
从基础到中级:结构(五)

概述
在前一篇文章中 “从基础到中级:结构(四)”中,我们开始更认真、更实际地讨论如何编写结构化代码。对许多人而言,这些观点可能显得愚蠢且缺乏实际意义,尤其是考虑到如今的焦点几乎完全集中在面向对象编程上。而且许多人没有意识到,面向对象编程(OOP)并非一夜之间出现。它是整个编程社区广泛研究和辩论的结果,只有在结构化编程的局限性变得明显时才出现。
然而,与传统的编程不同,在传统编程中,我们声明变量、函数和过程来解决特定任务,而结构化编程旨在实现一种方法,使我们不仅能解决一个任务,还能解决一系列相互关联的问题。
我知道你们中的许多人(尤其是初学者)可能都在想:“朋友,我不想学这个。我想学习如何创建 EA 交易或指标。学习实现我根本不打算使用的解决方案,这真的不适合我。”好吧,你有权这么想。但是,如果你不懂得如何实现那些与指标或甚至与 EA 代码无关的解决方案,那么你会比你想象的更早走进死胡同。之所以出现这种情况,是因为你不懂得如何实现那些既不显而易见也不简单的解决方案。
为了能够解决出现的任何问题,你需要具备程序员的思维方式。其中一个问题正是迄今为止尚未解释清楚的:如何扩展结构化编程以解决更广泛的任务。换言之,如果我们编写代码来解决整数类型的问题,那么我们如何在不从头开始的情况下,为浮点数据实现一个解决方案呢?这是一个非常有趣的问题,但也可能让人感到非常困惑,因为实现同一目标的方法有很多种。
我将尝试至少解释两种不同的方法来完成这件事。第二种方法涉及内存操作,我不知道你是否准备好接受这种方法。不过,我们先从最简单的开始吧。这将使你对如何处理这个问题有一个大致的了解。那么,现在是时候关注本文的主题了。事情要变得有趣起来了。
如何在结构中使用模板
接下来,我们将分析在数据结构中使用模板的第一种方法,这是理解结构如何被重载的最简单方式。请记住,此处展示的所有内容仅供教育用途。在任何情况下,都不应将此材料视为最终代码,未经适当预防措施不得使用。
首先,让我们来看一下上一篇文章中的代码,因为我觉得与我们接下来要做的事情相关,这些代码非常实用且易于理解。我们将使用的版本如下所示:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. double Average(void) 20. { 21. double sum = 0; 22. 23. for (uint c = 0; c < Values.Size(); c++) 24. sum += Values[c]; 25. 26. return sum / Values.Size(); 27. } 28. //+----------------+ 29. double Median(void) 30. { 31. double Tmp[]; 32. 33. ArrayCopy(Tmp, Values); 34. ArraySort(Tmp); 35. if (!(Tmp.Size() & 1)) 36. { 37. int i = (int)MathFloor(Tmp.Size() / 2); 38. 39. return (Tmp[i] + Tmp[i - 1]) / 2.0; 40. } 41. return Tmp[Tmp.Size() / 2]; 42. } 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
代码 01
在 MetaTrader 5 平台执行代码 01,我们将得到以下结果:

图 01
目前还没有什么特别之处。但请考虑以下情况:代码 01 的实现是为了告诉我们两件事:一组值的平均值和中位数。但是,它只能处理浮点值,特别是双精度浮点值,因为它不理解单精度浮点值,即使单精度浮点值也是一种浮点数据类型。更不用说整数值了。
在这种情况下,尽管代码01看起来很实用,但实际上它基本上没什么用,因为要处理除 double 以外的数值数据类型,我们就必须一遍又一遍地实现这个结构,直到涵盖所有数值数据类型。
这种情况被称为重载。但是,结构重载的工作方式与函数和过程重载的工作方式不同。在这种情况下,执行重载时,我们必须更改结构的名称,即代码 01 的第 04 行处理的信息。
因此,我们将创建一系列具有相同目的、上下文和封装数据的新结构,但它们的名称却完全不同。换言之,就是一片混乱,工作量巨大。
程序员们,以我的经验来说,都不喜欢额外的工作。如果我们不得不重复代码多次,我们就会开始感到厌烦,失去兴趣。我们喜欢思考如何解决问题。但我们不喜欢仅仅为了改变一个细节就复制代码。我绝对讨厌做这件事。像我这样的其他程序员,也找到了解决此类问题的方法,并创建了一种机制,允许对无法重载的内容进行重载。这就是使用结构模板的想法诞生的原因。
我们已经在五篇短文中简要解释了模板的基本概念,第一篇是“从基础到中级:模板和类型名称(一) ”。因此,你务必充分掌握文中解释的所有知识和概念,以便理解接下来要做什么,这一点非常重要。这是因为之前所解释的内容仍然不明确的话,我们现在要做的事情就毫无意义。
但我们将展示的是处理结构重载最简单、最容易的方法,尽管还有其他方法,但它们要复杂得多,且具有非常特定的目标。我会考虑是否值得写一篇文章来展示其他方法。总之,最简单的办法就是使用模板。
所以,让我们先退一步,因为在考虑将结构模板应用于结构化实现之前,我们必须先看看它是如何应用于更一般的结构的。换言之,我们需要研究结构模板在常规代码中的使用方式。为此,我们将把代码 01 从结构代码更改为常规代码。最终结果如下:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. double Values[]; 07. }; 08. //+------------------------------------------------------------------+ 09. double Average(const st_Data &arg) 10. { 11. double sum = 0; 12. 13. for (uint c = 0; c < arg.Values.Size(); c++) 14. sum += arg.Values[c]; 15. 16. return sum / arg.Values.Size(); 17. } 18. //+------------------------------------------------------------------+ 19. double Median(const st_Data &arg) 20. { 21. double Tmp[]; 22. 23. ArrayCopy(Tmp, arg.Values); 24. ArraySort(Tmp); 25. if (!(Tmp.Size() & 1)) 26. { 27. int i = (int)MathFloor(Tmp.Size() / 2); 28. 29. return (Tmp[i] + Tmp[i - 1]) / 2.0; 30. } 31. return Tmp[Tmp.Size() / 2]; 32. } 33. //+------------------------------------------------------------------+ 34. #define PrintX(X) Print(#X, " => ", X) 35. //+------------------------------------------------------------------+ 36. void OnStart(void) 37. { 38. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 39. const double K[] = {12, 4, 7, 23, 38}; 40. 41. st_Data Info_1, 42. Info_2; 43. 44. ArrayCopy(Info_1.Values, H); 45. PrintX(Average(Info_1)); 46. 47. ArrayCopy(Info_2.Values, K); 48. PrintX(Median(Info_2)); 49. } 50. //+------------------------------------------------------------------+
代码 02
好了,现在代码 02 有了一个规范的格式。在 MetaTrader 5 中执行时,我们将得到以下结果:

图 02
那么,考虑到到目前为止所解释的一切,我相信你会很容易理解代码 02 的功能及其工作原理。就像我们可以使用浮点类型一样,我们也可以在这里实现函数和过程模板。因此,代码 02 将变为如下形式:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. double Values[]; 08. }; 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. double Average(const st_Data <T> &arg) 12. { 13. T sum = 0; 14. 15. for (uint c = 0; c < arg.Values.Size(); c++) 16. sum += arg.Values[c]; 17. 18. return sum / arg.Values.Size(); 19. } 20. //+------------------------------------------------------------------+ 21. template <typename T> 22. double Median(const st_Data <T> &arg) 23. { 24. T Tmp[]; 25. 26. ArrayCopy(Tmp, arg.Values); 27. ArraySort(Tmp); 28. if (!(Tmp.Size() & 1)) 29. { 30. int i = (int)MathFloor(Tmp.Size() / 2); 31. 32. return (Tmp[i] + Tmp[i - 1]) / 2.0; 33. } 34. return Tmp[Tmp.Size() / 2]; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uchar K[] = {12, 4, 7, 23, 38}; 43. 44. st_Data <double> Info_1; 45. st_Data <uchar> Info_2; 46. 47. ArrayCopy(Info_1.Values, H); 48. PrintX(Average(Info_1)); 49. 50. ArrayCopy(Info_2.Values, K); 51. PrintX(Median(Info_2)); 52. } 53. //+------------------------------------------------------------------+
代码 03
“多么复杂的宇宙难题啊。朋友,这是什么疯狂的代码?我们真的需要经历这一切吗?”冷静点,这段代码不像使用内存操作的那段代码那么疯狂。所以,我会考虑是否值得展示如何通过内存操作来实现结构重载。然而,代码 03 中的大部分内容对你来说应该是熟悉且易于理解的。或许只有第 44 行和第 45 行会有些出人意料之处。
顺便一提,在文章“从基础到中级:模板和类型名称(四)”中也讨论过类似的内容,但并非关于结构的使用,而是关于联合的使用。无论如何,工作原理都是相同的。既然之前已经解释过所有内容,我认为没有必要再次解释相同的概念,尤其是考虑到在两篇文章中都需要这样做。
所以,如果你不明白代码 03 中发生了什么,我建议你回顾之前的文章。正如我所说,知识是随着时间积累的。试图跳过某些阶段,认为不掌握基本概念也能理解更复杂的内容,这种做法很少能带来好的结果。
好吧,但这里有一个小细节,乍一看可能并不令人恼火:中位数返回的数据类型。这里的问题在于,如果数组包含偶数个元素,则第 28 行的测试将改变流程,从而执行第 32 行。但如果元素数量为奇数,则会执行第 34 行,这在很多情况下会导致得到与预期不同的值。
之所以会出现这种情况,是因为原则上,包含整数元素的数组不应返回浮点值,而此处却恰好返回了浮点值。因此,打印到终端的结果与第 42 行声明的数组值并不完全匹配,因为该数组包含整数元素,但返回值却是浮点类型。但鉴于这段代码纯粹是用于教学的,我宁愿保留这一小处差异,也不愿展示一个完全错误的结果。
因此,查看代码 03 并思考如何将其转换为类似于代码 01(具有结构化实现)的形式时,很容易找到正确的路径,因为只需修改代码 01,使其执行代码 03 中所示的模板声明即可。
但您可能会担心,在代码 03 中,我们必须将函数实现为模板。“那么,我们是否需要对代码 01 也进行同样的处理,以便结构化实现能够正常工作,并且编译器知道如何重载该结构?”那么,在这种情况下,就没有必要了,因为上下文本身很简单,没有太多需要补充的内容。
但是,与代码 03 中通过引用传递结构的值不同,在代码 01 中这是不可能实现的。原因已在前一篇文章中解释过,其中考虑了上下文问题以及数据封装问题。引入新值的唯一方法是通过 Set 过程,该过程存在于代码 01 中。因此,这一点将成为为数不多的、需实施与代码 01 中原有内容相异方案的情形之一。因此,下面我们展示了新的代码 01,该代码已经考虑到了结构重载的情况。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. double Average(void) 21. { 22. double sum = 0; 23. 24. for (uint c = 0; c < Values.Size(); c++) 25. sum += Values[c]; 26. 27. return sum / Values.Size(); 28. } 29. //+----------------+ 30. double Median(void) 31. { 32. T Tmp[]; 33. 34. ArrayCopy(Tmp, Values); 35. ArraySort(Tmp); 36. if (!(Tmp.Size() & 1)) 37. { 38. int i = (int)MathFloor(Tmp.Size() / 2); 39. 40. return (Tmp[i] + Tmp[i - 1]) / 2.0; 41. } 42. return (double) Tmp[Tmp.Size() / 2]; 43. } 44. //+----------------+ 45. }; 46. //+------------------------------------------------------------------+ 47. #define PrintX(X) Print(#X, " => ", X) 48. //+------------------------------------------------------------------+ 49. void OnStart(void) 50. { 51. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 52. const char K[] = {12, 4, 7, 23, 38}; 53. 54. st_Data <double> Info_1; 55. st_Data <char> Info_2; 56. 57. Info_1.Set(H); 58. PrintX(Info_1.Average()); 59. PrintX(Info_1.Median()); 60. 61. Info_2.Set(K); 62. PrintX(Info_2.Average()); 63. PrintX(Info_2.Median()); 64. } 65. //+------------------------------------------------------------------+
代码 04
请注意,将代码 01 转换为能够创建结构化重载的代码是多么简单,最终可以生成完全结构化的代码。由于函数和过程是在结构的上下文中声明的,因此它们继承了结构自身的声明。当编译器开始实现结构本身的重载时,就会出现这种情况。
如前所述,返回值的问题之所以出现,正是因为在某些时候我们会将整数值转换为浮点值,特别是 double 类型,这在某些情况下可能会引发问题。这可以从代码 04 的第 20 行和第 30 行看出。“但是等一下,我不明白这为什么会是个问题。如果确实存在这种情况,有没有办法克服它,避免不必要的风险?”
要理解这一点,我们首先需要看看执行代码 04 的结果会是什么。见下图:
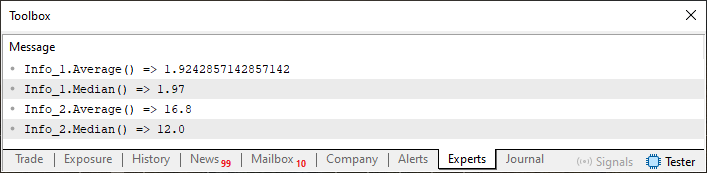
图 03
现在,请注意图片 03 中的一个细节。请注意,Info_2.Median 返回的值是一个浮点值,但在代码中声明时,Info_2 的类型为整数,如第 55 行所示。问题在于,当我们要求数据结构本身返回其中的中值时,该结构无法很好地处理这种情况,系统最终返回的是另一种类型。更准确地说,它应该返回一个整数值,但我们返回的是一个浮点数。
这些问题看似容易解决,但在实际操作和实际代码中,却要复杂得多。然而,从总体上看,许多程序员(我这么说是一般意义上的)使用一种方法论,即通过不断增加函数和过程来解决结构本身的某些内部问题。在大多数情况下,这种方法能解决问题,尽管它通常会产生一些在其他程序员看来原则上不太合理的解决方案或实现方式。原因很简单:解决问题的最佳方法不是直接解决问题,而是提供机制,使人们能够将问题分解成更小的部分来思考。
“但这怎么可能呢?这里似乎存在一些矛盾。”为了理解这一点,我们需要使用代码 04 作为教学机制。“第一点:为什么我们需要直接通过函数返回平均值?”有人可能会回答说,使用结构本身会让代码更简单。事实上,这的确是一个很好的论点。
但是,让我们回到第 55 行语句中的整数情况。我们放置在那里的元素(即第 61 行)的平均值实际上是一个浮点值,在本例中为 16.8。但考虑这样一种情况:我们需要一个平均值,而这个平均值必须是整数。那需要进行四舍五入。对于这种情况,有相应的四舍五入规则,但本案并不适用。
目标是让使用这种结构的程序员知道如何、何时以及为何对值进行舍入。任务是获取一个整数值。
为了实现这一目标,我们需要改变在结构中实现的内容的上下文。通常,我们不会删除代码的某些部分,而是会向其中添加新的部分,从而创建更小、更精确的代码块。为了更好地理解这一点,让我们来看一个实际例子。如您所见,在代码 04 的第 20 行,我们有一个函数来计算结构自身值的平均值。到目前为止,一切都很平常。
然而,请注意,要得出这个平均值,我们需要做两件事:首先,求出所有元素的总和;其次,确定总共有多少个元素。现在,你可能会想:“好的,接下来呢?”如果我们不直接在 Average 函数中实现这一功能,而是创建另外两个函数,那么就可以让结构的使用者选择如何、在何处以及为何对结构中元素的平均值进行舍入。
亲爱的读者,我不知道你们是否已经领会了要点,但让我们来看看在实践中是如何做到的。为此,我们将使用以下代码:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Sum(void) 21. { 22. T sum = 0; 23. 24. for (uint c = 0; c < NumberOfElements(); c++) 25. sum += Values[c]; 26. 27. return sum; 28. } 29. //+----------------+ 30. uint NumberOfElements(void) 31. { 32. return Values.Size(); 33. } 34. //+----------------+ 35. double Average(void) 36. { 37. return ((double)Sum() / NumberOfElements()); 38. } 39. //+----------------+ 40. double Median(void) 41. { 42. T Tmp[]; 43. 44. ArrayCopy(Tmp, Values); 45. ArraySort(Tmp); 46. if (!(Tmp.Size() & 1)) 47. { 48. int i = (int)MathFloor(Tmp.Size() / 2); 49. 50. return (Tmp[i] + Tmp[i - 1]) / 2.0; 51. } 52. return (double) Tmp[Tmp.Size() / 2]; 53. } 54. //+----------------+ 55. }; 56. //+------------------------------------------------------------------+ 57. #define PrintX(X) Print(#X, " => ", X) 58. //+------------------------------------------------------------------+ 59. void OnStart(void) 60. { 61. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 62. const char K[] = {12, 4, 7, 23, 38}; 63. 64. st_Data <double> Info_1; 65. st_Data <char> Info_2; 66. 67. Info_1.Set(H); 68. PrintX(Info_1.Average()); 69. PrintX(Info_1.Median()); 70. 71. Info_2.Set(K); 72. PrintX(Info_2.Average()); 73. PrintX(Info_2.Sum()); 74. PrintX(Info_2.NumberOfElements()); 75. PrintX(Info_2.Sum() / Info_2.NumberOfElements()); 76. PrintX(Info_2.Median()); 77. } 78. //+------------------------------------------------------------------+
代码 05
在代码 05 中,我们正在建模一种许多人认为只有在面向对象编程(OOP)中才会出现的现象,但其实它起源于结构化编程:将代码分解成小块。请注意,在此代码的第 20 行,我们现在有一个函数,其目的是返回结构中所有元素的总和。返回类型取决于结构体本身所包含的数据类型。请注意这一点,它很重要。我们还有另一个函数,位于第 30 行,其目的是返回结构体本身中的元素数量。
现在,最精彩的部分开始了。由于平均值是通过将上述函数中计算出的这两个量相除得到的,因此在第 37 行,我们进行了一项针对结构上下文的计算。但这才是关键所在。请注意,我们指示编译器将 Sum 函数的结果转换为 double 类型。为什么要这样做?答案可以在代码 05 的执行图像中看到。就在这里:
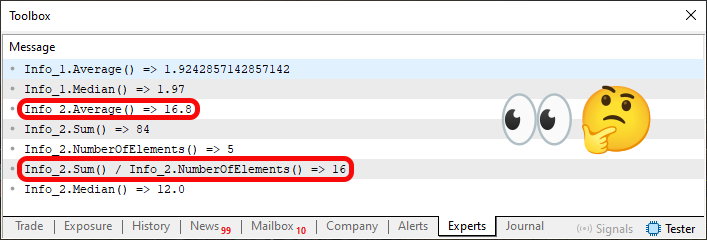
图 04
在这张图片中,有两个信息片段比较突出:一个对应于第 72 行的执行,另一个对应于第 75 行。然而,请注意,这两种呈现的数据类型是不同的。一个是浮点数,另一个是整数。下面,我们将解释为什么在第 37 行,Sum 函数的结果被转换为 double 类型。请注意,第 37 行执行的相同计算在第 75 行重复执行,但其中一种情况下,值 84(即第 62 行元素求和的结果)被转换为双精度浮点数,而另一种情况下则没有转换。因此,尽管上下文允许我们直接在结构内部计算平均值(如第 37 行所示),但我们也可以在结构外部进行计算。这正是我们能够根据所使用的数据类型来控制结果呈现方式的原因。
这或许看起来有些荒谬,但请注意,在不改变事物本质的情况下,我们赋予了程序员控制、调整甚至选择结果呈现方式的能力 —— 而若非如此,这将变得异常困难且耗时。所有这一切的实现,仅仅是通过将计算(之前在一个函数中完成)拆分为可在结构外访问的多个函数来实现的。然而,在这样做时,我们设法保留了结构本身的上下文,因为查看第 75 行,我们就能明白我们需要什么样的信息。
如果你研究这类内容,你就会明白,在大多数情况下,这就是我们在谈论类和面向对象编程时所指的意思。然而,通过这段简单的代码,我们已经证明了这个概念独立于面向对象编程(OOP)而存在。因此,当你在未来接触到这种编程模型时,你将已经具备了一个良好的基础,因为你会明白,面向对象编程(OOP)正是为了填补结构化编程无法解决的空白而设计的。
“好吧,这很有意思,但我们能不能做点别的,别把事情搞得太复杂?”是的,亲爱的读者。这里存在一种概念 —— 虽然不一定是概念,而是一种技术 —— 许多程序员在代码中使用它来简化我们在这里看到的很多内容。但如果你不明白这里讨论的内容,就很难理解我们如何实现结构重载。值得记住的是,我们一直在讨论的重载旨在构建一个更通用的结构,但这个结构适用于非常具体的上下文。
既然我们还有一点时间,我可以简要概述一下上述操作的具体内容。但在此之前,我们需要停下来思考以下几点。首先,请注意代码 05 的第 64 行和第 65 行中有一个语句,其目的是存储离散数据,即可以是整数或浮点数的值。然而,仔细想想,联合和结构也是数据的一种形式,因此它们也可以被声明为一种数据类型,用于构建代码,该代码将被重载以构建适合该特定数据类型的模型。
我认为你已经掌握了这一点,并且在我们讨论代码中重载和模板使用的文章中,你可能已经练习过了。然而,与离散数据类型不同,像联合和结构这样的类型更为复杂,因为它们可以包含多种不同的内容。以 MqlRates 结构为例。它定义了开盘价、收盘价、点差、成交量等元素。因此,尽管原则上我们可以声明一个能够接受任何类型信息(无论是复杂值还是离散值)的结构模板,但存在一些复杂因素阻碍我们(尽管“阻碍”一词可能不太恰当)在预期使用离散类型的地方定义复杂类型。但这并不妨碍我们创建特定的机制,以更低成本的方式解决特定任务。
所以,我希望你们思考一下,我们如何能够像代码 05 那样,在代码中使用诸如联合或结构之类的数据,以各种方式泛化结构的重载,从而构建完全结构化的代码。我知道这不是最容易的任务,但我想让你思考一下,因为在下一篇文章中,我们将深入探讨与此相关的内容。
总结性思考
在本文中,我们尝试以最简单、最易懂、最实用的方式解释如何重载结构化代码。我知道一开始理解起来可能会相当有挑战性,尤其是当你第一次看到它的时候。在尝试深入探讨更复杂、更精细的主题之前,掌握并理解这些概念是非常重要的。
附录中附有学习和练习所需的代码。在下一篇文章中,我们将进一步提高标准,将这种实现方式扩展到可以在结构中重载自身时使用任何数据类型的情况 —— 许多人认为这只有在面向对象编程(OOP)中才可能实现。但你会发现,要实现某些类型的解决方案,我们仍然不需要面向对象编程(OOP)。所以,祝你好运,学业有成!很快再见。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/15869
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
