
Neural networks made easy (Part 44): Learning skills with dynamics in mind

Introduction
When solving forecasting problems in a complex stochastic environment, it is quite difficult, and often impossible, to train a model that would demonstrate acceptable results outside the training set. At the same time, breaking the problem into smaller subtasks significantly improves the performance of the overall model. In previous articles, we have already become acquainted with the construction of hierarchical models. Their architecture makes it possible to divide the solution of a problem into several subtasks. Each subtask will be solved by a separate simpler model. Here the question arises of correct training of skills that can be easily identified by the behavior of the model in a particular state.
In the previous article, we got acquainted with the DIAYN method, which allows you to train separable skills. This makes it possible to build a model that can change the agent behavior depending on the current state. As you might remember, the DIAYN algorithm provides rewards for unpredictable behavior. This allows us to teach skills with as many different behaviors as possible. But there is also another side to the coin. Such skills become difficult to predict. This complicates planning and managing the agent.
In this paradigm, a question arises of learning skills whose behavior would be easily predictable. At the same time, we are not ready to sacrifice the diversity of their behavior. A similar problem is solved by the authors of the Dynamics-Aware Discovery of Skills (DADS) method presented in 2020. Unlike DIAYN, the DADS method seeks to teach skills that not only have variety in behavior, but are also predictable.
1. Overview of DADS architecture and basic steps
Studying multiple individual behaviors and corresponding environmental changes allows model predictive control to be used for planning in behavior space rather than action space. In this regard, the main question is how we can obtain such behaviors, given that they can be random and unpredictable. The Dynamics-Aware Discovery of Skills (DADS) method proposes an unsupervised reinforcement learning system for learning low-level skills with the explicit goal of facilitating model-based control.
The skills learned using DADS are directly optimized for predictability, providing better insight from which predictive models can be learned. A key feature of skills is that they are acquired entirely through autonomous exploration. This means that the skill toolkit and its predictive model are learned before the task and reward function are designed. Thus, with a sufficient number, you can quite fully study the environment and develop skills to behave in it.
As in the DIAYN method, the DADS algorithm uses 2 models: a skill model (agent) and a discriminator (skill dynamics model).
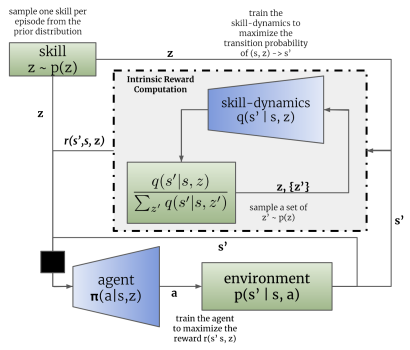
Models are trained sequentially and iteratively. First, the discriminator is trained to predict a future state based on the current state and the skill being used. To do this, the current state and the one-hot skill identification vector are fed to the input of the agent model. The agent generates an action that is executed in the environment. As a result of the action, the agent moves to a new state of the environment.
In turn, the discriminator, based on the same initial data, tries to predict a new state of the environment. In this case, the work of the discriminator resembles the work of the previously discussed auto encoder. However in this case, the decoder does not restore the original data from the latent state, but predicts the next state. Just like we trained the auto encoders, we train the discriminator using gradient descent.
As you can see, here lies the first difference between the DIAYN and DADS algorithms. In DIAYN, we determined the skill that brought us to this state based on the new state. The DADS discriminator performs the opposite functionality. Based on initial data and known skill, it predicts the subsequent state of the environment.
It should be noted here that the process is iterative. Therefore, we do not try to immediately achieve maximum likelihood. At the same time, we will need at least an initial approximation to train the agent.
After the first batch of discriminator training iterations, we move on to training the agent (skill model). Let's say right away that different packages of source data are used to train the discriminator and agent. However, this does not mean that it is necessary to create separate training samples. We share the same experience playback buffer. Only at each iteration, we randomly generate 2 separate batches of training data from this buffer.
Similar to the DIAYN method, the skill model is trained using reinforcement learning methods based on the reward generated by the discriminator. The difference, as always, is in the details. DADS uses a different mathematical equation to generate rewards. I will not now dwell on all the mathematical calculations and justification of the approach. You can find them in the original article. I will only consider the final reward equation.
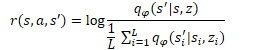
In the provided equation, q(s'|s,z) is the output of the discriminator for individual s initial state and z skill. L determines the number of skills. Thus, in the numerator of the reward equation, we see the predictive state for the analyzed skill. The denominator contains the average predicted state for all possible skills.
Using such a reward function allows us to solve the problem posed above. Since in the numerator we use the predicted state for the current skill, we reward the agent action that leads to achieving the predicted state. This achieves predictability of skill behavior.
At the same time, using the average state for all possible skills in the denominator allows us to reward more the skill behavior that will be as different as possible from the statistical average.
Thus, the DADS method achieves a balance between predictability and skill variety. This allows skills to be taught that have structured and predictable behavior while maintaining the ability to explore the environment.
Keep in mind that behavior of feedback from the discriminator and training of the skill model leads to a change in the behavior of the agent. As a result, its behavior will differ from the examples accumulated in the experience reproduction buffer. Therefore, to achieve an optimal result, we use an iterative process with sequential training of the discriminator and agent. During the process, the model training is repeated several times. In addition, the authors of the method propose using the importance coefficient, which is determined by the ratio of the probability of performing an action using the current agent policy to the probability of performing this action in the experience playback buffer. This allows more attention to be paid to the agent established behavior. At the same time, the influence of random actions is leveled out.
It should be noted that the DADS method was originally proposed for training skills and creating a model of the environment. As you can see, training a predictable skill and a dynamics model that allows us to predict a new state of the environment with a sufficient degree of probability allows us to plan several steps ahead. At the same time, in the planning process, we can move from specific actions to operating with a more general concept of skills. Specific actions will be determined by the agent in accordance with the planned skill.
However, at this stage, I decided not to move on to long-term planning and settled on training the scheduler to determine the skill for each individual step, just like in the previous article.
2. Implementation using MQL5
Let's move on to the practical implementation of the algorithm. Before moving directly to the implementation of the algorithm, we will decide on the architecture of the models.
Like DIAYN, we will use 3 models in our implementation. These are the agent (skill model), discriminator (dynamic model) and scheduler.
The algorithm provides that the agent determines the action to perform based on the current state and the selected skill. Therefore, the size of the source data layer should be sufficient to set a vector describing the current state and a one-hot vector identifying the selected skill.
At the agent output, we receive a vector of the probability distribution of the space of possible actions. As you can see, the initial data, functionality and result of the Agent are completely similar to the corresponding characteristics of the Agent of the DIAYN method. In this implementation, we will leave the Agent architecture unchanged. This will allow us to compare in practice the work of the 2 considered methods of training skills. However, this does not mean that another model architecture cannot be used.
Let me remind you that in the agent architecture we used a batch normalization layer to bring the source data into a comparable form.
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Normalized data is processed by a block of 2 convolutional and subsampling layers, which makes it possible to identify individual patterns and trends in the source data.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
The processed data after the convolutional layers is passed to the decision block, which contains fully connected layers and a fully parameterized quantile FQF model.
Using FQF as the output of the decision block allows us to get more accurate predictions of rewards after actions are taken, which take into account not only their average value, but also the probability distribution considering the stochasticity of the environment.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
As mentioned above, we did not create an environmental model in this implementation to make forecasts several steps ahead. Just like before, we will define the skill used at each step. Therefore, we also left the architecture and approaches to training the scheduler unchanged. Here we use a batch normalization layer to bring the raw data into a comparable form. The decision block consists of fully connected layers and an FQF model. Its results are transferred into the domain of probability distribution using the SoftMax layer.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
However, we have made changes to the architecture of the discriminator model. Let me remind you that the DADS algorithm uses the Dynamic model as a discriminator. According to the algorithm under consideration, it should predict a new state of the environment based on the current state and the selected skill. Also, the Dynamics model in the DADS method is used to predict future states when making plans several steps ahead. But, as mentioned above, we will not make long-term plans. This means that we may deviate slightly from predicting all indicators of the future state of the environment. As you know, our description of the state of the environment consists of 2 large blocks:
- historical data of price movement and indicators of analyzed indicators
- indicators of the current account status.
The influence of an individual trader on the state of the financial market is so insignificant that it can be neglected. Therefore, our agent actions do not affect the historical data. This means that we may exclude them from the formation of internal rewards when training our Agent. Since we will not make far-reaching plans, forecasting these indicators makes no sense. Thus, to form internal rewards, it is enough for us to predict the indicators of the future state of the account.
One more point should be noted. Look at the equation for forming the Agent internal reward. In addition to the forecast state for the analyzed skill, it also uses the average forecast state for all possible skills. This means that to determine one reward, we have to predict future states for all skills. In order to speed up the process of training models, it was decided to create a multi-head model output. The model will return predictive states for all possible skills based on a single initial data.
Thus, the source data layer of the Discriminator model is comparable to a similar layer of the Scheduler model and should be sufficient to record a description of the state of the system without taking into account the selected skill.
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; }
The received initial data undergoes primary processing in the batch normalization layer and is transferred to the decision-making block, consisting of a fully connected perceptron.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; }
The output of the model also uses a fully connected layer. Its size is equal to the product of the number of skills being taught and the number of elements to describe one state of the system. In this case, we indicate the number of elements of the account status description.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills*AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; }
It is worth noting that although we decided to use relative values of indicators for describing the state of the account in the previous article, nevertheless, these values do not seem to be normalized. We cannot use any one activation function when predicting them. Therefore, the output of the discriminator model uses a neural layer without an activation function.
The complete code for describing the architectures of all used models is collected in the CreateDescriptions function, which is placed in the library file "Trajectory.mqh". Transferring this function from the EA file to the library file allows us to use one model architecture at all stages of training and eliminates the need to manually copy the model architecture description between EAs.
While training models and testing the results obtained, we will use 3 EAs similar to training models using the DIAYN method. The primary data collection EA for training models "Research.mq5" has been transferred completely with virtually no changes. The changes affected only the name of the file for recording models and the architectural solutions described above. The full Expert Advisor code is available in the attachment.
The main changes for the implementation of the DADS algorithm were made to the model training EA "Study.mq5". First of all, this is monitoring the compliance of the model architecture with previously declared constants, which is carried out in the OnInit method. Here we have adjusted the controls to the modified model architectures.
Discriminator.getResults(DiscriminatorResult); if(DiscriminatorResult.Size() != NSkills * AccountDescr) { PrintFormat("The scope of the discriminator does not match the skills count (%d <> %d)", NSkills * AccountDescr, Result.Total()); return INIT_FAILED; } Scheduler.getResults(SchedulerResult); Scheduler.SetUpdateTarget(MathMax(Iterations / 100, 500000 / SchedulerBatch)); if(SchedulerResult.Size() != NSkills) { PrintFormat("The scope of the scheduler does not match the skills count (%d <> %d)", NSkills, Result.Total()); return INIT_FAILED; } Actor.getResults(ActorResult); Actor.SetUpdateTarget(MathMax(Iterations / 100, 500000 / AgentBatch * NSkills)); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Major changes have been made to the Train model training method. First, we will look at the 2 new auxiliary methods. The first method is GetNewState. In the body of this method, we will form the calculated state of balance indicators based on the previous state of the account, the planned action and the known "future" price movement.
Keep in mind that the method defines the calculated balance state, not the forecast one. There is a lot of meaning behind the wordplay here. The forecast value of balance parameters is carried out by the Dynamics model (Discriminator). In the current method, we define the calculated state of the balance based on our knowledge of subsequent price movements from the experience playback buffer. The need for such a calculation is caused by the high probability of a discrepancy between the agent’s action from the clipboard and the action generated by the agent taking into account the skill used and the updated behavior strategy. Data from the experience playback buffer allows us to accurately calculate account status and open positions for any agent action without the need to repeat the action in the strategy tester. This allows us to significantly expand the training set and thereby improve the quality of model training. Similar functionality has already been implemented in the previous article. Arranging a separate method is caused by multiple calls to this functionality during the process of training models.
In the parameters, the method receives a dynamic array of account description parameters at the decision-making stage, the action ID and the value of profit/loss from the subsequent price movement per 1 lot of a long position. As a result of operations, this method will return a vector of values describing the subsequent state of the account, taking into account the specified action.
In the body of the method, we create a vector to record the results and transfer the initial values into it in the form of the initial state of the account.
vector<float> GetNewState(float &prev_account[], int action, double prof_1l) { vector<float> result; //--- result.Assign(prev_account);
Next, branching is carried out depending on the action being performed. In the event of a trading operation of opening or adding to a position, we calculate the new value of open positions in the corresponding direction. Next, we calculate the change in accumulated profit/loss for each direction, taking into account the size of the open position and the subsequent price movement. The value of the accumulated profit/loss on the account is equal to the sum of the 2 indicators calculated above. By adding the resulting value with the balance indicator, we get the account equity.
switch(action) { case 0: result[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; case 1: result[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break;
If all open positions are closed, we simply add the value of the accumulated profit to the current balance. We copy the resulting value into equity and free margin. Reset the remaining parameters to zero.
case 2: result[0] += result[4]; result[1] = result[0]; result[2] = result[0]; for(int i = 3; i < AccountDescr; i++) result[i] = 0; break;
Recalculation of the parameters when waiting (no agent action) is similar to the trading operation of opening a position, with the exception of changes in the volume of open positions. This means that we only recalculate the accumulated profit/loss and equity for previously opened positions.
case 3: result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; } //--- return result return result; }
After recalculating all the parameters, we return the resulting vector of values to the calling program.
The second method we will add is to be used to calculate the amount of internal reward to the agent based on the predicted values of the discriminator, the selected skill and the previous account state.
Note that the agent receives a reward for a specific action. But we do not indicate the action selected by the agent in the method parameters. In fact, here we can notice a certain gap between the agent forecast and the reward received. After all, there is a possibility that the action chosen by the agent will not lead to the state predicted by the discriminator. Of course, in the process of training the agent and the discriminator, the probability of such a gap will decrease. Nevertheless, it will remain. At the same time, it is important for us that the reward corresponds to the action leading to the predicted state. Otherwise, we will not get the predicted behavior of the skills. That is why we will determine the rewarded action from 2 subsequent states: current and predictive for the selected skill.
So, the GetAgentReward function receives in its parameters the selected skill, the vector of results of the forward pass of the discriminator and an array describing the previous balance state. As a result of the function operation, we plan to obtain a vector of agent rewards.
We will have to conduct some preparatory work in the method body. The discriminator forward pass results vector contains predictive states for all possible skills. In order to determine the reward, we have to isolate individual skills and calculate average values in the context of individual parameters. Matrix operations will help us with this task. First, we need to reformat the vector of discriminator results into a matrix.
We create a new matrix of 1 row, while the number of columns is equal to the number of elements in the discriminator result vector. Let's copy the values from the vector into the matrix. Then reformat the matrix into a rectangular one, in which the number of rows will correspond to the number of skills, and the number of columns will be equal to the size of the vector describing one state. It is very important in this case to use the Reshape method and not the Resize one, since the first one redistributes the existing values in a matrix of a new format. The second one only changes the number of rows and columns without redistributing the existing elements. In this case, we will simply lose all data except the first skill. The added rows will be filled with random values.
vector<float> GetAgentReward(int skill, vector<float> &discriminator, float &prev_account[]) { //--- prepare matrix<float> discriminator_matrix; discriminator_matrix.Init(1, discriminator.Size()); discriminator_matrix.Row(discriminator,0); discriminator_matrix.Reshape(NSkills, AccountDescr); vector<float> forecast = discriminator_matrix.Row(skill);
Now we only have to extract the values of the corresponding row to retrieve the predictive state vector of the skill we are interested in.
Next, we need to determine the action for which the agent will receive rewards. Our main parameter of a trading operation is a change in position. I admit that there may be many conventions here. But their use will help us identify operations that will allow us to get closer to the forecast state with a reasonable degree of probability. This is what makes our model manageable and predictable.
First of all, we determine the change in position in each direction. If we have a decrease in the size of open positions in both directions, then we consider the action of closing positions to be most likely. Otherwise, we give preference to the largest change in position. We believe that a new deal was opened in this direction or an addition was made.
If the changes are equal, we simply wait. According to probability theory using floating point values, this outcome is the least likely. Thus, we want to stimulate the model to take active action.
//--- check action int action = 3; float buy = forecast[5] - prev_account[5]; float sell = forecast[6] - prev_account[6]; if(buy < 0 && sell < 0) action = 2; else if(buy > sell) action = 0; else if(buy < sell) action = 1;
Now that we have defined the rewarded action and prepared the data for calculations, we can proceed directly to filling out the reward vector.
First, we form a vector of zero values along the dimension of the action space. Next, we will divide the vector of predicted values of the skill we are interested in by the vector of average predicted values for all skills. From the resulting vector, we take the average value. We assume the possibility of obtaining a negative value as a result of performing these operations. Therefore, we will take its absolute value into the logarithm. This absolutely does not contradict the primary task since we want to maximize the reward for the most non-standard actions, which are as far as possible from the vector of average values. As an alternative solution, which will also help eliminate division by zero, I can suggest using the Euclidean distance between the vector of the analyzed skill and the vector of average values. Let's test the quality of the approaches in practice.
//--- calculate reward vector<float> result = vector<float>::Zeros(NActions); float mean = (forecast / discriminator_matrix.Mean(0)).Mean(); result[action] = MathLog(MathAbs(mean)); //--- return result return result; }
Set the resulting reward value into the vector element that corresponds to the previously defined action. At the end of the function operations, return the resulting reward vector to the calling program.
After completing the preparatory work, we move on to training our Train models. Here we first declare a number of local variables and determine the number of previously loaded training set trajectories.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action; int skill, shift;
Next, we arrange a system of cycles for the model training process. I should say right away that according to the DADS algorithm, model training is carried out sequentially and iteratively. We train the Discriminator (phase 0) first. Then we train the Agent (phase 1). And last but not least is the Scheduler (phase 2). The whole process is repeated several iterations. The number of iterations is set in the external parameters of the EA. In addition, we will indicate the size of the training package for each phase in the external parameters of the EA.
Now we will declare a system of nested loops in the body of the function. The external loop determines the number of iterations of the training process. The nested loop will determine the training phase.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { for(int phase = 0; phase < 3; phase++) {
The nested loop could be replaced with a sequence of operations. But this approach made it possible to eliminate the copying of common operations, such as loading the initial state from the playback buffer before directly passing of the models.
The operations of each training phase are repeated in the size of the training package, which is specified in the external parameters of the EA for each phase separately. Therefore, we first determine the size of the corresponding training package. Then we will create another nested loop with the required number of repetitions.
int batch = 0; switch(phase) { case 0: batch = DiscriminatorBatch; break; case 1: batch = AgentBatch; break; case 2: batch = SchedulerBatch; break; default: PrintFormat("Incorrect phase %d"); batch = 0; break; } for(int batch_iter = 0; batch_iter < batch; batch_iter++) {
Next, the process of directly training the models begins. First, we need to prepare the initial data. We randomly select them from the experience playback buffer. Here we randomly select a pass and a state from that pass.
int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Then we load the data describing the current state of the system into the data buffer.
State.AssignArray(Buffer[tr].States[i].state);
Then we convert the account data into relative units and add a buffer.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
At this stage, we can perform a direct pass of the models. But before we branch out the flow of operations depending on the current training phase, we will also prepare the data we are going to need at each phase of operations to calculate the estimated future state of the account.
bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
After all general operations have been completed, we proceed to dividing the flow of operations depending on the current phase of training.
As mentioned above, the learning process begins with training the discriminator model. First of all, we carry out a direct pass through the model based on previously prepared source data and check the correctness of the operations.
switch(phase) { case 0: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
We receive a vector of predictive states for all the skills being studied at the output of the discriminator. Therefore, we also have to generate target states for all skills to prepare target values. To achieve this, we will arrange the cycle according to the number of skills studied. Then we will carry out a direct pass of our agent for each individual skill in the body of the cycle.
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Based on the results of the forward pass, we sample the agent action. I want to focus specifically on action sampling. Since this will help to diversify the agent actions as much as possible and contribute to a comprehensive study of the environment.
Based on the initial state of the system, the sampled action and the experience of the subsequent price movement known from the playback buffer, we calculate the next state of the account and fill in the appropriate block of target discriminator values. Then we move on to handling the next skill.
action = Actor.getSample(); account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); shift = skill * AccountDescr; DiscriminatorResult[shift] = (account[0] - PrevBalance) / PrevBalance; DiscriminatorResult[shift + 1] = account[1] / PrevBalance; DiscriminatorResult[shift + 2] = (account[1] - PrevEquity) / PrevEquity; DiscriminatorResult[shift + 3] = account[2] / PrevBalance; DiscriminatorResult[shift + 4] = account[4] / PrevBalance; DiscriminatorResult[shift + 5] = account[5]; DiscriminatorResult[shift + 6] = account[6]; DiscriminatorResult[shift + 7] = account[7] / PrevBalance; DiscriminatorResult[shift + 8] = account[8] / PrevBalance; }
After preparing the target data, we perform a backward pass of the discriminator.
if(!Result) { Result = new CBufferFloat(); if(!Result) { PrintFormat("Error of create buffer %d", GetLastError()); ExpertRemove(); break; } } Result.AssignArray(DiscriminatorResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
In the next block, we will look at the iterations of the next phase of the training process - Agent training. Let me remind you that we prepared the initial data before dividing the flow of operations depending on the training phase. This means that by now we already have a generated buffer of source data. Therefore, we perform a forward pass of the discriminator and extract the results of the operations, since we will need them to form the internal reward.
case 1: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Discriminator.getResults(DiscriminatorResult);
Next, as in the previous phase of training, we organize a cyclical process of sequentially enumerating all skills for the current state.
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
In the body of the loop, we organize the operations of forward passage of the agent, formation of the reward vector and reverse passage of the model.
reward = GetAgentReward(skill, DiscriminatorResult, Buffer[tr].States[i].account); Result.AssignArray(reward); StateSkill.AssignArray(Buffer[tr].States[i + 1].state); account = GetNewState(Buffer[tr].States[i].account, Actor.getAction(), prof_1l); shift = skill * AccountDescr; StateSkill.Add((account[0] - PrevBalance) / PrevBalance); StateSkill.Add(account[1] / PrevBalance); StateSkill.Add((account[1] - PrevEquity) / PrevEquity); StateSkill.Add(account[2] / PrevBalance); StateSkill.Add(account[4] / PrevBalance); StateSkill.Add(account[5]); StateSkill.Add(account[6]); StateSkill.Add(account[7] / PrevBalance); StateSkill.Add(account[8] / PrevBalance); if(!Actor.backProp(Result, DiscountFactor, GetPointer(StateSkill), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } } break;
As you can see, the full enumeration of skills is slightly inconsistent with the general previously used paradigm of using random states. We remain faithful to the sampling in terms of determining the trajectory and the initial state. By completely enumerating skills for one individual state, we want to focus the model attention specifically on the skill identification indicators. After all, it is changes in the skill that should be a signal for the model to change the behavior strategy.
The next stage of our implementation of the DADS algorithm is training the scheduler. This process almost completely repeats the similar functionality in the implementation of the DIAYN method. First, a direct pass through the scheduler is carried out and we obtain a probabilistic distribution of skills. But unlike the previous implementation, we will neither sample nor carry out greedy skill selection. We understand that in real conditions there are no clear boundaries for dividing one strategy or another. These boundaries are very blurred. All the divisions are filled with various tolerances and compromises. Under such conditions, the decision arises to transfer the full probability distribution to the agent for decision making.
case 2: if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Scheduler.getResults(SchedulerResult);
I would like to draw your attention to the fact that during the agent training, clearly defined skill IDs were passed on to it. So, the experiment with transferring the full probability distribution to the agent for further decision-making becomes even more interesting. After all, such initial data goes beyond the training set, which makes the behavior of the model unpredictable.
State.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } action = Actor.getAction();
Based on the results of the forward pass, we greedily select the agent action. After all, our goal is to train the planner to manage decision-making policy at the skill level. This is only possible when using predictable skills whose behavior is determined by a meaningful and consistent strategy.
Next, we determine the estimated subsequent state of the account description indicators and, based on them, form the model reward vector. As you might remember, we use the relative change in account balance as the external reward of the model.
account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); SchedulerResult = SchedulerResult * (account[0] / PrevBalance - 1.0); Result.AssignArray(SchedulerResult); State.AssignArray(Buffer[tr].States[i + 1].state); State.Add((account[0] - PrevBalance) / PrevBalance); State.Add(account[1] / PrevBalance); State.Add((account[1] - PrevEquity) / PrevEquity); State.Add(account[2] / PrevBalance); State.Add(account[4] / PrevBalance); State.Add(account[5]); State.Add(account[6]); State.Add(account[7] / PrevBalance); State.Add(account[8] / PrevBalance); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
After preparing the model reward vector and subsequent system state, we perform a backward pass through the scheduler model.
default: PrintFormat("Wrong phase %d", phase); break; } } } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
At the end of the operations in the body of the model training cycle system, we display a message informing the user about the model training progress.
The remaining EA methods and functions, as well as the EA for testing the trained model, were transferred without changes. The full code of all programs used in the article can be found in the attachment in the MQL5\Experts\DADS directory.
3. Test
The models were trained on historical data for the first 4 months of 2023 on EURUSD H1. Indicators were used with default parameters. As you can see, the testing parameters are taken without changes from the previous article. This allows us to compare the results of two skill training methods.
To check the performance of the trained model, the test was carried out in the strategy tester on the time period of May 2023. In other words, the test of the trained model was carried out outside the training sample on a time interval of 25% of the training sample.
The model demonstrated the ability to generate profit with a profit factor of 1.75 and the recovery factor of 0.85. The share of profitable trades was 52.64%. At the same time, the average income of a profitable trade is 57.37% exceeding the average losing trade (2.99 versus -1.90).



We can also note the almost uniform use of skills. All skills were involved in the test.
While testing the trained model, the Agent was given not just one greedily selected skill, but a complete probability distribution generated by the scheduler. Moreover, each agent action was selected using a greedy strategy by the maximum predicted reward. This approach gives the scheduler maximum control over the model operation and eliminates the stochasticity of the Agent actions, which is possible during sampling. As you might remember, this is how we trained the Scheduler model.
It is noteworthy that the experiment with greedy skill selection showed similar results. The greedy choice of skill allowed us to increase the profit factor to 1.80. The share of profitable transactions increased by 0.91% to 53.55%. Here we also observe an increase in the average profitable trade to 3.08.

Conclusion
In this article, we have introduced another method of unsupervised skill training, Dynamics-Aware Discovery of Skills (DADS). Using this method allows training a variety of skills that can effectively explore the environment. At the same time, skills trained by the proposed method have fairly predictable behavior. This makes scheduler training easier and increases the stability of the trained model in general.
We have also implemented the considered algorithm using MQL5 and tested the constructed model. The test yielded encouraging results that demonstrate the model’s ability to generate profits beyond the training set.
However, all programs presented and used in the article are intended only to demonstrate the work of the approaches and are not ready for use in real trading.
List of references
Programs used in the article
| # | Name | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Example collection EA |
| 2 | Study.mql5 | Expert Advisor | Model training EA |
| 3 | Test.mq5 | Expert Advisor | Model testing EA |
| 4 | Trajectory.mqh | Class library | System state description structure |
| 5 | FQF.mqh | Class library | Class library for arranging the work of a fully parameterized model |
| 6 | NeuroNet.mqh | Class library | A library of classes for creating a neural network |
| 7 | NeuroNet.cl | Code Base | OpenCL program code library |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/12750
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
when stating the strategy tester.
I have searched a lot, do I need to create the file by myself? and if yes, where should I do that?
In all previous ones I get this error:
when stating the strategy tester.
I have searched a lot, do I need to create the file by myself? and if yes, where should I do that?
Hi, what's EA back error?
At first you must run Research.mq5 in strategy tester. And then run Study.mq5 in real mode.