記事「多通貨エキスパートアドバイザーの開発(第19回):Pythonで実装されたステージの作成」についてのディスカッション
こんにちは、
このコードでは シェルコマンドを実行して Python を起動します:
//+------------------------------------------------------------------+ //| タスクの開始| //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // これがEA最適化タスクの場合 if(m_type == TASK_TYPE_EX5) { // テスターで新しい最適化タスクを開始する MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // データベース内のタスク・ステータスを更新する DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // Pythonプログラムの実行タスクの場合 } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // シェルコマンド実行のためのオペレーションシステム(Windows)からの関数呼び出し ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
ここで
- m_pythonPathは 、現在のコンピュータ上のPythonへのパスです;
- m_settingは 、実行されたPythonプログラムの名前とそのコマンドライン引数を表す文字列です。
こんにちは
まずStage1を最適化し、完了しました。
その後、ClusteringStage1.pyとタスクとジョブをデータベースに追加し、再度最適化しましたが、このメッセージだけが表示され、うまくいきませんでした:
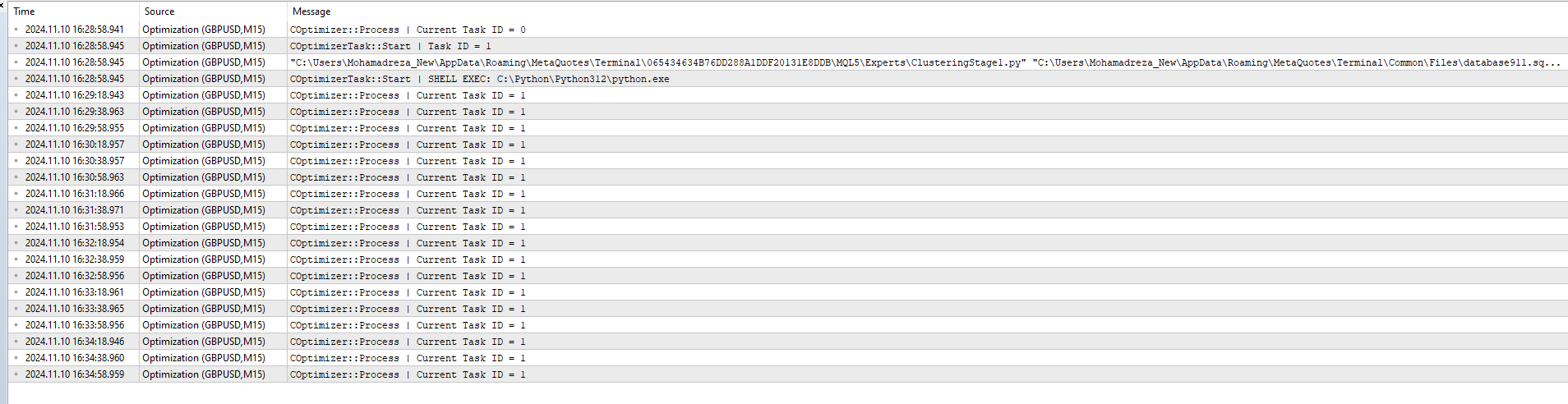
2024.11.10 16:35:18.952 最適化 ( GBPUSD , M15) COptimizer::Process | 現在のタスクID = 1
{kind=link}
こんにちは。
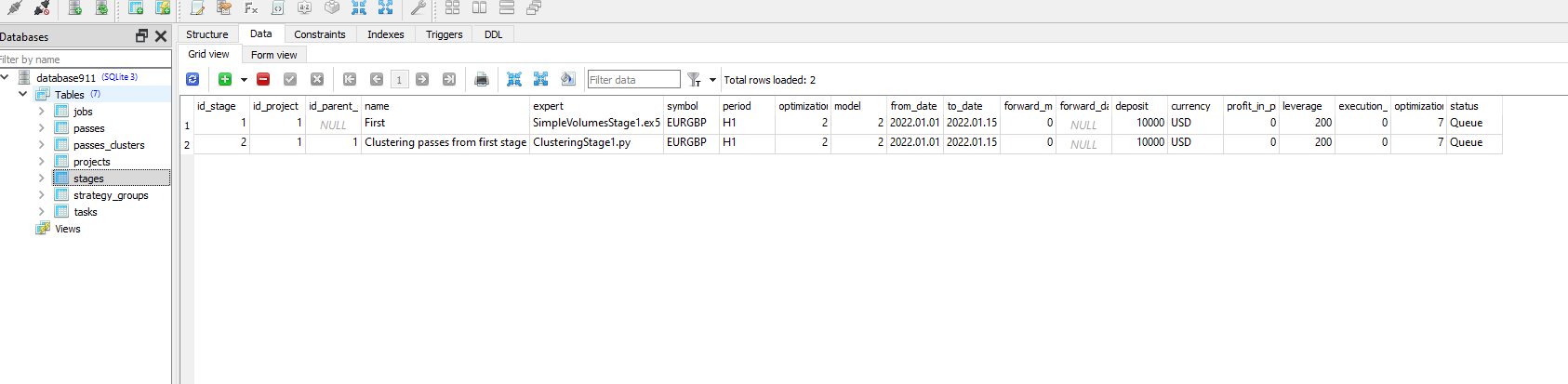
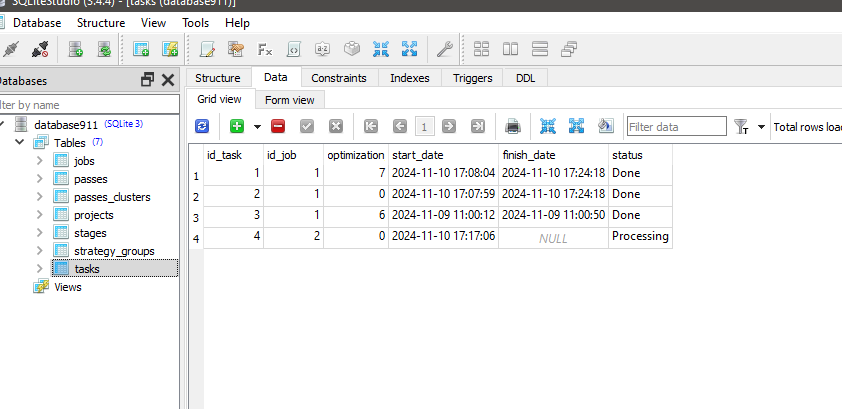
Python プログラムを実行しても、id_task=1 のタスクのステータスは変わらないようです。
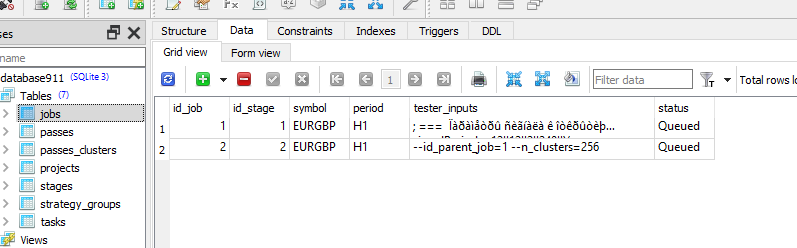
このタスクのジョブで、[tester_inputs] カラムに正しい値があるか確認してください。以下のようになります:
--id_parent_job=1 --n_clusters=256
1が最初の段階のジョブのid_job です。あなたの場合は他の値かもしれません。
コマンドラインから実際にパラメータを指定して Python プログラムを実行してみてください。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
パワーシェルで実行すると、次のようになる。
このように実行してみてください:
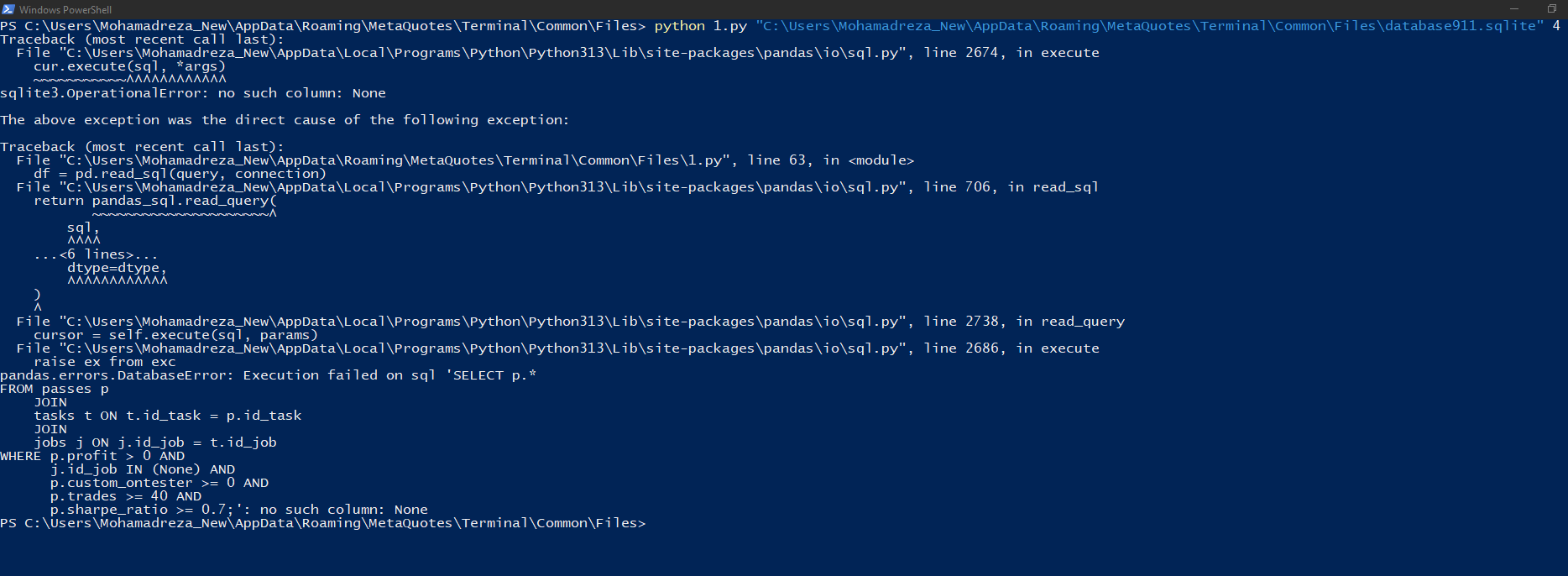
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" usage: ClusteringStage1.py [-h] [--id_parent_job ID_PARENT_JOB] [--n_clusters N_CLUSTERS] [--min_custom_ontester MIN_CUSTOM_ONTESTER] [--min_trades MIN_TRADES] [--min_sharpe_ratio MIN_SHARPE_RATIO] db_path id_task ClusteringStage1.py: error: the following arguments are required: db_path, id_task
db_path、id_taskの引数を設定する必要があります。そして、あなたが投稿したようなエラーメッセージが表示されました:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 Traceback (most recent call last): File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2674, in execute cur.execute(sql, *args) sqlite3.OperationalError: no such column: None The above exception was the direct cause of the following exception: Traceback (most recent call last): ... File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2686, in execute raise ex from exc pandas.errors.DatabaseError: Execution failed on sql 'SELECT p.* FROM passes p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job WHERE p.profit > 0 AND j.id_job IN (None) AND p.custom_ontester >= 0 AND p.trades >= 40 AND p.sharpe_ratio >= 0.7;': no such column: None
次の2つの引数も設定する必要があります: --id_parent_job=1 --n_clusters=256
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
どうなりますか?
私はこれを実行する
python -u "C:\UsersMohamadreza_NewAppDataRoamingMetaQuotesTerminal4B1CE69F577705455263BD980C39A82CMQL5ExpertsClusteringStage1.py.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\CommonFiles\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
以下のエラーが発生する
ValueError: n_samples=150 should be >= n_clusters=256.
そこで、 n_clusters=150に変更して、次のように実行しました 。
python -u "C: \UsersMohamadreza_NewAppDataRoaming\MetaQuotesTerminalpy" "C: \Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\CommonFiles\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
で、うまくいったと思う。しかし、データベースには変化がない。
その後、 n_samples=150で 最適化を 試したが、うまくいかなかった
興味深い記事だ!では、シリーズを全部読んでみよう。
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
なぜAlgLibライブラリの機能を捨てたのでしょうか?
#include <Math\Alglib\alglib.mqh> スピードの面ではマイナスだが、パイソンがすべてのコアで計算を並列化するからだ。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事「多通貨エキスパートアドバイザーの開発(第19回):Pythonで実装されたステージの作成」はパブリッシュされました:
クラスタリングには、Pythonの既製ライブラリであるscikit-learnのK-Meansアルゴリズムの実装を使用しました。これは唯一のクラスタリング手法ではありませんが、他のアルゴリズムを検討・比較してこの問題に最適なものを選ぶという作業は、現実的な範囲を超えていたため、手に入りやすいこのアルゴリズムを採用しました。その結果はかなり良好でした。
しかし、この実装を使うためには、小さなPythonプログラムを実行する必要がありました。操作の大部分を手動でおこなっていた当時は、これはそれほど面倒ではありませんでした。しかし今では、テストおよび戦略インスタンスのグループ選定のプロセス全体をかなり自動化しているため、連続的に実行される最適化タスクの中で、たとえ単純なものであっても手動操作が入るのは望ましくありません。
この問題を解決するには、2つの方法があります。ひとつは、MQL5で記述されたクラスタリングアルゴリズムの既製の実装を探すか、自分で実装する方法です。もうひとつは、最適化の自動化ステージの任意の段階で、MQL5で書かれたEAだけでなく、Pythonプログラムも実行できるようにすることです。
作者: Yuriy Bykov