
Datenwissenschaft und maschinelles Lernen (Teil 17): Geld von Bäumen? Die Kunst und Wissenschaft der Random Forests im Devisenhandel

Zwei Köpfe sind besser als einer, nicht weil einer von ihnen unfehlbar ist, sondern weil es unwahrscheinlich ist, dass sie sich in dieselbe Richtung irren.
Der Random Forest Algorithmus
Ein Random Forest (Zufallswald) ist eine Ensemble-Lernmethode, bei der während des Trainings viele Entscheidungsbäume gebildet werden und die Klasse, d. h. der Modus der Klassen (Klassifizierung) oder die mittlere Vorhersage (Regression) der einzelnen Bäume ausgegeben wird. Jeder Baum in einem Random Forest wird auf einer anderen Teilmenge der Daten trainiert, und die während des Trainings eingeführte Zufälligkeit trägt zur Verbesserung der Gesamtleistung und Generalisierung des Modells bei.
Um dies besser zu verstehen, müssen wir das Ensemble-Lernen im Fachjargon des maschinellen Lernens betrachten.
Ensemble-Lernen
Beim Ensemble-Lernen werden zwei oder mehr maschinelle Lernmodelle an dieselben Daten angepasst und die Vorhersagen der einzelnen Modelle kombiniert. Das Ensemble-Lernen zielt darauf ab, mit Ensemble-Modellen bessere Ergebnisse zu erzielen als mit einem einzelnen Modell.
Random Forest ist eine Ensemble-Methode, die die Vorhersagen mehrerer Entscheidungsbäume kombiniert, um die Gesamtvorhersagefähigkeit eines einzelnen Modells zu verbessern.

Zur Veranschaulichung habe ich einen Entscheidungsbaum und einen Zufallswald mit zehn (10) Bäumen erstellt. Bei Verwendung desselben Datensatzes erzielte ich mit der Random-Forest-KI eine bessere Genauigkeit in der Trainings- und Testphase.
Hauptmerkmale der Random Forest AI
01: Ensemble-Lernen
Random Forest ist eine Ensemble-Methode, die die Vorhersagen mehrerer Machine-Learning-Modelle kombiniert, um die Gesamtleistung zu verbessern.
for (uint i=0; i<m_ntrees; i++) //Build a given x number of trees { temp_data = data; matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets forest[i] = new CDecisionTreeClassifier(this.m_minsplit, this.m_maxdepth); //Add the tree to the forest forest[i].fit(x_subset, y_subset); //Add the trained tree to the forest preds = forest[i].predict(x_subset); }
02: Bootstrapping Aggregieren (Bagging)
Im Bereich des maschinellen Lernens ist Bootstrapping eine Wiederholungsstichprobentechnik, bei der wiederholt Stichproben aus den Quelldaten mit Ersetzung gezogen werden, oft um einen Populationsparameter zu schätzen.
Jeder Baum im Random Forest wird auf einer anderen Teilmenge der Daten trainiert, die durch Bootstrapping (Stichproben mit Ersatz) erstellt wird.
matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets
Quelle:
template<typename T> void CMatrixutils::Randomize(matrix<T> &matrix_,int random_state=-1, bool replace=false)
Der Parameter replace = true ermöglicht es, denselben Index mehrmals zu wählen und so den Bootstrapping-Prozess zu simulieren.
03: Merkmal Zufälligkeit:
Zufällige Teilmengen von Merkmalen werden bei der Aufteilung von Knoten während der Konstruktion jedes Baums berücksichtigt.
Dies führt zu einer weiteren Vielfalt unter den Bäumen und macht das Ensemble robuster.
04: Mechanismus der Abstimmung (oder Mittelwertbildung)
Bei Klassifizierungsproblemen wird der Modus (die häufigste Klasse) der Vorhersagen genommen.
Bei Regressionsproblemen wird der Durchschnitt der Vorhersagen berücksichtigt.
Der Abstimmungsprozess ist entscheidend für die Klassifizierung Random-Forest, und es gibt verschiedene Techniken, die man als Abstimmungsmechanismus verwenden kann; einige sind Soft Voting und Voting Threshold:
Soft Voting
Die Vorhersage jedes Baums wird mit einem Vertrauenswert (Wahrscheinlichkeit) im Soft Voting verknüpft. Die endgültige Vorhersage ist dann ein gewichteter Durchschnitt dieser Wahrscheinlichkeiten.
Da unsere Entscheidungsbaumklasse die Wahrscheinlichkeiten noch nicht vorhersagen kann, können wir diesen Abstimmungsmechanismus nicht verwenden. Wir werden eine nutzerdefinierte Abstimmung durchführen.
Schwellenwert für die Abstimmung
Der Abstimmungsmechanismus funktioniert folgendermaßen: Wenn ein bestimmter Prozentsatz der Bäume eine bestimmte Klasse vorhersagt, wird diese als endgültige Vorhersage betrachtet. Dies kann dazu beitragen, Bindungen zu lösen oder ein Mindestmaß an Vertrauen zu gewährleisten.
Die Verwendung des Prozentsatzes der Bäume zur Bestimmung der vorherzusagenden Klasse kann bei vielen vorherzusagenden Klassen anspruchsvoll sein; wir werden die Vorhersagefunktion so anpassen, dass die Klasse ausgewählt wird, die von den meisten Bäumen vorhergesagt wurde, unabhängig davon, wie viele Klassen vorhergesagt wurden.
double CRandomForestClassifier::predict(vector &x) { vector predictions(m_ntrees); //predictions from all the trees for (uint i=0; i<this.m_ntrees; i++) //all trees make the predictions predictions[i] = forest[i].predict(x); vector uniques = matrix_utils.Unique(predictions); return uniques[matrix_utils.Unique_count(predictions).ArgMax()]; //select the majority decision }
Erweitern der Entscheidungsbaumklasse
Im vorangegangenen Artikel haben wir den Klassifizierungs-Entscheidungsbaum besprochen, der für die Klassifizierung binärer Zielvariablen geeignet ist; ich musste die Klassen und den Code für einen Regressions-Entscheidungsbaum erweitern.
class CDecisionTreeRegressor: public CDecisionTreeClassifier { private: double calculate_leaf_value(vector &Y); split_info get_best_split(matrix &data, uint num_features); double variance_reduction(vector &parent, vector &l_child, vector &r_child); Node *build_tree(matrix &data, uint curr_depth = 0); public: CDecisionTreeRegressor(uint min_samples_split = 2, uint max_depth = 2); ~CDecisionTreeRegressor(void); void fit(matrix &x, vector &y); };
Die beiden Klassen ähneln sich in den meisten Fällen, und sie haben dieselbe Knotenklasse und viele Funktionen gemeinsam, mit Ausnahme der Berechnung der Blattwerte, des Informationsgewinns, der Baumbildung und der Anpassungsfunktion, die die Baumbildungsfunktion aufruft.
Blattwert in Regressor-Entscheidungsbäumen
Bei Regressionsproblemen ist der Blattwert eines bestimmten Knotens der Mittelwert aller seiner Werte.
double CDecisionTreeRegressor::calculate_leaf_value(vector &Y) { return Y.Mean();
Berechnung des Informationsgewinns
Wie bereits im vorangegangenen Artikel erwähnt, misst der Informationsgewinn die Verringerung der Entropie oder Unsicherheit nach der Aufteilung eines Datensatzes.
