Discusión sobre el artículo "Desarrollamos un asesor experto multidivisa (Parte 13): Automatización de la segunda fase: selección en grupos"
Gracias por los comentarios, seguiremos adelante.
Alexander, supongo que no te has enterado bien de cómo utilizar static. Con su ayuda, el patrón de diseño Singleton puede ser fácilmente implementado tanto en MQL5 como en C++. Yo lo utilicé, por ejemplo, para la clase CVirtualReceiver de la tercera parte. Este modificador no está relacionado de ninguna manera con el gráfico en el que se ejecutará el Asesor Experto. Una variable o una propiedad declarada con este modificador puede estar relacionada si le asignamos, por ejemplo, el resultado de la llamada a la función Symbol(). Pero esto no significa que no podamos cambiar el valor de dichas variables posteriormente
Hola Victor.
Yo utilizo SQLiteStudio. Este programa gratuito ha ampliado mucho su funcionalidad recientemente, por lo que no he encontrado en él la falta de algo necesario. En MetaEditor puedes editar la base de datos sólo ejecutando consultas SQL. Esto es menos conveniente, por supuesto.
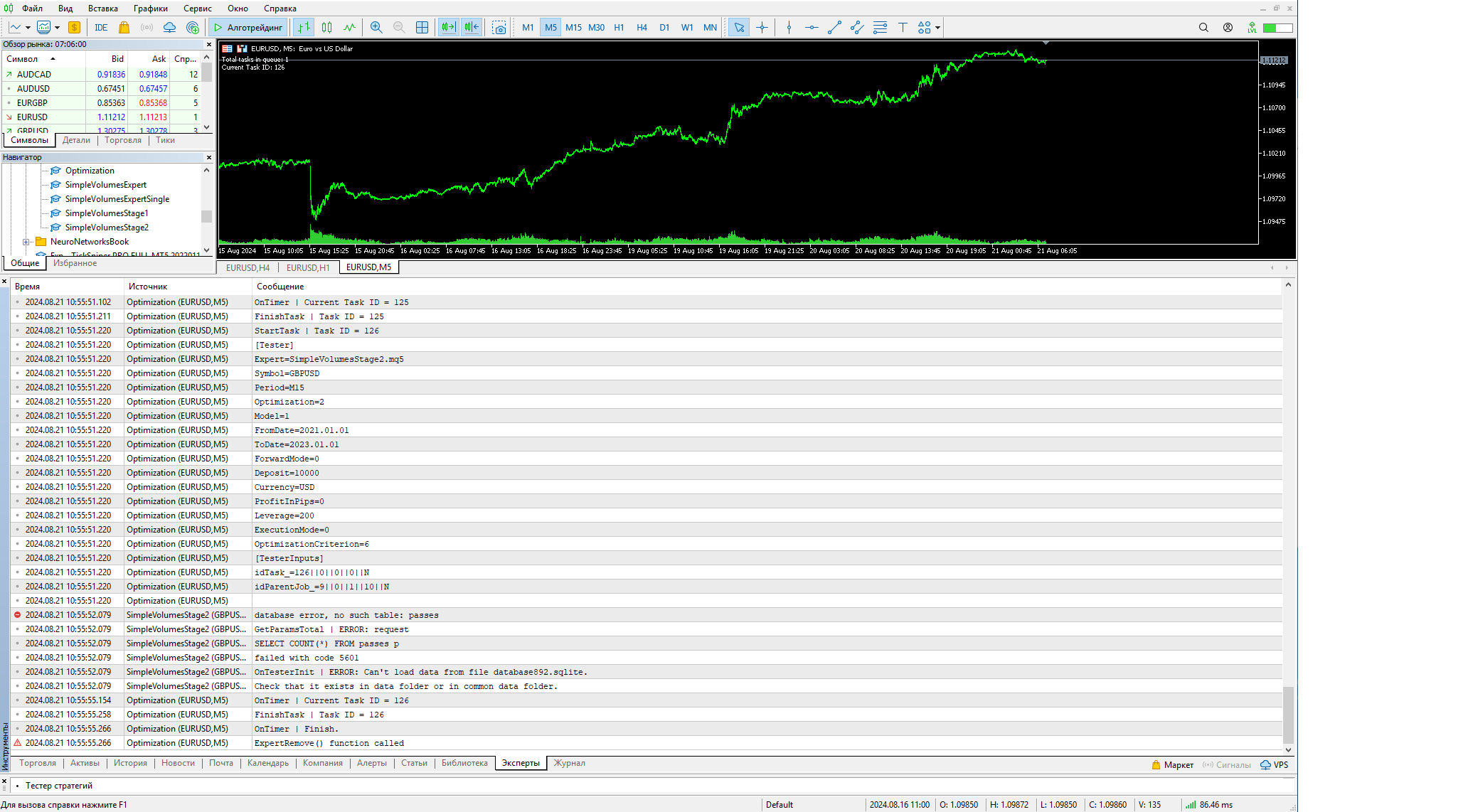
Yuri, gracias por el programa, ahora puedo abrir la base de datos y editarla. Y he hecho la primera etapa de los cálculos, pero la segunda etapa tiene un problema - no se inicia. Primero ejecuté la primera etapa, luego añadí manualmente una línea de la segunda etapa como tienes en la captura de pantalla y ejecuté dos consultas de tu artículo. Las tareas y los trabajos aparecieron en la base de datos y el Asesor Experto intenta ejecutar la segunda etapa. Pero por alguna razón no ve los pases de la primera etapa, aunque están en la base de datos. Puedo entender algo mal (no he trabajado con bases de nadie).
Aquí están los errores en las capturas de pantalla. ¿Cómo ejecutarlo?
{kind=link}
{kind=link}
Además, según entiendo estos parámetros
input int count_ = 16; // - Número de estrategias en el grupo (1 ... 16) input int i1_ = 1; // - Índice de estrategia nº 1 input int i2_ = 2; // - Índice de estrategia nº 2 input int i3_ = 3; // - Índice de estrategia nº 3 input int i4_ = 4; // - Índice de estrategia nº 4 input int i5_ = 5; // - Índice de estrategia nº 5 input int i6_ = 6; // - Índice de estrategia nº 6 input int i7_ = 7; // - Índice de estrategia nº 7 input int i8_ = 8; // - Índice de estrategia nº 8 input int i9_ = 9; // - Índice de estrategia nº 9 input int i10_ = 10; // - Índice de estrategia nº 10 input int i12_ = 11; // - Índice de estrategia nº 11 input int i11_ = 12; // - Índice de estrategia nº 12 input int i13_ = 13; // - Índice de estrategia nº 13 input int i14_ = 14; // - Índice de estrategia nº 14 input int i15_ = 15; // - Índice de estrategia nº 15 input int i16_ = 16; // - Índice de estrategia nº 16
deben buscarse dentro de cada tarea de la segunda etapa. ¿Pero en qué rangos deben buscarse y con qué paso? ¿Y el propio parámetro count_, según tengo entendido, no se debe buscar?
Para la segunda etapa, se debe crear automáticamente una segunda base de datos y enviarla a los agentes de pruebas. Su nombre se especifica en la directiva
#define PARAMS_FILE "database892.stage2.sqlite"
Debe ser diferente del nombre de la base de datos principal. En la captura de pantalla se le informa de que la tabla de pases no está en esta base de datos, aunque se esperaba que estuviera allí. Intente comprender el trabajo de la función CreateTaskDB(), que crea la segunda base de datos a partir de la inicial.
El paso y los límites de la búsqueda de parámetros del tipo i{N}_ se establecen automáticamente por el Asesor Experto Optimisation.mq5 basándose en la información de la segunda base de datos.
No es necesario buscar el parámetro count_. Se puede cambiar a un valor más pequeño, si queremos seleccionar grupos no a partir de 16, sino a partir de un número menor de instancias. Por ejemplo, a partir de 12 o a partir de 8. Pero para mi siempre ha sido igual a 16.
Yuri, no consigo que funcione.... El fichero de la base de datos común que tengo está especificado como tienes en el asesor base de datos892.sqlite, no lo he cambiado y está en el disco realmente, y el asesor Optimización.mq5 se conecta a él y ejecuta tareas. En el asesor experto SimpleVolumesStage2.mq5 también está especificado. Y el archivo de base de datos de la tarea se especifica database892.stage2.sqlite. Según tengo entendido son archivos diferentes. El archivo de base de datos común se encuentra en la carpeta Common\Files.
He intentado insertar comprobaciones en la función GetParamsTotal y especificar la variable fileName en la función DB::Connect, aquí está el código:
//+------------------------------------------------------------------+ //| Número de conjuntos de parámetros de estrategia en la base de datos de tareas //+------------------------------------------------------------------+ int GetParamsTotal(const string fileName) { int paramsTotal = 0; PrintFormat(__FUNCTION__" 1 "); // Si la base de datos de tareas está abierta, entonces if(DB::Connect(fileName, 0)) { PrintFormat(__FUNCTION__" 2 "); // Crear una consulta para obtener el número de pases para esta tarea string query = "SELECT COUNT(*) FROM passes p"; PrintFormat(__FUNCTION__" 3 "); int request = DatabasePrepare(DB::Id(), query); PrintFormat(__FUNCTION__" 4 "); if(request != INVALID_HANDLE) { // Estructura de datos para el resultado de la consulta PrintFormat(__FUNCTION__" 5 "); struct Row { int total; } row; PrintFormat(__FUNCTION__" 6 "); // Obtener el resultado de la consulta de la primera línea if (DatabaseReadBind(request, row)) { paramsTotal = row.total; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } PrintFormat(__FUNCTION__" 7 "); return paramsTotal; }
Cuando se ejecuta en el registro, las salidas como esta:
2024.08.21 22:05:27.964 Optimization (EURUSD,M5) idTask_=124||0||0||0||N 2024.08.21 22:05:27.964 Optimization (EURUSD,M5) idParentJob_=7||0||1||10||N 2024.08.21 22:05:27.964 Optimization (EURUSD,M5) 2024.08.21 22:05:29.096 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 1 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 2 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 3 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) database error, no such table: passes 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 4 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal | ERROR: request 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) SELECT COUNT(*) FROM passes p 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) failed with code 5039 2024.08.21 22:05:29.098 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 7 2024.08.21 22:05:29.098 SimpleVolumesStage2 (GBPUSD,H1) OnTesterInit | ERROR: Can't load data from file database892.sqlite. 2024.08.21 22:05:29.098 SimpleVolumesStage2 (GBPUSD,H1) Check that it exists in data folder or in common data folder. 2024.08.21 22:05:32.900 Optimization (EURUSD,M5) OnTimer | Current Task ID = 124 2024.08.21 22:05:33.008 Optimization (EURUSD,M5) FinishTask | Task ID = 124 2024.08.21 22:05:33.022 Optimization (EURUSD,M5) StartTask | Task ID = 125 2024.08.21 22:05:33.022 Optimization (EURUSD,M5) [Tester]
Donde el número de error todavía puede escribir 5602 . Según tengo entendido tropieza con la función DatabasePrepare.
Tomé la base de datos como usted ha publicado en el archivo al artículo 11 Lo único que he cambiado el nombre del archivo de database.sqlite a database892.sqlite y cambió el nombre del asesor de la primera etapa en la base de datos a la real en esta parte y después de ejecutar la primera etapa he añadido la línea de la segunda etapa a la tabla de etapas y ejecutado 2 conjuntos de comandos de su artículo. No cambié nada más. Hay alrededor de 388.000 filas con pases en la tabla de pases.
El error se produce antes, sólo que no se informa de él, ya que todo está bien desde el punto de vista de la ejecución del programa.
Este mensaje
2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) database error, no such table: passes
dice directamente que no hay tabla de pases en la segunda base de datos, y estamos intentando obtener datos de ella. Por eso debemos tratar con la función que debe crearla - CreateTaskDB().
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Desarrollamos un asesor experto multidivisa (Parte 13): Automatización de la segunda fase: selección en grupos:
Ya hemos puesto en marcha la primera fase del proceso de optimización automatizada. Para distintos símbolos y marcos temporales, realizamos la optimización utilizando varios criterios y almacenamos información sobre los resultados de cada pasada en la base de datos. Ahora vamos a seleccionar los mejores grupos de conjuntos de parámetros de entre los encontrados en la primera etapa.
La siguiente etapa consistirá en la selección de buenos grupos de instancias únicas de estrategias comerciales, que al trabajar juntas mejorarán los parámetros comerciales, disminuyendo la reducción, aumentando la linealidad del crecimiento de la curva de balance, etc. En la parte 6 de esta serie de artículos, ya vimos cómo implementar esta etapa manualmente. En primer lugar, seleccionábamos de entre los resultados de la optimización de parámetros de instancias únicas de estrategias comerciales aquellos que eran dignos de mención. Esto podía hacerse usando varios criterios, pero en aquel momento nos limitábamos a eliminar simplemente los resultados con rendimientos negativos. A continuación, probábamos diferentes combinaciones de ocho estrategias comerciales, las combinábamos en un asesor experto y las ejecutábamos en el simulador para evaluar los parámetros de su trabajo conjunto.
A partir de la selección manual, se implementaba la selección automática de combinaciones de parámetros de entrada de instancias únicas de estrategias comerciales, que se seleccionaban de una lista de parámetros almacenados en un archivo CSV. Resultó que incluso en el caso más sencillo, cuando solo ejecutábamos la optimización genética eligiendo ocho combinaciones, se obtenía el resultado deseado.
Ahora vamos a modificar el asesor experto que estaba optimizando la selección de grupos para que pueda utilizar los resultados de la primera etapa de la base de datos. También deberá almacenar sus resultados en una base de datos. Asimismo, veremos cómo crear trabajos para las optimizaciones de la segunda fase añadiendo los registros necesarios a nuestra base de datos.
Autor: Yuriy Bykov