
Redes neuronales en el trading: Pipeline de pronóstico inteligente (Time-MoE)

Introducción
La previsión de series temporales sigue siendo una de las tareas clave sobre las que se basa el trading algorítmico moderno. La precisión del modelo determina no solo el éxito de una estrategia de trading, sino también su capacidad de adaptación a la naturaleza cambiante del mercado. La mayoría de los modelos se desarrollaron para una tarea específica, perdiendo estabilidad ante los más mínimos cambios en el entorno del mercado. Recientemente, se ha producido un rápido desarrollo de los modelos fundamentales (foundation models). Uno de esos modelos se presentó en el artículo "Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts".
El Time-MoE es un Decoder-Only Transformer de última generación diseñado específicamente para secuencias basadas en el tiempo. Se basa en los principios de aprendizaje disperso, modularidad y predicción multiescala. Los autores de este framework demostraron cómo transferir la escalabilidad y la flexibilidad de los modelos a gran escala al dominio de las series temporales sin sacrificar la eficiencia computacional. La arquitectura del modelo que presentaron admite longitudes de secuencias analizadas y horizontes de planificación arbitrarios. Además, el modelo es capaz de procesar flujos de datos en tiempo real.
El primer eslabón en la arquitectura es la tokenización punto por punto de la serie temporal (Point-Wise Tokenization). A diferencia de los enfoques de ventana o agregación, aquí cada paso de tiempo se convierte en un token aparte. Esta propiedad puede resultar útil en el trading de alta frecuencia, donde incluso un solo tick puede cambiar el panorama. En el entorno MQL5, los tokens se pueden generar según las barras, ticks e indicadores derivados, como la volatilidad, los volúmenes y las señales de estrategias personalizadas.
Tras la tokenización, los datos pasan por una capa de incorporación con activación SwiGLU, que es un híbrido de Swish y Gated Linear Unit. Permite representaciones más suaves y estables de la información analizada, lo cual resulta especialmente útil en presencia de ruido de mercado y tendencias inestables.
El corazón del modelo es una pila de N unidades repetitivas, cada una de las cuales combina la autoatención causal multiabeza (Causal Multi-Head Self-Attention) y una mezcla de expertos dispersa (Sparse MoE). La atención se centra estrictamente en el pasado, lo cual garantiza una cronología justa; el modelo no prevé el futuro y, por lo tanto, es aplicable a las condiciones reales del mercado. El MoE añade escalabilidad a la arquitectura: en lugar de activar todos los parámetros del modelo, se selecciona un número limitado de submodelos especializados (expertos) para cada token. Algunos aprenden a trabajar mejor con movimientos impulsivos, otros, con fases de consolidación o movimientos planos. El mecanismo adaptativo toma decisiones sobre el enrutamiento de tokens.
Pero el modelo no se detiene en el nivel de procesamiento de datos: una de las características clave de TIME-MOE es la previsión multiescala (Multiscale Forecasting). Durante el entrenamiento, el modelo tiene la tarea de realizar predicciones simultáneamente en distintos horizontes temporales. Esto se implementa mediante módulos de salida paralelos (cabezas), cada uno de los cuales se entrena con su propia etiqueta objetivo: a corto plazo, a medio plazo o a largo plazo. Esta arquitectura nos permite considerar simultáneamente la microdinámica y el comportamiento macro del mercado. Y el modelo es capaz de alternar entre ellos en función del contexto del mercado.
Durante la inferencia, entra en juego la programación dinámica de cabezas (Dynamic Head Scheduling). Según la volatilidad, la fuerza de la tendencia o la confianza en el modelo, se activan diferentes módulos de previsión. Este enfoque adaptativo hace que Time-MoE resulte particularmente valioso en el trading, donde el comportamiento del mercado puede cambiar instantáneamente.
Es importante destacar que Time-MoE está optimizado para el entrenamiento con conjuntos de datos de series temporales a gran escala. Los autores del framework entrenaron el modelo con ayuda de Time-300B, el conjunto de datos abierto más grande que contiene más de 300 mil millones de puntos de datos temporales de nueve dominios. Esto permitió lograr una alta universalidad del modelo, estabilidad frente a desplazamientos de distribución y la capacidad de generalizar a problemas desconocidos. Al mismo tiempo, el Time-MoE admite hasta 2.400 millones de parámetros, activando solo una parte de ellos durante el proceso de inferencia, lo que lo hace eficiente y rentable en términos computacionales.
El algoritmo Time-MoE
El framework Time-MoE se basa en la idea de crear un modelo unificado y escalable para la previsión de series temporales que pueda adaptarse a cualquier condición del entorno analizado, manteniendo al mismo tiempo una carga manejable en los recursos informáticos. El algoritmo del framework comienza con la tokenización punto por punto (Point-Wise Tokenization), donde se registran todas las características importantes de cada paso de la serie temporal. Este enfoque garantiza que no se pierda ningún matiz durante la agregación.
La transformación de los tokens sin procesar en un espacio latente informativo se realiza mediante la técnica de incorporación SwiGLU.
![]()
donde las matrices W y V se entrenan junto con el modelo. La multiplicación elemento a elemento ⨂ mejora las características significativas, mientras que la combinación de la función Swish y el mecanismo de unidad lineal con compuerta (Gated Linear Unit) produce incorporaciones más expresivas capaces de codificar dependencias no lineales complejas.
Tras su incorporación, los tokens se envían a una pila de N bloques transformadores idénticos. Cada bloque consta de tres etapas:
- La normalización y atención causal: los vectores de entrada h t,l-1 se normalizan primero y luego se analizan mediante Self-Attention multicabeza delimitada por una máscara que excluye información sobre valores futuros. El token literalmente echa la vista atrás, repasando toda la historia que ha transcurrido, pero al mismo tiempo no puede mirar hacia adelante, como si siguiera una regla estricta: las decisiones reales se basan únicamente en la experiencia pasada.
- La renormalización ayuda a evitar reacciones exageradas ante anomalías poco frecuentes.
- La capa dispersa Mixture-of-Experts. Aquí dirigimos cada ventana histórica a un grupo de expertos: Mixture-of-Experts. El enrutador adaptativo decide cuáles de los K expertos de entre N debe activar. Un experto (común N+1) participa siempre mediante una función de ponderación sigmoide. Los expertos en activo procesan los datos de manera independiente y presentan sus pronósticos. La salida final del bloque se suma a la señal original.
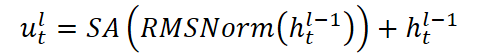
donde SA es el mecanismo de Self-Attention con H cabezas, cada una de las cuales analiza las posiciones anteriores t-1. Este diseño permite que el modelo monitoree eventos importantes de la historia, manteniendo al mismo tiempo las relaciones de causa y efecto.
![]()
![]()
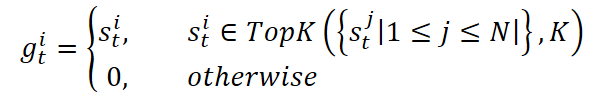
![]()
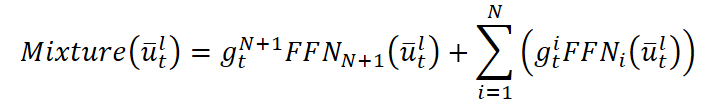
![]()
Esta estructura permite una especialización dinámica: durante los periodos de alta volatilidad, los tokens se asignan a expertos entrenados para reconocer movimientos impulsivos, mientras que en momentos de mayor calma, se asignan a aquellos que tienen mayor habilidad para identificar tendencias o periodos de estabilidad. La selección experta Top-K permite limitar el número de subredes activas manteniendo el conjunto principal de parámetros en estado inactivo. Esto permite que el modelo se adapte a miles de millones de parámetros con un presupuesto de inferencia constante.
Cuando un token x T pasa por todas las N capas, obtenemos un vector de contexto hT,L que contiene toda la historia y los patrones del mercado. Para la predicción de múltiples resoluciones (Multi-Resolution Forecasting), genera P predicciones para horizontes p 1,…, p P a través de FFN de una sola capa.
![]()
Esta arquitectura permite realizar predicciones simultáneas para diferentes segmentos temporales, manteniendo al mismo tiempo una única representación oculta.
Durante el entrenamiento, el modelo se enfrenta a la tarea de pronosticar simultáneamente varios horizontes temporales: desde las fluctuaciones del minuto más cercano hasta las tendencias con retraso de días y semanas. Para cada pronóstico, los autores del framework usan la función de pérdida de Huber, que combina la suavidad del componente cuadrático y la robustez de la parte lineal. Para errores pequeños, la función de pérdida de Huber se comporta como un MSE clásico, penalizando cuidadosamente las pequeñas desviaciones, y para errores grandes, cambia gradualmente a L1, reduciendo así la influencia de los valores atípicos poco frecuentes y evitando la explosión del gradiente. El modelo luego acumula las pérdidas en todas las cabezas de pronóstico.
Gracias a este sistema, el modelo aprende a capturar simultáneamente los impulsos a corto plazo y a mantener las tendencias a largo plazo, preservando la integridad del pronóstico en todos los niveles.
Sin embargo, el uso de expertos dispersos (MoE) introduce el riesgo de una carga de trabajo desigual: algunos expertos pueden estar sobrecargados mientras que otros están inactivos. Para eliminar este efecto, se añadió una regularización auxiliar que mide el desequilibrio. El objetivo final del aprendizaje se convierte en la suma de las partes principales y auxiliares.
El resultado final es un proceso unificado y coordinado: desde la tokenización detallada hasta el enrutamiento experto dinámico, la predicción multinivel y el aprendizaje equilibrado.
A continuación le presentamos la visualización del framework Time-MoE que propone el autor.

Implementación con MQL5
Ahora que hemos abarcado con detalle la teoría y los aspectos clave del framework Time-MoE, es hora de pasar a la parte práctica de nuestro trabajo y llevar la teoría a la práctica mediante código. Sin embargo, para evitar cubrir demasiado material a la vez, dividiremos todo el sistema en bloques lógicos. Y, siguiendo el flujo de información, implementaremos el framework paso a paso utilizando MQL5. Este enfoque práctico y gradual no solo facilitará las pruebas y la depuración de cada bloque, sino que también permitirá ensamblarlos en una implementación Time-MoE dinámica y con capacidad de respuesta, lista para un funcionamiento potente y eficaz en condiciones de mercado reales.
Tal como lo concibieron originalmente los autores de Time-MoE, todos los datos de entrada se pasan a través de un módulo Point-Wise Tokenization, que se puede implementar de manera eficiente utilizando la capa convolucional existente. Básicamente, cada barra o marca se introduce en un filtro convolucional 1D corto, y el resultado de la convolución no es más que un token atómico con un conjunto de características. Este enfoque nos ofrece dos ventajas importantes: primero, conservamos información sobre cada momento en el tiempo sin las pérdidas asociadas con la agregación; segundo, la convolución revela inmediatamente patrones locales.
A continuación, los datos se pasan al modelo de incorporación SwiGLU, con el que trabajaremos ahora.
Incorporaciones de SwiGLU
Una vez formados los tokens, se envían a la segunda etapa: el módulo de incorporación SwiGLU, que transforma las características sin procesar en vectores de espacio latente enriquecidos. La capa SwiGLU realiza una doble transformación sobre él:
- En primer lugar, el token pasa por una proyección lineal y una función Swish suave y fluida;
- luego, a través de otra proyección y la unidad lineal controlada selectiva Gated Linear Unit (GLU).
En la salida, los dos resultados se combinan mediante multiplicación elemento a elemento.
![]()
Swish aporta suavidad a la incorporación, lo que permite al modelo capturar señales sutiles, mientras que GLU abre o cierra componentes vectoriales individuales, resaltando los patrones que realmente importan.
En nuestra implementación, la capa SwiGLU estará representada como una clase CNeuronSwiGLUOCL que hereda del objeto base de capas neuronales. En esta clase, crearemos dos capas convolucionales especiales que realizan una doble proyección del vector analizado y generan dos versiones de la señal. Más abajo vemos resumida la estructura del nuevo objeto:
class CNeuronSwiGLUOCL : public CNeuronBaseOCL { protected: CNeuronConvOCL caProjections[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSwiGLUOCL(void) {}; ~CNeuronSwiGLUOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSwiGLUOCL; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Todos los objetos internos de nuestra nueva clase se declaran de forma estática. Por consiguiente, el constructor y el destructor permanecen vacíos. La inicialización de todas las proyecciones, los parámetros convolucionales y la comunicación con el contexto OpenCL se asignan al método Init. En los parámetros de esta función, el usuario indica el tamaño de la ventana convolucional, el paso de desplazamiento, el número de filtros y el puntero al contexto OpenCL. Todo esto permite un ajuste completo de las capas antes de su uso.
bool CNeuronSwiGLUOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, units_count * window_out * variables, optimization_type, batch)) return false; SetActivationFunction(None);
Dentro de este método, delegamos toda la preparación básica hacia arriba, al nivel de la clase padre, donde ya se han implementado los puntos de control y la configuración común de la interfaz. Para ello, basta con llamar al método homónimo de la clase padre. Esto nos permite evitar la duplicación de operaciones de bajo nivel y tener confianza en la fiabilidad del entorno de ejecución.
Aquí desactivamos explícitamente la función de activación de nuestra capa a nivel de interfaz, dado que todas las no linealidades son creadas por objetos internos.
Una vez definidos los detalles de la infraestructura, comenzaremos a perfeccionar nuestra capa. Un aspecto importante a considerar es que ambas capas convolucionales internas están diseñadas para generar vectores del mismo tamaño; esto es fundamental. Al fin y al cabo, solo con dimensiones coincidentes podemos multiplicarlas correctamente elemento por elemento. La única diferencia entre ellas radica en la posterior aplicación de diferentes funciones de activación.
Por lo tanto, durante la etapa de preparación, ejecutamos la inicialización de estas capas en un bucle, ajustando automáticamente cada una con la misma configuración de ventana convolucional, número de filtros y paso de desplazamiento. Esto evita la duplicación de código y garantiza que ambas proyecciones permanezcan siempre sincronizadas dimensionalmente.
for(uint i = 0; i < caProjections.Size(); i++) { if(!caProjections[i].Init(0, i, OpenCL, window, step, window_out, units_count, variables, optimization, iBatch)) return false; }
Una vez verificadas los tamaños y los parámetros básicos, configuramos individualmente la función de activación de cada capa para garantizar que las incorporaciones finales produzcan una combinación de características suaves y selectivas. Esta técnica simplifica el mantenimiento del código y garantiza una clara separación de funciones dentro de la capa SwiGLU.
caProjections[0].SetActivationFunction(GELU); caProjections[1].SetActivationFunction(None); //--- return true; }
Ahora podemos completar el método de inicialización de la capa SwiGLU devolviendo el resultado booleano de las operaciones al programa que ha realizado la llamada.
Una vez configurados todos los ajustes de las capas, es hora de poner en marcha el motor y procesar los datos analizados mediante nuestras dos convoluciones de proyección. Comencemos a construir el algoritmo de pasada directa, que se implementa en el método feedForward.
bool CNeuronSwiGLUOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { for(uint i = 0; i < caProjections.Size(); i++) if(!caProjections[i].FeedForward(NeuronOCL)) return false;
Como es habitual, en los parámetros de este método obtendremos un puntero al objeto de datos de origen. Esto es lo que necesitamos pasar a nuestras dos capas de proyección de datos. Realizaremos esta operación en un ciclo. Esta oportunidad se nos ofrece al declarar un array de objetos.
Precisamente porque ambas capas producen tensores de la misma dimensión, podemos multiplicarlos instantáneamente elemento a elemento sin preocuparnos por desajustes dimensionales. El resultado es un único tensor de salida donde cada valor es el producto de las opiniones de las proyecciones Swish y GLU. Esta técnica, basada en la transmisión cíclica de un puntero a los datos dentro de un array de capas, garantiza la compacidad del código y permite escalar fácilmente el número de "votos" dentro de una capa simplemente cambiando la longitud del array.
if(!ElementMult(caProjections[0].getOutput(), caProjections[1].getOutput(), Output)) return false; //--- return true; }
Guardamos los resultados obtenidos en el búfer de resultados de la interfaz externa y finalizamos el método, devolviendo el resultado lógico al programa que ha realizado la llamada.
Una vez completada la transferencia de datos directa a través de la capa SwiGLU, es hora de rastrear dónde se ha producido cada error y organizar una pasada inversa. La clave está en proyectar el gradiente de la capa de salida de vuelta a los datos de origen, pasando ordenadamente a través de nuestros dos proyectores convolucionales. Este proceso está organizado en el método calcInputGradients.
bool CNeuronSwiGLUOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
En el cuerpo del método obtenemos un puntero al objeto de datos de origen. El mismo que se ha utilizado para la pasada directa. Solo que esta vez necesitaremos devolverle el gradiente de error, de acuerdo con la influencia de los datos de origen en el resultado final. Obviamente, para transmitir correctamente los datos necesitamos un objeto válido. Por consiguiente, antes de iniciar otras operaciones, verificaremos la relevancia del puntero recibido.
En las interfaces externas de nuestra capa, ya tenemos la diferencia entre la previsión actual y el valor deseado. A continuación, gracias a que los vectores tienen tamaños similares, podemos aislar fácilmente la proporción del error que ha sido atribuida a cada uno de los filtros internos.
if(!ElementMultGrad(caProjections[0].getOutput(), caProjections[0].getGradient(), caProjections[1].getOutput(), caProjections[1].getGradient(), Gradient, caProjections[0].Activation(), caProjections[1].Activation() )) return false;
Enviaremos estas dos secuencias a las neuronas convolucionales correspondientes. Debido a que ambas capas almacenan sus propios búferes de gradiente, cada capa recibe su propio vector, idéntico en tamaño a los datos de origen.
Después de esto, cada objeto convolucional interno descompondrá de forma independiente su porción del error. Pero esta vez no podremos pasar valores al nivel del objeto de datos de origen en el ciclo. El problema es que cada operación posterior sobrescribirá los datos, eliminando los que se guardaron previamente. Necesitamos acumular los valores de todos los flujos de información. Por ello, primero pasamos los gradientes de error de la primera capa de proyección.
if(!NeuronOCL.calcHiddenGradients(caProjections[0].AsObject())) return false;
A continuación, almacenamos el puntero al búfer de gradiente de error del objeto de datos de origen en una variable local. Y su lugar será ocupado por otro búfer de datos libre del mismo tamaño.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(NeuronOCL.getPrevOutput(), false) || !NeuronOCL.calcHiddenGradients(caProjections[1].AsObject()) || !SumAndNormilize(temp, NeuronOCL.getGradient(), temp, 1, false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false) ) return false; //--- return true; }
Ahora podemos transmitir datos de forma segura a través del segundo flujo de información. Después, sumamos los valores obtenidos de las dos capas de proyección. Esta técnica garantiza que cada partícula de error de los distintos flujos de datos se conserve y se agregue correctamente, lo cual posibilitará una actualización de ponderación precisa y estable en el paso de optimización posterior.
Finalmente, restauramos los punteros a los búferes de datos a su estado original y finalizamos el método, devolviendo el resultado lógico de las operaciones al programa que ha realizado la llamada.
El algoritmo de pasada inversa, como de costumbre, se divide en dos etapas lógicas. Ya hemos examinado en detalle la primera etapa: la distribución del gradiente de error. Este es un paso clave que permite que el error se propague correctamente desde la salida de la capa hasta los datos de origen, respetando todas las características del flujo de datos multicanal.
La segunda etapa, la optimización de parámetros destinada a reducir el error global, queda fuera del alcance del presente artículo. Y no porque sea irrelevante, sino porque su implementación está estrictamente encapsulada dentro de cada uno de los objetos convolucionales. Esto nos ofrece una ventaja importante: la interfaz de nuestra clase no estará sobrecargada de detalles innecesarios, sino que mantendrá la pureza arquitectónica y la modularidad.
Todos los pasos necesarios para la corrección de peso ya están implementados dentro de cada capa de proyección. Por consiguiente, para realizar todo el ciclo de optimización, solo necesitamos llamar secuencialmente a los métodos correspondientes de todos los objetos internos. Este enfoque mantiene la clase principal compacta y la lógica de actualización de parámetros robusta y comprobable de forma aislada.
El código fuente completo de la clase CNeuronSwiGLUOCL y todos sus métodos, incluidas las funciones de pasada directa e inversa, se adjuntan en el archivo anexo y pueden examinarse para comprender mejor su funcionamiento interno.
Hemos completado la implementación del componente de incorporación SwiGLU y ahora podemos pasar sin problemas a la siguiente etapa, a saber, la implementación de la parte principal del framework Time-MoE: el bloque del Transformer modificado. Este paso abre un nuevo capítulo en la construcción del modelo, ya que es precisamente en el bloque transformador donde se forma una comprensión de alto nivel de la secuencia: el modelo aprende a capturar dependencias a largo plazo, analizar el contexto y predecir la dinámica probable de los eventos.
Transferir una serie temporal transformada del bloque SwiGLU al módulo del Transformer no supone solo una transferencia de datos, sino, en esencia, una transferencia de conocimiento. Las incorporaciones, comprimidas y ricas en información sobre patrones locales, se convierten ahora en material para el análisis profundo. Sin embargo, la arquitectura del transformador en Time-MoE se distingue significativamente de la implementación clásica. Y lo primero que llama la atención es la ausencia del bloque FeedForward habitual, que normalmente sigue inmediatamente al mecanismo de atención en cada capa.
En lugar del módulo estándar, los autores propusieron usar la denominada Mezcla de Expertos Dispersa (Sparse Mixture of Experts, o simplemente MoE). Esta solución arquitectónica no solo añade flexibilidad intelectual al modelo, sino que también hace que su entrenamiento sea más significativo y sensible al contexto. La idea principal de MoE es dividir una capa de propósito general en muchos submódulos altamente especializados (expertos), cada uno de los cuales está entrenado para procesar un tipo específico de datos de entrada. Este enfoque permite que a cada token de la secuencia de entrada únicamente accedan aquellos expertos más adecuados para procesar sus características, dejando a los demás en modo de espera.
El mecanismo de selección adaptativa de expertos se implementa mediante un enrutador, una subunidad independiente que, basándose en la representación inicial del token, decide qué expertos participarán. El artículo original destaca un punto importante: se utiliza un enrutamiento disperso, mediante el cual cada token no se enruta a todos los expertos a la vez, sino solo a unos pocos (por ejemplo, dos de cada diez posibles). Esto reduce sustancialmente los costos computacionales, lo que permite utilizar el MoE incluso a gran escala sin sobrecargar los recursos.
Este enfoque le confiere al modelo muchas ventajas. En primer lugar, aprende a dividir las tareas entre expertos: algunos se adaptan a las fluctuaciones de precios a corto plazo, otros a los movimientos de tendencia o a la volatilidad. En segundo lugar, el modelo adquiere la capacidad de generalizar el conocimiento: gracias a las diferentes experiencias de los distintos expertos, es posible modelar interacciones más complejas que en una arquitectura tradicional de un solo nivel.
Por lo tanto, el uso de la mezcla de expertos dispersa en el transformador Time-MoE puede considerarse la innovación central del framework. Esto no es solo un experimento arquitectónico, sino una revisión fundamental del enfoque para el procesamiento de secuencias temporales.
Y entonces nos surge la pregunta: ¿cómo trasladar estas ideas arquitectónicas a aplicaciones prácticas? No nos limitamos a teorizar, sino que estamos creando paso a paso un sistema que funcione. Si recordamos las etapas anteriores de nuestra investigación, ya nos hemos encontrado con el concepto de Mixture of Experts (MoE) como parte del desarrollo del framework DUET. A continuación, implementamos un prototipo sencillo que nos ayudó a comprender mejor cómo funcionan el enrutamiento y la agregación de decisiones de expertos. Sin embargo, esa implementación difícilmente puede considerarse verdaderamente dispersa. En realidad, era una simulación del mecanismo de selección en la que todos los expertos calculaban sus resultados simultáneamente y, a continuación, estos se multiplicaban simplemente por las máscaras correspondientes.
Desde una perspectiva matemática, el resultado final parecía plausible: las máscaras permitían restablecer las salidas de expertos innecesarios, creando así una superposición controlada. Sin embargo, desde el punto de vista de la eficiencia computacional, francamente, estábamos perdiendo. Al fin y al cabo, en este caso, cada experto realizaba su trabajo en su totalidad, independientemente de si su resultado se utilizaría o no. De este modo, la complejidad computacional crecía linealmente con el número de expertos, lo cual anulaba una de las ventajas clave de la arquitectura MoE: su capacidad para escalar sin un crecimiento exponencial de los costos.
Obviamente, este enfoque resulta aceptable para modelos pequeños donde el número de expertos y su tamaño son reducidos y los requisitos de rendimiento no son tan críticos. Pero en situaciones reales, por ejemplo, al trabajar con transformadores profundos y anchos, donde se utiliza MoE en una de cada dos capas y el número de expertos puede llegar a decenas, dicha solución simplemente resulta inviable. La carga computacional se vuelve rápidamente imposible, especialmente si queremos utilizar el modelo en condiciones de tiempo real, como en el comercio algorítmico en los mercados financieros.
Además, a medida que aumenta el número de expertos, el propio proceso de enrutamiento se vuelve más complejo. Si continuamos utilizando todo a la vez, inevitablemente nos encontraremos con una sobrecarga de memoria de vídeo y una pérdida de eficiencia en OpenCL. Y aquí cobra especial importancia adherirse a la filosofía de la verdadera austeridad: dejar que solo funcione una pequeña parte de la red, pero solo la que se necesita aquí y ahora. Este enfoque no solo ahorra recursos, sino que también hace que el modelo sea más adaptable y resistente al ruido.
En la implementación actual, hemos decidido no limitarnos al enmascaramiento formal, sino ir más allá y construir un algoritmo verdaderamente disperso que se ajuste a la filosofía del framework Time-MoE. Por supuesto, nos enfrentamos a una tarea de gran envergadura que abarca varios niveles de arquitectura. Lo importante aquí no es solo programar otro módulo, sino construir un sistema lógico en el que el enrutamiento, la activación, la agregación y la optimización de parámetros funcionen en armonía, exactamente como se concibió en el algoritmo original. Por ello, en esta etapa, le sugiero tomar un breve descanso.
Hemos dado un paso importante: hemos implementado nuestra propia integración de SwiGLU, hemos establecido un flujo de información y hemos allanado el camino para la integración de Mixture of Experts. Esta es ya una base sólida sobre la que podemos construir el siguiente nivel del modelo. Pero para no desviar la atención del tema principal ni sobrecargar al lector con tanto material, lo lógico será exponer la construcción del MoE en un artículo aparte. Esto nos permitirá no solo considerar todos los detalles de la forma más exhaustiva posible, sino también evitar la fragmentación en el código y la lógica.
Así pues, llegado este punto lógico, concluimos esta sección y les invitamos a continuar nuestro viaje en el próximo artículo, esta vez con el MoE disperso a bordo.
Conclusión
En este artículo, nos hemos familiarizado con la arquitectura de Time-MoE, un framework progresivo propuesto por los autores del artículo "Time-MoE: Temporal Mixture of Experts for Long-Term Time Series Forecasting". Este modelo combina con éxito las ventajas del enfoque del Transformer con la idea de una mezcla de expertos dispersa (Sparse Mixture of Experts), lo que permite mejorar la calidad de las predicciones mediante el enrutamiento adaptativo de los cálculos. Una de las principales ventajas de Time-MoE es su capacidad para gestionar de forma eficiente las dependencias a corto y largo plazo en las series temporales. Además, la introducción de los módulos SwiGLU hace que el modelo sea más flexible.
En la parte práctica, comenzamos a implementar nuestra propia visión de los enfoques propuestos usando MQL5, transformando paso a paso los conceptos teóricos en código real. Como parte de la etapa actual, hemos implementado un bloque de incorporación SwiGLU construido sobre la base de dos proyecciones convolucionales con multiplicación elemento a elemento. Nos centramos en cuestiones relacionadas con el pasada directa e inversa, la distribución correcta del gradiente y el procesamiento de la información dentro de las capas convolucionales.
Así pues, hemos sentado las bases y estamos listos para seguir adelante. En la siguiente parte, nos centraremos en la construcción de un bloque MoE verdaderamente disperso, lo cual requiere una lógica de enrutamiento más compleja y una gestión de expertos. Esta parte será clave para la arquitectura de Time-MoE, y su implementación requerirá tanto una planificación cuidadosa como soluciones de ingeniería originales.
Enlaces
- Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor experto para recopilar ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 4 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura de los modelos |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18499
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso