
数据科学和机器学习(第 38 部分):外汇市场中的 AI 迁移学习

内容
什么是迁移学习?
迁移学习是一种机器学习技术,其中把一个据某任务训练好的模型重新改造,作为第二个任务的基础。
在迁移学习中,取代从零开始训练机器学习模型,我们转移预训练模型的所学知识,并针对具体的新任务进行优调。该技术在以下情况下非常实用:
- 我们没有太多针对特定任务的标注数据。
- 从零开始训练模型会耗时过长、或需要过多的计算能力。
- 手头的任务与原始模型训练的任务有相似之处。
此处是一个现实示例,其中 AI 专家使用迁移学习;
假设您正在构建一个猫狗图像分类器,但您仅有 1000 张图片。从零开始训练深度卷积网络会很困难,您可先用 ResNet50 或 VGG16 等已在 ImageNet 上训练好的模型(ImageNet 有 1000 个类别的数百万张图像),然后用卷积层作为特征提取器,再添加自定义分类层,并在您所有的较小猫狗数据集上优调。
该过程开启了模型信息的共享,这令我们作为开发者的生涯更轻松,在于我们不想每次都重新发明轮子,取代从零开始训练模型,对于十分相似的任务,您可目的明确的基于可用模型进行取舍。
也就是说,大多数会滑冰或经常滑冰的人,即使没有经过密集的专项训练,在滑雪或滑雪运动中也会表现良好,反之亦然。这仅仅是因为这两项运动有一些相似之处。
这在金融市场中也当真,尽管有不同的金融工具(品种)代表不同的经济资产、或金融市场,但所有市场大多数时候行为相似,因为它们都是受到供需关系驱动和影响。

如果您从技术角度仔细观察市场,所有市场都倾向于上下波动,所有市场的烛条形态相似,不同金融工具上的指标也展现出相似的形态,还有更多。这也是为什么我们常常在单一金融工具上学习技术分析交易策略的主要原因,并将所学知识应用到所有市场,无关每种金融工具的价格量级差别。
在机器学习中,模型往往不能理解这些市场是可比的。在本文中,我们将讨论如何利用转移学习,来帮助模型理解各种金融工具中的形态,从而有效训练模型,该技术的优缺点,以及有效迁移学习所需考虑的诸多事项。
迁移学习是如何运作的?
迁移学习是一种聪明的模型复用方式,从一个任务中学到的知识,应用到另一个不同、但相关的任务上。这能节省时间,往往还会提升性能。
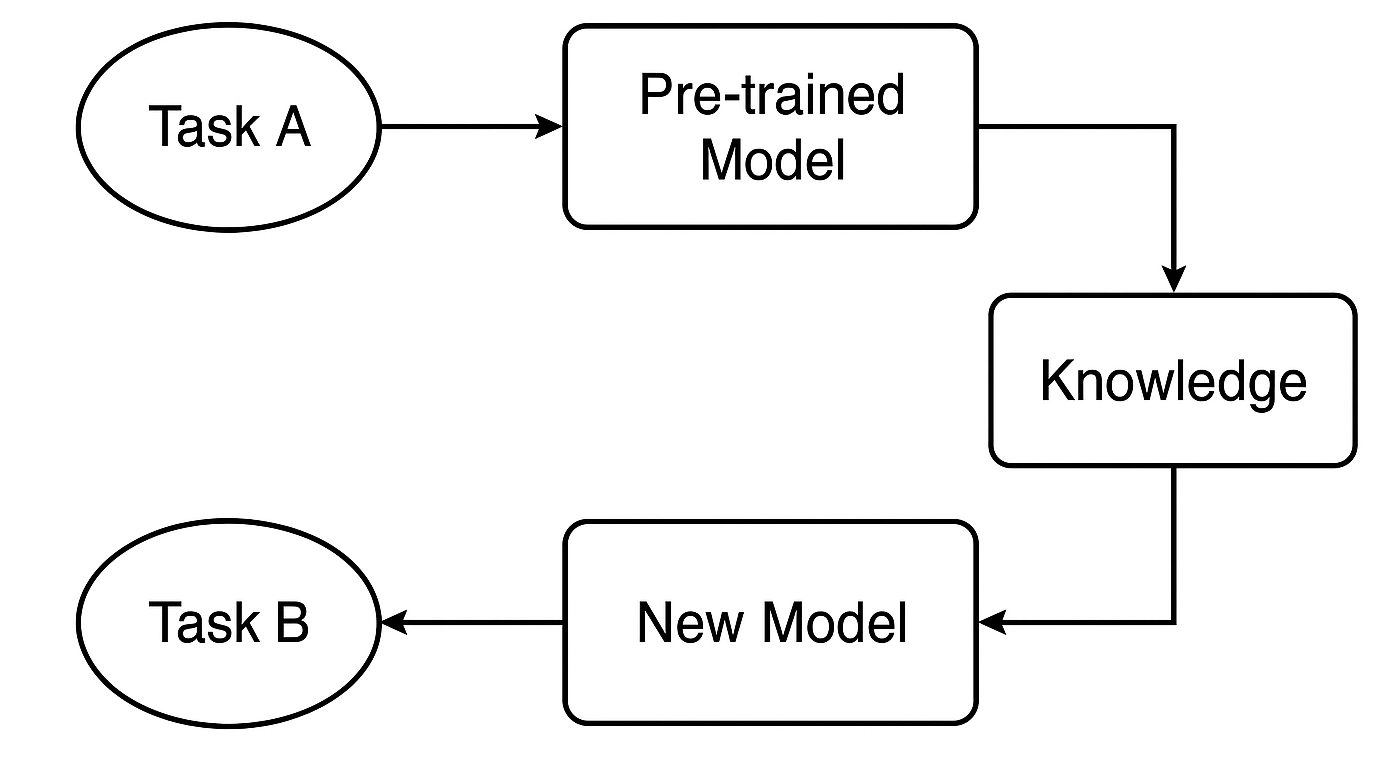
什么是预训练模型?
我们从一个已在任务 A 的大数据集上训练好的模型开始。该模型已学会识别能用到类似任务的普适形态和特征。
例如,在交易中,它可能是一个基于某一策略或品种训练好的模型,其已理解在其它外汇金融工具中也会出现的共同市场行为。
知识如何转移?
如果我们正在用像是 CNN 或 RNN 的神经网络,我们可取早期的层 — 捕捉普适特征的层 — 并复用它们。这些层权当基础,检测对原始和新任务都有益的宽泛形态。
针对新任务优调
接下来,我们调整模型,针对任务 B — 或许是其它金融工具或策略 — 优调某些层或参数,如此它就能搭配新数据执行良好。这一步是针对新状况定制模型。
为什么要使用迁移学习?
1. 更快的训练
取代从零开始,我们复用已学会的特征。这明显缩短了训练时间 — 尤其是在深度学习中,节省数小时、甚至数天的计算时间,这能带来巨大差别。
2. 往往会提升准确性
采用迁移学习的模型倾向于性能更佳,尤其是当标记数据有限时。预训练模型已知道如何检测重要信号,像是交易设置或指标,其有助于它在新任务中制定更聪明的决策。
3. 即使数据集较小、或太嘈杂,也能起作用
我们来面对它:在 MetaTrader 5 中获取一些品种的优质历史或即刻数据很难难。一些金融工具数据根本就不足。但使用依据更丰富数据集训练好的模型,我们就能避免过度拟合,即使数据有限,仍可构建强大的模型。
4. 跨金融工具的可复用知识
市场在技术层面上往往行为类似。故此,我们不必针对每个品种都训练一个新模型,而是在不同金融工具间共享和复用知识 — 节省时间,并提升一致性。
一个简单的基础模型
我们来训练一个简单的随机森林分类器,以获得一个起点(基础模型)。出于简化,我们就用 OHLC(开盘价、最高价、最低点、和收盘价)数值。
我们首从收集各种主要和次要外汇金融工具的 OHLC 价格开始,并在混搭里加入一些金属。
#include <pandas.mqh> //https://www.mql5.com/en/articles/17030 input datetime start_date = D'2005.01.01'; input datetime end_date = D'2023.01.01'; input string symbols = "EURUSD|GBPUSD|AUDUSD|USDCAD|USDJPY|USDCHF|NZDUSD|EURNZD|AUDNZD|GBPNZD|NZDCHF|NZDJPY|NZDCAD|XAUUSD|XAUJPY|XAUEUR|XAUGBP"; input ENUM_TIMEFRAMES timeframe = PERIOD_D1; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string SymbolsArr[]; ushort sep = StringGetCharacter("|",0); if (StringSplit(symbols, sep, SymbolsArr)<0) { printf("%s failed to split the symbols, Error %d",__FUNCTION__,GetLastError()); return; } //--- vector open, high, low, close; for (uint i=0; i<SymbolsArr.Size(); i++) { string symbol = SymbolsArr[i]; if (!SymbolSelect(symbol, true)) { printf("%s failed to select symbol %s, Error = %d",__FUNCTION__,symbol,GetLastError()); continue; } //--- open.CopyRates(symbol, timeframe, COPY_RATES_OPEN, start_date, end_date); high.CopyRates(symbol, timeframe, COPY_RATES_HIGH, start_date, end_date); low.CopyRates(symbol, timeframe, COPY_RATES_LOW, start_date, end_date); close.CopyRates(symbol, timeframe, COPY_RATES_CLOSE, start_date, end_date); CDataFrame df; df.insert("Open", open); df.insert("High", high); df.insert("Low", low); df.insert("Close", close); df.to_csv(StringFormat("Fxdata.%s.%s.csv",symbol,EnumToString(timeframe)), true); } }
数据收集完毕之后,我们就能立即在 Python 脚本内访问 CSV 文件。
def getXandY(symbol: str, timeframe: str, lookahead: int) -> tuple: df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{symbol}.{timeframe}.csv") # Target variable df["future_close"] = df["Close"].shift(-lookahead) df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) # Splitting data into X and y X = df.drop(columns=[ "future_close", "Signal" ]) y = df["Signal"] return (X, y)
读取 CSV 文件之后,getXandY 函数基于简单逻辑准备目标变量,如果下一根柱线的收盘价大于当前收盘价,则是看涨信号;当下一根柱线收盘价低于当前收盘价时,则是对立信号。
我们基于 X 和 y 数据打造训练模型的函数,并在 Scikit-学习流水线中返回一个训练好的模型。
def trainSymbol(X_train: pd.DataFrame, y_train: pd.DataFrame) -> Pipeline: # Training a model classifier = RandomForestClassifier(n_estimators=100, min_samples_split=3, max_depth = 5) pipeline = Pipeline([ ("scaler", RobustScaler()), ("classifier", classifier) ]) pipeline.fit(X_train, y_train) return pipeline
若有一个跨不同金融工具评估该模型的函数会很实用。
def evalSymbol(model: Pipeline, X: pd.DataFrame , y: pd.Series) -> int: # evaluating the model preds = model.predict(X) acc = accuracy_score(y, preds) return acc
我们先用 EURUSD 训练基础模型,然后评估其在剩余品种上的性能。
symbols = ["EURUSD","GBPUSD","AUDUSD","USDCAD","USDJPY","USDCHF","NZDUSD","EURNZD","AUDNZD","GBPNZD","NZDCHF","NZDJPY","NZDCAD","XAUUSD","XAUJPY","XAUEUR","XAUGBP"] # training on EURUSD lookahead = 1 X, y = getXandY(symbol=symbols[0], timeframe="PERIOD_H4", lookahead=lookahead) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, shuffle=True) model = trainSymbol(X_train, y_train) # Evaluating on the rest of symbols trained_symbol = symbols[0] print(f"Trained on {trained_symbol}") for symbol in symbols: X, y = getXandY(symbol=symbol, timeframe="PERIOD_H4", lookahead=1) acc = evalSymbol(model, X, y) print(f"--> {symbol} | acc: {acc}")
输出:
Trained on EURUSD --> EURUSD | acc: 0.5478518727715607 --> GBPUSD | acc: 0.5009182736455464 --> AUDUSD | acc: 0.5026133634694165 --> USDCAD | acc: 0.4973701860284514 --> USDJPY | acc: 0.49477401129943505 --> USDCHF | acc: 0.5078731817539895 --> NZDUSD | acc: 0.4976826463824518 --> EURNZD | acc: 0.5071507150715071 --> AUDNZD | acc: 0.5005597760895641 --> GBPNZD | acc: 0.503459397596629 --> NZDCHF | acc: 0.4990389436737423 --> NZDJPY | acc: 0.4908841561794127 --> NZDCAD | acc: 0.5023507681974645 --> XAUUSD | acc: 0.48674396277970605 --> XAUJPY | acc: 0.4816082121471343 --> XAUEUR | acc: 0.4925268155442237 --> XAUGBP | acc: 0.49455864570737607
模型在训练品种上准确率为 0.54,再其余品种上的准确率在 0.48 到0.50 之间,您或许会认为这与训练品种达成的效果差别不大,那么这意味着模型在未训练品种上运作良好;不过至少可以这么说, 这个成果太糟糕了。
简言之因为胜率为 1 的 0.5(100% 中的 50%),就像抛硬币,您的胜率也是 1 的 0.5。
尽管基准模型看似能在其它未训练过的金融工具上做出一些预测,但我们遇到的是连续特征(变量)导致的巨大问题。那些 OHLC 数值。
连续变量的问题
由于我们想打造健壮且通用的基准模型,令其能检测形态,并跨多品种操作,连续变量特征如开盘价、最高价、最低价、和收盘价在这项任务中并不适用,因为它们除了显示以往的价格走势之外,未提供其它形态。
更更不用提来自各种金融工具的价格差异量级。例如,今天的收盘价如下:
| 品种 | 每日收盘价 |
|---|---|
| USDJPY | 142.17 |
| EURUSD | 1.13839 |
| XAUUSD | 3305.02 |
这意味着在每种金融工具上训练的模型,由于它们的价格差异,或许不能应对其它品种。
除了不包含可学习的形态之外,据连续变量训练的模型需要频繁地重复训练,因为市场每天都在达到新的高度,故我们只得规律性训练模型,以便保持配速,并用新的/最新信息更新模型,这提升了计算成本,而迁移学习的标靶正是解决这一点。
仅有平稳变量能够协助机器学习模型跨不同市场捕捉信息,并令它们具有相关性,只是因为它们的均值、方差、和自相关性不随时间变化(它们维持常量)。这可在不同金融工具上观察到。
如果我们想利用迁移学习,那么从市场中提取的所有特征,如指标和形态,在自变量中必须要么是常量、或是平稳的。
例如,如果您读取任何金融工具的 RSI 指标读值,都会在 0 到 100 之间,这对于捕捉形态至关重要。
特征工程
有大量技术我们能够部署,并得到平稳变量,但目前,我们只能用少量技术来加工数据,比如计算收盘价的变化百分比、每个 OHLC 的差值,以及使用一些平稳指标。
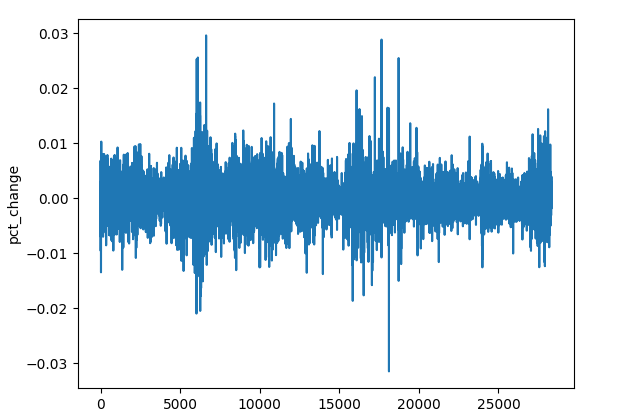
(a):收盘价变化百分比
res_df["pct_change"] = df["Close"].pct_change()
尽管不同品种(金融工具)价格量级有差异,但变化百分比数值始终是常量,令它们成为优秀的形态检测通用特征。
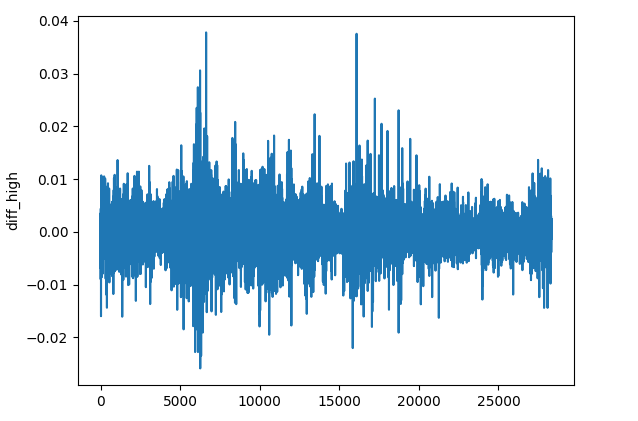
(b):每个 OHLC 值差值
res_df["diff_open"] = df["Open"].diff() res_df["diff_high"] = df["High"].diff() res_df["diff_low"] = df["Low"].diff() res_df["diff_close"] = df["Close"].diff()
diff() 方法计算当前元素与前一个元素之间的差值(按默认)。该特征能帮助我们检测每个金融工具的每根柱线与前一根柱线的价格差值。
(c):平稳指标
我们能够添加一些动量和振荡指标,来展现平稳成果。
指标 | 数值范围 |
|---|---|
# Relative Strength Index (RSI) res_df['rsi'] = ta.momentum.RSIIndicator(df["Close"], window=14).rsi() | 从 0 到 100。 |
# Stochastic Oscillator (Stoch) res_df['stoch_k'] = ta.momentum.StochasticOscillator(df['High'], df['Low'], df['Close'], window=14).stoch() | 从 0 到 100。 |
# Moving Average Convergence Divergence (MACD) res_df['macd'] = ta.trend.MACD(df["Close"]).macd() | 很小的正数值和负数值,通常在 -0.1 至 +0.1 之间。 |
# Commodity Channel Index (CCI) res_df['cci'] = ta.trend.CCIIndicator(df['High'], df['Low'], df['Close'], window=20).cci() | 典型值从 -300 到 +300.。 |
# Rate of Change (ROC) res_df['roc'] = ta.momentum.ROCIndicator(df["Close"], window=12).roc() | 无界,既可是负数值的,亦可是正数值。 |
# Ultimate Oscillator (UO) res_df['uo'] = ta.momentum.UltimateOscillator(df['High'], df['Low'], df['Close'], window1=7, window2=14, window3=28).ultimate_oscillator() | 从 0 到 100。 |
# Williams %R res_df['williams_r'] = ta.momentum.WilliamsRIndicator(df['High'], df['Low'], df['Close']).williams_r() | 从 -100 到 0。 |
# Average True Range (ATR) res_df['atr'] = ta.volatility.AverageTrueRange(df['High'], df['Low'], df['Close'], window=14).average_true_range() | 无界的小正数值。 |
# Awesome Oscillator (AO) res_df['ao'] = ta.momentum.AwesomeOscillatorIndicator(df['High'], df['Low']).awesome_oscillator() | 无界的小数值,典型值从 -0.1 到 +0.1 |
# Average Directional Index (ADX) res_df['adx'] = ta.trend.ADXIndicator(df['High'], df['Low'], df['Close'], window=14).adx() | 从 0 到 100。 |
# True Strength Index (TSI) res_df['tsi'] = ta.momentum.TSIIndicator(df['Close'], window_slow=25, window_fast=13).tsi() | 典型值从 -100 到 +100.。 |
这些只是一些平稳变量,您可随意补充更多。
所有这些方法和操作都能夹带在独立函数当中。
def getStationaryVars(df: pd.DataFrame) -> pd.DataFrame: res_df = pd.DataFrame() res_df["pct_change"] = df["Close"].pct_change() res_df["diff_open"] = df["Open"].diff() res_df["diff_high"] = df["High"].diff() res_df["diff_low"] = df["Low"].diff() res_df["diff_close"] = df["Close"].diff() # Relative Strength Index (RSI) res_df['rsi'] = ta.momentum.RSIIndicator(df["Close"], window=14).rsi() # Stochastic Oscillator (Stoch) res_df['stoch_k'] = ta.momentum.StochasticOscillator(df['High'], df['Low'], df['Close'], window=14).stoch() # Moving Average Convergence Divergence (MACD) res_df['macd'] = ta.trend.MACD(df["Close"]).macd() # Commodity Channel Index (CCI) res_df['cci'] = ta.trend.CCIIndicator(df['High'], df['Low'], df['Close'], window=20).cci() # .... See the code in the notebook in the attachments and above # .... # .... # True Strength Index (TSI) res_df['tsi'] = ta.momentum.TSIIndicator(df['Close'], window_slow=25, window_fast=13).tsi() return res_df
现在我们来创建一个基准模型,把来自一个金融工具的知识迁移到另一个。
迁移学习
迁移学习通常在深度模型上进行,大多是卷积神经网络(CNN)。只是因为 CNN 擅长形态检测,这种能力令其能够识别相似的形态,并能迁移到同一领域的不同层面。
我们把卷积神经网络(CNN)模型夹带在一个名为 trainCNN 的函数之中。
import tensorflow as tf from tensorflow.keras import layers, models, Model from tensorflow.keras.callbacks import EarlyStopping
def trainCNN(train_set: tuple, val_set: tuple, learning_rate: float=1e-3, epochs: int=100, batch_size: int=32): X_train, y_train = train_set X_val, y_val = val_set input_shape = X_train.shape[1:] num_classes = len(np.unique(y_train)) model = models.Sequential([ layers.Input(shape=input_shape), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.GlobalAveragePooling1D(), layers.Dense(32, activation='tanh'), layers.Dense(num_classes, activation='softmax') ]) # Compile with Adam optimizer model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='categorical_crossentropy', metrics=['accuracy'] ) # Early stopping callback early_stop = EarlyStopping( monitor='val_loss', # Watch validation loss patience=10, # Stop if no improvement restore_best_weights=True ) # Train the model model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=epochs, batch_size=batch_size, callbacks=[early_stop], verbose=1 ) # Save trained weights model.save_weights('cnn_pretrained.weights.h5') return model
该序列模型有两个 1-维卷积层,能帮助我们从输入序列中提取特征。
引入全局平均池化层来降低序列,如此它们能被投喂到密度层(FNN 层),激活函数是 tanh。
最后一层激活函数 softmax,用于返回每个类的预测概率。
我们保存模型权重,在于它们代表所有从数据中学到的形态,这些权重能被传递给前一个模型。
采用 EURUSD 的 H4 时间帧,我们可从原始数据帧中收集 OHLC 数值。
lookahead = 1 trained_symbol = symbols[0] timeframe = "PERIOD_H4" df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{trained_symbol}.{timeframe}.csv") stationary_df = getStationaryVars(df) stationary_df["Close"] = df["Close"] # add the close price for crafting the target variable X, y = getXandY(df=stationary_df, lookahead=lookahead)
再次,函数 getXandY 采用收盘价,基于给定的前瞻值(本例为 1),创建目标变量。
def getXandY(df: pd.DataFrame, lookahead: int) -> tuple: # Target variable df["future_close"] = df["Close"].shift(-lookahead) df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) # if next bar closed above the current one, thats a bullish signal otherwise bearish # Splitting data into X and y X = df.drop(columns=[ "Close", "future_close", "Signal" ]) y = df["Signal"] return (X, y)
我们必须将数据拆分为训练集和验证(测试)集,然后用所选的标量(本例是 健壮度)标准化成果。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=42) # Scalling the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)
由于卷积神经网络(CNN)需要 3-维输入/数据,我们处理这些数据时,能限定在特定窗口以内,从而覆盖特定横向范围检测时间形态。
def create_sequences(X, Y, time_step): if len(X) != len(Y): raise ValueError("X and y must have the same length") X = np.array(X) Y = np.array(Y) Xs, Ys = [], [] for i in range(X.shape[0] - time_step): Xs.append(X[i:(i + time_step), :]) # Include all features with slicing Ys.append(Y[i + time_step]) return np.array(Xs), np.array(Ys)
# Prepare data within a window window = 10 X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, window) X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, window)
独热编码对于涉及神经网络的任何分类问题中的目标变量都至关重要,在于它有助于区分类别。
# One-hot encode the labels for multi-class classification
y_train_encoded = to_categorical(y_train_seq, num_classes=num_classes)
y_test_encoded = to_categorical(y_test_seq, num_classes=num_classes)
最后,我们能训练一个基准模型。
base_model = trainCNN(train_set=(X_train_seq, y_train_encoded), val_set=(X_test_seq, y_test_encoded), learning_rate = 0.01, epochs = 1000, batch_size =32) print("Test acc: ", base_model.evaluate(X_test_seq, y_test_encoded)[1])
输出:
Epoch 1/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 4s 4ms/step - accuracy: 0.4994 - loss: 0.6990 - val_accuracy: 0.5023 - val_loss: 0.6938 Epoch 2/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4976 - loss: 0.6939 - val_accuracy: 0.5023 - val_loss: 0.6936 Epoch 3/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4977 - loss: 0.6940 - val_accuracy: 0.5023 - val_loss: 0.6938 Epoch 4/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5034 - loss: 0.6937 - val_accuracy: 0.4977 - val_loss: 0.6962 ... ... Epoch 16/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5039 - loss: 0.6934 - val_accuracy: 0.5023 - val_loss: 0.6932 Epoch 17/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4988 - loss: 0.6940 - val_accuracy: 0.4977 - val_loss: 0.6937 Epoch 18/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5013 - loss: 0.6943 - val_accuracy: 0.5023 - val_loss: 0.6931 266/266 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.5037 - loss: 0.6931 Test acc: 0.5022971034049988
太棒了,我们刚刚依据 EURUSD 训练好一个基准模型,整体准确率达到了 0.502。
现在,我们用该模型来迁移并分享自其它不同金融工具训练得来的知识,看看成效如何。
for symbol in symbols: if symbol == trained_symbol: # skip transfer learning on the trained symbol continue print(f"Symbol: {symbol}") df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{symbol}.{timeframe}.csv") stationary_df = getStationaryVars(df) stationary_df["Close"] = df["Close"] # we add the close price for crafting the target variable X, y = getXandY(df=stationary_df, lookahead=lookahead) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=42) # Scalling the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # Prepare data within a window window = 10 X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, window) X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, window) # One-hot encode the labels for multi-class classification y_train_encoded = to_categorical(y_train_seq, num_classes=num_classes) y_test_encoded = to_categorical(y_test_seq, num_classes=num_classes) # Freeze all layers except the last one for layer in base_model.layers[:-1]: layer.trainable = False # Create new model using the base model's architecture model = models.clone_model(base_model) model.set_weights(base_model.get_weights()) # Recompile with lower learning rate model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy']) early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = model.fit(X_train_seq, y_train_encoded, validation_data=(X_test_seq, y_test_encoded), epochs=1000, # More epochs for fine-tuning batch_size=32, callbacks=[early_stop], verbose=1) print("Test acc:", model.evaluate(X_test_seq, y_test_encoded)[1])
同样的过程也可复用于拆分数据、创建顺序数据、和编码目标变量。针对每个品种仅需指定操作。
为了迁移基准模型的知识,我们据其构建另一个模型,此处的关键是冻结一些 CNN 层。
我们冻结 CNN 模型的所有层,最后一层除外,因为我们要保留模型从基准数据中学到的形态。通过冻结一些层,我们就可预防当依据新数据重新训练模型时破坏有用的特征。
我们留下最后一层不冻结,因为我们打算把最终层的权重按每个品种的新决策边界重新校准,故基本上,我们为模型提供了目标变量的新分布,令其判定基准模型中学到的形态、与新数据中目标变量之间的关系。
我们还把基准模型的架构克隆到当前模型,并将其权重赋予新模型。记住我们把权重保存在 trainCNN 函数里,当您导入模型时可直接从文件加载权重,或者若基准模型在同一个 Python 脚本或文件当中,也可直接从模型对象加载权重,就像上面那样。
末了,我们在编译模型时,会采用与训练基准模型不同的金融工具的市场数据,其它参数也可被修改。
以下是跨不同外汇品种达成的准确度。
| 品种 | GBPUSD | AUDUSD | USDCAD | USDJPY | USDCHF | NZDUSD | EURNZD | AUDNZD | GBPNZD | NZDCHF | NZDJPY | NZDCAD | XAUUSD | XAUJPY | XAUEUR | XAUGBP |
| ACCURACY | 0.505 | 0.506 | 0.501 | 0.516 | 0.506 | 0.497 | 0.505 | 0.502 | 0.504 | 0.505 | 0.51 | 0.505 | 0.506 | 0.514 | 0.507 | 0.504 |
该成果并不能告诉我们太多信息,我们协同分类报告来详细分析该成果。
preds = base_model.predict(X_test_seq) pred_indices = preds.argmax(axis=1) pred_class_labels = [classes_in_y[i] for i in pred_indices] print("Classification report\n", classification_report(pred_class_labels, y_test_seq))
基准模型的分类报告。
Classification report precision recall f1-score support 0 1.00 0.50 0.66 8477 1 0.00 0.00 0.00 0 accuracy 0.50 8477 macro avg 0.50 0.25 0.33 8477 weighted avg 1.00 0.50 0.66 8477
该成果示意一个可怕的结局。该模型产生的分类报告颇具偏见。
这表明我们的模型存在偏见,这可能是由模型或数据导致。
正如我们在之前文章中讨论的,有几种途径可解决这种偏见状况,但现在,我们先做几件事:
(a):如果数据中存在类别不平衡,我们就添加类别权重来修正。
from sklearn.utils.class_weight import compute_class_weight
def trainCNN: #.... #.... y_train_integers = np.argmax(y_train, axis=1) # return to non-one hot encoded class_weights = compute_class_weight('balanced', classes=np.unique(y_train_integers), y=y_train_integers) class_weight_dict = {i: weight for i, weight in enumerate(class_weights)} # Train the model model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=epochs, batch_size=batch_size, callbacks=[early_stop], class_weight=class_weight_dict, verbose=1 )
(b):我们再增加一个卷积层,并提升密度层的神经元数量,帮助捕捉复杂形态。
def trainCNN: # ... # ... model = models.Sequential([ layers.Input(shape=input_shape), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(32, kernel_size=3, activation='relu', padding='same'), layers.GlobalAveragePooling1D(), layers.Dense(128, activation='relu'), layers.Dense(num_classes, activation='softmax') ])
(c):由于这是一个二元分类问题,我们的目标变量中只有两个类别。卖出信号为 0,买入信号为 1,我们将损失函数改为 “binary_crossentropy”,评估量值改为 “binary_accuracy”。
# Compile with Adam optimizer model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='binary_crossentropy', metrics=['binary_accuracy'] )
当 CNN 模型重新训练时,数值看起来好多了。
.... .... 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5257 - loss: 0.6920 - val_binary_accuracy: 0.5043 - val_loss: 0.6933 Epoch 7/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5259 - loss: 0.6918 - val_binary_accuracy: 0.5027 - val_loss: 0.6934 Epoch 8/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5283 - loss: 0.6915 - val_binary_accuracy: 0.5042 - val_loss: 0.6936 Epoch 9/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5284 - loss: 0.6912 - val_binary_accuracy: 0.5028 - val_loss: 0.6937 Epoch 10/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5315 - loss: 0.6909 - val_binary_accuracy: 0.5036 - val_loss: 0.6938 Epoch 11/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5295 - loss: 0.6907 - val_binary_accuracy: 0.5042 - val_loss: 0.6940 Epoch 12/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5298 - loss: 0.6904 - val_binary_accuracy: 0.5074 - val_loss: 0.6941 619/619 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5101 - loss: 0.6926 265/265 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - binary_accuracy: 0.5018 - loss: 0.6933 Train acc: 0.5114434361457825 Test acc: 0.5050135850906372 265/265 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step Classification report precision recall f1-score support 0 0.58 0.50 0.54 4870 1 0.43 0.51 0.47 3607 accuracy 0.51 8477 macro avg 0.51 0.51 0.50 8477 weighted avg 0.52 0.51 0.51 8477
修改参数并无特别原因。我曾想证明,就像任何其它基于神经网络的模型,优化和调谐参数都非常重要。
目前的成果或许也不是最优解,就如关于卷积神经网络和神经网络的话题我们还有很多能讨论。
我们提议当下先参数,但您可以随意调谐这些数值,以获得适合您需要的模型。
现在我们有一个不那么偏见的基准模型,能用它将知识迁移到其它金融工具上,并将所有模型保存为 ONNX 格式,以便观察迁移学习在真实交易环境中的成果。
交易机器人(EA)上的迁移学习
为了在 MetaTrader 5 的交易环境中测试迁移学习,我们必须先将模型保存为 ONNX 格式,然后用 MQL5 编程语言加载。
导入。
import onnxmltools import tf2onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
函数
def saveCNN(model, window: int, features: int, filename: str): model.output_names = ["output"] # Specifying the input signature for the model spec = (tf.TensorSpec((None, window, features), tf.float16, name="input"),) # Convert the Keras model to ONNX format onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=14) # Save the ONNX model to a file with open(filename, "wb") as f: f.write(onnx_model.SerializeToString())
由于 Keras 模型不支持管道,而像我们常用的都夹带所有预处理技术与 Scikit-learn 模型,这令保存模型及其所有步骤到单一 ONNX 文件变得更容易,因此我们必须将 Keras 模型和缩放器分别保存到独立的 ONNX 文件。
def saveScaler(scaler, features: int, filename: str): # Convert to ONNX format initial_type = [("input", FloatTensorType([None, features]))] onnx_model = convert_sklearn(scaler, initial_types=initial_type, target_opset=14) with open(filename, "wb") as f: f.write(onnx_model.SerializeToString())
现在,我们可以在保存基准模型和之前的模型时调用这些函数。
保存基准模型。
# .... # .... base_model = trainCNN(train_set=(X_train_seq, y_train_encoded), val_set=(X_test_seq, y_test_encoded), learning_rate = 0.01, epochs = 1000, batch_size =32) saveCNN(model=base_model, window=window, features=X_train_seq.shape[2], filename=f"{trained_symbol}.basemodel.{timeframe}.onnx") saveScaler(scaler=scaler, features=X_train.shape[1], filename=f"{trained_symbol}.{timeframe}.scaler.onnx")
保存迁移学习训练过的模型。
for symbol in symbols: # ... # ... history = model.fit(X_train_seq, y_train_encoded, validation_data=(X_test_seq, y_test_encoded), epochs=1000, # More epochs for fine-tuning batch_size=32, callbacks=[early_stop], verbose=1) saveCNN(model=model, window=window, features=X_train_seq.shape[2], filename=f"basesymbol={trained_symbol}.symbol={symbol}.model.{timeframe}.onnx") saveScaler(scaler=scaler, features=X_train.shape[1], filename=f"{symbol}.{timeframe}.scaler.onnx")
在将文件保存到 Common Folder 之后,我们就能在智能系统(EA)内,以类似的命名式样加载它们。
#include <ta.mqh> //similar to ta in Python --> https://www.mql5.com/en/articles/16931 #include <pandas.mqh> //similar to Pandas in Python --> https://www.mql5.com/en/articles/17030 #include <CNN.mqh> //For loading Convolutional Neural networks in ONNX format --> https://www.mql5.com/en/articles/15259 #include <preprocessing.mqh> //For loading the scaler transformer #include <Trade\Trade.mqh> //The trading module #include <Trade\PositionInfo.mqh> //Position handling module CCNNClassifier cnn; RobustScaler scaler; CTrade m_trade; CPositionInfo m_position; input string base_symbol = "EURUSD"; input string symbol_ = "USDJPY"; input ENUM_TIMEFRAMES timeframe = PERIOD_H4; input uint window_ = 10; input uint lookahead = 1; input uint magic_number = 28042025; input uint slippage = 100; long classes_in_y_[] = {0, 1}; int OldNumBars = -1; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!MQLInfoInteger(MQL_TESTER)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe)) { printf("%s Failed to set symbol_ = %s and timeframe = %s, Error = %d",__FUNCTION__,symbol_,EnumToString(timeframe), GetLastError()); return INIT_FAILED; } //--- string filename = StringFormat("basesymbol=%s.symbol=%s.model.%s.onnx",base_symbol, symbol_, EnumToString(timeframe)); if (!cnn.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s failed to load a CNN model in ONNX format from the common folder '%s', Error = %d",__FUNCTION__,filename,GetLastError()); return INIT_FAILED; } //--- filename = StringFormat("%s.%s.scaler.onnx", symbol_, EnumToString(timeframe)); if (!scaler.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s failed to load a scaler in ONNX format from the common folder '%s', Error = %d",__FUNCTION__,filename,GetLastError()); return INIT_FAILED; } }
因为我们已有Python 版本 TA(技术分析)模块 的等同 MQL5 版本,其在这篇文章中讨论过。我们就能调用指标函数,并在类似 Python-Pandas 的数据帧中分配成果。
CDataFrame getStationaryVars(uint start = 1, uint bars = 50) { CDataFrame df; //Dataframe object vector open, high, low, close; open.CopyRates(Symbol(), Period(), COPY_RATES_OPEN, start, bars); high.CopyRates(Symbol(), Period(), COPY_RATES_HIGH, start, bars); low.CopyRates(Symbol(), Period(), COPY_RATES_LOW, start, bars); close.CopyRates(Symbol(), Period(), COPY_RATES_CLOSE, start, bars); vector pct_change = df.pct_change(close); vector diff_open = df.diff(open); vector diff_high = df.diff(high); vector diff_low = df.diff(low); vector diff_close = df.diff(close); df.insert("pct_change", pct_change); df.insert("diff_open", open); df.insert("diff_high", high); df.insert("diff_low", low); df.insert("diff_close", close); // Relative Strength Index (RSI) vector rsi = CMomentumIndicators::RSIIndicator(close); df.insert("rsi", rsi); // Stochastic Oscillator (Stoch) vector stock_k = CMomentumIndicators::StochasticOscillator(close,high,low).stoch; df.insert("stock_k", stock_k); // Moving Average Convergence Divergence (MACD) vector macd = COscillatorIndicators::MACDIndicator(close).main; df.insert("macd", macd); // Commodity Channel Index (CCI) vector cci = COscillatorIndicators::CCIIndicator(high,low,close); df.insert("cci", cci); // Rate of Change (ROC) vector roc = CMomentumIndicators::ROCIndicator(close); df.insert("roc", roc); // Ultimate Oscillator (UO) vector uo = CMomentumIndicators::UltimateOscillator(high,low,close); df.insert("uo", uo); // Williams %R vector williams_r = CMomentumIndicators::WilliamsR(high,low,close); df.insert("williams_r", williams_r); // Average True Range (ATR) vector atr = COscillatorIndicators::ATRIndicator(high,low,close); df.insert("atr", atr); // Awesome Oscillator (AO) vector ao = CMomentumIndicators::AwesomeOscillator(high,low); df.insert("ao", ao); // Average Directional Index (ADX) vector adx = COscillatorIndicators::ADXIndicator(high,low,close).adx; df.insert("adx", adx); // True Strength Index (TSI) vector tsi = CMomentumIndicators::TSIIndicator(close); df.insert("tsi", tsi); if (MQLInfoInteger(MQL_DEBUG)) df.head(); df = df.dropna(); //Drop not-a-number variables return df; //return the last rows = window from a dataframe which is the recent information fromthe market }
在每根柱线上,我们会收集后退 50 根柱线的指标,从索引为 1 的最近已收盘柱线开始计算。
给定 50 根柱线的主要原因是为指标计算留出足够空间,因其会伴随我们想避免的 NaN(非数字)值。
Awesome 动量振荡器是一款过去最常出现的指标,周期值为 34,这意味着 50-34 = 16 是符合我们模型的剩余数据量。
在调试模式下运行该函数,将在 MetaTrader 5 专家标签中为您提供数据概览。
MD 0 18:17:26.145 Transfer Learning EA (USDJPY,H4) | Index | pct_change | diff_open | diff_high | diff_low | diff_close | rsi | stock_k | macd | cci | roc | uo | williams_r | atr | ao | adx | tsi | FF 0 18:17:26.145 Transfer Learning EA (USDJPY,H4) | 0 | nan | 142.67000000 | 143.08800000 | 142.49100000 | 142.68300000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | JO 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 1 | -0.25300842 | 142.68400000 | 142.84900000 | 142.28700000 | 142.32200000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | IR 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 2 | 0.09977375 | 142.32300000 | 142.63500000 | 141.89900000 | 142.46400000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | HF 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 3 | -0.00070193 | 142.46400000 | 142.71900000 | 142.34400000 | 142.46300000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | GJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 4 | -0.04702976 | 142.37400000 | 142.47200000 | 142.18600000 | 142.39600000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | IJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | ... | NR 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 45 | -0.22551954 | 142.33800000 | 142.38800000 | 141.98200000 | 142.01700000 | 28.79606321 | 1.70731707 | 0.20202343 | -149.46898289 | -0.42629273 | 28.03714657 | -48.58934169 | 0.58185714 | 0.84359706 | 29.65580624 | 8.31951160 | NJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 46 | 0.16054416 | 141.97800000 | 142.31600000 | 141.96400000 | 142.24500000 | 35.49705652 | 13.58800774 | 0.12993025 | -131.96513868 | -0.57316604 | 34.81743660 | -43.09139137 | 0.56978571 | 0.51217941 | 28.18573720 | 4.78996901 | HQ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 47 | 0.19543745 | 142.24500000 | 142.58100000 | 142.12400000 | 142.52300000 | 43.03880625 | 27.03094778 | 0.09414295 | -86.63856716 | -0.76174826 | 43.61239023 | -36.38775018 | 0.57742857 | 0.21773529 | 26.19967843 | 3.09202782 | FH 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 48 | 0.04771160 | 142.52300000 | 142.61500000 | 142.29800000 | 142.59100000 | 44.85843867 | 30.31914894 | 0.07045611 | -66.64608781 | -0.57732936 | 49.55462139 | -34.74801061 | 0.56007143 | -0.01222353 | 24.37916904 | 2.01861384 | MQ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 49 | -0.19776844 | 142.59100000 | 142.75800000 | 142.25100000 | 142.30900000 | 38.91058297 | 16.68278530 | 0.02859940 | -70.14493704 | -0.77257229 | 41.99481159 | -41.54810707 | 0.52700000 | -0.13378529 | 23.02215655 | 0.05188403 |
在 OnTick 函数内,我们首先要做的是获取这些平稳变量,随后进行切片操作,旨在确保接收的数据、或柱线数量处于训练 CNN 模型时所需的窗口内。
void OnTick() { //--- if (!isNewBar()) return; CDataFrame x_df = getStationaryVars(); //--- Check if the number of rows received after indicator calculation is >= window size if ((uint)x_df.shape()[0]<window_) { printf("%s Fatal, Data received is less than the desired window=%u. Check your indicators or increase the number of bars in the function getSationaryVars()",__FUNCTION__,window_); DebugBreak(); return; } ulong rows = (ulong)x_df.shape()[0]; ulong cols = (ulong)x_df.shape()[1]; //printf("Before scaled shape = (%I64u, %I64u)",rows, cols); matrix x = x_df.iloc((rows-window_), rows-1, 0, cols-1).m_values; }
现在我们有一个与窗口值相似的 10 行切片矩阵,和训练期间用到的 16 个特征,我们在将数据传递给 CNN 模型之前,先把它传递至加载的 RobustScaler,然后进行最终预测。
matrix x_scaled = scaler.transform(x); //Transform the data, very important long signal = cnn.predict(x_scaled, classes_in_y_).cls; //Predicted class
最后,利用获自模型的信号,我们能够制定一个简单的交易策略:当模型收到的信号等于 1(看涨信号)时,我们开一笔买入交易;反之,当收到的信号等于 0(看跌信号)时,我们开一笔卖出交易。
每笔交易将在当前时间帧内,经过 lookahead 数量的柱线之后平仓。
//--- Trading functionality MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); if (signal == 1) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask,0,0); } if (signal == 0) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid,0,0); } CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe
就是这样,在迁移学习期间所用的多个金融工具上,我们运行这个交易机器人,并观察它们从 2023 年 1 月 1 日到 2025 年 1 月 1 日的预测结果。
时间帧:PERIOD_H4。建模:1 分钟 OHLC。
品种:XAUEUR
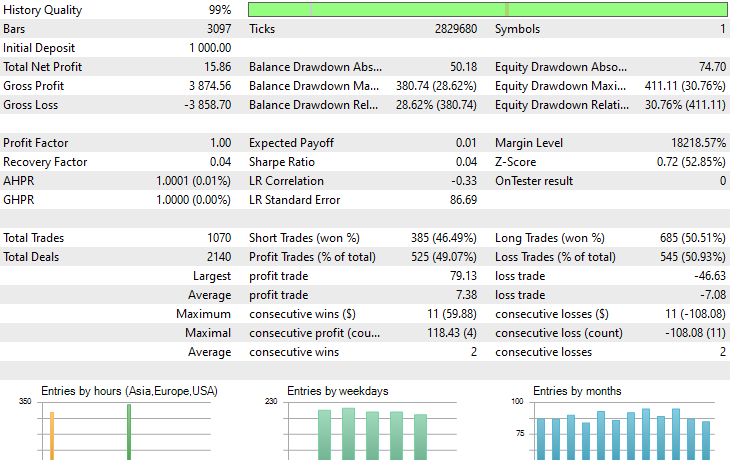
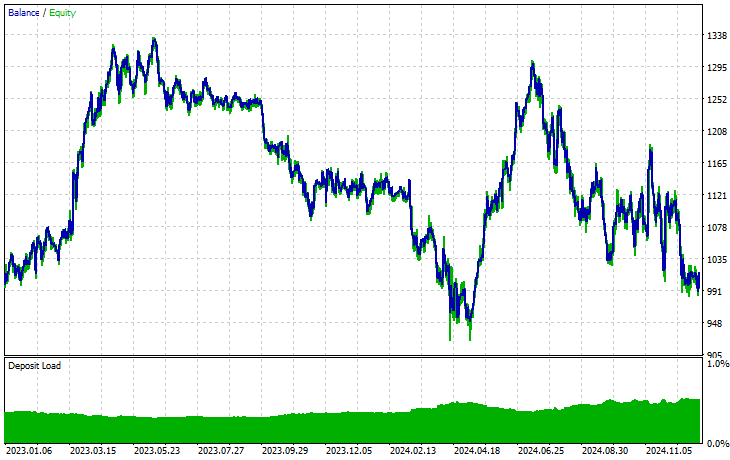
品种:XAUUSD
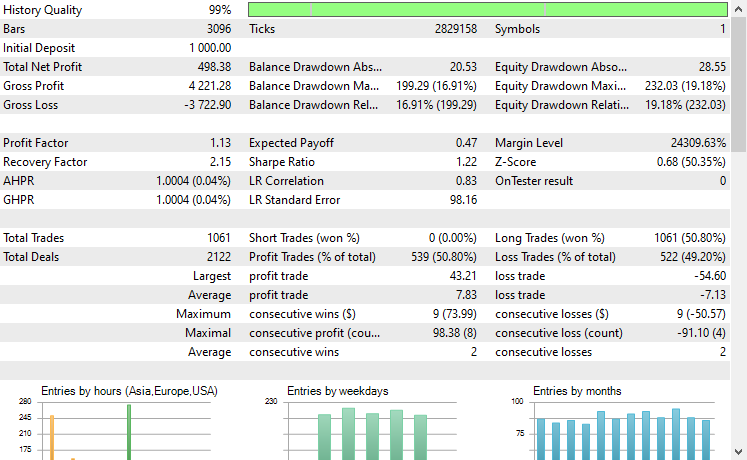
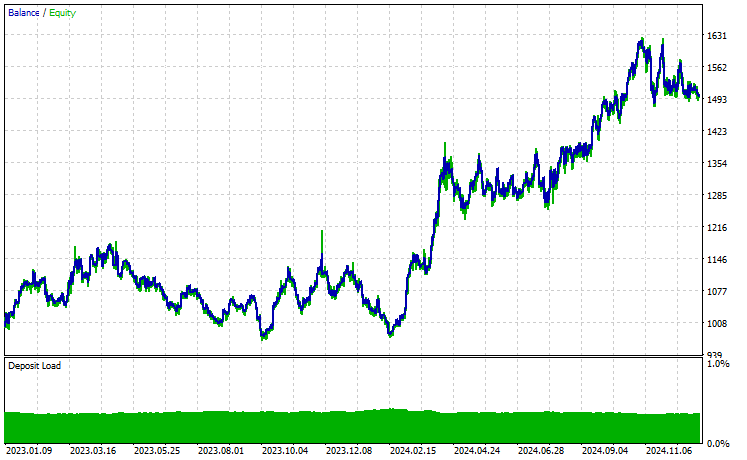
基于 EURUSD 训练的基准模型,我们在 17 种金融工具运行迁移学习,只有 2 个金融得到了有前途的结果。其余的完全是垃圾。
这可能意味着两件事,一是在 EURUSD 上观察到的形态与 XAUUSD 、XAUEUR 显示的形态有着强烈的联系、或相似性。这很合理,因为这两种金融工具都包含 EUR 和 USD,而 USD 又是 EURUSD 的基准货币。
其次,这也可能意味着我们得到的是欠优化 CNN 模型,因为我们尚未优化模型,以便发现模型架构和参数的最佳组合,更不用说我们甚至尚未针对不同的基准品种进行操练,也未观察其它品种的成果。
我们本可以再完成几件事,但这超出了本文的篇幅。我把这些留给您了。
后记
我们正处于人工智能和机器学习的黄金时代,这项技术的发展速度超出预期,这都要归功于开源,您现在只需几行代码就能在现有模型基础上构建出色的模型,而这就是我们称之的迁移学习。
虽然在计算机视觉和图像相关任务中,我们已拥有这些庞大的开源模型,比如 ResNet50、MobileNet、等等。这让开发者能够进入前沿,获得有意义的人工智能解决方案,但在开源层面,金融领域尚未被充分探索。
本文旨在开阔您的眼界,了解转移学习的可能性及其在这一领域的可能模样,作为起点,帮助您构建庞大的模型,利用各种工具中常见的形态来理解金融市场。
祝您好运。
附件表格
文件名 | 说明/用法 |
|---|---|
| Expert\Transfer Learning EA.mq5 | 交易环境中测试迁移学习模型的主要智能系统。 |
| Include\CNN.mqh | 加载和部署 .onnx 文件形式 CNN 模型的 MQL5 函数库。 |
Include\pandas.mqh | 类似 Python 的 Pandas 函数库,用于数据操纵和存储 |
Include\preprocessing.mqh | 包含加载、缩放、和转换 .onnx 格式数据的类。 |
Include\ta.mqh | 一个采用即插即用方式处理指标的 MQL5 函数库。 |
Scripts\CollectData.mqh | 一个跨各种金融工具收集并保存 OHLC 数据的脚本。 |
| Python\forex-transfer-learning.ipynb | 一个执行本文中描述的所有 Python 代码的 Python 脚本(Jupyter Notebook)。 |
Common\Files\*scaler.onnx | 在 ONNX 格式文件中保存数据的预处理缩放器。 |
Common\Files\*.onnx | 保存在 ONNX 文件中的 CNN 模型。 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/17886
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
