuição regular de resultados no segmento [0, 32767] foi observado.
// generates a single Bernoulli test (+-1 with different probabilities) int genBernTest( double probab ) { int rnd = MathRand(); if( rnd < probab * 32767 ) return( _what ); else return( -_what ); }
Depois de uma única chamada de MathSrand( GetTickCount() ), essa função é chamada tantas vezes quanto existam trades no período de teste (_testsTotal). Então, quando temos as séries Bernoulli geradas, os resultados são correspondentemente processados pela contagem de cluster e funções de construção de "histograma". Essas ações são responsáveis pela criação de um histograma correspondendo a uma função de teste genSynthHistogr( int& h, int nr ) ). E, finalmente, a última função é chamada no loop, para que no resultado, o arranjo de séries de Bernoulli seja gerado, histogramas para eles são formados e eles são escritos no arquivo de saída.
Agora podemos abrir esse arquivo no MS Excel, construir diagramas necessários e elaborar conclusões sobre a correspondência do sistema com o esquema de Bernoulli. Números nas linhas do arquivo têm o seguinte significado (a tabela é cortada, e não mostramos aqui os dados dos clusters-5 e outros):
1 9 1639 1058 724 440Número de série de teste Comprimento de cluster máx. Número de clusters-1 Número de clusters-2 Número de clusters-3 Número de clusters-4
0
11
1649
1044
688
478
1
8
1681
1093
675
458
2
13
1628
1067
701
461
3
7
1616
1039
726
474
4
12
1601
1054
699
465
A primeira linha do arquivo (verde) mostra o resultado do teste real , e as linhas abaixo correspondem à série de teste sintética, com o número de início a partir de 0.
E,finalmente, o último estágio - estimativa dos resultados de teste real para a correspondência com o esquema de Bernoulli: a partir das colunas correspondentes das séries sintéticas de Bernoulli são escolhidas para construir um histograma dos comprimentos de clusters necessários, Por exemplo, para construir um histograma de distribuição de quantidade de cluster-1 de ganho, devemos pegar a terceira coluna ((1649, 1681, 1628, 1616, 1601….); a quantidade total de tais números é igual à quantidade de séries de Bernoulli sintéticas. Para os clusters-2 de ganho, pegamos a quarta coluna (1044, 1093, 1067, 1039, 1054…), e assim por diante.
Tais histogramas são construídos de acordo com o método descrito por Bulashev [7] e então verificamos a Hipótese Zero sobre a igualdade do número no teste real para a estimativa de média em séries sintéticas. O nível pré-aceito da significância para a Hipótese Zero, "Número real igual à média para sintéticas, é igual a 0,05 (refere-se a aproximadamente dois desvios padrões).
Primeiros resultados
Vamos começar o script nos resultados de teste do Lucky nos parâmetros 3, 20, 10. Os parâmetros do script: _what = 1 (clusters lucrativos), _globalSeriesQty = 5000. O parâmetro (*) na tabela grande é igual a 1, ou seja, podemos esperar que os resultados da operação do script deveriam mostrar a correspondência com o esquema de Bernoulli. Mostraremos aqui somente os registros de arquivo correspondentes à verificação direta da hipótese Zero para comprimentos de cluster 1-6 (eles são superficialmente corrigidos em uma tabela para percepção mais fácil):
// A primeira linha do arquivo é resultados do teste real feito no testador. As duas primeiras figuras são o número de série e o comprimento de um cluster máximo.
1,20,1639,1058,724,440,271,212,137,91,62,30,26,22,5,7,1,4,1,0,1,1,
...
// Fim do arquivo (parcialmente):

Em cada uma das tabelas 6 de duas linhas, a linha superior corresponde aos valores esquerdos dos intervalos de histograma e a inferior ao número de série de Bernoulli (fora de 5000), na qual os números de clusters de dado comprimento estavam dentro desses intervalos. Abaixo, o mesmo é visualizado graficamente (o número de r-clusters lucrativos em séries de Bernoulli contanto que o número total de séries seja igual a 5000):
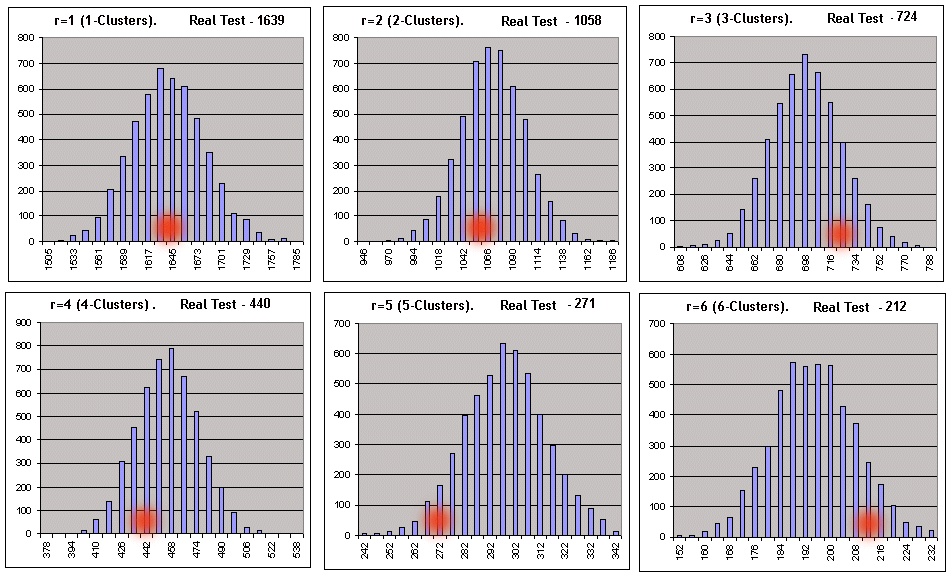
Abcissas de pontos vermelhos correspondem aos números de clusters obtidos no teste real. O mesmo script para clusters prejudiciais (_what = -1) nos mesmos parâmetros também fornece uma boa imagem - com o desconto para o comprimento razoável dos clusters prejudiciais: assim que o número de intervalos calculado de acordo com recomendações em [7] começa a exceder a propagação de dados nas sintéticas, a construção de histogramas com o número configurado de intervalos é possível. Não obstante, zeros formais no relatório do script não deveriam assustar, pois todos os parâmetros necessários podem ser calculados sem um histograma. Nos parâmetros presentes somo para os clusters -3 e -7 a hipótese zero foi rejeitada. Como critérios principais para referência de um sistema testado para o sistema de Bernoulli, um critério bastante duvidoso do tipo fuzzy foi escolhido. Vamos considerar o princípio de tomada de decisão no exemplo dos resultados de operação do script para clusters prejudiciais:
A diferença de um teste real da estimativa de uma média = -0,37 SD (desvio padrão)
A diferença de um teste real da estimativa de uma média = 0,95 SD
A diferença de um teste real da estimativa de uma média = -2,04 SD
A diferença de um teste real da estimativa de uma média = -0,45 SD
A diferença de um teste real da estimativa de uma média = 0.36 SD
A diferença de um teste real da estimativa de uma média = 1,13 SD
A diferença de um teste real da estimativa de uma média = 3,27 SD
A diferença de um teste real da estimativa de uma média = 0,11 SD
A diferença de um teste real da estimativa de uma média = 0,46 SD
A diferença de um teste real da estimativa de uma média = -0,47 SD
Então, aqui está o critério principal:
- Se a média dos modelos de figura não excede 1,5 (aqui é 0,96),
- a édia de figuras não mais do que 1,2 por módulo,
- o número de camadas externas (aqui elas estão em negrito e correspondem ao excesso de diferença 2 SD) não excedem 20% de sua quantidade total,
um sistema é considerado "certamente bernoullian". Se as figuras "críticas" correspondentes são 2, 1, 5 e 30%, o sistema é "sem dúvida "bernoullian". Se as figuras excedem essas fronteiras, a hipótese é refutada. Considero o segundo ponto razoável, pois os desvios não deveriam ser principalmente um sinal.
Os critérios estatísticos da correspondência com esquema de Bernoulli são desconhecidos para mim e é por isso que eu tive que pensar em tais critérios. Os resultados de critérios decisivos improvisados são dados no arquivo de relatório de operação do script. Um leitor interessado pode oferecer critérios decisivos mais razoáveis.
Para esse caso, podemos "concluir com certeza" que o sistema Lucky_ com parâmetros 3, 20, 10 realmente obedece ao esquema de Bernoulli, ou seja, com um esquema de uma fatia de pão com manteiga jogada aleatoriamente.
Agora, vamos pegar um dos "piores" casos e conduzir os mesmo cálculos no número de série de Bernoulli igual a 1000; os parâmetros do Lucky são 5, 10, 1. Vamos considerar clusters-1 lucrativos:
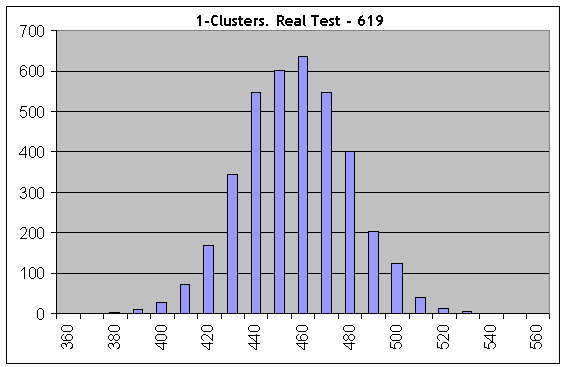
Até mesmo no primeiro histograma, tudo está completamente diferente: resultados de testes reais (619 clusters-1) não batem com as "sintéticas" com o mesmo comprimento de séries de teste e a mesma probabilidade de ganho. Portanto, os trades não são independentes.
Note que os testes de estimativa similares com muitas outras configurações de parâmetros de uma grande tabela permitem concluir que o esquema de Bernoulli ("jogar uma fatia de pão com manteiga) é mais uma regra do que uma exceção. Além disso, há casos onde, para algum grupo de trades (por exemplo, 'trades lucrativos") o esquema de Bernoulli é alcançado e para outro grupo não é. Isso não impede de usar esse modelo pelo menos parcialmente para obter informações úteis, que serão discutidas mais adiante nesse artigo. E a última questão: o critério decisivo não é tão confiável para os clusters prejudiciais por causa da quantidade insuficiente de dados estatísticos, mas apliquei o script para eles também - apenas para obter a imagem completa.
Sistema "Universum": Esquema de Bernoulli novamente!
Agora vamos pegar um sistema totalmente diferente para o nosso estudo - "Universum", seu código fonte está postado em https://www.mql5.com/pt/code/7999. O autor reivindica que o sistema opera nas barras formadas, por isso "todos os ticks" em teste não são necessários, O equilíbrio, no qual o sistema pode reunir estatísticas de trade para o período de 2000.01.01 - 2008.04.04, foi configurado igual a aproximadamente $10M. O primeiro lote aberto é 0,1. Atualmente os três parâmetros modificados são p, tp, sl. Nenhuma multiplicação presente, então o estudo é fácil:
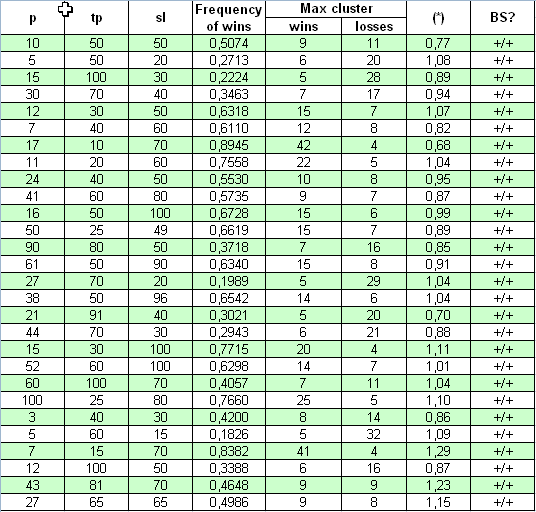
Veja, aqui a conformidade do parâmetro (*) com 1 é muito melhor do que no caso anterior: Os valores (*) diferem superficialmente de um. A verificação com um critério decisivo mostra que, em todos os casos, em uma faixa bastante ampla de parâmetros, esse TS obedece ao esquema de Bernoulli.
Conclusões preliminares
Ralph Vince em [4] oferece outro procedimento de séries de teste verificando a correspondência com o esquema de Bernoulli. Esse é o cálculo de Z-score e teste de resultados de trade para uma correlação especial (autocorrelação de uma fila fonte e uma fila trocada por um). Não sinto que o procedimento dele dê muito mais resultados significantes do que aquele descrito acima (onde o desvio de números de clusters com comprimento diferente em uma série real é verificado vs. uma série modelo) Verdade, o critério decisivo oferecido é mais livre e precisa de alguma fundamentação. Além disso, como notei antes, a confiabilidade dessa verificação em um comprimento curto do cluster máximo não é alta (para o Lucky_ esses são geralmente testes de séries de prejuízo). Entretanto, na minha opinião, embora esse critério decisivo precise de mais cálculos extensivos, é melhor abranger a característica específica da série de teste no contexto da sua conformidade com o esquema de Bernoulli. Essa questão precisa ser estudada mais profundamente e, claro, o assunto ainda não está encerrado.
Não obstante, as expectativas foram provadas: na maioria dos casos, em configurações de parâmetros externos bastante diferentes, a série de trade não corresponde ao esquema de Bernoulli e os desvios do esquema de Bernoulli quase sempre resultam da exploração sistemática de regularidades que são características de processo de filtro de cotações e mais frequentemente inerentes aos sistemas com o valor pequeno de Pr_limit. Isso fica especialmente evidente na tabela grande com os resultados de verificação do Lucky.
As anotações de Vince a respeito da verificação empírica da correlação serial ou do teste Z-score revelaram a dependência entre os trades, então o sistema é subótimo e a dependência deveria ser explicitamente incluída no TS para diminuí-la nos resultados de teste e aumentar a otimização do TS. Assim, colando os resultados de teste dos dois sistemas de lado, devemos admitir que o sistema "Universum" é geralmente melhor do que o sistema "Lucky". Entretanto, isso não justifica o uso do MM no Universum.
Como, possivelmente, usar a Bernoullity do sistema?
1. O que sabemos agora?
Sabendo de antemão que, pelo menos em alguns casos, a sequência de resultados de trade expressados por 1 ("sucesso", ou seja, lucro) e -1 ("fracasso", ou seja, prejuízo) é a Bernoulli, conseguimos um modelo adequado desse processo. Agora, sabemos o suficiente sobre esse processo, pois atualmente essa é a modificação de um movimento Brownian comum com um curso. P. Samuelson introduziu o movimento geométrico Brownian (ou, como ele chamou, econômico) na teoria e prática financeira ([6]):
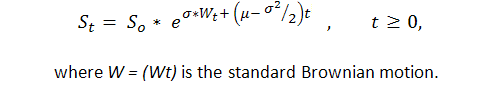
Assim, podemos aplicar resultados mais fortes dos estudos teóricos do movimento padrão Brownian (leis de arcsen, por exemplo) à curva de equilíbrio. Entretanto, a teoria do movimento Brownian é bastante complicada e pode ser entendida somente pelo pequeno número de pessoas com um sólido conhecimento matemático em integração estocástica.
A segunda abordagem é negar a partir das computações altamente teóricas, conduzir geração de programa direta de séries de Bernoulli longas e então, transformá-las em curvas de equilíbrio para "testing MM 0.1 lot". Aqui, precisamos saber somente os valores médios de trades lucrativos e prejudiciais e a frequência de ganho p. Até mesmo várias centenas de tais séries (por exemplo, arranjo-1000 de série de Bernoulli) podem nos dar uma boa ideia do que uma estratégia que obedece o esquema de Bernoulli é capaz.
É importante entender claramente que tal teste sintético é uma boa alternativa para um teste Pardo cansativo ([5]): se soubermos realmente validar a Hipótese Zero ("a sucessão do trade é bernoullian) não é refutada), isso pode nos fornecer informação suficiente sobre o sistema substancialmente diferente daquele dado pela análise walk-forward descrita em [5]. Claro que as curvas de equilíbrio podem diferir muito da curva obtida pelo teste real.
***********
Geralmente, nada impede a implementação de tal abordagem, pois tal teste é realizado em um computador por vários minutos; como resultado obtemos vasta informação que pode ser analisada cuidadosamente. Infelizmente, o volume do artigo não nos permite postar todos os resultados. Aqui estão vários gráficos para o Lucky com parâmetros 4, 70, 10 no mesmo período de teste da tabela acima. A tarefa de gerar esquemas de Bernoulli sintéticos é muito mais fácil do que tarefas realizadas pelo script descrito acima; então meios de MS Excel são suficientes.
Teste real em 0,1:
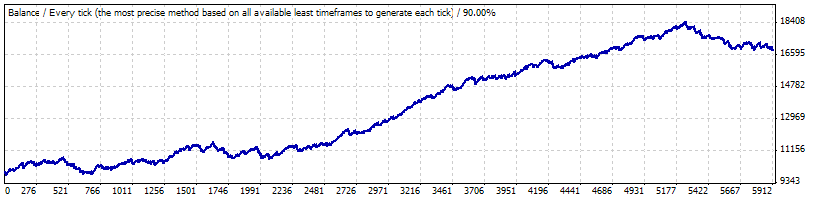
Os seguintes parâmetros do relatório são importante para nós; iremos configurá-los ao gerar séries de Bernoulli e transformar séries em curvas de equilíbrio de mudança:
Frequência de trades lucrativos (p) 0,8765
Média de trade de ganho
11,71
Média de trade prejudicial
-73,73
Quantidade total de trades
5904
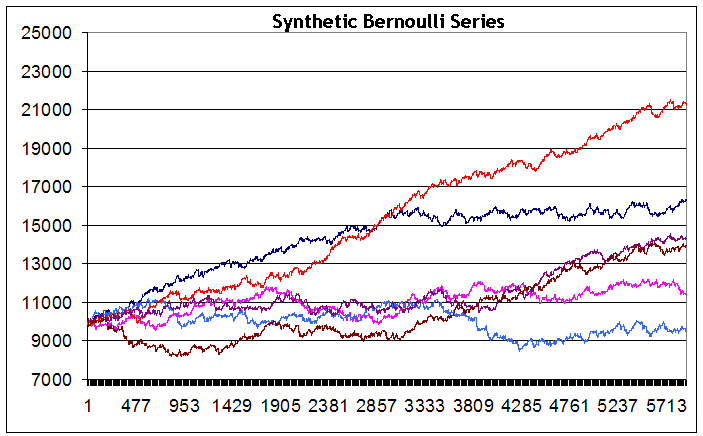
Vemos, apesar do fato de que as séries foram geradas em dados de entrada idênticos, que o resultado do equilíbrio integral no final do período de teste foi consideravelmente diferente de série para série - de um prejuízo pequeno (linha azul) a um prejuízo grande (linha vermelha). Devo admitir que não consegui gerar um série com um equilíbrio evidentemente em queda (embora desejasse alcançar tal gráfico e fiz aproximadamente 200 tentativas). Talvez, em um número grande de séries isso possa ser alcançado. Mas parece que tal caso não é típico dessa estratégia. Além disso, em nenhuma série eu vi baixas maiores do que 2500 pontos.
Agora vamos considerar alguns resultados isolados conectados com a estimativa de alguns parâmetros de uma estratégia que obedece o esquema de Bernoulli.
2. Estimativa de um cluster prejudicial máximo excedendo valores de relatório ("cisne negro")
Tendo recebido evidências da bernoullity do sistema, podemos, de forma realística, estimar o comprimento máximo de um cluster prejudicial que pode nos esperar na mesma quantidade de trades do que no teste real. Aqui, podemos apenas gerar muitas séries Bernoulli e então, estimar as chances de um "cisne negro" real (veja [2,3]) ou seja, tal evento, para o qual nós nunca seríamos capazes de estimar a possibilidade baseados somente nos resultados de teste, pois ele simplesmente não aconteceu no período de teste. É apenas com esse modelo teórico de probabilidade que podemos reunir as estatísticas necessárias para qualquer volume que seja preciso.
Vamos usar os resultados de trading de todos os mesmos sistemas Lucky_ com os parâmetros 4, 50, 7:

De acordo com o relatório, o comprimento do cluster prejudicial máximo é igual a 5. Agora vamos configurar um número muito grande de série Bernoulli, 65000 com o parâmetro _what equal to -1 (cluster prejudicial), e então aplicar nosso script ao relatório do testador. Vamos encontrar a linha mais longa (o primeiro número é um número de série de Bernoulli, o segundo é o comprimento do cluster máximo e então os números de clusters de cada comprimento):
26001 9 1030 136 13 4 0 0 0 0 1
Veja, o comprimento do cluster prejudicial máximo pode ser muito maior do e (aqui é 9)! Talvez seja raro demais em um evento? Verdade, é muito raro: foi encontrado apenas uma vez em 65.000 series, então sua aparência em um teste real pode ser considerada como quase desaparecida, levando em conta "a hipótese de ergodicidade" (veja um pouco maior). Não obstante, essa estimativa de frequência não é muito confiável; portanto você não pode confiar nela: essa série poderia ocorrer, por exemplo, entre somente 20 séries de Bernoulli. Como resultado, se não sabíamos os critérios estatísticos de estimativa de confiabilidade, iriamos erroneamente considerar que essa estimativa tinha alta probabilidade.
Na versão, como eu ofereço isso, "a hipótese de ergodicidade" é a seguinte: a probabilidade de um evento no "espaço de teste sintético" (com base no modelo adequado do evento) é aproximadamente igual à probabilidade do mesmo evento no espaço de tempo, ou seja, para o trading real - contanto que o número de trades nos testes reais seja igual àquele nos testes modelos. É considerado, claro, que a sequência de resultados de trades nos testes reais é estacionária, como o esquema de Bernoulli. Em uma quantidade grande de trades, essa declaração não está longe de ser verdade, pois a única fonte não estacionário aqui pode ser, provavelmente, o conhecido "desvio de ganho" distribuído de acordo com a lei normal e descrito abaixo.
Abaixo está a tabela de números de clusters prejudiciais no arranjo-65000 de séries de Bernoulli:
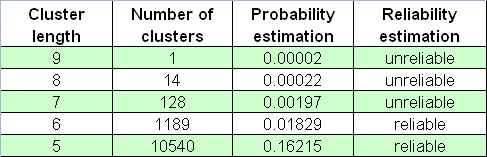
ainda não devemos esquecer os “cisnes negros” que vêm exatamente quando você não espera.
Em contraste com os cálculos acima, podemos usar estimativas para "cisnes negros" de uma característica contrária, a saber clusters lucrativos do comprimento aumentado. Lembramos que o teste real mostra que o comprimento do cluster lucrativo máximo é igual a 59. Adotando o modelo análogo para séries modelo 65,000, encontramos novamente a maior linha no relatório do script:
44118 153 115 117 111 87 70 71 52 51 50 40 36 42 42 34 20 32 15 20 20 13 10 11 12 8 5 7 3 5 4 2 2 6 7 0 2 1 2 1 1 5 0 0 1 0 0 0 0 0 0 1 0 0 2 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
Essa é uma série modelo #44118 com o comprimento de cluster lucrativo máximo igual a 153 trades (segunda figura na lista), aproximadamente 2,6 vezes maior do que o cluster máximo no teste real! Entretanto, as estimativas estatisticamente significantes de frequências de clusters podem ser obtidas no seu comprimento começando a partir de aproximadamente 80 (a probabilidade de estimativa da série é 0,0088) e mais baixa e 80 é muito mais do que 59. A quantidade de meia ordem (o valor do comprimento de cluster no qual a função de distribuição integral obtém o valor de 0,5, ou seja um valor pelo qual a distribuição é dividida em duas partes iguais na área abaixo da função de distribuição de probabilidade de densidade) para clusters lucrativos é aproximadamente 62, ou seja um pouco mais do que 59. O histograma da distribuição do comprimento de cluster máximo no arranjo de séries Bernoulli está incluído aqui para sua referência:
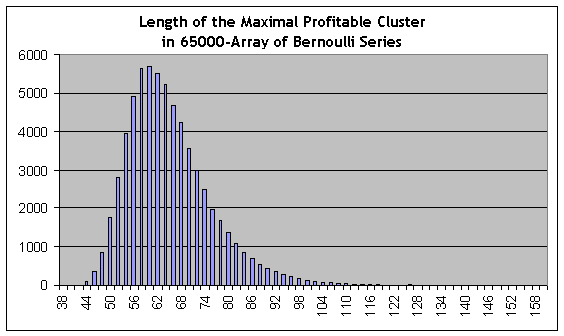
Claro, o termo “cisne negro” é usado aqui com pouco cuidado, pois como na tabela, parece ser um evento cuja probabilidade é incomputável. Não obstante, podemos notar que, julgando apenas pelos dados empíricos (relatório de teste) e não usando modelos teóricos, dificilmente chegaríamos a qualquer conclusão estatisticamente confiável sobre as probabilidades de clusters-6 prejudiciais ou clusters-80 lucrativos, ou seja, para os eventos que não encontramos no relatório!
3. "Desvio de fracasso": Um desvio desfavorável de probabilidade de fracasso a partir da frequência empírica.
Aparato de abordagem, tentativa nº 1
Na grande quantidade de testes nas séries pelo esquema Bernoulli (aproximadamente vários milhares ou isso) a frequência de fracasso f difere superficialmente da probabilidade de fracasso q e obedece o distribuição normal "correta" com uma pequena variação: a lei de números grandes (aqui teorema de Laplace) ainda é eficaz. Não obstante, f também pode desviar e para estratégias de scalping com uma expectativa matemática muito pequena de um trade tal desvio pode ser crítico e é capaz de tornar o sistema e um sistema prejudicial para o intervalo de teste todo. Agora temos facilidades suficientes para a estimativa estatística de chances de tal desvio - se houver uma evidência que prove que o esquema de Bernoulli "funcione" nesse caso.
Infelizmente, o EA Lucky_ até mesmo limitado em suas possibilidades até um trade para um tempo fixo fornece estatísticas demais.
Essa declaração está errada, mas se tornou clara somente depois que o artigo original em Russo foi publicado; não obstante, eu decidi deixar "como está" nessa tradução para torná-la autêntica. -Matemática
Para um desenvolvedor de estratégia sério, isso é mais uma exceção do que uma regra, pois uma pessoa geralmente tem que fazer conclusões sinuosas com base nos resultados de teste contendo várias centenas ou até mesmo dúzias de trades (veja explicação abaixo). O aumento do volume de estatísticas apropriadamente leve à diminuição correspondente da largura da distribuição de Gauss e consideravelmente diminui as chances de desvio maiores do seu valor central.
Como exemplo, vamos considerar o Lucky_ com os parâmetros longe dos favoráveis para o EA: 4, 80, 20, no lote 0,1. Primeiro, vamos conduzir seu teste para o intervalo completo de tempo ("interval A") – de 01 de janeiro de 2004 a 04 de abril de 2008 (EURUSD H1). Aqui está o gráfico de equilíbrio dado pelo relatório:
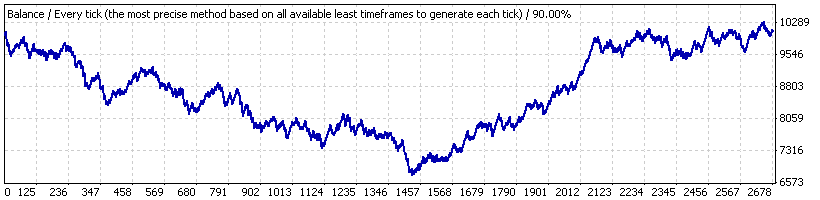
Percebemos que é impressionante. Depois de verificar a sequência de trades com nosso script (nas séries de Bernoulli modelo 1000), encontramos que a série de trade completa pode ser considerada correspondente ao esquema de Bernoulli - ambos para os clusters lucrativos e prejudiciais.
Vamos notar os parâmetros de trades médios:
Trade lucrativo médio
21,71
Trade prejudicial
-83,32
Agora, suponha que testamos o EA somente por um pequeno período de 2005.10.21 a 2007.06.07 ("interval B"), onde a estratégia mostra um crescimento estável. O gráfico está abaixo:
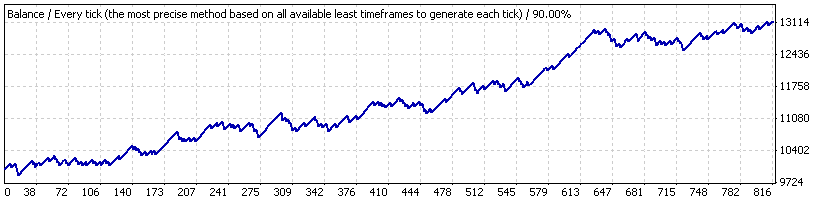
Aqui estão os resultados de trades médios:
| Trade lucrativo médio | 21,69 | Trade prejudicial | -82,94 |
Na média, os trades mudaram muito superficialmente; portanto, eles podem ser considerados aproximadamente invariáveis, irrelevantes para a lucratividade da estratégia para o período de teste. Na verdade, poderíamos ver isso antes, levando em conta que os trades são fechados apenas depois que eles alcançam um certo nível de lucro/prejuízo configurado por parâmetros externos rígidos.
A segunda verificação de expressão para bernoullity (série modelo 1000) confirma novamente sua conformidade com o esquema de Bernoulli. Agora vamos aplicar nosso script com um grande número de séries de Bernoulli (65000) aos resultados de tempo de teste curto (intervalo B), e então importar os resultados das séries modelo de Bernoulli 65000 ao MS Excel para construir o histograma para a distribuição de razões de trades lucrativos
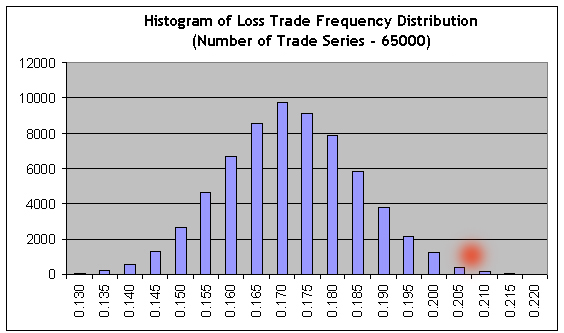
É óbvio que para alcançar o não-lucro, as frequências de lucros e prejuízos deveriam relatar inversamente à razão dos valores médios: r = 21,69/82,94 = 0,2615. Consequentemente, a frequência de trades prejudiciais deveria ser igual a f = r / ( 1+r ) = 0,2073. Vemos que esse valor (veja o ponto vermelho) está localizado longe na área da extremidade direita, onde a soma de barras para a direita é aproximadamente 0,3% da soma de todas as barras de histograma, ou seja a probabilidade de chance de não-lucro/prejuízo é aproximadamente 0,003. Aproximadamente o mesmo valor é obtido no uso direto do teorema de Laplace.
Algo está errado no Reino da Dinamarca: os dados de relatório no intervalo A nos dizem que na primeira metade de A, antes desse intervalo de crescimento, o equilíbrio estava caindo quase que com a mesma velocidade, e o período de queda não é menor do que B assim como o número de trades. Se fizermos uma estimativa da probabilidade de aproximadamente o mesmo intervalo do equilíbrio em queda (prejuízo estável) com base nos nosso dados de teste do intervalo B, ela desaparecerá (porque a frequência de fronteira f será deslocada ainda mais para a direita) e isso parece ser contraditório para os dados experimentais.
Provavelmente, o problema é tal que uma série longa de trades com a lucratividade correspondente ao intervalo B é um desvio muito grande: o teste desde Janeiro de 1999 até o início de Maio de 2008 mostra que essa estratégia não é nem lucrativa e nem prejudicial:
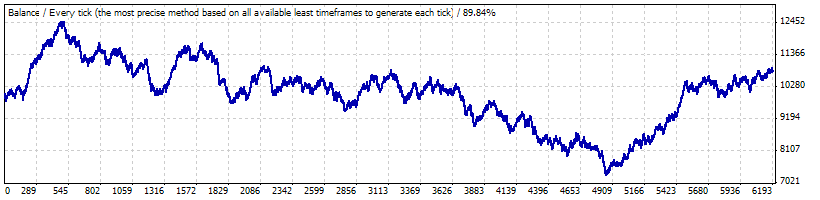
A expectativa matemática de um trade é de apenas 0,17 e a frequência "natural" de trades prejudiciais é aproximadamente igual ao calculado anteriormente f (0.2073) e faz 0,2054.
Fica claro que as estimativas de probabilidade baseadas nas estatísticas de eventos raros (a frequência de trades prejudiciais no intervalo B é igual a 0,1706 e difere da "natural" em aproximadamente 2,8 "sigmas" na direção favorável) não pode ser suficientemente confiável. Mas não podemos saber ao certo a "verdadeira" frequência. Ainda assim, a noção de "desvio de fracasso" pode trazer benefícios para nós?
4. "Desvio de fracasso": Estimativa de probabilidade de baixas de"choque" a curto prazo.
Aparato de abordagem, tentativa nº. 2
Aparentemente, podemos - se configurarmos alvos razoáveis e não extremos correspondentes às "extremidades" das distribuições. Vamos colocar a tarefa dessa forma: suponha que tenhamos os resultados de teste para o intervalo B. Estamos certos de que esse esquema de Bernoulli e as expectativas matemáticas de trades lucrativos e prejudiciais praticamente não dependem do que está acontecendo no equilíbrio. Com base em estimativas muito otimistas (na verdade, falsas!) de probabilidade de prejuízo, vamos tentar estimar nossas chances para baixas de "choque" curtas, mas graves Exatamente, tais baixas tem o efeito mais devastador na mente de um trader, pois depois disso um trader começa a falar frases místicas como "o mercado mudou" ou até mesmo "se tornou um comando".
Deveria adicionar aqui o teorema de Laplace não deveria ser de grande ajuda aqui, pois o valor n*p*q contido na sua fórmula será pequeno, aproximadamente 10 e menos (isso corresponde a aproximadamente várias dúzias de trades). A ideia principal na base desse cálculo é que em cada pequena série de trade a frequência de prejuízos possa suficientemente diferir da "verdadeira", ou seja, a partir da probabilidade: a distribuição da frequência de prejuízo é propagada amplamente por causa do número pequeno de testes.
Note que a estimativa de uma baixa a curto-prazo é a tarefa que mais difere do problema de estimar o comprimento máximo de um cluster prejudicial, pois uma baixa não necessariamente consiste somente em trades prejudiciais. Vamos usar nosso script para gerar séries 65000 de comprimento 40 em um frequência "muito favorável" de prejuízos 0,1706 ("intervalo B"), e então elaborar o histograma como aquele do aparato de abordagem, tentativa nº1:
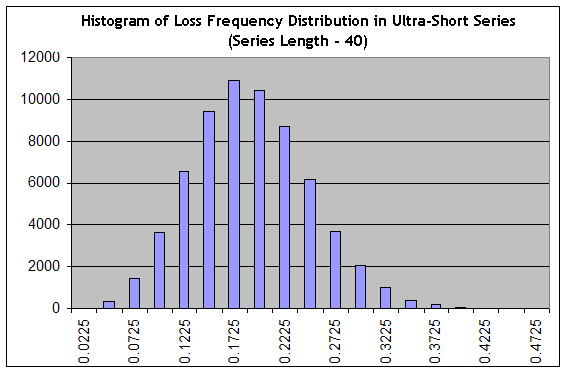
Vemos que a configuração mudou crucialmente: a distribuição passou de afiada para suave, ou seja sua "largura relativa" aumentou. A probabilidade que em séries de tamanho 40 iremos obter algo na faixa de trading praticamente sem lucro (ou seja, na frequência de trades prejudiciais igual a 0,1975, um trade médio faz 0,25 pontos) a um trading altamente prejudicial (na frequência de trades prejudiciais 0,3000, a estimativa de uma expectativa matemática de trade na série é igual a 0,7*20-0,3*80=-10 pontos), é igual à soma de colunas a partir da coluna "0,2225" e à direita dela, que é aproximadamente 34% da soma total de colunas (65000). Tudo o mesmo, essa é uma estimativa otimista, pois o pico de distribuição está na frequência "otimista" 0,1706!
Trazendo à mente a hipótese de ergodicidade, que é colocar uma ponte entre a distribuição de probabilidade e o espaço de trading, ou seja, o espaço de tempo real, obtemos que, em pelo menos 34% do tempo de trading o sistema não terá lucro ou prejuízo na média. Essa figura correlaciona-se bem com os dados em [4], de acordo com o qual o sistema de Bernoulli permanece em baixa aproximadamente de 35 a 55% de todo o tempo de trading.
Preste atenção ao fato de que a probabilidade real de encontrar uma baixa de choque não depende totalmente da frequência inicial "favorável", não importa o quão atrativa pareça. Essa é a característica principal do sistema, que é conectada com sua bernoullity e esse vento pode ser amenizado somente pela razão aumentada de resultados de trade lucrativos e prejudiciais.
A propósito, exatamente essas estimativas com base na geração de séries ultrapequenas permitem com muita frequência e confiança, modificar os resultados de teste de um sistema bastante "lucrativo" com apenas algumas dúzias de trades no intervalo de teste: apesar de uma "expectativa matemática" positiva de um trade, com tão poucos números de trades as baias de "choque" são inevitáveis, no caso da bernoullity do sistema.
Conclusão
Apesar do fato de que gostamos de elaborar construções lógicas orgulhosamente chamadas de “Sistemas de trading mecânicos”, geralmente não percebemos o quanto de aleatoriedade elas contêm - incluindo aquela que não precisamos encontrar nos resultados de teste (cisnes negros").
Como os resultados de trades sucessivos expressaram na anotação binária (”sucesso” ou “fracasso” com muita frequência obedecem o esquema de Bernoulli, elas não têm nenhuma diferença expressa a partir de jogar uma fatia de pão com manteiga. Claro, isso não significa que sistemas lucrativos são impossíveis: uma estratégia pode ser lucrativa e robusta, até mesmo se ela idealmente obedece o esquema de Bernoulli. Isso claramente resulta da ideia que se, ambas, a probabilidade de um trade lucrativo e sua expectativa matemática são altamente estáveis do que aquelas de um trade prejudicial, a estratégia é obviamente lucrativa.
Um leitor que, pelo menos às vezes, é capaz de se "comunicar" com a matemática como um "relativo" deveria entender o benefício de modelos bem - até mesmo se eles estiverem longe de serem deterministas. O valor principal dos modelos que são adequados para o fenômenos estatísticos real é que eles permitem obter um conhecimento valioso sobre o universo - ou seja, a informação que não pode ser obtida diretamente da escassez dos dados experimentais . Nesse caso, o valor do esquema de Bernoulli é consideravelmente alto por causa da simplicidade da sua geração e ausência de "extremidade grossa" em distribuições de probabilidade chave.
Vamos terminar esse artigo com um questão muito difícil: provavelmente, a parte analítica da maioria dos TS é inútil e a maioria dos esforços devem ser investidos em métodos eficientes e bem estruturados de gerenciamento de dinheiro ("A analítica não é nada, o gerenciamento de dinheiro é tudo!"), não é?
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/1530
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 O show deve continuar, ou Mais uma vez sobre o ZigZag
O show deve continuar, ou Mais uma vez sobre o ZigZag
 Modificação de dois estágios de posições abertas
Modificação de dois estágios de posições abertas
 Integrando o terminal do cliente do MetaTrader 4 com o MS SQL SERVER
Integrando o terminal do cliente do MetaTrader 4 com o MS SQL SERVER
 Interação entre o MetaTrader 4 e Matlab via DDE
Interação entre o MetaTrader 4 e Matlab via DDE
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso