Обсуждение статьи "Скрытые марковские модели в торговых системах на машинном обучении"
Затем, следует скомпилировать приложенного в конце статьи бота и протестировать его в тестере MetaTrader 5.
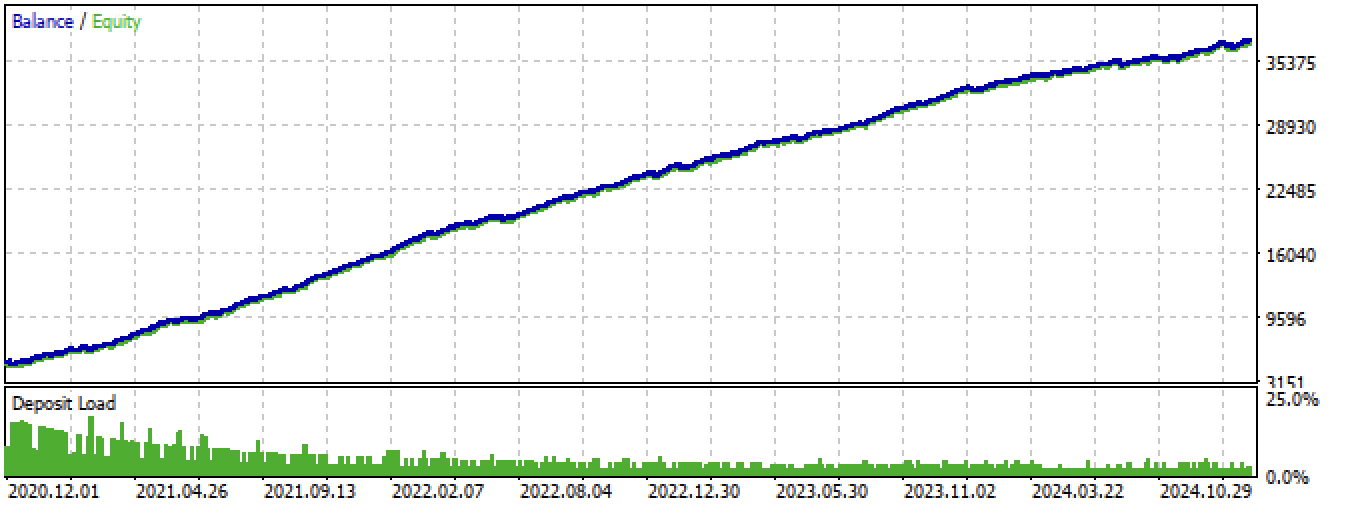
Рис 14. тестирование лучшей модели в терминале Meta Trader 5 за весь период
Архив MQL5 files.zip cодержит файлы для терминала MetaTrader 5
Просьба сделать стандартом публикацию и соответствующих tst-файлов выложенных в статьях результатов бэктестов. Спасибо.
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Опубликована статья Скрытые марковские модели в торговых системах на машинном обучении:
Скрытые марковские модели (СММ) представляют собой мощный класс вероятностных моделей, предназначенных для анализа последовательных данных, где наблюдаемые события зависят от некоторой последовательности ненаблюдаемых (скрытых) состояний, которые формируют марковский процесс. Основные предположения СММ включают марковское свойство для скрытых состояний, означающее, что вероятность перехода в следующее состояние зависит только от текущего состояния, и независимость наблюдений при условии знания текущего скрытого состояния.
Библиотека hmmlearn представляет собой набор алгоритмов на языке Python для обучения без учителя (скрытых марковских моделей). Она разработана с целью предоставить простые и эффективные инструменты для работы с СММ, следуя API библиотеки scikit-learn, что облегчает интеграцию в существующие проекты машинного обучения и упрощает процесс обучения для пользователей, знакомых с scikit-learn. Hmmlearn построена на базе таких фундаментальных библиотек научного Python, как NumPy, SciPy и Matplotlib.
Основные возможности hmmlearn включают реализацию различных моделей СММ с разными типами эмиссионных распределений, обучение параметров моделей по наблюдаемым данным, вывод наиболее вероятных последовательностей скрытых состояний, генерацию выборок из обученных моделей, а также возможность сохранения и загрузки обученных моделей. Разнообразие реализованных моделей позволяет пользователям выбирать наиболее подходящий тип эмиссионного распределения в зависимости от характера их данных. Тип данных (непрерывные, дискретные, счетчики) определяет, какое вероятностное распределение лучше всего описывает процесс генерации наблюдений в каждом скрытом состоянии.
Автор: Maxim Dmitrievsky