
От начального до среднего уровня: Struct (IV)

Введение
В предыдущей статье "От начального до среднего уровня: Struct (III)", мы начали рассматривать тему, которая порождает большую путаницу среди новичков: разницу между структурированным и организованным кодом. Многие путают тот факт, что код правильно организован, с тем, что он структурирован. Хотя может показаться, что понятия одинаковы, это не совсем так. Однако эта статья служит лишь началом к чему-то более сложному, красивому и увлекательному в рамках структурированного программирования.
Поскольку существует несколько концепций, которые могут быть более или менее сложными для понимания, в зависимости от предыдущей практики, мы постараемся показать каждую концепцию в ясной и объективной форме. Цель состоит в том, чтобы вы получили правильное представление о том, что такое структурированный код и как с его помощью можно построить практически всё, что угодно. Я говорю "почти", поскольку существует ограничение на то, что управляет структурированным кодом. Когда мы приблизимся к этому ограничению, необходимо будет ввести еще одно понятие - класс. В этот момент мы оставим структурное программирование и перейдем к объектно-ориентированному программированию (ООП). Но пока мы можем изучить множество вещей и получить массу удовольствия от создания нескольких примеров структурированного кода, чтобы действительно понять концепции и ограничения структурированного программирования.
Ну что ж, продолжим с того места, на котором мы остановились в предыдущей статье: именно там мы упомянули и показали, как используются публичные и приватные части кода. Хотя не было объяснено, зачем это делается, мы начнем с этого момента.
Приватная часть кода в структуре
Поскольку каждый элемент, определенный в структуре, по умолчанию является публичным, я не вижу смысла объяснять часть public, поскольку ее не нужно объявлять в коде, она неявная, так как объявляется в структуре. Однако с приватной частью кода дело обстоит иначе. В этом случае часть должна быть явно выражена. Но это имеет определенные последствия для кода и того, как мы с ним работаем. Давайте начнем с чего-то простого. И, поскольку цель - образовательная, не пытайтесь найти логику, почему нужно реализовать код тем или иным способом. Постарайтесь понять концепцию, ведь это то, что действительно важно для нас.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. double Values[]; 08. //+----------------+ 09. void Set(const double &arg[]) 10. { 11. ArrayCopy(Values, arg); 12. } 13. //+----------------+ 14. double Average(void) 15. { 16. double sum = 0; 17. 18. for (uint c = 0; c < Values.Size(); c++) 19. sum += Values[c]; 20. 21. return sum / Values.Size(); 22. } 23. //+----------------+ 24. double Median(void) 25. { 26. double Tmp[]; 27. 28. ArrayCopy(Tmp, Values); 29. ArraySort(Tmp); 30. if (!(Tmp.Size() & 1)) 31. { 32. int i = (int)MathFloor(Tmp.Size() / 2); 33. 34. return (Tmp[i] + Tmp[i - 1]) / 2.0; 35. } 36. return Tmp[Tmp.Size() / 2]; 37. } 38. //+----------------+ 39. }; 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. st_Data Info; 47. 48. Info.Set(H); 49. PrintX(Info.Average()); 50. PrintX(Info.Median()); 51. } 52. //+------------------------------------------------------------------+
Код 01
Код 01 делает что-то очень простое, практичное и понятное. Идея заключается в том, чтобы создать полностью структурированный код. Для этого мы должны сначала определить нашу собственную структуру. Это делается в строке 04. А теперь внимание: единственное, что обычно делается в данной структуре, - это объявление в строке 07. Потому что именно это объясняли и изучали в статьях о структурах. Однако в предыдущей статье мы начали говорить о структурированном коде и, чтобы добиться этого, добавили в структуру ещё кое-что. В этом случае мы перейдем к добавлению функций и/или процедур. Итак, в структуре появятся внутренние подпрограммы, которые и определят структурированный код.
Однако эти подпрограммы, будь то функции или процедуры, должны быть частью контекста, а этот контекст связан с переменными, присутствующими в структуре, или с целью, для которой структура разрабатывается и реализуется. Пока, я думаю, вы всё поняли. После того, как структура определена, можно приступать к ее использованию. Чтобы проиллюстрировать использование данной конкретной структуры, мы воспользуемся тем, что находится внутри процедуры OnStart, присутствующей в строке 43.
Во-первых, в строке 45 мы определяем массив числовых констант. Неважно, что представляют собой данные значения, нам просто необходимо, чтобы они были. Теперь, в строке 46, мы объявляем переменную, чтобы получить доступ к структуре, определенной в строке 04. После этого у нас есть два пути, по которым мы можем продолжить. Первый - это использовать то, что мы видим в строке 48; второй рассмотрим позже. После выполнения строки 48 в структуре появится массив, объявленный в строке 07, с интересующими нас в данный момент значениями. Вот тут-то и начинается самое интересное.
Проследите за рассуждением, чтобы понять, как структурированный код облегчает понимание назначения переменной. Когда мы объявляем Info в строке 46, мы не знаем, для чего это объявление; нам просто нужна переменная данного конкретного типа. Но поскольку структура содержит внутренние функции и процедуры, которые придают контекст содержащимся в ней значениям, мы знаем, какой вид деятельности мы можем предпринять при её использовании. Если бы эти функции и процедуры не были объявлены, наша структура могла бы служить любой цели (и продолжает служить). Это связано с вопросом, который до сих пор остается открытым. Но, взглянув на строки 49 и 50, мы видим, что наша структура нацелена на вычисление средней и медианы тех самых данных, которые мы вводим в нее.
Подобные вещи создают то, что мы знаем как контекст. Другими словами, что-то имеет смысл только тогда, когда мы понимаем, почему оно существует. Без него любая переменная, функция или процедура может означать что угодно и иметь любое назначение. Таким образом, при выполнении кода 01 мы увидим следующий результат:
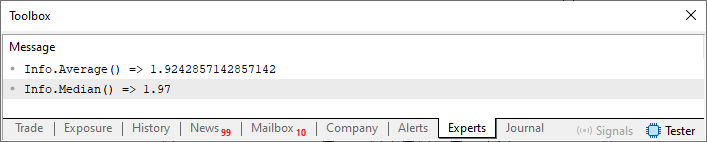
Изображение 01
Другими словами, нас не интересует, что означают значения, указанные в строке 45, и какова их связь с реальным миром. Но мы можем утверждать, что в контексте, предложенном структурой значений, результат, который должен быть показан, должен быть таким: Подобные вещи могут быть расширены множеством способов, поскольку всякий раз, когда нам нужно что-то связанное с данными в структуре, мы можем использовать контекст, чтобы подчеркнуть и упростить понимание самого результата, так как сама структура обеспечивает контекст для такого вида информации.
Прошу заметить, что мы могли бы создать такой же код для той же цели, но у нас не было бы реального контекста, связывающего данные в структуре с генерируемым ответом. И теперь наступает та часть, которую многим новичкам часто бывает трудно понять. В ней отмечается, что, поскольку в структуре не указана часть о доступе, всё, что там находится, считается публичным. Другими словами, мы можем манипулировать информацией совершенно произвольным образом. Чтобы показать это и понять сложность процесса, давайте изменим код таким образом:
. . . 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. const double K[] = {12, 4, 7, 23, 38}; 47. 48. st_Data Info; 49. 50. Info.Set(H); 51. PrintX(Info.Average()); 52. 53. ArrayPrint(Info.Values, 2); 54. ZeroMemory(Info); 55. ArrayCopy(Info.Values, K); 56. 57. PrintX(Info.Median()); 58. 59. ArrayPrint(Info.Values, 2); 60. } 61. //+------------------------------------------------------------------+
Код 02
В коде 02, который является лишь фрагментом полного кода (который будет в приложении), видно, что изменению подверглась только часть, относящаяся к процедуре OnStart. Однако данная модификация, хотя и не изменила контекст структуры, в итоге разрушила все надежды на получение соответствующих значений. Это происходит, потому что внутренняя переменная в структуре может быть изменена, а точнее, к ней можно получить доступ. И это действительно очень опасно. Можно подумать: «Конечно, значения будут другими, когда мы запустим этот код». Это очевидно, ведь строка 55 присваивает новые значения переменной, определенной в строке 04, которая, в свою очередь, находится внутри структуры.
Я не понимаю, в чем здесь проблема, поскольку мы ясно видим, что происходит. Верно, дорогой читатель, но я должен напомнить вам, что данные коды обучающие, и по этой причине в них легко найти ошибку. В реальном коде вам будет трудно добиться этого, так как используемый контекст сохраняется и присутствует в структуре. Однако тот факт, что в строке 55 мы заставляем переменную, присутствующую в структуре, быть измененной в то время как структура не знает об этом, значительно усложняет ситуацию и не позволяет понять, почему результаты неправильные и не соответствуют ожидаемому.
Этот вид ошибки называется «ошибкой инкапсуляции», поскольку код, который не должен видеть что-то, видит это, или, что ещё хуже, умудряется изменить переменную, которая не должна быть изменена. Однако проблема ещё более серьезная. Чтобы понять это, необходимо знать результат выполнения кода 02. Данный момент можно увидеть ниже:
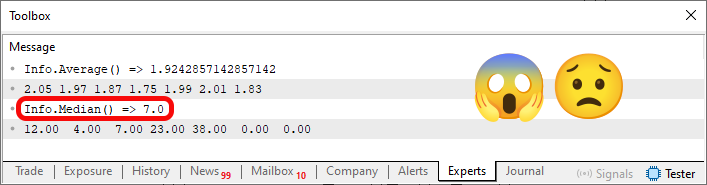
Изображение 02
Будьте внимательны, ведь это повод для провала при тестировании программиста, так как если работодатель хочет оценить ваш уровень знаний о возможных ошибках в коде, вы окажетесь в неудобном положении. Когда выполняется строка 50, выделяется достаточно памяти для хранения значений строки 45. Пока всё хорошо. Поэтому, когда выполняется строка 53, мы видим значения, объявленные в строке 45. То есть код работает так, как ожидалось, и структура определятся правильно. Однако при выполнении строки 54 все переменные, присутствующие в структуре, будут сброшены. Это не ошибка. На самом деле, во многих случаях это даже допустимо и желательно, так как в структуре может быть несколько предопределенных элементов, и мы хотим удалить их все.
Но при выполнении строки 55 в коде возникает ошибка. Это происходит, потому что выделенная память НЕ БЫЛА ОСБОВОЖДЕНА, она была просто сброшена. Поэтому фактическое содержимое памяти отображается в строке 59. Таким образом, медиана K, выделенная на изображении 02, является неверной. «Но почему это неправильно? Я не понимаю». Чтобы понять это, нужно знать, какой будет медиана K. Если посмотреть на код 02, то, при условии, что вы знаете, как найти медиану, вы увидите, что правильное значение - 12, а не 7. Причина неправильного значения заключается в том, что в структуре, которая видна из-за строки 59, присутствуют нули или элементы, которых НЕ ДОЛЖНО БЫТЬ.
Именно по этой причине нам необходимо использовать приватную часть кода. Это подводит нас к вопросу, который послужил основой для этой темы: понять, зачем и когда использовать приватную часть. Но можно подумать: «Брат, а что, если бы я случайно вместо того, чтобы использовать всё так, как показано в коде 02, повторил бы строку 50 в строке 55, только заменив H на K? Разве это не решило бы проблему?». В данном случае - нет. Код структуры содержит небольшой недостаток, но к этому мы еще вернемся. Идея заключается в том, чтобы понять, что мы можем совершать определенные ошибки, не осознавая этого. Но если применять правильные концепции, таких ошибок можно избежать, а код будет гораздо легче исправить.
Чтобы решить первую проблему, заключающуюся в том, что мы можем напрямую обращаться к переменной, которая объявляется в структуре, нам нужно изменить код, как показано ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayCopy(Values, arg); 16. } 17. //+----------------+ 18. double Average(void) 19. { 20. double sum = 0; 21. 22. for (uint c = 0; c < Values.Size(); c++) 23. sum += Values[c]; 24. 25. return sum / Values.Size(); 26. } 27. //+----------------+ 28. double Median(void) 29. { 30. double Tmp[]; 31. 32. ArrayCopy(Tmp, Values); 33. ArraySort(Tmp); 34. if (!(Tmp.Size() & 1)) 35. { 36. int i = (int)MathFloor(Tmp.Size() / 2); 37. 38. return (Tmp[i] + Tmp[i - 1]) / 2.0; 39. } 40. return Tmp[Tmp.Size() / 2]; 41. } 42. //+----------------+ 43. }; 44. //+------------------------------------------------------------------+ 45. #define PrintX(X) Print(#X, " => ", X) 46. //+------------------------------------------------------------------+ 47. void OnStart(void) 48. { 49. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 50. const double K[] = {12, 4, 7, 23, 38}; 51. 52. st_Data Info; 53. 54. Info.Set(H); 55. PrintX(Info.Average()); 56. 57. ArrayPrint(Info.Values, 2); 58. ZeroMemory(Info); 59. ArrayCopy(Info.Values, K); 60. 61. PrintX(Info.Median()); 62. 63. ArrayPrint(Info.Values, 2); 64. } 65. //+------------------------------------------------------------------+
Код 03
Теперь будьте внимательны, потому что многие программисты не используют приватную часть (private) в структурах именно из-за того, что сейчас произойдет.
Помните, мы говорили, что вся проблема была вызвана строкой 59? В коде 03 мы сообщаем компилятору, что переменная, объявленная внутри структуры, имеет тип private, то есть больше НЕ БУДЕТ ВИДНА ВНЕ ТЕЛА СТРУКТУРЫ. Это происходит именно благодаря строке 07. Но нам нужна строка 11, чтобы позволить другим элементам быть доступными вне тела структуры; в данном случае это функции и процедуры. Иначе конструкция станет совершенно бесполезной.
Когда мы попытаемся скомпилировать код 03, компилятор выдаст предупреждающие сообщения, указывающие на наличие ошибок в коде. Это часть процесса, поскольку мы изменили способ использования структуры. Данные ошибки можно увидеть чуть ниже:
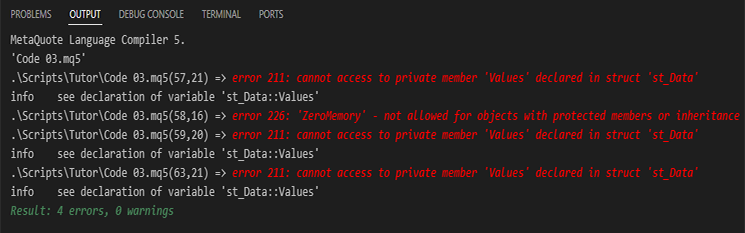
Изображение 03
Можно было бы ожидать, что ошибка возникнет только в строке 59 из кода 03, поскольку именно там мы присваиваем что-то переменной. Однако возникло четыре ошибки. Почему? Причина проста. Ошибки в строках 57, 59 и 63, которые можно видеть на изображении 03, как раз связаны с тем, что мы пытаемся получить доступ к тому, к чему мы уже не можем получить доступ, так как переменная является приватной в структуре. По этой причине доступ к ней возможен только в структуре, в которой она объявлена, что создает и поддерживает контекст существования структуры и самой переменной.
А как быть тогда с ошибкой в строке 58, где мы используем библиотечную функцию ZeroMemory для полной очистки данных в структуре? Почему эта ошибка появилась именно сейчас? Причина этого заключается в том, что мы создаем контекст для структуры и содержащихся в ней данных.
При этом мы больше не можем напрямую обращаться к структуре данных или изменять её, поскольку это нарушит инкапсуляцию и может повлиять на контекст внутренних данных. Именно эти понятия, инкапсуляция и контекст, гарантируют, что данные в структуре всегда будут в целости и сохранности. Это заставляет нас внедрять ряд новых решений, чтобы сохранить данные концепции. Так мы начнем строить полностью структурированное программирование.
«Но подождите секундочку. Если мы не можем делать всё так, как делали раньше, как мы собираемся поддерживать этот код в рабочем состоянии? Инкапсуляция и контекст, кажется, были созданы только для того, чтобы усложнить нам жизнь. Я предпочитаю программировать так, как это было раньше, - это намного проще». Что ж, я отчасти согласен с вами и со многими программистами, которые поначалу, сталкиваясь с чем-то новым, думают точно так же. Я и сам так думал, когда начинал программировать. И я ненавидел необходимость создавать структурированный код, потому что не видел в этом особого смысла, так как это часто заставляет нас думать и детализировать, как всё должно работать на самом деле. Но со временем я привык к этому, особенно когда твои коды становятся всё сложнее и сложнее. Именно тогда понимаешь, что структурированное программирование имеет огромное значение.
Давайте теперь вернемся к самому коду. Поскольку код 03 не может генерировать исполняемый файл, мы должны исправить его, чтобы он заработал. Для этого мы снова изменим его, как показано ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ . . . 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
Код 04
В коде 04 мы имеем одно из возможных предложений по реализации того же, что было сделано ранее в коде 02, где мы хотели сгенерировать среднее значение H, а затем медиану значений K. Но обратите внимание, что мы не заинтересованы в изучении внутреннего содержания структуры, поскольку мы знаем, какие значения будут использоваться для исследования. Однако посмотрите на строку 15 из кода 04. Здесь мы исправляем ошибку, возникшую при попытке присвоить структуре новые внутренние значения. Поэтому я и говорю, что это одно из возможных решений, ведь в зависимости от каждого конкретного случая можно выполнить эту чистку по-другому.
Например, предположим, что нам нужно, чтобы код выполнял именно то, что делалось в коде 02. Иными словами, мы очищаем значения структуры, как это было сделано в строке 54 из кода 02, а также можем вывести содержимое переменных. Как можно решить эту проблему, чтобы сохранить концепцию инкапсуляции и контекста? Для этого ниже приводится одно из возможных предложений. Это самая интересная часть игры, поскольку каждый программист может придумать и разработать различные способы решения одной и той же задачи.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ZeroMemory(void) 20. { 21. Print(__FUNCTION__); 22. ArrayFree(Values); 23. } 24. //+----------------+ 25. void ArrayPrint(void) 26. { 27. Print(__FUNCTION__); 28. ArrayPrint(Values, 2); 29. } 30. //+----------------+ 31. double Average(void) 32. { 33. double sum = 0; 34. 35. for (uint c = 0; c < Values.Size(); c++) 36. sum += Values[c]; 37. 38. return sum / Values.Size(); 39. } 40. //+----------------+ 41. double Median(void) 42. { 43. double Tmp[]; 44. 45. ArrayCopy(Tmp, Values); 46. ArraySort(Tmp); 47. if (!(Tmp.Size() & 1)) 48. { 49. int i = (int)MathFloor(Tmp.Size() / 2); 50. 51. return (Tmp[i] + Tmp[i - 1]) / 2.0; 52. } 53. return Tmp[Tmp.Size() / 2]; 54. } 55. //+----------------+ 56. }; 57. //+------------------------------------------------------------------+ 58. #define PrintX(X) Print(#X, " => ", X) 59. //+------------------------------------------------------------------+ 60. void OnStart(void) 61. { 62. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 63. const double K[] = {12, 4, 7, 23, 38}; 64. 65. st_Data Info; 66. 67. Info.Set(H); 68. Info.ArrayPrint(); 69. PrintX(Info.Average()); 70. Info.ZeroMemory(); 71. 72. Info.Set(K); 73. PrintX(Info.Median()); 74. Info.ArrayPrint(); 75. } 76. //+------------------------------------------------------------------+
Код 05
Если запустить код 05 в MetaTrader 5, то результат будет таким:
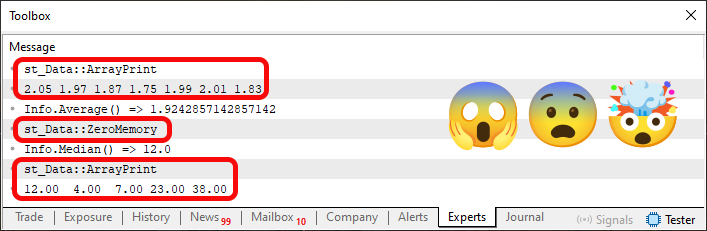
Изображение 04
Прошу заметить, что на изображении 04 мы выделяем некоторые аспекты. Но конечно вы можете спросить: почему вы выделяете эти вещи? Причину можно смотреть в коде 05. «Посмотрите на строки 19 и 25. Что за безумие вы здесь творите? Можно ли так делать?»
Как я уже недавно говорил, самое интересное заключается именно в том, что каждый программист может разрабатывать разные способы решения одной и той же задачи. В структурированном программировании можно без проблем использовать имена функций или библиотечных процедур, как я это делаю здесь, в коде 05. Однако следует быть осторожным, чтобы не сгенерировать рекурсивный вызов, не осознавая этого, как это происходит здесь, где мы создаем перегрузку стандартных функций библиотеки MQL5.
И мы делаем это в контексте, который присутствует в структуре. Такая конструкция не создаст никаких проблем, тем более что код в строках 68, 70 и 74 гораздо проще понять, чем если бы был создан специальный тег, так как мы можем четко видеть, какая процедура или функция должна быть выполнена. Но есть одна небольшая деталь: как уже говорилось, при ее реализации нужно быть осторожным. Чтобы показать, как это работает на практике, я добавил в код строки 21 и 27, чтобы вы могли проследить за ходом выполнения и понять, что мы не используем вызовы стандартной библиотеки с самого начала. Сначала компилятор использует процедуры, объявленные в структуре, и только потом выполняет дальнейшие действия.
В случае вызова ArrayPrint компилятор сначала использует то, что объявлено в структуре. Это происходит, потому что в строках 68 и 74 мы сообщаем ему, что выполняемый код находится в структуре. Только решив эту проблему, компилятор решит вторую проблему - вызов в строке 28. Это вызов, который направит поток выполнения на код, присутствующий в стандартной библиотеке MQL5.
Прошу заметить, что даже без объявления части private, которая сделала бы переменную, объявленную в строке 09, исключительной для структуры и скрытой от остального кода, мы могли бы легко преобразовать код 05 в код 02, поскольку нам нужно было бы сделать всего несколько изменений. То же самое можно сделать и наоборот: преобразовать код 02 в код 05. Но в этом случае преобразование не будет очень гладким, именно из-за строки 55 в коде 02. Однако, если проблема выполнения кода 02 не является для вас проблемой, можно реализовать решение, которое будет на 100% соответствовать тому, что делает код 02 в рамках 100% структурированного программирования. Чтобы добиться этого, нам нужно сделать следующее:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ArrayCopy(const double &arg[]) 20. { 21. ArrayCopy(Values, arg); 22. } 23. //+----------------+ 24. void ZeroMemory(void) 25. { 26. ZeroMemory(Values); 27. } 28. //+----------------+ 29. void ArrayPrint(void) 30. { 31. ArrayPrint(Values, 2); 32. } 33. //+----------------+ 34. double Average(void) 35. { 36. double sum = 0; 37. 38. for (uint c = 0; c < Values.Size(); c++) 39. sum += Values[c]; 40. 41. return sum / Values.Size(); 42. } 43. //+----------------+ 44. double Median(void) 45. { 46. double Tmp[]; 47. 48. ArrayCopy(Tmp, Values); 49. ArraySort(Tmp); 50. if (!(Tmp.Size() & 1)) 51. { 52. int i = (int)MathFloor(Tmp.Size() / 2); 53. 54. return (Tmp[i] + Tmp[i - 1]) / 2.0; 55. } 56. return Tmp[Tmp.Size() / 2]; 57. } 58. //+----------------+ 59. }; 60. //+------------------------------------------------------------------+ 61. #define PrintX(X) Print(#X, " => ", X) 62. //+------------------------------------------------------------------+ 63. void OnStart(void) 64. { 65. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 66. const double K[] = {12, 4, 7, 23, 38}; 67. 68. st_Data Info; 69. 70. Info.Set(H); 71. PrintX(Info.Average()); 72. Info.ArrayPrint(); 73. 74. Info.ZeroMemory(); 75. Info.ArrayCopy(K); 76. 77. PrintX(Info.Median()); 78. Info.ArrayPrint(); 79. } 80. //+------------------------------------------------------------------+
Код 06
При выполнении кода 06 мы получим точно такой же результат, как на изображении 02. Но обратите внимание, чем код 06 отличается от кода 02.
Прежде всего, код 02 не соблюдает инкапсуляцию, и по этой причине контекст оказывается в несколько затруднительном положении, так как в какой-то момент мы можем столкнуться с риском изменения внутреннего содержимого структуры без того, чтобы структура знала об этом.
Во-вторых, поскольку код 06 полностью использует структурированный код, любые проблемы или сбои ни в коем случае не могут быть вызваны простой рассеянностью, поскольку в процессе создания структурных процедур мы осознаем, что создаем. Поэтому если и случается сбой, то именно из-за неправильного использования или попытки изменить контекст структуры, даже без понимания её изначального назначения.
Подобные вещи создают много путаницы, когда мы переходим от структурного программирования к ООП, потому что там мы можем полностью изменить значение объекта, который в теории должен быть структурой, на что-то, не имеющее ничего общего с исходным объектом. В будущем, когда мы будем говорить об ООП, мы вернемся к этому вопросу о контексте.
Поэтому очень важно не пропускать шаги и не двигаться вперед слишком быстро. Попытка понять что-то, не разобравшись сначала в более простых вещах, которые усложнили реализацию, не поможет вам как программисту. Чем лучше понятна концепция, тем легче применять её в самых разных ситуациях.
«Кажется, я начинаю понимать, для чего нужно структурированное программирование. По сути, оно помогает нам создавать более безопасные и эффективные коды. Но у меня есть вопрос: всё, что мы делали до сих пор, приходилось делать вручную. То есть мы не получили от компилятора большой помощи в вопросах, подобных тем, которые обсуждались при объяснении перегрузки и использования шаблонов функций и процедур. Можем ли мы не генерировать перегрузку и использовать шаблоны функций и процедур с помощью компилятора в этом виде программирования с целью создания структурированного кода? Будет ли это структурным программированием?»
Это, безусловно, отличный вопрос. Тем не менее, я оставлю вас с желанием узнать, как это сделать, по крайней мере, до выпуска следующей статьи.
Заключительные идеи
В этой статье мы рассмотрели, как создавать так называемый структурный код, в котором весь контекст и способы манипулирования переменными и информацией помещаются в структуру, чтобы создать подходящий контекст для реализации любого нужного нам кода. Мы убедились в необходимости использования части private, чтобы разделить то, что является публичным, и то, что не является таковым, соблюдая тем самым правило инкапсуляции и сохраняя контекст, для которого была создана структура данных, в целостности, безопасности и надежности. Мы также увидели, что даже в структурированном коде можно совершать ошибки, а точнее, запускать лавину багов, именно внедряя функции или процедуры, которые нарушают изначально задуманный контекст, тем самым превращая простой код в нечто сложное и трудное для поддержки и использования.
Также был поднят вопрос об использовании шаблонов в этом типе реализации. Поскольку это гораздо более сложная тема, и в этой статье вам уже достаточно материала для понимания и практики, мы начнем обсуждать тему шаблонов в структурном коде в следующей статье. Но а вы можете начать уделять этому внимание, используя приведенные здесь коды. Это поможет вам применить на практике гипотезу об использовании концепций для того, о чем ещё не думали или не исследовали.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15860
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования