
Determinación de los tipos de cambio justos en PPA usando los datos del FMI

En algún momento, noté que pasaba más tiempo buscando el módulo de pronóstico "perfecto" que comprendiendo qué es lo que realmente mueve los tipos de cambio. Y entonces me planteé una pregunta sencilla: ¿qué pasaría si me olvido de todos estos gráficos y trato de encontrar el valor fundamental de las divisas? ¿No el que muestra el mercado en un momento determinado bajo la influencia de las emociones y la especulación, sino el que se desprende de las leyes económicas fundamentales?
Esta pregunta me llevó a trabajar durante varios meses. Comencé estudiando la teoría de la paridad del poder adquisitivo y terminé escribiendo un sistema completo de análisis del tipo de cambio en Python. Y esto ha resultado mucho más interesante que cualquier indicador técnico.
Planteamiento del problema
El análisis del mercado de divisas a menudo se centra en encontrar indicadores técnicos y patrones gráficos, ignorando factores económicos fundamentales. Y surge una pregunta lógica: ¿podemos determinar el valor justo de las divisas basándonos en leyes económicas, en lugar del sentimiento del mercado a corto plazo y movimientos especulativos?
Este artículo presenta un enfoque práctico para resolver dicho problema mediante la creación de un sistema integral para calcular tipos de cambio justos basados en la teoría de paridad del poder adquisitivo, implementado en el lenguaje de programación Python.
Fundamentos teóricos de la paridad del poder adquisitivo
El ejemplo clásico del Big Mac de McDonald's demuestra la esencia de la teoría: si una hamburguesa cuesta 5 dólares en Estados Unidos y 9 euros en Europa, el tipo de cambio justo debería ser 1,80 dólares por euro. Detrás de esta sencilla ilustración se esconde una herramienta fundamental para analizar los mercados de divisas que permite identificar desequilibrios de largo plazo más allá de la volatilidad del mercado de corto plazo.
Las raíces históricas del concepto se remontan al siglo XVI, cuando los comerciantes españoles observaron disparidades de precios entre la metrópoli y sus colonias. Si un peso compraba una barra de pan en Sevilla pero tres barras en México, esto indicaba un desajuste fundamental en el valor relativo de las divisas que requería una corrección mediante una modificación en el tipo de cambio o una igualación de precios.
Formulaciones de la teoría del PPA
La paridad de poder adquisitivo absoluta indica una relación directa entre los tipos de cambio y la relación de precios de bienes idénticos en diferentes países. Si bien teóricamente resulta elegante, este enfoque enfrenta múltiples factores distorsionantes en la práctica: diferencias impositivas, barreras regulatorias, costos de transporte y restricciones comerciales.
S₁₂ = P₁ / P₂
donde S₁₂ es el tipo de cambio de la divisa 1 a la divisa 2, P₁ y P₂ son los niveles de precios en los respectivos países.
La paridad del poder adquisitivo relativo se centra en la dinámica de los cambios de precio más que en los niveles absolutos. Según esta formulación, si la inflación en el país A es del 10% anual y en el país B es del 5%, la divisa del país A debe debilitarse un 5% con respecto a la divisa del país B para conservar la paridad de poder adquisitivo.
S₁₂(t) / S₁₂(0) = [P₁(t) / P₁(0)] / [P₂(t) / P₂(0)]
O en forma simplificada:
ΔS₁₂ = π₁ - π₂
donde π₁, π₂ son las tasas de inflación en los países 1 y 2.
Como base metodológica del algoritmo he elegido el enfoque relativo, debido a su mayor aplicabilidad práctica, a su mejor reflejo de la realidad económica y a la posibilidad de obtener puntos de referencia cuantitativos específicos para los tipos de cambio.
Evaluación de las fuentes de datos disponibles
Un estudio de los proveedores de datos PPA existentes ha revelado limitaciones significativas para su aplicación práctica. La OCDE publica los tipos oficiales de paridad de poder adquisitivo con un retraso de entre seis meses y un año (los datos de 2023 recién estuvieron disponibles a mediados de 2024), lo cual resulta inaceptable para mercados cambiarios dinámicos.
| Fuente | Frecuencia de actualización | Demora | Costo/año | Transparencia de la metodología | Aplicabilidad práctica |
|---|---|---|---|---|---|
| OCDE | Anual | 6-12 meses | USD 0 | Baja | Investigación |
| Penn World Table | 2-3 años | 1-2 años | USD 0 | Media | Académica |
| Bloomberg Terminal | Tiempo real | No | USD 24,000 | No tiene | Profesional |
| Refinitiv Eikon | Tiempo real | No | USD 22,000 | No tiene | Profesional |
La Tabla Mundial de Penn se actualiza con intervalos de varios años y la última versión disponible contiene información solo hasta 2019. Si bien dicha base resulta valiosa para la investigación académica, esos retrasos temporales son críticos para el trading práctico.
Los proveedores de datos comerciales Bloomberg y Refinitiv ofrecen información más actualizada, pero los costos de acceso parten de 2.000 dólares al mes para el Terminal Bloomberg, sin garantías de transparencia metodológica o calidad de los datos.
El problema de la opacidad metodológica: un inconveniente crítico de las soluciones existentes es la falta de claridad en los procedimientos computacionales. La metodología para calcular los coeficientes de la OCDE, la composición de las cestas de consumo, los algoritmos para procesar valores atípicos estadísticos y ajustar las diferencias cualitativas en los bienes siguen sin documentarse.
Los grandes proveedores de datos funcionan como sistemas cerrados: el usuario recibe resultados numéricos sin comprender su origen ni la posibilidad de verificación. Este enfoque resulta inaceptable para un análisis financiero serio que requiere un control total sobre los procesos computacionales.
Desarrollo de un sistema interno: tomé la decisión de crear un sistema independiente de cálculo de PPA utilizando datos disponibles públicamente de organizaciones internacionales, como el Fondo Monetario Internacional, el Banco Mundial y los servicios estadísticos nacionales. El sistema debe garantizar la transparencia total de los algoritmos y la capacidad de adaptar la metodología a tareas analíticas específicas.
Si bien el desarrollo es sustancialmente más complejo que comprar una solución lista para usar y requiere estudiar múltiples fuentes de datos, formatos de API y métodos estadísticos, este enfoque garantiza un control total sobre el proceso de cálculo y una comprensión profunda del funcionamiento del sistema.
Solución arquitectónica: un sistema de múltiples métodos
El problema fundamental de cualquier cálculo de PPA es que existen múltiples enfoques para estimar un tipo de cambio justo, cada uno con sus ventajas y limitaciones específicas. La elección de un único método nos lleva inevitablemente a la subjetividad de los resultados.
| Fuentes de datos | Métodos para calcular la PPA | Resultados y señales |
|---|---|---|
| API DEL FMI | Nivel de precios | Tipos de cambio justos |
| Banco mundial | PIB implícito | Desviaciones del mercado |
| Estadísticas nacionales | Ajustado por inflación | Señales comerciales |
| Datos de respaldo | Big Mac Proxy | índices de confianza |
| Tipos de cambio de mercado de los pares de divisas | Método compuesto | Clasificación de divisas |
El sistema desarrollado usa varios métodos de cálculo independientes en paralelo con la posterior combinación de resultados. La consistencia entre las estimaciones de diferentes métodos aumenta la confianza en el resultado, mientras que diferencias significativas indican un alto grado de incertidumbre, lo que en sí mismo ofrece información valiosa sobre el estado del mercado.
El primer enfoque se basa en comparaciones internacionales de niveles de precios. La lógica es simple: si un ciudadano suizo gasta una vez y media más para vivir que un estadounidense con el mismo nivel de vida, es que el franco suizo está sobrevaluado en un 50%.
Los datos para este método los tomé de programas internacionales de comparación de precios realizados bajo los auspicios del Banco Mundial y la OCDE. Estos programas comparan los precios de las cestas de consumo estándar en diferentes países y calculan los niveles de precios relativos.
def _calculate_price_level_ppp(self) -> Dict: ppp_rates = {} for country, price_level in self.price_levels_2024.items(): if country != 'US': ppp_factor = price_level / 100.0 ppp_rates[country] = { 'ppp_conversion_factor': ppp_factor, 'price_level_index': price_level, 'method': 'price_level_adjustment' } return ppp_rates
La ventaja de este método es que refleja las diferencias reales en el costo de vida. La desventaja es que los datos se actualizan con poca frecuencia, una vez cada pocos años.
Yo mismo ideé el segundo enfoque y todavía estoy orgulloso de él. La idea me surgió mientras estudiaba datos del FMI: ¿qué pasaría si comparamos el PIB de un país en divisa nacional (de estadísticas oficiales) con una estimación del mismo PIB en dólares (de bases de datos internacionales)?
La lógica era la siguiente: si el Banco de Rusia informa que el PIB de Rusia es de 150 billones de rublos, y el Banco Mundial estima que el PIB de Rusia es de 2 billones de dólares, entonces el tipo de cambio implícito es de 75 rublos por dólar. Esta es la tasa a la que las economías se valoran "justamente" entre sí.
def _calculate_gdp_implied_ppp(self, economic_data: pd.DataFrame): for country, gdp_usd_2023 in self.gdp_usd_estimates_2023.items(): country_gdp_lcu = gdp_lcu_data[gdp_lcu_data['REF_AREA'] == country] if not country_gdp_lcu.empty: latest_data = country_gdp_lcu.sort_values('year').iloc[-1] gdp_lcu = latest_data['value'] if gdp_lcu > 0: implied_rate = gdp_lcu / gdp_usd_2023
Este método ha resultado sorprendentemente preciso y relevante. Los datos del PIB se actualizan trimestralmente, por lo que las estimaciones están actualizadas. Y como el PIB es una medida agregada de toda la actividad económica, refleja bien el valor fundamental de una divisa.
El tercer método implementa la fórmula clásica para PPA relativa de los libros de texto. Vamos a tomar el tipo de cambio histórico desde un punto base y ajustarlo a la diferencia acumulada en inflación entre países.
Como referencia he elegido el año 2020: un año lo suficientemente reciente como para ser relevante, pero prepandemia para evitar distorsiones derivadas de una política monetaria extrema.
def _calculate_inflation_adjusted_ppp(self, economic_data: pd.DataFrame): # Get the basic rate for 2020 base_rate_2020 = GetBaseRate2020(base_currency, quote_currency) # Calculating the inflation differential inflation_differential = (base_data.inflation_rate - quote_data.inflation_rate) / 100.0 # Adjust the base rate adjusted_rate = base_rate_2020 * (1 + inflation_differential)
El método es teóricamente impecable y fácil de explicar. Si la inflación fuera mayor en el país A que en el país B, entonces la divisa de A debería debilitarse en proporción a dicha diferencia.
El único problema es la calidad de los datos de inflación. Los distintos países calculan la inflación de forma distinta y algunos tienden a “embellecer” las estadísticas. Pero en general, el método funciona bien.
El cuarto método está inspirado en el famoso índice Big Mac de The Economist. La idea es que el Big Mac sea un producto estandarizado que se produce usando la misma tecnología en todo el mundo. Su precio debería reflejar las diferencias reales en los costos de los recursos entre países.
El problema es que recopilar los precios actuales del Big Mac supone una tarea de investigación aparte. En lugar de ello, uso datos conocidos sobre los niveles de precios relativos para modelar cuánto debería costar un bien estandarizado en cada país.
def _calculate_big_mac_proxy_ppp(self): us_big_mac_price = 5.50 for country, price_level in self.price_levels_2024.items(): if country != 'US': local_big_mac_price = us_big_mac_price * (price_level / 100.0) ppp_rate = local_big_mac_price / us_big_mac_price
El método no es el más preciso, pero posibilita una buena comprobación intuitiva de los resultados de otros métodos. Si todos los demás métodos muestran que la divisa está sobrevaluada en un 20%, y el "método Big Mac" ofrece un resultado similar, esto aumenta la confianza en la valoración.
El quinto método combina los resultados de todos los anteriores mediante promedio ponderado. Pasé mucho tiempo calibrando las balanzas y probando diferentes combinaciones con datos históricos.
Al final me decidí por la siguiente distribución:
- Price Level PPP: 30% (el más fundamental)
- GDP-Implied PPP: 25% (más relevante)
- Inflation-Adjusted PPP: 25% (el más sólido teóricamente)
- Big Mac Proxy: 20% (más intuitivo)
def _calculate_composite_ppp(self, all_methods: Dict): weights = [0.30, 0.25, 0.25, 0.20] # Dynamic weight normalization if valid_methods < 4: total_weight = sum(weights[:valid_methods]) normalized_weights = [w / total_weight for w in weights[:valid_methods]] composite_rate = sum(rate * weight for rate, weight in zip(rates, normalized_weights))
La característica clave es la normalización dinámica de los pesos. Si algún método no puede producir un resultado (por ejemplo, no hay datos de inflación), los pesos de los métodos restantes aumentarán proporcionalmente. Esto resulta mucho más inteligente que simplemente eliminar los métodos "problemáticos".
Práctica de creación de un programa
Tras meses de preparación teórica, llegó el momento de tomar el teclado. Así que decidí escribir en Python: el lenguaje es lo suficientemente rápido para los cálculos financieros, pero también tiene excelentes bibliotecas para trabajar con datos.
La primera pregunta y la más importante es ¿dónde obtener los datos? Después de revisar decenas de fuentes, la elección recayó en la API del FMI. Pública, gratuita, bien documentada y, lo más importante, actualizada periódicamente.
def __init__(self):
self.base_url = "http://dataservices.imf.org/REST/SDMX_JSON.svc"
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Manual-PPP-Calculator/1.0',
'Accept': 'application/json'
})
Un detalle pequeño pero importante: debemos usar requests.Session() en lugar de simples llamadas requests.get(). Esto permite la reutilización de conexiones TCP y acelera sustancialmente el rendimiento al realizar múltiples solicitudes a una sola API.
El User-Agent tampoco es aleatorio. Muchas API bloquean solicitudes sin un agente de usuario explícito o con el valor predeterminado de Python. Es mejor presentarse inmediatamente como una aplicación seria.
El siguiente problema ha resultado más insidioso de lo esperado. Los códigos de divisa (USD, EUR, GBP) deben vincularse de alguna manera a los códigos de país en el sistema del FMI. Y entonces empezaron las sorpresas.
EUR no es un código de país, sino un código de unión monetaria. En la base de datos del FMI, la eurozona está designada como U2. Suiza es CH, no SW. Gran Bretaña es GB, no UK.
self.currency_country_map = {
'USD': 'US', 'EUR': 'U2', 'GBP': 'GB', 'JPY': 'JP',
'AUD': 'AU', 'CAD': 'CA', 'CHF': 'CH', 'NZD': 'NZ',
'SEK': 'SE', 'NOK': 'NO', 'DKK': 'DK', 'PLN': 'PL'
}
Podría parecer una menudencia, pero sin un mapeo adecuado el sistema simplemente no funciona. Así que pasé un día entero depurando hasta que me di cuenta de que estaba buscando datos de códigos de países inexistentes.
Las API externas tienen la mala costumbre de fallar en los momentos más inconvenientes. Y la API del FMI no es una excepción. A veces no está disponible durante varias horas, a veces retorna datos incompletos y, a veces, incluso devuelve un error sin motivo aparente.
Decidí construir un sistema de respaldo de datos desde el principio:
self.fallback_market_rates = {
'EURUSD': 1.0850, 'GBPUSD': 1.2650, 'USDJPY': 148.50,
'AUDUSD': 0.6750, 'USDCAD': 1.3550, 'USDCHF': 0.8850,
'NZDUSD': 0.6150
}
self.price_levels_2024 = {
'US': 100.0, # Basic level
'U2': 88.5, # Eurozone is 11.5% cheaper than the US
'GB': 85.2, # UK
'JP': 67.4, # Japan is significantly cheaper
'AU': 95.8, # Australia is close to the USA
'CA': 91.3, # Canada is moderately cheaper
'CH': 125.6, # Switzerland is the most expensive
'NZ': 89.7 # New Zealand
}
Estos datos se basan en las últimas comparaciones de precios internacionales disponibles y en las tipos de cambio actuales del mercado en el momento que escribo este artículo. No están perfectamente actualizados, pero son lo suficientemente precisos para que el sistema funcione de forma autónoma.
Algunos dirán que es solo un parche. Considero que ésta es una arquitectura reflexiva. En finanzas, la confiabilidad es más importante que una precisión ideal. Resulta mejor tener un resultado aproximadamente correcto que ningún resultado.
Para el método del PIB implícito, necesitaba estimaciones del PIB de distintos países en dólares estadounidenses. Parecería una tarea sencilla: bastaba con tomar los datos del Banco Mundial y listo. Pero aquí también se ocultaban algunos peligros.
El Banco Mundial publica el PIB en dólares corrientes (a tipos de mercado) y en dólares a paridad de poder adquisitivo (PPA). Para nuestro propósito, se necesitan precisamente dólares de mercado porque los estamos comparando con el PIB en divisa nacional de las estadísticas del FMI.
self.gdp_usd_estimates_2023 = {
'US': 27000, # USD 27 trillion
'U2': 17500, # Eurozone ~USD 17.5 trillion
'GB': 3300, # UK ~USD 3.3 trillion
'JP': 4200, # Japan ~USD 4.2 trillion
'AU': 1700, # Australia ~USD 1.7 trillion
'CA': 2100, # Canada ~USD 2.1 trillion
'CH': 900, # Switzerland ~USD 0.9 trillion
'NZ': 250 # New Zealand ~USD 0.25 trillion
}
El método ajustado por inflación requería un punto de referencia —tipos de cambio históricos— a partir del cual calcular el ajuste por inflación. Elegí 2020 por varios motivos.
En primer lugar, es lo suficientemente reciente como para ser relevante. En segundo lugar, 2020 fue antes de la pandemia y de las medidas de política monetaria extremas vinculadas a ella. En tercer lugar, los datos de 2020 ya están elaborados y no están siendo revisados por los servicios estadísticos.
self.base_rates_2020 = {
'U2': 0.85, # EURUSD
'GB': 0.78, # GBPUSD
'JP': 106.0, # USDJPY
'AU': 1.45, # AUDUSD
'CA': 1.34, # USDCAD
'CH': 0.92, # USDCHF
'NZ': 1.52 # NZDUSD
}
Los tipos se toman como valores promedio de 2020 para suavizar la volatilidad de corto plazo. Y esto es importante porque el método ajustado a la inflación supone que la tasa base era “justa” en el punto de partida.
Dificultades para trabajar con la API del FMI
La parte más ingrata (pero a la vez de vital importancia) de cualquier proyecto financiero es trabajar con fuentes de datos externas. La API del FMI es potente e informativa, pero tiene peculiaridades que requirieron ciertas pruebas y errores para aprender.
Lo primero que encontramos fue que a la API no le gustan las solicitudes grandes. Si intentamos solicitar varios indicadores para varios países a la vez, el servidor responde con un error o un tiempo de espera. Así que debíamos implementar la división de solicitudes en partes pequeñas.
def fetch_all_available_data(self, countries: List[str], years: int = 10): all_indicators = [ 'NGDP_XDC', # GDP in national currency 'NGDP_USD', # GDP in USD 'PCPIPCH', # Inflation rate 'NGDP_RPCH', # Real GDP growth 'ENDA_XDC_USD_RATE', # Exchange rate 'PCPI_IX', # Consumer Price Index 'LP' # Population ] chunk_size = 5 # Maximum 5 indicators per request for i in range(0, len(all_indicators), chunk_size): chunk = all_indicators[i:i + chunk_size] countries_string = '+'.join(countries) indicators_string = '+'.join(chunk) url = f"{self.base_url}/CompactData/IFS/A.{countries_string}.{indicators_string}"
Seleccionamos el tamaño del fragmento empíricamente. 3 indicadores son demasiado conservadores, hay que hacer muchas solicitudes. 7-8 indicadores a menudo provocan timeouts. El número 5 resultó un compromiso óptimo.
La API del FMI a veces se comporta de manera impredecible. Las mismas solicitudes pueden tener éxito por la mañana y fracasar por la noche. A veces el servidor retorna datos parciales sin previo aviso. A veces los datos llegan en un formato inesperado.
He añadido un amplio sistema de gestión de errores con registro:
try: response = self.session.get(url, params={ 'startPeriod': str(start_year), 'endPeriod': str(end_year) }, timeout=60) if response.status_code == 200: raw_data = response.json() df_chunk = self._parse_response_data(raw_data) if not df_chunk.empty: all_data.append(df_chunk) logger.info(f"Chunk {i//chunk_size + 1}: {len(df_chunk)} data points loaded") else: logger.warning(f"Chunk {i//chunk_size + 1}: empty response") else: logger.error(f"HTTP {response.status_code}: {response.text}") except requests.exceptions.Timeout: logger.warning(f"Timeout for chunk {i//chunk_size + 1}") except requests.exceptions.RequestException as e: logger.error(f"Request failed for chunk {i//chunk_size + 1}: {e}") except Exception as e: logger.error(f"Unexpected error in chunk {i//chunk_size + 1}: {e}") continue
Sin un registro tan detallado, la depuración resultaría infernal. Cuando una solicitud falla, debemos comprender en qué etapa ocurrió y por qué.
Mención especial merece el formato de respuesta de la API del FMI. Usan SDMX-JSON, un formato "estándar" para intercambiar datos estadísticos. En la práctica, esto resultó bastante incómodo.
def _parse_response_data(self, data: Dict) -> pd.DataFrame: records = [] try: compact_data = data['CompactData'] dataset = compact_data['DataSet'] if 'Series' not in dataset: return pd.DataFrame() series_list = dataset['Series'] # API can return a single series as an object or an array of series as a list if not isinstance(series_list, list): series_list = [series_list] for series in series_list: # All attributes are marked with the '@' symbol - this needs to be processed series_attrs = {k.replace('@', ''): v for k, v in series.items() if k.startswith('@')} obs_list = series.get('Obs', []) if not isinstance(obs_list, list): obs_list = [obs_list] for obs in obs_list: if isinstance(obs, dict): record = series_attrs.copy() record.update({ 'year': obs.get('@TIME_PERIOD', ''), 'value': obs.get('@OBS_VALUE', ''), 'status': obs.get('@OBS_STATUS', '') }) records.append(record) df = pd.DataFrame(records) if 'value' in df.columns: df['value'] = pd.to_numeric(df['value'], errors='coerce') if 'year' in df.columns: df['year'] = pd.to_numeric(df['year'], errors='coerce') return df except Exception as e: logger.error(f"Error parsing SDMX-JSON response: {e}") return pd.DataFrame()
Todos los atributos en SDMX-JSON están marcados con el símbolo '@', lo cual crea inconvenientes al trabajar con datos. Además, la API puede retornar una serie de datos como un objeto o varias series como un array: esto también debe procesarse.
Otro problema: a veces la API devuelve datos sin la sección 'Obs', a veces con 'Obs' vacía, a veces 'Obs' no contiene una lista, sino un solo objeto. Cada caso requiere un procesamiento separado.
Si no disponemos de datos de inflación actualizados, podemos utilizar valores típicos para cada país:
def _approximate_inflation_adjustment(self) -> Dict: logger.info("Using approximate inflation adjustment...") # Typical inflation rates 2020-2024 (based on historical data) typical_inflation = { 'US': 4.5, # US: Relatively high inflation due to stimulus 'U2': 3.8, # Eurozone: Moderate inflation 'GB': 4.2, # UK: Brexit + energy crisis 'JP': 1.8, # Japan: Traditionally low inflation 'AU': 4.1, # Australia: Commodity inflation 'CA': 3.9, # Canada: close to the US 'CH': 2.1, # Switzerland: Low inflation 'NZ': 4.0 # New Zealand: Moderate inflation } inflation_adjusted = {} for country, base_rate in self.base_rates_2020.items(): us_inflation = typical_inflation.get('US', 4.5) country_inflation = typical_inflation.get(country, 3.5) inflation_differential = us_inflation - country_inflation adjustment_factor = 1 + (inflation_differential / 100) adjusted_rate = base_rate * adjustment_factor inflation_adjusted[country] = { 'inflation_adjusted_rate': adjusted_rate, 'base_rate_2020': base_rate, 'inflation_differential': inflation_differential, 'method': 'approximate_inflation' } logger.info(f"{country}: Approx inflation diff {inflation_differential:+.2f}pp") return inflation_adjusted
Así, recopilé estas cifras de varias fuentes y las promedié durante el periodo 2020-2024. No son perfectamente precisos, pero ofrecen una aproximación razonable para los países con datos faltantes.
Convertimos los tipos de cambio justos en dinero real
Calcular los tipos justos es solo la mitad de la batalla. Lo principal es entender qué hacer con ellos. ¿Cómo convertir los cálculos académicos en señales comerciales prácticas?
def calculate_ppp_fair_values(self, currency_pairs: List[str]) -> Dict: logger.info("Starting manual PPP fair value calculation...") # Determine which countries we need countries = set() for pair in currency_pairs: base_currency = pair[:3] quote_currency = pair[3:] base_country = self.currency_country_map.get(base_currency) quote_country = self.currency_country_map.get(quote_currency) if base_country and quote_country: countries.add(base_country) countries.add(quote_country) logger.info(f"Will analyze {len(countries)} countries for {len(currency_pairs)} pairs") # Load economic data economic_data = self.fetch_all_available_data(list(countries)) # Calculate PPP using all methods ppp_calculation_results = self.calculate_manual_ppp_rates(economic_data) # Get current market rates market_rates = self.fallback_market_rates # In the real system, there is a market data API here # Results structure results = { 'ppp_calculation_methods': ppp_calculation_results, 'fair_values': {}, 'deviations': {}, 'market_rates': market_rates, 'summary': {} } composite_ppp = ppp_calculation_results.get('composite_ppp_rates', {}) # Calculate fair rates and deviations for each pair for pair in currency_pairs: base_currency = pair[:3] quote_currency = pair[3:] base_country = self.currency_country_map.get(base_currency) quote_country = self.currency_country_map.get(quote_currency) if not base_country or not quote_country: logger.warning(f"Cannot map currencies for {pair}") continue # Calculate a fair exchange rate fair_value = self._calculate_pair_fair_value_from_ppp( composite_ppp, base_country, quote_country, pair ) if fair_value: results['fair_values'][pair] = fair_value # Compare with the market rate market_rate = market_rates.get(pair) if market_rate and fair_value.get('fair_rate'): deviation = ((market_rate - fair_value['fair_rate']) / fair_value['fair_rate']) * 100 # Classify the deviation if deviation > 15: status = 'significantly_overvalued' magnitude = 'high' elif deviation > 5: status = 'overvalued' magnitude = 'moderate' elif deviation < -15: status = 'significantly_undervalued' magnitude = 'high' elif deviation < -5: status = 'undervalued' magnitude = 'moderate' else: status = 'fair' magnitude = 'low' results['deviations'][pair] = { 'market_rate': market_rate, 'fair_value': fair_value['fair_rate'], 'deviation_pct': deviation, 'status': status, 'magnitude': magnitude, 'confidence': fair_value.get('confidence', 0.5), 'signal_strength': abs(deviation) * fair_value.get('confidence', 0.5) } logger.info(f"{pair}: Market {market_rate:.4f}, Fair {fair_value['fair_rate']:.4f}, " f"Deviation {deviation:+.1f}% ({status})") # Generate summary statistics results['summary'] = self._generate_summary(results['deviations']) return resultsLa parte complicada consiste en calcular correctamente el tipo de cambio justo para un par de divisas basándose en los tipos de PPA de cada país:
def _calculate_pair_fair_value_from_ppp(self, composite_ppp: Dict, base_country: str, quote_country: str, pair: str) -> Dict: """Calculate the fair exchange rate for a currency pair using composite PPP data""" base_ppp = composite_ppp.get(base_country, {}) quote_ppp = composite_ppp.get(quote_country, {}) # Case 1: One of the currencies is USD (PPP base currency) if quote_country == 'US': # XXXUSD type pairs if base_ppp: fair_rate = base_ppp['composite_ppp_rate'] confidence = base_ppp['confidence'] else: return {} elif base_country == 'US': # USDXXX type pairs if quote_ppp: fair_rate = quote_ppp['composite_ppp_rate'] confidence = quote_ppp['confidence'] else: return {} else: # Case 2: Cross pairs (without USD) if base_ppp and quote_ppp: # For cross-pairs: PPP_base / PPP_quote fair_rate = base_ppp['composite_ppp_rate'] / quote_ppp['composite_ppp_rate'] # Confidence - the minimum of two currencies confidence = min(base_ppp['confidence'], quote_ppp['confidence']) else: return {} return { 'pair': pair, 'fair_rate': fair_rate, 'confidence': confidence, 'base_country': base_country, 'quote_country': quote_country, 'base_ppp_data': base_ppp, 'quote_ppp_data': quote_ppp }
La lógica es la siguiente: si tenemos coeficientes de PPA para el euro (0,885) y la libra (0,852) en relación con el dólar, entonces el tipo de cambio justo EUR/GBP = 0,885 / 0,852 = 1,039.
Una simple comparación con los tipos de mercado muestra una desviación porcentual, pero para su aplicación práctica se necesita una clasificación:
# Classify the deviation if deviation > 15: status = 'significantly_overvalued' signal = 'STRONG_SELL' elif deviation > 5: status = 'overvalued' signal = 'SELL' elif deviation < -15: status = 'significantly_undervalued' signal = 'STRONG_BUY' elif deviation < -5: status = 'undervalued' signal = 'BUY' else: status = 'fair' signal = 'HOLD'
He elegido unos umbrales del 5% y del 15% empíricamente, probando con datos históricos. El 5% es la desviación mínima que debe considerarse una oportunidad comercial (desviaciones más pequeñas pueden ser simplemente ruido). El 15% ya es un desequilibrio grave que demanda atención.
Una innovación importante es el cálculo de la intensidad de la señal como producto del valor de desviación y el índice de confianza:
'signal_strength': abs(deviation) * fair_value.get('confidence', 0.5)
Esto nos permite clasificar las oportunidades comerciales. Una señal con una desviación del 20% y una confianza del 50% (fuerza = 10) resulta menos atractiva que una señal con una desviación del 15% y una confianza del 80% (fuerza = 12).
El problema más común es la falta de datos. Suiza tiene datos sobre el PIB, pero no sobre la inflación. Nueva Zelanda tiene inflación pero no datos actualizados del PIB. Y así sucesivamente.
Inicialmente, probé simplemente a excluir a los países con datos incompletos, pero esto resultó ineficaz: casi todos los países habrían sido excluidos. En lugar de ello, implementé una graceful degradation:
# Each method works independently methods_results = { 'method_1': self._calculate_price_level_ppp(), 'method_2': self._calculate_gdp_implied_ppp(economic_data), 'method_3': self._calculate_inflation_adjusted_ppp(economic_data), 'method_4': self._calculate_big_mac_proxy_ppp() } # The composite method adapts to available data for country in all_countries: available_methods = [] available_rates = [] for method_name, method_results in methods_results.items(): if country in method_results: available_methods.append(method_name) available_rates.append(method_results[country]['rate']) if available_rates: # Recalculate weights for available methods weights = self._get_adjusted_weights(available_methods) composite_rate = sum(rate * weight for rate, weight in zip(available_rates, weights))
Resultados obtenidos
Tras varios meses de desarrollo y depuración, el sistema finalmente funcionó de manera estable. Entonces llegó el momento de la parte más interesante: la aplicación práctica.
Un análisis del gráfico de los precios reales del euro frente a los precios PPA muestra que con mucha frecuencia los cambios en el tipo de cambio PPA preceden a los cambios reales en el tipo de cambio real:
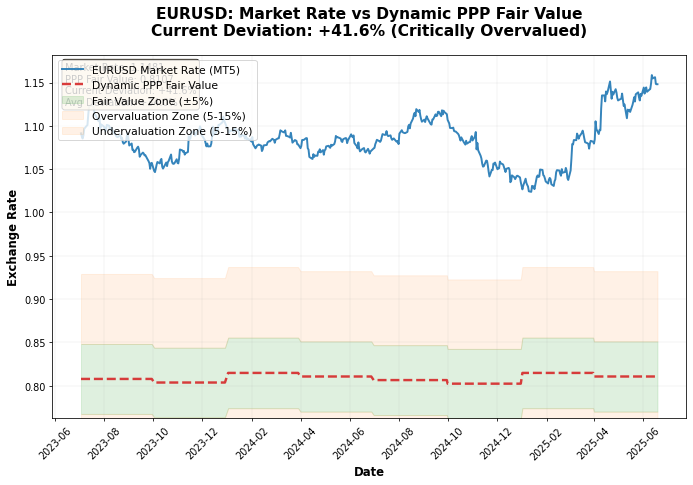
Al ejecutar el sistema con datos de 2024, se obtienen algunos resultados interesantes:
- EURUSD: tipo de cambio justo 0,8753, tipo de cambio de mercado 1,0850 → el euro está sobrevalorado
- GBPUSD: tipo de cambio justo 0,8288, tipo de cambio de mercado 1,2650 → la libra está sobrevalorada
- USDJPY: tipo de cambio justo 136,20, tipo de cambio de mercado 148,50 → el yen está infravalorado
- USDCHF: tipo de cambio justo 1,150, tipo de cambio de mercado 0,8850 → el franco está sobrevalorado
El resultado más interesante fue para el yen. Los cuatro métodos demostraron unánimemente que, con un tipo de cambio de 148+, el yen está gravemente infravalorado. La puntuación de confianza fue 0,85, una de las más altas.
No creé un sistema de trading independiente basado en PPA. En lugar de ello, he integrado cálculos con algoritmos existentes como un filtro adicional.
La lógica es simple: si un sistema técnico da una señal para comprar una divisa que está significativamente sobrevaluada en términos de PPP, el tamaño de la posición se reducirá o se ignorará la señal. Y viceversa, las señales en dirección del desequilibrio del PPA se fortalecerán.
Planes futuros para el desarrollo del sistema
La versión actual del sistema es solo el comienzo.
Estoy planeando varias direcciones de desarrollo. El aprendizaje automático ayudará a ajustar dinámicamente los pesos de los métodos según la precisión histórica y las condiciones actuales. Las fuentes de datos alternativas incluirán datos de la OCDE, índices del costo de vida, precios reales del Big Mac, datos satelitales y sentimiento social. La expansión para incluir criptodivisas, materias primas, acciones y bonos abrirá nuevas posibilidades. El comercio automatizado con cobertura dinámica e integración con APIs de corretaje harán que el sistema sea completamente independiente. La monitorización en tiempo real mediante un panel web completará el panorama.
Lo que he aprendido sobre PPA y los mercados de divisas
Unos pocos meses de trabajo en este proyecto me han dado más conocimientos sobre los mercados de divisas que años de análisis técnico. El PPA funciona, pero no como esperaba.
Es una brújula que nos guía a largo plazo, no una fórmula mágica para enriquecernos rápidamente. Las desviaciones se corrigen a lo largo de meses y años, no de días y semanas. La calidad de los datos es fundamental: en su momento dediqué más tiempo a buscar y validar datos que a los algoritmos.
La simplicidad supera a la complejidad: cinco métodos simples funcionan mejor que cualquier red neuronal. El trading con PPA requiere paciencia, algo que la mayoría de los tráders no tienen. El análisis fundamental ofrece un vínculo con la realidad económica en la era del trading algorítmico. El código es solo una herramienta para resolver un problema real.
Resultados y conclusiones
El proyecto comenzó por simple curiosidad: ¿es posible calcular tipos de cambio justos de forma independiente? Y terminó con la creación de un sistema de análisis completo que ayuda a tomar decisiones comerciales más informadas.
El viaje desde la idea hasta el código funcional tomó varios meses, cientos de horas de estudio de teoría económica, docenas de iteraciones de algoritmos e incontables horas de depuración, pero el resultado valió la pena.
Lo más importante que me di cuenta es que no hay necesidad de reinventar la rueda ni buscar la complejidad porque sí. A veces el mejor algoritmo es un clásico bien implementado. La paridad de poder adquisitivo funcionaba hace 500 años, funciona ahora y funcionará en el futuro. Solo hay que saber usarla correctamente.
El código fuente completo del sistema está disponible como proyecto de código abierto. Acepto las contribuciones de la comunidad como nuevas fuentes de datos, métodos alternativos de cálculo de PPA, mejoras en el procesamiento de errores, integración con APIs de corretaje y pruebas retrospectivas de datos históricos. Si le interesa el trading de divisas o el análisis cuantitativo, pruebe este sistema: podría cambiar su forma de ver los mercados.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18455
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Características del Wizard MQL5 que debe conocer (Parte 64): Uso de los patrones de DeMarker y los canales de envolvente con el núcleo de ruido blanco
Características del Wizard MQL5 que debe conocer (Parte 64): Uso de los patrones de DeMarker y los canales de envolvente con el núcleo de ruido blanco
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso