
Neural networks made easy (Part 43): Mastering skills without the reward function

Introduction
Reinforcement learning is a powerful machine learning approach that allows an agent to learn on its own by interacting with the environment and receiving feedback in the form of a reward function. However, one of the key challenges in reinforcement learning is the need to define a reward function that formalizes the desired behavior of the agent.
Determining the reward function can be a complex art, especially in tasks where multiple goals are required or where there are ambiguous situations. Additionally, some tasks may not have an explicit reward function, making traditional reinforcement learning methods difficult to apply.
In this article, we introduce the concept of "Diversity is All You Need", which allows you to teach a model a skill without an explicit reward function. Variety of actions, exploration of the environment, and maximizing the variability of interactions with the environment are key factors for training an agent to behave effectively.
This approach offers a new perspective on learning without a reward function and may be useful in solving complex problems where identifying an explicit reward function is difficult or impossible.
1. "Diversity is All You Need" concept
In real life, in order for a performer to perform certain functions, certain knowledge and skills are required. Similarly, when training a model, we strive to develop the skills necessary to solve the given problem.
In reinforcement learning, the main tool for stimulating a model is the reward function. It allows the agent to understand how successful its actions were. However, rewards are often rare and additional approaches are required to find optimal solutions. We have already looked at some methods of encouraging a model to explore its environment, but they are not always effective.
Models trained in the traditional way have a narrow specialization and are capable of solving only specific problems. With small changes in the formulation of the problem, a complete retraining of the model is required, even if the existing skills may be useful. The same thing happens when the environment changes.
One possible answer to this problem is to use hierarchical models consisting of several blocks. In such models, we create separate models for different skills and a scheduler that manages the use of those skills. Scheduler training allows us to solve new problems using previously trained skills. However, this raises questions about the sufficiency and quality of pre-trained skills, as additional skills may be required to solve new problems.
The "Diversity is All You Need" concept suggests using hierarchical models with separate skills and a scheduler. It emphasizes maximum variety of actions and exploration of the environment, allowing the agent to learn and adapt effectively. By teaching diverse and distinct skills, the model becomes more flexible and adaptive, capable of using different strategies in different situations. This approach is useful when identifying explicit rewards is challenging, allowing the model to autonomously explore and find new solutions.
The central idea behind this concept is to use diversity as a tool for learning. Diversity in a model's actions and behavior allows it to explore state space and discover new possibilities. Diversity is not limited to random or ineffective actions, but is aimed at discovering different useful strategies that can be applied in different situations.
The "Diversity is All You Need" concept implies that diversity is a key component of successful training without an obvious reward function. A model trained on a variety of skills becomes more flexible and adaptive, capable of employing different strategies depending on the context and task requirements.
This approach has potential application in solving complex problems where determining an explicit reward function is difficult or inaccessible. It allows the model to independently explore the environment, learning various skills and strategies, which can lead to the discovery of new paths and solutions.
Another presupposition underlying the "Diversity is All You Need" concept is the assumption that the current state of the model depends not only on the specific action chosen, but also on the skill used. That is, instead of simply associating an action and a state, the model learns to associate certain states with certain skills.
The concept algorithm consists of two stages. First, unguided learning of a variety of skills occurs without connection to a specific task, which allows for a thorough exploration of the environment and expands the agent's behavioral toolkit. This is followed by a stage of supervised reinforcement learning, aimed at achieving maximum efficiency of the model in solving the set goal.
At the first stage, we train the skill model. The model's input consists of the current state of the environment and the specific skill selected to be applied. The model generates the appropriate action, which is then executed. The result of this action is a transition to a new state of the environment. At this stage, we are only interested in this new state, and no external reward is used.
Instead, we use a discriminator model that, based on the new state, tries to determine which skill was used in the previous step. The cross-entropy between the discriminator results and the one-hot vector corresponding to the applied skill serves as the reward for our skill model.
The skill model is trained using reinforcement learning methods such as Actor-Critic. The discriminator model, on the other hand, is trained using classical supervised learning methods.
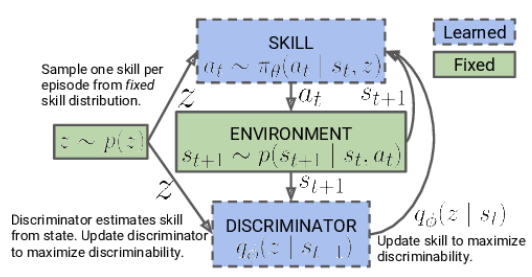
At the beginning of skill model training, we work with a fixed base of skills that does not depend on the current state. This is due to the fact that we do not yet have information about skills and their usefulness in different states. Our job is to learn these skills. When developing the model architecture, we determine the number of skills that will be trained.
During the skill model training process, the agent actively explores and completes each skill based on information received from the environment. We feed skill IDs randomly to the model so that it can learn and populate each skill independently of the others.
The model uses the learned skill IDs and the current state of the environment to determine the appropriate action to perform. It learns to associate certain skills with specific states and select actions for each skill.
It is important to note that at the beginning of training, the model has no prior knowledge about the skills or their usefulness in specific conditions. It independently studies and determines connections between skills and states in the training process. In this case, a reward function is used, which promotes maximum variety of agent behavior depending on the skill used.
Once the skill model training phase is completed, we move on to the next phase, which is supervised reinforcement learning. At this step, we train a scheduler model with the goal of maximizing a given goal or obtaining the maximum reward within a specific task. While doing this, we can use a fixed skill model, which can speed up the training process of the scheduler model.
Thus, a two-step approach to training a skill model, starting with unsupervised skill completion and ending with supervised reinforcement learning, allows the model to independently learn and use skills across a variety of tasks.
Note that in our approach we have modified the hierarchical decision-making process from the previously discussed hierarchical model. Previously, we used multiple agents, each with their own skills. The agents proposed options for action, and then the scheduler evaluated these options and made the final decision.
We have changed this sequence in the current approach. Now the scheduler first analyzes the current situation and decides to select the appropriate skill. The agent then decides on the appropriate action based on the selected skill.
Thus, we have inverted the hierarchical process: now the scheduler makes a decision about the skill to use, and then the agent performs the action corresponding to the selected skill. This change allows us to effectively manage and use skills depending on the current situation.
2. Implementation using MQL5
Now let's move on to the practical implementation of our work. As in the previous article, we start by creating a database of examples that we will use to train the model. Data collection is carried out by the "DIAYN\Research.mq5" EA, which is a modified version of the EA from the previous article. However, there are some differences in the current algorithm.
The first change we made is related to the architecture of the models. We have made modifications to the architecture to meet new requirements and ideas arising from the "Diversity is All You Need" concept.
We use three models in the learning process :
- Agent (skills) model. It is responsible for teaching and implementing various skills according to the current state of the environment.
- A scheduler who makes decisions based on an assessment of the situation and selects the appropriate skill to complete the task. The scheduler works in collaboration with the skill model and guides higher-level decision making.
- A discriminator that is used only during skill model training and is not used in real time. It is used to provide feedback and serves to calculate rewards during training.
It is important to note that the skill model and scheduler are the main models that are used in industrial operation and problem solving. The discriminator is only used to improve training of the skill model and is not used in the actual operation of the system.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler, CArrayObj *discriminator) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- if(!discriminator) { scheduler = new CArrayObj(); if(!scheduler) return false; }
According to the "Diversity is All You Need" algorithm, the agent model (skill model) is given an input data buffer containing descriptions of the current state and the identifier of the skill being used. In the context of our work, we convey the following information:
- Historical data of price movements and indicators: This data provides information about past price movements in the market and the values of various indicators. They provide important context for the agent model's decision making.
- Information about the current account balance and open positions: This data includes information about the current account balance, open positions, position size and other financial parameters. They help the agent model take into account the current situation and constraints when making decisions.
- One-hot skill ID vector: This vector is a binary representation of the ID of the skill being used. It indicates a specific skill that the agent model should apply in a given state.
To process such input, a sufficiently sized source data layer is required to allow the agent model to obtain all the necessary information about market conditions, financial data and the selected skill to make optimal decisions.
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
After receiving the input data, we create a data normalization layer, which plays an important role in processing the input data before passing it to the agent model. The data normalization layer allows you to bring different initial features to the same scale. This will ensure data stability and consistency. This is important for the agent model to work effectively and produce high-quality results.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
The prepared raw data can be processed using a block of convolutional layers.
Convolutional layers are a key component in the architecture of deep learning models, especially in image and sequence processing tasks. They allow extracting spatial and local dependencies from the source data.
In case of the "Diversity is All You Need" algorithm, convolutional layers can be applied to historical price movement data and indicators to extract important patterns and trends. This helps the agent to grasp the relationships between different time steps and make decisions based on the detected patterns.
Each convolutional layer consists of 4 filters that scan the input data with a specific window. The result of applying convolutional operations is a set of feature maps that highlight important characteristics of the data. Such transformations allow the agent model to detect and take into account important features of the data in the context of a reinforcement learning task.
Convolutional layers provide the agent model with the ability to "see" and focus on meaningful aspects of the data, which is an important step in the "Diversity is All You Need" decision-making and performing action.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
After passing through the convolutional layer block, the data is processed in the decision block, which consists of three fully connected layers. By passing data through fully connected layers, the agent model is able to learn complex dependencies and discover relationships between different aspects of the data.
The output of the decision block uses FQF (Fully Parameterized Quantile Function). This model is used to estimate quantiles of the distribution of future rewards or target variables. It allows the agent model to obtain estimates not only of average values, but also to predict various quantiles, which is useful for modeling uncertainty and decision making under stochastic conditions.
Using a fully parameterized FQF model as the output of the decision block allows the agent model to make more flexible and accurate predictions that can be used to optimally select actions within the framework of the "Diversity is All You Need" concept.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
The scheduler model performs a classification of the current state of the environment to determine the skill to use. Unlike the agent model, the scheduler has a simplified architecture without the use of convolutional layers for data preprocessing, which saves resources.
The input data for the scheduler is similar to that of the agent except for the skill identification vector. The scheduler receives a description of the current state of the environment, including historical price movement data, indicators, as well as information about the current account status and open positions.
Classification of the state of the environment and determination of the skill used is performed by passing data through fully connected layers and the FQF block. The results are normalized using the SoftMax function. This leads to a vector of probabilities reflecting the probability of a state belonging to each possible skill.
Thus, the scheduler model allows one to determine which skill should be used based on the current state of the environment. This further helps the agent model to make an appropriate decision and select the optimal action in accordance with the "Diversity is All You Need" concept.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
To diversify skills, we use a third model - Discriminator. Its task is to reward the most unexpected actions, which contributes to the diversity of the Agent’s behavior. The accuracy of this model is not required at a high level, so we decide to further simplify its architecture and eliminate the FQF block.
In the Discriminator architecture, we use only the normalization layer and fully connected layers. This allows for reduced computational resources while maintaining the model's classification ability. At the output of the model, we use the SoftMax function to obtain the probabilities of actions belonging to different skills.
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- return true; }
After describing the architecture of the models, we can move on to organizing the process of collecting data for training. At the first stage of data collection, we will only use the Agent model, since we do not have any primary information about the environment. Instead, we can effectively use a randomly generated skill identification vector that will produce comparable results using an untrained model. This will also allow us to significantly reduce the use of computing resources.
The OnTick method organizes the direct process of data collection. At the beginning of the method, we check if the new bar opening event has occurred, and if so, we load the historical data.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Similar to the previous article, we load information about the current state into two arrays: the array of historical data state and the array of information about the account state of the sState structure.
MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
We save the resulting structure into a database of examples for subsequent training of models. To transfer source data to the Agent model, we need to create a data buffer. In this case, we start by loading historical data into this buffer.
State1.AssignArray(sState.state);
To ensure more stable and equally effective operation of the model with different account sizes, it was decided to convert information about the account status to relative units. To do this, we will make some changes to the account status indicators.
Instead of the absolute balance value, we will use the balance change factor. This will allow for relative changes in balance over time.
We will also replace the equity indicator with the equity to balance ratio. This will help take into account the relative proportion of equity relative to balance and make the indicator more comparable between different accounts.
In addition, we will add an equity change to balance ratio, which will allow us to take into account changes in relative equity over time.
Finally, we will introduce the accumulated profit/loss to balance ratio to account for the relative magnitude of accumulated trading results relative to the account balance.
These changes will create a more versatile model that can effectively handle different account sizes and account for their relative health.
State1.Add((sState.account[0] - prev_balance) / prev_balance); State1.Add(sState.account[1] / prev_balance); State1.Add((sState.account[1] - prev_equity) / prev_equity); State1.Add(sState.account[3] / 100.0f); State1.Add(sState.account[4] / prev_balance); State1.Add(sState.account[5]); State1.Add(sState.account[6]); State1.Add(sState.account[7] / prev_balance); State1.Add(sState.account[8] / prev_balance);
To finish preparing the data for the model, we will create a random one-hot vector that will serve as a skill identifier. A one-hot vector is a binary vector in which only one element is 1 and the remaining elements are 0. This allows the model to differentiate and identify different skills based on the value of the element corresponding to a particular skill.
Generating a random one-hot vector ensures that skill IDs are diverse and distinct in each data example. This is consistent with our "Diversity is All You Need" concept.
vector<float> one_hot = vector<float>::Zeros(NSkills); int skill=(int)MathRound(MathRand()/32767.0*(NSkills-1)); one_hot[skill] = 1; State1.AddArray(one_hot);
At this stage, we transfer the prepared initial data to the Actor model and perform a forward pass through the model. Forward pass is the process of passing input data through the layers of a model and producing corresponding output values.
After performing the forward pass, we obtain model outputs that represent the probabilities for each action as determined by the Actor model. To select an action to perform, we sample (select randomly, taking into account probabilities) one of the possible actions based on the obtained probabilities.
Action sampling allows the Actor to explore the environment as much as possible based on each skill. This increases the variety of actions the model can take and helps avoid choosing the same actions too often. This approach provides the model with greater flexibility and the ability to adapt to different situations in the environment.
if(!Actor.feedForward(GetPointer(State1), 1, false)) return; int act = Actor.getSample();
Further code of the method was taken from the previous EA version without any changes. The complete code of the EA, including all its methods, can be found in the attached file.
Collecting a database of examples has already been described in detail in the previous articles, so we will not repeat ourselves and will immediately move on to developing the "DIAYN\Study.mq5" EA for training models. We mostly used the previous code, but made significant changes to the training method called Train.
We deviated slightly from the original algorithm proposed by the method authors. In our EA, we train a skill model and a scheduler in parallel. Of course, the discriminator is trained along with them, according to the “Diversity is All You Need” concept.
Thus, we strive to achieve diversity in the skills and behavior of models to obtain more sustainable and effective results.
As before, model training occurs inside a loop. The number of iterations of this cycle is determined in the EA external parameters.
At each iteration of the training loop, we randomly select a pass and state from the example database. After selecting a state, we load historical data about price movements and indicators into a data buffer, similar to how it is done in the data collection EA.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State1.AssignArray(Buffer[tr].States[i].state);
We also add account status and open positions data to the same data buffer. As mentioned earlier, we convert this data into relative units to make the models more robust across different account sizes. This allows us to unify the representation of account status and open positions in the model and ensure their comparability for training.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State1.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State1.Add(Buffer[tr].States[i].account[1] / PrevBalance); State1.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State1.Add(Buffer[tr].States[i].account[3] / 100.0f); State1.Add(Buffer[tr].States[i].account[4] / PrevBalance); State1.Add(Buffer[tr].States[i].account[5]); State1.Add(Buffer[tr].States[i].account[6]); State1.Add(Buffer[tr].States[i].account[7] / PrevBalance); State1.Add(Buffer[tr].States[i].account[8] / PrevBalance);
The prepared data is sufficient for the scheduler model and we can perform a forward pass through the model to determine the skill to use.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Scheduler.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
After performing a forward pass through the scheduler model and obtaining a vector of probabilities, we form a one-hot skill identification vector. Here we have two options for skill selection: greedy selection, which selects the skill with the highest probability, and sampling, in which we select the skill at random based on probabilities.
During the training phase, it is recommended to use sampling to maximize exploration of the environment. This allows the model to explore different skills and discover hidden capabilities and optimal strategies. During the training, sampling helps avoid premature convergence to a particular skill and allows for more varied exploration activities, promoting a more flexible and adaptive training model.
int skill = Scheduler.getSample(); SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; State1.AddArray(SchedulerResult);
The resulting skill identification vector is added to the source data buffer, which is passed to the input of the Agent model. After this, a forward pass through the Agent model is performed to generate the action. The probability distribution obtained from the model is used to sample the action.
Sampling an action from a probability distribution allows the Agent model to make a variety of decisions based on the probabilities of each action. This encourages exploration of different strategies and behavioral options, and also helps the model avoid prematurely fixating on a particular action.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } int action = Actor.getSample();
After performing a forward pass of the Agent model, we proceed to forming a data buffer for a forward pass of the Discriminator model, where the next state of the system will be described. Similar to the previous step, we start by loading historical data into a buffer. In this case, we simply copy the historical data from the example database into the data buffer without any hassle, since these indicators do not depend on the model and the skills used.
State1.AssignArray(Buffer[tr].States[i + 1].state);
We have some difficulties describing the account status. We cannot simply take data from the example database, as it will rarely match the selected action. Likewise, we cannot simply substitute an action from the example database, since the discriminator will analyze the state received as input and compare it with the skill used. This is where the gap arises.
However, it is important to note that the output of the discriminator is used only as a reward function. We do not require high precision in describing the new account balance state. Instead, we need comparability of data across different activities. Therefore, we can approximately estimate the values of the account state values based on the previous state, taking into account the size of the last candle and the selected action. We already have all the necessary data for the calculation.
At the first stage, we copy the account data from the previous state and calculate the profit for a long position when the price moves by the value of the last candle. Here we do not take into account the specific volume of the position and its direction. We will consider these parameters later.
vector<float> account; account.Assign(Buffer[tr].States[i].account); int bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT);
Then we make adjustments to the account information based on the action chosen. The simplest case is closing positions. We simply add the accumulated profit or loss to the current account balance. The resulting value is then transferred to the equity and free margin elements, and the remaining indicators are reset to zero.
When performing a trading operation, we need to increase the corresponding position. Considering that all trades are made with a minimum lot, we increase the size of the corresponding position by the minimum lot.
To calculate the accumulated profit or loss for each direction, we multiply the previously calculated profit for one lot by the size of the corresponding position. Since the profit for the long position was previously calculated, we add this value to the previous accumulated profit for the long positions and subtract it for the short ones. The total profit on the account is obtained by adding profits in different directions.
Equity is calculated as the sum of the balance and accumulated profit.
Margin indicators remain unchanged, since the change to the minimum lot will be insignificant.
In the case of holding a position, the approach is similar, with the exception of changing the position volume.
switch(action) { case 0: account[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 1: account[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; case 2: account[0] += account[4]; account[1] = account[0]; account[2] = account[0]; for(bar = 3; bar < AccountDescr; bar++) account[bar] = 0; break; case 3: account[7] += account[5] * (float)prof_1l; account[8] -= account[6] * (float)prof_1l; account[4] = account[7] + account[8]; account[1] = account[0] + account[4]; break; }
After adjusting the data on the balance status and open positions, we add them to the data buffer. In this case, as before, we convert their values into relative units and carry out a direct pass through the discriminator model.
PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; State1.Add((account[0] - PrevBalance) / PrevBalance); State1.Add(account[1] / PrevBalance); State1.Add((account[1] - PrevEquity) / PrevEquity); State1.Add(account[3] / 100.0f); State1.Add(account[4] / PrevBalance); State1.Add(account[5]); State1.Add(account[6]); State1.Add(account[7] / PrevBalance); State1.Add(account[8] / PrevBalance); //--- if(!Discriminator.feedForward(GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
After a forward pass of the discriminator, we compare its results with a one-hot vector, which contains the identification of the skill used in the forward pass of the agent.
Discriminator.getResults(DiscriminatorResult);
Actor.getResults(ActorResult);
ActorResult[action] = DiscriminatorResult.Loss(SchedulerResult, LOSS_CCE);
The cross-entropy value obtained by comparing the two vectors is used as the reward for the selected action. This reward allows us to back-pass the agent model and update its weights to improve future action selection.
Result.AssignArray(ActorResult); State1.AddArray(SchedulerResult); if(!Actor.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
The One-hot identity vector, which represents the skill being used, is the target value when training the discriminator model. We use this vector as a target to train the discriminator to correctly classify system states according to the selected skill.
Result.AssignArray(SchedulerResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
We only use account balance changes as a reward for the scheduler. We calculate this quantity accurately and convey it as relative values. However, unlike the agent, which receives rewards only for the selected action, we distribute the scheduler's reward across all skills based on the probabilities of choosing each skill. Thus, the scheduler's reward is divided among the skills according to their selection probabilities.
Result.AssignArray(SchedulerResult * ((account[0] - PrevBalance) / PrevBalance)); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State1), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Upon completion of each iteration of the learning cycle, we generate an information message containing data about the learning process. This message is displayed on a chart to visualize the process. We then move on to the next iteration, continuing the training process.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Upon completing the training process, we perform a message cleanup on the chart, removing previous information data. Then the EA shutdown is initiated.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Discriminator", Discriminator.getRecentAverageError()); ExpertRemove(); //--- }
The attachment contains the complete code of all methods and functions used in the EA. Check it out for detailed information.
3. Test
The model was trained on historical data of the EURUSD instrument with the H1 timeframe during the first four months of 2023. During the training process, a non-indicative error in the operation of the agent model was discovered, associated with the reward policy, which can lead to unlimited growth of rewards. However, the training process is still controlled by the performance of the scheduler and discriminator models.
The second feature of the process is the absence of a direct relationship between the choice of the scheduler and the action performed. The choice of planner has more influence on the choice of strategy than on the specific action. This means that the planner determines the overall decision-making approach, while the specific action is selected by the agent model based on the current state and the selected skill.
To test the performance of the trained model, we used data from the first two weeks of May 2023, which was not included in the training set but closely follows the training period. This approach allows us to evaluate the performance of the model on new data, while the data remains comparable, since there is no time gap between the training and test sets.
For testing, we used the modified "DIAYN\Test.mq5" EA. The changes made affected only the data preparation algorithms in accordance with the model architecture and the process of preparing source data. The sequence of calling direct passes of models has also been changed. The process is built similarly to the previously described advisors for collecting a database of examples and training models. The detailed EA code is available in the attachment.


As a result of testing the trained model, a small profit was achieved, with the profit factor of 1.61 and the recovery factor of 3.21. Within the 240 bars of the test period, the model made 119 trades, and almost 55% of them were closed with a profit.
A significant role in achieving these results was played by the scheduler, which evenly distributed the use of all skills. It is important to note that the greedy strategy was used to select actions and skills. The model selected the most profitable action based on the current state.

Conclusion
This article presented an approach to training a trading model based on the DIAYN (Diversity Is All You Need) method, which allows training the model in a variety of skills without being tied to a specific task.
The model was trained on historical data for the EURUSD instrument using the H1 timeframe during the first 4 months of 2023.
During the training, it was revealed that there was no direct relationship between the choice of the scheduler and the action performed. However, the training process remained controlled and showed some ability of the model to trade profitably.
After training was completed, the model was tested on new data that was not included in the training set. The testing results showed a small profit, the profit factor of 1.61 and the recovery factor of 3.21. However, to achieve more stable and better results, further optimization and improvement of the model strategy is required.
An important aspect of the model was the scheduler, which evenly distributed the use of all skills. This highlights the importance of developing effective decision-making strategies to achieve successful trading results.
In general, the presented approach to training a trading model based on the DIAYN method provides interesting prospects for the development of automated trading. Further research and improvements to this approach may lead to more efficient and profitable trading models.
List of references
Programs used in the article
| # | Name | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Example collection EA |
| 2 | Study.mql5 | Expert Advisor | Model training EA |
| 3 | Test.mq5 | Expert Advisor | Model testing EA |
| 4 | Trajectory.mqh | Class library | System state description structure |
| 5 | FQF.mqh | Class library | Class library for arranging the work of a fully parameterized model |
| 6 | NeuroNet.mqh | Class library | A library of classes for creating a neural network |
| 7 | NeuroNet.cl | Code Base | OpenCL program code library |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/12698
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Good evening,
If you want to configure by time, you can add one-hot vector of session identification and concatenate it with the vector of source data.
The second option is to add time-embedding to the source data. It can be configured with the desired periodicity. For trading sessions, a period of a day will do. For seasonality, you can set it to a year.