Datenwissenschaft und ML (Teil 46): Aktienmarktprognosen mit N-BEATS in Python

Inhalt
- Was ist N-BEATS?
- Wie funktioniert N-BEATS?
- Kernziele des N-BEATS-Modells
- Aufbau des N-BEATS-Modells
- Prognosen außerhalb der Stichprobe unter Verwendung des N-BEATS-Modells
- Prognose von mehreren Zeitreihen
- Handelsentscheidungen mit dem N-BEATS-Modell treffen
- Schlussfolgerung
Was ist N-BEATS?
N-BEATS (Neural Basis Expansion Analysis for Time Series) ist ein Deep-Learning-Modell, das speziell für die Prognose von Zeitreihen entwickelt wurde. Es bietet einen flexiblen Rahmen für univariate und multivariate Prognoseaufgaben.
Es wurde von Forschern von Element AI (jetzt Teil von ServiceNow) im Jahr 2019 mit dem Artikel „N-BEATS: Neural basis expansion analysis for interpretable time series forecasting“ vorgestellt.
Die Entwickler von Element AI haben dieses Modell entwickelt, um die Dominanz klassischer statistischer Modelle wie ARIMA und ETS in Zeitreihen herauszufordern, ohne dabei die Fähigkeiten klassischer maschineller Lernmodelle zu beeinträchtigen.
Wir alle wissen, dass die Vorhersage von Zeitreihen eine schwierige Aufgabe ist. Deshalb verlassen sich Experten für maschinelles Lernen und Anwender manchmal auf Deep-Learning-Modelle wie RNNs, LSTMs usw., die häufig eingesetzt werden:
- Überkompliziert für einige einfache Aufgaben.
- Schwer zu interpretieren.
- Trotz ihrer Komplexität sind sie nicht durchgängig besser als die statistischen Basiswerte.
Herkömmliche Modelle für Zeitreihenprognosen, wie ARIMA, sind für viele Aufgaben zu einfach.
Daher beschlossen die Autoren/Entwickler, ein Deep-Learning-Modell für Zeitreihenprognosen zu entwickeln, das gut funktioniert, interpretierbar ist und keine domänenspezifischen Anpassungen benötigt.

Hauptziele des N-BEATS-Modells
Die Entwickler hatten klare Ziele und Beweggründe für die Entwicklung dieses maschinellen Lernwerkzeugs; sie wollten die Grenzen sowohl der klassischen als auch der auf Deep Learning basierenden Zeitreihenprognose überwinden.
Im Folgenden werden die Kernziele von N-BEATS ausführlich erläutert:
- Einfaches Modell ohne Einbußen bei der Genauigkeit
Da einfachere/lineare Modelle für Zeitreihenprognosen wie ARIMA nicht in der Lage sind, komplexe Beziehungen zu erfassen, die besser von Modellen auf der Grundlage neuronaler Netze (Deep-Learning-Modelle) erfasst werden, haben sich die Entwickler entschieden, einfache Architekturen neuronaler Netze (MLPs) für Zeitreihenprognosen zu verwenden, da diese besser interpretierbar, schneller und einfacher zu beheben sind.
Die Verwendung von Deep-Learning-Modellen (RNNs, LSTMs oder Transformers) erhöht die Komplexität des Systems, wodurch das Modell schwieriger abzustimmen ist und nur langsam trainiert werden kann. - Interpretierbarkeit durch Struktur
Da MLPs und andere auf neuronalen Netzen basierende Modelle keine interpretierbaren Ergebnisse liefern, wollten die Entwickler ein auf neuronalen Netzen basierendes Modell schaffen, das vom Menschen interpretierbare Prognosen liefern kann, indem es die Ausgabe in Trend- und saisonale Komponenten zerlegt, ähnlich wie klassische Zeitreihenmodelle wie ETS.
