
Del básico al intermedio: Estructuras (VI)

Introducción
En el artículo anterior, "Del básico al intermedio: Estructuras (V)", se mostró y explicó cómo crear plantillas de estructuras simples. El objetivo era sobrecargar una estructura para otros tipos de datos sin tener que volver a programar todo un contexto estructural. Aunque aquel artículo pudiera resultar algo complicado de entender, traté de explicarlo de forma que resultara lo más simple y práctico posible. El objetivo es que todos puedan seguir y estudiar los temas para lograr utilizar realmente los conceptos mostrados y adoptados en cada uno de los artículos.
Pues bien, a pesar de todo, lo que se vio en aquel artículo es la parte fácil de un conjunto de conceptos e informaciones que buscan, principalmente, agrupar bajo un mismo paraguas una amplia y variada gama de actividades que puede llevar a cabo un programador cualificado.
Lo que vamos a empezar a ver ahora, y esto lo iré mostrando poco a poco, tiene como objetivo ampliar literalmente lo que se vio en el artículo anterior. Por lo tanto, es un tema que se trata en muchos cursos de programación avanzada y análisis de datos. Así que no esperes verlo todo en un único artículo. Sería necesario un conjunto enorme de artículos solo para abordar adecuadamente este tema. Y eso sin siquiera entrar en la programación orientada a objetos.
¿Y por qué estoy recalcando esto? El motivo es que veo a mucha gente ansiosa por aprender a utilizar clases y cosas similares. Sin embargo, estas mismas personas carecen de los conocimientos básicos para comprender la programación orientada a objetos. Y estos conceptos solo nacen cuando se comprende adecuadamente la programación estructural. Para entenderla, es preciso dedicar mucho tiempo al estudio y a la resolución de problemas reales. Algo que solo se consigue con el tiempo y la experiencia.
Sin embargo, el objetivo de estos artículos es precisamente acelerar esta fase de aprendizaje. Así, lo que llevaría años se puede realizar en cuestión de meses o incluso semanas, dependiendo de tu esfuerzo y tu perfil. Créeme, tener un perfil de programador es extremadamente necesario para asimilar las cosas de forma rápida. Sin ello, podrías aprender a crear diversas cosas, pero lamentablemente llegará un punto en que no podrás avanzar más. Mi objetivo con estos artículos es precisamente este: mostrarte que, con calma, paciencia, dedicación y estudio, no importa si tienes o no el perfil correcto. Cualquiera puede llegar a ser un buen programador.
Así que vamos a comenzar un nuevo tema para revisar lo que se hizo en el artículo anterior y entender algunos detalles que quizás pasaron desapercibidos. Esto es muy importante para comprender algunos aspectos que veremos muy pronto.
Pensemos en problemas del día a día
Una de las cosas más simples que existen es buscar un contacto en la agenda. Se trata, sin duda, de una tarea muy simple y básica, como buscar sinónimos de palabras en un diccionario o el significado de una palabra en el diccionario. Son cosas que un niño puede aprender, ya que es muy fácil enseñar cómo se hace. Sin embargo, ¿te has parado a pensar en cómo sería si no supieras cómo buscar un contacto en una agenda o un número de teléfono en una guía telefónica, o cómo tu navegador de internet encuentra rápidamente la página web que has solicitado? Pues bien, todos estos problemas tienen como base el mismo tipo de concepto primordial: las estructuras.
No obstante, aunque el concepto sea el mismo, el tipo de información que se almacena puede variar enormemente. Por ejemplo, en una agenda de contactos podemos tener un nombre, una dirección o un número de teléfono. Sin embargo, en un diccionario encontraremos una palabra seguida de su significado. Todo esto puede organizarse de una manera muy simple y práctica. Sin embargo, lo realmente notable es implementar un código que consiga lidiar con diferentes tipos de estructura sin que sea necesario realizar enormes modificaciones. Existen formas de hacerlo, pero no llegaremos tan lejos, ya que no sería necesario, pues el objetivo es mostrar cómo se pueden implementar cosas sencillas.
En el artículo anterior, expliqué cómo abordar un tipo de código estructural muy simple, en el que dentro de la propia estructura se utilizan datos discretos para diversos objetivos. Sin embargo, este tipo de solución no se ajusta a problemas de naturaleza más amplia. Para que lo entiendas, vamos a crear un código muy simple y fácil de entender. Este puede verse a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. }; 26. //+------------------------------------------------------------------+ 27. #define PrintX(X) Print(#X, " => ", X) 28. //+------------------------------------------------------------------+ 29. void OnStart(void) 30. { 31. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 32. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 33. 34. st_Data <double> Info_1; 35. st_Data <uint> Info_2; 36. 37. Info_1.Set(H); 38. Info_2.Set(K); 39. 40. PrintX(Info_1.Get(Info_2.Get(3))); 41. } 42. //+------------------------------------------------------------------+
Código 01
Este código binario puede resultar muy gracioso e interesante, dependiendo de cómo lo analices, incluso antes de entender lo que quiero explicar. En él, creamos una relación desconectada entre dos entidades. Pero vayamos con calma, ya que el concepto que se debe entender nos ayuda a comprender cómo los problemas del día a día pueden modelarse de forma que nos permita hacer uso de una programación estructural muy simple y relativamente abarcadora.
En este código 01, lo que intentamos hacer es crear, mediante programación estructural, una conexión entre los elementos de los arrays K y H. Por supuesto, podríamos crear lo mismo de forma convencional. Sin embargo, si creamos las cosas de manera estructural, pronto veremos lo mucho más sencillo que resulta aplicarlas a otros tipos de problemas. Sin necesidad de modificar el código ya creado.
Si has estado practicando y estudiando el contenido de los artículos, sabrás perfectamente qué tipo de resultado generará este código. Y, además, sabes por qué este código genera el resultado que genera, y todo esto solo con mirar el código 01. Sin embargo, para quienes aún no han alcanzado este nivel, mostraremos el resultado impreso en el terminal de MetaTrader 5, que se puede ver en la imagen de abajo.

Imagen 01
Pregunta: ¿Por qué la línea 40 muestra este valor en la imagen 01? Respuesta: Porque estamos usando un elemento del array K para indexar un elemento del array H, pero no es exactamente lo que queríamos hacer. En realidad, la idea es vincular un valor del array K para conocer el valor correspondiente en el array H, pero la conexión no se ha producido como se esperaba.
Para dejar claro cuál sería la idea aquí, es necesario que entiendas lo siguiente, mi querido lector: el array K sería como una clave, donde cada uno de los valores sería un índice para acceder o conocer el valor del array H. Sin embargo, el array K está fuera de orden, y se hizo a propósito para que comprendas por qué no siempre se encuentra la solución de inmediato.
Para que entiendas cómo se va a desarrollar esta relación, vamos a modificar el código 01 al código 02.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. uint NumberOfElements(void) 26. { 27. return Values.Size(); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. void OnStart(void) 33. { 34. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 35. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 36. 37. st_Data <double> Info_1; 38. st_Data <uint> Info_2; 39. 40. Info_1.Set(H); 41. Info_2.Set(K); 42. 43. for (uint c = 0; c < Info_2.NumberOfElements(); c++) 44. PrintFormat("Index [%d] => [%.2f]", Info_2.Get(c), Info_1.Get(c)); 45. } 46. //+------------------------------------------------------------------+
Código 02
Tal vez ahora, con este código 02, las cosas queden más claras. En la línea 43, hacemos uso de un bucle para recorrer todos los elementos y mostrar cómo se correlaciona un array con otro. Cuando ejecutemos este código 02, obtendremos lo que se muestra en la imagen de abajo.
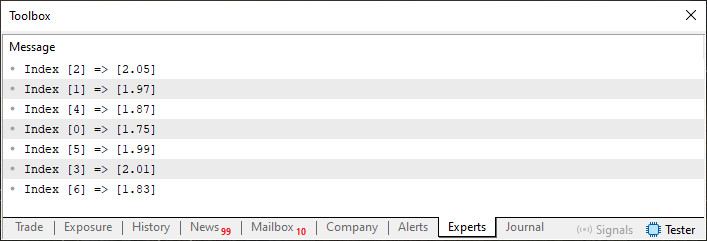
Imagen 02
Muy bien, ahora podemos volver a la cuestión del código 01, ya que, basándonos en la imagen 02, sabemos que, para cada índice declarado en el array K, hay un valor correspondiente en el array H. Por tanto, cuando en el código 01 preguntamos cuál es el valor del tercer índice, en realidad no nos referimos al valor mostrado en la imagen 01. Esto se debe a que, si ignoramos el hecho de que los arrays están fuera de orden, el tercer índice en el array K sería cero. Sin embargo, al pedir que se nos muestre el valor correspondiente, no estaríamos apuntando al índice correcto en el array H. Sé que esto puede parecer confuso, pero pronto entenderás a dónde quiero llegar.
Entonces, el primer problema que tenemos es que los arrays están desordenados. Y, para una búsqueda realmente eficiente, necesitamos que estén ordenados. Hay que recordar que la relación mostrada en la imagen 02 debe mantenerse, ya que un array servirá como fuente de búsqueda y el otro como fuente de respuesta.
Muchos principiantes, al oír estas cosas, ya piensan de inmediato en una solución, siendo la más obvia el uso de la función ArraySort para organizar los arrays o la ArrayBsearch para buscar en el array. En cualquier caso, necesitamos modificar el código 01 para lograr nuestro objetivo. Así surge el código que se ve justo a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. T Search(const uint index) 26. { 27. return ArrayBsearch(Values, index); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. #define PrintX(X) Print(#X, " => ", X) 33. //+------------------------------------------------------------------+ 34. void OnStart(void) 35. { 36. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 37. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 38. 39. st_Data <double> Info_1; 40. st_Data <uint> Info_2; 41. 42. Info_1.Set(H); 43. Info_2.Set(K); 44. 45. PrintX(Info_1.Get(Info_2.Search(3))); 46. } 47. //+------------------------------------------------------------------+
Código 03
Al ejecutar este código 03, finalmente tenemos la conexión correcta y deseada. Esto genera la respuesta que se ve justo abajo.

Imagen 03
Observa, querido lector, que el valor que se da como respuesta corresponde, de hecho, al índice buscado en nuestra lista, por así decirlo, como se puede ver en la correspondencia entre los arrays K y H de la imagen 02. Sin embargo, existen formas más simples de hacer este mismo tipo de conexión, en las que podemos trabajar de manera más adecuada manteniendo una relación más estrecha entre los arrays K y H.
Una de estas formas sería utilizar arrays multidimensionales. Sin embargo, los arrays multidimensionales no son muy adecuados para trabajar con diferentes tipos de información, por lo que es necesario utilizar otro método para crear este tipo de conexión. Recordemos que la idea es crear un código contenido dentro de una estructura.
Por tanto, necesitamos dar un paso atrás para luego dar dos hacia adelante. El objetivo es hacer más sencilla la comprensión de la solución. Para separar las cosas, vamos a cambiar de tema.
Estructuras de estructuras
Una de las cosas que suele confundir mucho a los principiantes es cuando pasamos a usar conceptos que se han visto hasta ahora de forma individual en un formato combinado. Sé que puede parecer extraño decir esto, ya que básicamente el concepto se mantiene intacto. Sin embargo, cuando unimos conceptos y los aplicamos de forma más profunda, surgen nuevas posibilidades que pueden resultar bastante confusas al principio.
Para explicar esto, vamos a modificar el código 03 visto en el tema anterior, de modo que podamos generar algo sencillo de entender que, al mismo tiempo, nos permita enfocar la explicación hacia nuestro objetivo principal. Es decir, crear un tipo de conexión entre un conjunto de valores y otro conjunto completamente distinto.
Para esto, vamos a usar el código implementado justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. struct st_Reg 07. { 08. double h_value; 09. uint k_value; 10. }Values[]; 11. }; 12. //+------------------------------------------------------------------+ 13. bool Set(st_Data &dst, const uint &arg1[], const double &arg2[]) 14. { 15. if (arg1.Size() != arg2.Size()) 16. return false; 17. 18. ArrayResize(dst.Values, arg1.Size()); 19. for (uint c = 0; c < arg1.Size(); c++) 20. { 21. dst.Values[c].k_value = arg1[c]; 22. dst.Values[c].h_value = arg2[c]; 23. } 24. 25. return true; 26. } 27. //+------------------------------------------------------------------+ 28. string Get(const st_Data &src, const uint index) 29. { 30. for (uint c = 0; c < src.Values.Size(); c++) 31. if (src.Values[c].k_value == index) 32. return DoubleToString(src.Values[c].h_value, 2); 33. 34. return "-nan"; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 43. 44. st_Data info; 45. 46. Set(info, K, H); 47. PrintX(Get(info, 3)); 48. } 49. //+------------------------------------------------------------------+
Código 04
Muy bien, antes de empezar a explicar los detalles de lo que hace este código 04, necesito que entiendas lo siguiente: lo que vemos aquí es solo una forma de implementar algo con un objetivo previamente definido.
En ningún caso debes considerar lo que se explicará a continuación como la única forma de hacer las cosas, ya que existen otras formas, algunas más simples y otras más complicadas, que incluyen el uso de arrays multidimensionales. Esto, tomando como base lo que ya se ha explicado y mostrado hasta este momento.
Pero hay una forma aún mejor de hacerlo. Sin embargo, esto se verá más adelante. Dicho esto, veamos qué hace el código 04. Para comenzar, veremos el resultado de la ejecución. Puede observarse en la imagen de abajo.

Imagen 04
Hmm, qué resultado más interesante, ¿verdad, mi querido lector? Es posible que estés pensando lo siguiente: cuando se ejecuta la línea 47, se hace algo muy parecido a lo que se vio en el código 01. Sin embargo, al observar la función Get, presente en la línea 28 de este código 04, podemos ver que el valor de index se busca dentro del conjunto de elementos del array K.
Pero el punto clave y de verdadero interés es que, cuando la línea 31 tiene éxito, no devolvemos el índice del elemento del array K, sino el valor de ese mismo índice del array H, con lo que creamos la conexión. Ahora, presta atención al siguiente hecho: como el número de elementos es pequeño, no necesitamos preocuparnos por el tiempo de ejecución del código.
Sin embargo, en una situación normal y real, esta estructura que se está creando en la línea 4 debería ordenarse de alguna manera. Así, durante la búsqueda que estamos realizando en la línea 28, el tiempo de ejecución será el menor posible.
Entonces, surge una nueva idea: ¿cómo podríamos crear un código más cercano a la realidad? Bien, querido lector, para ello necesitamos dotar a esta estructura de un contexto propio. Y es en este punto donde comienza lo que en ciencia de la computación se llama análisis de datos.
Cuando aplicamos análisis de datos a nuestros códigos, debemos estructurarlos de alguna forma, pero no existe una estructura perfecta para todos los casos. En algunos casos, será necesario implementar el código de una determinada manera, mientras que en otros será necesario implementarlo de una manera muy diferente. Por tanto, cada problema requiere un nivel de conocimiento adecuado para obtener el mejor resultado en el menor tiempo posible.
Bien, en este momento ya estarás pensando: "Entonces, ¿vamos a empezar a estudiar análisis de datos?" Aún no, querido lector. Tenemos algunas otras cosas que ver antes de eso. Podríamos comenzar a hacerlo pronto, pero no es el caso por ahora. El detalle es que, habiendo entendido que ahora tenemos una conexión entre el conjunto de elementos del array K y el conjunto de elementos del array H, podemos comenzar a pensar en una forma de convertir la estructura de la línea cuatro en una estructura contextual que contenga los mecanismos necesarios para mantener, gestionar y garantizar que esta conexión entre los elementos se mantenga adecuadamente establecida.
Para lograrlo, primero utilizaremos el código 04 para construir esta modelización. Es decir, aún no vamos a generalizar el mecanismo. Así el compilador podrá crear la sobrecarga de tipos. A continuación, se muestra el nuevo código modificado.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. struct st_Reg 10. { 11. double h_value; 12. uint k_value; 13. }Values[]; 14. //+----------------+ 15. public: 16. //+----------------+ 17. bool Set(const uint &arg1[], const double &arg2[]) 18. { 19. if (arg1.Size() != arg2.Size()) 20. return false; 21. 22. ArrayResize(Values, arg1.Size()); 23. for (uint c = 0; c < arg1.Size(); c++) 24. { 25. Values[c].k_value = arg1[c]; 26. Values[c].h_value = arg2[c]; 27. } 28. 29. return true; 30. } 31. //+----------------+ 32. string Get(const uint index) 33. { 34. for (uint c = 0; c < Values.Size(); c++) 35. if (Values[c].k_value == index) 36. return DoubleToString(Values[c].h_value, 2); 37. 38. return "-nan"; 39. } 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. #define PrintX(X) Print(#X, " => ", X) 44. //+------------------------------------------------------------------+ 45. void OnStart(void) 46. { 47. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 48. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 49. 50. st_Data info; 51. 52. info.Set(K, H); 53. PrintX(info.Get(3)); 54. } 55. //+------------------------------------------------------------------+
Código 05
Ahora, presta atención, querido lector, para no perder el hilo de la historia. Cuando se ejecute el código 05, veremos en el terminal de MetaTrader 5 la misma información básica que en la imagen 04, pero con una pequeña diferencia, que se puede observar justo abajo.

Imagen 05
A diferencia del código 04, el código 05 es un código construido de forma estructural. No obstante, debido a las declaraciones de tipo realizadas en las líneas 11 y 12, estamos atados a un tipo específico de dato que puede usarse aquí. Supongamos que quieres o necesitas crear un sistema diferente, en el que, en lugar de crear una conexión de valores numéricos, quieras crear una conexión de valores de texto, es decir, cadenas, en lugar de los valores que se están utilizando en el código 05. ¿Cómo podríamos hacer esto, cambiando lo mínimo posible del código 05?
Bien, este es el punto en el que la cosa se vuelve confusa si has llegado a este artículo sin haber leído los anteriores, ya que en ellos se explicaron algunos detalles que no voy a volver a comentar aquí. Sin embargo, voy a mostrar cómo podrías generalizar la estructura declarada en la línea cuatro para que el compilador cree la sobrecarga de tipo necesaria y, de esta manera, cubrir casos que aparentemente no serían posibles.
Para simplificar, comenzaremos generalizando solo un tipo base, el definido en la línea 11. A continuación, se muestra el nuevo código.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. struct st_Reg 11. { 12. T h_value; 13. uint k_value; 14. }Values[]; 15. //+----------------+ 16. string ConvertToString(T arg) 17. { 18. if ((typename(T) == "double") || (typename(T) == "float")) return DoubleToString(arg, 2); 19. if (typename(T) == "string") return arg; 20. 21. return IntegerToString(arg); 22. } 23. //+----------------+ 24. public: 25. //+----------------+ 26. bool Set(const uint &arg1[], const T &arg2[]) 27. { 28. if (arg1.Size() != arg2.Size()) 29. return false; 30. 31. ArrayResize(Values, arg1.Size()); 32. for (uint c = 0; c < arg1.Size(); c++) 33. { 34. Values[c].k_value = arg1[c]; 35. Values[c].h_value = arg2[c]; 36. } 37. 38. return true; 39. } 40. //+----------------+ 41. string Get(const uint index) 42. { 43. for (uint c = 0; c < Values.Size(); c++) 44. if (Values[c].k_value == index) 45. return ConvertToString(Values[c].h_value); 46. 47. return "-nan"; 48. } 49. //+----------------+ 50. }; 51. //+------------------------------------------------------------------+ 52. #define PrintX(X) Print(#X, " => ", X) 53. //+------------------------------------------------------------------+ 54. void OnStart(void) 55. { 56. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 57. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 58. 59. st_Data <double> info; 60. 61. info.Set(K, H); 62. PrintX(info.Get(3)); 63. } 64. //+------------------------------------------------------------------+
Código 06
Ahora la cosa se puso realmente divertida con la construcción de este código 06. Esto es así porque en este código 06 podemos comenzar a generalizar la estructura para que el compilador pueda realizar la sobrecarga cuando sea necesario. De este modo, podremos trabajar con diferentes tipos de datos para construir algún tipo de mecanismo de búsqueda. Sin embargo, cuando intentes compilar este código, notarás que, a diferencia de los anteriores, el mensaje es diferente.
Este puede verse justo abajo.

Imagen 06
Quizá recuerdes, querido lector, que mencioné que existen situaciones en las que los mensajes del compilador pueden ignorarse y otras en las que no. Pues bien, este es un ejemplo típico de un momento en el que podemos ignorar las advertencias del compilador. Esto se debe a que estos mensajes existen únicamente porque el compilador NO HA CONSEGUIDO entender lo que estamos haciendo en las líneas 19 y 21, que solo se ejecutarán en casos muy específicos, al igual que la propia línea 18. Hay una forma de evitar que se muestren estos mensajes, pero lo mostraré en otro momento, probablemente en el próximo artículo, ya que estamos llegando al final de este.
Bien, entonces, como ahora estamos generalizando uno de los valores, necesitamos indicarle al compilador qué tipo de información se utilizará. Así podrá crear el código adecuado para ese tipo de dato. Para ello, usamos la línea 59 para declarar la variable que nos dará acceso a la estructura. Ahora, dado que el tipo base declarado en la línea 56 es double, necesitamos usar un tipo compatible o idéntico en la declaración de la línea 59. De lo contrario, tendremos problemas al buscar en la estructura de datos.
Pero ¿cómo así? No entendí esta parte. Entiendo el motivo de la declaración de la línea 59, precisamente por la declaración que hay en la estructura. Sin embargo, no entiendo por qué necesito declarar un tipo adecuado igual que el de la línea 56. Si estamos creando algo genérico, para mí esto no tiene mucho sentido.
Bien, mi querido lector, como esto es un poco complicado de explicar, voy a dedicar el resto del artículo a tratar este tema, dejando así una buena parte de la explicación para el próximo artículo.
Quiero que observes que comenzamos el artículo usando un código muy similar al del código 06. Sin embargo, cuando se hizo, el resultado era, en cierto modo, conocido de antemano, ya que no nos preocupaba convertir o devolver el tipo de dato adecuado.
Ahora, piensa en lo siguiente: en el código 01, el tipo de dato que se devuelve depende del tipo de dato almacenado. Sin embargo, y aquí está el quid de la cuestión, en este código 06 siempre habrá un tipo de dato que se devolverá, independientemente del tipo de dato almacenado. En este caso, almacenaremos datos del tipo double. No obstante, la respuesta SIEMPRE será del tipo string.
El simple hecho de que esto se esté haciendo termina, por así decirlo, confundiendo al propio sistema, ya que la conversión no sería esperada por el programador que utilice la estructura que estamos definiendo. Tal vez pienses: ¿cómo es posible? Por supuesto que él lo sabrá. Pero esto no siempre es así, querido lector, ya que podemos crear bibliotecas de código y utilizarlas en diversos momentos. Y cuando hablo de biblioteca de código, no me refiero a que acumules un montón de códigos fuente.
Estas bibliotecas normalmente están formadas por código ejecutable, como ocurre con las famosas DLL. En ellas, no sabemos exactamente cómo funciona el código interno, solo tenemos una noción de ello, ya que pasamos valores a la DLL y esta nos devuelve un resultado. Es importante saber el tipo de dato que estamos pasando a la estructura, ya que puede que necesitemos convertirlos a su tipo original, dado que el resultado siempre será una cadena.
Bien. Pero, ¿no podemos dejar las cosas de forma totalmente generalizada? Es decir, en lugar de convertir los datos al tipo string, si los mantuviéramos en su tipo original, no tendríamos este problema del que hablamos hace un momento. ¿Estoy en lo cierto? Sí, amigo lector, estás en lo cierto respecto a esto. Sin embargo, recuerda que aquí el objetivo es didáctico, no producir un código que se pueda utilizar en la práctica, en una situación real.
Sin embargo, aun así, como quiero darte la oportunidad de que te detengas por unos instantes y reflexiones sobre ciertas cosas, vamos a modificar el código 06, de modo que solo se cambie el fragmento mostrado abajo en el código visto arriba. Y por el simple hecho de que esto se haya hecho, tenemos una situación completamente diferente planteada e implementada aquí. Mira el fragmento modificado.
. . . 53. //+------------------------------------------------------------------+ 54. void OnStart(void) 55. { 56. const string T = "possible loss of data due to type conversion"; 57. const uint K[] = {2, 1, 4, 0, 7, 5, 3, 6}; 58. 59. st_Data <string> info; 60. string H[]; 61. 62. StringSplit(T, ' ', H); 63. info.Set(K, H); 64. PrintX(info.Get(3)); 65. } 66. //+------------------------------------------------------------------+
Código 07
No necesitas preocuparte, porque en el anexo tendrás acceso a estos códigos en su totalidad para que puedas experimentar y practicar cada detalle que se muestra aquí. De todos modos, quiero que te detengas a pensar en lo que estamos haciendo aquí: al cambiar el código 06 por el fragmento mostrado en el código 07, el simple hecho de modificar el tipo de información que habrá en la estructura nos permitirá construir cosas que parecerían poco probables o difíciles de realizar, según muchos.
Un consejo para ayudarte a reflexionar sobre lo que se está haciendo: dependiendo de la forma en que se cree y se coloque la información en la variable de la línea 60 de este código 07, podemos crear un código que se pueda ejecutar en cualquier idioma, siempre y cuando, por supuesto, implementemos y coloquemos adecuadamente la información en la variable de la línea 60.
Piensa en cómo se podría hacer y en cómo afectaría a toda una generación de códigos que puedas llegar a construir.
Consideraciones finales
En este artículo, en el que exploramos con más profundidad ciertos aspectos básicos de la programación, vimos cómo podemos empezar a implementar una base de código genérico. El objetivo es reducir nuestro trabajo a la hora de programar y aprovechar todo el potencial que ofrece el propio lenguaje de programación. En este caso, MQL5. Lo que estoy mostrando, o intentando explicar aquí, es algo que me llevó mucho tiempo comprender.
Sin embargo, esto se debió a que las cosas se estaban creando mientras yo las estudiaba. Hoy en día, prácticamente todo el mundo dice que la programación orientada a objetos es lo mejor. Y sí, realmente es muy buena y útil. Pero ¿por qué? No sirve de nada que veas un código de una clase, lo uses o incluso consigas modificarlo sin entender por qué funciona. Para entender y aprender de verdad, primero hay que comprender cómo los lenguajes de programación llegaron a este nivel, por qué se creó la programación orientada a objetos y por qué se usa de forma tan extensiva.
Entender esto solo se logra con práctica y experimentación, usando códigos con principios solo comentados en la programación orientada a objetos, pero que, de hecho, no se crean como los métodos y posibilidades que únicamente esta programación nos proporciona. De hecho, estos principios nacieron en la programación estructural, un tema del que casi nadie habla hoy en día y que es precisamente el que estamos comenzando a explorar aquí.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15889
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Cliente en Connexus (Parte 7): Añadir la capa de cliente
Cliente en Connexus (Parte 7): Añadir la capa de cliente
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso