記事"強化学習におけるモンテカルロ法の応用"についてのディスカッション
観察に貢献したい:
このバージョンの利点
*************************************
1.以前のバージョンとは異なり、このバージョンは常に取引するわけではありません。シグナルが良い時に選択的に取引します。これは、あなたのニーズを満たすための大きな利点です。それ以外は良いことです。)))..
2.素早く簡単に最適化できる。
3.トレーナーモデルのサイズが小さいので、大きなデータをトレーニングできる。
このバージョンの欠点
*******************************************
1.多くの場合、将来のパスに多くの時間がかかるため、最適化プロセスを手動で停止しなければなりません。
2.いくつかの理由により、テストを実行するのはそれほど簡単ではありません。MT5ターミナルを再起動しなければならず、それでもうまくいかないことがある。
私の改善提案
*************************************
1.open、close、high、lowなど、少なくとも4~5つの入力関数をトレーニングに使用してみてください。
2.取引シグナルの取得を最適化する際に、「MathMoments()」関数を 適切に使用するようにしてください:
https:// www.mql5.com/en/docs/standardlibrary/mathematics/stat/mathsubfunctions/statmathmoments
3.日または週単位で反復トレーニングコースを実施してみる。
これはランダム化された結果である。
4.複数の期間を試す。
私はこれをしなければならない。どうしたらもっとうまくできるだろうか :))))

- www.mql5.com
モンテカルロ 法は確かにランダム・プロセスを研究するのに有効な方法である。しかし、この手法の適用には(他の手法と同様に)プロセスの性質(私たちにとっては金融市場)を考慮に入れる 必要がある 。
現代分析の問題点は、これまでのところ、伝統的なTAも他の手法も、市場の値動きの基本的な構造(物理学における原子のようなもの)を明らかにできていないこと、また、利用可能な構造(TAパターン、エリオット波動など )は 、分析に連続的でない(曖昧に現れたり、稀に現れたりする)ため、基本的でないことである。したがって、最新の手法を使うことは、いわゆる「最良のモデル」をブルートフォース法(この場合はモンテカルロ法)で盲目的に探すことに近い。
しかし、これはアナリティクス業界全体の問題である。そして著者は、手法の枠組みの中で、 独創的な 解決策を示してくれた!
このトピックの他の参加者や運営側のズグンダーが秘密裏にマウスをいじっているにもかかわらず、MOへのオープンで建設的なアプローチに対して、また興味深い記事を書いてくれた著者に敬意を表します:)
ジグザグの頂点や同じリターンの値によって、ターゲットはほぼ明確に決定論的であり、桁違いに速く見つけることができるからです。
IMHOは、予測変数の選択と順位付けのような、はるかに不確実で多次元的な問題にこの方法を適用する方が合理的であると考える。理想的には、この問題を解決するとき、予測変数は複合体で評価されるべきであり、記事で説明されている各個別の検索と代替トレーニングは、1つの未知数を持つ方程式系のように見える。
このトピックの他の参加者や管理側のズグンダーが秘密裏にマウスをいじっているにもかかわらず、MOへのオープンで建設的なアプローチに対して、また興味深い記事を書いてくれた著者に敬意を表します:)
ジグザグの頂点や同じリターンの値に従って、ほぼ明確に決定論的であり、桁違いに速く見つけることができるからです。
IMHOは、予測変数の選択とランキングのような、より不確実で多次元的な問題にこの方法を適用する方がより合理的であると考える。理想的には、この問題を解くとき、予測変数は複合的に評価されるべきであり、記事で説明されている各々別々に検索し交互にトレーニングすることは、1つの未知数で連立方程式を構成しているように見えます。
このトピックの他の参加者や管理側のズグンダーが秘密裏にマウスをいじっているにもかかわらず、MOへのオープンで建設的なアプローチに対して、また興味深い記事を書いてくれた著者に敬意を表します:)
ジグザグの頂点や同じリターンの値に従って、ほぼ明確に決定論的であり、桁違いに速く見つけることができるからです。
IMHOは、予測変数の選択とランキングのような、より不確実で多次元的な問題にこの方法を適用する方がより合理的であると考える。理想的には、この問題を解くとき、予測変数は複合的に評価されるべきであり、記事で説明されているような、それぞれ別々に検索し、交互にトレーニングすることは、1つの未知数で連立方程式を構成しているように見える。
TAの数値や「リターン」は分析する上で非常に曖昧で信頼できないものだからだ。
したがって、著者はそれらを使わず、モンテカルロ法で実験している。
こんにちは、マキシム。
一つ質問があります。
"shift_probab "と "regularisation" 使用されている値は、最適化のためだけであり、ライブ取引の コースではありません。正しいですか?
それとも、最適化されたshift_probabとregularisationの値は、ライブ取引のために最適化が完了した後にチャート上に設定する必要がありますか?
ありがとうございます。
こんにちは、モンテカルロ法では、RLのすべての規範に従って、ターゲットのランダムな列挙が行われます。つまり、多くの戦略(ステップ)があり、エージェントはOOSの最小誤差を通して最適なものを探索します。新しい特徴の構築は、MSUAを介してライブラリの1つに実装されている(コードベース参照)。本稿では、新しいフィーチャを構築することなく、既存のフィーチャを総当たりで探索する。再帰的消去法を参照。つまり、フィッシュとターゲットの両方が再帰的に消去される。後で、私は他のバリエーションを提案することができる。しかし、比較テストには多くの時間がかかる。
もちろん、行動のランダム選択はRLの規範であり、さらに、エージェントの異なる行動が環境を変化させ、無限大に近い数の変種を生成する可能性があるため、それは必要かもしれない。
しかし、我々の場合、環境 - 市場相場 - はエージェントの行動には依存しません。特に、考慮されている実装では、過去の既知のデータが使用されます。
P.S. 例えば、https://www.mql5.com/ja/code/9234 の相場によって、可能な限り利益が最大となる目標取引順序を見つけることが可能です。

- www.mql5.com
こんにちは、マキシム。
一つ質問があります。
"shift_probab "と "regularisation" 使用されている値は、最適化のためだけであり、ライブ取引の コースではありません。正しいですか?
それとも、最適化されたshift_probabとregularisationの値は、ライブ取引のために最適化が完了した後にチャート上に設定する必要がありますか?
ありがとうございます。
もちろん、アクションのランダムな選択はRLの規範であり、さらに、エージェントの異なるアクションが環境を変化させる可能性があるため、それは必要かもしれません、それは無限大のオプションの数を生成し、もちろんモンテカルロは、そのようなアクションのシーケンスを最適化するために適用されるかもしれません。
しかし、我々の場合、環境 - 市場相場 - はエージェントの行動には依存しません。特に、検討した実装では、過去の既知のデータが使用されます。したがって、エージェントの一連の行動(取引)の選択は、確率的手法なしで行うことができます。
P.S. 例えば、https://www.mql5.com/ja/code/9234。
TAの数字や "リターン "は非常に曖昧で、分析するには信頼できないものだからだ。
したがって、著者はそれらを使わず、モンテカルロ法で実験している。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事 強化学習におけるモンテカルロ法の応用 はパブリッシュされました:
自己学習を行うEAを作成するためのReinforcement learningの適用。前回の記事では、Random Decision Forestアルゴリズムを学び、Reinforcement learning(強化学習)に基づく簡単な自己学習EAを作成しました。このアプローチの主な利点は、取引アルゴリズムを書くことの単純さと『学習」の高速性でした。強化学習(以下、単にRL)は、どのEAにも簡単に組み込むことができ、最適化のスピードを上げられます。
最適化を停止したら、シングルテストモードをオンにします(最良のモデルがファイルに書き込まれ、それだけがロードされるため)。
2か月前の履歴をスクロールして、モデルが4か月全体にわたってどのように機能するかを見てみましょう。
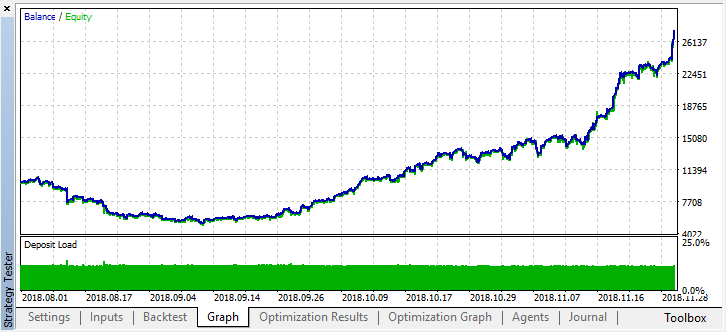
結果として得られたモデルは、8月に故障し、もう1か月(ほぼ9月全体)続いたことがわかります。作者: Maxim Dmitrievsky