
古典的な戦略を再構築する(第17回):テクニカル指標のモデリング

機械学習やその他の現代的な統計手法をアルゴリズム取引に適用することには、特有の難しさが伴います。私たちのコミュニティが直面している問題は金融市場に固有のものであり、そのため、より広範な機械学習分野ではほとんど議論されていません。その結果、古典的な教師あり学習は、私たちの分野にとって重要な論点について実践的な指針をほとんど提供していません。特に見過ごされがちな重要課題の一つは、金融時系列をモデル化する際には固定された目的変数が存在しないという事実です。これは、一見すると重大には思えないかもしれませんが、実際には本質的な問題です。
これを理解するために、医療分野でこれらの手法がどのように用いられているかを考えてみましょう。教師あり学習の多くがもともと医療分野から発展してきたこと、そして私たちのコミュニティがそれらを借用していることを思い出してください。医療においては、目的変数は明確かつ厳密に定義されています。たとえば、医師は患者ががんであるか否かを分類します。これは明確で不変のラベルを持つ二値分類問題です。医師の目的は一貫しており、目的変数は物理的現実に根ざしています。さらに、医療モデルは生物学的制約、倫理的制約、手続き的制約といった自然な枠組みの中で運用されており、それが学習問題に安定した構造を与えています。
これに対して、金融の領域にはそのような構造がありません。アルゴリズム取引に携わる私たちには、目的変数の固定された定義が存在しません。市場は年率収益率、日次収益率、15分足収益率、年間価格上昇率、最大下落率、変動率、あるいは資産間の相対変動として定式化することができます。実際、取引文脈において目的変数を定義する方法は無数に存在します。そして、これらはすべて同じ基礎データから導かれているにもかかわらず、ある定義は他のものよりもはるかに予測が困難です。
ここで重要な問いが生じます。私たちが直面している性能の上限は、モデルの能力やデータ品質の問題ではなく、目的変数の選択が不適切であることに起因している可能性はないでしょうか。さらに厄介なことに、何が「正しい」目的変数なのか、あるいは市場を横断して普遍的な定義が存在するのかを、私たちは事前に知ることができません。市場ごとに最適な予測問題の定式化が異なる可能性があります。
この観点に立てば、統計モデルの性能は必ずしもその真の潜在能力を反映しているわけではないことが明らかになります。私たちが経験している限界、すなわち一見すると不可避に思える誤差水準は、多くの場合、方法論上のガラスの天井の表れにすぎません。
本記事では、慎重な実験と適応的な方法論を通じて、モデルの学習方法だけでなく、何を予測対象とするのかを再定義することによって、性能を継続的に改善できることを示します。さまざまな目的変数の定義を体系的に試行することで、性能はデータ品質やモデル複雑度だけでなく、そして何よりも、学習問題をどのように構造化するかという方法論そのものに大きく依存していることを明らかにします。
MetaTrader 5からのデータ取得
取り組みを開始するにあたり、まずMetaTrader 5ターミナルから必要な市場データを取得します。このプロジェクトでは、多数の特徴量に対して複数の変換を適用します。本記事を通じて合計22個の特徴量を使用します。学習時にモデルが参照するデータと、実運用時に受け取るデータとの整合性を確保するため、専用のMQL5スクリプトを用いてデータを取得します。この方法により、バックテスト期間終了後であっても、同一のデータ変換処理を再現することが可能になります。
スクリプトは、始値、高値、安値、終値の4つの基本価格水準を取得し、それぞれにテクニカル指標を適用します。これらの値を取得した後、生の価格データと対応するインジケーター値の両方を記録します。次に、4つの価格水準およびそれぞれに対応するインジケーターについて、変化量(差分)を算出します。さらに、各価格水準の組み合わせ間における相対的な変化量を計算します。たとえば、始値と高値、始値と安値、始値と終値の間の増加率を求めます。この処理により、一本の足の内部における価格変動の詳細な内訳が得られます。その結果、モデルは各足の内部で価格がどのように推移しているかについて、より豊富な情報に基づいて学習することが可能になります。
//+------------------------------------------------------------------+ //| Fetch Data MA | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_TYPE MODE_SMA //--- Type of moving average we have //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; //--- File name string file_name = Symbol() + " Detailed Market Data As Series Moving Average.csv"; //--- Amount of data requested input int size = 3000; input int MA_PERIOD = 5; input int HORIZON = 5; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close", //--- MA OHLC "True MA O", "True MA H", "True MA L", "True MA C", //--- Growth in OHLC "Diff Open", "Diff High", "Diff Low", "Diff Close", //--- Growth in MA OHLC "Diff MA Open 2", "Diff MA High 2", "Diff MA Low 2", "Diff MA Close 2", //--- Growth Across Price Levels "O-C", "H-L", "O-H", "O-L", "C-H", "C-L" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], ma_reading[i], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), //--- Growth in MA OHLC ma_o_reading[i] - ma_o_reading[(i + HORIZON)], ma_h_reading[i] - ma_h_reading[(i + HORIZON)], ma_l_reading[i] - ma_l_reading[(i + HORIZON)], ma_reading[i] - ma_reading[(i + HORIZON)], //--- Growth Across Price Levels iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef MA_TYPE //+------------------------------------------------------------------+
Pythonによる分析の開始
データ抽出用スクリプトが完成した後、分析をおこなうためにPython環境へ移行します。多くの機械学習実験と同様に、まずは古典的なモデリング枠組みに基づいて基準となる性能水準を確立することを目的とします。最初に、標準的なPythonライブラリを読み込みます。
#Import the libraries we need to get started import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
ここで注意すべき点として、ここで使用しているMQL5スクリプトの初期バージョンは、後に提示する最終バージョンとはわずかに異なります。初期バージョンでは17列を取得していますが、最終バージョンでは追加の特徴量が含まれています。これらの違い、そしてデータセットを拡張する動機については、本記事の終盤で明らかになります。
#Read in the data data = pd.read_csv("../EURUSD Detailed Market Data As Series Moving Average.csv") data
図1:データセットは非常に大規模であり、初期状態では17列を含んでいる
データセットを読み込んだ後、古典的な1ステップ先予測のアプローチを用いてデータにラベル付けをおこないます。
#Classical Target #Baseline value HORIZON = 1 #Label the data data['Target'] = data['True Close'].shift(-HORIZON) #Drop the last batch of forecasts data = data.iloc[:-HORIZON,:] data
この統計モデルをバックテストによって評価する予定であることを思い出してください。そのため、直近3年分の観測データを分離し、別個のテストセットとして保持します。このテストセットでモデルを学習させてしまうと、本記事の目的に反することになります。
#Drop the last 3 years of data test = data.iloc[-(365*3):,:] data = data.iloc[:-(365*3),:]
興味深いことに、目的変数と入力変数の間の相関の強さは、時間とともに特に不安定であることが分かります。これを検証するために、観測値を拡張ウィンドウで増やしながら、目的変数と各入力変数との間のピアソン相関係数を計算しました。これにより、目的変数と各入力変数との相関の強さを表すベクトルが得られます。次に、このベクトルのL1ノルム(絶対値の総和)を計算することで、相関の総合的な強さを単一の指標として算出しました。
最初は1日分のデータから始め、次に2日分、3日分と徐々に拡張し、最終的に1年(365日)に到達するまで繰り返しました。下図に示されているように、相関の水準は時間的に安定しておらず、変動しています。ある日は強く見え、別の日には弱まります。全体としては、ウィンドウが拡張するにつれて相関が減衰しているように見え、入力変数と目的変数の関係が時間とともに不安定であることを示唆しています。
corr_strength = [] EPOCHS = 365 for i in np.arange(EPOCHS): corr_strength.append(np.linalg.norm(data.loc[:i+1,:].corr().iloc[:,-1],ord=1)) sns.barplot(corr_strength) plt.ylabel('Correlational Strength') plt.title('Correlation Between Future Price And Historical Data')
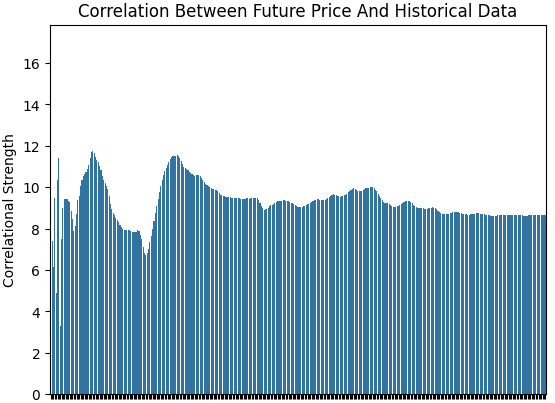
図2:過去のEURUSDデータセットにおける相関の強さは定常的ではない
次に、学習セット全体にわたるすべての入力変数間の相関構造をヒートマップで可視化しました。ご覧のとおり、目的変数は実数値の価格水準およびその移動平均と強い相関を示す傾向がありますが、それらの変化量は目的変数との相関が比較的弱いことが分かります。
sns.heatmap(data.iloc[:,1:].corr())
plt.title('Analyzing Market Correlation Strucute') 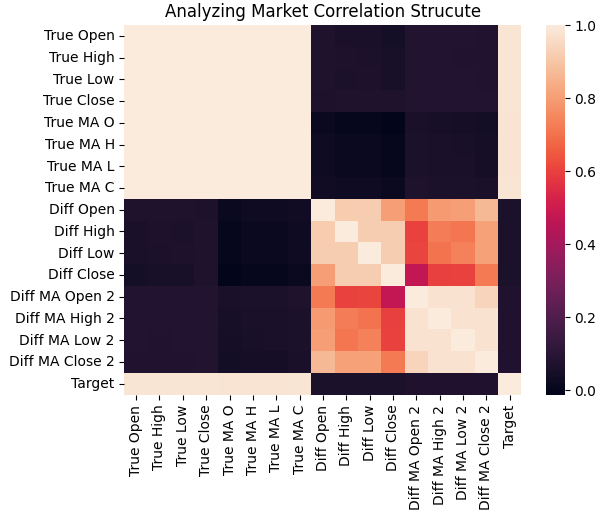
図3:過去のEURUSD市場データの相関構造は、目的変数が過去価格と強く関連していることを示している
相関行列から得られる情報はこれだけではありません。NumPyのeig関数を用いて固有値分解をおこなうこともできます。この関数は固有値と固有ベクトルの両方を返します。ここではまず固有値に注目します。固有値は、相関構造における分散のどれだけが各主成分によって説明されているかを示します。言い換えれば、固有値は市場データがいくつの支配的な「変動モード」を持っているかを示しています。
安定した市場では通常、強いトレンドや平均回帰プロセスなど、1つの支配的なモードが卓越します。一方、より混沌とした市場では、複数の競合するモードが存在します。本ケースでは、固有値の棒グラフから2つの大きな支配的モードと、平均閾値をわずかに上回る3つ目のモードが確認できます。これは、市場に2つの主要な変動モードと、より弱い3つ目のモードが存在する可能性を示唆しています。残りの固有値は極めて小さく、データの相関構造に意味のある寄与をしていません。
eig_val ,eig_vec =np.linalg.eigh(data.iloc[:,1:].corr()) sns.barplot(eig_val,color='black') plt.axhline(np.mean(eig_val),color='red',linestyle=':') plt.ylabel('Eigen Value') plt.title('Spectrum Analysis of The EURUSD Market')
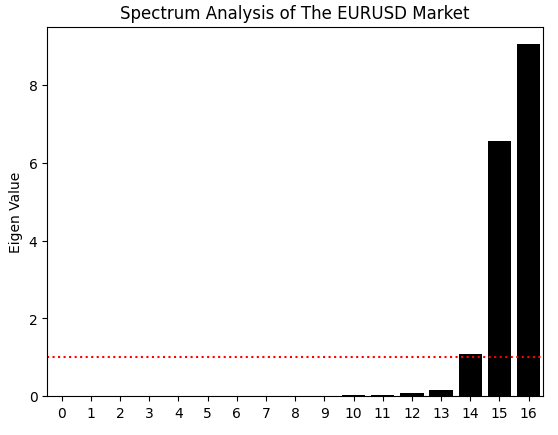
図4:過去のEURUSD市場データの相関構造における固有値は、市場に3つの主要な不安定モードが存在することを示唆している
次に、統計的学習ライブラリを読み込みます。
from sklearn.linear_model import LinearRegression
入力変数と目的変数を定義します。まずは4つの入力変数を用いた単純なモデルから始めます。
X = ['True Open','True High','True Low','True Close'] y = 'Target'
市場データに対してモデルを学習させます。
model = LinearRegression() model.fit(data.loc[:,X],data[y])
このモデルは、アウトオブサンプルにおいても市場の動きをある程度捉えているように見えます。
preds = model.predict(test.loc[:,X]) plt.plot(preds,color='black') plt.plot(test.loc[:,y].values,color='red',linestyle=':') plt.title('Visualizing Our Accuracy Out of Sample') plt.xlabel('Historical Time') plt.ylabel('EURUSD Exchange Rate') plt.legend(['Model Predictions','Observed Exchange Rate']) plt.grid()
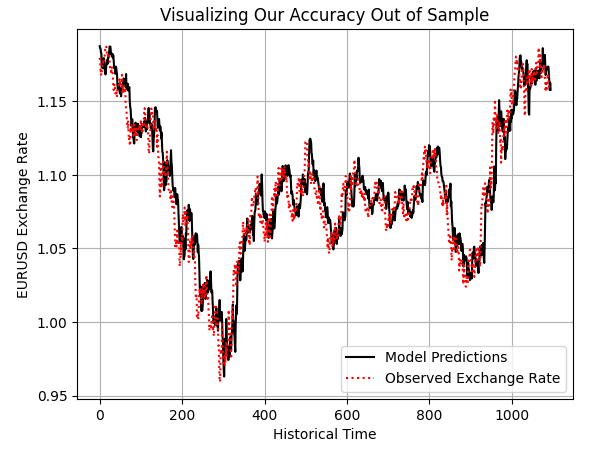
図5:アウトオブサンプル予測を可視化し、モデルの妥当性を検証する
ONNXへのエクスポート
これで、学習済みの統計モデルをONNX形式へエクスポートする準備が整いました。ONNX (Open Neural Network Exchange)は、は、モデルを作成したフレームワークへの依存を持ち込むことなく、構築およびデプロイを可能にする、世界的に広く認知された規格(API仕様)です。まずは、必要なONNX関連ライブラリを読み込みます。
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
次に、モデルの入力および出力の形状を定義します。本ケースでは、モデルは4つの入力を受け取り、1つの出力を生成します。
initial_types = [('float_input',FloatTensorType([1,4]))] final_types = [('float_output',FloatTensorType([1,1]))]
続いて、ONNXのプロトコルバッファを作成します。これは最終的な変換前にモデルを保持する中間構造です。
onnx_proto = convert_sklearn(model,initial_types=initial_types,final_types=final_types,target_opset=12) 最後に、プロトコルバッファと保存したいファイル名をonnx.save関数に渡し、.onnxファイルとしてモデルを保存します。
onnx.save(onnx_proto,"EURUSD 2022-2025 LR.onnx") 古典的手法によるベースラインの確立
これで準備が整ったので、MQL5で取引アプリケーションの構築を開始します。最初のステップは、先ほどPythonでの分析からエクスポートしたONNXファイルをインポートすることです。
//+------------------------------------------------------------------+ //| Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/ja/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/ja/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 LR.onnx" as const uchar onnx_proto[];
次に、ポジションの新規建てや決済、変更処理、新しいローソク足の確認、ONNXバッファの管理などの各種処理をおこなうための補助ライブラリを読み込みます。
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\ONNX\ONNXFloat.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; Time *time; TradeInfo *trade; ONNXFloat *onnx_model;
続いて、アプリケーション全体で使用するいくつかのグローバル変数を初期化します。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int atr_handler; double atr[]; float prediction;
初期化処理では、先ほど読み込んだバッファからONNXモデルを生成します。以前の議論において、ONNXファイルを効率的に扱うための専用ライブラリを開発しました。このカスタムライブラリのおかげで、ONNXモデルを読み込み使用するために必要な設定手順は大幅に削減されています。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- onnx_model = new ONNXFloat(onnx_proto); trade = new TradeInfo(Symbol(),PERIOD_CURRENT); time = new Time(Symbol(),PERIOD_D1); atr_handler = iATR(Symbol(),PERIOD_CURRENT,14); if(!onnx_model.DefineOnnxInputShape(0,1,4)) { Print("Failed to specify ONNX input shape"); return(INIT_FAILED); } if(!onnx_model.DefineOnnxOutputShape(0,1,1)) { Print("Failed to specify ONNX output shape"); return(INIT_FAILED); } //--- return(INIT_SUCCEEDED); }
ONNXモデルやその他の確保したリソースを使用しなくなった場合には、MetaTrader 5開発におけるベストプラクティスとして、適切に解放処理をおこないます。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- delete onnx_model; delete time; delete trade; }
新しい価格データが到来するたびに、インジケーターバッファを更新し、ONNXモデルに適切な入力値を定義し、予測値を取得します。予測結果に基づいて売買を実行または決済します。問題が発生した場合には、エラーメッセージが表示されます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time.NewCandle()) { if(PositionsTotal()==0) { CopyBuffer(atr_handler,0,0,1,atr); onnx_model.DefineInputValues(0,(float) iOpen(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(1,(float) iHigh(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(2,(float) iLow(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(3,(float) iClose(Symbol(),PERIOD_CURRENT,0)); double padding = (atr[0]*1.5); if(onnx_model.Predict()) { prediction = onnx_model.GetPrediction(0); Print("Onnx Prediction:\n",prediction); if(prediction > iClose(Symbol(),PERIOD_CURRENT,0)) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } if(prediction < iClose(Symbol(),PERIOD_CURRENT,0)) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } else { Print("Failed to obtain a prediction from our model: ",GetLastError()); return; } } } } //+------------------------------------------------------------------+
この時点で、バックテストを開始する準備が整いました。まず、テスト対象のアプリケーションを選択します。ここでは、取引システムのベンチマーク版です。テスト期間は2022年から2025年10月(執筆時点)までと定義します。

図6:初期ベースラインのバックテストは非常に重要であり、目標とすべき基準を示す
次に、戦略を評価するテスト条件を指定します。実際の市場挙動を模倣するために、ランダム遅延を有効にします。これにより、ライブ取引の予測不可能性を近似することができます。
図7:実際の市場条件を信頼性高く再現するためにランダム遅延設定を選択する
結果を見ると、この単純な設定では戦略はかなり不安定であることが分かります。これらの結果は完全に予想外というわけではありません。なぜなら、このモデルは1ステップ先のみを予測するよう設計されており、実質的に取引ごと、ローソク足ごとの予測をおこなっているからです。このアプローチは人間のトレーダーが市場を見る方法とは異なり、システムの実運用上の妥当性や堅牢性を制限してしまいます。それでもなお、これは標準的なベストプラクティスに従って得られたベースライン結果です。
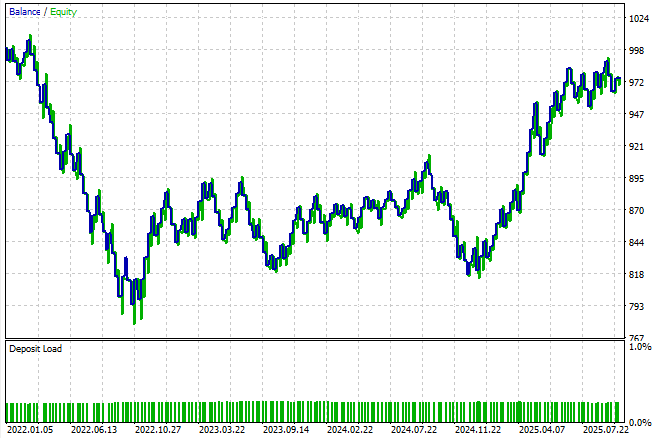
図8:取引アプリケーションの初期バージョンによって生成されたエクイティカーブは、さらなる改善努力の必要性を示している
バックテストを詳しく分析すると、このシステムが深刻にパフォーマンス不足であることが分かります。バックテスト期間を通じて一貫して損失を出しているだけでなく、取引分布も最適とは言えず、市場ダイナミクスに対する有意義な理解を示していません。3年間の期間において、この統計モデルは183回のロングポジションを開き、ショートポジションはわずか1回しか開いていません。この不均衡は、市場構造を適切に捉えられていない可能性を示唆しており、標準的な機械学習手法だけに依存するよりも、はるかに優れたパフォーマンスを達成できる余地があることを明確に示しています。
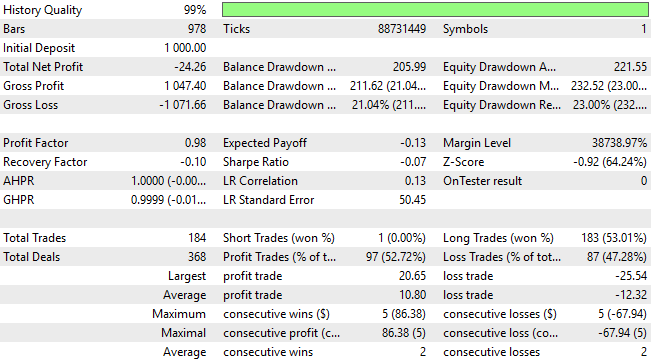
図9:取引アプリケーションの詳細統計は、従来アプローチの欠陥を明らかにしている
古典的手法を用いたベースラインの改善
それでは、取引アプリケーションの改善を実装していきましょう。最初に取り組む改善点は、予測期間です。一般的に言って、1ステップ先のみを予測する手法は、利益を上げている人間トレーダーの運用スタイルを十分に反映しているとは言えません。そこで、予測期間を10ステップ先まで拡張します。これにより、単一ステップ予測よりも現実的な見通しが得られるはずです。この段階では、Jupyter Notebook内のその他のコードは変更していないため、それらの部分は省略し、変更点のみを示します。
#Classical Target #V1 value HORIZON = 10
モデルを10ステップ先を予測するように学習させた後、ファイルに保存し、更新されたバージョンを取引アプリケーションに読み込みます。
onnx.save(onnx_proto,"EURUSD 2022-2025 LR V1.onnx") MetaTrader 5アプリケーションへの改善の実装
前述の通り、アプリケーションの全体構造は大きく変わっていません。そのため、変更のないコード部分は簡略化して省略します。
//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 LR V1.onnx" as const uchar onnx_proto[];
更新されたモデルをアプリケーションに組み込んだ後、同じ期間に対して新しいバックテストを実行し、パフォーマンスを評価します。
図10:取引アプリケーションのベンチマーク版を上回る最初の試みを評価する
新バージョンのシステムによって生成されたエクイティカーブを見ると、視覚的には以前のバージョンとほとんど変化がないように見えます。しかし、詳細統計を注意深く確認すると、いくつかの有意な改善点が見えてきます。
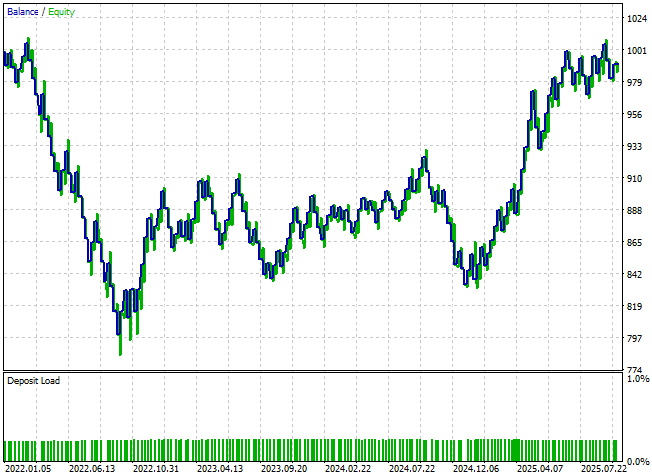
図11:取引アプリケーションの改善版によるエクイティカーブは、最初に作成したアプリケーションとほぼ同一に見える
総純損失は大幅に減少し、−24ドルから−8ドルとなりましたが、それでも望ましい結果とは言えません。さらに、ショートポジションの総数は依然としてゼロであり、システムが市場方向の理解において依然として偏りや不十分さを抱えていることを示しています。このことから、修正によって一定の改善は見られるものの、依然として大きな改善余地があることは明らかです。
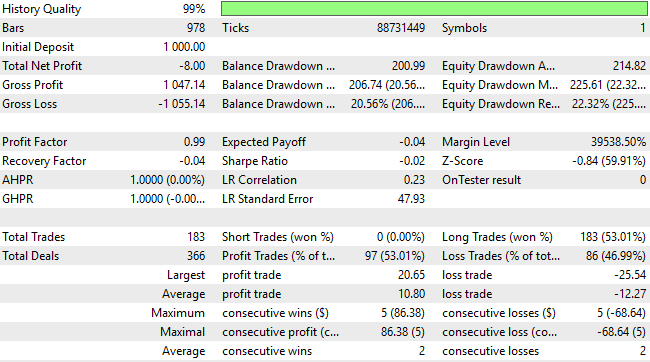
図12:新しい結果の詳細分析により、いくつかの改善は見られるものの、目標にはまだ遠いことが分かる
古典的手法を上回る
この時点で、古典的モデリングの原理はほぼ使い尽くされました。そこで、ここからは従来の考え方から一歩踏み出し、本連載の記事を通じて得られた洞察に基づいて改善を試みます。特に注目すべき観察として、多くの市場では、テクニカル指標は生の価格よりも予測しやすい傾向があることが分かっています。この洞察に基づき、モデル設定を変更し、目的変数を将来の価格から移動平均の将来値に切り替えます。#Classical Target #V1 value HORIZON = 10 #Label the data data['Target'] = data['True MA C'].shift(-HORIZON) #Drop the last batch of forecasts data = data.iloc[:-HORIZON,:] data
当然、この変更に伴い、モデルの入力空間も再定義する必要があります。ここでは、移動平均の現状を表す4つの新しい変数を導入し、特徴量セットを拡張します。
X = ['True Open','True High','True Low','True Close','True MA O','True MA H','True MA L','True MA C'] y = 'Target'
その結果、モデルの入力形状もこの更新された構成に合わせて修正する必要があります。
initial_types = [('float_input',FloatTensorType([1,8]))] final_types = [('float_output',FloatTensorType([1,1]))]
設定が完了したら、新しいモデルを保存します。
onnx.save(onnx_proto,"EURUSD 2022-2025 R V2.onnx") MQL5での改善点の実装
ここで、取引アプリケーションを更新し、改良版ONNXモデルを参照するようにします。
//+------------------------------------------------------------------+ //| Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/ja/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/ja/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 R V2.onnx" as const uchar onnx_proto[];
移動平均インジケーターがモデルの入力に加わったため、まず使用する移動平均の期間と種類を指定するシステム定数を定義します。
//--- System constants #define MA_PERIOD 5 #define MA_TYPE MODE_SMA
次に、新しい価格データが到来するたびに最新の移動平均値を読み取り更新するためのインジケーターハンドルを作成します。
//---Setup our technical indicators atr_handler = iATR(Symbol(),PERIOD_CURRENT,14); ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW);
ポジションの建て方も変更されます。まず、4つの移動平均ハンドルから最新のインジケーター値を各バッファにコピーします。次に、OnyxToolsライブラリのDefineInputValues()関数を使い、ONNXモデル用の現在の入力値を準備します。その後、OnyxPredict()関数を呼び出して予測を取得し、浮動小数点変数predictionに保存します。予測が得られたら、モデルが予測した移動平均の将来値と現在値を比較します。移動平均が上昇すると予測された場合はロングポジションを建て、下降すると予測された場合はショートポジションを建てます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time.NewCandle()) { if(PositionsTotal()==0) { CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_handle,0,0,1,ma_reading); CopyBuffer(ma_o_handle,0,0,1,ma_o_reading); CopyBuffer(ma_h_handle,0,0,1,ma_h_reading); CopyBuffer(ma_l_handle,0,0,1,ma_l_reading); onnx_model.DefineInputValues(0,(float) iOpen(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(1,(float) iHigh(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(2,(float) iLow(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(3,(float) iClose(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(4,(float) ma_o_reading[0]); onnx_model.DefineInputValues(5,(float) ma_h_reading[0]); onnx_model.DefineInputValues(6,(float) ma_l_reading[0]); onnx_model.DefineInputValues(7,(float) ma_reading[0]); double padding = (atr[0]*1.5); if(onnx_model.Predict()) { prediction = onnx_model.GetPrediction(0); Print("Onnx Prediction:\n",prediction); if(ma_reading[0]>ma_o_reading[0]) { if(prediction > ma_reading[0]) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } } if(ma_reading[0]<ma_o_reading[0]) { if(prediction < ma_reading[0]) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } } else { Print("Failed to obtain a prediction from our model: ",GetLastError()); return; } } } } //+------------------------------------------------------------------+
これまでと同様に、この新しいバージョンのアプリケーションを、モデルが学習時に一度も見ていない同じテスト期間で実行します。

図13:同じバックテスト期間で改良版取引アプリケーションを実行し、改善効果を評価する
エクイティカーブを見ると、ようやく上向きの傾向が現れ始め、健康的なトレンドを形成しつつありますが、まだ多少の変動は見られます。
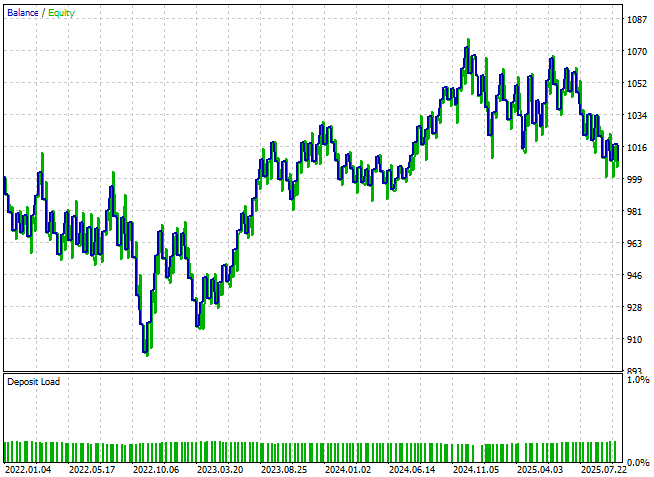
図14:アプリケーションが初めて損益分岐点を突破した
詳細なパフォーマンス統計を確認すると、戦略は損益分岐点を超えています。利益はまだ控えめですが、勝率は50%を超え、約53%に達しており、プロフィットファクターも正の期待値を示しています。これらの改良により、システムは正しい方向に進んでいることが明らかです。とはいえ、さらなる改善余地は依然として残っています。
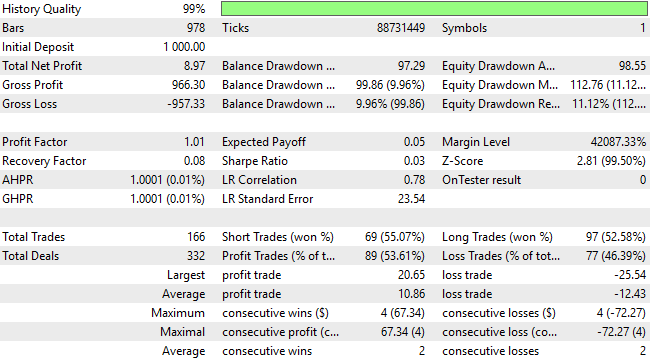
図15:アプリケーションはロングとショートのエントリーにバランスの取れた見方を示しているが、依然として利益率は十分ではない
さらなる改善余地の認識
古典的手法からさらに離れる中で、関連連載記事「AIの限界を克服する」におけるもう一つの重要な観察結果を活用できます。この研究では、複数の予測期間を用いることで、モデルが実世界のデータよりも内部的に一貫性のある予測を出す場合があることが分かりました。今回の演習でも、この洞察が役立つかどうかを検証します。そのために、モデル用に2つの目的変数を作成します。
具体的には、移動平均インジケーターの1ステップ先の値と10ステップ先の値です。前回の記事を読んでいない読者のために説明すると、このアプローチの論理はシンプルです。売買シグナルは、2つの予測期間間の傾きから導きます。つまり、移動平均が2つの予測期間で下落すると予測される場合は売り、上昇すると予測される場合は買いをおこないます。
#Classical Target #V1 value HORIZON = 10 #Label the data data['Target 1'] = data['True MA C'].shift(-1) data['Target 2'] = data['True MA C'].shift(-HORIZON) #Drop the last batch of forecasts data = data.iloc[:-HORIZON,:] data
予想通り、これらの変更によりONNXモデルの出力形状も変わるため、新しい出力構成に合わせてモデル定義を更新する必要があります。
initial_types = [('float_input',FloatTensorType([1,8]))] final_types = [('float_output',FloatTensorType([1,2]))]
最後に、更新されたモデルを保存し、アプリケーション内で再読み込みします。
onnx.save(onnx_proto,"EURUSD 2022-2025 R MFH V3.onnx") MQL5での改善点の実装
ここで、改良版ONNXファイルを読み込みます。//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 R MFH V3.onnx" as const uchar onnx_proto[];
読み込み後、新しいモデル出力形状を定義します。
if(!onnx_model.DefineOnnxOutputShape(0,2,1)) { Print("Failed to specify ONNX output shape"); return(INIT_FAILED); }
次に、予測値の解釈方法に必要な調整をすべておこないます。この段階では、モデルの予測値をインジケーターの実際の値と比較するのではなく、短期予測と長期予測の間の傾きに基づいて取引をおこないます。
if(onnx_model.Predict()) { onnx_model.GetPrediction(0); Print("Onnx Prediction:\n",prediction); if(ma_reading[0]>ma_o_reading[0]) { if(onnx_model.GetPrediction(1) > onnx_model.GetPrediction(0)) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } } if(ma_reading[0]<ma_o_reading[0]) { if(onnx_model.GetPrediction(1) < onnx_model.GetPrediction(0)) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } }
実務上、ファイル階層を明確に保つことを強く推奨します。私のローカル環境では、アプリケーションの各バージョンごとにフォルダを分けています。これにより作業環境を整理しやすく、必要に応じて以前のバージョンに簡単に戻すことができます。
図16:アプリケーションの反復的な改善をおこなう際には、明確なファイル構造を維持することが重要である
適切なバージョンのアプリケーションが準備できたら、前回と同じバックテスト期間でテストを実行します。
図17:テスト期間におけるアプリケーション第3版のバックテスト結果
結果として得られたエクイティカーブは、初期結果と比べて顕著な改善を示しています。上向きのトレンドは、分析開始時よりもはるかに明確で支配的です。さらに、今回のアプリケーションは、従来は到達不可能であった新しいエクイティ高値を記録しています。バランスカーブにはまだ変動が残り、完全な安定化は達成されていませんが、全体的な成長の軌道は明らかに強化されています。
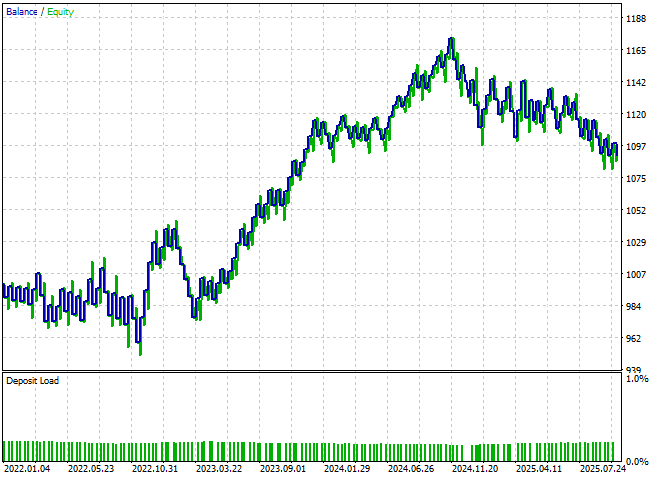
図18:アプリケーションはこれまで到達できなかったエクイティカーブの新高値に到達している
詳細な結果を確認すると、顕著な改善が見られます。システムは、初期の24単位の損失から90単位の利益へと移行しており、これは非常に印象的な変化です。特に注目すべきは、戦略の複雑さを増やしたり、モデリングのアーキテクチャを変更したりしていないにもかかわらず、この成果が得られた点です。これまでに達成された利益はすべて、より適切な方法論の選択をおこない、もはや目標達成に寄与しない手法を排除したことによるものです。
取引分布をさらに詳しく見ると、追加の洞察が得られます。更新版アプリケーションではショートポジションが大幅に増加しており、以前のバージョンで課題だった売り機会の認識不足が改善されています。モデルはショートポジションを約62%の精度で分類していますが、依然としてわずかに偏りがあり、ロングポジションはショートポジションの約2倍の割合で建てています。このことから、パフォーマンスは大幅に向上したものの、さらなる改善の余地が依然として存在することが分かり、私たちにさらなる努力を促しています。
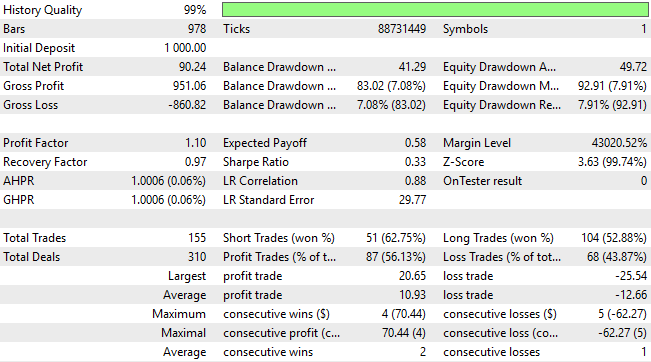
図19:第3版取引アプリケーションの詳細分析により、改善点と残る課題が明らかになった
さらなる改良を求めて
これで、取引アプリケーションのさらなる改善に向けて、より深く掘り下げる準備が整いました。振り返った結果、モデルに現在の市場状況をより詳細に伝えることで、より良い結果が得られると考えました。そこで、データセットにいくつかの新しい特徴量を追加し、合計で23の入力変数となりました。これらすべての23の特徴量は、本記事冒頭で提供したスクリプトで完全に取得可能です。
#Read in the data data = pd.read_csv("../EURUSD Detailed Market Data As Series Moving Average.csv") data
図20:更新された市場データは合計23列となっている
これらの追加により、データの相関構造がどのように変化したかを確認できます。新しいヒートマップを、以前のもの(図3)と比較すると、その違いは顕著です。今回は、2つの予測対象変数に注目すると、目的変数と入力変数の間により信頼性の高い、構造化された相関パターンが確認できます。図3のように目的変数が入力変数との関係が弱く不安定であった場合とは異なり、新しいヒートマップは明確に「ホット」になっており、データ内の依存関係がより強く、有意であることを示しています。
この改善は理にかなっています。ご記憶の通り、今回予測対象としている移動平均値は価格レベルから直接算出されます。そのため、移動平均と入力変数の間に強い相関があることは期待されるべきであり、望ましい現象です。移動平均は本質的に過去の価格の加重和であるためです。
sns.heatmap(data.iloc[:,1:].corr())
plt.title('Analyzing Market Correlation Strucute') 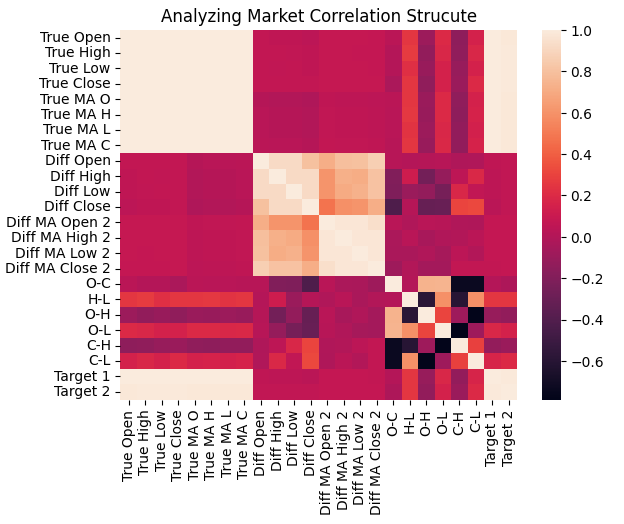
図21:更新された市場データは、図3の初期データよりも強い相関を示している
しかし、新しいデータセットの相関行列から得られる固有値スペクトルを分析すると、より複雑な状況が見えてきます。以前のデータセット(図4)では、主に2つの支配的な固有値が観察され、3つ目は平均値よりわずかに上回る程度でした。これは、以前のシステムが2つの強い変動モードと、比較的軽微な3つ目のモードを持っていたことを意味します。
今回、新たな特徴量を追加した市場データを分析すると、平均値を上回る固有値が4つ存在することが分かります。これは重要な観察です。特徴量を豊かにしたことで、追加の支配的な変動モード、つまりより多様な市場レジームが導入されたことを示しています。市場の記述はより豊かになった一方で、構造の複雑性が増し、信頼性の高いモデル化が難しくなる可能性があります。モデル化しようとしているシステムは、以前よりも多くのレジームや動的挙動を示すようになっています。
eig_val ,eig_vec =np.linalg.eigh(data.iloc[:,1:].corr()) sns.barplot(eig_val,color='black') plt.axhline(np.mean(eig_val),color='red',linestyle=':') plt.ylabel('Eigen Value') plt.title('Spectrum Analysis of The EURUSD Market')
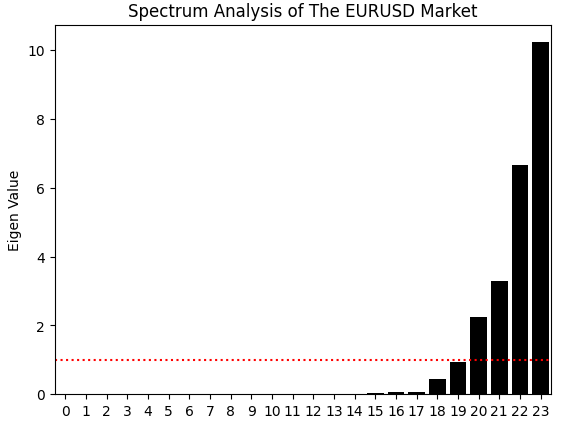
図22:残念ながら、市場データは競合する変動モードを伴い、より複雑になっていることが分かる
それでも、入力変数と目的変数を分離して進めます。
X = data.iloc[:,1:-2].columns y = ['Target 1','Target 2']
モデル用の更新された入力形状を定義します。
initial_types = [('float_input',FloatTensorType([1,len(X)]))] final_types = [('float_output',FloatTensorType([1,2]))]
最後に、新たに学習させたモデルをファイルに保存します。
onnx.save(onnx_proto,"EURUSD 2022-2025 R V4.onnx") 新しいモデルには、22の入力特徴量があることも確認できます。
len(X)
22
改善内容の実装
モデルを学習させた後、改良版モデルを取引アプリケーションに読み込みます。
//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 R V4.onnx" as const uchar onnx_proto[];
ONNXモデルの定義も、それに応じて更新することを忘れないでください。
if(!onnx_model.DefineOnnxInputShape(0,1,22)) { Print("Failed to specify ONNX input shape"); return(INIT_FAILED); }
今回の主な変更点は、新しい価格データの取り扱い方です。22個すべての特徴量を個別に定義し、float型にキャストする必要があります。これは、自動データ変換による精度の損失を防ぐためです。入力の扱いを除けば、モデルの予測値の解釈ロジック自体は従来と変わりません。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time.NewCandle()) { if(PositionsTotal()==0) { CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_handle,0,0,HORIZON*2,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,HORIZON*2,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,HORIZON*2,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,HORIZON*2,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); onnx_model.DefineInputValues(0,(float) iOpen(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(1,(float) iHigh(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(2,(float) iLow(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(3,(float) iClose(Symbol(),PERIOD_CURRENT,0)); onnx_model.DefineInputValues(4,(float) ma_o_reading[0]); onnx_model.DefineInputValues(5,(float) ma_h_reading[0]); onnx_model.DefineInputValues(6,(float) ma_l_reading[0]); onnx_model.DefineInputValues(7,(float) ma_reading[0]); onnx_model.DefineInputValues(8,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iOpen(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(9,(float) iHigh(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(10,(float) iLow(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(11,(float) iClose(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,(0 + HORIZON))); onnx_model.DefineInputValues(12,(float) ma_o_reading[0] - ma_o_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(13,(float) ma_h_reading[0] - ma_h_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(14,(float) ma_l_reading[0] - ma_l_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(15,(float) ma_reading[0] - ma_reading[(0 + HORIZON)]); onnx_model.DefineInputValues(16,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(17,(float) iHigh(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(18,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(19,(float) iOpen(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(20,(float) iClose(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0)); onnx_model.DefineInputValues(21,(float) iClose(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0)); double padding = (atr[0]*1.5); if(onnx_model.Predict()) { if(ma_reading[0]>ma_o_reading[0]) { if(onnx_model.GetPrediction(1) > onnx_model.GetPrediction(0)) { Trade.Buy(trade.MinVolume(),Symbol(),trade.GetAsk(),trade.GetBid()-padding,trade.GetBid()+padding,""); } } if(ma_reading[0]<ma_o_reading[0]) { if(onnx_model.GetPrediction(1) < onnx_model.GetPrediction(0)) { Trade.Sell(trade.MinVolume(),Symbol(),trade.GetBid(),trade.GetAsk()+padding,trade.GetAsk()-padding,""); } } } else { Print("Failed to obtain a prediction from our model: ",GetLastError()); return; } } } } //+------------------------------------------------------------------+
次に、前回と同じ評価期間でバックテストを実行します。
図23:第4版取引アプリケーションを同じバックテスト期間で実行する
残念ながら、得られたエクイティカーブにはほとんど改善が見られません。パフォーマンスはほぼ変わらず、最終的な口座残高はむしろ減少しています。
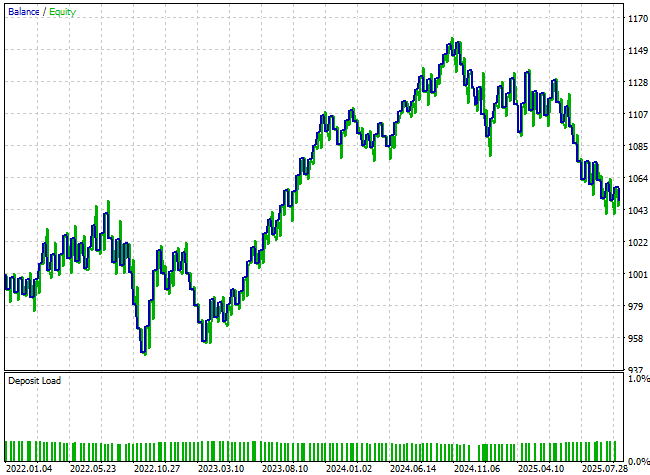
図24:追加した新しい特徴量は、市場状況の理解向上にはほとんど寄与していないようである
詳細なパフォーマンス統計をさらに確認すると、収益改善の限界に近づいていることが分かります。総純利益や全体的な精度は低下しています。前回の目的の一つは、システムがより多くのショート取引の機会を認識できるようにすることでした。以前のバージョンではロングポジションがショートのほぼ2倍に達していました。しかし、この不均衡は依然として解消されておらず、モデルは依然としてロング取引を優先しており、望ましいショートエントリーの改善はまだ達成されていません。
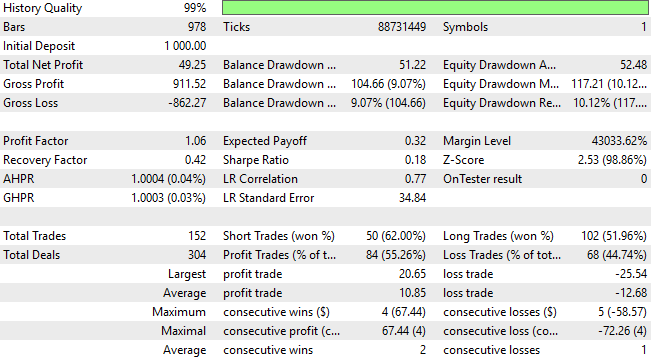
図25:詳細な結果から、新しい特徴量の追加は、収益改善の効果が限定的である可能性を示している
最終的な改良の試み
今回導入した22の特徴量は、互いに非線形な関係を持っていた可能性があります。そのため、これまで依存していた線形モデルでは、こうした複雑な関係性を十分に捉えられなかった可能性があります。これを解決するために、より強力な非線形モデルを定義します。具体的には、ランダムフォレストを用います。ランダムフォレストは、複数の決定木を構築し、それらの出力を平均化することで動作します。これにより、非線形の相互作用を学習し、線形モデルでは捉えにくいデータ内の微妙な依存関係も捉えることが可能になります。
from sklearn.ensemble import RandomForestRegressor
次に、同じデータセットに対して非線形モデルを学習させます。
model = RandomForestRegressor(random_state=0,max_depth=5,n_estimators=50) model.fit(data.loc[:,X],data[y])
最後に、学習済みモデルをONNXファイルとして書き出します。
onnx.save(onnx_proto,"EURUSD 2022-2025 RFR V5.onnx") MQL5での変更点の実装
先ほど書き出した改良版ONNXモデルを読み込みます。
//+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD 2022-2025 RFR V5.onnx" as const uchar onnx_proto[];
モデルを読み込んだら、前回と同じバックテスト期間でアプリケーションを再実行します。

図26:最終版取引アプリケーションを同じテスト期間で評価する
残念ながら、結果は前回バージョンと比べてわずかに収益性が改善した程度で、パフォーマンスは依然として第3版の戦略で達成した最適結果には大きく及びません。さらに、ショート取引とロング取引の分布を分析すると、シグナルの質が再び低下していることが分かります。ショート対ロングの比率が悪化しており、モデルは再び売りの機会を効果的に識別する能力を失っています。言い換えれば、より複雑なモデルで苦労しても、第3版というシンプルなモデルの方が、より強く安定した結果をより少ない複雑さで実現していたことが分かります。
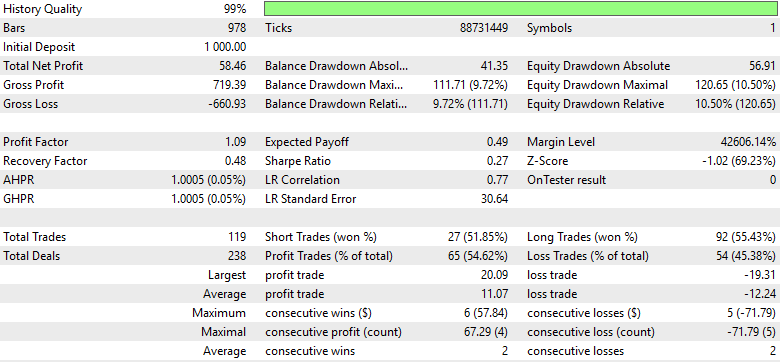
図27:最終版取引アプリケーションの詳細分析により、ピークパフォーマンスから後退していることが明らかになった
最新バージョンのエクイティカーブを確認すると、安定性や収益性において意味のある改善は見られません。この結果から、複雑さを増したモデルの探索は自然な停止点に達したと考えられます。そのため、第3版にロールバックして、今後の実験の安定した基準として使用することが最も妥当と考えられます。
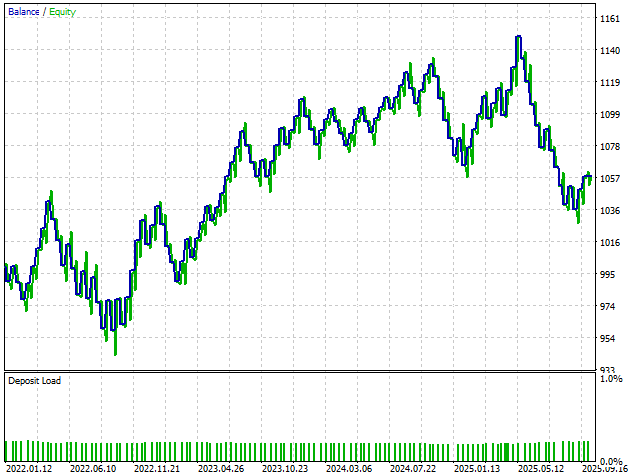
図28:最終版取引アプリケーションのエクイティカーブは、第3版が最適であったことを示している
結論
この議論を読むことで、読者は金融分野における統計モデルの収益性や潜在能力を制限する真の課題について、より深く理解できるようになります。重要なのは、成功はモデルの複雑さではなく、*方法論、つまり、モデルの設計、適用、解釈の仕方に大きく依存するという点です。
最先端のモデルや大量のデータを追求すれば必ずしも結果が改善するわけではなく、むしろ不必要なコストや収益低下を招くことすらあります。単純なモデルでも、適切に適用されれば、誤った前提に基づいた複雑なモデルを上回ることがしばしばあります。モデルのパフォーマンスは数学的手法だけで決まるのではなく、設定された目標、評価フレームワーク、設計上の選択によっても左右されます。多くの場合、方法論そのものが隠れた制約、つまり、「無視されている問題」なのです。
数十年にわたり、金融モデリングは固定された関係性や厳格な予測期間に依存してきましたが、市場は本質的に動的です。モデルが失敗する場合、それは学習できないからではなく、間違った目的を与えられたり、不適切な方法で学習したりすることが原因であることが多いです。
この議論は、金融における機械学習適用において、慎重な実験、注意深い検証、方法論の厳密性がいかに重要であるかを強調しています。進展が停滞したとき、解決策は必ずしもより大きなモデルやより多くのデータではありません。場合によっては、より良い目的変数を特定することやプロセスを改善することが鍵となります。複雑さそのものではなく、思慮深い方法論こそが、統計モデルの真の潜在能力を引き出します。
| ファイル名 | ファイルの説明 |
|---|---|
| Benchmark.mq5 | アプリケーションのベンチマーク版。利益は出なかったが、今後上回るための主要なパフォーマンス指標を確立した。 |
| V1.mq5 | 古典的手法に基づいて構築された初版。バックテストでは利益を生まなかった。 |
| V2.mq5 | 古典的手法から脱却し、移動平均インジケーターをモデル化した第2版。わずかな成功を収めた。 |
| V3.mq5 | 議論の中で発見した最良のバージョン。移動平均インジケーターを複数のホライズンでモデル化し、傾きから取引を実施する。 |
| V4.mq5 | 第3版と同じターゲットを使用した第4版。データ量を増やしたことで方法論上の制約により収益性は低下した。 |
| V5.mq5 | 非線形学習器を用いて大規模データセットをモデル化した最終版。第4版よりは利益が出たが、第3版のパフォーマンスには届かなかった。 |
| Deep_Analysis_V5.ipynb | 議論のために取得した市場データを分析したJupyter Notebook。 |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/20090
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索