
初級から中級まで:構造体(IV)

はじめに
前回の「初級から中級まで:構造体(III)」では、初心者が特に混乱しやすいテーマである「構造化されたコード」と「整理されたコード」の違いについて解説を始めました。多くの人が、コードがきれいに整理されていることと、構造化されていることを同一視してしまいますが、これらは似ているようで厳密には同じ概念ではありません。ただし、本記事は構造化プログラミングの世界における、より複雑で洗練され、興味深い内容への導入に過ぎません。
これから扱ういくつかの概念は、これまでの経験によって理解のしやすさが異なる可能性があります。そのため、本記事では各概念をできるだけ明確かつ客観的に説明することを目指します。目的は、構造化されたコードとは何か、そしてそれを用いてほぼあらゆるものをどのように構築できるのかを正しく理解することです。「ほぼ」としているのは、構造化プログラミングには制御できる範囲に限界があるためです。その限界に到達したときには、新たに「クラス」という概念を導入する必要があります。その段階で構造化プログラミングは終わりを迎え、オブジェクト指向プログラミング(OOP)へと移行することになります。ただし現時点では、構造化プログラミングを用いた多くの例を通じて、概念とその限界をしっかりと理解しながら、楽しく学んでいくことができます。
それでは、前回の記事の続きから進めていきましょう。そこではコードのpublicセクションとprivateセクションの使い方について触れましたが、なぜそのように使うのかという理由までは説明していませんでした。今回はその部分から解説を始めます。
構造体におけるコードのprivateセクション
構造体で定義される要素はすべてデフォルトでpublicであるため、publicセクションについては特に説明する必要はないと考えます。これは明示的に宣言する必要がなく、構造体の中で暗黙的に公開扱いとして扱われるためです。一方で、コードのprivateセクションはこれとは異なります。この場合、セクションを明示的に宣言する必要があります。しかしこれはコードの設計や扱い方にいくつかの重要な影響を与えます。まずは簡単な例から始めましょう。そして本記事は教育目的であるため、なぜそのように実装するのかという論理的背景を深く追求する必要はありません。重要なのは、その仕組みを理解することです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. double Values[]; 08. //+----------------+ 09. void Set(const double &arg[]) 10. { 11. ArrayCopy(Values, arg); 12. } 13. //+----------------+ 14. double Average(void) 15. { 16. double sum = 0; 17. 18. for (uint c = 0; c < Values.Size(); c++) 19. sum += Values[c]; 20. 21. return sum / Values.Size(); 22. } 23. //+----------------+ 24. double Median(void) 25. { 26. double Tmp[]; 27. 28. ArrayCopy(Tmp, Values); 29. ArraySort(Tmp); 30. if (!(Tmp.Size() & 1)) 31. { 32. int i = (int)MathFloor(Tmp.Size() / 2); 33. 34. return (Tmp[i] + Tmp[i - 1]) / 2.0; 35. } 36. return Tmp[Tmp.Size() / 2]; 37. } 38. //+----------------+ 39. }; 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. st_Data Info; 47. 48. Info.Set(H); 49. PrintX(Info.Average()); 50. PrintX(Info.Median()); 51. } 52. //+------------------------------------------------------------------+
コード01
コード01は非常にシンプルで、実用的かつ理解しやすい処理をおこないます。目指しているのは、文脈と操作手段を構造体の中にまとめた、完全に構造化されたコードを作ることです。そのために、まず独自の構造体を定義する必要があります。これは04行目でおこなわれています。ここで注意してください。この構造体で通常行われるのは、07行目の宣言のみです。なぜなら、それはまさに構造体に関する記事で説明・学習してきた内容だからです。しかし前回の記事では構造化プログラミングについての議論を始めており、それを実現するために構造体へさらに要素を追加しました。この場合は関数や手続きの追加へと進みます。つまり、構造体の内部にサブルーチンが存在し、それが構造化プログラムを定義することになります。
ただし、これらのサブルーチン(関数であれ手続きであれ)は必ずコンテキストの一部である必要があります。このコンテキストは、構造体内の変数や、その構造体を何のために設計したのかと密接に結び付いています。ここまでで、すべて理解できていると思います。構造体を定義したら、それを使用することができます。この特定の構造体の使用例として、43行目にあるOnStart手続きの中身を利用します。
まず45行目では数値定数の配列を定義します。これらの値が何を意味するかは重要ではありません。ここでは単なるサンプルデータです。次に46行目で、04行目で定義された構造体へアクセスするための変数を宣言します。この後、2つの方法があります。1つ目は48行目の処理を使用する方法であり、もう1つは後ほど検討します。48行目を実行すると、構造体内の07行目で宣言された配列が、現在必要としている値で埋められます。ここから興味深い部分が始まります。
構造化プログラミングがどのように変数の目的理解を容易にするかを考えてみてください。46行目でInfoを宣言した時点では、その宣言が何のためなのかは分かりません。その型の変数が必要だと分かるだけです。しかし構造体が内部に関数や手続きを持ち、それが値にコンテキストを与えているため、その構造体を使用する際にどのような処理がおこなわれるのかを理解できます。これらの関数や手続きが存在しなければ、構造体はあらゆる目的に使用可能(そして実際にそうすることも可能)になります。これは未解決の問題にも関係しています。しかし49行目と50行目を見ると、入力データの平均値と中央値を計算するための構造体だと分かります。
このような仕組みが「コンテキスト」を生み出します。つまり、何かが存在する理由を理解して初めて、それに意味が生まれるということです。コンテキストがなければ、変数も関数も手続きも、すべてがどのような意味にも解釈できてしまいます。そのためコード01を実行すると、次のような結果が得られます。
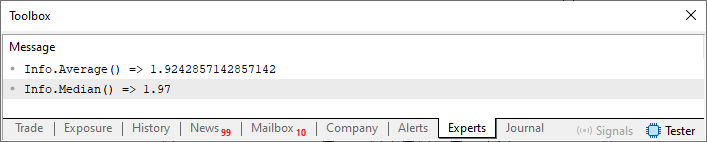
図01
言い換えると、45行目で指定された値が何を意味するか、あるいは現実世界とどのように関連しているかは問題ではありません。しかし構造体によって提供されるコンテキストの中では、表示される結果は次のようになるべきであると断言できます。この考え方はさまざまな用途に応用でき、構造体内のデータに関連する処理が必要な場合には、そのコンテキストを利用して結果の理解を簡潔かつ明確にすることができます。なぜなら構造体そのものがその情報に対する文脈を提供しているからです。
ポイントは、同じ目的のコードを別の方法で作成することも可能だという点です。しかしその場合、構造体内のデータと生成された結果を結びつける明確なコンテキストが失われます。そしてここが、多くの初心者が理解に苦しむ部分です。構造体にアクセス修飾子のセクションが指定されていない場合、その中のすべてはpublicとして扱われます。つまり情報を自由に操作できるということです。これを示し、プロセスの複雑さを理解するために、コードを以下のように変更します。
. . . 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. const double K[] = {12, 4, 7, 23, 38}; 47. 48. st_Data Info; 49. 50. Info.Set(H); 51. PrintX(Info.Average()); 52. 53. ArrayPrint(Info.Values, 2); 54. ZeroMemory(Info); 55. ArrayCopy(Info.Values, K); 56. 57. PrintX(Info.Median()); 58. 59. ArrayPrint(Info.Values, 2); 60. } 61. //+------------------------------------------------------------------+
コード02
コード02では、完全なコード(付録に掲載予定)のうち、OnStart手続きに関連する部分だけが変更されています。しかし、この変更は構造体のコンテキスト自体を変えていないにもかかわらず、最終的には正しい値を得るためのあらゆる期待を壊してしまいます。なぜなら、構造体内部の変数を変更できてしまうからです。より正確には、その変数へ直接アクセスできてしまうことが問題です。そして、これは非常に危険です。「もちろん、このコードを実行すれば値が変わるのは当然ではないか」と思うかもしれません。確かにその通りです。55行目では、04行目で定義された変数に新しい値を代入しています。そしてその変数は構造体の内部に存在しています。
「何が問題なのか分からない。何が起きているかは明らかではないか」と思うかもしれません。確かに、この説明用コードでは問題点を簡単に見つけられます。しかし実際のコードでは事情が異なります。実際の開発では、構造体の内部にコンテキストが保持されているため、この種の問題を特定するのは非常に困難になります。しかし55行目では、構造体自身が認識していない形で内部変数を強制的に変更しています。これによって状況は大きく複雑化し、なぜ結果が期待と一致しないのかを理解することが難しくなります。
この種のエラーは「カプセル化エラー」と呼ばれます。本来アクセスできるべきではないコードが内部情報を参照できてしまう、あるいはさらに悪い場合には、本来変更されるべきではない変数を変更できてしまうためです。しかし問題はさらに深刻です。これを理解するために、コード02の実行結果を確認する必要があります。結果は以下の通りです。
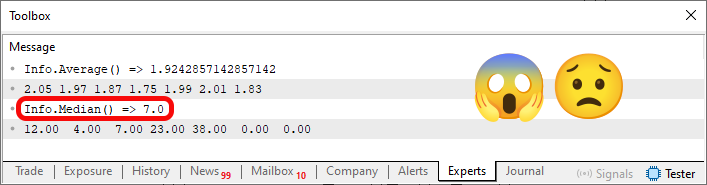
図02
注意してください。これはプログラマ採用試験で減点対象になり得る典型的な問題です。雇用者によってコード内で発生し得るエラーに対する理解度が確認された場合、この種の問題を見抜けないと不利になります。50行目が実行されると、45行目の値を格納するために十分なメモリが確保されます。この点までは問題ありません。そして53行目が実行されると、45行目で定義された値が正しく表示されます。つまり、コードは期待通りに動作しており、構造体も正しく定義されています。しかし54行目が実行されると、構造体内に存在するすべての変数がリセットされます。これはエラーではありません。実際、多くの場合、この動作は許容されるだけでなく望ましいものでもあります。構造体には複数の事前定義済み要素が存在する可能性があり、それらをまとめて削除したいケースがあるためです。
ところが55行目が実行されると、コード内でエラーが発生します。なぜなら、確保されたメモリが解放されておらず、単にリセットされただけだからです。その結果、59行目ではメモリ上に残っている実際の内容が表示されます。つまり、図02で強調されている配列Kの中央値は誤った値になります。「なぜ間違っているのか分からない」と感じるかもしれません。これを理解するには、本来の配列Kの中央値が何であるべきかを知る必要があります。コード02を見れば、中央値の求め方を理解している場合、正しい値は7ではなく12であることが分かります。誤った値が出力される理由は、59行目から参照可能になっている構造体内部に、本来存在してはいけないゼロ値や不要な要素が残っているためです。
これこそが、コードのprivateセクションを使用する必要がある理由です。そしてこれが、このテーマの根本にある問い、すなわち「なぜprivateセクションを使う必要があるのか」「どのような場面で使うべきなのか」につながります。ここで、「だったらコード02のようにせず、55行目でHをKに置き換えた上で、50行目と同じ処理を繰り返せば問題は解決するのでは?」と思うかもしれません。しかし、この場合は解決しません。構造体のコードには小さな欠陥が含まれているためです。ただし、その点については後ほど説明します。ここで重要なのは、私たちは気付かないうちにこの種のミスを犯してしまう可能性があるということです。しかし適切な概念を適用すれば、こうしたエラーは回避可能になり、コードの修正もはるかに容易になります。
最初の問題、つまり構造体内で宣言された変数へ直接アクセスできてしまう問題を解決するために、コードを以下のように修正します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayCopy(Values, arg); 16. } 17. //+----------------+ 18. double Average(void) 19. { 20. double sum = 0; 21. 22. for (uint c = 0; c < Values.Size(); c++) 23. sum += Values[c]; 24. 25. return sum / Values.Size(); 26. } 27. //+----------------+ 28. double Median(void) 29. { 30. double Tmp[]; 31. 32. ArrayCopy(Tmp, Values); 33. ArraySort(Tmp); 34. if (!(Tmp.Size() & 1)) 35. { 36. int i = (int)MathFloor(Tmp.Size() / 2); 37. 38. return (Tmp[i] + Tmp[i - 1]) / 2.0; 39. } 40. return Tmp[Tmp.Size() / 2]; 41. } 42. //+----------------+ 43. }; 44. //+------------------------------------------------------------------+ 45. #define PrintX(X) Print(#X, " => ", X) 46. //+------------------------------------------------------------------+ 47. void OnStart(void) 48. { 49. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 50. const double K[] = {12, 4, 7, 23, 38}; 51. 52. st_Data Info; 53. 54. Info.Set(H); 55. PrintX(Info.Average()); 56. 57. ArrayPrint(Info.Values, 2); 58. ZeroMemory(Info); 59. ArrayCopy(Info.Values, K); 60. 61. PrintX(Info.Median()); 62. 63. ArrayPrint(Info.Values, 2); 64. } 65. //+------------------------------------------------------------------+
コード03
ここで注意してください。多くのプログラマが構造体でprivateセクションを使用しないのは、まさにこれから起こることが原因です。
思い出してください。問題の原因はすべて59行目にあると言いました。コード03では、構造体内部で宣言された変数をprivateとして指定しています。つまり、その変数は構造体の外部から見えなくなります。これはまさに07行目によって実現されています。しかし一方で、構造体の外部から関数や手続きを利用できるようにするためには11行目が必要です。そうでなければ、その構造体はまったく役に立たなくなってしまいます。
コード03をコンパイルすると、コンパイル時にエラーメッセージが表示されます。これは当然の結果です。なぜなら、構造体の利用方法そのものを変更したからです。これらのエラーは以下に示されています。
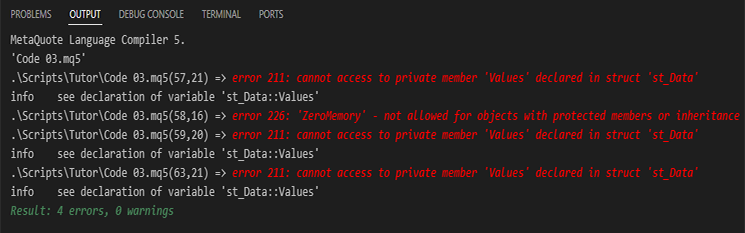
図03
コード03では、変数へ代入を行っている59行目だけでエラーが発生すると考えるかもしれません。しかし実際には4つのエラーが発生しています。なぜでしょうか。その理由は簡単です。理由は単純です。図03に示されている57行目、59行目、63行目のエラーは、いずれも「すでにアクセスできなくなったものへアクセスしようとしている」ことに起因しています。変数は構造体内部でprivateとして定義されているため、その構造体の内部からしかアクセスできません。これによって、構造体の存在理由と、その変数が持つコンテキストが維持されます。
では、58行目でZeroMemoryライブラリ関数を使い、構造体内のデータを完全に消去しようとした際に発生したエラーはどうでしょうか。なぜこのエラーまで発生するのでしょうか。その理由は、構造体および内部データに対して「コンテキスト」を形成しているからです。
その結果、データ構造へ直接アクセスしたり変更したりすることができなくなります。なぜなら、それはカプセル化を破壊し、内部データの本来の文脈を壊す可能性があるからです。まさに、この「カプセル化」と「コンテキスト」という概念こそが、構造体内のデータを常に安全かつ整合性のある状態に保つ役割を果たします。そしてそのために、これらの概念を維持するための新たな仕組みを実装する必要が生まれます。こうして、完全な構造化プログラミングが形作られていくのです。
「でもちょっと待ってください。以前のように自由に扱えないなら、このコードをどうやって動かし続けるんですか。カプセル化やコンテキストは、単にプログラミングを面倒にしているだけに思えます。昔のやり方の方がずっと簡単だったじゃないですか。」と思うかもしれません。正直に言えば、その考えには私も部分的に同意します。そして、新しい概念に初めて触れた多くのプログラマも、最初は同じように感じます。私自身もプログラミングを始めた頃はそうでした。当時は、構造化プログラミングのためにコードを設計する必要性が嫌で仕方ありませんでした。なぜなら、すべてが実際にどう動くべきかを細かく考え、整理することを強いられるからです。しかし時間が経ち、コードが複雑になるにつれて、その考えは変わっていきます。そこで初めて、構造化プログラミングが非常に大きな違いを生み出すことに気付くのです。
それでは、コードそのものに戻りましょう。コード03は実行可能ファイルを生成できないため、動作するよう修正する必要があります。そのため、以下のように再びコードを変更します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ . . . 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
コード04
コード04では、以前コード02でおこなっていた処理の実装例のひとつを示しています。そこでは、まず平均値Hを生成し、その後に配列Kの中央値を求めようとしていました。ただし注意してほしいのは、ここでは構造体の内部内容そのものを調査することが目的ではないという点です。なぜなら、分析に使用される値が何であるかはすでに分かっているからです。しかし、コード04の15行目を見てください。ここでは、構造体へ新しい内部値を代入しようとした際に発生していたエラーを修正しています。これはあくまで解決方法の一例です。実際には、ケースごとに異なる方法でこの初期化処理やクリーンアップ処理を実装することも可能です。
たとえば、コード02で行われていた処理をそのまま実現したい場合を考えてみましょう。つまり、コード02の54行目でおこなわれていたように構造体内の値をクリアし、さらに変数の内容を出力できるようにしたい場合です。では、カプセル化とコンテキストという概念を維持しながら、この問題をどのように解決すればよいのでしょうか。そのためのひとつの提案を以下に示します。ここが最も興味深い部分です。なぜなら、同じ問題を解決するための方法を、各プログラマがそれぞれ異なる形で考案し、実装できるからです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ZeroMemory(void) 20. { 21. Print(__FUNCTION__); 22. ArrayFree(Values); 23. } 24. //+----------------+ 25. void ArrayPrint(void) 26. { 27. Print(__FUNCTION__); 28. ArrayPrint(Values, 2); 29. } 30. //+----------------+ 31. double Average(void) 32. { 33. double sum = 0; 34. 35. for (uint c = 0; c < Values.Size(); c++) 36. sum += Values[c]; 37. 38. return sum / Values.Size(); 39. } 40. //+----------------+ 41. double Median(void) 42. { 43. double Tmp[]; 44. 45. ArrayCopy(Tmp, Values); 46. ArraySort(Tmp); 47. if (!(Tmp.Size() & 1)) 48. { 49. int i = (int)MathFloor(Tmp.Size() / 2); 50. 51. return (Tmp[i] + Tmp[i - 1]) / 2.0; 52. } 53. return Tmp[Tmp.Size() / 2]; 54. } 55. //+----------------+ 56. }; 57. //+------------------------------------------------------------------+ 58. #define PrintX(X) Print(#X, " => ", X) 59. //+------------------------------------------------------------------+ 60. void OnStart(void) 61. { 62. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 63. const double K[] = {12, 4, 7, 23, 38}; 64. 65. st_Data Info; 66. 67. Info.Set(H); 68. Info.ArrayPrint(); 69. PrintX(Info.Average()); 70. Info.ZeroMemory(); 71. 72. Info.Set(K); 73. PrintX(Info.Median()); 74. Info.ArrayPrint(); 75. } 76. //+------------------------------------------------------------------+
コード05
MetaTrader 5でコード05を実行すると、結果は以下のようになります。
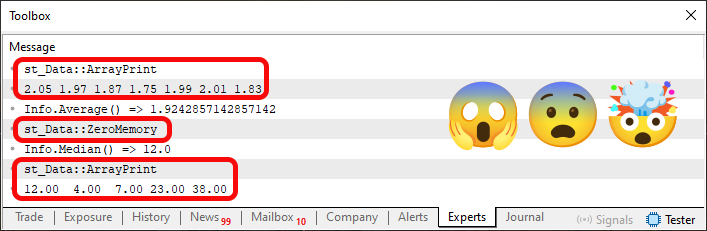
図04
図04では、いくつかの点を強調表示していることに注意してください。もちろん、「なぜその部分を強調しているのか?」と思うかもしれません。その理由はコード05を見ることで分かります。「19行目と25行目で一体何をしているのですか。こんなことをしても本当に大丈夫なのですか。」
先ほども述べたように、最も興味深い点は、同じ問題に対して各プログラマが異なる方法を考案できることにあります。構造化プログラミングでは、ここでコード05において私がおこなっているように、関数やライブラリ手続きの名前を自由に使用することができます。ただし注意が必要です。意図せず再帰呼び出しを発生させないようにしなければなりません。ここではMQL5標準ライブラリの関数をオーバーロードしているため、その危険性があります。
そして、この処理は構造体内に存在するコンテキストの中でおこなわれています。この構成によって問題が発生することはありません。特に68行目、70行目、74行目のコードは、独自のタグのようなものが作成された場合よりもはるかに理解しやすくなっています。どの手続きや関数が実行されるべきかを明確に確認できるからです。ただし、小さな注意点があります。すでに述べたように、この仕組みを実装する際には慎重さが必要です。これが実際にどのように動作するのかを示すために、コードへ21行目と27行目を追加しています。これにより実行フローを追跡し、最初から標準ライブラリ呼び出しが使用されているわけではないことを確認できます。コンパイラはまず、構造体内部で宣言された手続きや関数を使用し、その後で次の処理へ進みます。
ArrayPrint呼び出しの場合、コンパイラは最初に構造体内部で宣言されたものを使用します。これは68行目および74行目において、「現在実行されているコードは構造体内部のものである」とコンパイラへ通知しているためです。そしてこの問題を解決した後で、コンパイラは次の問題、つまり28行目の呼び出しを処理します。この呼び出しによって、実行フローはMQL5標準ライブラリ内のコードへ移行します。
ここで注意してほしいのは、privateセクションを宣言していなかったとしても、つまり9行目で宣言された変数を構造体専用かつ外部privateにしていなかったとしても、コード05を容易にコード02へ変換できるという点です。必要なのはわずかな変更だけです。逆に、コード02をコード05へ変換することも可能です。ただしこの場合、変換はそれほど簡単ではありません。その理由は、まさにコード02の55行目にあります。それでも、コード02における実行上の問題が特に気にならないのであれば、100%構造化プログラミングの枠組みの中で、コード02と完全に同じ動作を実現するソリューションを実装することも可能です。そのためには、次のようにする必要があります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ArrayCopy(const double &arg[]) 20. { 21. ArrayCopy(Values, arg); 22. } 23. //+----------------+ 24. void ZeroMemory(void) 25. { 26. ZeroMemory(Values); 27. } 28. //+----------------+ 29. void ArrayPrint(void) 30. { 31. ArrayPrint(Values, 2); 32. } 33. //+----------------+ 34. double Average(void) 35. { 36. double sum = 0; 37. 38. for (uint c = 0; c < Values.Size(); c++) 39. sum += Values[c]; 40. 41. return sum / Values.Size(); 42. } 43. //+----------------+ 44. double Median(void) 45. { 46. double Tmp[]; 47. 48. ArrayCopy(Tmp, Values); 49. ArraySort(Tmp); 50. if (!(Tmp.Size() & 1)) 51. { 52. int i = (int)MathFloor(Tmp.Size() / 2); 53. 54. return (Tmp[i] + Tmp[i - 1]) / 2.0; 55. } 56. return Tmp[Tmp.Size() / 2]; 57. } 58. //+----------------+ 59. }; 60. //+------------------------------------------------------------------+ 61. #define PrintX(X) Print(#X, " => ", X) 62. //+------------------------------------------------------------------+ 63. void OnStart(void) 64. { 65. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 66. const double K[] = {12, 4, 7, 23, 38}; 67. 68. st_Data Info; 69. 70. Info.Set(H); 71. PrintX(Info.Average()); 72. Info.ArrayPrint(); 73. 74. Info.ZeroMemory(); 75. Info.ArrayCopy(K); 76. 77. PrintX(Info.Median()); 78. Info.ArrayPrint(); 79. } 80. //+------------------------------------------------------------------+
コード06
コード06を実行すると、図02とまったく同じ結果が得られます。しかし、コード06がコード02とどのように異なっているかに注目してください。
まず第一に、コード02はカプセル化に従っていません。そのため、構造体のコンテキストが損なわれています。なぜなら、ある時点で、構造体自身が認識しないまま内部内容を変更してしまう危険性が存在するからです。
第二に、コード06は構造化プログラミングを完全に活用しています。そのため、問題や不具合が発生した場合、それは単純な見落としによるものとは言えません。構造化された手続きや関数を作成する際には、自分たちが何を作っているのかを理解しているからです。したがって、もし不具合が発生した場合、それはまさに誤った使用方法によるもの、あるいは本来の目的を理解しないまま構造体のコンテキストを変更しようとした結果だと言えます。
このような問題は、構造化プログラミングからOOPへ移行する際に非常に多くの混乱を生みます。なぜならOOPでは、理論上は構造体であるべきオブジェクトの意味を、元のオブジェクトとはまったく無関係なものへ完全に変えてしまうことができるからです。将来、OOPについて議論する際に、この「コンテキスト」という問題へ再び戻ることになります。
そのため、手順を飛ばしたり、あまりにも急いで先へ進もうとしたりしないことが非常に重要です。複雑な実装を生み出している基礎概念を理解しないまま先へ進もうとしても、プログラマとして成長する助けにはなりません。概念を深く理解すればするほど、それをさまざまな状況へ適用しやすくなります。
「構造化プログラミングの目的が少し分かってきた気がします。要するに、より安全で効率的なコードを書くためのものなんですね。でも質問があります。これまでおこなってきたことは、すべて手作業で実装していました。つまり、オーバーロードや関数と手続きテンプレートの説明で触れたような問題について、コンパイラから大きな支援を受けていたわけではありません。この種のプログラミングで、オーバーロードを避け、コンパイラの支援を利用しながら関数や手続きテンプレートを使って構造化プログラミングはできますか。それでも構造化プログラミングと言えるのでしょうか。」
これは非常に良い質問です。しかし、その方法については、少なくとも次回の記事が公開されるまでのお楽しみにしておきます。
まとめ
本記事では、構造化プログラミングにおけるコードの作成方法について解説しました。変数や情報を操作するためのコンテキストおよびメソッドを構造体内部へ配置することで、必要なコードを実装するための適切な文脈を構築する方法を見てきました。また、privateセクションを用いて公開されるものと公開されないものを分離する必要性についても確認しました。これによりカプセル化の原則が守られ、データ構造が本来持つべきコンテキストの整合性、安全性、信頼性を維持できることを理解しました。さらに、構造化プログラミングであってもミスが発生する可能性があること、あるいは本来意図されていないコンテキストを壊す関数や手続きを追加することで、不具合の連鎖を引き起こす可能性があることも確認しました。その結果、本来は単純だったコードが複雑化し、保守や利用が困難になる場合があります。
また、この種の実装におけるテンプレート利用についての疑問も提起しました。ただし、これはさらに複雑なテーマであり、本記事だけでも理解と実践のための十分な内容を含んでいるため、構造化プログラミングにおけるテンプレートの話題については次回の記事から扱う予定です。しかし、今回提供したコードを使って、今の段階からその考え方を意識し始めることはできます。そうすることで、まだ試していない概念や、これまで考えたことのない応用方法を実際に試すきっかけになるでしょう。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15860
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索