
Reguläre Ausdrücke für Trader

Einführung
Reguläre Ausdrücke (eng. regular expressions) stellen ein besonderes Werkzeug, eine Sprache für die Textverarbeitung nach einem gegebenen Muster dar. Dieses Muster oder ein Pattern, hat auch andere Namen - eine Schablone oder ein regulärer Ausdruck. Die Syntax der regulären Ausdrücke wird durch Regeln und Meta-Zeichen definiert.
Reguläre Ausdrücke können zwei grundlegende Aufgaben erledigen:
- Suche nach Mustern in einer Zeile;
- Die Ersetzung des gefundenen Musters.
Bei der Bildung der Musters für reguläre Ausdrücke, wie wir bereits geschrieben haben, verwendet man spezielle Zeichen, Meta-Zeichen und Klassen (Sets) von Zeichen. Dies bedeutet, dass ein regulärer Ausdruck eigentlich eine einfache Zeile ist, und alle nicht-spezifischen (nicht reservierten) Zeichen drin als konventionell gelten.
Die Suche nach einem bestimmten Muster in einer Zeile wird vom Verarbeiter der regulären Ausdrücke durchgeführt. In .NET Framework, auch — in der Bibliothek RegularExpressions für MQL5, der Verarbeiter der regulären Ausdrücke führt diese Suche mit der Rückgabe für reguläre Ausdrücke durch. Es ist eine Variante der traditionellen NFA-Maschine (nicht-deterministischer endgültiger Automat), ähnlich mit denen, die in Perl, Python, Emacs und Tcl. verwendet werden. Die Ersetzung der Übereinstimmungen in der Zeile wird eben von ihm durchgeführt.
1. Die Grundlagen der regulären Ausdrücke
Die Metazeichen - sind spezielle Zeichen, die Kommando- und Kontrollreihenfolgen eingeben, wie Kontrollreihenfolgen in MQL5 und C # funktionieren. Solche Symbole werden durch einen Backslash (\) vorangestellt, jeder von ihnen hat einen bestimmten Zweck.
In den folgenden Tabellen wurden die Metazeichen der regulären Ausdrücke MQL5 und C # von Bedeutung gruppiert.
1.1. Die Symboleklassen:
| Symbol | Werte | Beispiel | Entspricht |
|---|---|---|---|
| [...] | jedem Symbol, welches in Klammern eingegeben wurde | [a-z] | In der Anfangszeile kann ein Symbol vom englischen Alphabet im unteren Register sein |
| [^...] | jedes Symbol, welches in Klammern eingegeben wurde | [^0-9] | In der Anfangszeile kann ein Symbol sein, außer einer Zahl |
| . | Jedes Symbol, außer Newline oder einem anderen Separator der Unicode-Zeile | ta.d | "trad" in der Zeile "trade" |
| \w | Ein beliebiges Textzeichen, welches kein Leerzeichen ist, oder Tabulationszeichen, u.s.w. | \w | "M","Q","L","5" in der Zeile "MQL 5" |
| \W | jedes Symbol, welches kein Textzeichen ist | \W | " ", "." in der Zeile "MQL 5." |
| \s | jedes Leer-Symbol aus dem Unicode-Satz | \w\s | "L " in der Zeile "MQL 5" |
| \S | jedes nicht leeres Symbol aus dem Unicode-Satz. Bitte beachten Sie, dass Symbole \w und \S - ist es nicht das gleiche |
\S | "M", "Q", "L", "5", "." in der Zeile "MQL 5." |
| \d | Jede ASCII-Zeilen. Gleichwertig [0-9] | \d | "5" in "MQL 5." |
1.2. Die Wiederholungssymbole:
| Symbol | Werte | Beispiel | Entspricht |
|---|---|---|---|
| {n,m} | Entspricht dem vorhergehenden Muster, das mindestens n und höchstens m mal wiederholt wurde | s{2,4} | "Press", "ssl", "progressss" |
| {n,} | Entspricht dem vorhergehenden Muster, das n mal und höchstens | s{1,} mal wiederholt wurde | "ssl" |
| {n} | Entspricht genauso n-Exemplars von dem vorhergehenden Muster | s{2} | "Press", "ssl", aber nicht "progressss" |
| ? | Entspricht 0 oder einem Exemplar von dem vorhergehenden Muster; das vorhergehende Muster ist nicht nötig |
Gleichwertig {0,1} | |
| + | Entspricht einem oder mehreren Exemplars von dem vorhergehenden Muster | Gleichwertig {1,} | |
| * | Entspricht 0 oder mehreren Exemplars von dem vorhergehenden Muster | Gleichwertig {0,} |
1.3. Die Wahl-Symbole der regulären Ausdrücke:
| Symbol | Werte | Beispiel | Entspricht |
|---|---|---|---|
| | | Entspricht entweder dem linken Unterausdruck, oder dem rechten Unterausdruck (die Analog der logischen Operation ODER). | 1(1|2)0 | "110", "120" in der Zeile "100, 110, 120, 130" |
| (...) | Gruppierung. Die gruppiert die Elemente in einer einzigen Einheit, die mit den Symbolen *, +, ?, | u.s.w. verwendet werden kann Speichert auch die Symbole, die dieser Gruppe für die Verwendung in nachfolgenden Links entsprechen. |
||
| (?:...) | Es ist nur Gruppierung. Die gruppiert die Elemente in einer einzigen Einheit, aber speichert nicht die Symbole, die dieser Gruppe entsprechen. |
1.4. Anker-Symbole von regulären Ausdrücken:
| Symbol | Werte | Beispiel | Entspricht |
|---|---|---|---|
| ^ | Das entspricht dem Anfang des Zeilesausdrucks oder dem Anfang der Zeile bei der mehrzeiligen Suche. | ^Hello | "Hello, world", aber nicht "Ok, Hello world" denn das Wort "Hello" ist in dieser Zeile nicht an Anfang |
| $ | Das entspricht dem Ende des Zeilesausdrucks oder dem Ende der Zeile bei der mehrzeiligen Suche. | Hello$ | "World, Hello" |
| \b | Entspricht der Grenze des Wortes, das heißt entspricht der Position zwischen den Symbolen \w und \W oder zwischen dem Symbol \w und dem Anfang oder dem Ende der Zeile. |
\b(my)\b | In der Zeile "Hello my world" wählt das Wort "my"aus |
Weitere Informationen über die Elemente von regulären Ausdrücken können Sie im Artikel auf der offiziellen Website Microsoft lesen.
2. Besonderheiten für die Realisierung der regulären Ausdrücke für MQL5
2.1. Die Fremddateien im Ordner Internal gespeichert sind
Für die maximale ähnliche Realisierung RegularExpressions für MQL5 zum Anfangscode .Net haben wir gebraucht, ein Teil der Fremddateien zu übertragen. Sie bleiben alle im Ordner Internal gespeichert und sind auch interessant.
Betrachten wir gründlicher den Inhalt des Ordners Internal.
- Generic — in diesem Ordner wurden die Dateien für die Realisierung von stark typisierten Sammlungen, Aufzählungen und Interface für sie angeordnet. Die genauere Beschreibung wird unten aufgeführt.
- TimeSpan — Die Dateien für die Realisierung der TimeSpan Struktur, die das Zeitintervall darstellt.
- Array.mqh — in dieser Datei wurde die Klasse Array realisiert, für die wiederum eine Reihe von statischen Methoden für Arbeiten mit Arrays hat. Zum Beispiel: Sortierung, binäre Suche, die Aufzählungen erhalten, ein Index des Elementes und andere erhalten.
- DynamicMatrix.mqh — in dieser Datei gibt es zwei Hauptklassen für die mehrdimensionale dynamische Arrays zu realisieren. Diese Klassen sind strukturiert und somit geeignet für Standardtypen und Verweise auf Klassen.
- IComparable.mqh — Die Datei, die die Interface IComparable realisiert, ist erforderlich, um eine Vielzahl von Methoden in typisierten Sammlungen zu unterstützen.
- Wrappers.mqh — die Wrapper für Standardtypen und Methoden für die Suche nach Hash-Codes.
in Generic wurden drei streng typisierten Sammlungen realisiert:
- List<T> ist eine stark typisierte Liste von Objekten, die auf dem Index zur Verfügung stehen. Es unterstützt die Methoden für die Suche in der Liste, die Ausführung der Sortierung und andere Operationen mit Listen.
- Dictionary<TKey,TValue> ist eine Sammlung von Schlüsseln und Werten.
- LinkedList<T> ist eine doppelt verknüpfte Liste.
Wir betrachten die Verwendung von List<T> aus dem Experte TradeHistoryParsing. Dieser Experte liest die Handelshistory aus der .html-Datei und filtert sie nach den ausgewählten Spalten und Dateneinträgen. Die Handelshistory besteht aus zwei Tabellen: Aufträge und Orders. Die Klassen OrderRecord und DealRecord interpretieren einen Eintrag (Tupel) aus den Tabellen Orders und Aufträge. Folglich kann jede der Tabellen als eine Liste ihrer Einträge dargestellt werden:
List<OrderRecord*>*m_list1 = new List<OrderRecord*>(); List<DealRecord*>*m_list2 = new List<DealRecord*>();
Da die Klasse List<T> die Sortierungs-Methoden unterstützt, heißt das, müssen Objekte vom Typ T miteinander vergleichbar sein. Mit anderen Worten, für diese Art wurden die folgenden Operationen realisiert <,>,==. Falls es mit Standardelementen alles gut ist, aber wenn wir eine List <T> erstellen müssen, wo T - ein Zeiger auf die benutzerdefinierte Klasse ist, wir erhalten einen Fehler. Das Problem kann man mit zwei Arten lösen. Erstens können wir in unserer Klasse explizit Vergleichsoperatoren überlasten. Eine andere Lösung - die Klasse dem Nachfolger von der IComparable-Interface zu machen. Die zweite Art ist wesentlich kürzer bei der Umsetzung, aber die Richtigkeit der Sortierung wird verletzt. In Fällen, in denen ein Bedarf besteht, die Sortierungen für benutzerdefinierten Klassen zu machen, müssen wir alle Vergleichsoperatoren neu zu laden, und außerdem ist es wünschenswert, den Nachfolger zu realisieren.
Dies ist nur eine von den Merkmalen der Klasse List<T>. Genauere wird es unten betrachtet.
Dictionary<TKey,TValue> — eine Art des Wörterbuchs aus einer Reihe von Werten und der entsprechenden eindeutigen Schlüssel. Dabei kann ein Schlüssel zu mehreren Werten verbunden sein. Die Arten von Schlüsseln und Werten wird der Anwender bei der Erstellung des Objekts definieren. Wie aus der Beschreibung ersichtlich ist, die Klasse Dictionary<TKey,TValue> ist perfekt für die Rolle der Hash-Tabelle. Um die Arbeit mit Dictionary<TKey,TValue> zu beschleunigen, muss eine neue Klasse erstellt werden, die ein Nachfolger der Klasse IEqualityComparer<T> sein wird und startet zwei Funktionen neu:
- bool Equals(T x,T y) — die Funktion gibt true zurück, wenn x dem y gleich ist, anderenfalls false.
- int GetHashCode(T obj) — die Funktion gibt Hash-Code des Objekts obj zurück.
In der Bibliothek RegularExpresiions für MQL5 ist diese Besonderheit in allen Wörterbüchern verwendet, bei denen die Zeile als Schlüssel dient.
Die Realisierung der Klasse StringEqualityComparer:
class StringEqualityComparer : public IEqualityComparer<string> { public: //--- Methods: //+------------------------------------------------------------------+ //| Determines whether the specified objects are equal. | //+------------------------------------------------------------------+ virtual bool Equals(string x,string y) { if(StringLen(x)!=StringLen(y)){ return (false); } else { for(int i=0; i<StringLen(x); i++) if(StringGetCharacter(x,i)!=StringGetCharacter(y,i)){ return (false); } } return (true); } int GetHashCode(string obj) { return (::GetHashCode(obj)); } };
Nun, wenn Sie ein neues Objekt erstellen, die zur Klasse Dictionary<TKey,TValue> gehört, wo die Zeilen als die Schlüssel gelten, im Konstruktor als Parameter leiten wir eine Anzeige zum Objekt StringEqualityComparer zu:
Dictionary<string,int> *dictionary= new Dictionary<string,int>(new StringEqualityComparer);
LinkedList<T> — das ist die Struktur der Daten, die ein paar Elementen enthält. Jedes Element enthält einen Informationsteil und zwei Zeiger: auf das vorhergehende und folgende Element. Dementsprechend verweisen aufeinander die beiden Schließelemente. Die Knoten einer solchen Liste werden von Objekten LinkedListNode <T> realisiert. In jedem solchen Knoten enthält einen Standardsatz: der Wert, ein Zeiger auf die Liste und die Zeiger auf die benachbarten Knoten.
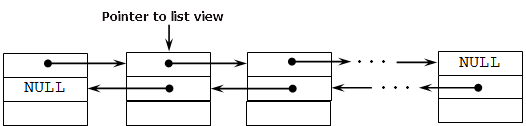
Auch für alle drei der oben genannten Sammlungen wurden Aufzählungen realisiert. Die Aufzählung — ist ein Objekt, das eine generische Interface IEnumerator<T> darstellt. IEnumerator<T> ermöglicht einen vollständigen Crawl für die Sammlung, unabhängig von seiner Struktur zu realisieren.
Für die Erhaltung des Aufzählers muss die Methode GetEnumerator() von einem Objekt aufgerufen werden, deren Klasse die IEnumerable-Interface realisiert:
List<int>* list = new List<int>(); list.Add(0); list.Add(1); list.Add(2); IEnumerator<int> *en = list.GetEnumerator(); while(en.MoveNext()) { Print(en.Current()); } delete en; delete list;
In diesem Beispiel werden wir durch die gesamte Liste laufen und jeden Wert drucken. All dies könnte durch eine regelmäßige Loop for durchgeführt werden, doch oft dieser Ansatz mit der Verwendung des Aufzählers ist bequemer. Insbesondere ist eine solche Lösung geeignet, wenn Sie über Dictionary <TKey, TValue> durchführen wollen.
2.2. Die Besonderheiten der Bibliothek RegularExpressions für MQL5.
1. Um die gesamte Funktionalität von regulären Ausdrücken zu unserem Projekt hinzuzufügen, müssen Sie das folgende Fragment hinzufügen:
#include <RegularExpressions\Regex.mqh>
2. Aufgrund der Abwesenheit in MQL5 der Namensbereiche, und in Folge — weil es keinen Zugriffsmodifikator gibt, wie internal, haben wir den Zugriff zu allen internen Klassenbibliotheken, und zu vielen Methoden für sie. In der Tat ist es nicht notwendig, bei der Arbeit mit regulären Ausdrücken.
Um mit regulären Ausdrücken zu arbeiten, sind für uns die folgenden Klassen interessant:
- Capture — stellt die Ergebnisse einer erfolgreichen Aufzeichnung des Ausdrucks dar.
- CaptureCollection — stellt eine Reihe von Einträgen von einer Gruppe dar.
- Group — stellt die Ergebnisse einer einzelnen Einträge-Gruppe dar.
- GroupCollection — gibt eine Reihe der aufgenommenen Gruppen im selben Vergleich zurück.
- Math — stellt die Ergebnisse aus einer separaten Übereinstimmung eines regulären Ausdrucks dar.
- MathCollection — ist eine Reihe von erfolgreichen Übereinstimmungen, die durch die iterative Verwendung eines Musters eines regulären Ausdrucks zur Eingangszeile gefunden wurden.
- Regex — stellt einen unveränderlichen regulären Ausdruck dar.
Zusätzlich zu dem obigen, verwenden wir noch:
- MatchEvaluator — ein Funktionszeiger, der ein Verfahren darstellt, welches jedes Mal aufgerufen wird, wenn eine Übereinstimmung eines regulären Ausdrucks gefunden ist.
- RegexOptions — die Aufzählung, die bei der Festlegung der Parameter von regulären Ausdrücken Werte für die Verwendung zur Verfügung stellt.
RegexOptions — eine unvollständige Kopie der anfangs Aufzählung aus .Net und es umfasst die folgenden Elemente:
| Paramter | Beschreibung |
|---|---|
| None |
Die Parameter wurden nicht eingestellt. |
| IgnoreCase |
Der Register wird bei der Suche nach Übereinstimmungen nicht berücksichtigt. |
| Multiline | wird ein mehrzeiliger Modus angegeben. |
| ExplicitCapture | erfasst die unbenannten Gruppen. Die einzige gültige Auswahl - ist die eindeutig benannten oder nummerierten Gruppen im Format (?<der Name> Der Teil des Ausdrucks). |
| Singleline | gibt ein einzeiliger Modus an. |
| IgnorePatternWhitespace | entfernt aus der Vorlage das Trennzeichen ohne escape-Reihenfolge und fügt die Kommentare hinzu, die mit dem Symbol "#" markiert sind. |
| RightToLeft | gibt an, dass die Suche in Richtung von rechts nach links durchgeführt wird, und nicht von links nach rechts. |
| Debug | gibt an, dass das Programm unter dem Debugger ausgeführt wird. |
| ECMAScript | hat ECMAScript-bestimmtes Verhalten für den Ausdruck. Dieser Wert kann nur zusammen mit den Werten IgnoreCase und Multiline verwendet werden. |
Diese Optionen werden bei der Erstellung eines neuen Objekts Regex oder beim Aufruf seinen statischen Methoden verwendet.
Die Beispiele für die Verwendung all dieser Klassen, auch für die Zeiger und Transfers können Sie im Quellcode des Experten Tests.mq5 finden
3. Wie in der Version für .Net, wurde in dieser Bibliothek die Lagerung (statische Cache) der regulären Ausdrücke realisiert. Alle implizit erstellte reguläre Ausdrücke (Die Muster der Regex-Klasse) werden zur Lagerung eingetragen. Dieser Ansatz beschleunigt den Arbeitsprozess bei Skripten, weil es keine Notwendigkeit mehr gibt, einen regulären Ausdruck neu zu bauen, wenn deren Muster mit einem verfügbaren Muster entspricht. Die Standardspeichergröße beträgt 15. Die Methode Regex::CacheSize() gibt oder legt die maximale Anzahl der Dateneinträge in der aktuellen statischen Cache-Speicher von kompilierten regulären Ausdrücken.
4. Der oben erwähnte Speicher muss gereinigt werden. Dafür wird die statische Funktion Regex::ClearCache() aufgerufen. Dies empfiehlt sich nur, wenn Sie die Arbeit mit regulären Ausdrücken beendet haben, sonst wird es wahrscheinlich der richtige Zeiger und die richtige Objekte entfernt.
5. Das Syntax der Sprache C # ermöglicht es Ihnen, vor den Linien das Zeichen '@' zu setzen, um alle Formatierungszeichen zu ignorieren. In MQL5, ist dieser Ansatz nicht vorgesehen, deshalb alle Steuerzeichen in einem regulären Ausdruck-Muster sollten klar vorgeschrieben werden.
3. Die Probenanalyse der Handelshistorie
In diesem Beispiel werden die folgenden Operationen vorgesehen.
- Das Lesen der Handelshistory aus dem Sandbox im Format der .html-Datei.
- Die Auswahl einer der beiden Tabellen (Die Tabellen "Orders" oder "Aufträge") für die weitere Arbeit mit ihr.
- Die Wahl der Filter für die Tabelle.
- Eine grafische Darstellung der gefilterten Tabelle.
- Eine kurze mathematische Statistik über die gefilterte Tabelle.
- Die Möglichkeit, die gefilterte Tabelle zu speichern.
Diese sechs Punkte werden im EA TradeHistoryParsing.mq5 realisiert.
Für die Arbeit mit einem Experten muss an erster Stelle die Handelshistory heruntergeladen werden. Um dies zu tun, auf dem Feld "Extras" im MetaTrader5 Handelsterminal gehen Sie auf "History" - klicken Sie rechts, es wird das Dialogfeld geöffnet, wählen Sie "Berichte" und dann - HTML (Internetexplorer).
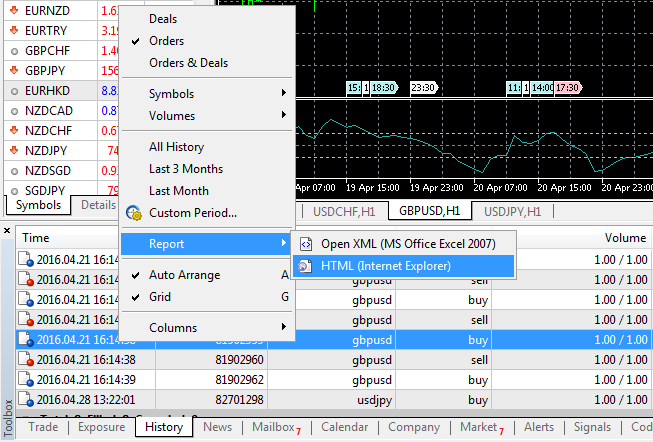
Speichern Sie die Datei in Sandbox (\MetaTrader 5\MQL5\Files).
Nun beim Start des Experten im Dialogfeld gehen Sie in "Eingabeparameter" und im Feld file_name geben Sie den Namen unserer Datei:
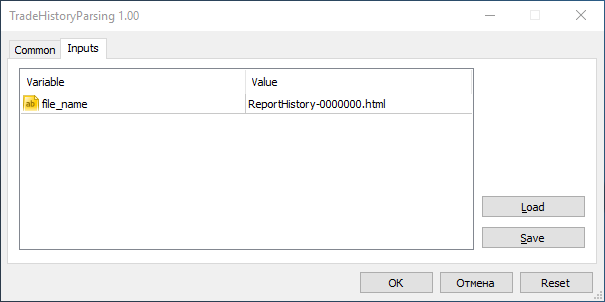
Jetzt, nach dem Drücken "OK" erscheint die Interface des Experten:
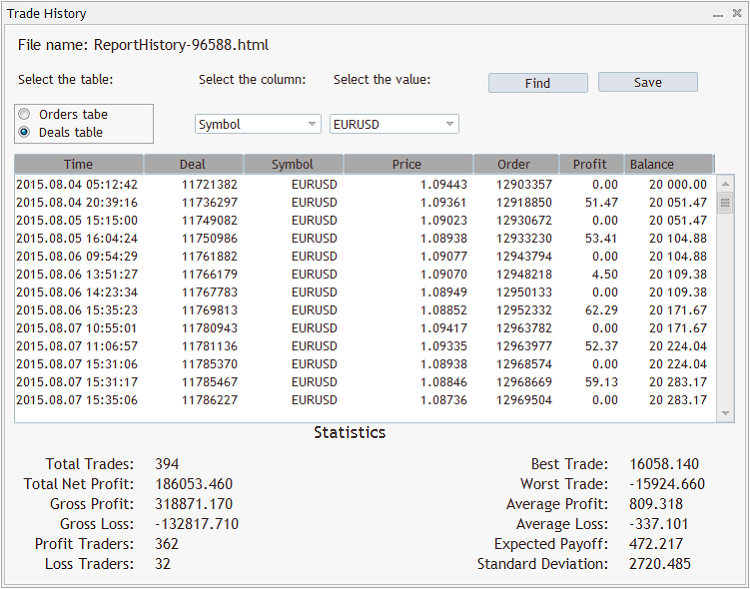
Wie es schon oben erwähnt wurde, werden die beiden Tabellen im EA in Form von zwei getippten Blätter präsentiert: List<OrderRecord*> und List<DealRecord*>.
Die Konstruktore für die Klassen OrderRecord und DealRecord nehmen als Parameter ein Array aus Zeilen, das von sich selbst einen Dateneintrag aus der Tabelle ist.
Für die Erstellung dieser Arrays brauchen wir eben diese regulären Ausdrücke. Die gesamte Analyse der History wird im Konstruktor der Klasse TradeHistory durchgeführt, auch in der Klasse wird die Darstellung der beiden Tabellen gespeichert und werden Methoden zur Filterung realisiert. Der Konstruktor dieser Klasse nimmt ein einziger Parameter - path, in diesem Fall ist der unter dem Namen der .html-Datei der History:
TradeHistory(const string path) { m_file_name=path; m_handel= FileOpen(path,FILE_READ|FILE_TXT); m_list1 = new List<OrderRecord*>(); m_list2 = new List<DealRecord*>(); Regex *rgx=new Regex("(>)([^<>]*)(<)"); while(!FileIsEnding(m_handel)) { string str=FileReadString(m_handel); MatchCollection *matches=rgx.Matches(str); if(matches.Count()==23) { string in[11]; for(int i=0,j=1; i<11; i++,j+=2) { in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2); } m_list1.Add(new OrderRecord(in)); } else if(matches.Count()==27) { string in[13]; for(int i=0,j=1; i<13; i++,j+=2) { in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2); } m_list2.Add(new DealRecord(in)); } delete matches; } FileClose(m_handel); delete rgx; Regex::ClearCache(); }
Wie aus dem Code des Konstruktors zu sehen ist, für die Analyse der Handelshistorie verwenden wir nur einen regulären Ausdruck mit dem Muster "(>) ([^ <>] *) (<)". Betrachten wir dieses Muster gründlicher:
| (>) | Die Suche des Symbols '>' |
| (^[<>]*) | Jedes Symbol, außer '>' und '<', das sich 0 oder mehrmals wiederholt |
| (<) | Die Suche des Symbols '<' |
Dieser reguläre Ausdruck sucht allen Unterzeilen, die mit '>' beginnen und '<' beenden. Der Text, der zwischen ihnen ist, darf nicht mit '<' oder '>' beginnen. Einfacher gesagt, wir bekommen einen Test zwischen der Tags in der HTML-Datei, bei deren Kanten noch unnötige Klammern sein werden, entfernen wir sie später. Alle gefundenen Unterzeilen speichern wir in MathcCollection - eine Sammlung aller Unterzeilen, die das Muster des regulären Ausdrucks erfüllt und die Muster, die in der Quellzeile gefunden wurden. Aufgrund der Struktur der HTML-Datei können wir genau definieren, ob unsere Zeile ein Eintrag aus der Tabelle der Orders ist, der Eintrag aus der Tabelle der Aufträge oder eine Zeile ist. Dafür zahlen wir einfach die Anzahl der Übereinstimmungen. So ist die Zeile ein Eintrag der Orders-Tabelle ist, wenn es die Anzahl ihrer Übereinstimmungen 23 entspricht, für die Tabelle der Aufträge ist es - wenn die Anzahl ihrer Übereinstimmungen 27 ist. Ansonsten interessiert uns diese Zeile nicht. Nun, aus unserer Sammlung extrahieren wir alle gerade Elemente ( "> <" werden in den ungeraden Zeilen sein), schneiden Sie das erste und das letzte Symbol und schreiben wir die fertige Zeile im Array ein:
in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2);
In diesem Fall muss nach dem Lesen jeder Zeile die Sammlung von Übereinstimmungen entfernt werden. Nach dem Lesen der gesamten Datei muss es geschlossen werden, auch muss der reguläre Ausdruck entfernt werden und der Puffer der regulären Ausdrücke gereinigt werden.
Jetzt müssen wir die Filterung der Tabellen durchführen, nämlich: eine bestimmte Spalte und einen bestimmten Wert daraus auswählen, und eine verkürzte Tabelle erhalten. In unserem Fall sollten wir eine Unterliste aus der Liste bekommen. Dazu können wir eine neue Liste erstellen, organisieren wir einfach eine vollständige Auflistung aller Elemente der alten Liste und wenn sie die angegebenen Kriterien erfüllt, fügen Sie sie zur neuen Liste.
Aber es gibt noch eine andere Art basierend der Methode (Predicate match) FindAll für die List <T>. Er nimmt alle Elemente, die die Bedingungen der Prädikat erfüllen, die ein Zeiger auf die Funktion ist, und hat die Form:
typedef bool (*Predicate)(IComparable*);
Über Interface IComparable wurde bereits früher erzählt.
Es muss nur noch die Funktion match selbst realisiert werden, wo bereits die Regel bekannt sind, nach den wir ein Liste-Element annehmen oder ablehnen. In unsrem Fall ist es die Spaltenummer und der Wert darin. Um dieses Problem in der Record-Klasse zu lösen, die der Nachfolger für die Klassen OrderRecord und DealRecord ist, gibt es zwei statische Methoden SetIndex(const int index) und SetValue(const string value). Diese Methoden nehmen und speichern die Spaltennummer und die Werte darin. Dann werden diese Daten eben in der Realisierung unserer Methode verwendet, für die Suche:
static bool FindRecord(IComparable *value) { Record *record=dynamic_cast<Record*>(value); if(s_index>=ArraySize(record.m_data) || s_index<0) { Print("Iindex out of range."); return(false); } return (record.m_data[s_index] == s_value); }
s_index ist hier eine statische Variable, deren Wert durch die Methode SetIndex gesetzt wird, und s_value ist eine statische Variable, deren Wert durch die Methode SetValue gesetzt wird.
Nun, wenn wir die nötigen Spaltennummer und den Wert darin setzen, können wir leicht eine vereinfachte Version unserer Liste erhalten:
Record::SetValue(value); Record::SetIndex(columnIndex); List<Record*> *new_list = source_list.FindAll(Record::FindRecord);
Diese gefilterten Listen werden in der grafischen Interface des Experten angezeigt.
Bei Bedarf ist es möglich, diese gefilterten Tabellen in CSV-Dateien zu speichern. Die Datei wird in einem Sandbox unter dem Namen Result.csv gespeichert.
Wichtig! Wenn eine Datei gespeichert wird, wird es ihnen immer den gleichen Namen zugeordnet. Wenn also eine Notwendigkeit entsteht, zwei oder mehrere Tabellen zu speichern, muss man sie einzeln speichern und umbenennen. Andernfalls wird die gleiche Datei überschrieben.
4. Die Probenanalyse der Optimierungsergebnisse des Experten
Dieses Beispiel verarbeitet die XML-Datei, die das Optimierungsergebnis des Experten aus dem Terminal MetaTrader5 ist. Darin wurde eine graphische Darstellung für Daten realisiert, die während der Optimierung erhalten wurde, sowie deren Filtrationsmöglichkeit. Alle Daten werden in zwei Tabellen unterteilt:
- "Tester results table" — es enthält alle statistischen Daten, die während des Tests erhalten wurden;
- "Input parameters table" — hier werden alle Werte der Eingangsvariablen gespeichert. Für diese Tabelle wurde eine Grenze von zehn Eingabeparametern gesetzt. Wenn die Einstellungen mehr sind, werden sie nicht angezeigt.
Um einen Filter auf einer der Tabellen zu setzen, müssen Sie den Namen der Spalte auswählen, nach der es filtert wird, den Wertebereich setzen.
Das Beispiel der grafischen Interface hat die folgende Form:
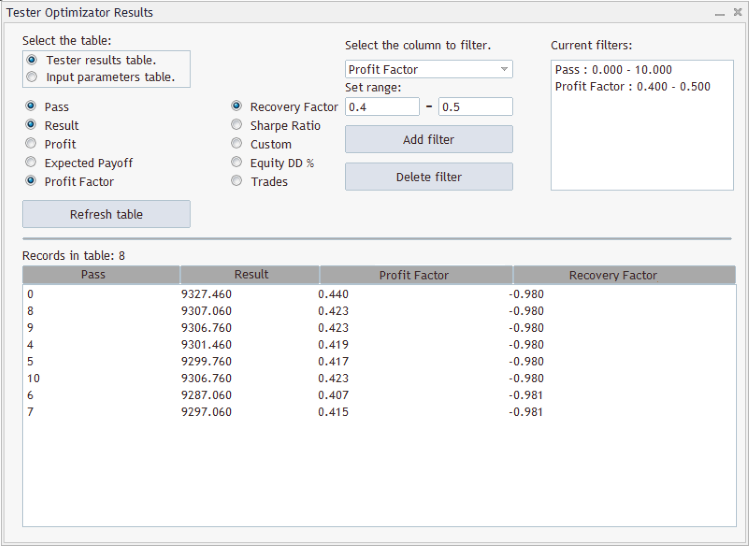
Dieses Bild zeigt die Darstellung der Tabelle "Tester results table" mit aktiven Spalten: "Pass", "Result", "Profit Factor", "Recovery Factor" und zwei Filter:
- Die Werte in der Spalte "Pass" müssen im Wertebereich [0; 10] sein;
- Die Werte in der Spalte "Profit Factor" müssen im Wertebereich [0.4; 0.5] sein.
5. Kurze Beschreibung von Beispielen aus der Bibliothek RegularExpressions für MQL5
Zusätzlich zu den beiden beschriebenen Experten enthält die Bibliothek RegularExpressions für MQL5 noch 20 Beispiele. In ihnen werden verschiedene Möglichkeiten der regulären Ausdrücken und dieser ganzen Bibliothek realisiert. Sie sind alle im Experten Tests.mq5:
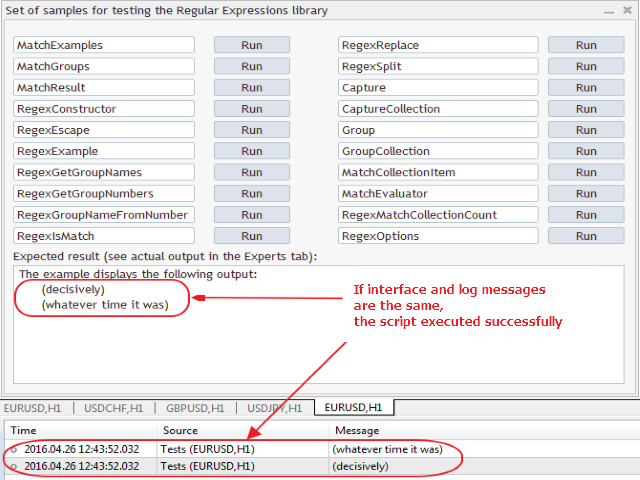
Betrachten wir, welche spezifischen Funktionen und Möglichkeiten der Bibliothek in jedem Beispiel verwendet wurden.
- MatchExamples — zeigt zwei mögliche Varianten der Sortierung aller Übereinstimmungen (Match) - durch die Erstellung MatchCollection oder durch die Verwendung der Methode Match.NextMatch().
- MatchGroups — zeigt die Art, die Ergebnisse der separaten Gruppenaufnahme (Group) zu bekommen und die weitere Arbeit mit ihnen.
- MatchResult — zeigt die Verwendung der Methode Match.Result (string), welche die Verlängerung des gegebenen Ersetzungsmusters zurückgibt.
- RegexConstructor — zeigt drei verschiedene Erstellungsvariante für die Regex-Klasse: basierend auf dem Muster, das Muster mit eingegebenen Parametern, das Muster mit Parametern und dem Wert, der angibt, wie lange die vergleichende Methode mit dem Muster versuchen muss, eine Übereinstimmung zu finden, bevor die Zeit abläuft.
- RegexEscape — zeigt die Methode Regex::Escape(string).
- RegexExample — zeigt den Prozess der Erstellung der regulären Ausdrücke und ihre weitere Verarbeitung.
- RegexGetGroupNames — zeigt ein Beispiel der Verwendung der Methode Regex.GetGroupNames(string);
- RegexGetGroupNumbers — zeigt ein Beispiel der Verwendung der Methode Regex.GetGroupNumbers(int);
- RegexGroupNameFromNumber — zeigt ein Beispiel der Verwendung der Methode Regex.GroupNameFromNumber(int);
- RegexIsMatch — zeigt ein Beispiel aller Verwendungsvariante der statischen Methode Regex::IsMatch();
- RegexReplace — zeigt ein Beispiel der grundlegenden Verwendungsvariante der statischen Methode Regex::Replace();
- RegexSplit — zeigt ein Beispiel der grundlegenden Verwendungsvariante der statischen Methode Regex::Split();
- Capture — das Beispiel der Arbeit mit dem Ergebnis eines erfolgreichen Eintrags des Ausdrucks (Capture).
- CaptureCollection — das Beispiel der Arbeit mit einer Reihe von Einträgen, die von einer Einträgen-Gruppe gemacht wurden(CaptureCollection).
- Group — das Beispiel der Arbeit mit dem Ergebnis von einer separaten Gruppenaufnahme(Group).
- GroupCollection — das Beispiel der Arbeit mit einer Reihe von Einträgen-Gruppen im selben Vergleich(GroupCollection).
- MatchCollectionItem — die Erstellung MatchCollection mit der statistischen Methode Regex::Matches(string,string);
- MatchEvaluator — das Beispiel der Erstellung und der Verwendung des Zeigers für die Funktion MatchEvaluator.
- RegexMatchCollectionCount — die Darstellung der Methode MatchCollection.Count();
- RegexOptions — die Darstellung der Auswirkung des Parameters RegexOptions auf die Verarbeitung des regulären Ausdrucks.
Die meisten Beispiele sind in der Funktionalität einig und sind meistens dafür vorgesehen, um die Bibliothek zu testen.
Fazit
In diesem Artikel werden die Möglichkeiten der regulären Ausdrücke und deren Anwendung betrachtet. Für weitere Informationen sollten Sie die Artikel unter den unten gegebenen Links lesen. Die Syntax der regulären Ausdrücke in .Net ist größtenteils mit der Realisierung auf MQL5 gleich, so dass alle die Hilfe von Microsoft aktuell sein werden, zumindest teilweise. Das gleiche betrifft auch die Klassen aus dem Ordner Internal.
Links
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/2432
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.

 Tipps zum Kauf eines Produkts auf dem Market. Schritt für Schritt
Tipps zum Kauf eines Produkts auf dem Market. Schritt für Schritt
 Signalrechner
Signalrechner
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich kann Ihre Beispiele nicht auf meinem MT5 build1340 ausführen, weil während der Kompilierung.