
機械学習の限界を克服する(第1回):相互運用可能な指標の欠如

残念ながら、「ベストプラクティス」に盲目的に従う危険性は、取引戦略で頼りにしている他のツールにも静かに影響を及ぼします。この問題はテクニカル指標に限ったものではないと、トレーダーは理解しておく必要があります。
本連載記事では、アルゴリズムトレーダーが日々直面している重要な問題を探ります。それは、機械学習モデルの使用時に安全を確保するためのガイドラインやプラクティスによってもたらされる問題です。簡単に言えば、もしMQL5クラウドで毎日展開される機械学習モデルが、トレーダーより先にこの議論で提示された事実を認識していれば、問題は避けられません。投資家は、予想以上のリスクに直面しかねません。
正直なところ、このような問題は、世界の主要な統計学習の書籍でも十分に強調されていません。本稿で扱う問題は、コミュニティのすべてのトレーダーが知っておくべき単純な真実です。
「RMSE、MAE、MSEのようなユークリッド分散指標の一次導関数は、目的変数の平均によって解けることが解析的に証明できます。」
この事実とその含意をすでに理解しているトレーダーは、ここから先を読む必要はありません。
しかし、この意味を理解していないトレーダーに対して、私は本稿を通して強く伝えたいのです。簡単に言えば、私たちがモデル構築に使用する回帰指標は、資産収益のモデリングには適していません。
本稿では、この現象がどのように起こるのか、それがあなたにとってどのような危険をもたらすのか、そして数百ある潜在的市場の中から取引対象を選ぶ際に、この原則を羅針盤として活用するための変更方法を順を追って説明します。
より深い証拠を求めるトレーダーには、ハーバード大学の文献でRMSEなどの指標の限界について論じられた資料があります。特にハーバードの論文では、サンプルの平均がRMSEを最小化することを分析的に証明しています。論文はこちらから参照可能です。
また、Social Science Research Network (SSRN)などの機関は、さまざまな分野からの査読済み論文を掲載したジャーナルを維持しており、資産価格タスクのためにRMSEを代替する損失関数を探求した論文も存在します。本稿では、読者向けに選定した論文を紹介します。この論文では、分野内の他の論文をレビューし、現行の文献の要約を提供した上で、新しいアプローチを示しています。この論文もこちらから容易にアクセス可能です。
思考実験(誰もが理解できるはず)
想像してみてください。あなたは宝くじスタイルのコンペティションに参加しています。あなたと他の99人の参加者がランダムに選ばれ、1,000,000ドルのジャックポットを競います。ルールはシンプルで、他の99人の身長を予測することです。勝者は、99人の予測の合計誤差が最も小さい人です。
さて、ここでひとつひねりを加えます。この例では、世界の平均身長が1.1メートルだと仮定します。もし単純に全員に対して1.1メートルと予測した場合、技術的にはすべての予測が間違っていても、実際にジャックポットに当たる可能性があります。なぜでしょうか。ノイズや不確実性の高い環境では、平均値を予測することが総合的な誤差を最小化する傾向があるからです。
取引への類推
この思考実験は、読者に対して、金融市場で使用される機械学習モデルがどのように選択されるかをドラマ化するためのものです。
たとえば、S&P500のリターンを予測するモデルを構築するとします。指数の過去の平均リターン、年間およそ7%を常に予測するモデルは、RMSE、MAE、MSEなどの指標で評価すると、より複雑なモデルよりも実際に良い成績を収めることがあります。しかしここに落とし穴があります。そのモデルは何も学習していません。ただ統計的平均に収束しているだけです。さらに悪いことに、あなたが信頼した評価指標や検証手法は、その「平均予測」を正当に評価してしまいます。
初心者向け注釈:RMSE (Root Mean Square Error)は、実数値の目的変数を予測する機械学習モデルの性能を評価するための「単位」です。
大きな誤差を罰する性質がありますが、なぜモデルが誤差を出したのかは考慮されません。しかし、これらの誤差の中には、実際には利益につながるものも含まれています。
つまり、市場理解がゼロでも、平均値を常に予測するモデルは、RMSEで評価すると紙上では優秀に見えるのです。残念ながら、これにより、数学的には正しいが実務的には無用なモデルを作ってしまうことになります。
実際に何が起きているのか
金融データはノイズが多いです。真の世界的な需給、投資家心理、機関投資家の注文深度などの重要な変数は観測できません。そのため、誤差を最小化するために、モデルは最も統計的に論理的なことを行います。平均値を予測するのです。
読者には理解してほしいことがあります。これは数学的には正しい手法です。平均値を予測することは、多くの回帰誤差を最小化します。しかし、取引とは統計誤差を最小化することではなく、不確実性の下で利益を上げる意思決定です。この違いが重要です。私たちのコミュニティでは、この行動は過学習に似ています。しかし、これらのモデルを構築した統計学者たちは、私たちとは見方が異なっていました。
この問題は回帰モデルに特有ではありません。分類タスクでも、モデルは訓練データで最も頻出するクラスを常に予測することで、誤差を最小化できます。そして、訓練データで最大のクラスが全体母集団でも最大のクラスに一致する場合、モデルが容易にスキルを装うことができることは明白です。
リワードハッキング:モデルがズルで勝つ場合
この現象は「リワードハッキング」と呼ばれます。モデルが望ましいパフォーマンスを達成する一方で、望ましくない行動を学習している状態です。取引の場合、リワードハッキングにより、トレーダーはスキルがあるように見えるモデルを選択してしまいます。しかし実際には、モデルは単に平均値ゲームをしているだけです。「全員が1.1メートル」と言っているのと統計的には同じことです。そしてRMSEは、何の疑問もなくそれを受け入れます。
実際の証拠
動機が明確になったところで、比喩を離れ、実際の市場データを考えてみます。MetaTrader 5のPython APIを使用して、ブローカーから333市場のデータを取得しました。4年以上の実際の過去データがある市場にフィルタリングすると、119市場に絞られました。
その後、各市場に対して2種類のモデルを構築しました。
- コントロールモデル:常に10日間リターンの平均を予測
- 予測モデル:将来リターンを学習し予測
結果
テストした市場の91.6%で、コントロールモデルが勝ちました。つまり、過去4年間の10日間平均リターンを常に予測するモデルが、91%の市場で誤差を最小化しました。トレーダーがすぐに理解するように、より深いニューラルネットワークを試しても、改善はほとんどありませんでした。
では、トレーダーは機械学習の「ベストプラクティス」に従い、最も誤差の少ないモデル(常に平均リターンを予測するモデル)を選ぶべきでしょうか。
初心者向け注釈:これは、機械学習があなたの取引に役立たないという意味ではありません。重要なのは、「良いパフォーマンス」を取引コンテキストでどのように定義するかを非常に慎重に考える必要がある、ということです。慎重でなければ、平均市場リターンを予測することで報酬を得ているモデルを、知らずに選んでしまう可能性があります。
今後の課題
結論は明確です。現在使用している評価指標(RMSE、MSE、MAE)は、取引のために設計されたものではありません。これらは統計学、医学、自然科学などで生まれ、平均を予測することが合理的な状況に適しています。しかし、私たちのアルゴリズム取引コミュニティでは、平均リターンを予測することは、予測を持たない場合よりも悪いことすらあります。理解のないAIは決して安全ではありません。
私たちは、有益なスキルを正当に評価する評価フレームワークが必要です。利益と損失を理解する指標が必要です。また、平均に偏った行動を罰し、モデルがコミュニティの価値観を学びながら取引の現実を理解するよう促す訓練プロトコルも必要です。 本連載では、そうした一連の課題に焦点を当てます。市場自体が生み出す問題ではなく、私たちが使用したいツール自体から生じる独特な問題です。他の記事、統計学習の学術書、あるいはコミュニティ内の議論でもほとんど取り上げられません。
トレーダーは、自分の安全のためにこれらの事実を十分に理解する必要があります。残念ながら、これらの制約の基本的な認識は、コミュニティのすべてのメンバーが容易に得られる知識ではありません。日々のトレーダーは、非常に危険な統計的手法を躊躇なく繰り返しています。
はじめに
これまで議論してきたことに何かメリットがあるかどうか見てみましょう。標準ライブラリを読み込みます。
import pandas as pd import numpy as np import matplotlib.pyplot as plt import MetaTrader5 as mt5 import multiprocessing as mp
どのくらい先の将来を予測したいかを定義します。
HORIZON = 10実際の市場データを取得できるように、MetaTrader 5端末を読み込みます。
if(not mt5.initialize()): print("Failed to load MT5")
利用可能なすべての銘柄の包括的なリストを取得します。
symbols = mt5.symbols_get()
銘柄の名前を抽出します。
symbols[0].name
symbol_names = []
for i in range(len(symbols)):
symbol_names.append(symbols[i].name)次に、常に平均値を予測するモデルを上回ることができるかどうかを確認する準備をしましょう。
from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,cross_val_score
時系列検証スプリッターを作成します。
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)常に平均市場リターンを予測した場合の誤差と、将来の市場リターンを予測しようとした場合の誤差を返す方法が必要です。
def null_test(name): data_amount = 365 * 4 f_data = pd.DataFrame(mt5.copy_rates_from_pos(name,mt5.TIMEFRAME_D1,0,data_amount)) if(f_data.shape[0] < data_amount): print(f"{symbol_names[i]} did not have enough data!") return(None) f_data['time'] =pd.to_datetime(f_data['time'],unit='s') f_data['target'] = f_data['close'].shift(-HORIZON) - f_data['close'] f_data.dropna(inplace=True) model = Ridge() res = [] res.append(np.mean(np.abs(cross_val_score(model,f_data.loc[:,['open']] * 0,f_data['target'],cv=tscv)))) res.append(np.mean(np.abs(cross_val_score(model,f_data.loc[:,['open','high','low','close']],f_data['target'],cv=tscv)))) return(res)
ここで、利用可能なすべての市場でテストを実行します。
res = pd.DataFrame(columns=['Mean Forecast','Direct Forecast'],index=symbol_names) for i in range(len(symbol_names)): test_score = null_test(symbol_names[i]) if(test_score is None): print(f"{symbol_names[i]} does not have enough data!") res.iloc[i,:] = [np.nan,np.nan] continue res.iloc[i,0] = test_score[0] res.iloc[i,1] = test_score[1] print(f"{i/len(symbol_names)}% complete.") res['Score'] = ((res.iloc[:,1] / res.iloc[:,0])) res.to_csv("Deriv Null Model Test.csv")
0.06606606606606606% complete.
0.06906906906906907% complete.
0.07207207207207207% complete.
...
GBPUSD RSI Trend Down Index did not have enough data!
GBPUSD RSI Trend Down Index does not have enough data!
利用可能なすべての市場のうち、いくつの市場を分析できたのでしょうか。
#How many markets did we manage to investigate? test = pd.read_csv("Null Model Test.csv") print(f"{(test.dropna().shape[0] / test.shape[0]) * 100}% of Markets Were Evaluated")
35.73573573573574% of Markets Were Evaluated
次に、119市場を、それぞれの市場に関連付けられたスコアに基づいてグループ化します。このスコアは、市場を予測した際の誤差と、常に平均リターンを予測した場合の誤差の比率として計算されます。スコアが1未満であれば印象的です。なぜなら、それは平均リターンを常に予測するモデルよりも優れたパフォーマンスを示していることを意味するからです。一方、スコアが1を超える場合は、本稿冒頭で述べた動機を裏付けるものとなります。
初心者向け注釈:ここで簡単に説明したスコアリング方法は、機械学習において特に目新しいものではありません。一般的に決定係数として知られる指標で、提案モデルが目的変数の分散のどれだけを説明できているかを示します。ただし、ここで使用するスコアは、独学で学んだr²の厳密な公式とは異なります。
まず、スコアが1未満となった市場をすべてグループ化してみましょう。
res.loc[res['Score'] < 1]
| 市場名 | 平均予測 | 直接予測 | スコア |
|---|---|---|---|
| AUDCAD | 0.022793 | 0.018566 | 0.814532 |
| EURCAD | 0.037192 | 0.027209 | 0.731587 |
| NZDCAD | 0.019124 | 0.015117 | 0.790466 |
| USDCNH | 0.125586 | 0.112814 | 0.898297 |
テストしたすべての市場のうち、4年間にわたって常に平均市場リターンを予測するモデルよりも優れたパフォーマンスを示した市場の割合は、約8%です。
res.loc[res['Score'] < 1].shape[0] / res.shape[0]
0.08403361344537816
したがって、4年間にわたって、テストしたすべての市場のうち約91.6%で、常に平均リターンを予測するモデルを上回ることができなかったことになります。
res.loc[res['Score'] > 1].shape[0] / res.shape[0]
0.9159663865546218
この時点で、一部の読者は「著者は単純な線形モデルを使っただけだ。もっと柔軟なモデルを時間をかけて構築すれば、常に平均リターンを予測するモデルを上回れるはずだ。これはナンセンスだ」と考えているかもしれません。しかしこれは部分的に正しい指摘です。まず、EURUSDの為替レートに関する詳細な市場情報を取得するために、
MQL5スクリプトが必要です。私たちは4つの価格レベルそれぞれの変動、およびそれらの間の相互変動を記録します。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| File name | //+------------------------------------------------------------------+ string file_name = Symbol() + " IID Candlestick Recognition.csv"; //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int size = 3000; input int HORIZON = 10; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","Delta Open","Delta High","Delta Low","Delta Close","O - H","O - L","O - C","H - L","H - C","L - C"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON
次に、作成したスクリプトをチャート上にドラッグ&ドロップして、市場の過去データを取得します。その後、作業を開始できます。
#Read in market data HORIZON = 10 data = pd.read_csv('EURUSD IID Candlestick Recognition.csv') #Label the data data['Null'] = 0 data['Target'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last HORIZON rows of data data = data.iloc[:-HORIZON,:] data
平均市場リターンを予測するモデルを上回る問題が、ディープニューラルネットワークや高度なモデルで解決できると思っている読者は、本稿の残りの部分を読むと驚くことでしょう。
モデルを自己資金で運用する前に、ぜひご自身のブローカーでこの実験を繰り返すことをお勧めします。では次に、scikit-learnのツールを読み込み、私たちのディープニューラルネットワークが、単純な線形モデルと比べてどの程度優れているかを比較してみましょう。
#Load our models from sklearn.neural_network import MLPRegressor from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,train_test_split,cross_val_score
データを分割します。
#Split the data into half train,test = train_test_split(data,test_size=0.5,shuffle=False)
時系列検証オブジェクトを作成します。
#Create a time series validation object tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)
常に平均市場収益を予測するモデルを適合させます。 常に平均値を予測することで生じる誤差は「総平方和(TSS: Total sum of squares)」と呼ばれます。TSSは機械学習における重要な誤差ベンチマークであり、私たちに「どちらが正しい方向か」を示す指標のようなものです。
#Fit the model predicting the mean on the train set null_model = Ridge() null_model.fit(train[['Null']],train['Target']) tss = np.mean(np.abs(cross_val_score(null_model,test[['Null']],test['Target'],cv=tscv,scoring='neg_mean_absolute_error'))) tss
np.float64(0.011172426520738554)
入力データと目的変数を定義します。
X = data.iloc[:,4:-2].columns y = 'Target'
ディープニューラルネットワークを適合させます。読者の皆さんには、このニューラルネットワークを自由に調整して、自分に平均値を上回る力があるか試してみることをお勧めします。
#Let us now try to outperform the null model model = MLPRegressor(activation='logistic',solver='lbfgs',random_state=0,shuffle=False,hidden_layer_sizes=(len(X),200,50),max_iter=1000,early_stopping=False) model.fit(train.loc[:,X],train['Target']) rss = np.mean(np.abs(cross_val_score(model,test.loc[:,X],test['Target'],cv=tscv,scoring='neg_mean_absolute_error'))) print(f"Test Passed: {rss < tss} || New R-Squared Metric {rss/tss}") res = [] res.append(rss) res.append(tss) sns.barplot(res,color='black') plt.axhline(tss,color='red',linestyle=':') plt.grid() plt.ylabel("RMSE") plt.xticks([0,1],['Deep Neural Network','Null Model']) plt.title("Our Deep Neural Network vs The Null Model") plt.show()
多くの設定調整や最適化の結果、ディープニューラルネットワークを用いて平均リターンを予測するモデルを上回ることに成功しました。しかし、ここで何が起きているのかをもう少し詳しく見てみましょう。

図1:平均市場リターンを予測するモデルを上回ることは非常に困難である
では、ディープニューラルネットワークがどのように改善しているかを可視化してみましょう。まず、テストセットにおける市場リターンの分布と、モデルが予測したリターンの分布を評価するためのグリッドを設定します。そして、モデルがテストセットに対して予測したリターンを保存します。
predictions = model.predict(test.loc[:,X])
まず最初に、トレーニングセットで観測された平均市場リターンを、グラフ中央の赤い点線としてマークします。
plt.title("Visualizing Our Improvements")
plt.plot()
plt.grid()
plt.xlabel("Return")
plt.axvline(train['Target'].mean(),color='red',linestyle=':')
legend = ['Train Mean']
plt.legend(legend)
図2:トレーニングセットからの平均市場リターン
次に、テストセットに対するモデルの予測を、トレーニングセットの平均リターンの上に重ねて表示してみましょう。ご覧の通り、モデルの予測はトレーニングセットの平均値の周りに分布しています。しかし、本当の問題は、市場が実際に辿った分布を黒いグラフとして下に重ねて表示すると、明確になります。
plt.title("Visualizing Our Improvements") plt.plot() plt.grid() plt.xlabel("Return") plt.axvline(train['Target'].mean(),color='red',linestyle=':') sns.histplot(predictions,color='blue') legend = ['Train Mean','Model Predictions'] plt.legend(legend)
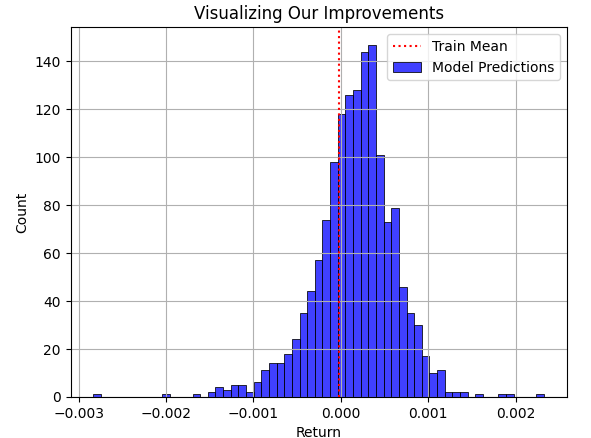
図3:トレーニングセットでモデルが観測した平均リターンに関するモデルの予測
図3では、モデルが生成した予測の青い領域は一見妥当な範囲に見えました。しかし、図4で市場が実際に辿った真の分布を考慮すると、このモデルが今回のタスクには適していないことが明らかになります。モデルは市場の真の分布の幅を捉えられておらず、その結果、最も大きな利益や損失の一部がモデルの視野から隠れてしまっています。残念ながら、RMSEはその性質を十分に理解し尊重し解釈しない限り、トレーダーをこうしたモデルに導きがちです。このようなモデルを実際の取引に使用すると、壊滅的な結果をもたらしかねません。
plt.title("Visualizing Our Improvements") plt.plot() plt.grid() plt.xlabel("Return") plt.axvline(train['Target'].mean(),color='red',linestyle=':') sns.histplot(test['Target'],color='black') sns.histplot(predictions,color='blue') legend = ['Train Mean','Test Distribution','Model Prediction'] plt.legend(legend)
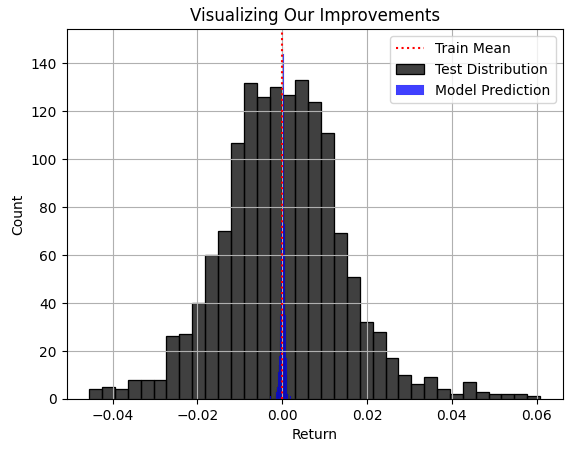
図4:市場の真の分布に関するモデルの予測の分布
提案される解決策
ここまでで、読者にはRMSEのような指標が、常に平均市場リターンを予測することで簡単に最適化できることを示しました。また、そのようなモデルが実務的に魅力的でない理由も示しました。なぜなら、RMSEはこのような無意味なモデルが「私たちが達成できる最善」と報告してしまうことが頻繁にあるからです。ここで明確にしたいのは、次のことを明示的に評価・促進する手法や新しい技術が必要である、という点です。
- 実世界の市場理解をテストすること
- 利益と損失の違いを理解すること
- 平均への偏り行動を抑制すること
私は、読者が検討できる可能性のあるユニークなモデルアーキテクチャを提案したいと思います。この戦略を「動的レジーム切り替えモデル(DRS: Dynamic Regime Switching Models)」と呼びます。高確率のセットアップに関する別の記事では、直接市場を予測するよりも、取引戦略によって生成される利益/損失をモデル化する方が簡単である場合があることを観察しました。この関連記事をまだ読んでいない読者は、リンクから参照可能です。
ここで、この観察を面白い形で活用してみましょう。まず、1つの取引戦略の反対バージョンをシミュレートするために、2つの同一モデルを構築します。1つ目のモデルは常に市場がトレンドフォロー状態にあると仮定します。もう1つのモデルは常に市場が平均回帰状態にあると仮定します。各モデルは別々にトレーニングされ、互いの予測に関して認識や協調手段は持ちません。
効率的市場仮説が教えるところを思い出してください。すべての資産を同じ量だけ買いと売りを同時におこなえば、投資家は完全にヘッジされ、ポジションを同時に開閉すれば総利益は0になります(取引手数料は除く)。したがって、私たちのモデルも常にこの事実と一致することが期待されます。実際、モデルがこの真実と一致しているかをテストできます。真実と一致しないモデルは、真の市場理解を持っていないことになります。
したがって、RMSEのような指標に依存する代わりに、DRSモデルが市場構造を構築する原理を理解しているかどうかをテストすることができます。ここで実世界の市場理解をテストする意味があります。もし両モデルが取引の現実を真に理解しているなら、両モデルの予測の合計は常に0になるはずです。トレーニングセットでモデルを適合させ、アウトオブサンプルでテストして、モデルの予測が過負荷状態でも常に合計0になるかどうかを確認します。
ここで注意すべきは、モデルの予測は一切協調されていないということです。モデルは別々に学習され、互いを認識していません。したがって、モデルが望ましい誤差指標を「ハック」しているのではなく、真に市場の構造を学習している場合、両モデルの予測の合計が0であれば、その予測は倫理的に導かれたものだと証明されます。
任意の時点で、これらのモデルのうち1つだけが正の報酬を期待できます。もし予測の合計が0でない場合、モデルは効率的市場仮説に反する方向性バイアスを学習してしまった可能性があります。一方、最良のシナリオでは、これら2つの市場状態を動的に切り替えることができ、過去には得られなかったレベルの自信を持つことができます。任意の瞬間に正の報酬を期待できるのは1つのモデルのみであり、私たちの取引哲学では、そのモデルが市場の現在の隠れ状態に対応していると考えます。そして、この考え方は、低いRMSEの数値よりも私たちにとって価値がある可能性があります。
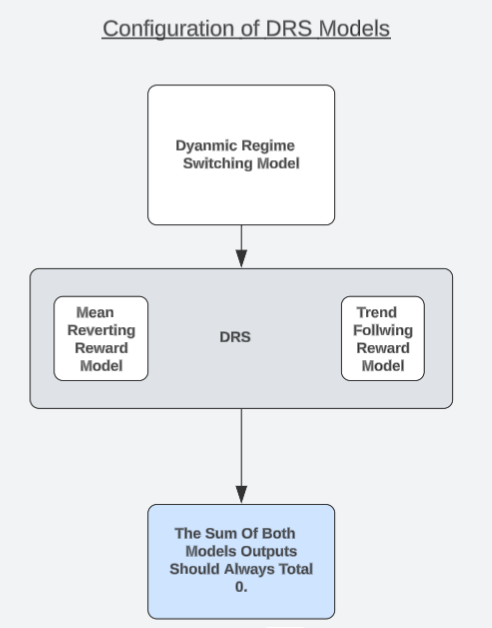
図5:DRSモデルの一般的なアーキテクチャ
端末からのデータ取得
最良の結果を得るためには、データは可能な限り詳細である必要があります。したがって、現在のテクニカル指標や価格レベルの値だけでなく、同時にこれらの市場ダイナミクスで発生している変動も追跡して記録しています。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define HORIZON 10 //--- Our handlers for our indicators int ma_handle; //--- Data structures to store the readings from our indicators double ma_reading[]; //--- File name string file_name = Symbol() + " DRS Modelling.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","Delta O","Delta H","Delta Low","Delta Close","SMA 5","Delta SMA 5"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), ma_reading[i], ma_reading[i] - ma_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
はじめに
まず最初に、標準ライブラリをインポートします。
#Load our libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
これで、先ほどCSVに書き出したデータを読み込むことができます。
#Read in the data data = pd.read_csv("/content/drive/MyDrive/Colab Data/Financial Data/FX/EUR USD/DRS Modelling/EURUSD DRS Modelling.csv") data
MQL5スクリプトを構築したとき、私たちは10ステップ先の未来を予測していました。それを維持します。
#Recall that in our MQL5 Script our forecast horizon was 10 HORIZON = 10 #Calculate the returns generated by the market data['Return'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last horizon rows data = data.iloc[:-HORIZON,:]
次にデータにラベルを付けます。ここで2種類のラベルを用意します。1つ目は常に市場がトレンドを継続すると仮定するラベル、もう1つは常に市場が平均回帰の状態にあると仮定するラベルです。
#Now let us define the signals being generated by the moving average, in the DRS framework there are always at least n signals depending on the n states the market could be in #Our simple DRS model assumes only 2 states #First we will define the actions you should take assuming the market is in a trending state #Therefore if price crosses above the moving average, buy. Otherwise, sell. data['Trend Action'] = 0 data.loc[data['Close'] > data['SMA 5'], 'Trend Action'] = 1 data.loc[data['Close'] < data['SMA 5'], 'Trend Action'] = -1 #Now calculate the returns generated by the strategy data['Trend Profit'] = data['Trend Action'] * data['Return']
トレンドに従うアクションにラベルを付けた後、平均回帰アクションを挿入します。
#Now we will repeat the procedure assuming the market was mean reverting data['Mean Reverting Action'] = 0 data.loc[data['Close'] > data['SMA 5'], 'Mean Reverting Action'] = -1 data.loc[data['Close'] < data['SMA 5'], 'Mean Reverting Action'] = 1 #Now calculate the returns generated by the strategy data['Mean Reverting Profit'] = data['Mean Reverting Action'] * data['Return']
このようにデータにラベルを付けることで、コンピュータが各戦略が損失を出す条件や、どの戦略に従うべきかを学習できることを期待しています。累積目的変数の値をプロットすると、選択した期間においてEURUSD市場は、トレンドフォローよりも平均回帰的な挙動を示す時間の方が長かったことが明確にわかります。しかし、両方の線には突然のショックが見られます。私はこれらのショックが、市場における急激なレジーム変化に対応している可能性があると考えています。
#If we plot our cumulative profit sums, we can see the profit and losses aren't evenly distributed between the two states plt.plot(data['Trend Profit'].cumsum(),color='black') plt.plot(data['Mean Reverting Profit'].cumsum(),color='red') #The mean reverting strategy appears to have been making outsized profits with respect to the trending stratetefgy #However, closer inspection reveals, that both strategies are profitable, but never at the same time! #The profit profiles of both strategies show abrupt shocks, when the opposite strategy become more profitable. plt.legend(['Trend Profit','Mean Reverting Profit']) plt.xlabel('Time') plt.ylabel('Profit/Loss') plt.title('A DRS Model Visualizes The Market As Being in 2 Possible States') plt.grid() plt.axhline(0,color='black',linestyle=':')
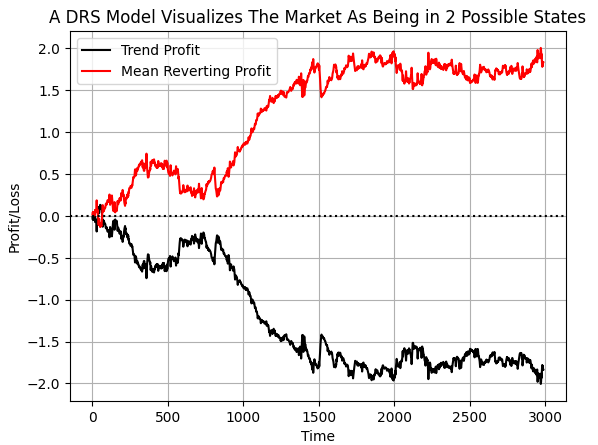
図6:2つの相反する戦略における利益の分配
入力データと目的変数を定義します。
#Let's define the inputs and target X = data.iloc[:,1:-5].columns y = ['Trend Profit','Mean Reverting Profit']
市場をモデリングするためのツールを選択します。
#Import the modelling tools from sklearn.model_selection import train_test_split,TimeSeriesSplit from sklearn.ensemble import RandomForestRegressor
データを2回分割します。トレーニングセット、検証セット、最終テストセットが作成されます。
#Split the data train , test = train_test_split(data,test_size=0.5,shuffle=False) f_train , f_validation = train_test_split(train,test_size=0.5,shuffle=False)
2つのモデルを準備します。両方のモデルは世界を二重視点(Dual-View)で捉えますが、いかなる方法でも互いに協調させてはいけません。
#The trend model trend_model = RandomForestRegressor() #The mean reverting model mean_model = RandomForestRegressor()
モデルに適合させます。
trend_model.fit(f_train.loc[:,X],f_train.loc[:,y[0]]) mean_model.fit(f_train.loc[:,X],f_train.loc[:,y[1]])
モデルの妥当性をテストします。テストセットにおける各モデルの目的変数がどの値を取るかの予測を記録します。ここで重要なのは、モデルは同じ目的変数を学習しているわけではないという点です。各モデルは独立して自身の目的変数を学習し、他のモデルに依存せずに誤差を最小化するように訓練されています。
pred_1 = trend_model.predict(f_validation.loc[:,X]) pred_2 = mean_model.predict(f_validation.loc[:,X])
検証セットの内容は、モデルにとってアウトオブサンプルです。つまり、これまで見たことのないデータを使ってモデルをストレステストし、重要なストレス下でもモデルが倫理的に振る舞うかを確認します。
テストは、両モデルの予測の合計に対しておこないます。もし予測の合計の最大値が0.0であれば、モデルはテストに合格したことになります。これは、両モデルを同時に追従した場合、投資家は何も得られないという点で、モデルが効率的市場仮説と一致していることを意味します。私たちは、常に1つのモデルのみを追従するつもりです。したがって、市場レジーム間を動的に切り替えることになります。つまり、この戦略は、人間の介入なしに戦略を変更できる能力を持っているということです。
test_result = pred_1 + pred_2 print(f" Test Passed: {np.linalg.norm(test_result,ord=2) == 0.0}")
numpyパッケージには、先ほど使用した線形代数パッケージなど、多くの便利なライブラリが含まれています。ここで呼び出したnorm関数は、呼び出し方によってベクトルの内容の総和やベクトル内の最大値を返します。これは、配列内のすべての数値が0であることを自分で確認するのと論理的には同じです。なお、配列の出力は省略して表示していますが、読者は安心してください。実際にはすべての値が0でした。
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
トレンドフォロー戦略によって実際に得られた利益をプロットし、トレンドフォローモデルの予測と比較すると、600日目や700日目付近のようにEURUSD市場が大きく変動した際の極端な利益の振れを除けば、モデルは通常サイズの利益に関しては十分に追従できていたことが分かります。
plt.plot(f_validation.loc[:,y[0]],color='black') plt.plot(pred_1,color='red',linestyle=':') plt.legend(['Actual Profit','Predicted Profit']) plt.grid() plt.ylabel('Loss / Profit') plt.xlabel('Out Of Sample Days') plt.title('Visualizing Our Model Performance Out Of Sample on the EURUSD 10 Day Return')
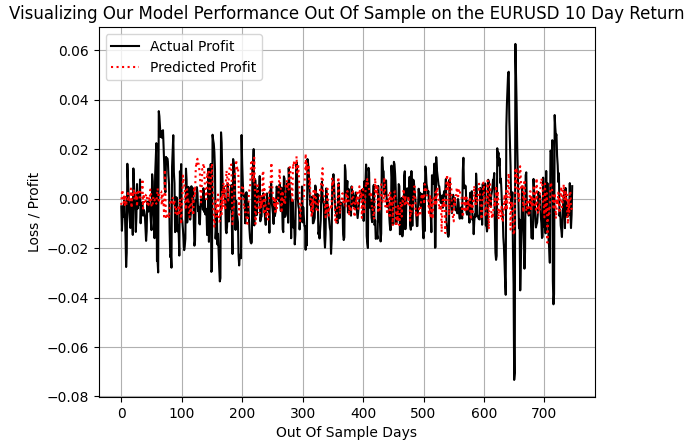
図7:DRSモデルは市場の真のボラティリティを捉えることができなかった
これで、機械学習モデルをONNX形式にエクスポートし、取引アプリケーションを新しい方向に導く準備が整いました。ONNX (Open Neural Network Exchange)は、広く採用されているAPIセットを通じて機械学習モデルを構築・デプロイできる仕組みです。この広範な採用により、異なるプログラミング言語でも同じONNXモデルを扱うことが可能になります。そして、各ONNXモデルは単にあなたの機械学習モデルの表現に過ぎないことを覚えておいてください。skl2onnxやonnxライブラリがまだインストールされていない場合は、まずそれらをインストールしてください。
!pip install skl2onnx onnx
次に、エクスポートする必要があるライブラリを読み込みます。
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
ONNXモデルの入出力の形状を定義します。
eurusd_drs_shape = [("float_input",FloatTensorType([1,len(X)]))] eurusd_drs_output_shape = [("float_output",FloatTensorType([1,1]))]
DRSモデルのONNXプロトタイプを準備します。
trend_drs_model_proto = convert_sklearn(trend_model,initial_types=eurusd_drs_shape,final_types=eurusd_drs_output_shape,target_opset=12) mean_drs_model_proto = convert_sklearn(mean_model,initial_types=eurusd_drs_shape,final_types=eurusd_drs_output_shape,target_opset=12)
モデルを保存します。
onnx.save(trend_drs_model_proto,"EURUSD RF D1 T LBFGSB DRS.onnx") onnx.save(mean_drs_model_proto,"EURUSD RF D1 M LBFGSB DRS.onnx")
これで、初めてのDRSモデルアーキテクチャを構築しました。次に、モデルのバックテストの準備をおこない、モデルが実際に差を生むか、そして設計プロセスにおけるRMSEの代替として意味のある結果を得られるかどうかを確認してみましょう。
MQL5の始め方
まず最初に、取引活動にとって重要なシステム定数を定義します。
//+------------------------------------------------------------------+ //| EURUSD DRS.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 10 #define MA_PERIOD 5 #define MA_SHIFT 0 #define MA_MODE MODE_SMA #define TRADING_VOLUME SymbolInfoDouble(Symbol(),SYMBOL_VOLUME_MIN)
次にシステムリソースを読み込みます。
//+------------------------------------------------------------------+ //| System dependencies | //+------------------------------------------------------------------+ #resource "\\Files\\DRS\\EURUSD RF D1 T DRS.onnx" as uchar onnx_proto[] //Our Trend Model #resource "\\Files\\DRS\\EURUSD RF D1 M DRS.onnx" as uchar onnx_proto_2[] //Our Mean Reverting Mode
取引ライブラリを読み込みます。
//+------------------------------------------------------------------+ //| System libraries | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
テクニカル指標用の変数も必要になります。
//+------------------------------------------------------------------+ //| Technical Indicators | //+------------------------------------------------------------------+ int ma_o_handle,ma_c_handle,atr_handle; double ma_o[],ma_c[],atr[]; double bid,ask; int holding_period;
グローバル変数を指定します。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model,onnx_model_2;
アプリケーションが最初に読み込まれるときに、テクニカル指標とONNXモデルを読み込むメソッドを呼び出します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); }
アプリケーションを使用していない場合は、不要になったリソースをクリーンアップします。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- release(); }
最後に、更新された価格レベルを受け取ったら、取引の機会を探すか、保有しているポジションを管理します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- static datetime time_stamp; datetime current_time = iTime(Symbol(),PERIOD_D1,0); if(time_stamp != current_time) { time_stamp = current_time; update_variables(); if(PositionsTotal() == 0) { find_setup(); } else if(PositionsTotal() > 0) { manage_setup(); } } } //+------------------------------------------------------------------+
これは、システム全体をセットアップするために作成した関数の実装です。
//+------------------------------------------------------------------+ //| Attempt To Setup Our System Variables | //+------------------------------------------------------------------+ bool setup(void) { atr_handle = iATR(Symbol(),PERIOD_CURRENT,14); ma_c_handle = iMA(Symbol(),PERIOD_CURRENT,MA_PERIOD,MA_SHIFT,MA_MODE,PRICE_CLOSE); ma_o_handle = iMA(Symbol(),PERIOD_CURRENT,MA_PERIOD,MA_SHIFT,MA_MODE,PRICE_OPEN); holding_period = 0; onnx_model = OnnxCreateFromBuffer(onnx_proto,ONNX_DEFAULT); onnx_model_2 = OnnxCreateFromBuffer(onnx_proto_2,ONNX_DEFAULT); if(onnx_model == INVALID_HANDLE) { Comment("Failed to load Trend DRS model"); return(false); } if(onnx_model_2 == INVALID_HANDLE) { Comment("Failed to load Mean Reverting DRS model"); return(false); } ulong input_shape[] = {1,10}; ulong output_shape[] = {1,1}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set Trend DRS Model input shape"); return(false); } if(!OnnxSetInputShape(onnx_model_2,0,input_shape)) { Comment("Failed to set Mean Reverting DRS Model input shape"); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set Trend DRS Model output shape"); return(false); } if(!OnnxSetOutputShape(onnx_model_2,0,output_shape)) { Comment("Failed to set Mean Reverting DRS Model output shape"); return(false); } return(true); }
システムを初期化解除するときに、使用しなくなったインジケーターとONNXモデルを手動で解放します。
//+------------------------------------------------------------------+ //| Free up system resources | //+------------------------------------------------------------------+ void release(void) { IndicatorRelease(ma_c_handle); IndicatorRelease(ma_o_handle); OnnxRelease(onnx_model); OnnxRelease(onnx_model_2); }
新しい価格情報がある場合は、システム変数を更新します。
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update_variables(void) { bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); CopyBuffer(ma_c_handle,0,1,(HORIZON*2),ma_c); CopyBuffer(ma_o_handle,0,1,(HORIZON*2),ma_o); CopyBuffer(atr_handle,0,0,1,atr); ArraySetAsSeries(ma_c,true); ArraySetAsSeries(ma_o,true); }
基本的に10日間のリターンまでカウントダウンすることで、取引を管理します。
//+------------------------------------------------------------------+ //| Manage The Trade We Have Open | //+------------------------------------------------------------------+ void manage_setup(void) { if((PositionsTotal() > 0) && (holding_period < (HORIZON-1))) holding_period +=1; else if((PositionsTotal() > 0) && (holding_period == (HORIZON - 1))) Trade.PositionClose(Symbol()); }
現在の市場状況に関する詳細な情報を取得し、それをモデルに入力して、取引セットアップを見つけましょう。私たちの戦略は、移動平均(Moving Averages, MA)を投資家心理の指標として利用することに基づいています。移動平均がショートシグナルを示す場合、私たちは「ほとんどの投資家はショートしたいと考えている」と仮定します。しかし、FX市場では多数派は往々にして間違う傾向があると考えています。
//+------------------------------------------------------------------+ //| Find A Trading Oppurtunity For Our Strategy | //+------------------------------------------------------------------+ void find_setup(void) { vectorf model_inputs = vectorf::Zeros(10); vectorf model_outputs = vectorf::Zeros(1); vectorf model_2_outputs = vectorf::Zeros(1); holding_period = 0; int i = 0; model_inputs[0] = (float) iOpen(Symbol(),PERIOD_CURRENT,0); model_inputs[1] = (float) iHigh(Symbol(),PERIOD_CURRENT,0); model_inputs[2] = (float) iLow(Symbol(),PERIOD_CURRENT,0); model_inputs[3] = (float) iClose(Symbol(),PERIOD_CURRENT,0); model_inputs[4] = (float)(iOpen(Symbol(),PERIOD_CURRENT,0) - iOpen(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[5] = (float)(iHigh(Symbol(),PERIOD_CURRENT,0) - iHigh(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[6] = (float)(iLow(Symbol(),PERIOD_CURRENT,0) - iLow(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[7] = (float)(iClose(Symbol(),PERIOD_CURRENT,0) - iClose(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[8] = (float) ma_c[0]; model_inputs[9] = (float)(ma_c[0] - ma_c[HORIZON]); if(!OnnxRun(onnx_model,ONNX_DEFAULT,model_inputs,model_outputs)) { Comment("Failed to run the ONNX model correctly."); } if(!OnnxRun(onnx_model_2,ONNX_DEFAULT,model_inputs,model_2_outputs)) { Comment("Failed to run the ONNX model correctly."); } if(model_outputs[0] > 0) { if(ma_c[0] < ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) > ma_c[0]) Trade.Buy(TRADING_VOLUME,Symbol(),ask,0,0,""); } else if(ma_c[0] > ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) < ma_c[0]) Trade.Sell(TRADING_VOLUME,Symbol(),bid,0,0,""); } } else if(model_2_outputs[0] > 0) { if(ma_c[0] < ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) < ma_c[0]) Trade.Buy(TRADING_VOLUME,Symbol(),ask,0,0,""); } if(ma_c[0] > ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) > ma_c[0]) Trade.Sell(TRADING_VOLUME,Symbol(),bid,0,0,""); } } Comment("0: ",model_outputs[0],"1: ",model_2_outputs[0]); }
システム定数を未定義にします。
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_MODE #undef MA_PERIOD #undef MA_SHIFT #undef TRADING_VOLUME //+------------------------------------------------------------------+
まず、バックテストの日付を選択します。ここで重要なのは、モデルのトレーニングセットの範囲外の日付を選ぶことです。これにより、モデルが将来どの程度うまく機能するかを信頼性のある形で把握できます。
図8:モデルのトレーニングセットを超える日付を選択したことを確認する
一般的に、モデルをストレステストしたいので、戦略を現実的かつ厳しい市場環境で試すために、[ランダム遅延]と[実ティックに基づく全てのティック]を選択します。
図9:[実ティックに基づく全てのティック]を使用することは、DRSアーキテクチャのストレステストに選択できる最も現実的なモデリングの選択肢である
以下に、新しいDRS戦略のパフォーマンスに関する詳細な概要を示します。注目すべき点は、DRSによってRMSEの代替を試みたにもかかわらず、初めて正式にモデル構築プロセスでRMSEを置き換えたにも関わらず、依然として利益を生む戦略を構築できたことです。
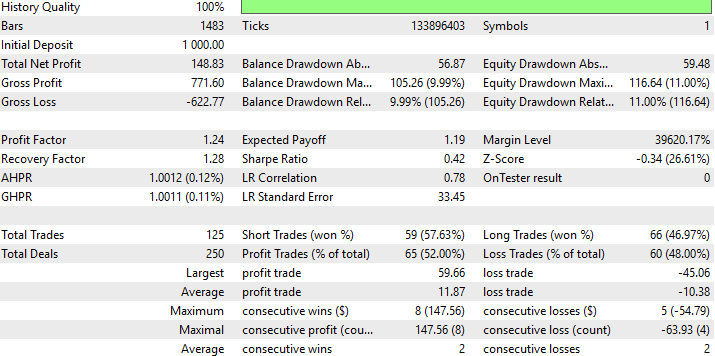
図10:未知データに基づく戦略のパフォーマンスの詳細な結果
戦略によって生成された資産曲線を見ると、前述の通り、DRSモデルが市場のボラティリティを予測できなかったことによる問題が見えてきます。これにより、戦略は利益が出る期間と損失が出る期間の間で揺れ動きます。しかし、それでも戦略は回復して軌道に戻る能力を示しており、これは私たちが望む挙動です。
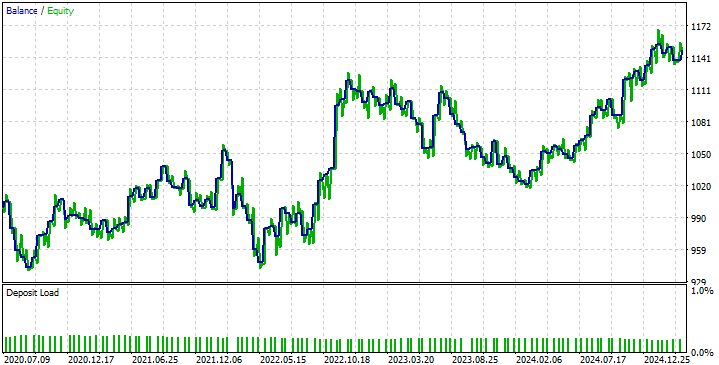
図11:新しい取引戦略によって生成された資産曲線
結論
これらの指標の限界を認識していなかった読者は、この記事を読み始めたときよりも強い気持ちで読み終えます。ツールの限界を知ることは、その長所を知ることと同じくらい重要です。AIを構築するために使用する最適化手法は、特に困難な問題を解決しようとすると「行き詰まる」ことがあります。そして、トレーダーがこれらのツールを使用して資産収益をモデル化する場合、そのモデルが市場の平均収益で行き詰まる傾向がある可能性があることを十分に認識する必要があります。
読者は実用的な洞察も得て、市場の平均収益を予測するモデルをどれだけうまく上回ることができるかによって市場をフィルタリングすることの利点を理解しています。これは、市場には実践者が利用すべき非効率性があることを意味するためです。
実践者が平均をどれだけ上回ることができるかに基づいて市場をフィルタリングすることにより、読者はRMSEを単独の指標として盲目的に解釈するのをやめ、常にTSSに対するRMSEを読み取ることを学びます。読者は、これらの指標が日常業務に課す制限を実際的に理解することで恩恵を受けています。これは、この主題を扱ったほとんどの文献や、ここにリンクされている研究論文では一般的ではない特徴です。
そして最後に、読者がすぐに機械学習モデルを導入して個人資本を取引するつもりだが、これらの制限を認識していない場合は、読者が気づかないうちに自ら足を撃ってしまうことがないように、まずこの記事で示した演習を繰り返すように警告します。RMSEにより、モデルはテストを不正におこなうことができますが、ここまで読んできた読者はAIの限界に簡単に騙されることはないと確信しています。
| ファイル名 | ファイルの説明 |
|---|---|
| DRS Models.mq5 | DRSモデルの構築に必要な詳細な市場データを取得するために作成したMQL5スクリプト |
| Dynamic_Regime_Switching_Models_(DRS_Modelling).ipynb | DRSモデルを設計するために作成したJupyterノートブック |
| EURUSD DRS.mq5 | DRSモデルを採用したEURUSD用EA |
| EURUSD RF D1 T DRS.onnx | トレンドフォロー型DRSモデルでは、常に市場にトレンドがあると想定する |
| EURUSD RF D1 M DRS.onnx | 平均回帰型DRSモデルでは、市場が常に平均回帰状態にあると想定する |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/17906
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
「しかし、私たちの戦略は、挽回し、軌道に乗り続ける能力を示している。
私はいつも、人が努力すべきは利益を生み出す戦略だと考えている :)
「しかし、我々の戦略は挽回し、軌道に乗る能力を示している。
私は常々、利益をもたらすために戦略を努力すべきだと思っています :)
記事をありがとう、@Gamuchirai Zororo Ndawana
最終的な目標は収益性であるという@Maxim Dmitrievsky氏の 意見に同意します。回復して軌道に乗る」という考え方は、堅牢性とドローダウンの抑制として理にかなっていますが、利益に取って代わるものではありません。
実践的な提案:ウォーク・フォワード・テスト、コストとスリッページ、非対称または分位損失または効用ベースの目標、平均抱擁を避けるために回転率にペナルティを課す。(実際的な考え方: 損失を儲け方に合わせる。)
そうですね:そうですね。しかし残念ながら、利益と損失の違いを認識できる標準化された機械学習の指標はまだありません。
回答損益欄が存在するのは、バックテストした商品 または平坦な市場が、この注文ラインに続くポートフォリオまたはインデックスのバスケットに対して使用しているフォワード市場と同程度に優れている場合のみです。
このような使用目的のために作られたダウ・ジョーンズ30指数や他の多くの指数のように、このような結果や利益率を生み出す指数や新しく設立されたETFがあります。 ピーター・マティ
記事をありがとう、 @Gamuchirai Zororo Ndawana
最終的な目標は収益性であるという @Maxim Dmitrievsky氏の 意見に同意します。回復して軌道に乗るという考え方は、堅牢性とドローダウンの抑制のためには理にかなっているが、利益には代えられない。
私たちが頼りにしている翻訳ツールは、元のメッセージを捉え損ねているのではないかと思うことがある。あなたの回答は、私が @Maxim Dmitrievskyの 元のメッセージから理解したものよりも、多くの論点を提供している。
ルック・フォワード・バイアス(i + HORIZONを使った機能)における見落としを指摘してくれてありがとう。
また、実際にモデルを検証するために使用される検証尺度についても貴重なフィードバックをいただきました。シャープレシオは普遍的なゴールドスタンダードに似ているはずです。カルマーとソルティーノについては、もっと勉強して意見をまとめる必要があります。
この2つの用語は設計上非対称であり、テストはモデルが非対称のままであるべきであり、この期待からの逸脱はテストに不合格であるということに同意します。片方または両方のモデルに許容できないバイアスがある場合、予測は私たちが期待するような非対称性を保てなくなる。
しかし、利益という概念は、私が問題を強調するために示した簡単な図解に過ぎない。私たちが今日持っているどの指標も、平均ハギングがいつ起こっているかを教えてはくれない。統計学習に関する文献のどれをとっても、なぜミーン・ハギングが起きているのかを教えてくれるものはない。これは、ベストプラクティスの危険性について、もっと多くの会話を始めたいと私が願っている方法の一つに過ぎない。
。この記事は、私たちが集まって、新しいプロトコルを一から設計するための、助けを求める叫びのようなものだった。新しい基準。オプティマイザーが直接取り組む、我々の関心に合わせた新しい目標。