Anstelle von Gini und Entropie, die auf Wahrscheinlichkeiten basieren, verwenden wir die Varianzreduktionsformel, um die Unreinheit in einem bestimmten Knoten zu messen.
double CDecisionTreeRegressor::variance_reduction(vector &parent, vector &l_child, vector &r_child) { double weight_l = l_child.Size() / (double)parent.Size(), weight_r = r_child.Size() / (double)parent.Size(); return parent.Var() - ((weight_l * l_child.Var()) + (weight_r * r_child.Var())); }
Die obige Funktion berechnet die Verringerung der Varianz, die durch die Aufteilung eines Datensatzes in linke und rechte Kindknoten an einem bestimmten Knoten im Entscheidungsbaum erreicht wird.
Baum aufbauen & Funktion anpassen
Baum erstellen
Node *CDecisionTreeRegressor::build_tree(matrix &data, uint curr_depth=0) { matrix X; vector Y; if (!matrix_utils.XandYSplitMatrices(data,X,Y)) //Split the input matrix into feature matrix X and target vector Y. { #ifdef DEBUG_MODE printf("%s Line %d Failed to build a tree Data Empty",__FUNCTION__,__LINE__); #endif return NULL; //Return a NULL pointer } ulong samples = X.Rows(), features = X.Cols(); //Get the number of samples and features in the dataset. ArrayResize(nodes, nodes.Size()+1); //Append the nodes to memory Node *left_child, *right_child; if (samples >= m_min_samples_split && curr_depth<=m_max_depth) { split_info best_split = this.get_best_split(data, (uint)features); #ifdef DEBUG_MODE Print(__FUNCTION__," | ",__LINE__,"\nbest_split left: [",best_split.dataset_left.Rows(),"x",best_split.dataset_left.Cols(),"]\nbest_split right: [",best_split.dataset_right.Rows(),"x",best_split.dataset_right.Cols(),"]\nfeature_index: ",best_split.feature_index,"\nInfo gain: ",best_split.info_gain,"\nThreshold: ",best_split.threshold); #endif if (best_split.info_gain > 0) { left_child = this.build_tree(best_split.dataset_left, curr_depth+1); right_child = this.build_tree(best_split.dataset_right, curr_depth+1); nodes[nodes.Size()-1] = new Node(best_split.feature_index,best_split.threshold,left_child,right_child,best_split.info_gain); return nodes[nodes.Size()-1]; } } nodes[nodes.Size()-1] = new Node(); nodes[nodes.Size()-1].leaf_value = this.calculate_leaf_value(Y); return nodes[nodes.Size()-1]; }
Funktion anpassen
void CDecisionTreeRegressor::fit(matrix &x, vector &y) { matrix data = matrix_utils.concatenate(x, y, 1); this.root = this.build_tree(data); is_fitted = true; }
Der einzige Unterschied zwischen dieser Funktion build_tree für die Klasse Regressor und der für die Klasse Classifier ist die Funktion variance_reduction.
Ich habe die beliebten verrauschten Daten verwendet, um den erstellten Regressionsbaum zu testen.
matrix data = matrix_utils.ReadCsv("airfoil_noise_data.csv"); matrix x; vector y; if (!matrix_utils.XandYSplitMatrices(data, x, y)) return INIT_FAILED; regressor_tree = new CDecisionTreeRegressor(3,3); regressor_tree.fit(x, y); regressor_tree.print_tree(regressor_tree.root); vector preds = regressor_tree.predict(x); Print("r-squared: ",metrics.r_squared(y, preds));
Ausdruck:
KS 0 00:04:11.402 RandomForest Test (EURUSD,H1) : X_0<=3150.0?7.6482714516406745 FI 0 00:04:11.402 RandomForest Test (EURUSD,H1) ---> left: X_4<=0.0150478?4.070223732531591 ME 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> left: X_2<=0.1016?2.453283788183441 RR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=630.0?2.3366165961173238 JR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 126.94465000000002 MF 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 130.51523904382472 II 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_0<=1600.0?4.999630155449349 HF 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 127.90983653846149 JM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 122.97036507936505 JR 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> right: X_4<=0.0483159?6.040280153408631 FI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=1250.0?5.315257051142112 IG 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 125.68045918367342 GM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 120.69493181818189 NQ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_0<=1250.0?13.291165881821172 GK 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 117.69977777777775 GH 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 109.80075000000001 EL 0 00:04:11.402 RandomForest Test (EURUSD,H1) ---> right: X_4<=0.00152689?28.997059993530435 OL 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> left: X_0<=6300.0?11.053304033466667 HK 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_4<=0.000930789?9.067095683299033 FG 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 134.9866388888889 NO 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 128.59900000000002 QS 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_4<=0.000930789?9.783359845444707 NI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 128.05125581395347 GJ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 120.90806666666667 RM 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->---> right: X_4<=0.0341183?5.715854852017056 LN 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> left: X_0<=5000.0?5.190320913085316 GN 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 120.08625170068028 NE 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 115.52968965517242 MI 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->---> right: X_4<=0.0483159?4.450134400476193 IS 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> left: 109.44371428571428 GQ 0 00:04:11.402 RandomForest Test (EURUSD,H1) --->--->--->---> right: 104.84033333333332 PH 0 00:04:11.403 RandomForest Test (EURUSD,H1) r-squared: 0.5937442611327515
Der Regressionsbaum scheint bei gleichen Parametern mehr Verzweigungen zu haben, was zu weniger Verzweigungen im Klassifikationsentscheidungsbaum führt.
Die Genauigkeit unseres Regressionsmodells lag beim Training bei 59 %, was ein guter Hinweis darauf ist, dass wir es richtig gemacht haben? Wenn die Vorhersagen in ein Diagramm eingetragen wurden, sahen sie etwa so aus wie unten:

So wie die Vorhersagen an die tatsächlichen Werte angepasst sind, sehen sie fast wie ein Baum aus.
Warum Random Forest?
Hohe Genauigkeit: Random Forests bieten oft eine höhere Genauigkeit sowohl bei Klassifizierungs- als auch bei Regressionsaufgaben.
Robustheit: Der Ensemble-Charakter von Random Forest macht ihn robust gegenüber Überanpassungen und verrauschten Daten.
Merkmal Wichtigkeit: Random Forests können Informationen über die Wichtigkeit von Merkmalen liefern und so bei der Merkmalsauswahl helfen.
Reduzierte Varianz: Durch die Vielfalt der Bäume wird die Varianz des Modells minimiert, was zu einer besseren Verallgemeinerung führt.
Keine Notwendigkeit für eine Eigenschafts-Skalierung: Wie der Entscheidungsbaum reagieren auch Random Forests weniger empfindlich auf die Skalierung von Merkmalen, sodass sie sich für Datensätze mit unterschiedlichen Skalen eignen.
Vielseitigkeit: Praktisch für verschiedene Arten von Daten, einschließlich kategorischer und numerischer Merkmale.
Aufbau des Random Forest Classifier
Nachdem wir nun gesehen haben, warum man den Random-Forest-Algorithmus dem Entscheidungsbaum vorziehen sollte, sehen wir uns an, wie man das Random-Forest-Modell aufbaut, beginnend mit dem Klassifikator.
Einbinden der Klasse CDecisionTreeClassifier.
class CRandomForestClassifier { CMetrics metrics; protected: uint m_ntrees; uint m_maxdepth; uint m_minsplit; int m_random_state; CMatrixutils matrix_utils; CDecisionTreeClassifier *forest[]; string ConvertTime(double seconds); public: CRandomForestClassifier(uint n_trees=100, uint minsplit=NULL, uint max_depth=NULL, int random_state=-1); ~CRandomForestClassifier(void); void fit(matrix &x, vector &y, bool replace=true); double predict(vector &x); vector predict(matrix &x); };
Da der Random-Forest-Klassifikator einfach eine x-fache Anzahl von Klassifikatorbäumen ist, die in einem „Forest“ kombiniert werden, wird die Klasse in ein Array von CDecisionTreeClassifier benannten Objekten forest[] gezeigt.
n_trees = 100 (standardmäßig), was bedeutet, dass 100 Bäume im Random-Forest-Klassifikator vorhanden sind.
min_split und max_depth sind die Parameter für jeden Baum, die wir im vorherigen Artikel besprochen haben. min_split ist die Mindestanzahl von Zweigen, die der Baum haben sollte, während max_depth angibt, wie lang der Baum in Bezug auf diese Zweige sein sollte.
Bäume in einen Random Forest anpassen
Dies ist die wichtigste Funktion in der Klasse CRandomForestClassifier, wobei der Wald aus n_trees, der Anzahl der im Klassenkonstruktor gewählten Bäume, besteht.
void CRandomForestClassifier::fit(matrix &x, vector &y, bool replace=true) { matrix x_subset; vector y_subset; matrix data = this.matrix_utils.concatenate(x, y, 1); matrix temp_data = data; vector preds; datetime time_start = GetTickCount(), current_time; Print("[ Classifier Random Forest Building ]"); for (uint i=0; i<m_ntrees; i++) //Build a given x number of trees { time_start = GetTickCount(); temp_data = data; matrix_utils.Randomize(temp_data, m_random_state, replace); //Get randomized subsets if (!this.matrix_utils.XandYSplitMatrices(temp_data, x_subset, y_subset)) //split the random subset into x and y subsets { ArrayRemove(forest,i,1); //Delete the invalid tree in a forest printf("%s %d Failed to split data for a tree ",__FUNCTION__,__LINE__); continue; } forest[i] = new CDecisionTreeClassifier(this.m_minsplit, this.m_maxdepth); //Add the tree to the forest forest[i].fit(x_subset, y_subset); //Add the trained tree to the forest preds = forest[i].predict(x_subset); current_time = GetTickCount(); printf(" ==> Tree <%d> Rand Seed <%s> Accuracy Score: %.3f Time taken: %s",i+1,m_random_state==-1?"None":string(m_random_state),metrics.accuracy_score(y_subset, preds), ConvertTime((current_time - time_start) / 1000.0)); } m_ntrees = ArraySize(forest); //The successfully build trees }
Entscheidungsbaum-Klassifikator vs. Random Forest Klassifikator
Um zu prüfen, ob zufällige Klassifizierer bei Klassifizierungsaufgaben besser abschneiden als Entscheidungsbäume, habe ich 5 Tests durchgeführt.
Test 01:
| Zug | Test | |
|---|---|---|
| Entscheidungsbaum | 73.8% | 40% |
| Random Forest | 78% | 45% |
Test 02:
| Entscheidungsbaum | 73.8% | 40% |
| Random Forest | 83% | 45% |
Test 03:
| Entscheidungsbaum | 73.8% | 40% |
| Random Forest | 80% | 45% |
Test 04:
| Entscheidungsbaum | 73.8% | 40% |
| Random Forest | 78.8% | 45% |
Test 05:
| Entscheidungsbaum | 73.8% | 40% |
| Random Forest | 78.8% | 45% |
Meiner Erfahrung nach kann die Verwendung des Random-Forest-Klassifikators für Handelsdaten zu Verwirrung führen, da die Gesamtgenauigkeit des Random-Forest-Klassifikators nicht höher ist als die eines einzelnen Entscheidungsbaums; dies ist auf einen oder mehrere der folgenden Faktoren zurückzuführen:
Faktoren, die dazu beitragen, dass der Random Forest keine bessere Genauigkeit liefert als ein einzelner Entscheidungsbaum:
Mangelnde Vielfalt bei Bäumen
Random Forests profitieren von der Vielfalt der einzelnen Bäume. Wenn alle Bäume ähnlich sind, wird das Ensemble keine große Verbesserung bringen.
Vergewissern Sie sich, dass Sie die Zufälligkeit beim Training jedes Baums richtig einführen. Die Randomisierung kann die Auswahl zufälliger Teilmengen von Merkmalen und/oder die Verwendung verschiedener Teilmengen der Trainingsdaten beinhalten.
Anpassen der Hyperparameter
Experimentieren Sie mit verschiedenen Hyperparametern, z. B. mit der Anzahl der Merkmale, die für jeden Split berücksichtigt werden sollen (m_max_features), mit den Mindeststichproben, die für den Split eines internen Knotens erforderlich sind (m_minsplit), und mit der maximalen Tiefe der Bäume (m_maxdepth).
Die Rastersuche oder die zufällige Suche über einen Bereich von Hyperparameterwerten kann helfen, bessere Konfigurationen zu ermitteln.
Kreuzvalidierung
Verwenden Sie die Kreuzvalidierung, um die Leistung des Modells zu bewerten. Auf diese Weise lässt sich besser abschätzen, wie gut sich das Modell auf neue Daten verallgemeinern lässt.
Die Kreuzvalidierung kann auch dabei helfen, Probleme mit der Über- oder Unteranpassung zu erkennen.
Training mit dem gesamten Datensatz
Vergewissern Sie sich, dass die Bäume nicht zu stark an die Trainingsdaten angepasst sind. Wenn jeder Baum im Wald mit dem gesamten Datensatz trainiert wird, könnte er eher Rauschen als Signal erfassen.
Sie können jeden Baum auf einer Bootstrap-Stichprobe (Bagging) der Daten trainieren.
Merkmal Skalierung
Wenn Ihre Merkmale unterschiedliche Maßstäbe haben, kann es von Vorteil sein, sie zu skalieren. Entscheidungsbäume sind im Allgemeinen unempfindlich gegenüber der Skalierung von Merkmalen, aber eine Normalisierung oder Standardisierung von Merkmalen kann hilfreich sein, insbesondere wenn Sie die Leistung eines einzelnen Baums mit der eines Ensembles vergleichen.
Bewertungsmaßstab
Vergewissern Sie sich, dass Sie eine geeignete Bewertungsmetrik für das Problem verwenden, das Sie mit Ihren Modellen zu lösen versuchen; die übliche Bewertungsmetrik für Regression ist das R-Quadrat, während die übliche Bewertungsmetrik für Klassifizierung die Genauigkeitsbewertung ist.
Das letzte Argument einer der Funktion fit() hat ein Fehlerargument, mit dem Sie eine geeignete Metrik für die Messung der Genauigkeit jedes Baums im Wald wählen können.
enum errors_classifier { ERR_ACCURACY }; enum errors_regressor { ERR_R2_SCORE, ERR_ADJUSTED_R };
Größe des Ensembles
Experimentieren Sie mit der Anzahl der Bäume im Wald. Manchmal kann eine Erhöhung der Anzahl der Bäume die Leistung des Ensembles verbessern.
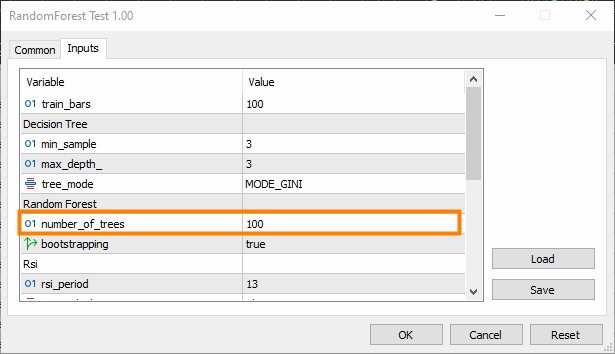
Beachten Sie, dass dies die Komplexität erhöht; die Trainings- und Testzeit könnte sich nach der Änderung drastisch erhöhen.
Qualität der Daten
Sichern Sie die Qualität Ihrer Daten. Wenn es Ausreißer oder fehlende Werte gibt, kann dies die Leistung des Random Forest beeinträchtigen.
Random Seed
Stellen Sie sicher, dass der Zufallswert bei jedem Lauf gleich bleibt, um die Reproduzierbarkeit zu gewährleisten.
Mit demselben Zufallsanfangswert von Random Seed werden alle Bäume die gleiche Genauigkeit erzielen, was nicht besser ist als ein einziger Entscheidungsbaum.
Der Kampf geht weiter im Strategietester
Der Zufallsforst hat sich in der Trainings- und Testphase durchgesetzt, aber kann er auch im Handel siegreich sein, wo mehr als nur die Fähigkeit zur Vorhersage erforderlich ist, um profitabel zu werden?
Ich habe Tests mit beiden Algorithmen mit den Standardeinstellungen von 2022.01.01 bis 2023.02.01 durchgeführt.
Andere Einstellungen des Testers:
- Verzögerung: Zufällige Verzögerung
- Modellierung: Nur Öffnungspreise
- Einzahlung: 1000$
- Hebel: 1/100
Random Forest Ergebnisdiagramm:
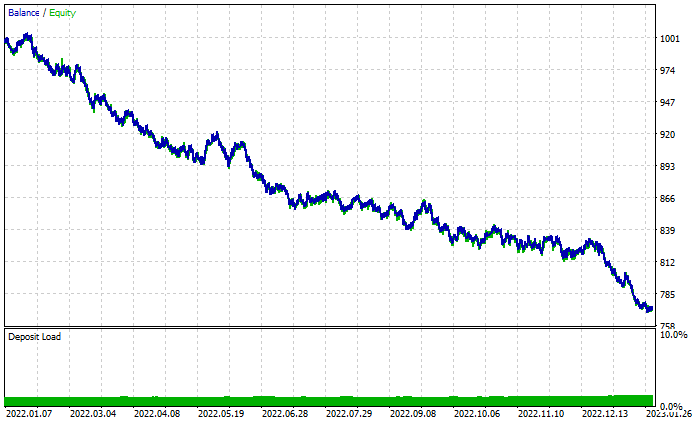
Trotz der insgesamt 46 % profitablen Geschäfte sieht das Diagramm schrecklich aus. Schauen wir uns an, was der Entscheidungsbaum macht:

Besser als der aus 100 Bäumen bestehende Zufallswald, obwohl er nur 44 % profitable Geschäfte aufweist.
Eine schnelle Optimierung wurde durchgeführt, um die besten Stop-Loss = 960 und Take-Profits = 1295 für beide Modelle zu finden, während der minimale Split auf 2 gesetzt wurde. Nachfolgend finden Sie die Ergebnisse beider Modelle.
Der Entscheidungsbaum-Klassifikator:
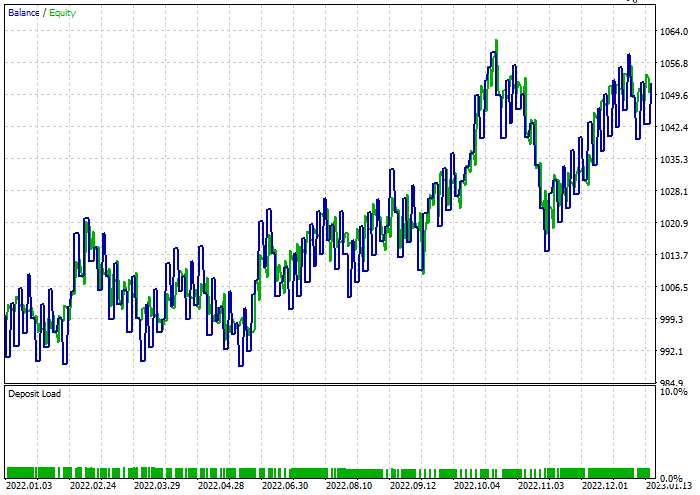
47,68 % der Geschäfte waren während des Tests profitabel. Das Modell machte während des Tests 52$ Gewinn.
Der Klassifikator von Random Forest:

Abschließende Überlegungen
Random Forest wurde in vielen Branchen eingesetzt, z. B. im Finanzwesen, in der Unterhaltungsbranche und im medizinischen Bereich. Doch wie jedes Modell hat auch dieses einige Nachteile, die man verstehen muss, bevor man sich für dieses Modell für sein Handelsprojekt entscheidet.
Computerkomplexität:
Random-Forest-Modelle, insbesondere mit vielen Bäumen, können sehr rechenintensiv sein und erfordern erhebliche Ressourcen.
Speicherverbrauch:
Mit zunehmender Anzahl von Bäumen wächst auch der Speicherbedarf des Random Forest-Modells, was zu einer hohen Speichernutzung führen kann.
Interpretierbarkeit:
Der Ensemble-Charakter von Zufallswäldern macht sie weniger interpretierbar als einzelne Entscheidungsbäume, vor allem wenn der Wald aus vielen Bäumen besteht.
Überanpassung:
Obwohl Random Forests weniger anfällig für Überanpassung sind als einzelne Entscheidungsbäume, können sie dennoch verrauschte Daten oder Daten mit Ausreißern überanpassen.
Bias gegenüber den dominanten Klassen:
Bei Klassifizierungsproblemen mit unausgeglichener Klassenverteilung können Random Forests gegenüber der dominanten Klasse voreingenommen sein, was die Vorhersageleistung des Modells bei Minderheitsklassen beeinträchtigt.
Empfindlichkeit der Parameter:
Random Forests sind zwar robust gegenüber der Wahl von Hyperparametern, aber die Leistung des Modells kann dennoch empfindlich auf bestimmte Parameterwerte reagieren.
Black-Box Natur:
Der Ensemble-Charakter von Random Forests, der mehrere Entscheidungsbäume kombiniert, kann die Interpretation des Entscheidungsprozesses des Modells schwierig machen.
Trainingszeit:
Das Training eines Random-Forest-Modells kann länger dauern als das Training eines einzelnen Entscheidungsbaums, insbesondere bei großen Datensätzen.
Die Handelsaktivität verzögerte sich um 10 Minuten, da sie darauf warten mussten, 100 Bäume zu trainieren.
Vielen Dank für die Lektüre;
Wir diskutieren die Entwicklung dieses maschinellen Lernmodells und vieles mehr in dieser Artikelserie in diesem GitHub Repo.
Anhänge:
| Datei | Verwendung & Beschreibung |
|---|---|
| forest.mqh (zu finden im Ordner include) | Enthält die Random-Forest-Klassen, sowohl CRandomForestClassifier als auch CRandomForestRegressor |
| matrix_utils.mqh (Include) | Enthält zusätzliche Funktionen für Matrixmanipulationen. |
| metrics.mqh (Include) | Enthält Funktionen und Code zur Messung der Leistung von ML-Modellen. |
| preprocessing.mqh (Include) | Die Bibliothek für die Vorverarbeitung von rohen Eingabedaten, um sie für die Verwendung von Modellen des maschinellen Lernens geeignet zu machen. |
| tree.mqh (Include) | Enthält die Entscheidungsbaumklassen. |
| RandomForest Test.mq5 (Experte) | Der endgültige Expert Advisor zum Ausführen und Testen von Random-Forest-Modellen. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/13765
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Verständnis von Programmierparadigmen (Teil 1): Ein verfahrenstechnischer Ansatz für die Entwicklung eines Price Action Expert Advisors
Verständnis von Programmierparadigmen (Teil 1): Ein verfahrenstechnischer Ansatz für die Entwicklung eines Price Action Expert Advisors
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Sehr informativ und interessant