
知っておくべきMQL5ウィザードのテクニック(第58回):移動平均と確率的オシレーターパターンを用いた強化学習(DDPG)
はじめに
前回の記事では、2つのインジケーター(移動平均とストキャスティクス)から抽出した10個のシグナルパターンをテストしました。 そのうち7つは1年分のテスト期間でフォワードウォークに成功しましたが、ロング・ショート両方のポジションを取れたのはその中の2つだけでした。これはテスト期間が短かったことが原因だと考えられるため、実運用を検討する前に、より長い過去データで再テストすることをおすすめします。
今回のテーマは、機械学習の3つの主要なモードを「フェーズ」ごとに使い分けるという仮説に基づいています。その3つとは、教師あり学習(SL, Supervised Learning)、強化学習(RL, Reinforcement Learning)、推論学習(IL, Inference Learning)です。前回はこのうちの教師あり学習(SL)にフォーカスしました。移動平均とストキャスティクスの組み合わせパターンを二値特徴量ベクトルに変換し、それを使って、通貨ペアEUR/USDの2023年のデータを元にシンプルなニューラルネットワークを学習させました。そして、そのモデルを使って2024年のフォワードテストをおこないました。
今回の記事では、「RLは運用中にモデルを調整するための手法として機能する」という前提のもと、前回のSLの結果とネットワークを活用しながら、強化学習を組み合わせた運用例を見ていきます。ここでいうRLは、単純な価格変動予測だけに依存していたSLモデルに対して、買い・売り判断を微調整する、展開時のバックプロパゲーション的な役割を果たすと考えています。
この「微調整」は、過去のRL関連記事でも扱ってきたように、探索と活用のバランスを取るプロセスです。これにより、方策ネットワークは実際の市場環境の中で、どの状態が買いまたは売りにつながるのかを学習していきます。たとえば、見かけ上強気な状態であっても、必ずしも買いエントリーが正解とは限らない場合もあります。逆もまた然りです。つまり、RLはSLが出した判断に対して、もう一段階フィルタをかける役割を担うということです。SLモデルでは、状態は1次元の連続値として扱っていましたが、今回のRLでもほぼ同様の行動空間を使います。
DDPG
これまでにいくつかの強化学習(RL)アルゴリズムを扱ってきましたが、今回の記事ではDeep Deterministic Policy Gradient (DDPG)を取り上げます。このアルゴリズムは、以前紹介したDQNと同様に、連続行動空間での予測に対応しています。最近扱った多くのアルゴリズムは、分類モデルであり、「次に取るべき行動は買いか売りか、あるいは様子見か」といった確率分布の出力を目的としていました。
一方で、DDPGは分類ではなく回帰モデルです。行動空間を0.0~1.0の浮動小数点値として定義し、この値によって次の行動を制御します。このアプローチは、単に以下のような単純な判断だけでなく、さらに多様なオプションを調整できる柔軟性を持っています。
- 0.5より上なら「買い」
- 0.5より下なら「売り」
- 0.5付近なら「様子見」
たとえば、指値・逆指値などの予約注文の導入や、ポジションサイズの調整などにも応用可能です。ただし、この記事では閾値0.5を基準とした最低限の実装に限定して進めていきます。拡張部分についてはご自分で工夫してみてください。
基本的に、DDPGはニューラルネットワークを用いてQ値(行動から得られる報酬)を近似し、単にQ値を推定するのではなく、環境の状態が与えられたときに次に取るべき最良の行動を選択する方策を直接最適化します。これに対して、DQNは「右に進む」「左に進む」といった離散的な行動や分類的な意思決定にも対応していますが、DDPGは連続行動空間のみに特化しています(例:ロボット制御におけるハンドル角度やモーター出力など)。では、DDPGは具体的にどう動作するのでしょうか。
DDPGでは、主に2つのニューラルネットワークが使用されます。
- 1つ目はActorネットワークで、これは現在の環境状態に対して最適な行動を選択する役割を持ちます。
- 2つ目はCriticネットワークで、こちらはActorが選んだ行動がどれだけ良いものかを評価します。具体的には、その行動を取ることで得られると予想される報酬を推定します。
この推定値はQ値とも呼ばれます。また、DDPGにおいて重要な要素として経験リプレイバッファがあります。これは、状態、行動、報酬、次の状態といった過去の経験をバッファに蓄積し、そこからランダムにサンプリングしてネットワークの学習に使用します。これにより、各更新ステップ間の相関を減らすことができます。
さらに、先述のActorおよびCriticの2つのネットワークに加えて、それぞれのターゲットネットワークも使用されます。これらは本体のネットワークとは独立したコピーであり、より遅い更新速度で重みを調整します。これにより、ターゲット値が急激に変化するのを防ぎ、学習の安定性を高めることができます。最後に、強化学習における重要な要素である「探索」は、DDPGではさらに一歩進められており、行動にノイズ成分を加えるアルゴリズムが導入されています。中でも代表的なのがオーンスタイン=ウーレンベックノイズです。
DDPGの学習プロセスは、大きく分けて3つの要素で構成されています。まず、Actorネットワークの改善です。Criticネットワークの評価に基づいて、Actorが「どの行動が良く、どれが悪いか」を学び、報酬を最大化する行動を選択できるように重みを更新していく工程です。次に、Criticネットワークの改善があります。こちらは、ベルマン方程式に基づいて、報酬(Q値)をより正確に推定できるように学習をおこないます。

ここで
-
Q(s,a):状態sにおいて行動aを取った際の、CriticによるQ値の予測(推定値)です。
-
r:状態sで行動aを取った直後に得られる即時報酬です。
-
γ:割引率(0≤γ<1)。将来の報酬をどの程度重視するかを決定します。γが0に近いほど短期的な報酬を重視し、1に近いほど長期的な報酬を重視します。
-
s′:状態sで行動aを取った後に観測される次の状態です。
-
Qtarget(s′,⋅):次の状態s′におけるQ値の推定値で、ターゲットCriticネットワークによって計算されます。学習の安定性を高めるために使用されます。
-
Actortarget(s′):次の状態s′に対して、ターゲットActorが出力する行動(決定論的方策)です。
加えて、ActorターゲットおよびCriticターゲットに対してはソフトアップデートがおこなわれます。これは、メインのネットワークに少しずつ追従するかたちで重みを更新するもので、以下の式に従って実行されます。
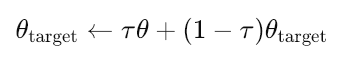
ここで
- θtarget:ターゲットネットワーク(ActorまたはCritic)のパラメータ(重み)です。
- θ:メイン(オンライン)ネットワーク(ActorまたはCritic)のパラメータです。
- τ:ソフトアップデート率(0≪τ≪1、例:0.001)。ターゲットネットワークのアップデート速度を制御します。
- τが小さい場合:ターゲットネットワークは非常にゆっくり変化し、学習は安定しやすくなります。
- τが大きい場合:ターゲットネットワークはより速くアップデートされますが、不安定になる可能性もある一方、環境の変化に素早く適応できる場合もあります。
なぜDDPGなのか。その理由は、高次元かつ連続した行動空間でうまく機能する点にあります。DDPGは、Q学習の安定性と方策勾配の柔軟性を組み合わせており、上で述べたようなロボティクスにおける連続行動の制御では非常に人気があります。実際、ロボティクスや物理ベースの制御、その他の複雑なタスクで広く使われています。ただし、これは金融時系列に使えないという意味ではありません。むしろ、今回はそこに応用していこうというのが本稿の狙いです。
実装には主にPython 3.10を使用しています。これは、非常に深いネットワークのトレーニング時における効率性が高いためです。ただ、この分野では定期的に新しい発見があります。私の場合、Pythonがこれほど高速に学習をこなせる理由が、実はPyTorchやTensorFlowの中核がC/C++やCUDAで実装されている点にあるということに改めて気づかされました。MQL5もCに非常に近く、OpenCLの実装もすでにサポートされています。つまり、これが意味するところは、おそらくMQL5側における行列積の基本ライブラリ(OpenCL一部利用)が欠けているだけであり、それさえ用意できればMQL5でも同様のパフォーマンスが出せるのではという仮説が成り立ちます。これは、実際に検討してみる価値があるかもしれません。
リプレイバッファ
リプレイバッファは、DDPGをはじめとするオフポリシー型強化学習アルゴリズムにおいて非常に重要な要素です。その主な役割は、連続するサンプル間の時間的相関を断ち切ること、経験の再利用によって学習効率を高めること、多様な状態遷移を提供して学習の安定性を確保すること、そして過去の経験(状態、行動、報酬、次の状態、doneフラグを含む遷移タプル)を保存し、ネットワークの学習および重み更新時に利用可能にすることです。
その実装の核は、まずは初期化関数から始まります。
def __init__(self, capacity): self.buffer = deque(maxlen=capacity)
私たちは、固定容量のcollections.dequeを使用しており、容量がいっぱいになると先入れ先出しの挙動で古い経験を自動的に破棄します。これはシンプルでメモリ効率にも優れています。次に、push操作では、バッファに完全な遷移タプルを格納します。成功した遷移だけでなく、終了状態を示すdoneフラグも考慮し、正常終了とエピソード終了の両方に対応します。新しい経験を追加する際のオーバーヘッドは最小限に抑えられています。
def push(self, state, action, reward, next_state, done): self.buffer.append((state, action, reward, next_state, done))
使用しているサンプリング機構はランダム一様サンプリングであり、これは相関を断ち切る上で非常に重要です。効率的で、「zip(*batch)」によるバッチ処理を活用して環境の各要素を分離しています。これにより、Q学習の更新に必要なすべての成分を返します。
def sample(self, batch_size): batch = random.sample(self.buffer, batch_size) states, actions, rewards, next_states, dones = zip(*batch)
次に、リプレイバッファクラスでは、環境の各要素(状態、行動、報酬、次状態、doneフラグ)をテンソルに変換し、デバイス管理をおこないます。既に示したように、変換対象は状態、行動、報酬、次状態、doneフラグです。この変換処理は非常に堅牢で、NumPy配列とPyTorchテンソルの両方を入力として扱えます。これにより、計算グラフから切り離されたテンソル(勾配情報を持つ配列と考えてください)を確実に得られます。
デバイスの競合を避けるために、データは一旦CPUに移動します。その後、ニューラルネットワークで一般的な前提条件であるFloat Tensor (float-32)に明示的に変換します。このデータ型は、MQL5でよく使われるdoubleよりも小さく、計算効率が大幅に向上します。最後に、PyTorchでは(TensorFlowとは異なり)、利用可能であればGPUなど特定の計算デバイスにデータを移動させることも自由に選択できます。
states = torch.FloatTensor( np.array([s.detach().cpu().numpy() if torch.is_tensor(s) else s for s in states]) ).to(device)
私たちのリプレイバッファクラスは、DDPGと非常に相性が良いです。まず、DDPGは過去の経験から学習するためにリプレイバッファ必須であり、オフポリシー学習を容易にします。連続行動空間もFloat Tensor変換によってうまく扱えます。さらに、ランダムサンプリングによって相関のある更新を防ぎ、学習の安定性を高める効果があります。また、NumPyとtorchの両方の入力に対応できるため、一般的な強化学習パイプラインに柔軟に組み込める点も強みです。
将来的な改善点としては、重要な遷移を優先的に扱うPrioritized Experience Replayへの切り替えや、マルチステップリターン(n-step learning)の導入、経験の種類ごとの分類・分離、NumPyを介さずにより効率的なテンソル変換の実装などが考えられます。
全体としては、torch.is_tensor()による型チェックやCPU/GPUのデバイス管理、環境コンポーネントの明確な分離を備えた堅牢な実装です。性能面でも、dequeがO(1)(英語)のappend/pop操作を提供し、バッチ処理でオーバーヘッドを最小限に抑え、適度なサイズのバッファに対して効率的なランダムサンプリングを実現しています。加えて、コードは明快で拡張や修正が容易、出力の型整合性も良好なため、メンテナンス性も高いと言えます。
主な制約や考慮点としては、メモリ使用量が挙げられます。完全な遷移を保存するため、遷移数が多い環境では容量が非常に大きくなる可能性があります。また、固定容量は環境に応じて調整が必要になることもあります。さらに、サンプリング効率の観点では、一様ランダムサンプリングは重要な経験を優先しないため、すべての経験に等しい重みを与えてしまいます。また、サンプリング時にエピソード境界を考慮しない点も課題です。
これらの課題に対応する代替案としては、非常に大きなバッファに対してディスクベースのストレージを使う方法、圧縮表現を用いた画像ベースの状態管理、ログ確率など追加情報の保存サポートの導入などが考えられます。こうした拡張により、DDPGの基盤を堅牢に保ちつつ、用途に応じた柔軟な拡張が可能になります。
CriticネットワークとActorネットワーク
両者とも基本的には類似した多層パーセプトロン構造を持ちますが、強化学習において当然のことながら、DDPGではそれぞれ異なる役割を果たします。CriticネットワークはQ関数とも呼ばれ、状態-行動ペアの価値(Q値または報酬)を推定します。一方、Actorネットワークは方策ネットワークとも呼ばれ、与えられた状態に対して最適な行動を決定します。
Criticネットワークの初期化および層構造は以下のような形をとります。
def __init__(self, state_dim, action_dim, hidden_dim): super(Critic, self).__init__() self.fc1 = nn.Linear(state_dim + action_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, 1)
ここでの重要なポイントは、他の手法の価値関数とは異なり、状態と行動の両方を入力として受け取る(以前の強化学習アルゴリズムでも見られるように)こと、3層の全結合層で構成されており、最初の2層はそれぞれ隠れ層のニューロン数を持つこと、最終出力層は1つのQ値スカラーのみを出力すること、そしてこのアーキテクチャは連続行動空間におけるQ(s,a)を推定することを目的としている点です。
フォワードパスの動作は以下の通りです。
def forward(self, state, action): x = torch.cat([state, action], dim=1) x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) q_value = self.fc3(x)
この実装における重要な要素は、DDPGの行動価値推定に不可欠なtorch.catです。これは状態ベクトルと行動ベクトルを結合し、処理に渡します。dim=1の指定により、バッチ処理に適した形で正しく連結されます。もうひとつ注目すべき点は活性化関数です。隠れ層にはReLUが使われており、勾配消失問題の軽減に役立っています。最終層には活性化関数を適用していません。これはQ値が任意の実数値を取るためです。
情報の流れは、状態-行動ペアから隠れ層を経てQ値の推定へと進み、これがQ学習関数の中核を成しています。Actorネットワークは以下の初期化および構造を持ちます。
def __init__(self, state_dim, action_dim, hidden_dim): super(Actor, self).__init__() self.fc1 = nn.Linear(state_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, action_dim) self.tanh = nn.Tanh()
ここで注目すべき重要な点は、方策が状態依存であるため、入力として状態の次元(state-dim)のみを受け取ることです。今回の実装では、Criticネットワークと同様の3層構造を持ちますが、出力の扱いが異なります。最終層のサイズは行動空間の次元数と一致しており、出力層にはTanh活性化関数が用いられています。これは行動を一定範囲内に制限するために重要です。フォワードパスの動作は以下のコードで定義されます。
def forward(self, state):
x = self.relu(self.fc1(state))
x = self.relu(self.fc2(x))
action = self.tanh(self.fc3(x)) Criticネットワークに比べて、Actorネットワークははるかにシンプルかつ直接的です。状態処理は(Criticと異なり)状態の次元のみを入力として受け取り、隠れ層を通じて状態表現を構築します。行動生成はTanh活性化によって[-1,1]に制限されており、これはDDPGの連続行動空間にとって不可欠です。この固定範囲は環境の行動範囲(例:[0,1]など)にスケール変換可能です。さらに重要なのは、方策が本質的に決定論的であり、確率分布ではなく特定の行動を出力する点です。これは確率的方策でよく見られる離散行動の分布とは異なります。
DDPGに特化した設計としてCriticネットワークは、状態と行動を結合して入力として扱う点、連続行動空間に適したスカラー出力を持つ点、そして活性化を最終層に適用しないことでQ値推定の全範囲を保持する点で、他の強化学習アルゴリズムとも部分的に共通しています。一方、DDPGにおけるActorネットワークの設計上の特徴としては、まずTanh関数によって出力に上限・下限を設け、行動を学習可能な範囲内に制約している点、確率的な方策ではなく決定論的な方策を採用しており、より明確な行動値を出力する設計となっている点、さらに、最終層の出力サイズは環境の行動空間の次元数に合わせて調整されており、動作空間との整合性が取られている点があります。
今回のDDPG例は1次元の行動空間を使用しており、状態空間も1次元です。これは前回の記事で使った教師あり学習ネットワークの出力に対応しています。共通するアーキテクチャの特徴として、ReLU活性化があり、これは深層強化学習の隠れ層で一般的に用いられます。隠れ層のサイズは一貫しており、低次元状態空間に適したMLP構造を採用しています。
PyTorchネットワークとして際立った特徴はないものの、実装の強みは、入出力の次元を明確に管理・指定している堅牢さ、隠れ層と出力層の活性化を適切に分離している活性化管理、そして全操作がテンソルのバッチ次元を維持しバッチ処理に対応している点にあります。加えて、これらのネットワークの性能を高める要因としては、他の活性化関数に比べて高速なReLUの効率性、畳み込みや再帰処理を用いない線形層のシンプルさ、そして効率化されたフォワードパスによる最小限の演算が挙げられます。
Criticネットワークの潜在的な改良点としては、学習安定化のためのレイヤー正規化、状態価値を別に扱うデュエリング構造、そしてTD3で用いられるような複数Q出力によるクリップドダブルQ学習などがあります。Actorネットワークでは、探索のためのノイズ注入(ただしDDPGでは外部ノイズを使用)、状態スケールの変動に対応するバッチ正規化、より安定した学習を目指すスペクトル正規化などが考えられます。
DDPGにおけるこの2つの統合では、Criticネットワークは方策更新のためのQ値推定を提供し、その推定値を使って自身の時間差分ターゲット(TDターゲット)を計算します。入力である状態-行動の価値を正確に評価し、Actorネットワークの重み・バイアスをどの程度調整すべきかを示します。Actorネットワークは環境での行動生成とQ値計算に用いられ、CriticのQ値に基づく勾配上昇で方策を更新し、連続制御のための滑らかな決定論的方策を学習します。
結論
今回は、DDPGのAgentクラスとEnvironmentのデータクラスを確認した上で、前回の記事でフォワードテストに成功した7つのパターンのストラテジーテスター報告をレビューする予定でした。しかし、この記事がすでにかなりの長さになっているため、これらは次回に回します。ここで扱った内容の多くはPythonでの実装で、ONNX形式のネットワークをエクスポートし、MQL5に統合することを前提としています。
現在Pythonを使う理由は、純粋なMQL5よりもトレーニングが効率的だからです。ただし、将来的にはOpenCLを利用した回避も検討可能で、今後の記事で取り上げるかもしれません。また、シグナルクラスからウィザードで組み立てる際に使う典型的なコードについても次回触れる予定で、今回の記事にはコードの添付はありません。
| 名前 | 詳細 |
|---|---|
| wz_58_ddpg.py | Pythonによる強化学習DDPG実装のスクリプトファイル |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/17668
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索