
データサイエンスと機械学習(第17回):木の中のお金?外国為替取引におけるランダムフォレストの芸術と科学

頭が2つある方が1つよりいいのは、どちらかが確実だからではなく、同じ方向に間違っていく可能性が低いからです。
ランダムフォレストアルゴリズム
ランダムフォレストは、訓練中に多数の決定木を構築することで動作し、クラス、つまりクラスのモード(分類)または個々の木の平均予測(回帰)を出力するアンサンブル学習方法です。ランダムフォレスト内のそれぞれの木はデータの異なるサブセットで訓練され、訓練中に導入されるランダム性はモデルの全体的なパフォーマンスと一般化の向上に役立ちます。
これをよりよく理解するには、機械学習用語のアンサンブル学習について考察する必要があります。
アンサンブル学習
アンサンブル学習は、2つ以上の機械学習モデルを同じデータに適合させ、各モデルの予測を組み合わせるアプローチです。アンサンブル学習は、個別のモデルよりもアンサンブルモデルを使用した方がパフォーマンスが向上することを目的としています。
ランダムフォレストは、複数の決定木の予測を組み合わせて、個別/単一モデルの全体的な予測能力を向上させるアンサンブル手法です。

これを実証するために、決定木と10本の木のランダムフォレストセットを作成しました。同じデータセットを使用することで、ランダムフォレストAIを使用した訓練とテストのフェーズでより高い精度が得られました。
ランダムフォレストAIの主な機能
01:アンサンブル学習
ランダムフォレストは、複数の機械学習モデルの予測を組み合わせて全体的なパフォーマンスを向上させるアンサンブル手法です。
for (uint i=0; i<m_ntrees; i++) //Build a given x number of trees { temp_data = data; matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets forest[i] = new CDecisionTreeClassifier(this.m_minsplit, this.m_maxdepth); //Add the tree to the forest forest[i].fit(x_subset, y_subset); //Add the trained tree to the forest preds = forest[i].predict(x_subset); }
02:ブートストラップ集約(バギング)
機械学習におけるブートストラップは、多くの場合、母集団パラメータを推定するために、置換を使用してソースデータからサンプルを繰り返し抽出するリサンプリング手法です。
ランダムフォレスト内のそれぞれの木は、ブートストラップ(置換を伴うサンプリング)によって作成されたデータの異なるサブセットで訓練されます。
matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets
ソース:
template<typename T> void CMatrixutils::Randomize(matrix<T> &matrix_,int random_state=-1, bool replace=false)
replace=trueパラメータを使用すると、同じインデックスを複数回選択して、ブートストラッププロセスをシミュレートできます。
03:特徴のランダム性
それぞれの木の構築中にノードを分割するときに、特徴のランダムなサブセットが考慮されます。
これにより、木の間にさらなる多様性が導入され、アンサンブルがより堅牢になります。
04:投票(または平均)メカニズム
分類問題の場合、予測のモード(最も頻度の高いクラス)が使用されます。
回帰問題の場合、予測の平均が考慮されます。
投票プロセスはランダムフォレスト分類にとって重要であり、投票メカニズムとして使用できるさまざまな手法があります。一部はソフト投票と投票しきい値です。
ソフト投票
それぞれの木の予測は、軟投票の信頼スコア(確率)に関連付けられています。最終的な予測は、これらの確率の加重平均になります。
私たちの決定木クラスはまだ確率を予測できないため、この投票メカニズムを使用できません。カスタム投票を使用します。
投票しきい値
投票メカニズムは次のようになります。特定の割合の木が特定のクラスを予測した場合、それが最終的な予測とみなされます。これは、つながりに対処したり、最小限の信頼レベルを確保したりするのに役立ちます。
木の割合を使用してどのクラスを予測するかを決定することは、多くのクラスの予測を複雑にする可能性があります。予測されたクラスの数に関係なく、ほとんどの木が予測したクラスを選択するように予測関数をカスタマイズします。
double CRandomForestClassifier::predict(vector &x) { vector predictions(m_ntrees); //predictions from all the trees for (uint i=0; i<this.m_ntrees; i++) //all trees make the predictions predictions[i] = forest[i].predict(x); vector uniques = matrix_utils.Unique(predictions); return uniques[matrix_utils.Unique_count(predictions).ArgMax()]; //select the majority decision }
決定木クラスの拡張
前回の記事では、バイナリターゲット変数の分類に適した分類決定木について説明しました。回帰決定木のクラスとコードを拡張する必要がありました。
class CDecisionTreeRegressor: public CDecisionTreeClassifier { private: double calculate_leaf_value(vector &Y); split_info get_best_split(matrix &data, uint num_features); double variance_reduction(vector &parent, vector &l_child, vector &r_child); Node *build_tree(matrix &data, uint curr_depth = 0); public: CDecisionTreeRegressor(uint min_samples_split = 2, uint max_depth = 2); ~CDecisionTreeRegressor(void); void fit(matrix &x, vector &y); };
2つのクラスはほとんどの場合類似しており、同じノードクラスと、リーフ値の計算、情報利得、木の構築、および木の構築関数を呼び出すFit関数を除く多くの関数を共有します。
回帰決定木のリーフ値
回帰問題では、特定のノードのリーフ値は、そのすべての値の平均になります。
double CDecisionTreeRegressor::calculate_leaf_value(vector &Y) { return Y.Mean();
情報利得の計算
前の記事で述べたように、情報利得は、データセットが分割された後のエントロピーまたは不確実性の減少を測定します。
確率ベースのジニとエントロピーを使用する代わりに、分散低減公式を使用して、特定のノードの不純物を測定します。
double CDecisionTreeRegressor::variance_reduction(vector &parent, vector &l_child, vector &r_child) { double weight_l = l_child.Size() / (double)parent.Size(), weight_r = r_child.Size() / (double)parent.Size(); return parent.Var() - ((weight_l * l_child.Var()) + (weight_r * r_child.Var())); }
上記の関数は、決定木の特定のノードでデータセットを左右の子ノードに分割することによって達成される分散の減少を計算します。
木の構築とFit
木の構築
Node *CDecisionTreeRegressor::build_tree(matrix &data, uint curr_depth=0) { matrix X; vector Y; if (!matrix_utils.XandYSplitMatrices(data,X,Y)) //Split the input matrix into feature matrix X and target vector Y. { #ifdef DEBUG_MODE printf("%s Line %d Failed to build a tree Data Empty",__FUNCTION__,__LINE__); #endif return NULL; //Return a NULL pointer } ulong samples = X.Rows(), features = X.Cols(); //Get the number of samples and features in the dataset. ArrayResize(nodes, nodes.Size()+1); //Append the nodes to memory Node *left_child, *right_child; if (samples >= m_min_samples_split && curr_depth<=m_max_depth) { split_info best_split = this.get_best_split(data, (uint)features); #ifdef DEBUG_MODE Print(__FUNCTION__," | ",__LINE__,"\nbest_split left: [",best_split.dataset_left.Rows(),"x",best_split.dataset_left.Cols(),"]\nbest_split right: [",best_split.dataset_right.Rows(),"x",best_split.dataset_right.Cols(),"]\nfeature_index: ",best_split.feature_index,"\nInfo gain: ",best_split.info_gain,"\nThreshold: ",best_split.threshold); #endif if (best_split.info_gain > 0) { left_child = this.build_tree(best_split.dataset_left, curr_depth+1); right_child = this.build_tree(best_split.dataset_right, curr_depth+1); nodes[nodes.Size()-1] = new Node(best_split.feature_index,best_split.threshold,left_child,right_child,best_split.info_gain); return nodes[nodes.Size()-1]; } } nodes[nodes.Size()-1] = new Node(); nodes[nodes.Size()-1].leaf_value = this.calculate_leaf_value(Y); return nodes[nodes.Size()-1]; }
Fit関数
void CDecisionTreeRegressor::fit(matrix &x, vector &y) { matrix data = matrix_utils.concatenate(x, y, 1); this.root = this.build_tree(data); is_fitted = true; }
RegressorクラスとClassifierクラスのこのbuild_tree関数の唯一の違いは、variance_reduction関数です。
私は、人気のある翼型ノイズデータを使用して、構築された回帰ツリーをテストしました。
matrix data = matrix_utils.ReadCsv("airfoil_noise_data.csv"); matrix x; vector y; if (!matrix_utils.XandYSplitMatrices(data, x, y)) return INIT_FAILED; regressor_tree = new CDecisionTreeRegressor(3,3); regressor_tree.fit(x, y); regressor_tree.print_tree(regressor_tree.root); vector preds = regressor_tree.predict(x); Print("r-squared: ",metrics.r_squared(y, preds));
出力
KS 0 00:04:11.402 RandomForest Test (EURUSD,H1) : X_0<=3150.0?7.6482714516406745 FI 0 00:04:11.402 RandomForest Test (EURUSD,H1) ---> left: X_4<=0.0150478?4.070223732531591 ME 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> left: X_2<=0.1016?2.453283788183441 RR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=630.0?2.3366165961173238 JR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 126.94465000000002 MF 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 130.51523904382472 II 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_0<=1600.0?4.999630155449349 HF 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 127.90983653846149 JM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 122.97036507936505 JR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> right: X_4<=0.0483159?6.040280153408631 FI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=1250.0?5.315257051142112 IG 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 125.68045918367342 GM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 120.69493181818189 NQ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_0<=1250.0?13.291165881821172 GK 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 117.69977777777775 GH 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 109.80075000000001 EL 0 00:04:11.402 RandomForest Test (EURUSD,H1) ---> right: X_4<=0.00152689?28.997059993530435 OL 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> left: X_0<=6300.0?11.053304033466667 HK 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_4<=0.000930789?9.067095683299033 FG 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 134.9866388888889 NO 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 128.59900000000002 QS 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_4<=0.000930789?9.783359845444707 NI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 128.05125581395347 GJ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 120.90806666666667 RM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> right: X_4<=0.0341183?5.715854852017056 LN 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=5000.0?5.190320913085316 GN 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 120.08625170068028 NE 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 115.52968965517242 MI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_4<=0.0483159?4.450134400476193 IS 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 109.44371428571428 GQ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 104.84033333333332 PH 0 00:04:11.403 RandomForest Test (EURUSD,H1) r-squared: 0.5937442611327515
回帰木には同じパラメータに対してより多くの分岐があるように見えますが、その結果、分類決定木の分岐が少なくなります。
訓練中の回帰モデルの精度は59%でした。これは私たちが正しく理解できたという良い兆候でしょうか。予測をグラフにプロットすると、次のようになります。

予測が実際の値に適合する様子は、まるで木のように見えます。
なぜランダムフォレストなのか?
高い正確性:多くの場合、ランダムフォレストを使用すると、分類タスクと回帰タスクの両方で精度が向上します。
堅牢性:ランダムフォレストのアンサンブルの性質により、過剰適合やノイズの多いデータに対して堅牢になります。
機能の重要性:ランダムフォレストは、機能の重要性に関する情報を提供し、機能の選択に役立ちます。
分散の減少:木の間の多様性によりモデルの分散が最小限に抑えられ、一般化が向上します。
機能のスケーリングは不要:決定木と同様、ランダムフォレストは特徴のスケーリングの影響を受けにくいため、異なるスケールのデータセットに適しています。
多用途性:カテゴリ特徴や数値特徴など、さまざまな種類のデータに実用的です。
ランダムフォレスト分類器の構築
決定木よりもランダムフォレストアルゴリズムを選択する理由を説明したので、分類子から始めてランダムフォレストモデルを構築する方法を見てみましょう。
CDecisionTreeClassifierクラスが含まれます。
class CRandomForestClassifier { CMetrics metrics; protected: uint m_ntrees; uint m_maxdepth; uint m_minsplit; int m_random_state; CMatrixutils matrix_utils; CDecisionTreeClassifier *forest[]; string ConvertTime(double seconds); public: CRandomForestClassifier(uint n_trees=100, uint minsplit=NULL, uint max_depth=NULL, int random_state=-1); ~CRandomForestClassifier(void); void fit(matrix &x, vector &y, bool replace=true); double predict(vector &x); vector predict(matrix &x); };
ランダムフォレスト分類子は、単純にx個の分類子木を1つのフォレストに結合したものであるため、このクラスはForest[]という名前のCDecisionTreeClassifierオブジェクトの配列を指します。
n_trees=100(デフォルト)。これは、ランダムフォレスト分類子フォレストに100本の木が存在することを意味します。
min_splitとmax_Depthは、前の記事で説明したそれぞれの木のパラメータです。min_splitは木に必要な分岐の最小数であり、max_Depthはそれらの分岐に関して木がどのくらいの長さである必要があるかを示します。
ランダムフォレストに木を当てはめる
これはCRandomForestClassifierクラスで最も重要な関数であり、フォレストはクラスコンストラクタで選択されたn_trees本の木で構成されます。
void CRandomForestClassifier::fit(matrix &x, vector &y, bool replace=true) { matrix x_subset; vector y_subset; matrix data = this.matrix_utils.concatenate(x, y, 1); matrix temp_data = data; vector preds; datetime time_start = GetTickCount(), current_time; Print("[ Classifier Random Forest Building ]"); for (uint i=0; i<m_ntrees; i++) //Build a given x number of trees { time_start = GetTickCount(); temp_data = data; matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets if (!this.matrix_utils.XandYSplitMatrices(temp_data, x_subset, y_subset)) //split the random subset into x and y subsets { ArrayRemove(forest,i,1); //Delete the invalid tree in a forest printf("%s %d Failed to split data for a tree ",__FUNCTION__,__LINE__); continue; } forest[i] = new CDecisionTreeClassifier(this.m_minsplit, this.m_maxdepth); //Add the tree to the forest forest[i].fit(x_subset, y_subset); //Add the trained tree to the forest preds = forest[i].predict(x_subset); current_time = GetTickCount(); printf(" ==> Tree <%d> Rand Seed <%s> Accuracy Score: %.3f Time taken: %s",i+1,m_random_state==-1?"None":string(m_random_state),metrics.accuracy_score(y_subset, preds), ConvertTime((current_time - time_start) / 1000.0)); } m_ntrees = ArraySize(forest); //The successfully build trees }
決定木分類器とランダムフォレスト分類子
ランダム分類器が分類タスクにおいて決定木よりも優れた仕事をするかどうかを証明するために、5つのテストを実行しました。
テスト01:
| 訓練 | テスト | |
|---|---|---|
| 決定木 | 73.8% | 40% |
| ランダムフォレスト | 78% | 45% |
テスト02:
| 決定木 | 73.8% | 40% |
| ランダムフォレスト | 83% | 45% |
テスト03:
| 決定木 | 73.8% | 40% |
| ランダムフォレスト | 80% | 45% |
テスト04:
| 決定木 | 73.8% | 40% |
| ランダムフォレスト | 78.8% | 45% |
テスト05
| 決定木 | 73.8% | 40% |
| ランダムフォレスト | 78.8% | 45% |
私の経験では、取引データにランダムフォレスト分類子を使用すると、ランダムフォレストの全体的な精度が単一の決定木の精度よりも大きくない状況に遭遇する可能性があるため、混乱が生じる可能性があります。これは、以下の1つ以上の要因によって発生します。
ランダムフォレストが単一の決定木よりも高い精度を提供しない要因
木の多様性の欠如
ランダムフォレストは、個々の木の多様性から恩恵を受けます。すべての木が類似している場合、アンサンブルはあまり改善されません。
各木の訓練中にランダム性を適切に導入していることを確認してください。ランダム化には、特徴のランダムなサブセットを選択したり、訓練データの異なるサブセットを使用したりすることが含まれます。
ハイパーパラメータの調整
各分割で考慮する特徴の数(m_max_features)、内部ノードの分割に必要な最小サンプル数(m_minsplit)、ツリーの最大深さ(m_maxDepth)など、さまざまなハイパーパラメータを試してください。
ハイパーパラメータ値の範囲にわたるグリッド検索またはランダム検索は、より適切な構成を特定するのに役立ちます。
相互検証
相互検証を使用してモデルのパフォーマンスを評価します。これは、モデルが新しいデータにどの程度一般化されるかについて、より確実な推定を得るのに役立ちます。
相互検証は、過適合または過小適合の問題の検出にも役立ちます。
データセット全体の訓練
木が訓練データに過剰適合していないことを確認します。フォレスト内の各木がデータセット全体で訓練される場合、シグナルではなくノイズがキャプチャされる可能性があります。
データのブートストラップされたサンプル(バギング)でそれぞれの木を訓練することを検討してください。
特徴のスケーリング
特徴のスケールが異なる場合は、それらをスケールすると有益な場合があります。一般に、決定木は特徴スケールの影響を受けませんが、特に単一ツリーのパフォーマンスをアンサンブルと比較する場合には、特徴の正規化または標準化が役立つ可能性があります。
評価指標
モデルを使用して解決しようとしている問題に対して、適切な評価指標を使用していることを確認してください。回帰の一般的な評価指標は決定係数であり、分類の一般的な評価指標は精度スコアです。
fit()関数の最後の引数にはerror引数があり、フォレスト内のそれぞれの木の精度を測定するための適切なメトリックを選択できます。
enum errors_classifier { ERR_ACCURACY }; enum errors_regressor { ERR_R2_SCORE, ERR_ADJUSTED_R };
アンサンブルのサイズ
フォレストの中の木の数を試してみましょう。場合によっては、木の数を増やすとアンサンブルのパフォーマンスが向上することがあります。
これにより複雑さが増すことに注意してください。変更後は訓練とテストの時間が大幅に増加する可能性があります。
データ品質
データの品質を確保します。外れ値や欠損値がある場合、ランダムフォレストのパフォーマンスに影響を与える可能性があります。
ランダムシード
再現性を高めるために、各実行中にランダムシードが一貫して設定されていることを確認します。
同じランダムシードを持つと、すべてのツリーが同じ精度を生成しますが、これは単一の決定木と同等になります。
バトルはストラテジーテスターで続く
ランダムフォレストは訓練とテストの段階では勝利を収めていますが、利益を上げるためには予測能力以上のものが必要となる取引でも勝利を収めることができるのでしょうか。
2022.01.01から2023.02.01まで、デフォルト設定で両方のアルゴリズムのテストを実行しました。
その他のテスター設定
- Delays:ランダムな遅延
- Modelling:始値のみ
- Deposit:1000ドル
- Leverage:1/100
ランダムフォレストの結果グラフ
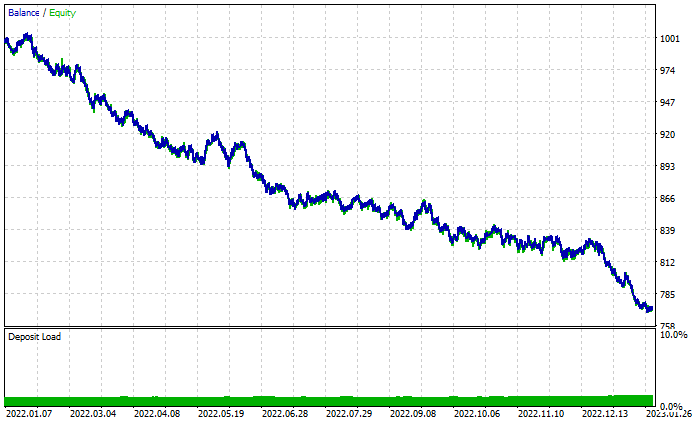
取引合計で46%の利益が得られているにもかかわらず、グラフはひどいものに見えます。決定木が何をおこなうかを見てみましょう。

44%の収益性のある取引にもかかわらず、100本の木で構成されるランダムフォレストよりも優れています。
両方のモデルで最適なストップロス=960およびテイクプロフィット=1295レベルを見つけるために簡単な最適化がおこなわれ、最小分割は2に設定されました。以下は両方のモデルの結果です。
決定木分類子
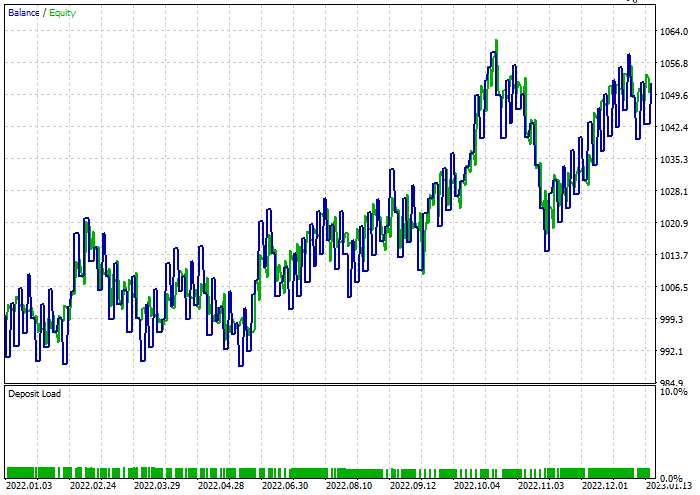
テスト中、取引の47.68%で利益が得られました。このモデルはテスト中に52ドルの利益を上げました。
ランダムフォレスト分類子

最後に
ランダムフォレストは、金融、エンターテイメント、医療分野など、多くの業界のさまざまな活動に使用されています。ただし、他のモデルと同様に、取引プロジェクトにこのモデルを選択する前に理解する必要があるいくつかの欠点があります。
計算の複雑さ
特に多数の木を含む場合、ランダムフォレストモデルは計算コストが高くつき、大量のリソースを必要とする可能性があります。
メモリ使用量
木の数が増えると、ランダムフォレストモデルのメモリ使用量も増加し、メモリ使用量が高くなる可能性があります。
解釈可能性
ランダムフォレストのアンサンブルの性質により、主にフォレストが多数の木で構成されている場合、個々の決定木よりも解釈しにくくなります。
過剰適合
ランダムフォレストは個々の決定木よりも過適合する傾向がありませんが、それでもノイズの多いデータや外れ値を含むデータを過適合する可能性があります。
支配的なクラスへの偏り
クラス分布の不均衡を伴う分類問題では、ランダムフォレストが支配的なクラスに偏り、少数クラスに対するモデルの予測パフォーマンスに影響を与える可能性があります。
パラメータの感度
ランダムフォレストはハイパーパラメータの選択に対して堅牢ですが、モデルのパフォーマンスは依然として特定のパラメータ値の影響を受ける可能性があります。
ブラックボックスの性質
複数の決定木を組み合わせるランダムフォレストのアンサンブルの性質により、モデルの意思決定プロセスの解釈が困難になる場合があります。
訓練の時間
ランダムフォレストモデルの訓練は、特に大規模なデータセットの場合、単一の決定木を訓練するよりも時間がかかることがあります。
100本の木を訓練するために待機する必要があったため、取引アクティビティは10分間遅れました。
ご精読ありがとうございました。
この連載での機械学習モデルのトラック開発についての詳細は、このGitHubリポジトリで説明します。
添付ファイル:
| ファイル | 使用法と説明 |
|---|---|
| Forest.mqh(インクルードフォルダ内) | ランダムフォレストクラ(CRandomForestClassifierとCRandomForestRegressorの両方)が含まれる |
| math_utils.mqh(インクルード) | 行列操作のための追加関数が含まれる |
| metrics.mqh(インクルード) | MLモデルのパフォーマンスを測定するための関数とコード |
| preprocessing.mqh(インクルード) | 生の入力データを前処理して機械学習モデルの使用に適したものにするためのライブラリ。 |
| tree.mqh(インクルード) | 決定木クラス |
| RandomForestTest.mq5 (EA) | ランダムフォレストモデルを実行およびテストするための最後のEA |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/13765
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 MQL5を使ったシンプルな多通貨エキスパートアドバイザーの作り方(第5回): ケルトナーチャネルのボリンジャーバンド—指標シグナル
MQL5を使ったシンプルな多通貨エキスパートアドバイザーの作り方(第5回): ケルトナーチャネルのボリンジャーバンド—指標シグナル
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
非常に有益で興味深い