
交易员的正则表达式

概论
正则表达式 是一种基于指定范式来处理文本的特殊工具和语言。多重 元字符和规则由正则表达式的语法定义。
它们能够执行两个主要功能:
- 在字符串里搜索范式;
- 替换发现的范式。
当创建由于正则表达式的范式时, 如前所述, 会使用特殊字符, 元字符和字符类 (集合)。这意味着正则表达式是一个规则字符串, 且所有非特殊 (非保留) 字符 均被认为是规则的。
在一个字符串里搜索指定的范式是通过正则表达式处理器来执行的。在 .NET 框架里, 当然, 同样在 RegularExpressions 库 MQL5 版本 里, 正则表达式处理器将会回溯正则表达式。它是传统 NFA (非确定有限自动机) 的变种, 如同类似的应用 Perl, Python, Emacs 和 Tcl。它用来替换在字符串中发现的匹配范式。
1. 正则表达式基础
元字符是特殊 字符, 就像 MQL5 和 C# 的管理序列一般, 指定操作的命令及管理序列。这些 字符会有前置的反斜线 (\), 而且它们的每一个都有特殊目的。
下表中的 MQL5 和 C# 正则表达式元字符, 根据其含义分组。
1.1. 字符类:
| 字符 | 描述 | 举例 | 匹配 |
|---|---|---|---|
| [...] | 在中括号里指示的所有字符 | [a-z] | 源字符串里可能存在的所有小写英文字母 |
| [^...] | 未在中括号里指示的所有字符 | [^0-9] | 源字符串里可能存在的除了数字的所有字符 |
| . | 除了换行或者其它 Unicode 分隔符之外的所有字符 | ta.d | 在 "trade" 字符串里的 "trad" |
| \w | 所有非空格符, 制表符等等的单词 | \w | 在 "MQL 5" 字符串里的 "M","Q","L","5" |
| \W | 所有不是单词的字符 | \W | 在 "MQL 5" 字符串里的 " ", "."。 |
| \s | 来自 Unicode 集合的所有空白符 | \w\s | 在 "MQL 5" 字符串里的 "L " |
| \S | 来自 Unicode 集合的所有非空白符请注意 这个 \w 和 \S 字符不一样 | \S | 在 "MQL 5" 字符窜里的 "M", "Q", "L", "5", "." |
| \d | 所有的 ASCII 数字。等效于 [0-9] | \d | 在 "MQL 5." 里的 "5" |
1.2. 重复字符:
| 字符 | 描述 | 举例 | 匹配 |
|---|---|---|---|
| {n,m} | 对应先前的范式, 重复不少于 n 或不多于 m 次 | s{2,4} | "Press", "ssl", "progressss" |
| {n,} | 对应先前的范式, 重复 n 或多于 m 次 | s{1,} | "ssl" |
| {n} | 与先前的范式精确匹配 n 个实例 | s{2} | "Press", "ssl", 但不包括 "progressss" |
| ? | 与先前的范式对应零个或一个实例; 先前的范式并非强制性的 | 等效于 {0,1} | |
| + | 与先前的范式对应一个或多个实例 | 等效于 {1,} | |
| * | 与先前的范式对应零个或多个实例 | 等效于 {0,} |
1.3. 选择正则表达式的字符:
| 字符 | 描述 | 举例 | 匹配 |
|---|---|---|---|
| | | 对应于左侧子表达式, 或右侧子表达式 (模拟逻辑操作 OR)。 | 1(1|2)0 | 在 "100, 110, 120, 130" 字符串里的 "110", "120" |
| (...) | 分组。在单一的整体里的分组元素, 可以使用字符 *, +, ?, |, 等等。 还应记住, 对应于该组的字符在子序列链表中还要用到。 | ||
| (?:...) | 仅有分组。在单一整体里的分组元素, 但不会记忆对应于该组的字符。 |
1.4. 正则表达式的定位字符:
| 字符 | 描述 | 举例 | 匹配 |
|---|---|---|---|
| ^ | 对应一个字符串表达式的开始, 或在多字符串搜索当中的字符串开始。 | ^Hello | "Hello, world", 但不是 "Ok, Hello world" 因为单词 "Hello" 在此字符串里没有位于开始 |
| $ | 对应一个字符串表达式的结尾, 或在多字符串搜索当中的字符串结尾。 | Hello$ | "World, Hello" |
| \b | 对应于单词边界, 即对应于 \w 和 \W 字符的之间位置 或在 \w 字符和字符串开始或结束之间。 | \b(my)\b | 在字符串 "Hello my world" 当中, 单词 "my" 被选中 |
有关正则表达式元素更多的信息, 请参阅 微软 官方网站上的文章。
2. MQL5 实现的正则表达式的功能
2.1. 第三方文件存储在内部文件夹
为了让 用于 MQL5 的正则表达式 更佳接近 .Net 的源代码, 它也需要传递第三方文件的一小部分。它们全被存储在 Internal 文件夹, 这也许是很有趣的。
让我们靠近些来看看 Internal 文件夹的内容。
- Generic — 此文件夹所包含的文件实现严格的类型化集合, 枚举和它们的接口。更多详尽描述提供如下。
- TimeSpan — 文件用来实现 TimeSpan 结构, 它提供一个时间间隔。
- Array.mqh — 在此文件里实现了具有若干静态方法的 Array 类, 用来操作数组。例如: 排序, 二叉树检索, 接收枚举, 接收元素索引, 等等。
- DynamicMatrix.mqh — 此文件有两个实现多维动态数组的主类。这些是范式类, 因此, 适合标准类型和指针类。
- IComparable.mqh — 文件实现 IComparable 接口, 这是支持类型化集合的一些方法所必要的。
- Wrappers.mqh — 查找哈希码的标准类型和方法的封套。
Generic 已实现了三个严格类型化的集合:
- List<T> 体现为严格类型化的可索引对象列表。支持通过列表搜索, 排序以及于其它列表的操作。
- Dictionary<TKey,TValue> 体现为关键字和数值的集合。
- LinkedList<T> 体现为双链列表。
让我们来看看 TradeHistoryParsing 智能交易程序中 List<T> 的用例。此 EA 从 .html 文件里读取所有交易历史, 并依据所选列和记录进行过滤。交易历史有两个表格构成: 成交和订单。类 OrderRecord 和 DealRecord 分别解读来自 Orders 和 Trades 表格的每一笔记录 (元组)。所以, 每一列可以表现为其记录的列表:
List<OrderRecord*>*m_list1 = new List<OrderRecord*>(); List<DealRecord*>*m_list2 = new List<DealRecord*>();
由于 List<T> 类支持排序方法, 这意味着 T 类型对象必须要在它们之间逐一比较。换言之, 为这个类型实现了<,>,== 操作符。对于标准元素这没问题, 但如果我们需要创建 List<T>, 此处 T 指明自定义类, 则我们会得到错误。有两种方式来处理这个问题。首先, 我们可以在我们的类中明确地重载比较运算符。另一种解决方案是编写 IComparable 接口的子类。第二种选择在实现时相当快捷, 然而, 它破坏了正确的排序。当有必要对自定义类进行排序的情况下, 我们必须重载所有比较运算符。此外, 建议实现继承。
这只是 List<T> 类的功能之一。更多信息提供如下。
Dictionary<TKey,TValue> — 具有唯一关键字及其相关数值集合的一种字典。若干数值可以同时赋予一个关键字。关键字类型和数值可在用户创建对象阶段确定。如同从描述里可见, 类 Dictionary<TKey,TValue> 十分适合哈希表的角色。为了提升 Dictionary<TKey,TValue> 的操作速度, 您应当创建一个新的类, 作为 IEqualityComparer<T> 的子类, 并重载两个函数:
- bool Equals(T x,T y) — 函数返回 true, 如果 x 等于 y, 以及 false — 如果反之。
- int GetHashCode(T obj) — 函数返回一个对象 obj 的哈希码。
在 MQL5 的 RegularExpressions 库里, 这个功能用于所有以字符串作为关键字的字典。
实现 StringEqualityComparer:
class StringEqualityComparer : public IEqualityComparer<string> { public: //--- 方法: //+------------------------------------------------------------------+ //| 判断指定对象是否相等。 | //+------------------------------------------------------------------+ virtual bool Equals(string x,string y) { if(StringLen(x)!=StringLen(y)){ return (false); } else { for(int i=0; i<StringLen(x); i++) if(StringGetCharacter(x,i)!=StringGetCharacter(y,i)){ return (false); } } return (true); } int GetHashCode(string obj) { return (::GetHashCode(obj)); } };
现在, 当创建属于 Dictionary<TKey,TValue> 类, 以字符串为关键字的新对象时, 我们将发送指针到 StringEqualityComparer 对象作为其构造器的参数:
Dictionary<string,int> *dictionary= new Dictionary<string,int>(new StringEqualityComparer);
LinkedList<T> 是 一个数据结构 包括一定数量的元素。每个元素包括一个信息部分, 和两个指向前一个和随后一个对象的指针。所以, 相邻两个元素互指彼此。列表的节点通过 LinkedListNode<T> 对象实现。在每个节点里都有标准设定, 其中包括数值, 指向列表和相邻节点的指针。
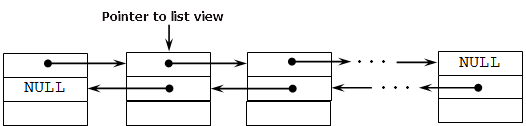
此外, 上述所有提及的三个集合均实现了枚举器。Enumerator 是一个广义的 IEnumerator<T> 接口。IEnumerator<T> 可以实现集合的全旁通, 无论其结构。
为了获取枚举器, 我们必须从对象里调用 GetEnumerator() 方法, 其类中实现了 IEnumerable 接口:
List<int>* list = new List<int>(); list.Add(0); list.Add(1); list.Add(2); IEnumerator<int> *en = list.GetEnumerator(); while(en.MoveNext()) { Print(en.Current()); } delete en; delete list;
在此例中, 我们迭代整个列表并输出每个数值。所有这些可以通过分配一个简单的 for 循环来实现, 但经常地, 使用枚举的方法更方便。事实上, 当创建 Dictionary<TKey,TValue> 的迭代之时, 这个解决方案十分适合。
2.2. MQL5 的 RegularExpressions 库功能
1. 为了在我们的项目里包括所有正则表达式的功能, 以下部分必须要加入:
#include <RegularExpressions\Regex.mqh>2. 由于在 MQL5 里缺乏名称空间, 因此, internal 访问修饰符, 我们可以访问到库中所有的内部类和方法。事实上, 当使用正则表达式操作时, 这些没必要考虑。
对于正则表达式操作, 以下的类将是我们感兴趣的:
- Capture — 提供子表达式中一个成功记录的结果。
- CaptureCollection — 提供由一个分组作出的记录集合。
- Group — 提供单独记录分组的结果。
- GroupCollection — 返回单一搜索匹配的记录分组集合。
- Match — 提供来自单独正则表达式匹配的结果。
- MatchCollection — 呈现在输入字符串当中通过正则表达式迭代发现的与范式成功匹配的集合。
- Regex — 代表不变的正则表达式。
除了以上提到的类, 我们还将使用:
- MatchEvaluator — 每次正则表达式发现匹配时要调用的表述方法指针。
- RegexOptions — 当正则表达式指定参数时使用的枚举表述值。
RegexOptions — 来自 .Net 源枚举的不完整拷贝, 包括以下元素:
| 参数 | 描述 |
|---|---|
| None |
参数未指定。 |
| IgnoreCase |
匹配搜索不区分大小写。 |
| Multiline | 指定多行模式。 |
| ExplicitCapture | 未覆盖没有名称的分组。仅有效选择 — 明确命名或具有格式的有数分组 (?<名称> 子表达式)。 |
| Singleline | 指定单行模式。 |
| IgnorePatternWhitespace | 不破坏顺序从范式里删除空白符, 并启用带有 "#" 字符标记的注释。 |
| RightToLeft | 指定搜索将从右向左执行, 而非从左向右。 |
| Debug | 指定程序使用调试器操作。 |
| ECMAScript | 启用表达式的 ECMAScript 兼容行为。此数值仅能配合 IgnoreCase 和 Multiline 使用。 |
这些选项可用于创建新的 Regex 类对象, 或当调用其静态方法时。
从 Tests.mq5 智能交易程序的源码当中可以找到所有这些类, 指针和枚举的使用例程。
3. 如同在 .Net 框架中的版本, 正则表达式的存储 (静态高速内存缓冲) 也已实现。所有未明确创建的正则表达式 (Regex 类的例子) 均被置于此存储内。如此方法可加快脚本的操作, 因为如果它们匹配存在的范式之一, 它不再需要从头开始构建正则表达式。存储容量省缺等于 15。方法 Regex::CacheSize() 返回或者指定一个当前静态高速缓存内已编译的正则表达式的最大记录数字。
4. 上述提及的存储需要被清除。为此目的将会调用静态函数 Regex::ClearCache()。当您完成正则表达式操作后建议清除存储, 否则当可能需要删除指针和对象时会有很高风险。
5. C# 语法可以在字符串之前放置 '@' 字符, 以便忽略所有格式化标志。MQL5 不提供这种方法, 因此在正则表达式的范式里的所有控制 字符 应当明确指定。
3. 分析交易历史举例
在此例中隐含以下操作。
- 从 .html 格式的沙盒里读取交易历史。
- 为随后的操作从 "订单" 或者 "成交" 选择一张表格。
- 选择表格的过滤器。
- 过滤后表格的图形表现。
- 基于已过滤表格的数理统计摘要。
- 保存已过滤表格的选项。
所有这 6 点在 TradeHistoryParsing.mq5 智能交易程序里均已实现。
首先, 当智能交易程序操作时, 一笔交易历史应被下载。所以, 在 MetaTrader5 终端上我们进入 "工具箱" 面板, "历史" 栏, 并右击鼠标键打开一个对话窗口, 选择 "报告" 及 HTML (Internet Explorer)。
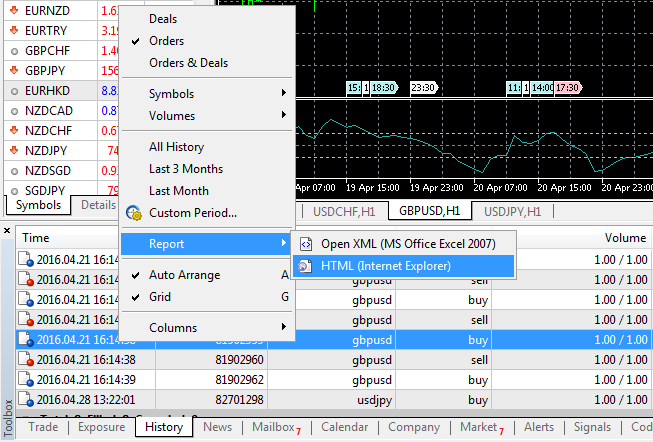
我们将文件保存在 沙箱里 (\MetaTrader 5\MQL5\Files)。
现在, 在对话窗口里运行智能交易程序时我们进入 "输入" 栏并在 file_name 字段里键入我们的文件名:
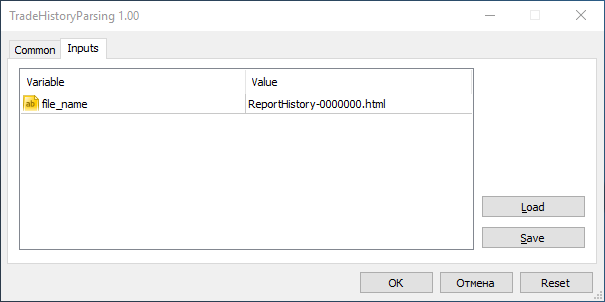
之后按下 "确定", EA 的界面将会出现:
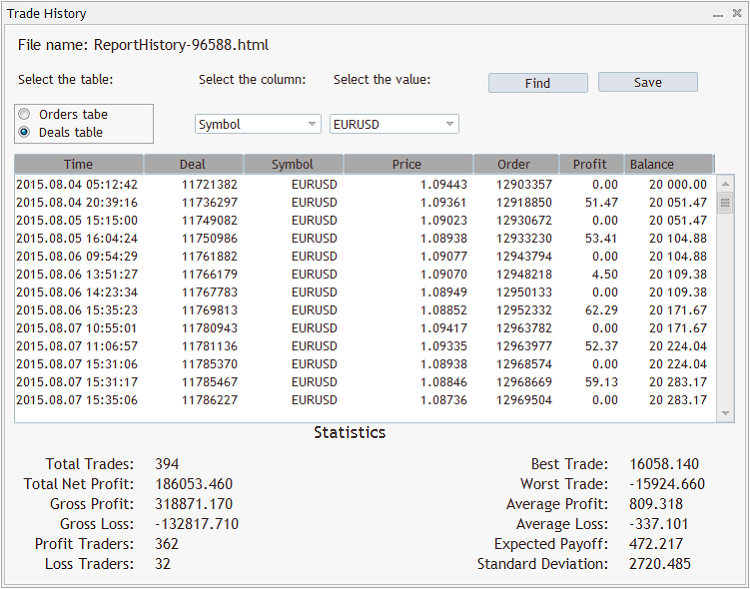
正如之前所述,在智能交易程序里两张表格以两个类型化的列表方式呈现: List<OrderRecord*> 和 List<DealRecord*>。
类 OrderRecord 和 DealRecord 的构造器使用字符串数组作为参数, 而它是来自表格中的单个记录。
为了创建这些数组我们将需要正则表达式。整体的历史分析在 TradeHistory 类的构造器里执行, 此处两个表示列均被保存, 且通过它们的过滤器来实现方法。类的构造器获取一个参数 — 路径, 在我们的例子里它是 .html 历史文件名:
TradeHistory(const string path) { m_file_name=path; m_handel= FileOpen(path,FILE_READ|FILE_TXT); m_list1 = new List<OrderRecord*>(); m_list2 = new List<DealRecord*>(); Regex *rgx=new Regex("(>)([^<>]*)(<)"); while(!FileIsEnding(m_handel)) { string str=FileReadString(m_handel); MatchCollection *matches=rgx.Matches(str); if(matches.Count()==23) { string in[11]; for(int i=0,j=1; i<11; i++,j+=2) { in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2); } m_list1.Add(new OrderRecord(in)); } else if(matches.Count()==27) { string in[13]; for(int i=0,j=1; i<13; i++,j+=2) { in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2); } m_list2.Add(new DealRecord(in)); } delete matches; } FileClose(m_handel); delete rgx; Regex::ClearCache(); }
此构造器的代码示意, 为了分析交易历史, 我们仅需要一个范式为 "(>)([^<>]*)(<)" 的正则表达式。让我们来仔细研究这个范式:
| (>) | 搜索 '>' 字符 |
| (^[<>]*) | 除了 '>' 和 '<' 的任意字符, 且重复零次或多次。 |
| (<) | 搜索 '<' 字符 |
此正则表达式遍历搜索所有起始为 '>' 且结尾是 '<' 的子字符串。在其之间的文本不应以 '<' 或 '>' 开始。换言之, 我们获得 .html 文件里标签之间的文本。在两侧将会有不必要的括号, 但它们很快会被删除。所有发现的子字符串会被保存在 MatchCollection 里, 它是在源字符串里被发现的, 所有满足正则表达式范式的子字符串的集合。由于 .html 文件的结构, 经过简单地计算匹配总数, 我们能够精确地判断是否我们的字符串是一笔来自订单、成交表格或者其它字符串的记录。以此方式, 如果匹配数量等于 23, 则记录来自订单表格, 或者匹配结果在 27 之上, 则是来自成交表格。若处于其它任何情况, 我们对此字符串不感兴趣。现在, 我们将从集合里提取所有偶数元素 ("><" 字符串处于奇数元素), 修剪第一个和最后一个字符, 并将准备就绪的字符串记录到数组:
in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2);
当每次读取新的字符串时, 匹配集合应当被删除。读取整个文件之后, 我们应该将其关闭, 删除正则表达式并清空缓冲区。
现在, 我们需要实现表格滤波器, 具体而言, 通过它选择一列, 及确定值, 来获得一个修订表格。在我们的例子中, 一个列表应该产生一个子表。为达此目的, 我们可以创建一个新的列表, 为旧表中的所有元素分配完整的迭代, 如果它满足指定条件, 我们将它添加到新的列表。
还有另一种方式是基于 List<T> 的 FindAll(Predicate match) 方法。它提取满足指定断言 (指向函数的指针) 条件的所有元素:
typedef bool (*Predicate)(IComparable*);
之前我们曾提到 IComparable 接口。
它留待实现真正的 match 函数, 此处我们已经知道如何接受或拒绝列表的规则。在我们的例子中, 这是一个列号码和其内含数值。为了解决 OrderRecord 和 DealRecord 类的子类 Record 存在的问题, 采用了两个静态方法 SetIndex(const int index) 和 SetValue(const string value)。它们接收并保存列号和数值。这个数据将被用于实现我们的搜索方法:
static bool FindRecord(IComparable *value) { Record *record=dynamic_cast<Record*>(value); if(s_index>=ArraySize(record.m_data) || s_index<0) { Print("Iindex 超出范围。"); return(false); } return (record.m_data[s_index] == s_value); }
此处, s_index 是一个静态变量, 其数值由 SetIndex 方法设置, s_value 也是一个静态变量, 其数值由 SetValue 设置。
现在, 通过指定必要的列号和其内部数值, 我们将会可轻易地获得我们的列表缩减版:
Record::SetValue(value); Record::SetIndex(columnIndex); List<Record*> *new_list = source_list.FindAll(Record::FindRecord);
这些已过滤列表将被显示在智能交易程序的图形界面上。
如有必要, 还有一个选项可以保存这些经过滤的表格至 .csv 文件。文件也会被保存在称为 Result.csv 的沙箱里。
重要!当保存文件时应当使用相同名字。以此方式, 如果需要保存两个或多个列, 我们必须逐一保存它们, 并且相应地改变它们的名称。否则, 我们最终将会重写同一文件。
4. 分析 EA 优化结果的例子
此例子处理来自 MetaTrader 5 终端 EA 优化结果的.xml 文件。它有一个图形界面, 用来在优化期间获取数据, 以及一个过滤选项。所有数据被划分为两个表:
- "测试器结果表" — 包括在测试期间获得的统计数据;
- "输入参数表" — 保存所有输入参数的数值。该表限制最多支持十个输入参数。超限量参数将不被显示。
为了给一个表设置过滤器, 我们应该选择列名并设置一个数值范围。
本例的图形化界面如下所示:
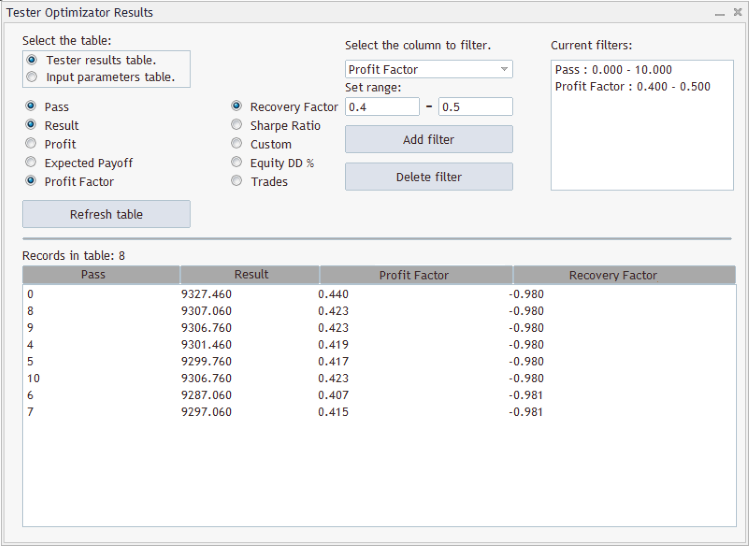
此图示意 "测试器结果表" 的 "通过", "结果", "盈利因子", "恢复因子" 等列被选中, 以及两个过滤器:
- 在 "通过" 列内的数值应属于 [0; 10] 数值范围;
- 在 "盈利因子" 列内的数值应属于 [0.4; 0.5] 数值范围。
5. 来自 MQL5 的 RegularExpressions 库例程摘要说明
除了以述的两个 EA, MQL5 的 RegularExpressions 库还提供了 20 个例程。它们展示了正则表达式以及库本身各种功能的实现。它们都位于 Tests.mq5 智能交易程序里:
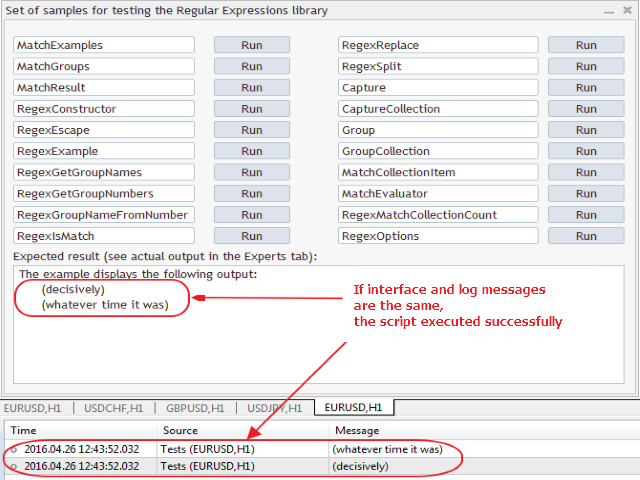
我们将研究每个实例中所用到的程序库特殊功能和选项。
- MatchExamples — 显示两个迭代所有匹配的可能选项, 即创建 MatchCollection 或是使用 Match.NextMatch() 方法。
- MatchGroups — 显示获取捕获 (Group) 的单独分组结果的方式, 以及进一步的操作。
- MatchResult — 演示 Match.Result(string) 方法的用例, 返回指定替代范式的扩展。
- RegexConstructor — 显示创建 Regex 类的三种不同选项: 基于范式, 指定参数的范式, 带参数和数值的范式以指示在超时到期前范式比较方法必须尝试多久。
- RegexEscape — 展示 Regex::Escape(string) 方法的操作。
- RegexExample — 指示创建正则表达式及其后续处理的过程。
- RegexGetGroupNames — 提供使用 Regex.GetGroupNames(string) 方法的例子;
- RegexGetGroupNumbers — 提供使用 Regex.GetGroupNumbers(int) 方法的例子;
- RegexGroupNameFromNumber — 提供使用 Regex.GroupNameFromNumber(int) 方法的例子;
- RegexIsMatch — 提供使用 Regex::IsMatch() 静态方法所有选项的例子;
- RegexReplace — 提供使用 Regex::Replace() 静态方法主要选项的例子;
- RegexSplit — 提供使用 Regex::Split() 静态方法主要选项的例子;
- Capture — 利用表达式成功捕获结果 (Capture) 进行操作的例子。
- CaptureCollection — 利用捕获组 (CaptureCollection 的捕获集合进行操作的例子。
- Group — 利用单独的 Group 结果进行操作的例子。
- GroupCollection — 利用单独搜索匹配 (GroupCollection) 内的捕获组集合操作的例子。
- MatchCollectionItem — 创建具有 Regex::Matches(string,string) 静态方法的 MatchCollection;
- MatchEvaluator — 创建和使用指向 MatchEvaluator 类型函数指针的例子。
- RegexMatchCollectionCount — 展示 MatchCollection.Count() 方法;
- RegexOptions — 展示 RegexOptions 参数对正则表达式处理的影响。
大多数例子也有类似的功能, 并主要为测试程序库是如何工作而服务。
结论
本文概括介绍了正则表达式的应用和功能。更多详细信息, 我们建议参阅以下链接的文章。在 MQL5 里实现了许多 .Net 的常用正则表达式语法, 所以与来自微软的帮助信息至少大部分相对应。这同样适用于 Internal 文件夹内的类。
引用
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/2432
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。

 EA交易的自我优化: 进化与遗传算法
EA交易的自我优化: 进化与遗传算法
 交易者的 LifeHack: 测试中的余额,回撤,负载和订单指标
交易者的 LifeHack: 测试中的余额,回撤,负载和订单指标
 通用EA交易:与MetaTrader的标准信号模块集成 (第7部分)
通用EA交易:与MetaTrader的标准信号模块集成 (第7部分)
我无法在 MT5 build1340 上运行您的示例,因为在编译过程中。