Ingeniería de características con Python y MQL5 (Parte IV): Reconocimiento de patrones de velas japonesas mediante regresión con UMAP

Los patrones de velas japonesas son ampliamente utilizados en muchas estrategias y estilos de negociación diferentes por la mayoría de los traders algorítmicos de nuestra comunidad. Sin embargo, nuestra comprensión de estos patrones se limita a las velas japonesas que hemos descubierto, cuando en realidad puede haber muchos otros patrones de velas japonesas rentables que simplemente aún desconocemos. Debido a la gran cantidad de información que abarca la mayoría de los mercados modernos, resulta muy difícil para los operadores tener la certeza de que siempre están utilizando los patrones de velas japonesas más fiables disponibles en el mercado elegido.
Para paliar este problema, propondremos una solución que potencialmente permita a nuestro modelo identificar nuevos patrones de velas japonesas que desconocíamos. El enfoque que proponemos se parece a un juego infantil con el que la mayoría de nosotros deberíamos estar familiarizados. El juego recibe diferentes nombres. Sin embargo, la premisa subyacente es la misma. El juego reta a los jugadores a describir un sustantivo utilizando adjetivos que no contengan dicho sustantivo. Por ejemplo, si el sustantivo dado fuera un plátano, el jugador que dirige el juego daría pistas a sus amigos que describan mejor el plátano, como "amarillo y curvado". Esto debería resultar intuitivo.
Este juego infantil es lógicamente idéntico a las tareas que le pediremos a nuestro modelo que realice para que podamos descubrir nuevos patrones de velas japonesas que de otro modo habrían permanecido ocultos debido a la gran cantidad de dimensiones que suelen tener nuestros conjuntos de datos en la actualidad. De forma análoga al juego que acabamos de describir, en el que se le pide al jugador que describa un plátano en 3 palabras o menos, proporcionaremos a nuestro modelo datos de mercado con 10 columnas que describen la vela actual y, a continuación, le pediremos que describa los datos de mercado originales en 8 columnas (embeddings) o menos. A este proceso lo conocemos como reducción de dimensionalidad.
Existen muchas técnicas bien conocidas de reducción de dimensionalidad con las que el lector probablemente ya esté familiarizado, como el Análisis de Componentes Principales (Principal Components Analysis, PCA). Estas técnicas son útiles porque guían a nuestro modelo para que se centre en el aspecto más significativo de los datos transformados. Hoy emplearemos una técnica conocida como Aproximación y Proyección de Variedades Uniformes (Uniform Manifold Approximation and Projection, UMAP). Se trata de un algoritmo reciente y, como el lector podrá comprobar en breve, nos puede resultar útil para poner de manifiesto, de una forma novedosa, las relaciones no lineales presentes en nuestros datos de mercado.
Nuestro objetivo es diseñar columnas en el conjunto de datos original que describan con precisión la vela actual. Al hacerlo, el algoritmo UMAP puede transformar nuestros datos, agrupar velas similares y describirlas en menos "palabras" (embeddings). Esto, a su vez, puede ayudar a nuestro modelo a reconocer patrones de velas japonesas que nos resultaban ocultos debido a la gran cantidad de dimensiones que necesitamos para describir cada vela con precisión.
Para comprobar la eficacia del algoritmo UMAP, entrenamos dos modelos estadísticos idénticos para pronosticar la evolución diaria del tipo de cambio EURGBP. El primer modelo fue entrenado con los datos de mercado originales en su formato original. En este ejemplo concreto, los datos de mercado originales tenían 10 dimensiones creadas directamente desde el mercado en nuestra terminal MetaTrader 5. Mediante el algoritmo UMAP, pudimos transformar los datos de mercado originales reduciéndolos a solo 3 dimensiones, lo cual fue suficiente para superar el error producido por los datos de mercado originales con los que comenzamos.
Por último, no consideraremos cómo implementar el algoritmo UMAP desde cero de forma nativa en MQL5. La razón es que el algoritmo es bastante sofisticado, y tratar de implementarlo con estabilidad numérica y eficiencia computacional no es una tarea trivial. Si el lector confía en que posee las habilidades necesarias en geometría analítica y topología algebraica, entonces puede seguir desarrollando su interés por implementar el algoritmo de forma nativa en MQL5. He incluido un enlace al artículo de investigación original, en el que se explican las especificaciones matemáticas exactas del algoritmo, aquí.
De lo contrario, para los lectores que no posean todas las habilidades numéricas necesarias, incluyéndome a mí, demostraremos cómo pueden sustituir la necesidad de implementar el algoritmo desde cero, utilizando en su lugar nuestras habilidades en aproximación de funciones.
¿Por qué UMAP?
Dado que existen tantas técnicas de reducción de dimensionalidad útiles y mejor conocidas, algunos lectores podrían preguntarse, naturalmente: "¿Por qué deberíamos estar interesados en aprender UMAP?". ¿De verdad necesito aprender a usar otra biblioteca más? Una de las principales ventajas de UMAP es que, a medida que aumenta el tamaño de nuestro conjunto de datos, el tiempo que tarda la biblioteca en transformar nuestros datos permanece prácticamente constante. Además, el algoritmo UMAP está especializado en revelar efectos no lineales en los datos, al tiempo que intenta preservar la estructura global original de los mismos. En otras palabras, esto significa que el algoritmo se esfuerza explícitamente por no distorsionar los datos ni crear artefactos engañosos que puedan introducir ruido adicional. Esto no suele ocurrir en la mayoría de los algoritmos de reducción de dimensionalidad.
El algoritmo UMAP es relativamente nuevo y la implementación que analizaremos hoy está construida utilizando Python y Numba. Numba es un compilador que convierte código Python en código máquina. Esta combinación de Python y código máquina nos permite experimentar una gran velocidad y cálculos numéricamente estables, incluso con grandes conjuntos de datos. Esta implementación específica del algoritmo UMAP fue diseñada por Leland McInnes et al. La biblioteca se publicó inicialmente en 2018.

Figura 1: Leland McInnes es uno de los autores principales del artículo de investigación UMAP y ayuda a mantener la biblioteca de Python.
No obstante, el lector debe tener en cuenta que estas características no pueden garantizarse si utiliza una implementación del algoritmo UMAP procedente de una biblioteca distinta a la que vamos a analizar hoy. Es de esperar que las distintas implementaciones de un mismo algoritmo difieran en sus propiedades numéricas.
Primeros pasos en MQL5
Para empezar, vamos a obtener datos cuantitativos que describan la vela actual. Queremos conocer la variación en los niveles de precios de apertura, máximo, mínimo y cierre que se ha producido durante un período determinado, denominado horizonte en este ejemplo. Además, buscamos medir la variación desde la apertura hasta el máximo, desde la apertura hasta el mínimo y desde la apertura hasta el cierre. Repetimos este cálculo de cambio para cada una de las 4 fuentes de precios que tenemos disponibles en nuestra terminal MetaTrader 5. Esto nos da un total de 10 columnas, excluyendo las dos primeras, Hora y Cierre Verdadero. Estas 10 columnas pueden describir eficazmente cualquier patrón de velas japonesas, como las velas Doji o los martillos. Sin embargo, nuestra técnica actual no será útil para identificar patrones de velas japonesas formados por más de una vela.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 24 //+------------------------------------------------------------------+ //| File name | //+------------------------------------------------------------------+ string file_name = Symbol() + " UMAP Candlestick Recognition.csv"; //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","True Close","Open","High","Low","Close","O - H","O - L","O - C","H - L","H - C","L - C"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON
Analizando los datos en Python
Nuestro objetivo es doble:
- Demostrar las ventajas de utilizar las transformaciones UMAP en lugar de utilizar los datos de precios en su formato original.
- Obtener una copia del algoritmo UMAP utilizando nuestras técnicas de aproximación de funciones, para que podamos realizar pruebas retrospectivas sobre la eficacia del algoritmo.
Vamos a ver las ventajas de usar UMAP en comparación con los datos de precios en su formato original para garantizar que nuestra motivación quede clara y que los beneficios sean evidentes para el lector. Tras demostrar las ventajas de emplear UMAP, utilizaremos las transformaciones que nos proporciona la biblioteca UMAP para entrenar nuestra primera red neuronal con el fin de estimar los embeddings UMAP de los datos de mercado proporcionados.
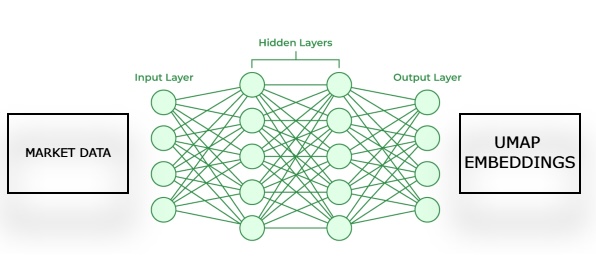
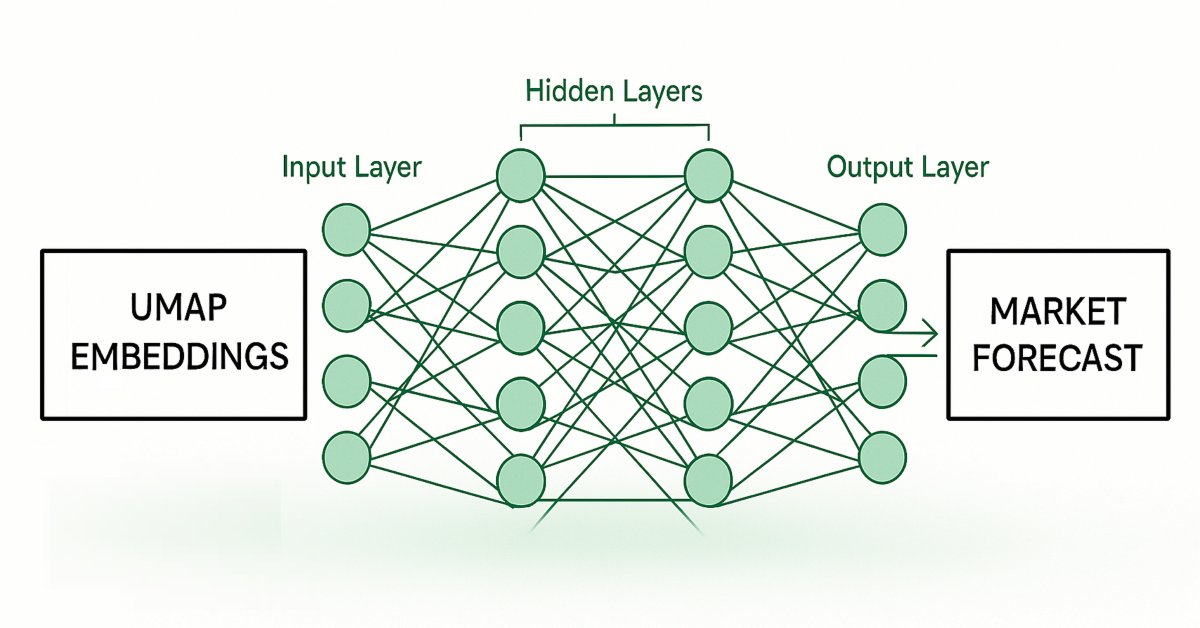
Figura 2: Visualización de nuestro enfoque para estimar los embeddings UMAP a partir de datos de mercado dados.
Posteriormente, entrenaremos un segundo modelo que aprende a pronosticar los movimientos futuros de los precios en el mercado, a partir de una estimación de sus embeddings UMAP obtenidas de nuestro primer modelo. Nuestro objetivo es que estos dos modelos estadísticos funcionen en cadena. El primer modelo estima los embeddings UMAP a partir de datos de mercado dados, y el segundo modelo toma el resultado del primer modelo para pronosticar los rendimientos futuros del mercado en el que operamos. Este sistema resultará ser considerablemente más rápido y posiblemente tan eficaz como haber implementado el algoritmo UMAP desde cero.
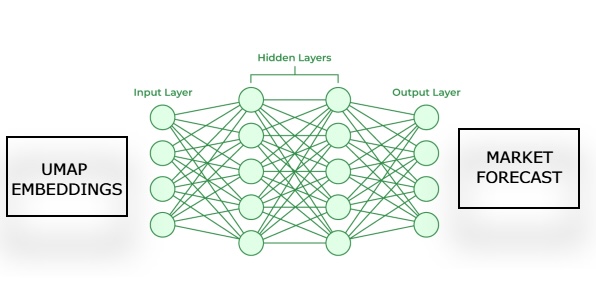
Figura 3: Visualización de nuestro enfoque para generar un pronóstico de mercado a partir de nuestros embeddings UMAP estimados
Ahora que hemos abordado nuestra motivación y la metodología que seguiremos, comencemos con Python. Comenzamos importando las bibliotecas que necesitamos. Si desea seguir las instrucciones, es posible que primero deba instalar la biblioteca UMAP en su sistema introduciendo el comando "pip install umap-learn".
import pandas as pd import numpy as np import matplotlib.pyplot as plt import umap import seaborn as sns
Posteriormente, si el lector está dispuesto a seguir las instrucciones, el siguiente paso que daremos será leer los datos de mercado que generamos utilizando nuestro script MQL5.
HORIZON = 24 data = pd.read_csv("..\EURGBP UMAP Candlestick Recognition.csv") data['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] data['Class'] = 0 data.loc[data['Target'] > 0,'Class'] = 1 data.dropna(inplace=True) data
Nuestros datos de mercado se han cargado correctamente, pero si observa la columna Time, verá que el archivo CSV incluye datos de mercado recientes. Queremos eliminar los datos de mercado de los últimos 5 años de nuestro archivo CSV, para que nuestra prueba retrospectiva (backtest) de la estrategia no se vea afectada por información filtrada que nuestro modelo no hubiera tenido en el pasado.
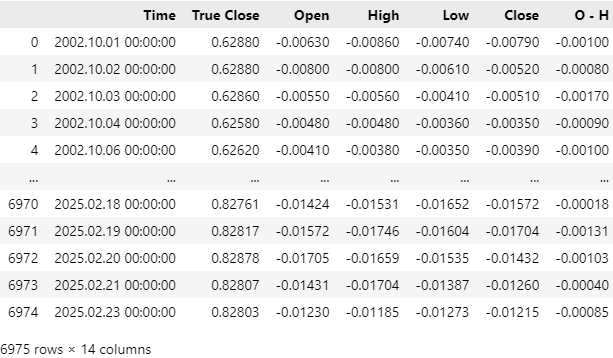
Figura 4: Nuestros datos históricos de mercado que obtuvimos utilizando nuestro script MQL5.
Extraemos los datos de mercado de los últimos 5 años de nuestro archivo CSV. Observe que nuestra última fecha en el archivo CSV es ahora el 16 de octubre de 2019. Nuestra prueba retrospectiva (backtest) se llevará a cabo a partir del 1 de enero de 2020. Este lapso entre el final de nuestro período de entrenamiento y el comienzo de nuestro período de pruebas es necesario para garantizar que nuestras pruebas sean sólidas.
#Delete all the data that overlaps with our back test data = data.iloc[:(-(365 * 5) + (31 * 5)),:] data
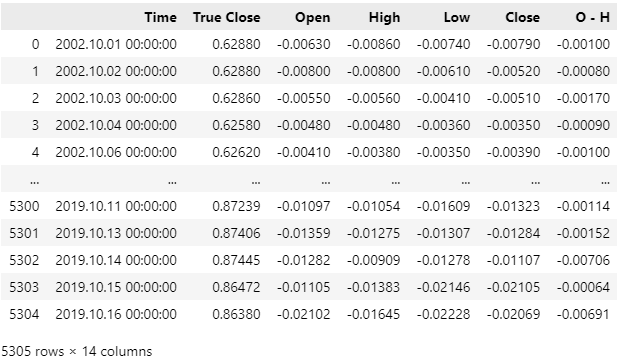
Figura 5: Asegúrese de eliminar todos los datos que se superpongan con el período que desea analizar retrospectivamente.
Visualicemos los efectos de las columnas que hemos creado para nuestro ejercicio. La columna "H - L" representa la diferencia entre el precio más alto y el más bajo del día. Este es el rango de negociación efectivo para cualquier día. Por otro lado, la columna "O - C" representa la variación neta del precio durante el día. Al realizar un diagrama de dispersión de estas dos columnas, nos interesa saber si existe alguna relación entre el rango del día y el cambio neto del día. Desafortunadamente, la relación parece ser complicada y no lineal. Este es el tipo de datos donde UMAP resulta útil.
sns.scatterplot(
data=data,
y='O - C',
x='H - L',
hue='Class'
)
plt.grid()
plt.title("Visualizing Our Custom Columns on EURUSD Market Data")
plt.axhline(0,color='black',linestyle='--')
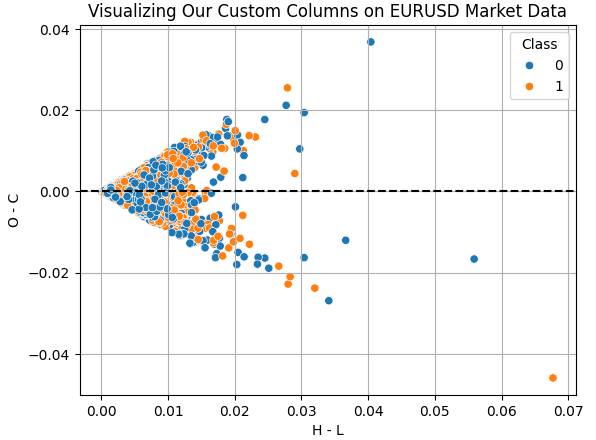
Figura 6: Visualización de la relación entre el rango de negociación y el cambio neto en el precio para el mismo día.
Aplicar las transformaciones UMAP es bastante sencillo. Primero necesitamos crear un objeto UMAP. Posteriormente, ajustamos el objeto UMAP a nuestros datos y obtenemos así los datos transformados. Por defecto, nuestro objeto UMAP reducirá los datos a 2 columnas. A medida que avancemos, mostraremos cómo especificar el número de columnas deseado. Las 10 columnas que obtuvimos originalmente usando nuestro script MQL5 se han reducido a las 2 dimensiones que se observan en la Figura 7.
En el siguiente ejemplo de código, exponemos ciertos parámetros de ajuste de la biblioteca UMAP al lector:
- n_neighbors: Este parámetro de ajuste indica al algoritmo cuántos puntos de datos debe intentar mantener dentro del mismo vecindario.
- metric: Existen diferentes métricas para medir cuán "cerca" están dos puntos entre sí y determinar si pertenecen al mismo vecindario. Cambiar la métrica de distancia modificará considerablemente la estructura de los datos proyectados.
reducer = umap.UMAP(n_neighbors=100,metric="euclidean") embedding = reducer.fit_transform(data.iloc[:,2:-2]) embedding = pd.DataFrame(embedding,columns=['X1','X2']) embedding['Class'] = data['Class'] sns.scatterplot( data=embedding, x='X1', y='X2', hue='Class' ) plt.grid() plt.title("Visualizing the effects of UMAP on our EURUSD Market Data")
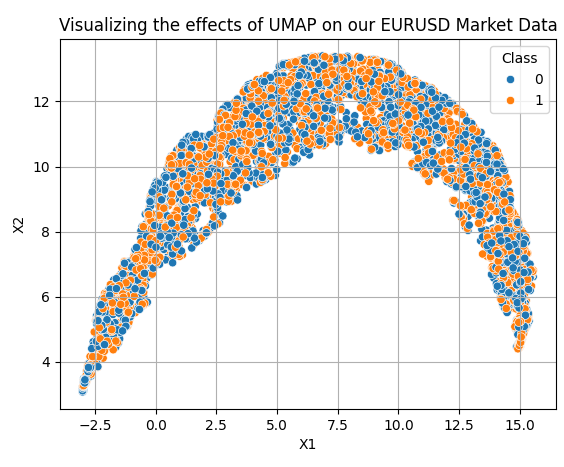
Figura 7: Visualización de nuestros datos transformados tras aplicar el algoritmo UMAP.
Nuestra nueva representación de datos no es perfecta. Sin embargo, tiene regiones dominadas por puntos naranjas y otras regiones dominadas por puntos azules. Esto facilita que nuestros modelos distingan entre las dos clases que estamos tratando de distinguir. Sin embargo, seleccionamos arbitrariamente solo dos columnas para que el lector se haga una idea de lo fácil que es empezar. En realidad, no sabemos cuántas dimensiones se requieren para transformar los datos de manera efectiva. Por lo tanto, realizaremos una búsqueda lineal entre 1 y 9. La siguiente función recibe un parámetro que especifica el número de dimensiones deseadas y nos devuelve los datos transformados correspondientes.
def return_transformed_data(n_components): HORIZON = 24 data = pd.read_csv("..\EURGBP UMAP Candlestick Recognition.csv") data['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] data.dropna(inplace=True) data = data.iloc[:(-(365 * 5) + (31 * 5)),:] reducer = umap.UMAP(n_neighbors=100,metric="euclidean",n_components=n_components,n_jobs=-1) embedding = reducer.fit_transform(data.iloc[:,2:-1]) cols = [] for i in np.arange(n_components): s = 'X' + ' ' + str(i) cols.append(s) embedding = pd.DataFrame(embedding,columns=cols) return embedding.copy()
Ahora preparemos nuestros modelos.
from sklearn.ensemble import GradientBoostingRegressor from sklearn.model_selection import TimeSeriesSplit,cross_val_score
Defina el objeto de división de la serie temporal para una validación cruzada de series temporales adecuada.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) Ahora vamos a realizar una búsqueda para determinar el número óptimo de dimensiones necesarias para representar los datos originales.
LEVELS = 8 res = pd.DataFrame(columns=['X'],index=np.arange(LEVELS)) for i in range(LEVELS): new_data = return_transformed_data(i+1) res.iloc[i,0] = np.mean(np.abs(cross_val_score(GradientBoostingRegressor(),new_data.iloc[:,0:],data['Target'],cv=tscv)))
Obtenga el índice mínimo y el valor mínimo.
res['X'] = pd.to_numeric(res['X'], errors='coerce') min_value = min(res.iloc[:,0]) min_index = res['X'].idxmin()
Los mejores resultados se obtuvieron al utilizar 3 columnas para representar las 10 originales. El lector debe entender que estas no deben considerarse como las 3 mejores columnas de las 10 con las que empezamos. Más bien, las 10 columnas se han transformado en 3.
plt.plot(res,color='black') plt.grid() plt.title('Finding The Optimal Number of U-MAP Components') plt.ylabel('RMSE Validation Error') plt.xlabel('Training Iteration') plt.scatter(min_index,min_value,color='red')
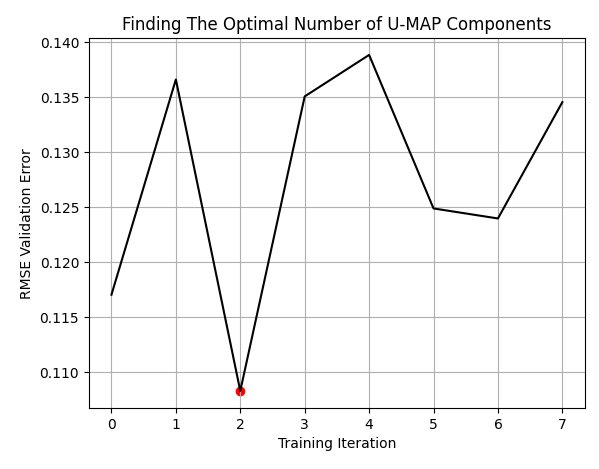
Figura 8: Nuestro número óptimo de columnas fue 3, de las 10 con las que comenzamos.
Ahora vamos a registrar nuestros niveles de error al utilizar los datos de mercado en su formato original.
classic_error = np.mean(np.abs(cross_val_score(GradientBoostingRegressor(),data.iloc[:,2:-2],data['Target'],cv=tscv)))
Ahora compararemos el error producido al utilizar los datos UMAP transformados con el error producido al utilizar los datos de mercado sin ninguna transformación. Como podemos observar, la transformación UMAP ha reducido nuestros niveles de error a regiones óptimas que no íbamos a alcanzar utilizando los datos de precios en su formato original.
results = [min(res.iloc[:,0]),classic_error] sns.barplot(results,color='black') plt.axhline(results[0],color='red',linestyle='--') plt.ylabel('RMSE Validation Error') plt.xlabel('0: UMAP Transformed Data | 1: Original OHLC Data') plt.title("UMAP Transformations Are Helping Us Reduce Our Error Rates")
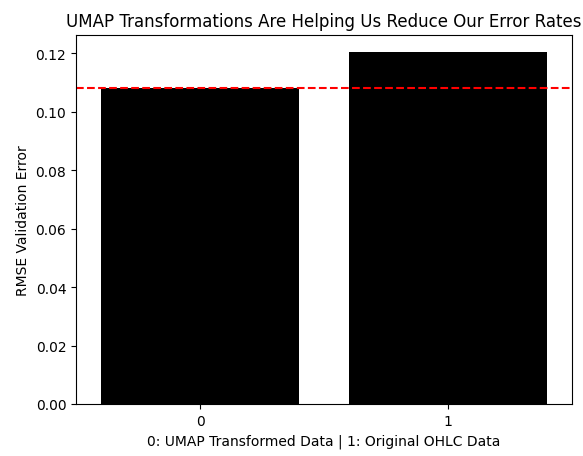
Figura 9: La transformación UMAP ha reducido nuestros niveles de error y está superando a los datos en su forma original.
Ahora que hemos establecido la motivación para utilizar las transformaciones UMAP, podemos comenzar a construir la arquitectura descrita en las figuras 2 y 3. Comenzaremos evaluando cuántas iteraciones de entrenamiento requiere nuestra red neuronal para aprender a transformar eficazmente nuestros datos de mercado originales en sus embeddings UMAP.
from sklearn.neural_network import MLPRegressor
Obtén los datos necesarios.
new_data = return_transformed_data(3) Realice una búsqueda lineal para observar la relación entre el error del modelo y el número de épocas de entrenamiento permitidas.
LEVELS = 18 NN_ERROR = pd.DataFrame(columns=['Error'],index=np.arange(LEVELS)) for i in range(LEVELS): model = MLPRegressor(hidden_layer_sizes=(data.iloc[:,2:-2].shape[1],10,5),max_iter=(2 ** i),solver='adam') NN_ERROR.iloc[i,0] = np.mean(np.abs(cross_val_score(model,new_data,data['Target'],cv=tscv)))
Vamos a graficar los resultados. Los mejores resultados se obtuvieron cuando permitimos que el modelo realizara 65 536 iteraciones de entrenamiento, o simplemente 2 elevado a la potencia 16.
NN_ERROR['Error'] = pd.to_numeric(NN_ERROR['Error'], errors='coerce') min_idx = NN_ERROR.idxmin() min_value = NN_ERROR.min() plt.plot(NN_ERROR,color='black') plt.grid() plt.ylabel('5 Fold CV RMSE') plt.xlabel('Max Iterations As Powers of 2') plt.scatter(min_idx,min_value,color='red') plt.title('Minimizing The Error of Our Neural Network')
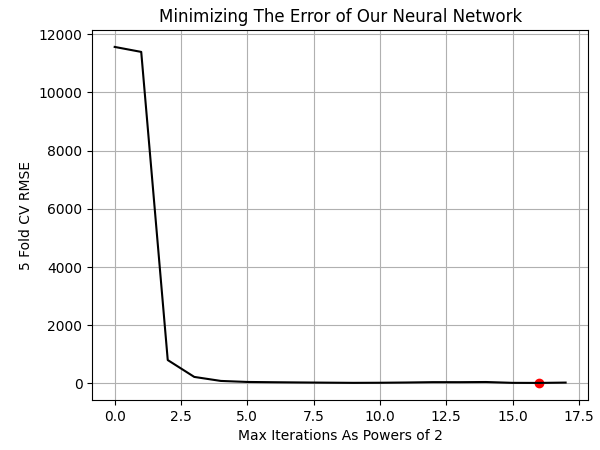
Figura 10: Visualización del número óptimo de iteraciones de entrenamiento de nuestro modelo necesarias para aprender los embeddings UMAP.
Ahora podemos entrenar ambos modelos.
#The first model will transform the given market data into its UMAP embeddings umap_transform_model = MLPRegressor(hidden_layer_sizes=(data.iloc[:,2:-2].shape[1],10,5),max_iter=int(2 ** min_idx),solver='adam') umap_transform_model.fit(data.iloc[:,2:-2],new_data) #The second model will forecast the future EURGBP returns, given UMAP embeddings forecast_model = MLPRegressor(hidden_layer_sizes=(new_data.shape[1],10,5),max_iter=int(2 ** min_idx),solver='adam') forecast_model.fit(new_data,data['Target'])
Preparémonos para exportar nuestros modelos al formato ONNX.
import onnx import netron from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
El modelo responsable de estimar nuestros embeddings UMAP estimados UMAP tiene una forma de entrada y salida única. Recibe 10 parámetros como entrada y devuelve 3 parámetros como salida. Lo especificaremos utilizando los parámetros initial_types y final_types de la API de ONNX.
umap_transform_shape = [("float_input",FloatTensorType([1,data.iloc[:,2:-2].shape[1]]))] umap_transform_output_shape = [("float_output",FloatTensorType([new_data.shape[1],1]))]
Por otro lado, el modelo responsable de pronosticar los cambios de precios a partir de los embeddings UMAP dados, tiene una forma de entrada y salida simple. Toma como entradas las 3 salidas del primer modelo y solo nos da 1 salida.
forecast_shape = [("float_input",FloatTensorType([1,new_data.shape[1]]))]
Defina las formas de entrada/salida de los modelos. Nótese que debemos dar un paso adicional para especificar que el primer modelo es de múltiples salidas, y luego proporcionamos la forma de nuestro modelo de múltiples salidas.
umap_model_proto = convert_sklearn(umap_transform_model,initial_types=umap_transform_shape,final_types=umap_transform_output_shape,target_opset=12) forecast_model_proto = convert_sklearn(forecast_model,initial_types=forecast_shape,target_opset=12)
Guarda los modelos.
onnx.save(umap_model_proto,"EURGBP UMAP.onnx") onnx.save(forecast_model_proto,"EURGBP UMAP Forecast.onnx")
Primeros pasos en MQL5
Ahora podemos empezar a escribir nuestro código MQL5 para probar la rentabilidad de la regresión UMAP. Recordemos que en la Figura 5, eliminamos todos los datos desde 2020 hasta el presente. Por lo tanto, la prueba retrospectiva (backtest) que obtendremos hoy nos brinda una representación justa de cómo se desempeñará nuestra estrategia en condiciones reales que no ha visto antes. Vamos a cargar nuestros modelos ONNX.
//+------------------------------------------------------------------+ //| UMAP Regression.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP UMAP.onnx" as uchar umap_onnx_buffer[]; #resource "\\Files\\EURGBP UMAP Forecast.onnx" as uchar umap_forecast_onnx_buffer[];
Además, necesitamos algunas variables globales. Dado que nuestra estrategia se basa en algoritmos, no necesitaremos tantos.
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ long umap_onnx_model,umap_forecast_onnx_model; vectorf umap_onnx_output(3),umap_forecast_onnx_output(1); double trade_sl;
Defina los manejadores y los búferes para nuestros indicadores técnicos.
//+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int ma_o_handler,ma_c_handler; double ma_o[],ma_c[];
Cargar la biblioteca de operaciones.
//+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int ma_o_handler,ma_c_handler; double ma_o[],ma_c[];
Para que el diseño de nuestro código sea legible para los humanos, hemos optado por dedicar una función a cada controlador de eventos. Esto hace que el contenido de nuestro programa sea fácil de leer de principio a fin. Si el usuario desea agregar más funcionalidades, le aconsejaría seguir el mismo principio de diseño y encapsular la utilidad deseada en un método, llamándolo desde el cuerpo de la función. Esto mantiene el código fuente en un estado mucho más fácil de mantener en comparación con la alternativa de tener que analizar cientos de líneas de código, todas encapsuladas en un único controlador de eventos.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- release(); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- update(); } //+------------------------------------------------------------------+
La función de liberación realiza una limpieza para nuestro Asesor Experto antes de que se desactive por completo.
//+------------------------------------------------------------------+ //| Custom functions | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Free up system memory | //+------------------------------------------------------------------+ void release(void) { IndicatorRelease(ma_c_handler); IndicatorRelease(ma_o_handler); OnnxRelease(umap_onnx_model); OnnxRelease(umap_forecast_onnx_model); }
La función de configuración se encarga de inicializar nuestro modelo ONNX y otras variables importantes del sistema. Devuelve un valor booleano que es falso si algo salió mal durante la inicialización. De lo contrario, la función debería devolvernos verdadero. Las formas de los modelos ONNX se emparejan como entradas y salidas, y sus llamadas también se emparejan.
//+------------------------------------------------------------------+ //| Setup system variables | //+------------------------------------------------------------------+ bool setup(void) { umap_onnx_model = OnnxCreateFromBuffer(umap_onnx_buffer,ONNX_DATA_TYPE_FLOAT); umap_forecast_onnx_model = OnnxCreateFromBuffer(umap_forecast_onnx_buffer,ONNX_DATA_TYPE_FLOAT); ma_c_handler = iMA(_Symbol,PERIOD_CURRENT,2,0,MODE_EMA,PRICE_CLOSE); ma_o_handler = iMA(_Symbol,PERIOD_CURRENT,2,0,MODE_EMA,PRICE_OPEN); if(umap_onnx_model == INVALID_HANDLE) { Comment("Failed to create EURGBP UMAP Transformer ONNX model"); return(false); } if(umap_forecast_onnx_model == INVALID_HANDLE) { Comment("Failed to create EURGBP UMAP Forecast ONNX model"); return(false); } ulong umap_input_shape[] = { 1 , 10 }; ulong umap_forecast_input_shape[] = { 1 , 3 }; ulong umap_output_shape[] = { 3 , 1 }; ulong umap_forecast_output_shape[] = { 1 , 1 }; if(!OnnxSetInputShape(umap_onnx_model,0,umap_input_shape)) { Comment("Failed to specify ONNX model input shape"); Print("Actual shape: ",OnnxGetInputCount(umap_onnx_model)); return(false); } if(!OnnxSetInputShape(umap_forecast_onnx_model,0,umap_forecast_input_shape)) { Comment("Failed to specify EURGBP Forecast ONNX model input shape"); Print("Actual shape: ",OnnxGetInputCount(umap_onnx_model)); return(false); } if(!OnnxSetOutputShape(umap_onnx_model,0,umap_output_shape)) { Comment("Failed to specify ONNX model output shape"); Print("Actual shape: ",OnnxGetOutputCount(umap_onnx_model)); return(false); } if(!OnnxSetOutputShape(umap_forecast_onnx_model,0,umap_forecast_output_shape)) { Comment("Failed to specify EURGBP Forecast ONNX model output shape"); Print("Actual shape: ",OnnxGetOutputCount(umap_onnx_model)); return(false); } trade_sl = 2e-2; return(true); }
Nuestra función de actualización nos ayudará a copiar las lecturas de los indicadores a sus búferes y a realizar nuestras rutinas de negociación de forma periódica, una vez al día.
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update(void) { static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_CURRENT,0); if(current_time != time_stamp) { time_stamp = current_time; CopyBuffer(ma_c_handler,0,0,1,ma_c); CopyBuffer(ma_o_handler,0,0,1,ma_o); if(PositionsTotal() == 0) { GetModelForecast(); FindSetup(); } } }
La función de pronóstico es necesaria para obtener nuestra cadena de pronósticos. La primera previsión será una aproximación de los embeddings UMAP de los datos de mercado originales. La segunda previsión es nuestra señal de negociación, la rentabilidad prevista del mercado EURGBP, dada una aproximación de su embeddings UMAP.
//+------------------------------------------------------------------+ //| Get a forecast from our models | //+------------------------------------------------------------------+ void GetModelForecast(void) { vectorf model_inputs = GetUmapModelInputs(); OnnxRun(umap_onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,umap_onnx_output); OnnxRun(umap_forecast_onnx_model,ONNX_DATA_TYPE_FLOAT,umap_onnx_output,umap_forecast_onnx_output); Print("Model Inputs: \n",model_inputs); Print("Umap Transformer Forecast: \n",umap_onnx_output); Print("EURUSD Return UMAP Forecast: \n",umap_forecast_onnx_output); }
Antes de poder obtener una previsión de nuestro modelo, necesitamos preparar sus datos de entrada. Recordemos que debemos preparar las entradas del primer modelo, y su salida alimentará al segundo modelo.
//+------------------------------------------------------------------+ //| Get our model's input data | //+------------------------------------------------------------------+ vectorf GetUmapModelInputs(void) { vectorf umap_model_inputs(10); umap_model_inputs[0] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iOpen(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[1] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iHigh(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[2] = (float)(iLow(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[3] = (float)(iClose(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[4] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iHigh(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[5] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[6] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[7] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[8] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[9] = (float)(iLow(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); return(umap_model_inputs); } //+------------------------------------------------------------------+
Recordemos que en las figuras 4 y 5 eliminamos todos los datos históricos que teníamos que se superponían con las fechas que estamos utilizando en la figura 11 a continuación. Esto nos permite ver cómo es probable que se comporte nuestro modelo al manejar datos fuera de la muestra y nos sirve como una estimación real de cuán rentable puede ser la estrategia.
")
Figura 11: Nuestro período de prueba retrospectiva (backtest) para evaluar nuestro conjunto de modelos UMAP.
Ahora decidiremos las condiciones bajo las cuales se pondrá a prueba la estrategia. Para obtener los resultados más fiables, someteremos al Asesor Experto a pruebas de estrés en condiciones exigentes, introduciendo un retraso aleatorio entre la ejecución de la orden y su cumplimiento en la prueba retrospectiva (backtest).
")
Figura 12: Las condiciones que estamos simulando anteriormente imitan escenarios de negociación reales.
En el registro de nuestro probador de estrategias, podemos ver las entradas para nuestros modelos ONNX, y la cadena de modelos UMAP está produciendo salidas válidas. El primer modelo redujo correctamente los 10 datos de entrada que registramos a partir de la información del mercado, a solo 3 datos de entrada, que posteriormente se utilizaron para obtener una previsión del mercado.

Figura 13: Todo parece funcionar correctamente en conjunto bajo el capó.
Nuestra curva de equidad parece estar brindándonos información positiva sobre el desempeño de nuestro modelo. Esto es alentador porque, como el lector recordará, solo hemos aproximado el algoritmo UMAP y sus embeddings.

Figura 14: Nuestra estrategia parece ser rentable hasta el momento.
Analicemos con mayor detalle el desempeño de nuestra estrategia. nuestro modelo tiene un índice de Sharpe de 0,42 con una ganancia esperada de 7,05; estas son estadísticas positivas. Nuestro porcentaje de operaciones rentables se sitúa en el 64%, mientras que en total realizamos 25 operaciones.
")
Figura 15: Análisis detallado de nuestro desempeño histórico mediante regresión UMAP.
En promedio, cada una de nuestras operaciones se mantuvo durante 1274 horas, aproximadamente 54 días. Esto sugiere que nuestro Asesor Experto debe estar detectando las tendencias del mercado, ya que el tiempo promedio de permanencia en las posiciones se sitúa en torno a los 54 días.
")
Figura 16: Visualización de la distribución de la duración de nuestras operaciones comerciales.
Tras analizar los datos de la prueba retrospectiva (backtest), comprobamos que, efectivamente, el Asesor Experto estaba detectando tendencias sostenidas en el mercado. En la captura de pantalla que aparece a continuación, las líneas blancas verticales representan períodos de 1 día, y las operaciones observadas fueron realizadas por nuestro Asesor Experto de Regresión UMAP durante su prueba retrospectiva (backtest). Podemos observar que el primero se inauguró en abril de 2020 y cerró al mes siguiente, en mayo. Mientras que el comercio posterior se extendió desde finales de mayo hasta principios de septiembre.
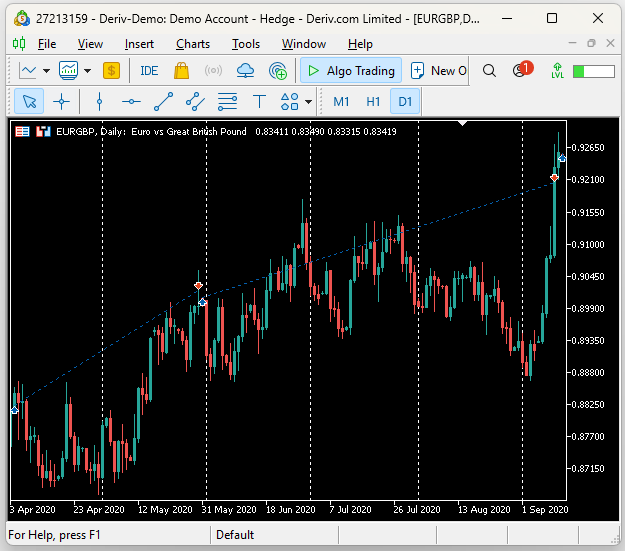
Figura 17: Visualización de las operaciones realizadas por nuestro asesor experto.
Conclusión
En este artículo, hemos demostrado cómo el lector puede emplear técnicas de reducción de dimensionalidad para ayudar a su modelo estadístico a aprender las características dominantes del mercado en los datos que posee. Demostramos que el algoritmo UMAP puede reducir nuestras tasas de error al utilizar modelos estadísticos hasta en un 40% en comparación con un modelo idéntico entrenado con los datos de mercado originales sin transformaciones UMAP. Por último, el lector ha aprendido un nuevo enfoque de trabajo que le permite aproximar de forma segura algoritmos que no puede implementar de forma nativa. Esto debería proporcionarte una ventaja competitiva en cualquier mercado en el que decidas operar. | Nombre del archivo | Descripción |
|---|---|
| EURGBP UMAP Forecast.onnx | Archivo ONNX que utiliza como entrada los embeddings UMAP aproximados para predecir el retorno futuro del EURGBP. |
| EURGBP UMAP.onnx | Archivo ONNX encargado de tomar como entrada los datos de mercado y aproximar los embeddings UMAP correspondientes. |
| UMAP Candlestick Recognition.ipynb | El cuaderno Jupyter que utilizamos para analizar nuestros datos de mercado de MetaTrader 5 y generar los archivos ONNX. |
| UMAP Candlestick Recognition.mq5 | El archivo de script MQL5 que desarrollamos para obtener datos de mercado detallados. |
| UMAP Regression.mq5 | El asesor experto que desarrollamos para operar el EURGBP utilizando nuestra arquitectura de dos modelos. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/17631
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Gracias , esta es una aplicación realmente interesante. Un par de cosas que pueden ser de ayuda error módulo 'umap' no tiene atributo 'UMAP' necesita umap-learninstalled , usted puede hacer esto con una línea!pip install umap-learn. si obtiene NameError: nombre 'FloatTensorType' no está definido es necesario instalar o actualizar onnixxmltools a través de !pip install onnxmltools. Mis datos resultaron muy diferentes de los datos que se muestran aquí, estaría interesado en cómo todo el mundo se va con el código
Quiero EA para MT5 y uso Exness broker