
Vereinfachen von Datenbanken in MQL5 (Teil 2): Verwendung von Metaprogrammierung zur Erstellung von Entitäten

Einführung
Im vorigen Artikel haben wir die ersten Schritte unternommen, um zu verstehen, wie MQL5 mit Datenbanken umgeht: Wir haben Tabellen erstellt, Datensätze eingefügt, aktualisiert und gelöscht und sogar Transaktionsfunktionen, Datenimport und -export erkundet. All dies wurde direkt durchgeführt, indem rohes SQL geschrieben und die von der Sprache angebotenen nativen Funktionen aufgerufen wurden. Dieser Schritt war von entscheidender Bedeutung, da er das Fundament legte, auf dem jede Abstraktionsschicht aufgebaut wird. Nun stellt sich aber unweigerlich die Frage, ob wir jedes Mal SQL schreiben wollen, wenn wir Daten in unseren Robotern und Indikatoren verarbeiten müssen.
Wenn wir ein robusteres System in Betracht ziehen, lautet die Antwort nein. Die ausschließliche Verwendung von SQL macht den Code langatmig, repetitiv und fehleranfällig, insbesondere wenn die Anwendung wächst und beginnt, mehrere Tabellen, Beziehungen und Validierungen zu verarbeiten. An dieser Stelle kommt ein ORM (Object-Relational Mapping) ins Spiel: eine Möglichkeit, die Kluft zwischen der objektorientierten Welt, in der wir programmieren, und der relationalen Welt, in der die Daten leben, zu überbrücken. Der erste Schritt in diese Richtung besteht darin, eine Möglichkeit zu schaffen, Datenbanktabellen direkt als Klassen in MQL5 darzustellen.
In diesem zweiten Artikel lernen wir, wie man eine oft unterschätzte, aber extrem leistungsfähige Sprachfunktion verwendet: #define. Es wird uns ermöglichen, die Erstellung von Strukturen zu automatisieren und zu standardisieren, wodurch Doppelarbeit vermieden und künftige Erweiterungen erleichtert werden. Damit erstellen wir unsere ersten Entitäten (Klassen, die Tabellen darstellen) und auch einen Mechanismus zur Beschreibung von Spaltenmetadaten, wie z. B. Datentyp, Primärschlüssel, automatische Inkrementierung, erforderliche Felder und Standardwerte.
Dieser Ansatz bildet die Grundlage für alles, was folgt: Repositories, Query Builders und automatische Tabellenerstellung. Mit anderen Worten: Wir beginnen, das MQL5 ORM zu gestalten, das wir uns von Anfang an vorgestellt haben.
Was #define ist und wie es in MQL5 funktioniert
In Sprachen der C-Familie (und MQL5 gehört zu dieser Gruppe) ist #define ein Vorverarbeitungswerkzeug, d. h. etwas, das der Compiler noch vor der Kompilierung des endgültigen Codes interpretiert. Es erzeugt keine Funktionen oder Variablen, sondern ersetzt den Text auf intelligente Weise, fast wie ein „Shortcut"-System oder Makro.
In der Praxis bedeutet dies, dass wir ein Muster einmal schreiben und es an mehreren Stellen im Code wiederverwenden können, wodurch Doppelarbeit und Fehler vermieden werden. Darüber hinaus können wir #define in ein Werkzeug für eine Metaprogrammierung umwandeln, das in der Lage ist, aus einfachen Definitionen komplexe Strukturen wie unsere Datenbankentitäten zu erzeugen.
Beginnen wir mit der Untersuchung der verschiedenen Verwendungszwecke, von den einfachsten bis zu den fortgeschrittensten.
1. Das einfachste #define: Aliase und direkte Ersetzungen
Der häufigste Anwendungsfall ist die Verwendung von #define zur Erstellung eines Textkürzels.
#define PI 3.14159 #define AUTHOR "João Pedro" //--- Use int OnInit() { double area = PI * 2 * 2; Print("Code written by", AUTHOR); return(INIT_SUCCEEDED); }
Wenn der Compiler hier auf PI stößt, ersetzt er es durch den Wert 3,14159. Es gibt keine Typ- oder Kontextprüfung; es ist eine reine Textersetzung. Dies ist nützlich, aber immer noch trivial.
2. Parameter in Makros
Mit #define können wir auch Makros erstellen, die Parameter erhalten.
#define SQUARE(x) (x * x) int OnInit() { Print("Square of 5: ", SQUARE(5)); Print("Square of 10: ", SQUARE(10)); }
Beim Kompilieren wird SQUARE(5) wörtlich durch (5 * 5) ersetzt. Dies gibt Ihnen eine Vorstellung davon, wie wir wiederkehrende Muster in wiederverwendbare Formen kapseln können.
3. Der #-Operator: Umwandlung von Argumenten in Zeichenketten
Eine wenig erforschte Funktion in MQL5 ist der #-Operator, der das an das Makro übergebene Argument in eine literale Zeichenkette verwandelt.
#define META(name) Print("Variable name: ", #name) int OnInit() { int value = 42; META(value); }
Beachten Sie, dass nicht der Inhalt der Variablen, sondern ihr Name ausgegeben wird. Dieser Trick ist äußerst nützlich für die Erstellung von Protokollen oder die Erzeugung von Metadaten aus den Code-Bezeichnern selbst.
4. Der ##-Operator: Verkettung von Bezeichnern
Eine weitere fortschrittliche Funktion ist der ##-Operator, der Token (Codestücke) verkettet.
#define META(name) Print("Concatenated: ", name##Id) int OnInit() { int userId = 7; META(user); }
Der Compiler fügt user und Id buchstäblich zusammen und bildet userId. Diese Technik ermöglicht die dynamische Generierung von Variablen-, Methoden- oder Konstantennamen, was in MQL5 sonst unmöglich wäre.
5. Makros als Parameter für andere Makros
Bislang haben wir #define als einfache Substitution oder mit Parametern gesehen. Aber hier wird es interessant, wenn wir feststellen, dass Makros auch andere Makros als Argumente erhalten können. Dies eröffnet eine Art „Wiederholungsmaschine", mit der wir komplexe Codeblöcke aus einer einzigen Definition erzeugen können.
Siehe dieses Beispiel:
// Step 1 - Macro that describes a set of operations #define MATH_OPERATIONS(OP) \ OP(Add, +) \ OP(Sub, -) \ OP(Mul, *) \ OP(Div, /) // Step 2 - Macro that generates functions from the list above #define GENERATE_FUNCTION(name, symbol) \ double name(double a, double b) { return a symbol b; } // Step 3 - Expansion: Creates multiple functions at once MATH_OPERATIONS(GENERATE_FUNCTION) // Step 4 - Use int OnInit() { Print("2 + 3 = ", Add(2,3)); Print("10 - 7 = ", Sub(10,7)); Print("6 * 4 = ", Mul(6,4)); Print("20 / 5 = ", Div(20,5)); return INIT_SUCCEEDED; }
Was passiert in diesem Beispiel? Lassen Sie uns Schritt für Schritt vorgehen:
-
Schritt 1: Hier erstellen wir ein Makro, das für sich genommen nichts Nützliches erzeugt. Sie enthält einfach vier Elemente (Add, Sub, Mul, Div), die jeweils mit dem Symbol einer mathematischen Operation verbunden sind. Der Clou ist, dass jede Zeile ein OP-Makro aufruft, von dem wir noch nicht wissen, wie es implementiert werden wird. Das bedeutet, dass MATH_OPERATIONS als Vorlage funktioniert, aber immer noch ein „Werkzeug" benötigt, das ihm sagt, was es mit jedem Element in der Liste tun soll.
-
Schritt 2: Dieses Makro tut bereits etwas Konkretes: Mit einem Namen und einem Symbol erstellt es eine Funktion, die die Operation anwendet. Wenn wir zum Beispiel (Add, +) übergeben, wird die folgende Funktion erstellt:
double Add(double a, double b) { return a + b; }
Und so weiter für den Rest (Sub, Mul, und Div).
-
Schritt 3: Jetzt kommt der Clou: Wir übergeben GENERATE_FUNCTION als Parameter an die Operationsliste. Dies veranlasst den Compiler, jeden OP-Aufruf innerhalb von MATH_OPERATIONS zu erweitern und OP durch GENERATE_FUNCTION zu ersetzen. Das Endergebnis ist gleichwertig mit dem manuellen Schreiben:
double Add(double a, double b) { return a + b; } double Sub(double a, double b) { return a - b; } double Mul(double a, double b) { return a * b; } double Div(double a, double b) { return a / b; }
-
Schritt 4: Hier verwenden wir direkt die Funktionen, die der Compiler aus der Kombination von Makros erstellt. Für den Programmierer sieht es so aus, als hätte es schon immer Funktionen namens Add, Sub, Mul und Div gegeben, aber in Wirklichkeit wurden sie automatisch eingebaut.
Zusammengefasst:
- Ein Makro kann Elemente auflisten ( MATH_OPERATIONS ).
- Ein weiteres Makro definiert, wie jedes Element in Code umgewandelt werden soll (GENERATE_FUNCTION).
- Wenn wir beide kombinieren, erzeugt der Compiler automatisch eine Reihe von Funktionen (oder Methoden, Eigenschaften, Klassen usw.).
Diese Technik der Übergabe von Makros als Parameter an andere Makros ist ein unglaubliches Werkzeug, das wir verwenden werden, um Wiederholungen zu vermeiden, Strukturen zu standardisieren und erweiterbare Blöcke zu erstellen. Später werden wir die gleiche Logik auf Datenbanktabellen und -spalten anwenden, aber hier wird deutlich, dass die Idee nicht auf Datenbanken beschränkt ist: Wir können die Funktion in jeder Situation verwenden, in der sich Muster wiederholen.
Erstellen einer Klasse, die eine Tabelle darstellt (Entity)
Vertiefen wir das Konzept einer Entität, die im Grunde eine Klasse ist, die eine Datenbanktabelle widerspiegelt. Mit anderen Worten: Wenn wir in der Datenbank eine Tabelle mit dem Namen „Account" haben, die Spalten wie „id", „number", „balance" und „owner" enthält, dann haben wir im Code eine Klasse „Account" mit Eigenschaften, die jede dieser Spalten darstellen. So können wir Daten als Objekte manipulieren, ohne uns ständig mit SQL beschäftigen zu müssen.
Nehmen wir an, wir haben die Tabelle „Account“ in der Datenbank. Um es in MQL5 darzustellen, würden wir eine Klasse wie diese erstellen:
class Account { public: ulong id; // unique identifier double number; // account number double balance; // available balance string owner; // account owner Account(void); ~Account(void); //--- Converts the data into a string string ToString(); }; Account::Account(void) { } Account::~Account(void) { } string Account::ToString(void) { return("Account[id="+ (string)id+ ", number="+ (string)number+ ", balance="+ (string)balance+ ", owner="+ (string)owner+ "]"); }
Dieser Code funktioniert, aber er hat zwei klassische Probleme:
- Wiederholung: Für jede Tabelle müssen wir alle Eigenschaften und Konstruktoren manuell umschreiben. Wenn das System 20 Tabellen hat, gibt es 20 nahezu identische Klassen, bei denen sich nur die Felder unterscheiden.
- Schlechte Skalierbarkeit: Wenn sich ein Tabellenfeld ändert (z. B. die Umbenennung von „number" in „account_number"), müssen wir es sowohl in der Datenbank als auch in der Klasse manuell ändern, was zu Inkonsistenzen führen kann.
An dieser Stelle kommt die Metaprogrammierung mit #define ins Spiel. Bei der Verwendung von Makros zur automatischen Generierung der Entität ist die Idee sehr ähnlich zu der, die wir im vorherigen Abschnitt gesehen haben: Wir erstellen eine Liste von Spalten als Makro und generieren daraus automatisch die entsprechende Klasse. Lassen Sie uns Schritt für Schritt vorgehen:
Schritt 1 – Definieren der Spalten mit einem Makro#define ACCOUNT_COLUMNS(COLUMN) \ COLUMN(ulong, id, 0) \ COLUMN(double, number, 0.0) \ COLUMN(double, balance, 0.0) \ COLUMN(string, owner, "")
Hier definiert ACCOUNT_COLUMNS alle Spalten der Tabelle Account. Beachten Sie, dass jede Spalte durch Typ, Name und Standardwert beschrieben wird.
Das Geheimnis liegt in dem Parameter COLUMN, der später in einem anderen Makro übergeben wird, um zu entscheiden, was mit den einzelnen Elementen geschehen soll.
Schritt 2 – Erstellen des Makros, das die Attribute der Klasse erzeugt#define ENTITY_FIELD(type, name, default_value) type name; #define ENTITY_DEFAULT(type, name, default_value) name = default_value; #define ENTITY_TO_STRING(type, name, default_value) _s += #name+"="+(string)name+", ";
Diese Makros sind die Bausteine unserer Entität. Jede von ihnen nimmt das in der Spaltenliste definierte Tripel (Typ, Name, Standardwert) und erzeugt ein bestimmtes Stück Code:
- ENTITY_FIELD → erstellt das Klassenattribut.
- Unter Berücksichtigung dieser Parameter: ENTITY_FIELD(ulong, id, 0) erzeugt ulong id;
- Mit anderen Worten: Es wird nur die Variable mit ihrem Typ deklariert.
- ENTITY_DEFAULT → initialisiert das Attribut mit einem Standardwert innerhalb des Konstruktors.
- Unter Berücksichtigung dieser Parameter: ENTITY_DEFAULT(double, balance, 0.0) erzeugt balance = 0.0;
- Dadurch wird sichergestellt, dass jedes Objekt in der Klasse mit konsistenten Werten beginnt.
- ENTITY_TO_STRING → erzeugt eine Zeichenkette zur Anzeige der Attributwerte.
- Unter Berücksichtigung dieser Parameter: ENTITY_TO_STRING(string, owner, „") wird der Name und der Wert _s += „owner="+(string)owner+", „; mit der Zeichenkette „_s" verkettet.
- Auf diese Weise können wir eine generische ToString-Methode erstellen, die alle Felder der Klasse ausgibt, ohne dass jedes Attribut manuell geschrieben werden muss.
#define ENTITY(name, COLUMN) \ class name \ { \ public: \ COLUMN(ENTITY_FIELD) \ name(void){COLUMN(ENTITY_DEFAULT)}; \ ~name(void){}; \ string ToString(void) \ { \ string _s = ""; \ COLUMN(ENTITY_TO_STRING) \ _s = StringSubstr(_s,0,StringLen(_s)-2); \ return(#name+ "["+_s+"]"); \ } \ };
Dies ist das Makro, das die gesamte Klasse erzeugt. Lassen Sie uns Zeile für Zeile aufschlüsseln:
-
class name {...};
- Erzeugt eine Klasse mit dem angegebenen Namen.
- Beispiel: ENTITY(Account, ACCOUNT_COLUMNS) → class Account {...};
-
COLUMN(ENTITY_FIELD)
- Wendet für jede Spalte der Liste das Makro ENTITY_FIELD an.
- Ergebnis: Alle Attribute der Klasse sind deklariert.
-
Konstruktor name(void){COLUMN(ENTITY_DEFAULT)};
- Der Konstruktor ruft COLUMN(ENTITY_DEFAULT) auf, d.h. er initialisiert alle Attribute mit ihren Standardwerten.
-
Destruktor ~name(void){};
- Hier machen wir nur den leeren Destruktor explizit.
-
Die Methode ToString()
- Sie setzt eine Zeichenkette _s durch Verkettung von name=wert aus jedem Feld zusammen.
- Sie verwendet COLUMN(ENTITY_TO_STRING), um diese Logik auf alle Spalten anzuwenden.
- Sie entfernt das nachgestellte Komma mit StringSubstr.
- Sie druckt so etwas wie:
Account[id=1, number=12345, balance=500.0, owner=João]
ENTITY(Account, ACCOUNT_COLUMNS)
Diese einzige Zeile erzeugt automatisch die Klasse, die der Klasse entspricht, die wir zu Beginn manuell geschrieben haben. Danach können wir die Klasse Account ganz normal verwenden:
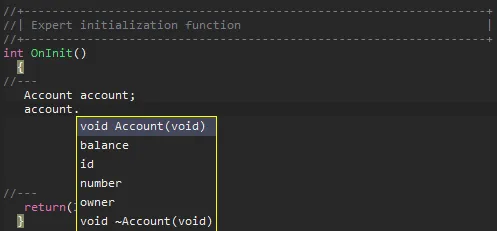
Der Unterschied zwischen der manuellen Version und der #define-Version ist im Hinblick auf Skalierbarkeit und Wartungsfreundlichkeit enorm. Um eine neue Entität zu erstellen, müssen Sie lediglich:
- Seine Spalten in einem TABLE_COLUMNS-Makro definieren und
- DEFINE_ENTITY(Table, TABLE_COLUMNS) aufrufen.
Dies vermeidet Wiederholungen, erleichtert die Aktualisierung (wenn Sie den Namen einer Spalte ändern, können Sie ihn im Makro ändern) und eröffnet uns Raum für die Erweiterung dieses Konzepts, z. B. durch Hinzufügen von automatischen Konstruktoren, Serialisierungsmethoden, SQL-Integration und vieles mehr.
Spaltenmetadaten: Verkapselung der Eigenschaften
Bislang haben wir Entitäten mit Attributen erstellt und es sogar geschafft, ihre Werte mithilfe von Makros automatisch zu drucken. Aber es gibt ein Problem: Diese Attribute sind immer noch "stumm".
Sie wissen, wie sie Daten speichern können, aber sie wissen nicht, wie sie sich selbst beschreiben können. Wir können zum Beispiel nicht nach einem Attribut fragen: "Handelt es sich um einen Primärschlüssel (PK)?", „Können Nullwerte akzeptiert werden?", „Handelt es sich um ein Feld mit automatischer Inkrementierung?", oder „Was ist der tatsächliche Typ in der Datenbank (INTEGER, TEXT, REAL, usw.)?"
Diese Informationen werden als Metadaten oder Daten über die Daten bezeichnet. Wenn unser ORM in der Lage sein soll, automatisch SQL zu generieren (z. B. Tabellen zu erstellen oder Strukturen zu validieren), benötigen wir eine zusätzliche Schicht, die diese Eigenschaften speichert und es der Entität ermöglicht, sich selbst zu beschreiben.
Die Idee ist, eine Metadatenklasse namens IColumnMetadata zu erstellen. Sie ist für die Speicherung aller Informationen über eine Spalte zuständig:
- Feldname (m_name)
- Logischer Typ in MQL5 (m_type)
- Datenbanktyp (m_db_type)
- ob sie Null sein kann (m_nullable)
- ob es sich um Autoinkrement handelt (m_auto_increment)
- ob es ein Primärschlüssel ist (m_primary_key)
- ob sie eindeutig ist (m_unique)
Auf diese Weise kann jede Spalte der Entität mit einer vollständigen Beschreibung versehen werden, die in Zukunft verwendet wird, um automatisch CREATE TABLE-Anweisungen zu generieren, zu überprüfen, ob die Datenbank mit der Entität übereinstimmt, und Werte korrekt zwischen MQL5 und SQL abzubilden.
Wir erstellen einen neuen Ordner mit dem Namen TickORM innerhalb von includes, und darin einen Ordner mit dem Namen metadata, und eine neue Datei mit dem Namen IColumnMetadata.mqh, am Ende ist dies das Verzeichnis: <MQL5/Includes/TickORM/metadata/ColumnMetadata.mqh>. Und wir erstellen die folgende Klasse:
//+------------------------------------------------------------------+ //| class abstract : IColumnMetadata | //| | //| [PROPERTY] | //| Name : IColumnMetadata | //| Heritage : No heritage | //| Description : Stores all the information in a column. | //| | //+------------------------------------------------------------------+ class IColumnMetadata { private: //--- Props string m_name; string m_type; string m_db_type; bool m_nullable; bool m_auto_increment; bool m_primary_key; bool m_unique; public: IColumnMetadata(string name, string type,string db_type,bool nullable,bool auto_increment,bool primary_key,bool unique); IColumnMetadata(void); ~IColumnMetadata(void); //--- Get Props string Name(void); string Type(void); string DbType(void); bool Nullable(void); bool AutoIncrement(void); bool PrimaryKey(void); bool Unique(void); }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ IColumnMetadata::IColumnMetadata(string name,string type,string db_type,bool nullable,bool auto_increment,bool primary_key,bool unique) { m_name = name; m_type = type; m_db_type = db_type; m_nullable = nullable; m_auto_increment = auto_increment; m_primary_key = primary_key; m_unique = unique; } //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ IColumnMetadata::IColumnMetadata(void) { } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ IColumnMetadata::~IColumnMetadata(void) { } //+------------------------------------------------------------------+ //| Get name | //+------------------------------------------------------------------+ string IColumnMetadata::Name(void) { return m_name; } //+------------------------------------------------------------------+ //| Get type | //+------------------------------------------------------------------+ string IColumnMetadata::Type(void) { return m_type; }; //+------------------------------------------------------------------+ //| Get database type | //+------------------------------------------------------------------+ string IColumnMetadata::DbType(void) { return m_db_type; }; //+------------------------------------------------------------------+ //| Get is nullable | //+------------------------------------------------------------------+ bool IColumnMetadata::Nullable(void) { return m_nullable; }; //+------------------------------------------------------------------+ //| Get is auto increment | //+------------------------------------------------------------------+ bool IColumnMetadata::AutoIncrement(void) { return m_auto_increment; }; //+------------------------------------------------------------------+ //| Get is primary key | //+------------------------------------------------------------------+ bool IColumnMetadata::PrimaryKey(void) { return m_primary_key; }; //+------------------------------------------------------------------+ //| Get is unique | //+------------------------------------------------------------------+ bool IColumnMetadata::Unique(void) { return m_unique; }; //+------------------------------------------------------------------+
Beachten Sie, dass die Klasse keine Intelligenz oder komplexe Logik besitzt, sondern lediglich die Daten der Tabellenspalten speichert. Diese Abstraktionsebene mag auf den ersten Blick bürokratisch erscheinen, aber sie ist genau das, was uns den nächsten Schritt ermöglicht:
- Eine Entität kann ihre Metadaten offenlegen.
- Der ORM kann diese Metadaten scannen und automatisch SQL generieren, um die entsprechende Tabelle in der Datenbank zu erstellen.
Ohne diese Schicht müssten wir jedes Mal, wenn wir eine Tabelle erstellen wollten, die gesamte Anweisung CREATE TABLE... manuell schreiben, was genau die Art von Wiederholung ist, die wir vermeiden wollen.
Stellen Sie sich vor, Sie haben eine Tabelle „Trades" mit drei Spalten:
- id: Ganzzahl, Primärschlüssel, auto_increment.
- symbol: erforderliche Zeichenkette, darf nicht leer sein.
- volume: Dezimalzahl, ebenfalls erforderlich.
Mit unserer Metadatenklasse können wir sie wie folgt beschreiben:
IColumnMetadata id("id", "int", "INTEGER", false, true, true, true); IColumnMetadata symbol("symbol", "string", "TEXT", false, false, false, false); IColumnMetadata volume("volume", "double", "REAL", false, false, false, false);
Jetzt ist es nicht nur ein einfaches Attribut: Es ist ein Objekt, das sich selbst kennt, das seine Regeln und Einschränkungen zu erklären weiß.
Jetzt ist es nicht mehr nur ein einfaches Attribut: Es ist ein Objekt, das sich selbst kennt und seine Regeln und Einschränkungen erklären kann.
Erstellung der Klasse ITableMetadata: die vollständige Beschreibung der Entität
Wenn wir bisher auf Spaltenebene gearbeitet haben, müssen wir jetzt einen Schritt weiter gehen und auf der Ebene der gesamten Tabelle denken. Jede Tabelle (oder Entität) besteht nicht nur aus einer Reihe von Attributen: Sie hat auch einen eigenen Namen, einen Primärschlüssel und eine Sammlung von Spaltenmetadaten.
Mit anderen Worten, wir brauchen eine Struktur, die alle IColumnMetadaten einer Entität speichern kann. Wenn IColumnMetadata ein Feld beschreibt, beschreiben die ITableMetadata, die wir erstellen werden, die gesamte Entität. Sie muss auch andere Fragen beantworten, wie zum Beispiel: "Wie lautet der Tabellenname?", „Was ist der Primärschlüssel?", „Wie viele Spalten hat die Tabelle?" und „Welche Eigenschaften hat jede Spalte?"
Darüber hinaus muss es erweiterbar sein, d. h. jede Entität wird ihre eigene Metadatenversion haben, aber sie können alle dieselbe „Basisschnittstelle" verwenden.
Erstellen wir eine neue Datei namens TableMetadata.mqh im Verzeichnis <MQL5/Include/TickORM/metadata/TableMetadata.mqh>. Wir haben bereits ColumnMetadata.mqh importiert.
//+------------------------------------------------------------------+ //| Import | //+------------------------------------------------------------------+ #include "PropertyMetadata.mqh" //+------------------------------------------------------------------+ //| class abstract : IEntityMetadata | //| | //| [PROPERTY] | //| Name : IEntityMetadata | //| Heritage : No heritage | //| Description : Stores all the information in a table. | //| | //+------------------------------------------------------------------+ class ITableMetadata { protected: IColumnMetadata *m_properties[]; public: ITableMetadata(void); ~ITableMetadata(void); //--- Add new column void AddColumn(IColumnMetadata *column); IColumnMetadata *Column(int index); int ColumnSize(void); }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ ITableMetadata::ITableMetadata(void) { } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ ITableMetadata::~ITableMetadata(void) { int size = ArraySize(m_columns); for(int i=0;i<size;i++) { delete m_columns[i]; } } //+------------------------------------------------------------------+ //| Add new column | //+------------------------------------------------------------------+ void ITableMetadata::AddColumn(IColumnMetadata *column) { int size = ArraySize(m_columns); ArrayResize(m_columns,size+1); m_columns[size] = column; } //+------------------------------------------------------------------+ //| Get property metadata | //+------------------------------------------------------------------+ IColumnMetadata *ITableMetadata::Column(int index) { return(m_columns[index]); } //+------------------------------------------------------------------+ //| Get size columns | //+------------------------------------------------------------------+ int ITableMetadata::ColumnSize(void) { return(ArraySize(m_columns)); } //+------------------------------------------------------------------+
Beachten Sie, dass bereits ein Array des IColumnMetadata-Objekts hinzugefügt wurde, wobei jede Position im Array eine Tabellenspalte darstellt. Auch wurden einige grundlegende Methoden zur Manipulation des Arrays hinzugefügt.
Schließlich haben wir zwei virtuelle Methoden hinzugefügt. Das bedeutet, dass jede untergeordnete Klasse TableName() und PrimaryKey() außer Kraft setzen kann, um sich selbst zu beschreiben, da nur untergeordnete Klassen den Tabellennamen kennen. Um dies zu vermeiden, haben wir eine Basisimplementierung erstellt, die NULL zurückgibt.
class ITableMetadata { public: //--- Virtual methods (will be implemented in the child class) virtual string TableName(void); virtual string PrimaryKey(void); }; //+------------------------------------------------------------------+ //| Get table name | //+------------------------------------------------------------------+ string ITableMetadata::TableName(void) { return(NULL); } //+------------------------------------------------------------------+ //| Get is primary key | //+------------------------------------------------------------------+ string ITableMetadata::PrimaryKey(void) { return(NULL); } //+------------------------------------------------------------------+
Alles miteinander verbinden
Bisher haben wir zwei grundlegende Schritte durchlaufen: Zuerst haben wir manuell eine Entitätsklasse erstellt; dann haben wir gesehen, wie man Makro-Metaprogrammierung verwendet, um diese Klassen automatisch zu generieren. Aber es fehlt noch ein wichtiger Teil: Wir müssen die Definition von Entitäten und ihren Spalten an einer einzigen Stelle zentralisieren. Dieser Ort muss in der Lage sein, native MQL5-Typen in SQL-Typen zu übersetzen und gleichzeitig alle Tabellen-Metadaten in einer organisierten Weise zu erfassen.
Dies ist genau die Aufgabe der Datei TickORM.mqh, die sich unter <MQL5/TickORM/TickORM.mqh> befindet. Wir können es als eine Brücke betrachten, die den in MQL5 geschriebenen Code mit dem relationalen Datenbankmodell verbindet. Die Logik ist einfach: Für jede Entität erstellen wir eine von ITableMetadata abgeleitete Klasse, die automatisch alle Tabellenspalten aufzeichnet.
Dadurch kann der ORM nicht nur die Tabellenstruktur verstehen, sondern auch, wie Spalten erstellt, validiert und manipuliert werden, ohne dass die Entwickler dieselben Konvertierungen für jede neue Entität manuell durchführen müssen.
Um die Nützlichkeit dieser Methode besser zu verstehen, gehen wir Schritt für Schritt vor: Erstellen Sie manuell eine Metadatenklasse für die Tabelle „Konto", die vier grundlegende Spalten hat. Wir werden hier noch keine Makros verwenden, um genau zu klären, welche Arbeit wir automatisieren wollen:
class AccountMetadata : public ITableMetadata { public: AccountMetadata(void); ~AccountMetadata(void); string TableName(); string PrimaryKey(void); }; AccountMetadata::AccountMetadata(void) { this.AddColumn(new IColumnMetadata("id","ulong","INTEGER",false,true,true,true)); this.AddColumn(new IColumnMetadata("number","ulong","REAL",false,false,false,false)); this.AddColumn(new IColumnMetadata("balance","ulong","REAL",false,false,false,false)); this.AddColumn(new IColumnMetadata("owner","ulong","TEXT",false,false,false,false)); } AccountMetadata::~AccountMetadata(void) { } string AccountMetadata::TableName(void) { return("Account"); } string AccountMetadata::PrimaryKey(void) { int size = ArraySize(m_columns); for(int i=0;i<size;i++) { if(m_columns[i].PrimaryKey()) { return(m_columns[i].Name()); } } return(NULL); }
Diese Implementierung ist ausreichend, um die Metadaten der Tabelle abzufragen. So können wir sie nutzen:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- AccountMetadata metadata; int size_cols = metadata.ColumnSize(); Print("table name: ",metadata.TableName()); Print("ptimary key: ",metadata.PrimaryKey()); Print("size columns: ",size_cols); for(int i=0;i<size_cols;i++) { IColumnMetadata *column = metadata.Column(i); Print("==="); Print("Column name: "+column.Name()); Print("Type: "+column.Type()); Print("DbType: "+column.DbType()); Print("Nullable: "+column.Nullable()); Print("PrimaryKey: "+column.PrimaryKey()); Print("Unique: "+column.Unique()); } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+
Die Konsolenausgabe zeigt alle erfassten Informationen deutlich an:
table name: Account ptimary key: id size columns: 4 === Column name: id Type: ulong DbType: INTEGER Nullable: false PrimaryKey: true Unique: true === Column name: number Type: ulong DbType: REAL Nullable: false PrimaryKey: false Unique: false === Column name: balance Type: ulong DbType: REAL Nullable: false PrimaryKey: false Unique: false === Column name: owner Type: ulong DbType: TEXT Nullable: false PrimaryKey: false Unique: false
Beachten Sie, dass alle wesentlichen Daten für die Tabelle und ihre Spalten bereits zur Laufzeit zur Verfügung stehen. Was jetzt noch fehlt, ist die Automatisierung der Erstellung dieser Metadatenklasse mittels #define, damit wir nicht für jede neue Entität diese gesamte Struktur manuell wiederholen müssen. Dies wird der nächste Schritt sein.
Automatisieren der Erstellung der Metadatenklasse
Wenn wir beginnen, MQL5-Entitäten mit der Datenbank zu verbinden, ergibt sich sofort eine Herausforderung: Die Datentypen sprechen nicht dieselbe Sprache. Im MQL5-Code verwenden wir int, double, string und andere. In der Datenbank sind die Typen unterschiedlich: INTEGER, REAL, TEXT, usw.
Ohne eine klare Übersetzungsregel müsste jede Spalte manuell zugeordnet werden, was mühsam und fehleranfällig wäre. Um diese Nacharbeit zu vermeiden, haben wir ein kleines „Umwandlungswörterbuch" mit #define erstellt:
#define MQL5_TO_SQL_int "INTEGER" #define MQL5_TO_SQL_double "REAL" #define MQL5_TO_SQL_float "REAL" #define MQL5_TO_SQL_long "INTEGER" #define MQL5_TO_SQL_ulong "INTEGER" #define MQL5_TO_SQL_datetime "INTEGER" #define MQL5_TO_SQL_string "TEXT" #define MQL5_TO_SQL_bool "INTEGER" #define DB_TYPE_FROM_MQL5(type) MQL5_TO_SQL_##type
Es funktioniert ganz einfach: Wenn wir eine Spalte in der Entität als int deklarieren, wandelt das Makro DB_TYPE_FROM_MQL5 sie automatisch in „INTEGER" um. Dadurch wird sichergestellt, dass jeder MQL5-Typ immer seinen entsprechenden Typ in der Datenbank hat, ohne dass man sich diese Zuordnung merken oder manuell wiederholen muss.
Nun, da die Typen geklärt sind, brauchen wir eine Möglichkeit, die Metadaten für jede Tabelle zu organisieren. Zu diesem Zweck erstellen wir dynamisch eine Klasse mit dem Namen name##Metadata (z. B. AccountMetadata ). Diese Klasse erbt von ITableMetadata und hat zwei Hauptfunktionen:
- Tabellenname(): gibt den Entitätsnamen zurück (der als Tabellenname verwendet wird).
- PrimaryKey(): identifiziert automatisch, welche Spalte als Primärschlüssel markiert wurde.
#define ENTITY_META_DATA(name, COLUMNS) \ class name##Metadata : public ITableMetadata \ { \ public: \ name##Metadata(void) \ { \ COLUMNS(ENTITY_META_DATA_COLUMNS); \ } \ ~name##Metadata(void){}; \ string TableName() { return(#name); }; \ string PrimaryKey(void) \ { \ int size = ArraySize(m_columns); \ for(int i=0;i<size;i++) \ { \ if(m_columns[i].PrimaryKey()) \ { \ return(m_columns[i].Name()); \ } \ } \ return(NULL); \ } \ };
Um schließlich eine vollständige Entität (Klasse + Metadaten) zu erstellen, verwenden wir zwei Makros: Das erste definiert die Spalten, das zweite erzeugt automatisch die Entität und ihre Metadatenklasse:
#define ACCOUNT_COLUMNS(COLUMN) \ COLUMN(ulong, id, false, 0, true, true, false) \ COLUMN(double, number, false, 0, false, false, false) \ COLUMN(double, balance, false, 0, false, false, false) \ COLUMN(string, owner, false,"", false, false, false) ENTITY(Account, COLUMNS) ENTITY_META_DATA(Account, COLUMNS)
Hier deklarieren wir in wenigen Zeilen die gesamte Struktur der Tabelle Konto:
- id ist der Primärschlüssel (primary = true) und auto-increment (auto_inc = true),
- number und balance sind Pflichtangaben,
- owner ist Pflichttext.
Mit anderen Worten: Mit einem einzigen Definitionspunkt konnten wir die Klasse Account und ihre Metadatenklasse AccountMetadata erstellen, die für die Verwendung durch den ORM bereit waren.
Schlussfolgerung und nächste Schritte
Wir haben das Ende einer weiteren Phase der Entwicklung unseres ORM erreicht. Mit diesem Artikel haben wir einen wichtigen Weg beschritten:
- Wir haben damit begonnen, besser zu verstehen, wie #define in MQL5 funktioniert, und zwar nicht nur für einfache Konstanten, sondern als Metaprogrammierwerkzeug.
- Wir sind zur Erstellung von Entitäten (den Klassen, die unsere Tabellen darstellen) übergegangen und haben gesehen, wie man ihre Definition mithilfe von Makros vereinfachen kann.
- Wir haben diese Entitäten mit Spaltenmetadaten angereichert, die Attribute wie Typ, Primärschlüssel, Autoinkrement, Eindeutigkeit und Nullbarkeit beschreiben.
- Schließlich haben wir alles in der Datei TickORM.mqh zentralisiert, MQL5-Typen mit SQL verbunden und die Erzeugung von Metadatenklassen automatisiert.
Diese Grundlage ist von entscheidender Bedeutung: Jetzt haben wir nicht nur Entitäten, sondern auch die vollständige Beschreibung ihrer Eigenschaften, und dies wird der Motor sein, der es dem ORM ermöglicht, die Datenbank intelligent und automatisch zu manipulieren.
Im nächsten Artikel werden wir einen weiteren entscheidenden Schritt tun: Wir werden die Repository-Schicht erstellen. Diese Schicht ist für die Bearbeitung der Daten zuständig, ohne dass SQL manuell geschrieben werden muss. Stattdessen machen wir Aufrufe wie accountRepository.Save(account) oder ordersRepository.FindById(1), und der ORM kümmert sich um den Rest.
Mit anderen Worten: Wenn wir bisher gelernt haben, die Struktur der Tabellen zu beschreiben, werden wir im nächsten Artikel lernen, wie wir die Daten auf saubere, organisierte und sichere Weise bearbeiten können.
| Dateiname | Beschreibung |
|---|---|
| Include/TickORM/metadata/ColumnMetadata.mq5 | Schnittstelle, die die Daten der Spalte darstellt |
| Include/TickORM/metadata/TableMetadata.mqh | Schnittstelle, die die Tabellendaten darstellt |
| Include/TickORM/TickORM.mqh | Hauptdatei |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/19594
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.