
Redes neuronales en el trading: Extracción eficiente de características para una clasificación precisa (Mantis)

Introducción
En un mundo donde los milisegundos y las más mínimas fluctuaciones de precios son cruciales, los tráderes buscan herramientas que no solo puedan predecir movimientos futuros, sino también clasificar con precisión patrones gráficos complejos. En este contexto, el modelo fundacional (foundation) de Mantis propuesto en el artículo "Mantis: Lightweight Calibrated Foundation Model for User-Friendly Time Series Classification", abre una nueva página en el análisis de series temporales. Con su diseño ligero, arquitectura sofisticada y calibración superior, Mantis permite una rápida integración del clasificador en los sistemas comerciales y la generación de intervalos de confianza fiables para la gestión de riesgos.
Los autores señalan que los enfoques clásicos entrenados para predecir valores posteriores con frecuencia resultan demasiado inertes: requieren una reconfiguración cuidadosa para cada nueva estrategia y los grandes saltos en la volatilidad pueden distorsionar significativamente su desempeño. En los últimos años, los modelos fundacionales para la predicción de series temporales han mostrado resultados impresionantes, pero, en esencia, están diseñados para la regresión más que para la clasificación de modos de mercado. Fue este vacío el que los autores del framework llenaron al proponer el framework Mantis con un preentrenamiento contrastivo.
La idea es simple y elegante: dividir la serie temporal en una serie de parches y luego, como el Vision Transformer en la visión por computadora, aplicar la atención multifacética. Al mismo tiempo, el mecanismo clásico de atención global es cuadrático en cuanto a complejidad, lo que se convierte en un cuello de botella para los datos de alta frecuencia. Para mitigar este efecto, Mantis utiliza simultáneamente tokens locales (obtenidos a través de convoluciones y pooling en ventanas pequeñas) y tokens globales (que acumulan información sobre las tendencias durante todo el periodo). Esta combinación proporciona una escalabilidad casi lineal a lo largo de la serie y conserva la capacidad de captar tanto pequeñas fluctuaciones como patrones a largo plazo.
El entrenamiento previo contrastante en Mantis se ha convertido en la salsa secreta que acerca diferentes aumentos del mismo fragmento temporal mientras repele series temporales radicalmente diferentes. Como resultado, las incorporaciones del mismo patrón con diferentes variaciones se unen en el espacio, mientras que los eventos diferentes divergen. Esta estrategia permite que el modelo aprenda características estables de distintos patrones, incluso aunque los picos y valles puedan cambiar en amplitud y tiempo.
El aspecto más importante para un tráder es evaluar la seguridad de la apertura de una posición: no basta con decir simplemente "esto es un cambio de tendencia"; es necesario entender qué tan seguro está el modelo en su conclusión. Mantis resuelve este problema con un módulo de escala de temperatura incorporado: ajusta los logits de salida para que las probabilidades posteriores reflejen verdaderamente la frecuencia de la clase. Debido a ello, cuando se selecciona la marca de "80% de probabilidad de reversión", el tráder puede esperar que la señal será correcta aproximadamente cuatro de cada cinco veces.
Los autores también prestan especial atención al análisis multimodal: el trading algorítmico a menudo usa docenas de indicadores simultáneamente (medias móviles, RSI, volúmenes, correlaciones de pares de divisas, etc.). La simple combinación de todos los canales en uno de alta dimensionalidad implica un aumento explosivo del número de parámetros, así como de los requisitos de memoria, mientras que el análisis univariante nos priva de información sobre las dependencias entre canales. Por consiguiente, los autores del framework incorporan adaptadores livianos que comprimen las interacciones entre canales en un espacio compacto sin perder información sobre las relaciones entre diferentes indicadores.
Para ilustrar la utilidad práctica de Mantis, imaginemos un escenario de "caída repentina" en el mercado de criptomonedas: el precio cae varios puntos porcentuales en cuestión de un segundo y luego se recupera con la misma rapidez. El modelo clásico puede percibir esta anomalía como ruido e ignorar la señal de entrada. Mantis, preentrenado con millones de ejemplos reales y sintéticos, entiende que tales eventos pueden ser “falsos” o “verdaderos”: así, emite una etiqueta de “anomalía de corto plazo” o “reversión verdadera” con diferentes intervalos de confianza, lo que permite al tráder desarrollar una estrategia adecuada de protección de capital.
Otro caso actual es la clasificación de los modos de mercado para las acciones tecnológicas. Durante la fase de crecimiento, los precios se mueven casi sincrónicamente según el contexto general de las noticias, pero durante la fase de corrección, cada activo se comporta de manera diferente. Mantis, gracias a los adaptadores, capta estas discrepancias entre canales: la baja correlación entre activos similares se convierte en una señal del comienzo de un ciclo correctivo, sobre el cual el modelo notifica con una estimación de confianza.
El algoritmo Mantis
El framework Mantis demuestra cómo una arquitectura reflexiva y un entrenamiento cuidadoso pueden convertir un conjunto de ideas en una herramienta sólida. El enfoque presentado por los autores del framework foundation se basa en cuatro pilares clave: tokenización de series temporales, atención híbrida, adaptadores de multidimensionalidad y preentrenamiento contrastivo autosupervisado con calibración posterior.
La idea principal de Mantis consiste en abandonar la partición tradicional de series temporales en ventanas fijas. En su lugar, se usa una partición en un número fijo de parches, lo que garantiza la independencia de la longitud de la secuencia de entrada y estabiliza los costos computacionales. Por ejemplo, las series de longitud 1024 y 2048 se convertirán en la misma cantidad de parches: 32. Este enfoque resulta fundamental para el procesamiento a gran escala de series temporales heterogéneas.
La formación de la incorporación se realiza en varias etapas. En primer lugar, se aplica una capa convolucional con 256 canales de salida. Esta capa transforma la serie temporal en una representación espacial más compacta. Luego, cada uno de los 32 parches se agrega usando la operación de promediación (mean pooling), lo que da como resultado un tensor de dimensionalidad (32, 256). Cada parche codifica características locales de la serie temporal, incluidos los picos, las oscilaciones y la microestructura del movimiento de precios.
Paralelamente se crea un segundo flujo de datos: el diferencial. Este se construye usando como base las diferencias de primer orden entre valores adyacentes de la serie temporal. Esta transformación ayuda a eliminar las tendencias de largo plazo y fortalecer las señales relacionadas con la dinámica de corto plazo. Resulta especialmente útil en situaciones donde las desviaciones de un nivel estable o movimientos bruscos cerca de los niveles de soporte y resistencia son de interés.
Ambos flujos pasan por el mismo procedimiento de procesamiento: convolución, promediado y normalización. El resultado son dos conjuntos de parches, cada uno de los cuales contiene 32 tokens con un tamaño de 256. Esto proporciona al modelo información igualitaria tanto sobre la forma de la señal como sobre sus cambios a lo largo del tiempo.
Además, se extraen dos tipos más de información: la escala y la volatilidad. Para ello, la serie temporal se divide en 32 ventanas iguales, en cada una de las cuales se calcula el valor medio y la desviación estándar. Estas estadísticas se codifican usando un Multi-Scaled Scalar Encoder que permite que el modelo comprenda las características de fondo de la señal. De esta forma, el modelo recibe cuatro flujos a la vez: los valores normalizados, los diferenciales, los valores medios y las desviaciones estándar.
Los cuatro flujos de datos resultantes se combinan mediante concatenación. Antes de esto, pasan por proyectores lineales individuales para igualar las dimensionalidades. Luego, las incorporaciones combinadas pasan a través de una capa de proyección seguida de una Layer Normalization, lo cual forma una representación final de la serie temporal como 32 tokens de dimensionalidad 256. Estos tokens son contenedores universales que contienen información estadística y de comportamiento sobre el mercado.
El siguiente paso en la arquitectura consiste en agregar un token de clase, un vector entrenable encargado de agregar la información de todos los tokens. Esto permite que el modelo forme una representación final de la serie considerando patrones tanto locales como globales. Para preservar la información del orden de los parches, se aplica una codificación de posición sinusoidal, después de lo cual los datos se envían al bloque del Transformer.
El transformer incluye 6 capas. Cada capa contiene una Multi-Head Attention de 8 cabezas, una capa de normalización y un bloque Feed-Forward de dos capas con activación GELU. Durante la etapa de preentrenamiento, se aplica un dropout con una probabilidad del 10%, lo que ayuda a evitar el sobreajuste. Después de pasar por todas las capas, se usa el vector de salida del token de clase, que forma la incorporación final de la secuencia.
Mantis está entrenado en un paradigma Self-Supervised utilizando aprendizaje contrastivo. El modelo aplica múltiples aumentos a la serie temporal de los datos de origen. En particular, el método RandomCropResize elimina aleatoriamente entre el 0 y el 20% de la secuencia y estira la parte restante hasta su longitud original. Esto mantiene la estructura general de la señal sin alterar el orden de los eventos.
Para cada ejemplo xi se seleccionan aleatoriamente dos aumentos del lote. Las representaciones resultantes pasan a través de la cabeza de proyección y se comparan utilizando la similitud de coseno.
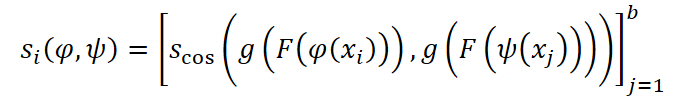
Después de lo cual se calcula la función de pérdida de entropía cruzada.
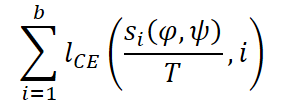
Los autores del framework realizaron un entrenamiento preliminar del modelo en una muestra combinada de 10 conjuntos de datos, que comprenden más de 7 millones de series temporales. El entrenamiento duró 100 épocas. Se utilizaron el lote 2048 y cuatro GPU Tesla V100-32GB.
En la etapa de ajuste fino se conectó una cabeza de clasificación a la incorporación. Los valores predichos obtenidos se someten a una calibración de temperatura (temperature scaling), lo que permite minimizar el error de calibración esperado e interpretar los resultados del modelo en forma probabilística.
No obstante, la naturaleza multivariante de las series temporales sigue siendo uno de los principales desafíos. Diferentes tareas pueden implicar un diferente número de canales, lo cual requiere la adaptación del modelo. Al igual que otros modelos fundamentales, Mantis se entrena de manera univariante y aplica el mismo mecanismo a cada canal. Esto no solo aumenta la carga de los recursos informáticos, sino que también ignora las correlaciones entre canales.
Para resolver estas limitaciones, los autores del framework proponen utilizar un adaptador de canal, que es una función a que transforma los d canales originales en d_new. Este enfoque nos permite adaptar los datos de origen al gasto computacional previsto, preservar la estructura temporal y garantizar la compatibilidad con cualquier modelo.
Aquí, los autores del framework Mantis consideran cinco opciones de adaptador. Los primeros cuatro son métodos clásicos de la reducción de dimensionalidad:
- PCA (Principal Component Analysis): encuentra un espacio ortogonal donde la varianza máxima se concentra en un número menor de componentes;
- Truncated SVD: similar al PCA, pero opera sobre la matriz no corregida;
- Random Projection: una proyección lineal aleatoria en un espacio de menor dimensionalidad;
- Variance-Based Selector: selecciona los canales más variables.
Los datos para estos adaptadores se dan en la forma (n*t, d), donde n es el número de ejemplos. La matriz requerida W implementa la proyección de los canales.
El quinto adaptador, el Differentiable Linear Combiner (LComb), se entrena junto con el modelo principal ajustando los parámetros durante la pasada inversa. Esto nos permite considerar el contexto de la tarea y lograr una mayor precisión.
Como resultado, Mantis se vuelve adecuado para una amplia gama de tareas sin perder la estructura temporal de los datos y las relaciones entre canales. El modelo sigue resultando versátil y productivo, incluso en escenarios multivariantes del mundo real.
A continuación le presentamos la visualización del autor del framework Mantis.

Implementación con MQL5
Tras un análisis exhaustivo de los aspectos teóricos del framework Mantis, es hora de pasar a la parte más interesante: su implementación práctica. Precisamente aquí, en las profundidades del código real, es donde las ideas toman forma y los principios abstractos comienzan a ser útiles. Nos centraremos en la implementación de software de las soluciones arquitectónicas clave del framework utilizando el lenguaje MQL5. A pesar de la alta complejidad de los conceptos, nos enfrentamos a un objetivo claro y ambicioso: construir un modelo que pueda procesar eficazmente datos reales del mercado, adaptarse a la volatilidad y, al mismo tiempo, seguir siendo lo más eficiente posible en cuanto al uso de recursos.
Discusión de enfoques
Antes de comenzar a escribir código, como es habitual en la práctica de ingeniería, debemos desarrollar una estrategia. Sin un plan claro, ninguna arquitectura puede soportar la presión del mercado real. Nuestro viaje comienza por la comprensión sistémica: qué queremos implementar exactamente, cuáles son los roles de los componentes individuales y dónde pueden estar los posibles cuellos de botella. Debemos no solo reescribir las ideas de los autores, sino adaptarlas a nuestra tarea y a las condiciones de MQL5, que tienen sus propias limitaciones y características.
La implementación se centra en la formación de los tokens. Aquí es donde se sientan las bases para el éxito futuro del modelo, ya que el Transformer no puede trabajar eficazmente con datos sin procesar. Este requiere datos de entrada en forma de secuencias de tokens, cada uno de los cuales lleva una representación comprimida pero expresiva de una sección de la serie temporal.
La arquitectura original de Mantis propone utilizar un diseño multicanal que incluye series de desviaciones, medias y desviaciones estándar de segmentos. Sin embargo, si las entradas están normalizadas (nuestros modelos trabajan precisamente con ellas con mayor frecuencia), el contenido de información de los flujos de media y desviación estándar disminuye. Nosotros vamos a renunciar deliberadamente a estos canales, apoyándonos en dos flujos clave: la serie temporal original y su primera diferencia. Esta combinación nos permite considerar simultáneamente los niveles globales y los cambios locales: una especie de compromiso entre estabilidad y sensibilidad.
El proceso de preparación de estos flujos comienza con la normalización de la serie temporal original. Este es un paso importante que ayuda a suavizar las fluctuaciones a gran escala y mejorar la resistencia del modelo ante valores atípicos. A continuación, aplicamos la operación de diferenciación, con cuya ayuda se calcula la diferencia entre observaciones adyacentes. La serie resultante se caracteriza por una mayor reacción a los cambios repentinos, lo cual resulta especialmente valioso cuando se intenta captar impulsos o reversiones del mercado. Después de ello, ambas series se combinan en un tensor con dos canales, donde cada canal representa un flujo de información separado.
Sin embargo, la unificación por sí sola no es suficiente. A pesar de la riqueza de la información contenida en las series temporales multicanal, el modelo muestra una carencia crítica de información sobre el contexto temporal. Los transformadores, como es bien sabido, no tienen una capacidad incorporada para comprender el orden de los elementos en la secuencia original y, por consiguiente, requieren información adicional que describa la ubicación de cada observación en relación con las demás.
La implementación original de Mantis resolvió este problema añadiendo codificación posicional sinusoidal, similar a lo propuesto en el artículo Attention is All You Need. Este enfoque resulta cómodo por su versatilidad y portabilidad: no requiere entrenamiento y funciona bien en tareas de diversa naturaleza. En este caso, la codificación se agrega después de que los canales se hayan combinado y segmentado en parches.
No obstante, nosotros proponemos un camino diferente. Antes de cortar la secuencia en fragmentos, introduciremos una codificación temporal, similar al framework Mamba4Cast. Esta codificación no solo denota la posición de un punto en una cuadrícula de tiempo, sino que también transmite información sobre la estructura temporal de la serie, lo cual permite que el modelo capture la estacionalidad oculta, los patrones repetitivos, las asimetrías y los ritmos en los datos del mercado. A diferencia de la codificación sinusoidal, la codificación temporal resulta más sensible a la microestructura del mercado y puede captar patrones que se extienden más allá de la ventana de análisis actual.
Solo después de añadir dicha codificación podemos pasar al siguiente paso lógico: la segmentación del canal. Este paso actúa como una especie de filtro que transforma la información temporalmente enriquecida en un formato cómodo para el modelo. En otras palabras, en este punto los datos ya tienen no solo significado y derivado, sino también una capa adicional de contexto que revela su dinámica de comportamiento a lo largo del tiempo. Esto simplifica sustancialmente la tarea del modelo en cuanto a la identificación de dependencias complejas y hace que su funcionamiento sea más resistente al ruido del mercado.
Hablaremos de los cambios en el algoritmo de segmentación un poco más adelante, cuando lleguemos directamente a su implementación. Dejaremos deliberadamente de lado por ahora la descripción de los bloques restantes para centrarnos en la base: la transformación de una serie temporal en una secuencia informativa, estandarizada y estructurada. Precisamente en esta etapa es donde reside el éxito de todo el modelo. Los datos bien preparados permiten identificar patrones de manera efectiva, captar correctamente el orden de los eventos y discernir patrones importantes de comportamiento del mercado.
Ahora que hemos establecido el marco conceptual y hemos delineado la hoja de ruta, es hora de pasar de las palabras a la acción. En esta etapa comienza la implementación directa del modelo: el mismo momento en el que la teoría se transforma en líneas de código. Comenzaremos con la parte más básica y, a la vez, crucial: el preprocesamiento de series temporales, en cuya salida se forma una representación de datos multicanal. Aquí es donde se realiza la extracción de características inicial, que más tarde determinará lo que ve el Transformer y cómo lo interpreta. Nuestra tarea consiste en extraer dos flujos: la serie original y su primera diferencia, y luego combinarlas en un único tensor. Implementaremos todo esto usando OpenCL.
Cambios en el programa OpenCL
Usamos OpenCL porque necesitamos acelerar los cálculos, especialmente al trabajar con grandes cantidades de series temporales. Las GPU permiten paralelizar operaciones en múltiples variables y aceleran la preparación de datos sin sobrecargar el procesador principal. Entonces lo primero que haremos es implementar un kernel ConcatDiff especializado. Su tarea consiste en calcular simultáneamente la primera diferencia y concatenar el resultado obtenido con los datos de origen, formando así un tensor con dos canales para cada intervalo de tiempo.
Los parámetros de este kernel solo pasan dos punteros a los búferes de datos: un minimalismo que ha resistido la prueba del tiempo. El primero es el array de entrada data, que contiene las series temporales analizadas, y el segundo es el búfer de salida output, que almacena los resultados del cálculo. Este enfoque hace que la interfaz del kernel sea lo más simple y directa posible, eliminando sobrecarga innecesaria.
Un parámetro adicional es la constante step: el paso con el que se calcula la diferencia. Esta innovación amplía significativamente la versatilidad del algoritmo. Ahora podemos calcular tanto la primera diferencia clásica (entre puntos adyacentes) como, por ejemplo, la diferencia entre el valor “ahora” y “en cinco pasos”. Esto último puede resultar especialmente útil en un contexto financiero: dicho parámetro permite preparar características que reflejen los cambios con diferentes horizontes temporales.
__kernel void ConcatDiff(__global const float* data, __global float* output, const int step) { const size_t i = get_global_id(0); const size_t v = get_local_id(1); const size_t inputs = get_local_size(0); const size_t variables = get_local_size(1);
Cada flujo de operaciones recibe un par único de índices: un índice de tiempo i y un índice de secuencia unitario v. De esta forma, cada flujo es responsable de procesar un valor específico en la matriz de datos de origen.
El array de datos de origen data supone una serie de tiempo normalizada presentada en forma lineal, descompuesta por tiempo y canales.
A continuación, dentro del kernel, calculamos shift, el desplazamiento en el array data, que corresponde a la posición actual variable en el tiempo.
const int shift = i * variables; const float d = data[shift + v];
Una vez obtenida la variable original d, procederemos a calcular su primera diferencia a lo largo del eje temporal. Para ello tomaremos la diferencia entre el valor actual y el que se encuentra un número step de pasos más adelante. Este esquema tiene como objetivo preparar características objetivo que reflejen la dinámica local: crecimiento o caída, aceleración o desaceleración del cambio. En este caso, comprobamos necesariamente que el índice sea correcto: no debemos salir de los límites del array.
float diff = 0; if(step > 0 && (i + step) < inputs) diff = IsNaNOrInf(d - data[shift + step * variables + v], 0);
El cálculo de la diferencia se completa con la función de protección IsNaNOrInf, que restablece el resultado si aparecen NaN o infinitos; esto resulta especialmente importante si hay valores faltantes o errores en los datos.
Luego viene la etapa clave: la formación del array de salida output. Aquí tiene lugar una operación interesante: los datos se escriben en pares. Primero se escribe el valor original, seguido del valor correspondiente de la primera diferencia. Como utilizamos el doble de desplazamiento entre las variables (el doble de canales), el tensor resultante para cada punto temporal contiene dos valores por variable. De esta forma, la estructura output adquiere un tamaño (T * 2 * V), donde T es el número de pasos de tiempo y V es el número de variables.
output[2 * shift + v] = d; output[2 * shift + v + variables] = diff; }
Esta solución permite preparar los datos para introducirlos en el modelo en una sola pasada: el tensor ya contiene características del mercado tanto estáticas como dinámicas.
El uso de OpenCL en este caso proporciona un doble beneficio: ahorramos tiempo (debido al procesamiento paralelo) y simplificamos la lógica del código, ya que todo el trabajo con los índices y arrays se realiza dentro del kernel. En lugar de engorrosos ciclos del lado de la CPU, tenemos un bloque compacto y eficiente que se escala fácilmente a datos de cualquier longitud y anchura.
Este módulo se convierte en el primer ladrillo en la base de todo el modelo. Implementa la idea clave: la descomposición primaria de una serie temporal en dos flujos complementarios. Los valores originales nos permiten ver niveles y tendencias, mientras que la primera diferencia ofrece sensibilidad al cambio, una especie de derivada que señala puntos de inflexión. Juntos crean una representación equilibrada que resulta resistente al ruido y adaptable a los cambios rápidos.
Merece la pena destacar una característica constructiva de esta etapa: el kernel ConcatDiff no contiene ningún parámetro entrenable. Su tarea es puramente funcional: realizar operaciones lineales simples (extraer valores y sus diferencias) y combinar los resultados en un solo array. Todo esto lo hace especialmente adecuado para la implementación en el lado OpenCL, donde las operaciones de procesamiento paralelo masivo sin lógica de estado compleja son particularmente efectivas.
Además, los propios datos de origen, considerando las particularidades de las series temporales financieras, pueden considerarse lógicamente como constantes dentro de una iteración de preparación. Es por esto que, en este caso, no vamos a implementar kernels para la propagación inversa del gradiente de error o la actualización de parámetros. Estas tareas son relevantes solo para las capas de aprendizaje que forman el modelo. Aquí nos ocuparemos del preprocesamiento, una etapa en la que la velocidad, la fiabilidad y el determinismo completo de los cálculos son importantes.
El código completo del programa OpenCL se ofrece en el archivo adjunto.
Objeto de cálculo de diferencia
El siguiente paso en nuestro trabajo será integrar el kernel ConcatDiff en la estructura del programa principal. Para ello, vamos a crear un objeto especializado implementado como la clase CNeuronConcatDiff. Este objeto actúa como una interfaz entre la lógica del modelo de red neuronal de alto nivel y el código OpenCL de bajo nivel, responsable de la correcta preparación de los parámetros, el inicio del kernel y la obtención del resultado.
class CNeuronConcatDiff: public CNeuronBaseOCL { protected: uint iUnits; uint iVariables; uint iStep; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return true; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronConcatDiff(void) : iUnits(0), iVariables(1), iStep(1) { activation = None; } ~CNeuronConcatDiff(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units_count, uint step, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronConcatDiff; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; };
La clase en sí incluye varias variables clave:
- iUnits — número de pasos de tiempo,
- iVariables — cantidad de canales o variables en los datos de origen,
- iStep — parámetro de desplazamiento que especifica el paso para calcular la diferencia. Este valor hace que el componente sea universal: se puede adaptar a cualquier anchura de ventana temporal o frecuencia de muestreo.
El constructor de clase inicializa los parámetros clave de manera predeterminada: un canal (iVariables = 1), un paso igual a uno (iStep = 1) y la función de activación deshabilitada (activation = None), lo cual es lógico: después de todo, nuestro componente funciona en el nivel de preprocesamiento y no debería introducir no linealidad.
La clase también implementa el método de inicialización del objeto Init, cuyos parámetros contienen constantes que permiten interpretar de forma inequívoca la arquitectura del objeto creado.
bool CNeuronConcatDiff::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units_count, uint step, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, 2 * units_count * variables, optimization_type, batch)) return false; if(step<=0 || step >= units_count) return false; //--- iUnits = units_count; iVariables = variables; iStep = step; //--- return true; }
La lógica del método Init es lo más simple y concisa posible. En su cuerpo se llama a la función homónima de la clase padre, considerando las características de la estructura de datos. Como combinamos los datos de origen y los primeros valores de diferencia en el array de salida, el tamaño del búfer de salida deberá duplicarse.
Tras inicializar la parte padre, todos los parámetros recibidos como entrada se guardan en las variables internas de la clase. Esto nos permite usarlos al generar parámetros para el kernel OpenCL.
Este enfoque hace que el objeto sea flexible, independiente y reutilizable.
Se presta especial atención al método virtual feedForward, que es responsable de la pasada directa y, en consecuencia, de la llamada al kernel OpenCL.
En los parámetros del método, obtenemos el puntero al objeto de datos de origen y verificamos inmediatamente su relevancia.
bool CNeuronConcatDiff::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL || !Output) return false; if(getOutputIndex() < 0) return false;
Después de pasar con éxito el bloque de control, el kernel ConcatDiff se coloca a la cola de ejecución. Aquí se utiliza el algoritmo con el que ya estará familiarizado. Los valores previamente almacenados en las variables internas se usan para especificar la dimensionalidad del espacio del problema.
{
uint global_work_offset[2] = {0};
uint global_work_size[2] = {iUnits, iVariables};
const int kernel = def_k_ConcatDiff;
if(!OpenCL.SetArgumentBuffer(kernel, def_k_concdiff_data, NeuronOCL.getOutputIndex()))
{
printf("Error of set parameter kernel %s: %d; line %d", OpenCL.GetKernelName(kernel),
GetLastError(), __LINE__);
return false;
}
if(!OpenCL.SetArgumentBuffer(kernel, def_k_concdiff_output, getOutputIndex()))
{
printf("Error of set parameter kernel %s: %d; line %d", OpenCL.GetKernelName(kernel),
GetLastError(), __LINE__);
return false;
}
if(!OpenCL.SetArgument(kernel, def_k_concdiff_step, iStep))
{
printf("Error of set parameter kernel %s: %d; line %d", OpenCL.GetKernelName(kernel),
GetLastError(), __LINE__);
return false;
}
//---
if(!OpenCL.Execute(kernel, global_work_size.Size(), global_work_offset, global_work_size))
{
printf("Error of set parameter kernel %s: %d; line %d", OpenCL.GetKernelName(kernel),
GetLastError(), __LINE__);
return false;
}
}
Sin embargo, el trabajo del método feedForward no termina ahí. El siguiente paso será normalizar el tensor generado, es decir, llevar los datos a una única escala, lo cual resulta fundamental al entrenar una red neuronal. Además, aquí se implementa la normalización separada por características (se normalizan los valores originales de las variables) y diferencias (los valores de la primera diferencia se procesan por separado). Esto permite que el modelo conserve su sensibilidad a cambios repentinos en las series temporales sin perder su robustez ante fluctuaciones de gran escala.
{
uint global_work_offset[1] = {0};
uint global_work_size[1] = {2 * iUnits};
const int kernel = def_k_Normilize;
if(!OpenCL.SetArgumentBuffer(kernel, def_k_norm_buffer, getOutputIndex()))
{
printf("Error of set parameter kernel %s: %d; line %d", OpenCL.GetKernelName(kernel),
GetLastError(), __LINE__);
return false;
}
if(!OpenCL.SetArgument(kernel, def_k_norm_dimension, iVariables))
{
printf("Error of set parameter kernel %s: %d; line %d", OpenCL.GetKernelName(kernel),
GetLastError(), __LINE__);
return false;
}
if(!OpenCL.Execute(kernel, global_work_size.Size(), global_work_offset, global_work_size))
{
string error;
CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error);
printf("Error of execution kernel %s: %d -> %s", OpenCL.GetKernelName(kernel),
GetLastError(), error);
return false;
}
}
//---
return true;
}
Este tipo de posprocesamiento puede mejorar sustancialmente la estabilidad del entrenamiento y acelerar la convergencia del modelo al unificar el rango de valores de entrada.
Vale la pena decir algunas palabras sobre el método de distribución del gradiente de error: calcInputGradients. Aunque no creamos un kernel de pasada inversa para esta capa, aún se implementa el método correspondiente.
¿Para qué? La respuesta es sencilla: esto nos permite incorporar este objeto en cualquier nivel del modelo sin temor a romper la cadena de propagación inversa. Incluso si esta capa no necesita calcular sus propios gradientes, deberá pasar correctamente la señal de error hasta el nivel de los objetos anteriores. De lo contrario, el entrenamiento de todo el modelo podría interrumpirse en ese momento, lo que provocaría un estancamiento del flujo de gradiente y, como consecuencia, la imposibilidad de optimizar los parámetros de los niveles subyacentes.
El algoritmo del método es simple y fiable. Obtenemos el puntero al objeto de datos de origen (NeuronOCL) y verificamos inmediatamente su relevancia.
bool CNeuronConcatDiff::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Luego enviamos el gradiente de error a lo largo del flujo directo de propagación de los datos de origen, acumulado en el objeto actual, como una señal para la capa anterior. Este proceso es pura desconcatenación sin ninguna sofisticación computacional.
if(!DeConcat(NeuronOCL.getGradient(), getPrevOutput(), getGradient(), iVariables, iVariables, iUnits)) return false;
De ser necesario (dependiendo de la arquitectura), el gradiente de error se puede ajustar usando la derivada de la función de activación.
if(NeuronOCL.Activation() != None) if(!DeActivation(NeuronOCL.getOutput(), NeuronOCL.getGradient(), NeuronOCL.getGradient(), NeuronOCL.Activation())) return false; //--- return true; }
Este enfoque garantiza la compatibilidad y flexibilidad de la arquitectura. El objeto CNeuronConcatDiff no interfiere con la propagación del gradiente y se puede utilizar como parte de modelos complejos, tanto en niveles bajos (cerca de la entrada) como en lo profundo del gráfico computacional.
Con esto concluye nuestra discusión de los algoritmos para construir los métodos de la clase CNeuronConcatDiff. El código completo de esta clase y todos sus métodos se puede encontrar en el archivo adjunto.
Poco a poco hemos alcanzado el límite del artículo actual. A pesar de ello, la mayor parte del trabajo aún está por delante: solo hemos puesto las bases, pero la historia no termina aquí. Para evitar abrumar al lector y mantener la legibilidad, haremos una breve pausa y continuaremos con la implementación en el próximo artículo de esta serie. Allí nos espera una etapa igualmente interesante y técnicamente intensa.
Conclusión
En este artículo, nos hemos familiarizado con el framework Mantis, que combina ligereza y alta precisión. Los autores del framework propusieron un enfoque innovador para la generación de tokens basado en convolución y pooling de medias, que permite una representación eficiente de series temporales como 32 tokens de dimensionalidad 256, reduciendo los costos computacionales en comparación con los métodos tradicionales. El preentrenamiento contrastivo con ejemplos de diversos conjuntos de datos garantiza la obtención de representaciones de características sólidas y transferibles, superando a sus contrapartes zero-shot y fine-tuning y logrando un error de calibración récord.
La parte práctica presenta la implementación de una capa de preprocesamiento de datos clave utilizando OpenCL y MQL5, asegurando la preparación paralela y determinista de los tensores de entrada. En el próximo artículo continuaremos implementando nuestra propia visión de los enfoques propuestos por los autores del framework Mantis.
Enlaces
- Mantis: Lightweight Calibrated Foundation Model for User-Friendly Time Series Classification
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor experto para recopilar ejemplos con el método Real-ORL |
| 3 | StudyContrast.mq5 | Asesor | Asesor de aprendizaje contrastivo del Codificador |
| 4 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 5 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 6 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 7 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 8 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 9 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18246
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso