Indicadores no lineales

Introducción
Los métodos no lineales se usan ampliamente para procesar series temporales financieras. Por ejemplo, en la plataforma comercial MetaTrader hay bastantes indicadores que utilizan enfoques no lineales, y todos ellos se utilizan activamente en el trading.
Los indicadores no lineales pueden resultar necesarios cuando ciertas características de la señal resultan más importantes que la información en general. Además, los indicadores no lineales pueden hacer frente a situaciones en las que los indicadores lineales son inservibles.
En términos generales, la creación de un indicador no lineal no es algo difícil. Un indicador lineal ordinario se puede describir usando la fórmula:
Donde, w[i] son los coeficientes de peso del indicador. Ahora haremos que este indicador sea no lineal. Para ello, en lugar de los precios, tomaremos sus logaritmos, y después de calcular la suma, hallaremos su exponente:
Este enfoque parece simple, pero en los cálculos del indicador hay cambios muy importantes. Todas las multiplicaciones se convierten en exponenciaciones, mientras que las sumas se reemplazan por multiplicaciones. Por ejemplo, en lugar de la media aritmética (SMA), obtendremos la media geométrica.
Además, el uso de logaritmos supone una indicación directa del uso de números positivos en los cálculos. Esta conversión de precio se puede utilizar en cualquier indicador lineal, y usted mismo podrá hacerlo fácilmente. Al mismo tiempo, todos los requisitos para los coeficientes seguirán siendo los mismos que para los indicadores lineales. Tomaremos la plantilla de indicador de este artículo y volveremos a convertirla en una variante logarítmica.
No obstante, también podremos construir indicadores no lineales utilizando la transformación de la propia serie temporal. En este artículo, analizaremos precisamente ese tipo de indicadores. Podemos decir que el artículo trata sobre la función ArraySort. Será la base para los nuevos indicadores.
Medidas de tendencia central
La tendencia central supone algún valor típico para un cierto conjunto de datos. Las medidas de tendencia central más comunes son la media aritmética, la mediana y la moda. La media aritmética supone una medida lineal y se implementa en una media móvil simple, mientras que la mediana y la moda no son lineales.
La mediana divide el conjunto de datos en dos mitades: la primera mitad contiene los valores inferiores a la mediana, mientras que la segunda mitad contiene los valores superiores a la misma. Veamos cómo se calcula. Supongamos que tenemos la siguiente serie de valores: 1, 6, 9, 3, 3, 7, 8. Primero clasificaremos estos números en orden ascendente: 1, 3, 3, 6, 7, 8, 9. Entonces la mediana será el número en el centro de esta serie. En nuestro ejemplo, este número será 6. Si la cantidad de datos es par, la mediana será la mitad de la suma de los números más próximos al centro. Por ejemplo, para la fila siguiente: 1, 3, 3, 6, 7, 8 la mediana será (3 + 6)/2 = 4,5. La característica principal de la mediana es que resulta muy resistente a los valores atípicos.
La moda es el valor que se encuentra con más frecuencia en la muestra de datos. Por ejemplo, en la muestra: 1, 6, 9, 3, 3, 7, 8, el número 3 es el más común, y supondrá la moda de esta serie. No obstante, al analizar los precios, cada valor puede encontrarse solo una vez. Luego, para calcular la moda, podremos usar la fórmula empírica de Pearson:
Moda = 3*Mediana – 2*Media.
En esta fórmula podemos ver que la moda es un indicador inestable (los coeficientes van más allá de los límites del intervalo -1…+1), pero puede resultar útil como adición a otros indicadores.
Otra medida central puede considerarse la mitad del rango. Para calcular este, deberemos encontrar la mitad de la suma de los valores máximo y mínimo de la serie temporal. Aunque el rango medio es sensible a los valores atípicos y no resulta muy fiable, se usa en algunos indicadores.
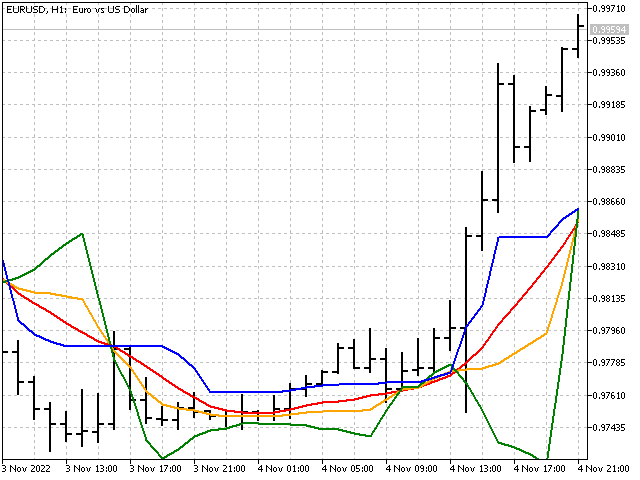
Así se verán las cuatro medidas de la tendencia central en el gráfico.
Suavizado bayesiano
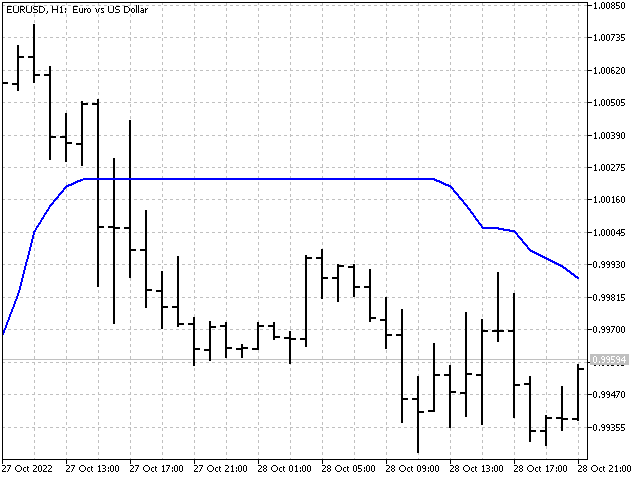
Si observamos el gráfico de la mediana, podremos encontrar áreas donde la mediana no cambia su valor durante bastante tiempo. Y cuanto más largo sea el periodo de la mediana, más significativas serán esas áreas. Por ejemplo, así se verá el gráfico de la mediana con un periodo de 51.
¿Qué pasará si tratamos de hacer que la mediana resulte más sensible a los cambios de precio? Por ejemplo, podremos tomar la mitad de la suma de la mediana y la media simple y combinar la estabilidad de la mediana y la media móvil. Bueno, esta opción es posible, pero le sugiero tomar un camino un poco distinto y usar el suavizado bayesiano.
Primero necesitaremos calcular la suma de todos los precios:
sum = price[1] + … + price[n].
A continuación, deberá seleccionar el valor relativo respecto al cual se producirá el suavizado. Entonces la media bayesiana se podrá calcular usando la fórmula:
Aquí, p será un parámetro con el que podremos establecer la fuerza de la influencia del valor seleccionado. Su valor deberá ser al menos uno. Por ejemplo, hemos elegido los siguientes valores: mediana, mitad del rango, máximo y mínimo.
El suavizado bayesiano también se podrá aplicar a varios valores. Entonces su fórmula tomará la forma siguiente:
En el indicador, esta opción se presentará en los valores máximo y mínimo. Así es como se verán en el gráfico.
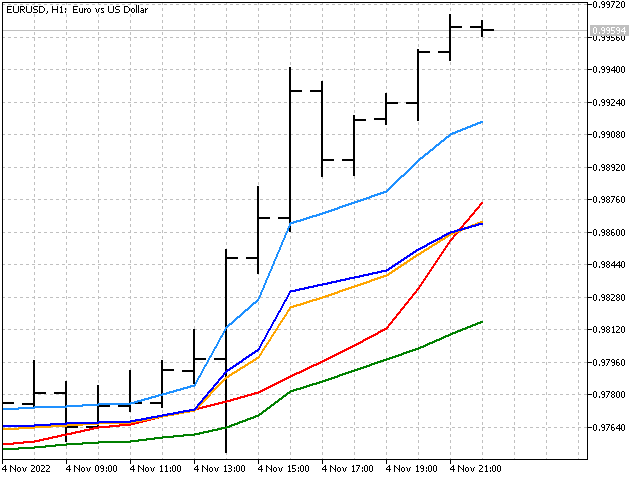
La aplicación del suavizado bayesiano mostrará cómo se pueden combinar métodos lineales y no lineales en un indicador.
Mediana de medianas
Vamos a recordar cómo podemos obtener una función de ventana triangular. Tomaremos como base una media móvil simple con un periodo de 3. Ahora necesitaremos encontrar los valores de las tres medias móviles desplazadas en una barra:
Después de eso, solo nos quedará encontrar la media de estos tres valores:
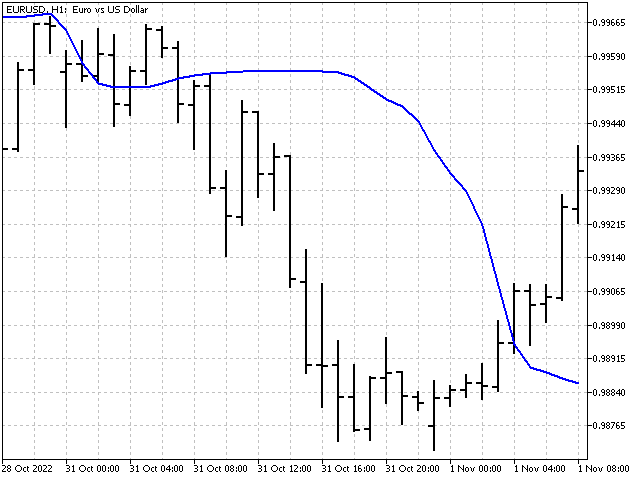
Ahora aplicaremos el mismo principio, pero a las medianas. Es decir, el algoritmo de cálculo será el siguiente, primero encontraremos los valores de las tres medianas:
Entonces, el valor del indicador será igual a la mediana de estas medianas:
Este será su aspecto en el gráfico.
Pseudomediana
El algoritmo para calcular la pseudomediana recuerda un poco al anterior. La única diferencia es que en cada paso no buscaremos la mediana de la subsecuencia, sino su máximo y mínimo.
Ahora necesitaremos tomar el valor mínimo de los máximos encontrados y el valor máximo de los mínimos. Su media será la pseudomediana.
La pseudomediana servirá como sustituta tanto de la mediana como de la mitad del rango.
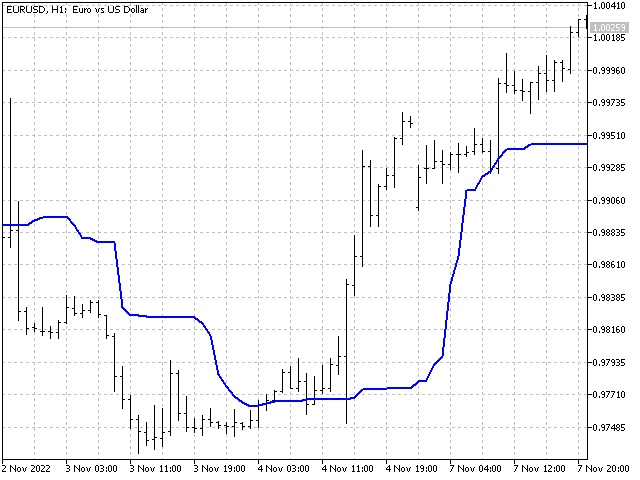
Su carácter no lineal no estropeará el indicador.
Fuerza de la tendencia. Tomaremos un indicador con un carácter de tendencia pronunciado. Por ejemplo, una media linealmente ponderada. El cálculo de los valores de este indicador (tomaremos para él un periodo igual a 5) se realizará de la siguiente manera:
A continuación, tomaremos estos precios y crearemos dos nuevas secuencias partiendo de ellos. En la primera (que denominaremos p[]), los precios se clasificarán en orden ascendente (del valor más bajo al más alto). Para la segunda secuencia (P[]), en cambio, clasificaremos los precios en orden descendente. Ahora aplicaremos pesos LWMA a estas secuencias.
Así, hemos obtenido dos nuevos valores que mostrarán cuál deberá ser el valor del indicador si los precios forman fuertes tendencias alcistas y bajistas.
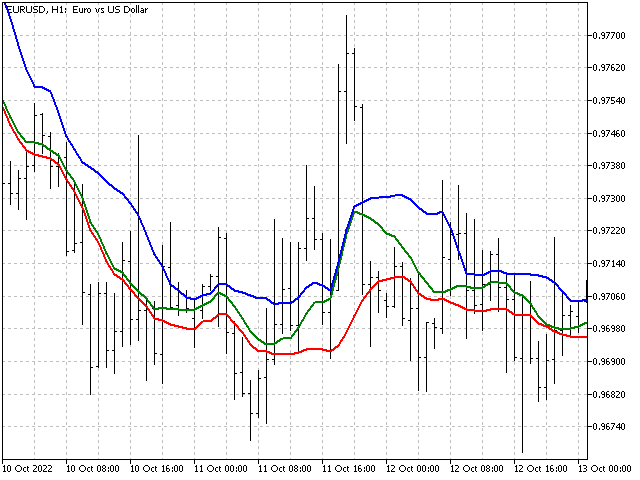
Ahora podremos evaluar visualmente la fuerza de la tendencia: cuanto más se acerque el indicador al borde inferior o superior, más fuerte será la tendencia descendente o ascendente. Además, la diferencia entre las líneas superior e inferior podrá valorar indirectamente la volatilidad del mercado. Cuanto más lejos estén unas de otras, mayor será la volatilidad.
Relative Strength Index. El indicador RSI fue desarrollado por J. Welles Wilder y publicado en la revista Commodities en junio de 1978. Para calcular este indicador, se usan dos variables auxiliares U y D. Estas se necesitan para separar el movimiento de precio ascendente y descendente.
Después de calcular los valores U y D, se aplicará un suavizado exponencial a sus valores. Entonces el valor del indicador será como sigue:
Es un excelente indicador, comprobado durante largo tiempo. Y, en este caso, no es lineal: a la entrada del indicador se suministra o bien la diferencia de precio, o bien cero. Bien, vamos a intentar cambiar una no linealidad por otra: en lugar de la diferencia de precio, usaremos la probabilidad de que ocurran. La intuición nos dice que las grandes desviaciones resultan menos comunes que las pequeñas. Una pequeña prueba demuestra que la intuición no nos ha engañado.
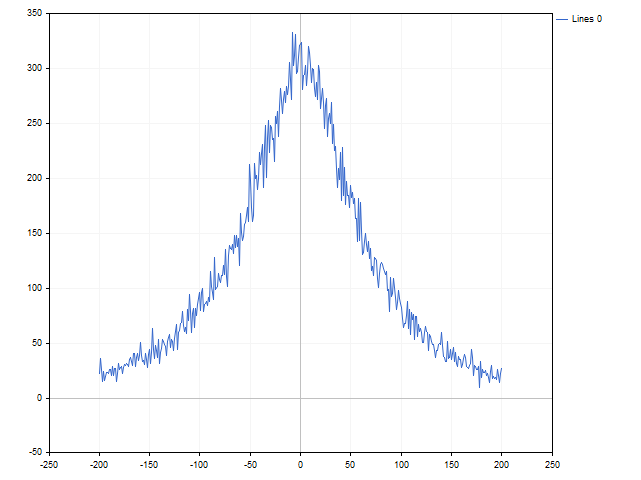
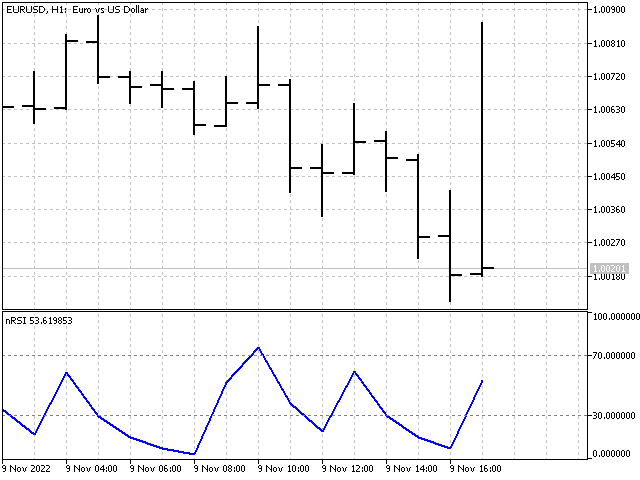
En lugar de la diferencia de precio, usaremos el valor que sigue:
Donde n será el número de veces que ha ocurrido esta diferencia en la historia, mientras que N será el número total de observaciones. Entonces la fórmula de nuestro indicador tendrá el aspecto siguiente:
Y el propio indicador se verá así.
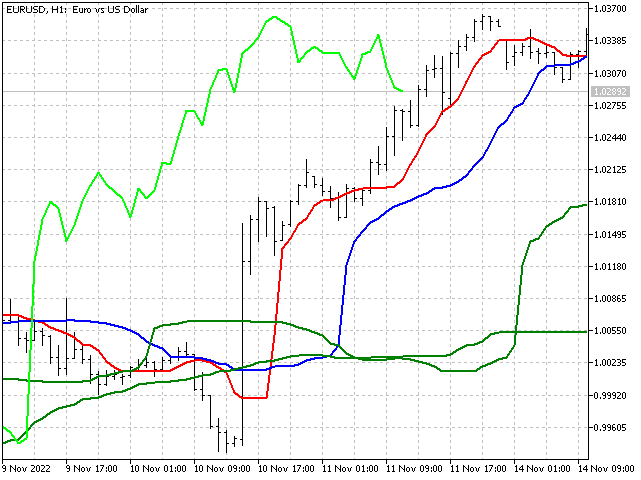
Ichimoku Kinko Hyo. Este indicador es un desarrollo del analista japonés Goichi Hosoda. El indicador Ichimoku combina varios enfoques para el análisis de mercado. Este indicador usa la mitad de los rangos para trazar las líneas Tenkan, Kijun y Senkou B. Intentaremos reemplazarlos con un indicador más estable: la mediana. Luego calcularemos la línea Senkou A usando una mediana ponderada. Estos reemplazos no deberían influir en la esencia del indicador, pero sí lo harán más estable. Este aspecto tendrán las líneas de la versión modificada del indicador Ichimoku. Las nubes las colorearemos nosotros mismos.
Patrones de velas
En el análisis técnico existe una tendencia bastante interesante basada en el análisis del aspecto de las velas japonesas y las combinaciones de velas entre sí. Muchos artículos están dedicados a esta tendencia. Por ejemplo, el "Análisis de los patrones de velas".
Seguiremos un camino ligeramente distinto y utilizaremos estadísticas ordinales para identificar patrones de velas japonesas. Veamos el aspecto de nuestras acciones en la práctica.
En primer lugar, deberemos establecer el orden de los precios que se usarán para el análisis. Luego registraremos los valores de precio en los puntos previamente elegidos. A continuación, guardaremos los índices que muestran el orden en que se han sucedido los precios.
| Precio | Valor | Índice |
|---|---|---|
| Open[0] | 1.03248 | 0 |
| Low[1] | 1.03133 | 1 |
| High[1] | 1.03204 | 2 |
| Open[1] | 1.03204 | 3 |
| Low[2] | 1.03191 | 4 |
| High[2] | 1.03256 | 5 |
| Open[2] | 1.03248 | 6 |
| Low[3] | 1.03217 | 7 |
| High[3] | 1.03296 | 8 |
| Open[3] | 1.03292 | 9 |
Ahora necesitaremos clasificar los valores de los precios en orden ascendente.
| 1.03133 | 1 |
| 1.03191 | 4 |
| 1.03204 | 3 |
| 1.03204 | 2 |
| 1.03217 | 7 |
| 1.03248 | 6 |
| 1.03248 | 0 |
| 1.03256 | 5 |
| 1.03292 | 9 |
| 1.03296 | 8 |
Ahora, deberemos resolver las posibles ambigüedades cuando los precios coincidan. Para hacer esto, desplazaremos el índice con el menor valor más cerca del comienzo del array. En el ejemplo analizado, los pares de índices (3, 2) y (6, 0) están intercambiados.
Después de ello, solo nos interesará una cosa: en qué orden se ubican los índices. Para facilitar el análisis, convertiremos los índices en un solo número: 8956073241. Este número supondrá la característica final del patrón. Aquí, debemos señalar que si usamos más de diez valores para el análisis, al ensamblar un solo número, deberemos usar la base adecuada del sistema numérico.
En código, este algoritmo podría tener el siguiente aspecto:
int array[10][2];//array for writing values and indices /*fill the array*/ array[0][0]=(int)MathRound(iOpen(_Symbol,PERIOD_CURRENT,1)/_Point); array[0][1]=0; for(int j=0; j<3; j++) { array[3*j+1][0]=(int)MathRound(iLow(_Symbol,PERIOD_CURRENT,j)/_Point); array[3*j+1][1]=3*j+1; array[3*j+2][0]=(int)MathRound(iHigh(_Symbol,PERIOD_CURRENT,j)/_Point); array[3*j+2][1]=3*j+2; array[3*j+3][0]=(int)MathRound(iOpen(_Symbol,PERIOD_CURRENT,j)/_Point); array[3*j+3][1]=3*j+3; } ArraySort(array); /*eliminate possible ambiguities when prices match*/ for(int j=1; j<10; j++) if(array[j-1][0]==array[j][0] && array[j-1][1]>array[j][1]) { int v=array[j-1][1]; array[j-1][1]=array[j][1]; array[j][1]=v; j=1; } /*gather the number*/ ulong number=0; for(int j=0; j<10; j++) number=number+array[j][1]*(ulong)MathRound(MathPow(10,j));//10 - number system base
Con la ayuda del script, podremos estimar la cantidad de patrones y cuántas veces han sucedido en la historia.
El único inconveniente de este algoritmo será su insensibilidad al escalado. Si estiramos o comprimimos las velas verticalmente, el patrón no cambiará. Por ejemplo, estas tres situaciones se han reconocido como iguales.
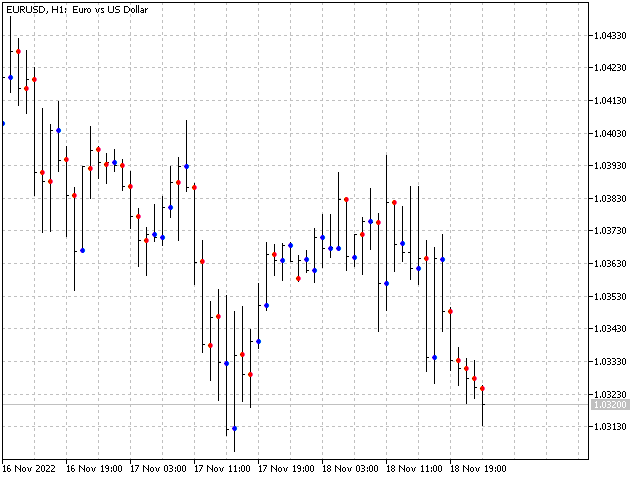
Sin embargo, el defecto mencionado no nos impedirá hacer un indicador basado en este algoritmo. En este caso, además, dejaremos que el indicador sea un poco predictivo. Para cada patrón, acumularemos las sumas de las diferencias de apertura máxima y apertura mínima para la barra que siga este patrón. Cuando el patrón reaparezca, el indicador evaluará qué cantidad es mayor y realizará un pronóstico. Como resultado, obtendremos una imagen así:
A lo largo y ancho
El algoritmo que obtuvimos antes también se puede usar al crear sistemas comerciales. Veamos dos ejemplos sencillos.
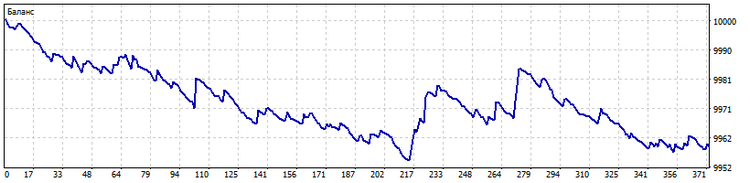
A lo largo. Muy a menudo, las señales de los sistemas comerciales se basan en los valores actuales de los indicadores. ¿Y qué pasaría si usáramos un cierto número de sus valores anteriores para generar una señal para abrir una posición? Por ejemplo, podemos tomar los últimos diez valores del indicador y aplicarles el algoritmo de creación de patrones, luego, el patrón resultante indicará el cambio en los valores del indicador a lo largo del tiempo. Por ejemplo, para encontrar el patrón, hemos usado los últimos diez precios de apertura. Además, hemos aumentado el horizonte de pronóstico a cinco barras por delante. Así es como se verá el comercio de este asesor experto.
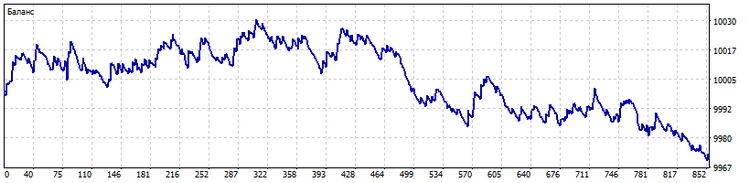
Al lo ancho. El algoritmo de cálculo de patrones también se puede usar para un grupo de indicadores. En este caso, el patrón indicará el orden en que se encuentran los indicadores unos respecto a otros. Y precisamente este será el orden que determinará las señales del sistema comercial. Como ejemplo, tomaremos diez medias móviles con periodos 2*n + 1 (n = 0…9). Así es como se verá el comercio en este caso.
En ambos casos, deberemos controlar el número de patrones reconocidos por el algoritmo. Su número no deberá ser muy pequeño, pues el sistema comercial podría no distinguir diferentes situaciones entre sí. Además, el número de patrones no puede ser grande, pues demasiadas situaciones comerciales se reconocerán como únicas y el sistema comercial simplemente no reaccionará a estas. Además, en el segundo caso, deberemos utilizar indicadores que difieran lo más posible entre sí. Por ejemplo, el uso exclusivo de medias móviles simples, incluso con pequeñas diferencias en sus periodos, será un claro error del desarrollador, aunque, eso sí, su esfuerzo resultaría digno de elogio.
Conclusión
Los métodos no lineales de procesamiento de información comercial se pueden usar tanto en indicadores como en estrategias comerciales. Ya se han usado antes, y pueden (y deben) seguir utilizándose. Los indicadores no lineales pueden ayudarnos a abordar el movimiento de los precios de una forma nueva, mientras que el uso de enfoques no lineales en los sistemas comerciales nos ayudará a obtener señales cualitativamente diferentes.
Programas utilizados en el artículo.
| Nombre | Tipo | Descripción breve |
|---|---|---|
| Base LogIndicator | indicador | Indicador basado en la transformación logarítmica de los precios. InpCoefficient - coeficientes de peso del indicador; podemos introducir cualquier número. Restricción - su suma no deberá ser igual a cero. |
| MMMM | indicador | Indicador que muestra medidas de tendencia central.iMode - selección de la tendencia. iPeriod - periodo del indicador (no inferior a 2). |
| Bayesian Moving Average | indicador | Indicador que implementa el suavizado bayesiano.iMode - selección de la tendencia a suavizar.iPeriod - periodo del indicador. Parameter - parámetro de suavizado. |
| Median Median | indicador | Indicador que muestra la mediana de las medianas. Análogo no lineal de la función de ventana triangular.iPeriod - periodo indicador. |
| Pseudomedian | indicador | Pseudo-mediana - en algunos casos puede ser un buen reemplazo para la mediana y la mitad del rango.iPeriod - periodo del indicador. |
| Strength Trend | indicador | Indicador que muestra la fuerza del componente de tendencia en la muestra de precios.iPeriod - periodo del indicador. |
| nRSI | indicador | Indicador basado en las probabilidades del incremento del precio.iMode - selección del método de suavizado.iPeriod - periodo del indicador. |
| nIchimoku Kinko Hyo | indicador | Ejemplo de modernización del indicador Ichimoku clásico. PeriodS, PeriodM, PeriodL - periodos cortos, medios y largos del indicador. |
| Script Pattern | script | Script que recopila estadísticas sobre los patrones de precio. Al final del trabajo, guardaremos los resultados en un archivo en la carpeta Files. |
| Pattern | indicador | Indicador que calcula patrones. Basándose en los datos históricos, realiza un pronóstico sobre el movimiento de precios predominante en la barra de apertura. Least - número mínimo de observaciones de patrones en la historia. El pronóstico se mostrará solo para los patrones que se hayan observado al menos un número Least de veces. |
| EA Along Across | experto | Asesor comercial que utiliza patrones de precios. Mode - seleccione la dirección del patrón. Least - número de observaciones de patrones en la historia. Percent - porcentaje de dominio de una dirección del movimiento de precios sobre otra. Influirá en el número de posiciones abiertas. El valor de este parámetro deberá seleccionarse dentro del rango de 51 - 99. |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/11782
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
La mediana de medianas en esta forma es mejor en comparación con una ventana triangular. La situación más "sabrosa" para ella es un cambio de la dirección de la tendencia a la opuesta. Si necesita una variante más sensible, es mejor hacerlo de esta forma. Primero encontramos la mediana de un último precio, luego encontramos la mediana de dos precios, luego de tres, etc. Al final, hallamos la mediana de todos los precios encontrados anteriormente. Obtenemos el análogo de una media ponderada lineal. Esto no eliminará la principal desventaja de la mediana, la pérdida de información en los bordes, pero hará que el indicador sea más sensible a los cambios actuales.
nah - todo en vano.
Al igual que todos mis intentos anteriores de hace muchos años para desarrollar diversos métodos de agrupación y promedio y crear cientos de robots con su aplicación fueron en vano. Créanme, en esto he tenido mucho más éxito. No quedan puntos blancos en este campo.
Sólo queda la IA con reconocimiento de patrones y procesos.
Llegarás a ella de todos modos, si no pisas el terreno.
Sí, no estaba prestando atención.
Si se quiere luchar contra el desfase, hay que utilizar un modelo adecuado. Por ejemplo, trazamos un polinomio de tercer grado hacia adelante por 20 puntos. Obtenemos los coeficientes {4979,3264,1904,864,109,-396,-686,-796,-761,-616,-396,-136,129,364,534,604,539,304,-136,-816} /8855 - un indicador de este tipo no tendrá desfase
si tenemos problemas con el desfase, tenemos que tomar un modelo apropiado. Por ejemplo, construimos un polinomio de tercer grado adelantado por 20 puntos. Obtenemos los coeficientes {4979,3264,1904,864,109,-396,-686,-796,-761,-616,-396,-136,129,364,534,604,539,304,-136,-816} /8855 - un indicador de este tipo no se quedará rezagado
hace mucho tiempo todo se ha implementado, comprobado, vuelto a comprobar, probado, vuelto a probar. No hay peces. Más precisamente, la existencia de los peces es siempre temporal, y el resto del tiempo de nivelación éxito temporal.
si tenemos problemas con el desfase, tenemos que tomar un modelo apropiado. Por ejemplo, construimos un polinomio de tercer grado adelantado por 20 puntos. Obtenemos los coeficientes {4979,3264,1904,864,109,-396,-686,-796,-761,-616,-396,-136,129,364,534,604,539,304,-136,-816} /8855 - un indicador de este tipo no se quedará rezagado
El propio polinomio se vuelve a dibujar, por lo que el valor es su traza, que forma una línea de deslizamiento no dibujado.
De hecho, es posible lograr un retraso mínimo, pero no comienzan otros problemas.
Foro sobre trading, sistemas de trading automatizados y prueba de estrategias de trading.
Lsma
Nikolai Semko, 2020.02.01:09
Media móvil simple (período 200):
Media móvil de regresión lineal (período 200):
Media móvil de regresión parabólica (período 200):
Media móvil de un polinomio de 3er grado (período 200):
Media móvil de un polinomio de 4º grado (período 200):
Media móvil de un polinomio de 5º grado (período 600):
etc.
nah - todo en vano.
Al igual que todos mis intentos anteriores de hace muchos años para desarrollar diversos métodos de agrupación y promedio y crear cientos de robots que los utilizan fueron en vano. Créeme, he tenido mucho más éxito en esto. No quedan puntos blancos en este campo.
Sólo queda la IA con reconocimiento de patrones y procesos.
Llegarás a ella de todos modos, si no pisas el terreno.