
Del básico al intermedio: Estructuras (IV)

Introducción
En el artículo anterior, "Del básico al intermedio: Estructuras (III)", comenzamos a tratar un tema que genera una gran confusión entre los principiantes: la diferencia entre un código estructurado y un código organizado. Muchos confunden el hecho de que un código esté debidamente organizado con que esté estructurado. Aunque aparentemente parezcan lo mismo, esto no es del todo cierto. No obstante, aquel artículo sirve solo como puerta de entrada a algo más elaborado, bello y divertido dentro de la programación estructurada.
Como existen diversos conceptos que pueden ser más o menos complejos de entender, dependiendo de la práctica previa de cada uno, intentaré mostrar cada concepto de manera clara y objetiva. El objetivo es que tú, mi querido lector, logres comprender de forma correcta qué es un código estructurado y cómo podemos trabajar con él para construir casi cualquier cosa. Digo «casi», pues existe una limitación en lo que rige un código estructurado. Cuando estemos próximos a alcanzar esta limitación, será necesario introducir otro concepto: el de las clases. En ese punto, saldremos de la programación estructurada y pasaremos a la programación orientada a objetos. Pero hasta entonces podremos explorar muchas cosas y divertirnos bastante creando varios ejemplos de código estructurado para comprender realmente los conceptos y limitaciones de la programación estructurada.
Bien, entonces continuaremos desde donde lo dejamos en el artículo anterior, que fue precisamente en el momento en que mencioné y mostré cómo se utilizaban las cláusulas public y private. Aunque no se explicó por qué se hace eso, partiremos de ese punto.
Cláusula private en una estructura
Como todo elemento definido en una estructura es público por defecto, no veo mucho sentido en explicar la cláusula public, ya que no es necesario declararla en el código, por lo que queda implícita en lo que se refiere a la declaración en una estructura. Sin embargo, esto no ocurre con la cláusula private. En este caso, la cláusula debe estar explícita en el código. Pero esto tiene algunas consecuencias para el código y para la forma de trabajar con él. Empecemos con algo sencillo y fácil de entender. Y, como el objetivo es la didáctica, no intentes buscar una lógica al porqué de implementar el código de una forma u otra. Intenta entender el concepto, pues eso es lo que realmente nos importa.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. double Values[]; 08. //+----------------+ 09. void Set(const double &arg[]) 10. { 11. ArrayCopy(Values, arg); 12. } 13. //+----------------+ 14. double Average(void) 15. { 16. double sum = 0; 17. 18. for (uint c = 0; c < Values.Size(); c++) 19. sum += Values[c]; 20. 21. return sum / Values.Size(); 22. } 23. //+----------------+ 24. double Median(void) 25. { 26. double Tmp[]; 27. 28. ArrayCopy(Tmp, Values); 29. ArraySort(Tmp); 30. if (!(Tmp.Size() & 1)) 31. { 32. int i = (int)MathFloor(Tmp.Size() / 2); 33. 34. return (Tmp[i] + Tmp[i - 1]) / 2.0; 35. } 36. return Tmp[Tmp.Size() / 2]; 37. } 38. //+----------------+ 39. }; 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. st_Data Info; 47. 48. Info.Set(H); 49. PrintX(Info.Average()); 50. PrintX(Info.Median()); 51. } 52. //+------------------------------------------------------------------+
Código 01
Este código 01 hace algo muy simple, práctico y fácil de entender. La idea aquí es crear un código completamente estructurado. Para ello, primero debemos definir nuestra propia estructura. Esto se hace en la línea cuatro. Ahora, presta atención. Lo único que se suele hacer dentro de esta estructura es declarar la línea siete. Esto es porque fue precisamente lo que se explicó y exploró en los artículos sobre estructuras. Sin embargo, en el artículo anterior, empezamos a hablar de código estructurado y, para conseguirlo, añadimos más cosas a la estructura. En este caso, iremos a añadir funciones y/o procedimientos. En resumen, en la estructura surgirán rutinas internas, lo que define un código estructurado.
Sin embargo, estas rutinas, ya sean funciones o procedimientos, necesitan formar parte de un contexto, y este contexto tiene que ver con las variables presentes en la estructura o con el objetivo para el que se está diseñando e implementando la estructura. Hasta este punto, creo que lo has comprendido. Una vez definida la estructura, podemos comenzar a utilizarla. Para ejemplificar la utilización de esta estructura en particular, usaremos lo que se encuentra dentro del procedimiento OnStart, presente en la línea 43.
En primer lugar, en la línea 45, definimos un array de constantes numéricas. No importa lo que representan estos valores, solo necesitamos que existan. Ahora, en la línea 46, declaramos una variable para poder acceder a la estructura definida en la línea 4. Una vez hecho esto, tenemos dos caminos que podemos seguir. El primero es utilizar lo que se ve en la línea 48; el segundo camino lo veremos después. Una vez ejecutada la línea 48, en la estructura tendremos el array declarado en la línea siete con los valores que nos interesan en este momento. Ahora es cuando la cosa comienza a ponerse interesante.
Sigue el razonamiento para entender cómo un código estructurado facilita la comprensión del propósito de una variable. Cuando declaramos Info en la línea 46, no sabemos con certeza cuál es el objetivo de dicha declaración; solo necesitábamos una variable de ese tipo específico. Sin embargo, como la estructura contiene funciones y procedimientos internos que dan contexto a los valores que contiene, sabemos qué tipo de actividad podemos adoptar al utilizarla. Si estas funciones y procedimientos no se hubieran declarado, nuestra estructura podría servir para cualquier propósito y aún podría servir. Esto se debe precisamente a una cuestión que todavía está abierta. No obstante, al mirar las líneas 49 y 50, vemos que nuestra estructura tiene como objetivo calcular la media y la mediana de los propios datos que estamos introduciendo en ella.
Este tipo de cosas crean lo que conocemos como contexto. Es decir, una cosa solo tiene sentido cuando entendemos el motivo por el que existe. Sin él, cualquier variable, función o procedimiento puede significar cualquier cosa y tener cualquier objetivo. Así, al ejecutar este código 01, el resultado que se debe mostrar aparece justo debajo.
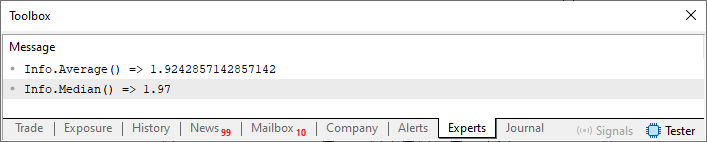
Imagen 01
Es decir, no nos interesa qué significan los valores declarados en la línea 45 ni cuál es su vínculo con el mundo real. Sin embargo, podemos afirmar que, dentro del contexto propuesto por la estructura de los valores, el resultado que se debe mostrar se ve justo abajo, en la imagen 01. Este tipo de cosas puede extenderse de diversas maneras, pues siempre que necesitemos algo relacionado con los datos dentro de una estructura, podemos utilizar el contexto para hacer hincapié y simplificar la comprensión del propio resultado, ya que la propia estructura nos proporciona un contexto para ese tipo de información.
Observa que podríamos crear el mismo código con el mismo objetivo, pero no tendríamos un contexto real que vincule los datos de la estructura con una respuesta generada. Pero ahora viene la parte que muchos principiantes suelen tener dificultades para entender. Observa que, por el hecho de que dentro de la estructura no se declare ninguna cláusula de acceso, todo lo que hay allí se considera público. Es decir, podemos manipular la información de manera completamente arbitraria. Para mostrar esto y para que puedas comprender la complejidad del proceso, vamos a cambiar el código tal y como se muestra a continuación.
. . . 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. const double K[] = {12, 4, 7, 23, 38}; 47. 48. st_Data Info; 49. 50. Info.Set(H); 51. PrintX(Info.Average()); 52. 53. ArrayPrint(Info.Values, 2); 54. ZeroMemory(Info); 55. ArrayCopy(Info.Values, K); 56. 57. PrintX(Info.Median()); 58. 59. ArrayPrint(Info.Values, 2); 60. } 61. //+------------------------------------------------------------------+
Código 02
En este código 02, que es solo un fragmento del código completo (el cual estará en el anexo), podemos ver que solo se modificó la parte referente al procedimiento OnStart. Sin embargo, esta modificación, a pesar de no haber alterado el contexto de la estructura, terminó por destruir cualquier expectativa de obtener valores adecuados. Esto se debe a que se permite modificar, o mejor dicho, acceder a la variable interna dentro de la estructura. Esto es algo realmente muy dramático y peligroso. Pero podrías pensar: «Claro, los valores serán diferentes cuando ejecutemos este código». Esto es obvio, ya que en la línea 55 se asignan nuevos valores a la variable definida en la línea cuatro, que a su vez está dentro de la estructura.
No sé cuál es el verdadero problema aquí, ya que claramente vemos lo que está pasando. Es cierto, querido lector, pero debo recordarte que estos códigos son didácticos y, por esta razón, es fácil encontrar un error. En un código real, te costaría mucho lograr esto, ya que el contexto que se utiliza se mantiene y está presente dentro de la estructura. No obstante, el hecho de que en la línea 55 estemos forzando que una variable presente en la estructura sea modificada sin que la estructura esté realmente al tanto de ello vuelve todo mucho más complicado y dificulta la comprensión de por qué los resultados son erróneos y no se corresponden con lo esperado.
A este tipo de fallo se le llama «falla de encapsulamiento», ya que un código que no debería ver algo lo está viendo, o incluso peor, está logrando modificar una variable que no debería ser modificada. Sin embargo, el problema es aún mayor. Para entenderlo, es necesario conocer el resultado de la ejecución del código 02. Esto puede verse a continuación.
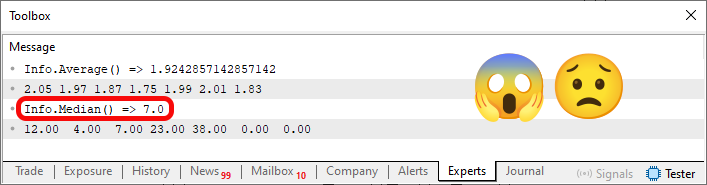
Imagen 02
Presta atención, pues esto es motivo de desaprobación en una prueba para programador, ya que el contratante quiere evaluar tu nivel de conocimiento sobre posibles fallos en los códigos. Cuando se ejecuta la línea 50, se asigna memoria suficiente para contener los valores de la línea 45. Hasta aquí todo parece correcto. Por esta razón, cuando se ejecuta la línea 53, podemos ver los valores declarados en la línea 45. Es decir, el código funciona como se espera y la estructura se define correctamente. No obstante, cuando se ejecuta la línea 54, se reiniciará cualquier variable presente en la estructura. No se trata de un error. De hecho, en muchos casos es incluso aceptable y deseable, ya que podemos tener diversos elementos previamente definidos en una estructura y querer eliminarlos todos.
Sin embargo, cuando se ejecuta la línea 55, se introduce un error en el código. Esto se debe a que la memoria asignada NO FUE LIBERADA, solo se reinició. Así, el contenido real de la memoria se muestra en la línea 59. Por tanto, la mediana de K, que aparece destacada en la imagen 02, es incorrecta. Pero, ¿por qué está equivocada? No lo entiendo. Para entenderlo, es necesario que sepas cuál sería la mediana de K. Al mirar el código 02, si sabes cómo encontrar la mediana, verás que el valor correcto es doce y no siete. El motivo por el que el valor es incorrecto es precisamente por los ceros o elementos que se encuentran en la estructura y que pueden verse debido a la línea 59, y que NO DEBERÍAN ESTAR ALLÍ.
Precisamente por este motivo, necesitamos hacer uso de la cláusula private. Así llegamos al punto que originó este tema: entender por qué y cuándo utilizar la cláusula private. Pero podrías estar pensando: «Amigo, ¿y si, por casualidad, en vez de usar las cosas como se mostró en este código 02, yo hubiera repetido la línea 50 en la línea 55, solo que cambiando la H por la K? ¿No resolvería esto el problema?» En este caso, no, mi querido lector. El código de la estructura contiene una pequeña falla. Pero ya llegaremos a eso. La idea aquí es precisamente mostrar que podemos cometer ciertos errores sin darnos cuenta. Sin embargo, si aplicamos los conceptos adecuados, tales errores se evitarían y el código se corregiría mucho más fácilmente.
Para resolver este primer problema, que consiste en que podemos acceder directamente a la variable declarada dentro de la estructura, necesitamos cambiar el código como se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayCopy(Values, arg); 16. } 17. //+----------------+ 18. double Average(void) 19. { 20. double sum = 0; 21. 22. for (uint c = 0; c < Values.Size(); c++) 23. sum += Values[c]; 24. 25. return sum / Values.Size(); 26. } 27. //+----------------+ 28. double Median(void) 29. { 30. double Tmp[]; 31. 32. ArrayCopy(Tmp, Values); 33. ArraySort(Tmp); 34. if (!(Tmp.Size() & 1)) 35. { 36. int i = (int)MathFloor(Tmp.Size() / 2); 37. 38. return (Tmp[i] + Tmp[i - 1]) / 2.0; 39. } 40. return Tmp[Tmp.Size() / 2]; 41. } 42. //+----------------+ 43. }; 44. //+------------------------------------------------------------------+ 45. #define PrintX(X) Print(#X, " => ", X) 46. //+------------------------------------------------------------------+ 47. void OnStart(void) 48. { 49. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 50. const double K[] = {12, 4, 7, 23, 38}; 51. 52. st_Data Info; 53. 54. Info.Set(H); 55. PrintX(Info.Average()); 56. 57. ArrayPrint(Info.Values, 2); 58. ZeroMemory(Info); 59. ArrayCopy(Info.Values, K); 60. 61. PrintX(Info.Median()); 62. 63. ArrayPrint(Info.Values, 2); 64. } 65. //+------------------------------------------------------------------+
Código 03
Ahora presta mucha atención, porque muchos programadores no usan la cláusula private en estructuras precisamente por lo que va a suceder en este momento.
¿Recuerdas que dije que todo el problema estaba causado por la línea 59? Pues bien, en este código 03 le estamos diciendo al compilador que la variable declarada dentro de la estructura es de tipo privado, es decir, que ya NO SERÁ VISIBLE FUERA DEL CUERPO DE LA ESTRUCTURA. Esto se debe precisamente a la línea siete. Sin embargo, necesitamos la línea 11 para permitir que otras cosas puedan accederse fuera del cuerpo de la estructura; en este caso, funciones y procedimientos. Si no, la estructura pasaría a ser completamente inútil.
Cuando intentes compilar este código 03, el compilador te mostrará mensajes de advertencia indicando que hay errores en el código. Es parte del proceso, ya que hemos cambiado la forma de utilizar la estructura. Estos errores se pueden ver justo debajo.
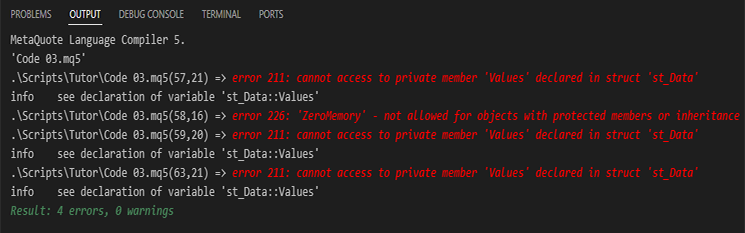
Imagen 03
Esperarías que el error solo ocurriera en la línea 59 del código 03, ya que es ahí donde estamos asignando algo a la variable. Sin embargo, se han generado cuatro errores. ¿Por qué? El motivo por el que ocurrió es simple. Los errores de las líneas 57, 59 y 63, que puedes ver en la imagen 03, se deben precisamente al hecho de que intentamos acceder a algo a lo que ya no podemos acceder, ya que la variable es privada dentro de la estructura. Por tanto, solo se puede acceder a ella dentro de la estructura donde se declara, creando y manteniendo así todo un contexto para la existencia de la estructura y de la propia variable.
Sin embargo, ¿qué pasa con el error de la línea 58, que es precisamente donde estamos usando la función de biblioteca ZeroMemory para limpiar completamente los datos de la estructura? ¿Por qué ha aparecido este error ahora? El motivo es precisamente el hecho de que estamos creando un contexto para la estructura y los datos que contiene.
Al hacerlo, ya no podemos acceder ni modificar directamente nada dentro de la estructura de datos, ya que esto rompería el encapsulamiento y podría afectar al contexto de los datos internos. Estos conceptos, el encapsulamiento y el contexto, son los que nos garantizan que los datos dentro de una estructura se mantendrán íntegros y seguros en todo momento. Esto nos obliga a implementar una serie de soluciones nuevas para mantener estos conceptos aplicados. Así es como se comienza a construir una programación completamente estructurada.
Pero espera un momento. Si no podemos hacer las cosas como las estábamos haciendo antes, ¿cómo vamos a mantener este código funcionando? El encapsulamiento y el contexto parecen haberse creado solo para complicarnos la vida. Prefiero programar como antes, porque es mucho más fácil y sencillo. Bien, mi querido lector, en parte estoy de acuerdo contigo y con muchos programadores que, al principio, cuando se enfrentan a algo nuevo, piensan igual. Yo mismo pensaba así cuando empecé. Y odiaba tener que crear códigos estructurados, porque no veía mucho sentido en hacerlo, ya que muchas veces nos obligan a pensar y detallar cómo necesitan funcionar realmente las cosas. Pero con el tiempo te acostumbras, sobre todo cuando tus códigos se vuelven cada vez más complejos y elaborados. Entonces es cuando te das cuenta de que una programación estructurada marca toda la diferencia.
Bien, pero volvamos al código en sí. Como este código 03 no puede generar un ejecutable, debemos corregirlo para que funcione. Para ello, lo modificaremos de nuevo, como se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ . . . 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
Código 04
En este código 04 tenemos una de las posibles propuestas para implementar lo mismo que se hacía antes en el código 02, donde se quería generar el promedio de los valores de H y, a continuación, la mediana de los valores de K. Pero fíjate que no nos interesa examinar el contenido interno de la estructura, ya que sabemos qué valores se van a utilizar realmente para el estudio. No obstante, fíjate en la línea 15 de este código 04. Allí estamos corrigiendo el error que se producía al intentar asignar nuevos valores internos a la estructura. Por eso digo que esta es una de las posibles soluciones, ya que, dependiendo de cada caso concreto, podrías querer hacer esta limpieza de otra manera.
Por ejemplo, supongamos que necesitas que el código ejecute exactamente lo que se hacía en el código 02. Es decir, limpiamos los valores de la estructura, como se hizo en la línea 54 del código 02, y también podemos imprimir el contenido de las variables. ¿Cómo podríamos resolver esta cuestión para mantener el concepto de encapsulamiento y contexto? Bien, para hacer esto, una de las posibles propuestas se muestra a continuación. Esta es la parte divertida del juego, ya que cada programador puede imaginar y elaborar diferentes formas de resolver el mismo problema.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ZeroMemory(void) 20. { 21. Print(__FUNCTION__); 22. ArrayFree(Values); 23. } 24. //+----------------+ 25. void ArrayPrint(void) 26. { 27. Print(__FUNCTION__); 28. ArrayPrint(Values, 2); 29. } 30. //+----------------+ 31. double Average(void) 32. { 33. double sum = 0; 34. 35. for (uint c = 0; c < Values.Size(); c++) 36. sum += Values[c]; 37. 38. return sum / Values.Size(); 39. } 40. //+----------------+ 41. double Median(void) 42. { 43. double Tmp[]; 44. 45. ArrayCopy(Tmp, Values); 46. ArraySort(Tmp); 47. if (!(Tmp.Size() & 1)) 48. { 49. int i = (int)MathFloor(Tmp.Size() / 2); 50. 51. return (Tmp[i] + Tmp[i - 1]) / 2.0; 52. } 53. return Tmp[Tmp.Size() / 2]; 54. } 55. //+----------------+ 56. }; 57. //+------------------------------------------------------------------+ 58. #define PrintX(X) Print(#X, " => ", X) 59. //+------------------------------------------------------------------+ 60. void OnStart(void) 61. { 62. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 63. const double K[] = {12, 4, 7, 23, 38}; 64. 65. st_Data Info; 66. 67. Info.Set(H); 68. Info.ArrayPrint(); 69. PrintX(Info.Average()); 70. Info.ZeroMemory(); 71. 72. Info.Set(K); 73. PrintX(Info.Median()); 74. Info.ArrayPrint(); 75. } 76. //+------------------------------------------------------------------+
Código 05
Cuando se ejecuta este código 05 en MetaTrader 5, el resultado es lo que se puede ver en la imagen a continuación.
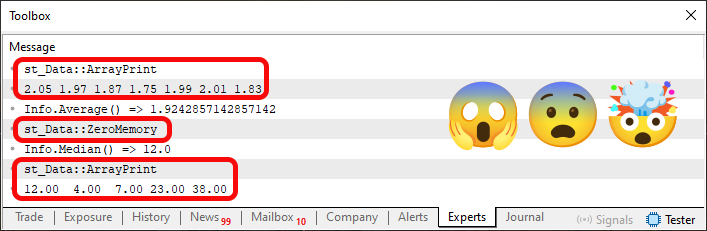
Imagen 04
Observa que en esta imagen 04 estoy resaltando algunos aspectos. Pero podrías preguntarte: ¿por qué motivo estás resaltando estas cosas? La razón puede verse en el código 05. Observa las líneas 19 y 25. ¿Cómo? ¿Qué locura estás haciendo aquí? ¿Esto se puede hacer?
Como mencioné recientemente, la parte divertida es precisamente que cada programador puede desarrollar formas diferentes para resolver el mismo problema. En una programación estructurada, puedes utilizar nombres de funciones o procedimientos de biblioteca sin problema, como hago aquí en el código 05. Sin embargo, debes tener cuidado para no generar una llamada recursiva sin darte cuenta, como ocurre aquí, donde estamos creando una sobrecarga de las funciones de la biblioteca estándar de MQL5.
Y estamos haciendo esto dentro de un contexto presente en la estructura. Esta construcción no nos generará ningún problema, sobre todo porque puedes ver que el código de las líneas 68, 70 y 74 es mucho más fácil de entender que si se hubiera creado una etiqueta exclusiva, ya que se puede ver claramente qué procedimiento o función se debe ejecutar. Sin embargo, hay un pequeño detalle: como se ha mencionado, debes tener cuidado al implementar esto. Para mostrar cómo funciona esto en la práctica, he añadido las líneas 21 y 27 al código, para que puedas seguir el flujo de ejecución y te des cuenta de que no estamos usando las llamadas a la biblioteca estándar desde el principio. En primer lugar, el compilador hará uso de las rutinas declaradas en la estructura y, solo después, tomará otras medidas.
En el caso de las llamadas a ArrayPrint, el compilador usará primero lo que está declarado en la estructura. Esto se debe a que, en las líneas 68 y 74, le indicamos que el código que se va a ejecutar se encuentra en la estructura. Solo después de resolver esta cuestión, el compilador resolverá la otra, que es la llamada de la línea 28. Esta es la llamada que dirigirá el flujo de ejecución al código presente en la biblioteca estándar de MQL5.
Observa que, incluso sin declarar la cláusula private, que haría que la variable declarada en la línea nueve fuera exclusiva de la estructura y oculta para el resto del código, podríamos transformar fácilmente el código 05 en el código 02, ya que solo necesitaríamos realizar algunos cambios. Lo mismo se puede hacer en sentido contrario: convertir el código 02 en el código 05. Sin embargo, en este caso, la transformación no sería muy suave, precisamente por la línea 55 presente en el código 02. No obstante, si el problema de ejecución del código 02 no te supone un inconveniente, puedes implementar una solución que sería 100 % fiel a lo que hace el código 02 dentro de una programación estructurada al cien por cien. Para conseguirlo, todo lo que necesitaríamos hacer se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ArrayCopy(const double &arg[]) 20. { 21. ArrayCopy(Values, arg); 22. } 23. //+----------------+ 24. void ZeroMemory(void) 25. { 26. ZeroMemory(Values); 27. } 28. //+----------------+ 29. void ArrayPrint(void) 30. { 31. ArrayPrint(Values, 2); 32. } 33. //+----------------+ 34. double Average(void) 35. { 36. double sum = 0; 37. 38. for (uint c = 0; c < Values.Size(); c++) 39. sum += Values[c]; 40. 41. return sum / Values.Size(); 42. } 43. //+----------------+ 44. double Median(void) 45. { 46. double Tmp[]; 47. 48. ArrayCopy(Tmp, Values); 49. ArraySort(Tmp); 50. if (!(Tmp.Size() & 1)) 51. { 52. int i = (int)MathFloor(Tmp.Size() / 2); 53. 54. return (Tmp[i] + Tmp[i - 1]) / 2.0; 55. } 56. return Tmp[Tmp.Size() / 2]; 57. } 58. //+----------------+ 59. }; 60. //+------------------------------------------------------------------+ 61. #define PrintX(X) Print(#X, " => ", X) 62. //+------------------------------------------------------------------+ 63. void OnStart(void) 64. { 65. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 66. const double K[] = {12, 4, 7, 23, 38}; 67. 68. st_Data Info; 69. 70. Info.Set(H); 71. PrintX(Info.Average()); 72. Info.ArrayPrint(); 73. 74. Info.ZeroMemory(); 75. Info.ArrayCopy(K); 76. 77. PrintX(Info.Median()); 78. Info.ArrayPrint(); 79. } 80. //+------------------------------------------------------------------+
Código 06
Cuando se ejecuta este código 06, se obtiene exactamente la misma salida que se observa en la imagen 02. Pero fíjate en cómo este código 06 es diferente del código 02.
En primer lugar, el código 02 no respeta el encapsulamiento y, por esta razón, el contexto termina en una situación algo complicada, ya que en algún momento podríamos estar corriendo el riesgo de cambiar el contenido interno de la estructura sin que esta esté realmente al tanto de ello.
En segundo lugar, dado que este código 06 hace uso completo de un código estructurado, cualquier problema o fallo no puede deberse en ningún caso a una simple distracción, ya que durante el proceso de creación de las rutinas de la estructura somos conscientes de lo que estamos creando. Por tanto, si se produce un fallo, es precisamente por un mal uso o por intentar cambiar el contexto de la estructura sin entender siquiera el objetivo inicial de esta.
Este tipo de cosas genera una gran confusión cuando pasamos de la programación estructurada a la programación orientada a objetos, ya que allí podemos cambiar completamente el significado de un objeto, que en teoría sería una estructura, por algo que no tiene nada que ver con el objeto original. En el futuro, cuando hablemos de programación orientada a objetos, volveremos a tratar este tema del contexto.
Por eso, es muy importante no saltarse etapas ni querer avanzar demasiado rápido. Intentar entender algo sin antes haber comprendido otras cosas más simples que dieron lugar a una implementación más elaborada no te ayudará en lo que se refiere a la programación. Cuanto mejor se comprenda un concepto, más fácil resultará aplicarlo a las situaciones más diversas.
Creo que empiezo a entender para qué sirve la programación estructurada. Básicamente, sirve para ayudarnos a crear códigos más simples, seguros y eficientes. Pero tengo una pregunta: todo lo que hemos hecho hasta ahora ha tenido que hacerse a mano. Es decir, no hemos contado con mucha ayuda del compilador en cuestiones como las que se vieron cuando se explicó la sobrecarga y el uso de plantillas de funciones y procedimientos. ¿No podemos generar sobrecarga y usar plantillas de funciones y procedimientos con la ayuda del compilador en este tipo de programación con miras a la creación de un código estructurado? ¿Esto sería programación estructural?
Sin duda, es una pregunta excelente, mi querido lector. Sin embargo, voy a dejarte con las ganas de saber cómo hacerlo, al menos hasta que se publique el próximo artículo.
Consideraciones finales
En este artículo, vimos cómo producir el llamado código estructural, en el que se coloca todo el contexto y las formas de manipular variables e información dentro de una estructura, con el fin de generar un contexto adecuado para la implementación de cualquier código. Vimos la necesidad de hacer uso de la cláusula private con el objetivo de separar lo que es o no público, respetando así la regla del encapsulamiento y manteniendo íntegro, seguro y confiable el contexto por el que una estructura de datos fue creada durante todo el tiempo. También vimos que, incluso dentro de un código estructurado, podemos llegar a cometer errores, o mejor dicho, iniciar una avalancha de fallos, precisamente por implementar funciones o procedimientos que rompen el contexto inicialmente pensado, convirtiendo así un código que sería simple y fácil de entender en algo complejo y difícil de mantener y utilizar.
También se planteó la cuestión del uso de plantillas en este tipo de implementación. Como este es un tema mucho más complejo, y ya tienes bastante que entender y practicar en este artículo, comenzaremos a abordar el tema de las plantillas en un código estructural en el próximo artículo. Pero puedes empezar a prestar atención para hacerlo con los códigos mostrados aquí. Esto te ayudará a poner en práctica la hipótesis de utilizar conceptos para algo no pensado ni explorado todavía.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15860
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso