
Redes neurais de maneira fácil (Parte 52): exploração com otimização e correção de distribuição

Introdução
Um dos elementos fundamentais para aumentar a estabilidade do treinamento da função Q é o uso do buffer de reprodução de experiências. Aumentar o buffer permite coletar mais exemplos variados de interação com o ambiente, o que, em geral, permite que nosso modelo estude e reproduza mais eficazmente a função Q do ambiente. Esta técnica é amplamente utilizada em vários algoritmos de aprendizado por reforço, incluindo os algoritmos da família Ator-Crítico.
No entanto, há um revés. Durante o treinamento, as ações do Ator cada vez mais se diferenciam dos exemplos salvos no buffer de reprodução de experiências. E quanto mais iterações de atualização dos parâmetros do modelo, maior essa diferença, levando à diminuição da eficácia do treinamento da política do Ator. Uma solução para esse problema foi apresentada no artigo "https://arxiv.org/abs/2110.12081Off-policy Reinforcement Learning with Optimistic Exploration and Distribution Correction" (outubro de 2021). Os autores do método propuseram a adaptação do método DICE (Distribution Correction Estimation) ao algoritmo Soft Actor-Critic.
Além disso, os autores do método chamaram a atenção para outro aspecto. Durante o treinamento, a política do método Soft Actor-Critic utiliza a menor avaliação das ações. A experiência prática desse enfoque demonstra uma tendência para uma exploração insuficiente e pessimista do ambiente e para uma uniformidade direcionada das ações. Para minimizar esse efeito, os autores do artigo propuseram treinar adicionalmente um modelo exploratório otimista do Ator. Isso, por sua vez, aumenta ainda mais o descompasso entre os exemplos de interação do modelo otimista do Ator com o ambiente e a distribuição das ações do modelo-alvo em treinamento.
No entanto, o uso conjunto da correção de estimativas de distribuição e da exploração do modelo otimista do Ator permite melhorar o resultado do treinamento do modelo-alvo.

1. Exploração com otimismo
Vale mencionar que as primeiras ideias sobre a exploração do ambiente com otimismo foram publicadas no artigo Exploration with Optimistic Actor-Critic" (outubro de 2019). Foram seus autores que destacaram que a combinação da atualização gananciosa do ator com a avaliação pessimista do crítico leva à evitação de ações sobre as quais o agente não sabe. Esse fenômeno foi denominado "subexploração pessimista". Além disso, a maioria dos algoritmos não é informada sobre a direção da exploração. As ações amostradas aleatoriamente têm a mesma probabilidade de estar em lados opostos do valor médio atual. Enquanto normalmente precisamos de ações tomadas em certas direções muito mais do que em outras. Para corrigir esses fenômenos, foi proposto o algoritmo Ator-Crítico Otimista (OAC), que aproxima os limites inferior e superior de confiança da função de valor estado-ação. Isso permitiu o uso do princípio do otimismo na incerteza da execução da exploração direcionada, utilizando o limite superior. Ao mesmo tempo, o limite inferior ajuda a evitar a superestimação das ações.
Os autores do método discutido neste artigo adotaram e desenvolveram as ideias do Ator-Crítico Otimista. Assim como no Soft Actor-Critic, treinaremos 2 modelos de Críticos. Mas, ao mesmo tempo, também ensinaremos dois modelos de Ator: a exploração πe e o alvo πt.
A política πe é treinada para maximizar a aproximação do limite superior dos valores da função Q, QUB. Simultaneamente, πt, no processo de treinamento, maximiza a aproximação do limite inferior da função Q, QLB. O OAC mostra que a exploração usando πe permite um uso mais eficiente da amostra em comparação com o Soft Actor-Critic.
Para obter a aproximação do limite superior da função Q, QUB, primeiro são calculados o valor médio e a dispersão das avaliações de ambos os Críticos:
![]()
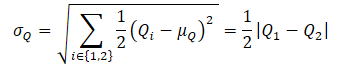
Em seguida, determinamos QUB pela fórmula:
![]()
onde βUB ∈ R e controla o nível de otimismo.
Note que o anterior limite inferior aproximado da função Q, QLB, pode ser expresso como
![]()
Com um nível de pessimismo βLB = 1, QLB é igual à menor das avaliações dos Críticos.
No Ator-Crítico Otimista, aplica-se uma restrição de máxima divergência KL entre πe e πt, o que permite obter uma solução fechada para πe e estabiliza o treinamento. Ao mesmo tempo, isso limita o potencial de πe em realizar ações mais informativas que potencialmente podem corrigir avaliações falsas dos críticos. Como essa restrição não permite que πe gere ações que sejam muito diferentes das geradas pela política πt, que é treinada conservadoramente com base na avaliação mínima dos críticos.
No algoritmo SAC+DICE, a adição da correção de distribuições permite abandonar o uso da restrição KL para explorar todas as possibilidades da política otimista. Ao mesmo tempo, a estabilidade do treinamento é mantida através da correção explícita da avaliação enviesada do gradiente durante o treinamento da política.
O processo de aprendizado da política comportamental do Ator πт usa o limite inferior aproximado do QLB como um crítico para evitar a superestimação da função Q, como no método Soft Actor-Critic. Porém, adiciona-se a correção da distribuição de amostras usando a relação dπт(s,a)/dD(s,a). Obtemos o seguinte objetivo de treinamento:
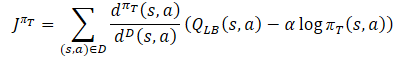
onde dπт(s,a) representa a distribuição estado-ação da política atual, e dD(s,a) é a distribuição estado-ação do buffer de reprodução de experiências. O gradiente de tal objetivo de treinamento fornece uma avaliação não enviesada do gradiente da política, diferentemente dos algoritmos anteriores de treinamento Ator-Crítico, que usavam uma avaliação enviesada no treinamento da política-alvo.
A política de exploração πе deve estudar o viés otimista em relação aos valores estimados da função Q, a fim de coletar experiências para a correção eficaz de avaliações falsas. Por isso, os autores do método sugeriram usar a aproximação do limite superior, similar ao Ator-Crítico Otimista QUB, como Crítico na função objetivo. O objetivo final da política πe e a melhor avaliação da função Q é facilitar uma avaliação mais precisa do gradiente para a política-alvo πt. Portanto, a distribuição de amostragem para a função de perda de πe deve estar alinhada com a política comportamental πt. Como consequência, os autores do método propõem usar o mesmo fator de correção que para a função de perda da política-alvo do Ator.
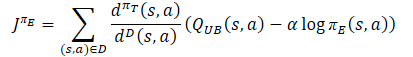
Quanto aos Críticos, mantém-se a abordagem anteriormente considerada no Soft Actor-Critic. E para o treinamento deles, utiliza-se o limite inferior da função Q dos modelos-alvo. No entanto, há uma série de pesquisas que comprovam a eficácia do uso das mesmas amostras para treinar Atores e Críticos. Consequentemente, um fator de correção de distribuição também foi adicionado à função de perda dos Críticos.
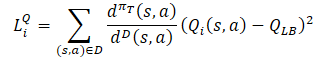
Como se pode notar, de tudo o que foi descrito acima, o fator de correção de distribuição é o que gera mais questões. Sobre ele, a continuação do nosso artigo.
2. Correção de distribuição
A família de algoritmos Estimação de Correção de Distribuição (DICE) se destina a resolver o problema de correção de avaliação sem interferência (Off-Policy Evaluation - OPE). Esses métodos permitem treinar um estimador do valor da política, ou seja, a recompensa esperada normalizada para um passo, com base em um buffer estático de repetição D. O DICE obtém um estimador não enviesado, avaliando o fator de correção de distribuição.
![]()
Para avaliar o fator de correção de distribuição, os autores do método adaptaram o esquema de otimização DICE, que pode ser formulado como um programa linear minimax de distribuição com diferentes regularizações. A aplicação direta dos algoritmos DICE às configurações de aprendizado por reforço fora da política apresenta consideráveis dificuldades de otimização. O treinamento com avaliação sem interferência pressupõe uma política-alvo fixa e um buffer estático de repetição com cobertura suficiente do espaço estado-ação, enquanto no RL a política-alvo e o buffer de reprodução de experiências mudam durante o treinamento. Por isso, os autores do método SAC+DICE introduzem várias modificações para superar essas dificuldades. Não vamos nos aprofundar na matemática e na análise dessas modificações agora. Qualquer pessoa interessada pode encontrá-las no original статье. Vamos apenas apresentar as funções de perda resultantes das modificações propostas.
![]()
![]()
![]()
Aqui ζ(s,a) e v(s,a) são modelos de redes neurais, e λ é um coeficiente de Lagrange ajustável. ζ(s,a) aproxima o fator de correção de distribuição. E v(s,a) atua como uma espécie de crítico. Para estabilizar o processo de treinamento, semelhante ao Crítico, usaremos um modelo-alvo v com atualização suave dos seus parâmetros.
Para otimizar todos os parâmetros, os autores sugerem o uso do método Adam.
Tudo o que foi dito acima é sintetizado em um algoritmo único, o SAC+DICE. Como nos algoritmos convencionais de aprendizado por reforço fora da política, interagimos sequencialmente com o ambiente, seguindo a política otimista de exploração πe, e armazenamos os dados no buffer de reprodução de experiências. Em cada etapa de treinamento, o algoritmo em questão primeiro atualiza os modelos e parâmetros do DICE (v, ζ, λ) usando o SGD em relação às funções de perda mencionadas acima.
Após isso, calculamos a relação de correção de distribuição ζ a partir do modelo atualizado.
Então, usando ζ, realizamos o treinamento de RL para atualizar πт, πе, Q1 e Q2.
Ao final de cada etapa de treinamento, é realizada uma atualização suave dos modelos-alvo Q1, Q2 e v.
3. Implementação usando MQL5
Ao ler a parte teórica, você deve ter notado o aumento acentuado no número de modelos treináveis e parâmetros. De fato, o número de modelos treináveis aumentou de 3 para 6. O processo de interação entre eles se complica. Ao mesmo tempo, esperamos obter um único modelo de política comportamental do Ator como resultado. Para ocultar todo o trabalho de rotina do usuário, mudaremos um pouco nossa abordagem e encapsularemos todo o processo de treinamento em uma classe separada, CNet_SAC_DICE. Nossa nova classe será uma herdeira da classe base de modelos de redes neurais, CNet. No corpo da classe, declararemos 5 modelos treináveis e 3 modelos-alvo. Também declararemos uma série de variáveis internas, cujas funcionalidades conheceremos durante a implementação.
class CNet_SAC_DICE : protected CNet { protected: CNet cActorExploer; CNet cCritic1; CNet cCritic2; CNet cTargetCritic1; CNet cTargetCritic2; CNet cZeta; CNet cNu; CNet cTargetNu; float fLambda; float fLambda_m; float fLambda_v; int iLatentLayer; //--- float fLoss1; float fLoss2; float fZeta; //--- vector<float> GetLogProbability(CBufferFloat *Actions); public: //--- CNet_SAC_DICE(void); ~CNet_SAC_DICE(void) {} //--- bool Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer = -1); //--- virtual bool Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &ActionsLogProbab, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float reward, float discount, float tau); virtual void GetLoss(float &loss1, float &loss2) { loss1 = fLoss1; loss2 = fLoss2; } //--- virtual bool Save(string file_name, bool common = true); bool Load(string file_name, bool common = true); };
Note-se que inicialmente falamos sobre 6 modelos treináveis, mas apenas 5 foram declarados. Entre os modelos declarados, falta a política-alvo do Ator. No entanto, o objetivo de todo o processo de treinamento é justamente obter essa política. O ponto é que nossa nova classe, conforme mencionado anteriormente, é uma herdeira da classe base da rede neural. Isso significa que ela mesma é um modelo treinável. Portanto, o treinamento da política principal do Ator será realizado com as ferramentas da classe pai.
Também é importante mencionar que a nova classe CNet_SAC_DICE será usada apenas para o treinamento do modelo. Durante a operação, não faz sentido criar objetos de modelos adicionais, pois isso resultaria em consumo desnecessário de recursos. Por isso, planejamos usar os objetos básicos dos modelos durante a operação. Em vista disso, a nova classe não possui métodos de propagação e retropropagação. Todo o funcional será implementado no método Study.
E, claro, há métodos para trabalhar com arquivos Save e Load. Mas vamos abordar isso em ordem.
No construtor da classe, inicializamos as variáveis internas com valores iniciais. Todos os objetos internos são declarados estaticamente e não requerem inicialização. Portanto, não há necessidade de limpar a memória no destruidor, o que permite deixá-lo vazio.
CNet_SAC_DICE::CNet_SAC_DICE(void) : fLambda(1.0e-5f), fLambda_m(0), fLambda_v(0), fLoss1(0), fLoss2(0), fZeta(0) { }
A inicialização completa dos modelos é realizada no método Create. Nos parâmetros do método, passaremos arrays dinâmicos que descrevem a arquitetura de todos os modelos usados e o identificador da camada latente do Ator com a representação compactada do estado analisado do ambiente.
No corpo do método, primeiro criamos os modelos dos Atores. O modelo otimista é criado no objeto cActorExploer, enquanto o modelo-alvo é criado no corpo da nossa classe, utilizando os meios herdados.
bool CNet_SAC_DICE::Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer) { ResetLastError(); //--- if(!cActorExploer.Create(actor) || !CNet::Create(actor)) { PrintFormat("Error of create Actor: %d", GetLastError()); return false; } //--- if(!opencl) { Print("Don't opened OpenCL context"); return false; }
Imediatamente verificamos o ponteiro do contexto OpenCL criado.
Em seguida, criamos os modelos treináveis dos dois Críticos.
if(!cCritic1.Create(critic) || !cCritic2.Create(critic)) { PrintFormat("Error of create Critic: %d", GetLastError()); return false; }
Depois, os objetos do bloco DICE e os modelos-alvo.
if(!cZeta.Create(zeta) || !cNu.Create(nu)) { PrintFormat("Error of create function nets: %d", GetLastError()); return false; } //--- if(!cTargetCritic1.Create(critic) || !cTargetCritic2.Create(critic) || !cTargetNu.Create(nu)) { PrintFormat("Error of create target models: %d", GetLastError()); return false; }
Após a criação bem-sucedida de todos os modelos, os transferimos para um único contexto OpenCL.
cActorExploer.SetOpenCL(opencl); cCritic1.SetOpenCL(opencl); cCritic2.SetOpenCL(opencl); cZeta.SetOpenCL(opencl); cNu.SetOpenCL(opencl); cTargetCritic1.SetOpenCL(opencl); cTargetCritic2.SetOpenCL(opencl); cTargetNu.SetOpenCL(opencl);
E copiamos os parâmetros dos modelos para suas cópias-alvo, assegurando o controle da execução das operações em cada etapa.
if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), 1.0) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), 1.0) || !cTargetNu.WeightsUpdate(GetPointer(cNu), 1.0)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; }
Após a criação bem-sucedida de todos os objetos necessários, transferimos os dados para as variáveis internas e finalizamos o trabalho do método.
fLambda = 1.0e-5f; fLambda_m = 0; fLambda_v = 0; fZeta = 0; iLatentLayer = latent_layer; //--- return true; }
Depois de inicializar os objetos internos da classe, passamos a trabalhar no método de treinamento do modelo CNet_SAC_DICE::Study. Nos parâmetros desse método, recebemos todas as informações necessárias para um passo de treinamento do modelo. Aqui estão o estado atual e subsequente do ambiente, cada um descrito em dois buffers de dados: dados históricos e estado do saldo. Aqui também veremos o buffer de ações e a variável de recompensa. Também há variáveis para os coeficientes de desconto e atualização suave dos modelos-alvo. Pela primeira vez, adicionamos um vetor de logaritmos da probabilidade da política original (usada na coleta de exemplos).
bool CNet_SAC_DICE::Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &ActionsLogProbab, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float reward, float discount, float tau) { //--- if(!Actions || Actions.Total()!=ActionsLogProbab.Size()) return false;
No corpo do método, primeiro organizamos um pequeno bloco de controle, no qual verificamos a atualidade do ponteiro para o buffer de ações e se seu tamanho corresponde ao tamanho do vetor de logaritmos de probabilidades. Não verificamos os ponteiros para os outros buffers, pois seu controle é implementado nos métodos chamados.
Após passar com sucesso pelo bloco de controle, realizamos estimativas do estado subsequente pelos modelos-alvo, levando em conta a política atual. Para isso, primeiro realizamos uma propagação com nossa política conservadora do Ator. Usamos isso para o pré-processamento dos dados brutos que descrevem o estado atual e para prever o vetor de ações a partir desse estado. Os dados obtidos são então passados para os 2 modelos-alvo dos Críticos e o modelo v do bloco DICE.
if(!CNet::feedForward(NextState, 1, false, NextSecondInput)) return false; if(!cTargetCritic1.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1) || !cTargetCritic2.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false; //--- if(!cTargetNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false;
O próximo passo é preparar os dados do estado atual. Assim como para o estado subsequente, usamos o modelo atual da política conservadora do Ator para o pré-processamento da descrição do estado atual.
if(!CNet::feedForward(State, 1, false, SecondInput)) return false; CBufferFloat *output = ((CNeuronBaseOCL*)((CLayer*)layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite();
Aqui, realizamos um pequeno truque com a substituição dos resultados da propagação. Em vez das ações obtidas pela política atual do Ator, salvamos no buffer de resultados o tensor de ações do buffer de reprodução de experiências no último neurônio da camada. O objetivo desta operação é manter a correspondência entre a ação e a recompensa do ambiente. Sim, reconhecemos que durante a propagação, é provável que tenham sido formadas ações diferentes. Mas nossa camada neuronal CNeuronSoftActorCritic, no âmago de seus objetos internos, estuda a distribuição de ações e suas probabilidades. E durante a retropropagação, serão definidos os quantis e probabilidades correspondentes às ações do buffer de reprodução de experiências. Com isso, o gradiente imparcial passará exatamente nesses quantis, permitindo treinar o modelo do Ator de forma mais precisa e sem distorções.
Após a preparação dos dados do estado atual do ambiente, podemos realizar a propagação dos modelos do bloco DICE. E, claro, não esquecemos de controlar o processo de execução das operações.
if(!cNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false; if(!cZeta.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false;
De acordo com o algoritmo SAC+DICE, inicialmente realizamos a atualização dos modelos e parâmetros do bloco DICE. Mas, antes de atualizar os parâmetros, precisamos calcular os valores das funções de perda para v, ζ, λ.
Note que, para obter o valor das funções de perda, precisamos do valor-alvo da relação de probabilidades estado-ação na política conservadora atual e na interação com o ambiente durante a coleta da base de exemplos. Aqui, é importante mencionar que os dados históricos da descrição do estado do ambiente não dependem da política do Ator. Além disso, o estado atual é percebido como um ponto de partida para a tomada de decisão e construção da trajetória de ações subsequente. Portanto, a probabilidade do estado inicial é percebida como igual a 1, já que nos encontramos nele.
No processo de treinamento da política, o que muda é apenas a distribuição probabilística das ações de acordo com a estratégia aprendida. Portanto, nosso valor-alvo será a relação das probabilidades de ações nas duas políticas. Durante as operações, em vez da relação de probabilidades, usaremos a diferença dos logaritmos das probabilidades. Em vez de multiplicar as probabilidades de todas as ações, usaremos a soma de seus logaritmos, restaurando o valor por meio da exponencial.
vector<float> nu, next_nu, zeta, ones; cNu.getResults(nu); cTargetNu.getResults(next_nu); cZeta.getResults(zeta); ones = vector<float>::Ones(zeta.Size()); vector<float> log_prob = GetLogProbability(output); float policy_ratio = MathExp((log_prob - ActionsLogProbab).Sum()); vector<float> bellman_residuals = next_nu * discount * policy_ratio - nu + policy_ratio * reward; vector<float> zeta_loss = zeta * (MathAbs(bellman_residuals) - fLambda) * (-1) + MathPow(zeta, 2.0f) / 2; vector<float> nu_loss = zeta * MathAbs(bellman_residuals) + MathPow(nu, 2.0f) / 2.0f; float lambda_los = fLambda * (ones - zeta).Sum();
Após determinar os valores das funções de perda, definiremos os gradientes de erro e atualizaremos os parâmetros. Primeiro, atualizamos os valores do coeficiente de Lagrange. Durante o ajuste do parâmetro, usamos o algoritmo do método Adam.
//--- update lambda float grad_lambda = (ones - zeta).Sum() * (-lambda_los); fLambda_m = b1 * fLambda_m + (1 - b1) * grad_lambda; fLambda_v = b2 * fLambda_v + (1 - b2) * MathPow(grad_lambda, 2); fLambda += lr * fLambda_m / (fLambda_v != 0.0f ? MathSqrt(fLambda_v) : 1.0f);
Em seguida, precisamos atualizar os parâmetros dos modelos v, ζ. É importante dizer que determinamos os valores das funções de perda, não os valores-alvo. Além disso, a função de perda para cada modelo é individual e muito diferente das que usamos anteriormente. Agora, não vamos adaptar as operações à função de perda básica do nosso modelo. Em vez disso, calcularemos diretamente o gradiente do erro. Transferiremos o valor obtido para o buffer correspondente do modelo e distribuiremos o gradiente do erro pelos parâmetros do modelo.
Primeiro, atualizamos os parâmetros do modelo v.
//--- CBufferFloat temp; temp.BufferInit(MathMax(Actions.Total(), SecondInput.Total()), 0); temp.BufferCreate(opencl); //--- update nu int last_layer = cNu.layers.Total() - 1; CLayer *layer = cNu.layers.At(last_layer); if(!layer) return false; CNeuronBaseOCL *neuron = layer.At(0); if(!neuron) return false; CBufferFloat *buffer = neuron.getGradient(); if(!buffer) return false; vector<float> nu_grad = nu_loss * (zeta * bellman_residuals / MathAbs(bellman_residuals) + nu); if(!buffer.AssignArray(nu_grad) || !buffer.BufferWrite()) return false; if(!cNu.backPropGradient(output, GetPointer(temp))) return false;
Depois, realizamos operações semelhantes para o modelo ζ.
//--- update zeta last_layer = cZeta.layers.Total() - 1; layer = cZeta.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; vector<float> zeta_grad = zeta_loss * (zeta - MathAbs(bellman_residuals) + fLambda) * (-1); if(!buffer.AssignArray(zeta_grad) || !buffer.BufferWrite()) return false; if(!cZeta.backPropGradient(output, GetPointer(temp))) return false;
Nesta etapa, atualizamos os parâmetros do bloco DICE e passamos diretamente para o procedimento de treinamento por reforço. Primeiro, realizamos a propagação de ambos os Críticos. Neste caso, não realizamos a propagação do Ator, pois já executamos essa operação ao atualizar os parâmetros dos objetos do bloco DICE.
//--- feed forward critics if(!cCritic1.feedForward(GetPointer(this), iLatentLayer, output) || !cCritic2.feedForward(GetPointer(this), iLatentLayer, output)) return false;
Em seguida, assim como na atualização dos parâmetros do DICE, determinaremos os valores das funções de perda. Mas primeiro realizaremos um pequeno trabalho preparatório. Para aumentar a estabilidade do treinamento do modelo, normalizaremos o fator de correção de distribuição e calcularemos o valor de referência previsto pelos modelos-alvo dos críticos, levando em conta a política atual do Ator.
vector<float> result; if(fZeta == 0) fZeta = MathAbs(zeta[0]); else fZeta = 0.9f * fZeta + 0.1f * MathAbs(zeta[0]); zeta[0] = MathPow(MathAbs(zeta[0]), 1.0f / 3.0f) / (10.0f * MathPow(fZeta, 1.0f / 3.0f)); cTargetCritic1.getResults(result); float target = result[0]; cTargetCritic2.getResults(result); target = reward + discount * (MathMin(result[0], target) - LogProbMultiplier * log_prob.Sum());
Apesar da existência de um valor-alvo, não podemos realizar o método básico de retropropagação dos modelos dos críticos, pois o uso do fator de correção de distribuição não se encaixa nele. Portanto, aplicamos o método já elaborado de cálculo do gradiente de erro e sua transferência direta para o buffer da camada de resultados neuronais, seguida pela distribuição dos gradientes pelo modelo.
//--- update critic1 cCritic1.getResults(result); float loss = zeta[0] * MathPow(result[0] - target, 2.0f); if(fLoss1 == 0) fLoss1 = MathSqrt(loss); else fLoss1 = MathSqrt(0.999f * MathPow(fLoss1, 2.0f) + 0.001f * loss); float grad = loss * 2 * zeta[0] * (target - result[0]); last_layer = cCritic1.layers.Total() - 1; layer = cCritic1.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.Update(0, grad) || !buffer.BufferWrite()) return false; if(!cCritic1.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
Simultaneamente, calculamos o erro médio do modelo, que será exibido ao usuário para controle visual do processo de treinamento do modelo.
Repetimos as operações para o segundo crítico.
//--- update critic2 cCritic2.getResults(result); loss = zeta[0] * MathPow(result[0] - target, 2.0f); if(fLoss2 == 0) fLoss2 = MathSqrt(loss); else fLoss2 = MathSqrt(0.999f * MathPow(fLoss1, 2.0f) + 0.001f * loss); grad = loss * 2 * zeta[0] * (target - result[0]); last_layer = cCritic2.layers.Total() - 1; layer = cCritic2.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.Update(0, grad) || !buffer.BufferWrite()) return false; if(!cCritic2.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
Após a atualização dos parâmetros dos Críticos, passamos para a atualização das políticas dos Atores. Primeiro, atualizamos a política do Ator conservador. Aqui, calculamos o valor-alvo levando em conta o limite inferior dos valores da função Q e a distribuição probabilística atual das ações. Ajustaremos o valor obtido ao fator de correção de distribuições e passaremos o gradiente de erro através do modelo do Crítico. Antes disso, desativaremos o modo de treinamento desse crítico.
//--- update policy cCritic1.getResults(result); float mean = result[0]; float var = result[0]; cCritic2.getResults(result); mean += result[0]; var -= result[0]; mean /= 2.0f; var = MathAbs(var) / 2.0f; target = zeta[0] * (mean - 2.5f * var + discount * log_prob.Sum() * LogProbMultiplier) + result[0]; CBufferFloat bTarget; bTarget.Add(target); cCritic2.TrainMode(false); if(!cCritic2.backProp(GetPointer(bTarget), GetPointer(this)) || !backPropGradient(SecondInput, GetPointer(temp))) { cCritic2.TrainMode(true); return false; }
Antes de atualizar os parâmetros da política otimista exploratória do Ator, realizamos uma propagação do modelo mencionado e substituímos os valores do buffer de resultados (como fizemos anteriormente para o modelo pessimista).
Depois, recalculamos o valor-alvo levando em conta o coeficiente de otimismo e distribuímos o gradiente de erro através do modelo do crítico.
//--- update exploration policy if(!cActorExploer.feedForward(State, 1, false, SecondInput)) { cCritic2.TrainMode(true); return false; } output = ((CNeuronBaseOCL*)((CLayer*)cActorExploer.layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite(); cActorExploer.GetLogProbs(log_prob); target = zeta[0] * (mean + 2.0f * var + discount * log_prob.Sum() * LogProbMultiplier) + result[0]; bTarget.Update(0, target); if(!cCritic2.backProp(GetPointer(bTarget), GetPointer(cActorExploer)) || !cActorExploer.backPropGradient(SecondInput, GetPointer(temp))) { cCritic2.TrainMode(true); return false; } cCritic2.TrainMode(true);
Após concluir as operações, reativamos o modo de treinamento do crítico e atualizamos os parâmetros dos modelos-alvo.
if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), tau) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), tau) || !cTargetNu.WeightsUpdate(GetPointer(cNu), tau)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; } //--- return true; }
Com isso, concluímos o trabalho no método de treinamento dos modelos e passamos para a construção dos métodos de trabalho com arquivos. Primeiro, criamos o método de salvamento dos modelos. É importante dizer que, diferentemente de métodos semelhantes anteriormente considerados, não salvaremos todos os dados em um único arquivo. Ao contrário, cada modelo treinável receberá um arquivo separado. Isso nos permitirá usar cada modelo individualmente, independentemente dos outros.
Nos parâmetros, o método de salvamento de dados CNet_SAC_DICE::Save receberá o nome comum do arquivo (sem extensão) e um sinalizador para salvar na pasta comum dos terminais. No corpo do método, imediatamente verificamos a presença do nome do arquivo na variável de texto recebida.
bool CNet_SAC_DICE::Save(string file_name, bool common = true) { if(file_name == NULL) return false;
Em seguida, criamos um arquivo com o nome especificado e a extensão ".set", salvando nele os valores das variáveis internas.
int handle = FileOpen(file_name + ".set", (common ? FILE_COMMON : 0) | FILE_BIN | FILE_WRITE); if(handle == INVALID_HANDLE) return false; if(FileWriteFloat(handle, fLambda) < sizeof(fLambda) || FileWriteFloat(handle, fLambda_m) < sizeof(fLambda_m) || FileWriteFloat(handle, fLambda_v) < sizeof(fLambda_v) || FileWriteInteger(handle, iLatentLayer) < sizeof(iLatentLayer)) return false; FileFlush(handle); FileClose(handle);
Em seguida, chamamos os métodos de salvamento dos modelos sequencialmente e controlamos o processo de execução das operações. Aqui, é importante prestar atenção nos nomes dos arquivos especificados. O Ator com a política conservadora recebe o sufixo do nome do arquivo "Act.nnw" (como já fizemos anteriormente para os Atores). Já o modelo do Ator otimista recebeu um arquivo com o sufixo "ActExp.nnw". Além disso, salvamos apenas os modelos-alvo dos Críticos e o modelo v. Os modelos treináveis correspondentes não são salvos.
if(!CNet::Save(file_name + "Act.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- if(!cActorExploer.Save(file_name + "ActExp.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- if(!cTargetCritic1.Save(file_name + "Crt1.nnw", fLoss1, 0, 0, TimeCurrent(), common)) return false; //--- if(!cTargetCritic2.Save(file_name + "Crt2.nnw", fLoss2, 0, 0, TimeCurrent(), common)) return false; //--- if(!cZeta.Save(file_name + "Zeta.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- if(!cTargetNu.Save(file_name + "Nu.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- return true; }
No método de carregamento de dados, repetimos as operações em estrita conformidade com a ordem de gravação dos dados. Aqui, os modelos treináveis e os modelos-alvo são carregados a partir dos mesmos arquivos correspondentes.
bool CNet_SAC_DICE::Load(string file_name, bool common = true) { if(file_name == NULL) return false; //--- int handle = FileOpen(file_name + ".set", (common ? FILE_COMMON : 0) | FILE_BIN | FILE_READ); if(handle == INVALID_HANDLE) return false; if(FileIsEnding(handle)) return false; fLambda = FileReadFloat(handle); if(FileIsEnding(handle)) return false; fLambda_m = FileReadFloat(handle); if(FileIsEnding(handle)) return false; fLambda_v = FileReadFloat(handle); if(FileIsEnding(handle)) return false; iLatentLayer = FileReadInteger(handle);; FileClose(handle); //--- float temp; datetime dt; if(!CNet::Load(file_name + "Act.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cActorExploer.Load(file_name + "ActExp.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cCritic1.Load(file_name + "Crt1.nnw", fLoss1, temp, temp, dt, common) || !cTargetCritic1.Load(file_name + "Crt1.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cCritic2.Load(file_name + "Crt2.nnw", fLoss2, temp, temp, dt, common) || !cTargetCritic2.Load(file_name + "Crt2.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cZeta.Load(file_name + "Zeta.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cNu.Load(file_name + "Nu.nnw", temp, temp, temp, dt, common) || !cTargetNu.Load(file_name + "Nu.nnw", temp, temp, temp, dt, common)) return false;
Após o carregamento dos dados dos modelos, os transferimos para um único contexto OpenCL.
cActorExploer.SetOpenCL(opencl); cCritic1.SetOpenCL(opencl); cCritic2.SetOpenCL(opencl); cZeta.SetOpenCL(opencl); cNu.SetOpenCL(opencl); cTargetCritic1.SetOpenCL(opencl); cTargetCritic2.SetOpenCL(opencl); cTargetNu.SetOpenCL(opencl); //--- return true; }
Com isso, concluímos o trabalho na classe CNet_SAC_DICE. Você pode se familiarizar com a totalidade de seus métodos no anexo. Continuamos nosso trabalho. Aqui, vale lembrar que nos parâmetros do método de treinamento mencionado anteriormente, especifica-se um vetor de logaritmos das probabilidades das ações. No entanto, não salvamos tais dados no buffer de reprodução de experiências anteriormente. Portanto, agora precisamos adicionar o array correspondente na estrutura de descrição estado-ação SState, que está presente no arquivo "..\SAC&DICE\Trajectory.mqh". O tamanho do array é igual ao número de ações.
struct SState { float state[HistoryBars * BarDescr]; float account[AccountDescr - 4]; float action[NActions]; float log_prob[NActions]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); ArrayCopy(action, obj.action); ArrayCopy(log_prob, obj.log_prob); } };
Não esquecemos de adicionar o array no algoritmo dos métodos de cópia da estrutura e trabalho com arquivos. O código completo da estrutura pode ser encontrado no anexo.
Agora, passamos para a criação e treinamento dos modelos. Quanto à arquitetura dos modelos, ela foi transferida sem alterações do artigo que descreve o método Soft Actor-Critic. No entanto, não criamos arquiteturas separadas para os modelos v e ζ. Para eles, utilizamos a arquitetura do crítico.
No processo de treinamento do modelo, assim como antes, usamos 3 EAs:
- Research — coleta de um banco de dados de exemplos
- Study — treinamento de modelos
- Test — verificação dos resultados obtidos.
É importante mencionar que, ao coletar dados para a base de exemplos no EA Research, usamos a política otimista do Ator (arquivo com o sufixo "ActExp.nnw"). Já para testar o modelo treinado, usaremos o modelo conservador (arquivo com o sufixo "Act.nnw"). Isso deve ser levado em consideração ao carregar os modelos nos arquivos correspondentes. Além disso, ao coletar dados no buffer de reprodução de experiências, não esquecemos de adicionar o carregamento do logaritmo das probabilidades de distribuição de ações. Você pode se familiarizar com o código completo dos EAs no anexo.
O EA de treinamento Study sofreu as maiores mudanças. Isso não é surpreendente. Uma grande parte de sua funcionalidade foi transferida para o método de treinamento Study da classe CNet_SAC_DICE.
Começamos com a mudança da biblioteca que contém nosso modelo.
#include "Net_SAC_DICE.mqh"
No bloco de variáveis globais, declaramos apenas um modelo da nova classe criada CNet_SAC_DICE. No entanto, aumentamos o número de buffers de dados. Isso se deve ao fato de que anteriormente podíamos usar um buffer para dois estados em diferentes etapas de treinamento. Agora, precisaremos transmitir simultaneamente informações sobre 2 estados subsequentes para o modelo.
STrajectory Buffer[]; CNet_SAC_DICE Net; //--- float dError; datetime dtStudied; //--- CBufferFloat bState; CBufferFloat bAccount; CBufferFloat bActions; CBufferFloat bNextState; CBufferFloat bNextAccount;
No método de inicialização do EA OnInit, assim como antes, primeiro carregamos o buffer de reprodução de experiências para o treinamento dos modelos.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Após isso, carregamos apenas um modelo. Se o modelo ainda não foi criado, formamos arrays de descrição da arquitetura dos modelos e criamos apenas um modelo, passando-lhe todas as descrições das arquiteturas. E verificamos apenas uma vez o resultado da execução das operações.
Como mencionado anteriormente, para os modelos do bloco DICE, passamos a descrição da arquitetura do crítico. No entanto, outras variantes são possíveis. Ao criar seus próprios modelos para este bloco, preste atenção no uso do modelo do Ator como bloco de processamento primário dos dados originais. Foi dessa forma que construímos todo o algoritmo de treinamento do modelo. É necessário seguir esse algoritmo ao criar arquiteturas de modelos ou fazer as alterações apropriadas no algoritmo do método.
//--- load models if(!Net.Load(FileName, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Net.Create(actor, critic, critic, critic, LatentLayer)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
Quando digo "apenas um modelo", estou, claro, simplificando. Afinal, durante o treinamento, criamos 6 modelos atualizáveis e 3 modelos-alvo. Simplesmente todos os modelos são criados dentro da nossa nova classe e ficam ocultos para o usuário. No nível superior, trabalhamos apenas com uma classe.
Ao finalizar o método de inicialização do EA, geramos um evento de treinamento do modelo.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Após a conclusão bem-sucedida de todas as operações, finalizamos o procedimento de inicialização do EA.
O próximo passo é trabalhar no procedimento de treinamento direto dos modelos, Train.
No corpo desta função, como antes, organizamos um ciclo de treinamento de acordo com o número de iterações especificado nos parâmetros externos do EA.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i<0) { iter--; continue; }
Dentro do ciclo, amostramos a trajetória e um passo separado para a iteração atual de treinamento dos modelos.
Em seguida, realizaremos o trabalho preparatório e coletaremos os dados necessários nos buffers de dados previamente declarados. Primeiro, transferiremos para o buffer os dados históricos que descrevem o estado subsequente do ambiente.
//--- Target bNextState.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; if(PrevBalance==0) { iter--; continue; } bNextAccount.Clear(); bNextAccount.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); bNextAccount.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); bNextAccount.Add(Buffer[tr].States[i + 1].account[2]); bNextAccount.Add(Buffer[tr].States[i + 1].account[3]); bNextAccount.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); bNextAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Em outro buffer, formaremos a descrição do estado da conta e adicionaremos marcas temporais.
De maneira semelhante, prepararemos os buffers com a descrição do estado do ambiente que está sendo analisado.
bState.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Depois, transferiremos para o buffer as ações executadas. O logaritmo das probabilidades será carregado em um vetor.
bActions.AssignArray(Buffer[tr].States[i].action); vector<float> log_prob; log_prob.Assign(Buffer[tr].States[i].log_prob);
Neste ponto, concluímos o trabalho preparatório e todos os dados necessários para uma iteração de treinamento já foram coletados nos buffers de dados. Chamamos o método de treinamento do nosso modelo CNet_SAC_DICE::Study, passando os dados necessários nos parâmetros.
if(!Net.Study(GetPointer(bState), GetPointer(bAccount), GetPointer(bActions), log_prob, GetPointer(bNextState), GetPointer(bNextAccount), Buffer[tr].Revards[i] - DiscFactor * Buffer[tr].Revards[i + 1], DiscFactor, Tau)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Note que no buffer de reprodução de experiências, salvamos as recompensas como um total acumulado. Agora, no método de treinamento do modelo, passamos a recompensa líquida para um passo individual. Os dados faltantes serão previstos pelos modelos-alvo.
Transferimos todas as operações de treinamento dos modelos para o método de treinamento da nossa classe. Agora, só precisamos verificar o resultado da execução das operações do método. Depois disso, informaremos o usuário sobre o progresso do treinamento do modelo.
if(GetTickCount() - ticks > 500) { float loss1, loss2; Net.GetLoss(loss1, loss2); string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), loss1); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), loss2); Comment(str); ticks = GetTickCount(); } }
Após a conclusão de todas as iterações do ciclo, limpamos o campo de comentários e iniciamos o procedimento de finalização do trabalho do EA.
Comment(""); //--- float loss1, loss2; Net.GetLoss(loss1, loss2); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", loss1); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", loss2); ExpertRemove(); //--- }
Como se pode observar, transferir as operações de treinamento do modelo para um método separado da classe permite reduzir significativamente o código e o esforço de trabalho no lado do programa principal. No entanto, essa abordagem também reduz a flexibilidade do processo de treinamento do modelo e as possibilidades do usuário para ajustá-lo. Ambas as abordagens têm seus prós e contras, e a escolha de uma abordagem específica depende da tarefa em questão e das preferências pessoais.
Você pode se familiarizar com o código completo deste EA, assim como todos os programas utilizados no artigo, no anexo.
4. Teste
O treinamento do modelo foi realizado com dados históricos do instrumento EURUSD, no timeframe H1, para o período de janeiro a maio de 2023. Os parâmetros dos indicadores e todos os hiperparâmetros foram usados conforme as configurações padrão. Durante o treinamento, foi obtido um modelo capaz de gerar lucro na amostra de treinamento.


Durante os 5 meses do período de treinamento, o modelo conseguiu gerar 15% de lucro. Foram abertas 314 posições, das quais 45,8% foram fechadas com lucro. A negociação mais lucrativa foi quase duas vezes maior que a maior perda. Enquanto isso, o lucro médio por negociação foi um terço maior do que a perda média. Essa relação entre lucros e perdas permitiu alcançar um fator de lucro de 1.13.
No entanto, para nós, como sempre, é de maior interesse a eficácia do modelo em dados novos. A capacidade de generalização e o desempenho do modelo em dados desconhecidos foram testados no testador de estratégias em dados históricos de junho de 2023. Como se pode observar, o período de teste segue imediatamente após a amostra de treinamento. Isso garante a máxima homogeneidade entre as amostras de treinamento e teste. Os resultados do teste são apresentados a seguir.

No gráfico apresentado, é visível uma área de retração na primeira década do mês. Mas, em seguida, há um período de rentabilidade, que continua até o final do mês. Como resultado, o EA obteve um lucro de 7,7% em um mês, com uma retração máxima de 5,46% no Equity. Quanto ao saldo, a retração foi ainda menor, não excedendo 4,87%.

Da tabela de resultados do teste, é evidente que durante o teste, o EA realizou operações de negociação em diferentes direções. Um total de 48 posições foram abertas. E 54,17% delas foram fechadas com lucro. Nesse caso, a negociação mais lucrativa foi mais de três vezes maior que a maior negociação perdedora. E a negociação lucrativa média foi quase metade maior do que a negociação perdedora média. Em termos quantitativos, em média, para cada 3 negociações lucrativas, houve 2 perdedoras. Tudo isso resultou em um fator de lucro de 1,74 e um fator de recuperação de 1,41.
Considerações finais
Neste artigo, nos familiarizamos com mais um algoritmo da família Ator-Crítico — o algoritmo SAC+DICE, que é baseado em duas principais direções de modificação do algoritmo Soft Actor-Critic. O uso de um modelo otimista para explorar o ambiente permite expandir a zona de exploração do ambiente. Ao mesmo tempo, a exploração é direcionada no sentido de aumentar a rentabilidade da política geral. Claro, isso leva a uma divergência nas distribuições das políticas de exploração do ambiente e da política conservadora em treinamento. Para obter uma avaliação imparcial dos gradientes, é utilizado uma abordagem modificada do DICE e introduzido um fator de correção de distribuição treinável. Tudo isso juntos permite aumentar a eficácia do treinamento dos modelos, o que foi confirmado na parte prática do nosso artigo.
Nós implementamos o algoritmo proposto usando MQL5. Durante esta implementação, demonstramos a abordagem de transferir o processo de treinamento do modelo para um método separado da classe. Isso permite reduzir significativamente o trabalho no lado do programa principal e simplificar o uso.
Treinamos e testamos o modelo treinado em novos dados. Os resultados do teste demonstraram a eficácia de nossa implementação. O modelo treinado conseguiu transferir a experiência adquirida para novos dados, e durante o teste, o EA obteve lucro.
No entanto, todos os programas apresentados apenas demonstram a possibilidade de uso da abordagem e não estão prontos para uso nos mercados financeiros reais. Antes de seu uso, é necessário refinar os EAs e realizar testes abrangentes adicionais.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | Study.mq5 | Expert Advisor | EA de treinamento do agente |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | Net_SAC_DICE.mqh | Biblioteca de classe | Classe de modelo |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para a criação de uma rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca do código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13055
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Dmitry, por que essa rede abre todas as negociações com exatamente 1 lote, ao treinar em todos os testes, e não tenta alterar o lote? Ela não tenta definir lotes fracionários e também não quer definir mais de 1 lote. Instrumento EURUSD. Os parâmetros de treinamento são os mesmos que os seus.
Na última camada do Actor, usamos sigmoide como função de ativação, o que limita os valores no intervalo [0,1]. Para TP e SL, usamos um multiplicador para ajustar os valores. O tamanho do lote não é ajustado. Portanto, 1 lote é o valor máximo possível.
Na última camada Actor, usamos sigmoide como função de ativação, o que limita os valores ao intervalo [0,1]. Para TP e SL, usamos um multiplicador para ajustar os valores. O tamanho do lote não é ajustado. Portanto, 1 lote é o valor máximo possível.
Entendido, obrigado.