
Redes neuronales: así de sencillo (Parte 52): Exploración con optimismo y corrección de la distribución

Introducción
Uno de los elementos esenciales para mejorar la estabilidad del aprendizaje de la función Q es el uso de un búfer de reproducción de experiencias. El aumento del búfer nos da la oportunidad de recopilar ejemplos más diversos de interacción con el entorno, lo que en general permite a nuestro modelo aprender y reproducir mejor la función Q del entorno. Esta técnica se usa ampliamente en varios algoritmos de aprendizaje por refuerzo, incluidos los de la familia Actor-Crítico.
No obstante, debemos considerar la otra cara de la moneda: Durante el proceso de aprendizaje, las acciones del Actor son cada vez más diferentes de los ejemplos almacenados en el búfer de reproducción de experiencias, y cuantas más iteraciones de actualización de los parámetros del modelo se realicen, mayor será esta diferencia, lo cual provoca una disminución de la eficacia del entrenamiento de la política del Actor. Una solución a este problema se presentó en el artículo "Off-policy Reinforcement Learning with Optimistic Exploration and Distribution Correction" (octubre de 2021). Los autores del método propusieron adaptar el método Distribution Correction Estimation (DICE) al algoritmo Soft Actor-Critic (SAC).
Al mismo tiempo, los autores del método destacaron otro punto de interés. El método SAC utiliza la evaluación de acciones mínimas en el entrenamiento de políticas. La experiencia de este enfoque en la práctica muestra una tendencia a la infraexploración pesimista del entorno y a la homogeneidad dirigida de la acción. Para minimizar dicho efecto, los autores del trabajo sugirieron entrenar adicionalmente el modelo de exploración optimista del Actor, lo que a su vez amplía aún más la brecha entre el ejemplo de la interacción del modelo del Actor optimista con el entorno y la distribución de acciones del modelo objetivo entrenado.
No obstante, el uso conjunto de la corrección de la estimación de la distribución y la exploración optimista del modelo del Actor puede mejorar el resultado del entrenamiento del modelo objetivo.

1. Exploración con optimismo
Hay que decir que las primeras ideas sobre la exploración del entorno se publicaron en el artículo "Better Exploration with Optimistic Actor-Critic" (octubre de 2019). Precisamente sus autores señalaron que la combinación de la actualización codiciosa del agente y la evaluación pesimista del Crítico lleva a evitar acciones de las que el agente no es consciente. Este fenómeno se denominó "infraexploración pesimista". Además, la mayoría de los algoritmos desconocen el «rumbo» de la exploración. Las acciones muestreadas aleatoriamente tienen la misma probabilidad de estar en lados opuestos del valor medio actual, mientras que normalmente necesitamos que se actúe en determinadas direcciones mucho más que en otras. Para corregir dichos fenómenos, se propuso el algoritmo Optimistic Actor Critic (OAC) para aproximar los límites de confianza inferiores y superiores de la función de valor estado-acción. Esto permitió utilizar el principio de optimismo en la incertidumbre de realización de la exploración dirigida usando un límite superior. Al mismo tiempo, el límite inferior ayuda a evitar la sobreestimación de las acciones.
Los autores del método analizado en este artículo han recogido y desarrollado las ideas del OAC. Al igual que sucede con el SAC, entrenaremos 2 modelos de Críticos, pero al mismo tiempo, también entrenaremos 2 modelos del Actor: la exploración πe y el objetivo πт.
La política πe se entrena para maximizar el límite superior aproximado de los valores de la función Q de QUB. Simultáneamente, πt maximiza la aproximación del límite inferior de la función Q de QLB durante el proceso de entrenamiento. El OAC muestra que la exploración que utiliza πe logra un uso más eficiente de la muestra en comparación con el Soft Actor-Critic.
Para obtener el límite superior aproximado de la función Q de QUB , primero se calculan la media y la varianza de las puntuaciones de ambos Críticos:
![]()
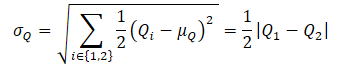
A continuación, determinamos el QUB mediante la fórmula:
![]()
donde βUB ∈ R y controla el nivel de optimismo.
Obsérvese que el anterior límite inferior aproximado de la función Q de QLB puede expresarse como
![]()
En el nivel de pesimismo βLB = 1 QLB es igual al mínimo de las puntuaciones de los Críticos.
El OAC aplica una restricción de divergencia KL máxima entre πe y πt, que permite obtener una solución de forma cerrada para πe y estabiliza el aprendizaje. Al mismo tiempo, esto limita el potencial de πe para realizar acciones más informativas que podrían corregir las falsas evaluaciones de los críticos, dado que esta restricción impide que πe genere acciones muy diferentes de las generadas por la política πt entrenada de forma conservadora basándose en la evaluación mínima de los críticos.
En el algoritmo SAC+DICE, la adición de la corrección distributiva permite prescindir de la restricción KL para liberar toda la potencia de la exploración optimista de la política. En este caso, la estabilidad del aprendizaje se mantiene corrigiendo explícitamente la estimación desplazada del gradiente en el entrenamiento de políticas.
El proceso de entrenamiento de la política conductual del Actor πт, para evitar la sobreestimación de la función Q, utiliza el límite inferior aproximado de QLB como crítico, al igual que en el método SAC. Pero añade un ajuste a la distribución de la muestra mediante la relación dπт(s,a)/dD(s,a). Obtenemos el siguiente objetivo de entrenamiento:
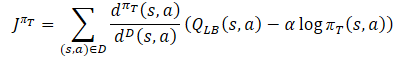
donde dπт(s,a) representa la distribución estado-acción de la política actual, mientras que dD(s,a) supone la distribución estado-acción del búfer de reproducción de experiencias. El gradiente de dicho objetivo de entrenamiento ofrece una estimación no desplazada del gradiente de política, a diferencia de los algoritmos de aprendizaje Actor-Crítico anteriores que utilizan una estimación desplazada al entrenar la política objetivo.
La política de exploración πе debe investigar el desplazamiento optimista en relación con los valores estimados de la función Q con el fin de reunir experiencia para corregir eficazmente las estimaciones falsas. Por lo tanto, los autores del método propusieron usar un límite superior aproximado, similar al Optimistic Actor-Critic QUB como Crítico en la función objetivo. El objetivo final de la política πe y una mejor estimación de la función Q consiste en facilitar una estimación más precisa del gradiente para la política πt objetivo. Por lo tanto, la distribución de la muestra para la función de pérdida πe debe ser coherente con la política conductual πt. En consecuencia, los autores del método proponen usar el mismo factor de corrección que en la función de pérdida de la política objetivo del Actor.
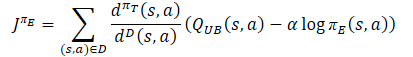
En cuanto a los Críticos, se mantiene el planteamiento de SAC anteriormente comentado, y el límite inferior de la función Q de los modelos objetivo se utilizará para entrenarlos. Sin embargo, existen varios estudios que demuestran la eficacia de utilizar muestras únicas para formar a Actores y Críticos. Por lo tanto, también se añadió un factor de corrección de la distribución a la función de pérdida de los Críticos.
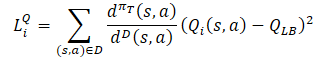
Como podemos ver, de todos ellos, el factor de corrección de la distribución es el que plantea más dudas. Veamos este tema en mayor profundidad.
2. Corrección de la distribución
La familia de algoritmos Distribution Correction Estimation (DICE) está diseñada para resolver el problema de la corrección de la Evaluación Fuera de Política (Off-Policy Evaluation - OPE). Estos métodos entrenan un estimador del valor de la política, es decir, la recompensa esperada normalizada por cada paso, basándose en un búfer de repetición estático D. DICE obtiene un estimador no desplazado que calcula el factor de corrección de la distribución.
![]()
Para estimar el factor de corrección de la distribución, los autores del método adaptaron el esquema de optimización DICE, que puede formularse como un programa de distribución lineal minimax con diversas regularizaciones. La aplicación directa de los algoritmos DICE a entornos de aprendizaje por refuerzo fuera de la política conlleva importantes dificultades de optimización. El aprendizaje con OPE supone una política objetivo fija y un búfer de repetición estático con cobertura suficiente del espacio estado-acción, mientras que en RL la política objetivo y el búfer de reproducción de experiencias cambian durante el entrenamiento. Por ello, los autores del método SAC+DICE introducen varias modificaciones para superar dichas dificultades. No nos sumergiremos ahora en las matemáticas, tampoco nos detendremos a considerar estas modificaciones. Si el lector está interesado en este punto, hallará información en el siguiente artículo. Mostraremos solo las funciones de pérdida obtenidas como resultado de las modificaciones propuestas.
![]()
![]()
![]()
Aquí ζ(s,a) y v(s,a) son modelos de red neuronal, mientras que λ es un coeficiente de Lagrange ajustable. ζ(s,a) aproxima el coeficiente de corrección de la distribución, y v(s,a) sería una especie de Crítico. Y para estabilizar el proceso de aprendizaje, de forma similar al Crítico, utilizaremos el modelo objetivo v con una actualización suave de sus parámetros.
Los autores proponen usar el método Adam para optimizar todos los parámetros.
Todo lo anterior se resume en un único algoritmo SAC+DICE. Al igual que con los algoritmos convencionales de aprendizaje por refuerzo sin política, realizamos interacciones secuenciales con el entorno siguiendo una política de exploración πe optimista y almacenamos los datos en un búfer de reproducción de experiencias. En cada paso de entrenamiento, el algoritmo analizado actualiza primero los modelos y parámetros DICE (v, ζ, λ) utilizando SGD con respecto a las funciones de pérdida anteriores.
A continuación, calculamos el coeficiente de corrección de la distribución ζ a partir del modelo actualizado.
Luego, utilizando ζ, realizamos el entrenamiento RL para actualizar πт, πе, Q1 y Q2.
Al final de cada paso de entrenamiento, los modelos objetivo Q1, Q2 y v se someten a una actualización suave.
3. Implementación con ayuda de MQL5
Al leer la parte teórica, supongo que el lector habrá notado que el número de modelos y parámetros entrenados aumenta drásticamente. De hecho, el número de modelos entrenados ha aumentado de 3 a 6. Así, el proceso de interacción con estos se hace más complejo. Al mismo tiempo, esperamos obtener un modelo de política conductual del Actor en el resultado. Para ocultar todo el trabajo rutinario al usuario cambiaremos ligeramente nuestro enfoque y envolveremos todo el proceso de entrenamiento en una clase CNet_SAC_DICE separada. Nuestra nueva clase será la sucesora de la clase básica de modelos de redes neuronales CNet. En el cuerpo de la clase, declaramos 5 modelos entrenados y 3 modelos objetivo. Aquí también declaramos una serie de variables internas, cuya funcionalidad conoceremos durante la implementación.
class CNet_SAC_DICE : protected CNet { protected: CNet cActorExploer; CNet cCritic1; CNet cCritic2; CNet cTargetCritic1; CNet cTargetCritic2; CNet cZeta; CNet cNu; CNet cTargetNu; float fLambda; float fLambda_m; float fLambda_v; int iLatentLayer; //--- float fLoss1; float fLoss2; float fZeta; //--- vector<float> GetLogProbability(CBufferFloat *Actions); public: //--- CNet_SAC_DICE(void); ~CNet_SAC_DICE(void) {} //--- bool Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer = -1); //--- virtual bool Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &ActionsLogProbab, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float reward, float discount, float tau); virtual void GetLoss(float &loss1, float &loss2) { loss1 = fLoss1; loss2 = fLoss2; } //--- virtual bool Save(string file_name, bool common = true); bool Load(string file_name, bool common = true); };
Tenga en cuenta que al principio hablábamos de 6 modelos entrenados, y solo se han declarado 5 modelos. Entre los modelos declarados no figura ninguna política objetivo del Actor. Al fin y al cabo, el objetivo de todo el proceso de aprendizaje es precisamente obtener esta política. El asunto es que nuestra nueva clase, como mencionamos antes, es heredera de la clase básica de la red neuronal, y, por tanto, es en sí misma un modelo «entrenable». Por lo tanto, el entrenamiento sobre la política básica del Actor se ofrece a través de los recursos de la clase padre.
También debemos decir que la nueva clase CNet_SAC_DICE creada solo se usará para entrenar el modelo. Durante la explotación, la creación de objetos modelo adicionales no tendrá sentido y supondrá un consumo innecesario de recursos. Por lo tanto, tenemos previsto utilizar los objetos básicos de los modelos durante la explotación. A causa de ello, la nueva clase carecerá de métodos de pasada directa e inversa. Toda la funcionalidad se implementará en el método Study.
Y, por supuesto, tendremos los métodos Save y Load para trabajar con los archivos. Pero lo primero es lo primero.
En el constructor de la clase, inicializamos las variables internas con los valores iniciales. Todos los objetos internos se declaran de forma estática y no hay necesidad de inicializarlos. En consecuencia, no necesitamos borrar memoria en el destructor, lo cual nos permite dejar el destructor vacío.
CNet_SAC_DICE::CNet_SAC_DICE(void) : fLambda(1.0e-5f), fLambda_m(0), fLambda_v(0), fLoss1(0), fLoss2(0), fZeta(0) { }
La inicialización completa de los modelos se realiza en el método Create. En los parámetros del método, transmitiremos los arrays dinámicos de la descripción de la arquitectura de todos los modelos utilizados y el identificador de la capa latente del Actor con una representación comprimida del estado del entorno analizado.
En el cuerpo del método, primero crearemos los modelos del Actor. El modelo optimista se crea en el objeto cActorExploer, mientras que el modelo objetivo se crea en el cuerpo de nuestra clase mediante los recursos heredados.
bool CNet_SAC_DICE::Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer) { ResetLastError(); //--- if(!cActorExploer.Create(actor) || !CNet::Create(actor)) { PrintFormat("Error of create Actor: %d", GetLastError()); return false; } //--- if(!opencl) { Print("Don't opened OpenCL context"); return false; }
Luego comprobamos de inmediato el puntero del contexto OpenCL creado.
A continuación, creamos los modelos entrenables de ambos Críticos.
if(!cCritic1.Create(critic) || !cCritic2.Create(critic)) { PrintFormat("Error of create Critic: %d", GetLastError()); return false; }
Y luego los objetos del bloque DICE y los modelos objetivo.
if(!cZeta.Create(zeta) || !cNu.Create(nu)) { PrintFormat("Error of create function nets: %d", GetLastError()); return false; } //--- if(!cTargetCritic1.Create(critic) || !cTargetCritic2.Create(critic) || !cTargetNu.Create(nu)) { PrintFormat("Error of create target models: %d", GetLastError()); return false; }
Una vez creados con éxito todos los modelos, los trasladamos a un único contexto OpenCL,
cActorExploer.SetOpenCL(opencl); cCritic1.SetOpenCL(opencl); cCritic2.SetOpenCL(opencl); cZeta.SetOpenCL(opencl); cNu.SetOpenCL(opencl); cTargetCritic1.SetOpenCL(opencl); cTargetCritic2.SetOpenCL(opencl); cTargetNu.SetOpenCL(opencl);
y copiamos los parámetros de los modelos en sus copias de destino. Al mismo tiempo, no deberemos olvidarnos de controlar la ejecución de las operaciones en cada paso.
if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), 1.0) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), 1.0) || !cTargetNu.WeightsUpdate(GetPointer(cNu), 1.0)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; }
Una vez creados con éxito todos los objetos necesarios, transferimos los datos a las variables internas y finalizamos el método.
fLambda = 1.0e-5f; fLambda_m = 0; fLambda_v = 0; fZeta = 0; iLatentLayer = latent_layer; //--- return true; }
Tras inicializar los objetos internos de la clase, comenzaremos a trabajar en el método de entrenamiento del modelo CNet_SAC_DICE::Study. En los parámetros de esta clase, obtenemos toda la información necesaria para realizar un paso del entrenamiento del modelo. Aquí tenemos los estados actual y futuro del entorno. En este caso, cada estado se describe en 2 búferes de datos: uno con los datos históricos y otro con el estado del balance. Aquí también veremos el búfer de acción y la variable de recompensa. Así que también hay variables para los factores de descuento y la actualización suave de los modelos objetivo. Primero añadimos un vector de logaritmos de probabilidad de la política de origen (utilizada al recopilar los ejemplos).
bool CNet_SAC_DICE::Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &ActionsLogProbab, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float reward, float discount, float tau) { //--- if(!Actions || Actions.Total()!=ActionsLogProbab.Size()) return false;
En el cuerpo del método, organizamos primero un pequeño bloque de control en el que comprobaremos la relevancia del puntero al búfer de acciones, así como la correspondencia de su tamaño con el tamaño del vector de logaritmos de probabilidades. No comprobaremos los punteros a los otros búferes, por lo que su control se implementa en los métodos llamados.
Una vez completado con éxito el bloque de control, realizamos las siguientes estimaciones del estado usando los modelos objetivo considerando la política actual. Para ello, primero aplicamos una pasada directa de nuestra política conservadora del Actor. Lo utilizamos para preprocesar los datos de origen de la descripción del estado actual y la predicción de un vector de acciones a partir de ese estado. Introducimos los datos obtenidos en los 2 modelos objetivo del Crítico y en el modelo v del bloque DICE.
if(!CNet::feedForward(NextState, 1, false, NextSecondInput)) return false; if(!cTargetCritic1.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1) || !cTargetCritic2.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false; //--- if(!cTargetNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false;
El siguiente paso será preparar los datos del estado actual. En cuanto al estado posterior, utilizamos el modelo conservador del Actor actual para preprocesar la descripción del estado actual.
if(!CNet::feedForward(State, 1, false, SecondInput)) return false; CBufferFloat *output = ((CNeuronBaseOCL*)((CLayer*)layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite();
Aquí también realizamos un pequeño truco de sustitución de los resultados de la pasada directa. En lugar de las acciones recibidas de la política del Actor actual, almacenaremos el tensor de acciones del búfer de reproducción de experiencias en el búfer de resultados de la última capa neuronal. El objetivo de esta operación consiste en mantener la coherencia entre la acción y la recompensa del entorno. Sí, reconocemos que es muy probable que se formen otras acciones durante el proceso de pasada directa. Pero nuestra capa neuronal CNeuronSoftActorCritic, en las entrañas de su funcionamiento interno, aprende la distribución de las acciones y sus probabilidades. Y la pasada inversa determinará los cuantiles y las probabilidades correspondientes a las acciones del búfer de reproducción de experiencias. En este caso, el gradiente no desplazado pasará exactamente por estos cuantiles, lo cual permitirá entrenar el modelo del Actor con mayor precisión y sin distorsiones.
Tras preparar los datos del entorno actual, podemos realizar una pasada directa de los modelos del bloque DICE. Y, obviamente, no nos olvidaremos de supervisar las operaciones.
if(!cNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false; if(!cZeta.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false;
Según el algoritmo SAC+DICE, primero actualizamos los modelos y parámetros del bloque DICE. Pero antes de actualizar los parámetros, necesitamos calcular los valores de las funciones de pérdida para v, ζ, λ.
Nótese que para obtener el valor de las funciones de pérdida, necesitamos el valor objetivo de la relación de probabilidades estado-acción en la política conservadora actual y en la interacción con el entorno durante la recogida de la base de datos de ejemplos. Hay que decir aquí que los datos históricos de la descripción del estado del entorno son independientes de la política del Actor. Además, percibimos el estado actual como un punto de partida para tomar una decisión y construir una trayectoria de acción posterior. Por ello, la probabilidad del estado inicial se percibe como 1, porque estamos en él.
En el proceso de aprendizaje de la política, solo cambia la distribución de probabilidad de las acciones según la estrategia entrenada. Por lo tanto, nuestro valor objetivo será la relación de las probabilidades de las acciones en las dos políticas. Durante las operaciones, en lugar del cociente de probabilidades, utilizaremos la diferencia con el logaritmo de probabilidades. En este caso, en lugar de multiplicar las probabilidades de todas las acciones, utilizaremos la suma de sus logaritmos restableciendo el valor mediante el exponente.
vector<float> nu, next_nu, zeta, ones; cNu.getResults(nu); cTargetNu.getResults(next_nu); cZeta.getResults(zeta); ones = vector<float>::Ones(zeta.Size()); vector<float> log_prob = GetLogProbability(output); float policy_ratio = MathExp((log_prob - ActionsLogProbab).Sum()); vector<float> bellman_residuals = next_nu * discount * policy_ratio - nu + policy_ratio * reward; vector<float> zeta_loss = zeta * (MathAbs(bellman_residuals) - fLambda) * (-1) + MathPow(zeta, 2.0f) / 2; vector<float> nu_loss = zeta * MathAbs(bellman_residuals) + MathPow(nu, 2.0f) / 2.0f; float lambda_los = fLambda * (ones - zeta).Sum();
Tras determinar los valores de la función de pérdida, determinaremos los gradientes de error y actualizaremos los parámetros. En primer lugar, actualizamos los valores del coeficiente de Lagrange. Durante el ajuste de parámetros, utilizamos el algoritmo del método Adam.
//--- update lambda float grad_lambda = (ones - zeta).Sum() * (-lambda_los); fLambda_m = b1 * fLambda_m + (1 - b1) * grad_lambda; fLambda_v = b2 * fLambda_v + (1 - b2) * MathPow(grad_lambda, 2); fLambda += lr * fLambda_m / (fLambda_v != 0.0f ? MathSqrt(fLambda_v) : 1.0f);
A continuación, debemos actualizar los parámetros de los modelos v, ζ. Hay que decir que hemos definido los valores de la función de pérdida, no los valores objetivo, al mismo tiempo, la función de pérdida de cada modelo es individual y muy diferente de las que hemos utilizado anteriormente. Y ahora no ajustaremos las operaciones a la función de pérdida básica de nuestro modelo. En su lugar, calculamos inmediatamente el gradiente de error. Luego transferimos el valor obtenido al búfer del modelo correspondiente y propagamos el gradiente de error sobre los parámetros del modelo.
Primero actualizamos los parámetros del modelo v.
//--- CBufferFloat temp; temp.BufferInit(MathMax(Actions.Total(), SecondInput.Total()), 0); temp.BufferCreate(opencl); //--- update nu int last_layer = cNu.layers.Total() - 1; CLayer *layer = cNu.layers.At(last_layer); if(!layer) return false; CNeuronBaseOCL *neuron = layer.At(0); if(!neuron) return false; CBufferFloat *buffer = neuron.getGradient(); if(!buffer) return false; vector<float> nu_grad = nu_loss * (zeta * bellman_residuals / MathAbs(bellman_residuals) + nu); if(!buffer.AssignArray(nu_grad) || !buffer.BufferWrite()) return false; if(!cNu.backPropGradient(output, GetPointer(temp))) return false;
Y luego realizamos operaciones similares para el modelo ζ.
//--- update zeta last_layer = cZeta.layers.Total() - 1; layer = cZeta.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; vector<float> zeta_grad = zeta_loss * (zeta - MathAbs(bellman_residuals) + fLambda) * (-1); if(!buffer.AssignArray(zeta_grad) || !buffer.BufferWrite()) return false; if(!cZeta.backPropGradient(output, GetPointer(temp))) return false;
En este punto, hemos actualizado los parámetros del bloque DICE, así que pasamos directamente al procedimiento de aprendizaje por refuerzo. En primer lugar, realizamos una pasada directa de ambos Críticos. En este caso no realizamos una pasada directa del Actor, puesto que ya hemos realizado esta operación al actualizar los parámetros de los objetos del bloque DICE.
//--- feed forward critics if(!cCritic1.feedForward(GetPointer(this), iLatentLayer, output) || !cCritic2.feedForward(GetPointer(this), iLatentLayer, output)) return false;
A continuación, al igual que sucede con las actualizaciones de los parámetros DICE, determinamos los valores de las funciones de pérdida. Pero primero, hagamos un poco de trabajo preparatorio. Para mejorar la estabilidad del entrenamiento del modelo, normalizamos el factor de corrección de la distribución y calculamos el valor de referencia predicho por los modelos objetivo de los críticos dada la política actual del Actor.
vector<float> result; if(fZeta == 0) fZeta = MathAbs(zeta[0]); else fZeta = 0.9f * fZeta + 0.1f * MathAbs(zeta[0]); zeta[0] = MathPow(MathAbs(zeta[0]), 1.0f / 3.0f) / (10.0f * MathPow(fZeta, 1.0f / 3.0f)); cTargetCritic1.getResults(result); float target = result[0]; cTargetCritic2.getResults(result); target = reward + discount * (MathMin(result[0], target) - LogProbMultiplier * log_prob.Sum());
A pesar de tener un valor objetivo, no podemos aplicar el método básico de pasada inversa de los modelos de los críticos porque no admite el uso de un factor de corrección de la distribución. Por lo tanto, aplicamos la técnica elaborada anteriormente con el cálculo del gradiente de error y su transferencia directa al búfer de la capa neuronal de resultados, seguida de la distribución de los gradientes sobre el modelo.
//--- update critic1 cCritic1.getResults(result); float loss = zeta[0] * MathPow(result[0] - target, 2.0f); if(fLoss1 == 0) fLoss1 = MathSqrt(loss); else fLoss1 = MathSqrt(0.999f * MathPow(fLoss1, 2.0f) + 0.001f * loss); float grad = loss * 2 * zeta[0] * (target - result[0]); last_layer = cCritic1.layers.Total() - 1; layer = cCritic1.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.Update(0, grad) || !buffer.BufferWrite()) return false; if(!cCritic1.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
Al mismo tiempo, debemos considerar el error medio del modelo, que mostramos al usuario para controlar visualmente el proceso de entrenamiento del modelo.
Luego repetimos las operaciones para el segundo Crítico.
//--- update critic2 cCritic2.getResults(result); loss = zeta[0] * MathPow(result[0] - target, 2.0f); if(fLoss2 == 0) fLoss2 = MathSqrt(loss); else fLoss2 = MathSqrt(0.999f * MathPow(fLoss1, 2.0f) + 0.001f * loss); grad = loss * 2 * zeta[0] * (target - result[0]); last_layer = cCritic2.layers.Total() - 1; layer = cCritic2.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.Update(0, grad) || !buffer.BufferWrite()) return false; if(!cCritic2.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
Una vez actualizados los parámetros del Crítico, pasamos a actualizar las políticas del Actor. Primero actualizamos la política del Actor conservador. Aquí calculamos el valor objetivo dado el límite inferior de los valores de la función Q y la distribución de probabilidad actual de las acciones. Después ajustamos el valor resultante mediante el factor de corrección de la distribución y transmitimos el gradiente de error por el modelo del Crítico. Previamente, desactivaremos el modo de entrenamiento de este Crítico.
//--- update policy cCritic1.getResults(result); float mean = result[0]; float var = result[0]; cCritic2.getResults(result); mean += result[0]; var -= result[0]; mean /= 2.0f; var = MathAbs(var) / 2.0f; target = zeta[0] * (mean - 2.5f * var + discount * log_prob.Sum() * LogProbMultiplier) + result[0]; CBufferFloat bTarget; bTarget.Add(target); cCritic2.TrainMode(false); if(!cCritic2.backProp(GetPointer(bTarget), GetPointer(this)) || !backPropGradient(SecondInput, GetPointer(temp))) { cCritic2.TrainMode(true); return false; }
Antes de actualizar los parámetros de la política de exploración optimista del Actor, realizamos una pasada directa del modelo especificado y sustituimos los valores del búfer de resultados (como hicimos anteriormente para el modelo pesimista).
A continuación, volvemos a calcular el valor objetivo con el coeficiente de optimismo y distribuimos el gradiente de error a través del modelo del Сrítico.
//--- update exploration policy if(!cActorExploer.feedForward(State, 1, false, SecondInput)) { cCritic2.TrainMode(true); return false; } output = ((CNeuronBaseOCL*)((CLayer*)cActorExploer.layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite(); cActorExploer.GetLogProbs(log_prob); target = zeta[0] * (mean + 2.0f * var + discount * log_prob.Sum() * LogProbMultiplier) + result[0]; bTarget.Update(0, target); if(!cCritic2.backProp(GetPointer(bTarget), GetPointer(cActorExploer)) || !cActorExploer.backPropGradient(SecondInput, GetPointer(temp))) { cCritic2.TrainMode(true); return false; } cCritic2.TrainMode(true);
Una vez finalizadas las operaciones, activamos el modo de entrenamiento del Crítico y actualizamos los parámetros de los modelos objetivo.
if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), tau) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), tau) || !cTargetNu.WeightsUpdate(GetPointer(cNu), tau)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; } //--- return true; }
Con esto concluimos nuestro trabajo sobre el método de entrenamiento de modelos y pasamos a la construcción de métodos de tratamiento de archivos. Lo primero que haremos es crear un método para guardar modelos. Aquí debemos decir que a diferencia de los métodos similares anteriormente analizados, no vamos a guardar todos los datos en un archivo. Por el contrario, cada modelo entrenado obtendrá un archivo independiente. Esto nos permitirá usar cada modelo independientemente de los demás.
En los parámetros, el método CNet_SAC_DICE::Save obtiene el nombre de archivo común (sin extensión) y la bandera de almacenamiento en la carpeta común del terminal. En el cuerpo del método comprobamos directamente si el nombre del archivo está presente en la variable de texto obtenida.
bool CNet_SAC_DICE::Save(string file_name, bool common = true) { if(file_name == NULL) return false;
A continuación, creamos un archivo con el nombre y la extensión ".set" y guardamos en él los valores de las variables internas.
int handle = FileOpen(file_name + ".set", (common ? FILE_COMMON : 0) | FILE_BIN | FILE_WRITE); if(handle == INVALID_HANDLE) return false; if(FileWriteFloat(handle, fLambda) < sizeof(fLambda) || FileWriteFloat(handle, fLambda_m) < sizeof(fLambda_m) || FileWriteFloat(handle, fLambda_v) < sizeof(fLambda_v) || FileWriteInteger(handle, iLatentLayer) < sizeof(iLatentLayer)) return false; FileFlush(handle); FileClose(handle);
Después, llamamos a los métodos de almacenamiento de modelos uno por uno y controlamos el proceso de las operaciones. Aquí merece la pena prestar atención a los nombres de archivo indicados. El Actor con una política conservadora recibe el sufijo de nombre de archivo "Act.nnw" (como especificamos antes para los Actores), mientras que el modelo del Actor optimista obtiene el archivo con el sufijo "ActExp.nnw". Además, solo conservamos los modelos objetivo del Crítico y el modelo v. Los modelos entrenados correspondientes no se almacenarán.
if(!CNet::Save(file_name + "Act.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- if(!cActorExploer.Save(file_name + "ActExp.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- if(!cTargetCritic1.Save(file_name + "Crt1.nnw", fLoss1, 0, 0, TimeCurrent(), common)) return false; //--- if(!cTargetCritic2.Save(file_name + "Crt2.nnw", fLoss2, 0, 0, TimeCurrent(), common)) return false; //--- if(!cZeta.Save(file_name + "Zeta.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- if(!cTargetNu.Save(file_name + "Nu.nnw", 0, 0, 0, TimeCurrent(), common)) return false; //--- return true; }
En el método de carga de datos, repetimos las operaciones siguiendo con precisión el orden de escritura de los datos. En este caso, los modelos entrenados y de destino se cargan desde los mismos archivos correspondientes.
bool CNet_SAC_DICE::Load(string file_name, bool common = true) { if(file_name == NULL) return false; //--- int handle = FileOpen(file_name + ".set", (common ? FILE_COMMON : 0) | FILE_BIN | FILE_READ); if(handle == INVALID_HANDLE) return false; if(FileIsEnding(handle)) return false; fLambda = FileReadFloat(handle); if(FileIsEnding(handle)) return false; fLambda_m = FileReadFloat(handle); if(FileIsEnding(handle)) return false; fLambda_v = FileReadFloat(handle); if(FileIsEnding(handle)) return false; iLatentLayer = FileReadInteger(handle);; FileClose(handle); //--- float temp; datetime dt; if(!CNet::Load(file_name + "Act.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cActorExploer.Load(file_name + "ActExp.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cCritic1.Load(file_name + "Crt1.nnw", fLoss1, temp, temp, dt, common) || !cTargetCritic1.Load(file_name + "Crt1.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cCritic2.Load(file_name + "Crt2.nnw", fLoss2, temp, temp, dt, common) || !cTargetCritic2.Load(file_name + "Crt2.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cZeta.Load(file_name + "Zeta.nnw", temp, temp, temp, dt, common)) return false; //--- if(!cNu.Load(file_name + "Nu.nnw", temp, temp, temp, dt, common) || !cTargetNu.Load(file_name + "Nu.nnw", temp, temp, temp, dt, common)) return false;
Una vez cargados estos modelos, los transferimos a un único contexto OpenCL.
cActorExploer.SetOpenCL(opencl); cCritic1.SetOpenCL(opencl); cCritic2.SetOpenCL(opencl); cZeta.SetOpenCL(opencl); cNu.SetOpenCL(opencl); cTargetCritic1.SetOpenCL(opencl); cTargetCritic2.SetOpenCL(opencl); cTargetNu.SetOpenCL(opencl); //--- return true; }
Con esto damos por concluido nuestro trabajo sobre la clase CNet_SAC_DICE. Encontrará el código completo de todos sus métodos en el archivo adjunto. Seguimos trabajando. Y aquí debemos recordar que en los parámetros del método de aprendizaje anteriormente analizado se especifica el vector de logaritmos de probabilidades de acciones. Pero hasta ahora no habíamos guardado esos datos en el búfer de reproducción de experiencias. Por lo tanto, ahora tenemos que añadir el array correspondiente a la estructura de descripción de estado-acción SState que se representa en el archivo "..\SAC&DICE\Trajectory.mqh". El tamaño del array es igual al número de acciones.
struct SState { float state[HistoryBars * BarDescr]; float account[AccountDescr - 4]; float action[NActions]; float log_prob[NActions]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); ArrayCopy(action, obj.action); ArrayCopy(log_prob, obj.log_prob); } };
No olvide añadir el array al algoritmo de métodos de copiado de estructuras y trabajo con archivos. El código completo de la estructura figura en el anexo.
Y pasamos a la construcción y el entrenamiento de los modelos. En cuanto a la arquitectura de los modelos, podemos decir que la trasladaremos sin cambios desde el artículo que describe el método Soft Actor-Critic. Al hacerlo, no creamos arquitecturas aparte para los modelos v y ζ. Para ellos, usamos la arquitectura del Crítico.
Para entrenar el modelo, como antes, usamos tres asesores:
- Research — recopilación de la base de datos de ejemplos
- Study — entrenamiento de modelos
- Test — comprobación de los resultados obtenidos.
Aquí hay que decir que, al recopilar los datos para la base de datos de ejemplos en el asesor Research, usamos la política optimista del Actor (archivo con sufijo "ActExp.nnw"), pero para probar el modelo entrenado, utilizaremos el modelo conservador (archivo con sufijo "Act.nnw"). Deberemos prestar atención a esto al cargar los modelos en los archivos correspondientes. Además, al recoger los datos en el búfer de reproducción de experiencias, no deberemos olvidarnos de añadir la carga del logaritmo de probabilidades de distribución de las acciones. Bueno, podrá leer el código completo de los asesores en el archivo adjunto.
Los mayores cambios se han introducido en el asesor de entrenamiento Study. Esto no resulta en absoluto sorprendente. Hemos trasladado gran parte de su funcionalidad al método Study de la clase CNet_SAC_DICE.
Vamos a comenzar modificando la biblioteca que contiene nuestro modelo.
#include "Net_SAC_DICE.mqh"
En el bloque de variables globales, declaramos un único modelo de la clase CNet_SAC_DICE que acabamos de crear. Pero al hacerlo, aumentará el número de búferes de datos. Esto se debe a que antes podíamos usar un búfer para dos estados en distintas fases del entrenamiento. Ahora debemos transmitir simultáneamente al modelo la información sobre los dos estados posteriores.
STrajectory Buffer[]; CNet_SAC_DICE Net; //--- float dError; datetime dtStudied; //--- CBufferFloat bState; CBufferFloat bAccount; CBufferFloat bActions; CBufferFloat bNextState; CBufferFloat bNextAccount;
En el método de inicialización OnInit EA, al igual que antes, cargamos primero el búfer de reproducción de experiencias para entrenar los modelos.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Después cargaremos solo un modelo. Si el modelo aún no se ha creado, formamos arrays de descripciones de la arquitectura del modelo y creamos un único modelo transmitiéndole todas las descripciones de la arquitectura. Y comprobamos el resultado de las operaciones solo una vez.
Como ya hemos mencionado, en el caso de los modelos del bloque DICE, transmitimos la descripción de la arquitectura al crítico. Pero existen otras opciones posibles. Al crear nuestros propios modelos para este bloque, debemos tener en cuenta el uso del modelo del Actor como bloque de procesamiento inicial de los datos de origen. Así es como construimos el algoritmo completo de entrenamiento del modelo. Y hay que seguirlo a la hora de crear las arquitecturas de los modelos, o bien hacer las modificaciones oportunas en el algoritmo del método.
//--- load models if(!Net.Load(FileName, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Net.Create(actor, critic, critic, critic, LatentLayer)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
Al decir "solo un modelo" estoy siendo, por supuesto, un poco socarrón. Al fin y al cabo, durante el proceso de entrenamiento creamos 6 modelos de actualización y 3 modelos objetivo. Lo único es que todos los modelos se crean dentro de nuestra nueva clase y se ocultan al usuario. En el nivel superior, trabajamos con una sola clase.
Al final del método de inicialización del asesor, generamos un evento de entrenamiento del modelo.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Después de completar con éxito todas las operaciones, finalizamos el procedimiento de inicialización del asesor.
Y a continuación comenzamos a trabajar en el procedimiento de entrenamiento directo de los modelos Train.
En el cuerpo de esta función, como antes, organizamos el ciclo de entrenamiento según el número de iteraciones especificado en los parámetros externos del asesor.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i<0) { iter--; continue; }
Dentro del ciclo, muestreamos una trayectoria y un paso aparte para la iteración actual del entrenamiento del modelo.
Acto seguido, realizamos algunos trabajos preparatorios y recopilamos los datos necesarios en los búferes de datos previamente declarados. En primer lugar, transferimos al búfer los datos históricos de la descripción del estado del entorno posterior.
//--- Target bNextState.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; if(PrevBalance==0) { iter--; continue; } bNextAccount.Clear(); bNextAccount.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); bNextAccount.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); bNextAccount.Add(Buffer[tr].States[i + 1].account[2]); bNextAccount.Add(Buffer[tr].States[i + 1].account[3]); bNextAccount.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); bNextAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
En el otro búfer, generamos una descripción del estado de la cuenta y añadimos las marcas temporales.
Del mismo modo, preparamos los búferes con las descripciones de la condición del entorno que se va a analizar.
bState.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
A continuación, transferiremos las acciones completadas al búfer. Y luego cargamos el logaritmo de probabilidades en el vector.
bActions.AssignArray(Buffer[tr].States[i].action); vector<float> log_prob; log_prob.Assign(Buffer[tr].States[i].log_prob);
En esta fase, hemos finalizado el trabajo preparatorio, recopilando en los búferes de datos todos los datos necesarios para una iteración de entrenamiento. Ahora llamamos al método de entrenamiento de nuestro modelo CNet_SAC_DICE::Study, transmitiendo en los parámetros los datos necesarios.
if(!Net.Study(GetPointer(bState), GetPointer(bAccount), GetPointer(bActions), log_prob, GetPointer(bNextState), GetPointer(bNextAccount), Buffer[tr].Revards[i] - DiscFactor * Buffer[tr].Revards[i + 1], DiscFactor, Tau)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Tenga en cuenta que hemos almacenado las recompensas en el búfer de reproducción de experiencias según el total acumulado. Ahora, transmitimos la recompensa neta de un solo paso individual al método de entrenamiento del modelo. Los datos restantes serán pronosticados por los modelos objetivo.
Todas las operaciones de entrenamiento de modelos las ponemos en nuestro método de entrenamiento de clases. Ahora solo tenemos que comprobar el resultado de las operaciones del método. A continuación, informamos al usuario sobre el proceso de entrenamiento del modelo.
if(GetTickCount() - ticks > 500) { float loss1, loss2; Net.GetLoss(loss1, loss2); string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), loss1); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), loss2); Comment(str); ticks = GetTickCount(); } }
Cuando se completan todas las iteraciones del ciclo, borramos el campo de comentarios e inicializamos el procedimiento de finalización del asesor.
Comment(""); //--- float loss1, loss2; Net.GetLoss(loss1, loss2); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", loss1); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", loss2); ExpertRemove(); //--- }
Como podemos ver, poner las operaciones de entrenamiento del modelo en un método de clase aparte nos permite reducir significativamente el gasto de código y el trabajo por parte del programa principal. Sin embargo, al mismo tiempo, este enfoque reduce la flexibilidad del proceso de aprendizaje del modelo y la capacidad del usuario para ajustarlo. Ambos enfoques tienen ventajas y desventajas. Y la elección de un enfoque concreto dependerá de la tarea a realizar y de las preferencias personales.
El código completo de este asesor, así como todos los programas utilizados en el artículo, se pueden encontrar en el archivo adjunto.
4. Simulación
El modelo se ha entrenado con los datos históricos del marco temporal H1 de EURUSD para el periodo comprendido entre enero y mayo de 2023. Tanto los parámetros de los indicadores como los hiperparámetros al completo se han utilizado por defecto. El proceso de entrenamiento ha producido un modelo capaz de generar beneficios en la muestra de entrenamiento.


El modelo ha sido capaz de obtener un 15% de beneficios en los 5 meses del periodo de entrenamiento. Se han abierto 314 posiciones, el 45,8% de las cuales se han cerrado con beneficio. La operación rentable máxima ha supuesto casi el doble de la pérdida máxima. Al mismo tiempo, la media de las operaciones rentables ha sido 1/3 superior a la media de las pérdidas. Es esta relación de beneficio y pérdidas la que ha permitido obtener un factor de beneficio de 1,13.
Pero a nosotros, como siempre, nos interesa mucho más el rendimiento del modelo con los nuevos datos. La capacidad de generalización y el rendimiento del modelo con datos desconocidos se han probado en un simulador de estrategias con datos históricos para junio de 2023. Como podemos ver, el periodo de prueba sigue inmediatamente a la muestra de entrenamiento. Esto garantiza la máxima homogeneidad de las muestras de entrenamiento y de prueba. Ahora le presentamos los resultados de las pruebas.

El gráfico presentado muestra una zona de descenso en los primeros diez días del mes. Sin embargo, le sigue un periodo de rentabilidad que dura hasta finales de mes. Como resultado, el asesor ha obtenido un beneficio del 7,7% en el mes, con una reducción máxima de la equidad del 5,46%. La reducción del balance ha sido aún menor y no ha superado el 4,87%.

La tabla de resultados muestra que durante las pruebas el asesor ha realizado operaciones comerciales multidireccionales. En total se han abierto 48 posiciones. Y el 54,17% de ellas se han cerrado con beneficios. En ese caso, la operación rentable máxima ha sido más de 3 veces superior a la operación perdedora máxima. Y la media de las operaciones rentables ha sido casi la mitad de la media de las operaciones perdedoras. En términos cuantitativos, de media, hay 2 operaciones perdedoras por cada 3 operaciones rentables. Todo ello ha proporcionado un factor de beneficio de 1,74 y un factor de recuperación de 1,41.
Conclusión
En este artículo, hemos introducido otro algoritmo de la familia Actor-Crítico, el algoritmo SAC+DICE, basado en las 2 direcciones principales de modificación del algoritmo Soft Actor-Critic. El uso del modelo optimista de exploración del entorno nos permite ampliar el ámbito de la exploración del entorno. De esta forma, la exploración se orienta a mejorar la rentabilidad de la política global. Obviamente, esto conlleva una ruptura en las distribuciones de las políticas de exploración del entorno y las políticas de aprendizaje conservadoras. Para obtener una estimación no desplazada de los gradientes, hemos utilizado un enfoque DICE modificado e introducido un factor entrenado de corrección de la distribución. Todo ello nos permite aumentar la eficacia del entrenamiento del modelo, lo cual se ha confirmado en la parte práctica de nuestro trabajo.
Además, hemos implementado el algoritmo propuesto mediante MQL5. Esta implementación ha demostrado las particularidades derivadas de sacar el proceso de entrenamiento del modelo a un método de clase aparte. Esto reduce enormemente el trabajo del programa principal y simplifica su uso.
Asimismo, hemos entrenado y probado el modelo con los nuevos datos. Los resultados de las pruebas han demostrado la eficacia de nuestra aplicación. El modelo entrenado ha sido capaz de transferir la experiencia aprendida a los nuevos datos. Además, durante las pruebas, el asesor ha obtenido beneficios.
No obstante, todos los programas presentados solo demuestran la viabilidad de la tecnología, y no están preparados para ser utilizados en los mercados financieros reales. Antes de utilizarlos, deberemos perfeccionar los asesores y realizar pruebas exhaustivas adicionales.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | Net_SAC_DICE.mqh | Biblioteca de clases | Clase de modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13055
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Dmitry, ¿por qué esta red abre todas las operaciones con exactamente 1 lote, cuando se entrena en todas las pruebas, y no intenta cambiar el lote? No intenta establecer lotes fraccionados y tampoco quiere establecer más de 1 lote. Los parámetros de entrenamiento son los mismos que los suyos.
En la última capa Actor utilizamos sigmoide como función de activación, que limita los valores en el rango [0,1]. Para TP y SL, usamos un multiplicador para ajustar los valores. El tamaño del lote no se ajusta. Por lo tanto, 1 lote es el valor máximo posible.
En la última capa Actor, utilizamos sigmoide como función de activación, que limita los valores al intervalo [0,1]. Para TP y SL utilizamos un multiplicador para ajustar los valores. El tamaño del lote no se ajusta. Por lo tanto, 1 lote es el valor máximo posible.
Entendido, Gracias.