Das N-BEATS-Modell ermöglicht eindeutige Zuordnungen, z. B. „Diese Spitze in den Daten ist auf den Trend zurückzuführen“ oder „dieser Rückgang ist saisonal bedingt“, dies wird durch Basiserweiterungsschichten (wie Polynom- oder Fourier-Basis) erreicht. - Wettbewerbsfähige Genauigkeit ohne bereichsspezifische Anpassungen
Ein weiteres Ziel, das mit diesem Modell erreicht werden soll, ist die Entwicklung eines universell einsetzbaren Modells, das für eine breite Palette von Zeitreihen geeignet ist und nur ein minimales manuelles Feature Engineering erfordert.
Der Grund dafür ist, dass Modelle wie Prophet vom Nutzer verlangen, dass er Trend- und Saisonmuster angibt.
N-BEATS lernt diese Muster automatisch, direkt aus den Daten. - Unterstützung der globalen Modellierung über viele Zeitreihen hinweg
Da viele Modelle für Zeitreihenprognosen nur eine einzige Zeitreihe prognostizieren können (Paneldaten), wurde dieses Modell für die Prognose mehrerer Zeitreihen entwickelt.Dies ist sehr praktisch, da wir bei Finanzdaten möglicherweise mehr als ein Merkmal haben, das wir prognostizieren wollen. Zum Beispiel die Vorhersage der Schlusskurse für NASDAQ und S&P 500 zur gleichen Zeit.
- Schnelles und skalierbares Training
N-BEATS wurde entwickelt, um das Modell im Gegensatz zu RNNs oder aufmerksamkeitsbasierten Modellen schnell und einfach zu parallelisieren. - Starke Basisleistung
N-BEATS zielt darauf ab, die modernsten klassischen Methoden wie ARIMA und ETS in einer fairen, rückgeprüften Bewertung zu schlagen. - Modularer und umfangreicher Aufbau
Klassische Modelle für Zeitreihenprognosen sind statisch und nicht veränderbar. N-BEATS verfügt über eine leicht zu modifizierende Architektur, die das einfache Hinzufügen von nutzerdefinierten Blöcken, wie z. B. Trendblöcken, Saisonblöcken oder generischen Blöcken, ermöglicht.
Bevor wir dieses Modell einführen, sollten wir uns einen kurzen Moment Zeit nehmen, um zu verstehen, worum es dabei geht.
Wie funktioniert das N-BEATS-Modell (eine kurze mathematische Einführung)
Betrachten wir nun die Architektur des N-BEATS-Modells.
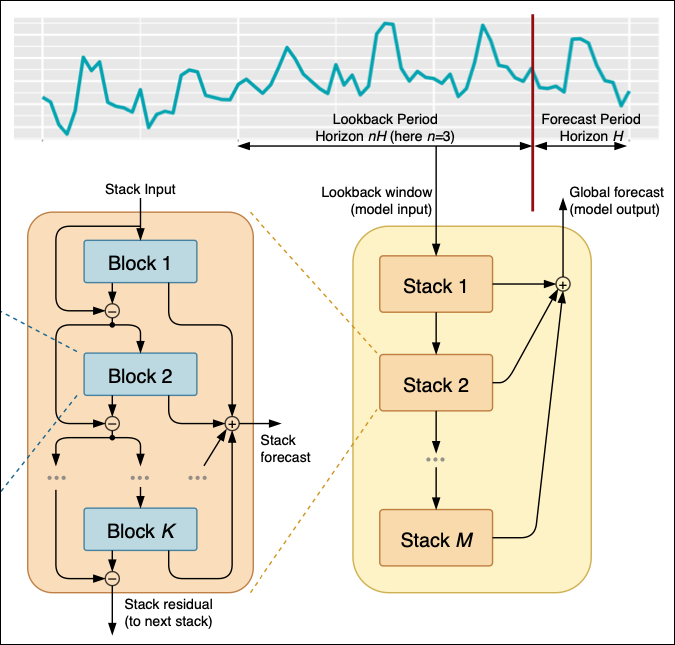
Abbildung 01
Oben befinden sich die Zeitreihendaten, die gefiltert und in verschiedenen Stapeln verarbeitet werden, von 1 bis M Stapeln.
Jeder Stapel besteht aus verschiedenen Blöcken von 1 bis K; aus jedem Block erzeugt das Modell einen Prognosewert oder ein Residuum, das dann an den nächsten Stapel weitergegeben wird.
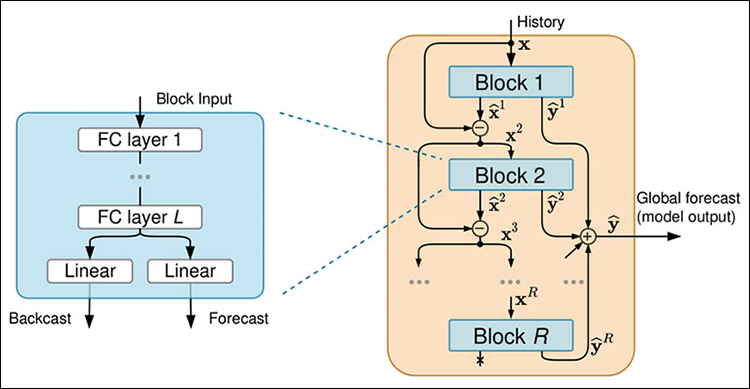
Abbildung 02
Jeder Block besteht aus vier vollständig verknüpften neuronalen Netzwerkschichten, die entweder einen Backcast oder eine Prognose erstellen.
Der Datenfluss in das Modell
01: In den Magazinen
Zu Beginn des Modells müssen der Rückblickszeitraum und der Prognosezeitraum festgelegt werden.
Der Rückblickszeitraum gibt an, wie weit wir in die Vergangenheit zurückblicken, um die Zukunft vorherzusagen, während der Prognosezeitraum angibt, wie weit wir in die Zukunft blicken wollen.
Nach der Festlegung des Rückblick- und Vorhersagezeitraums beginnen wir mit Stapel 01, der die Daten des Rückblickzeitraums aufnimmt und verarbeitet, um erste Vorhersagen zu treffen. Wenn unser Rückblickszeitraum beispielsweise die Schlusskurse der letzten Stunden für ein bestimmtes Instrument sind, verwendet Stack 01 diese Daten für die Prognose der nächsten 24 Stunden.
Die erhaltene erste Vorhersage und ihre Residuen (d.h. tatsächlicher minus vorhergesagter Wert) werden dann zur weiteren Verfeinerung an den nächsten Stapel (Stapel 02) weitergegeben.
Dieser Vorgang wird für alle nachfolgenden Stapel bis zum Stapel M wiederholt, wobei jeder Stapel die Vorhersagen des vorherigen Stapels verbessert.
Schließlich werden die Prognosen aus allen Stapeln kombiniert, um die Gesamtprognose zu erstellen. Wenn beispielsweise Stack 01 eine Spitze vorhersagt, passt Stack 02 den Trend an, und Stack M verfeinert die langfristigen Muster. Die globale Prognose integriert all diese Erkenntnisse, um eine möglichst genaue Vorhersage zu ermöglichen.
Sie können sich die Stapel als verschiedene Analyseebenen vorstellen. Stack 01 könnte sich auf die Erfassung kurzfristiger Muster konzentrieren, z. B. auf stündliche Schwankungen der Schlusskurse, während Stack 02 auf langfristige Muster ausgerichtet sein könnte, z. B. auf Trends bei den Tagesschlusskursen.
Jeder Stack verarbeitet die Eingabedaten, um einen einzigartigen Beitrag zur Gesamtprognose zu leisten.
02: Innerhalb von Eingabeblöcken
Beginnend mit Block 01, der die Stack-Eingabe entgegennimmt, bei der es sich um die ursprünglichen Lookback-Daten oder die Residuen aus dem vorherigen Stack handeln kann, werden diese Eingaben zur Erstellung einer Prognose und eines Backcasts verwendet. Wenn der Block beispielsweise die letzten 24 Stunden des Stromverbrauchs als Eingaben erhält, erstellt er die Prognose für die nächsten 24 Stunden und den Backcast, um die Eingabedaten anzunähern.
Der Backcast trägt dazu bei, dass die Modelle besser verstehen, wie die Vorhersage zu den Gesamtvorhersagen beiträgt.
Auch hier besteht jeder Stack aus mehreren Blöcken, die nacheinander arbeiten. Nachdem der erste Block den Stack-Input verarbeitet und seine Prognose und Backcasts erstellt hat, nimmt der nächste Block sowohl die Residuen des vorherigen Blocks als auch den ursprünglichen Stack-Input auf. Diese beiden Eingaben tragen dazu bei, dass der aktuelle Block genauere Vorhersagen macht als der vorherige, wobei auch die ursprünglichen Daten berücksichtigt werden, um die Gesamtgenauigkeit zu verbessern.
Diese iterative Verfeinerung innerhalb jedes Blocks eines Stapels sorgt dafür, dass die Vorhersagen über die Blöcke hinweg immer genauer werden. Nachdem alle Blöcke innerhalb eines Stapels die Daten verarbeitet haben, wird der letzte Rest des letzten Blocks (Block K) an den nächsten Stapel weitergegeben.
03: Zerlegen eines Blocks
Innerhalb jedes Blocks werden die Eingabedaten durch einen vierschichtigen, vollständig verknüpften Stack verarbeitet. Dieser Stack transformiert die Blockeingabe und extrahiert Merkmale, die bei der Erstellung des Backcasts und der Prognose helfen.
Die vollverknüpfte Schicht innerhalb jedes Blocks dient der Datenumwandlung und Merkmalsextraktion. Nachdem die Daten die vollverknüpften Schichten durchlaufen haben, werden sie in zwei Teile aufgeteilt (siehe Abbildung 02). Ein Teil für den Backcast und der andere für die Vorhersage.
Die Backcast-Ausgabe zielt auf eine Annäherung an die Eingabedaten ab und trägt dazu bei, die Residuen zu verfeinern, die an den nächsten Block weitergegeben werden, während die Prognose-Ausgabe vorausgesagte Werte für den Prognosezeitraum liefert.
Aufbau des N-BEATS-Modells in Python
Beginnen Sie mit der Installation aller Module, die in der Datei requirements.txt enthalten sind, die Sie in der Tabelle der Anhänge am Ende dieses Artikels finden.
pip install -r requirements.txt
Innerhalb von test.ipynb importieren wir zunächst alle erforderlichen Module.
import MetaTrader5 as mt5 import numpy as np import matplotlib.pyplot as plt import pandas as pd import seaborn as sns import warnings sns.set_style("darkgrid") warnings.filterwarnings("ignore")
Anschließend wird MetaTrader 5 initialisiert.
if not mt5.initialize(): print("Metratrader5 initialization failed, Error code =", mt5.last_error()) mt5.shutdown()
Wir sammeln 1000 Balken des täglichen Zeitrahmens für das Symbol NASDAQ (NAS100).
rates = mt5.copy_rates_from_pos("NAS100", mt5.TIMEFRAME_D1, 1, 1000) rates_df = pd.DataFrame(rates)
Obwohl dieses Modell Techniken des klassischen maschinellen Lernens verwendet, die häufig multivariat sind, verfolgt N-BEATS einen univariaten Ansatz, der demjenigen ähnelt, der in traditionellen Zeitreihenmodellen wie ARIMA und VAR verwendet wird.
Im Folgenden wird beschrieben, wie wir univariate Daten konstruieren.
univariate_df = rates_df[["time", "close"]].copy() univariate_df["ds"] = pd.to_datetime(univariate_df["time"], unit="s") # convert the time column to datetime univariate_df["y"] = univariate_df["close"] # closing prices univariate_df["unique_id"] = "NAS100" # add a unique_id column | very important for univariate models # Final dataframe univariate_df = univariate_df[["unique_id", "ds", "y"]].copy() univariate_df
Ausgabe:
| unique_id | ds | y | |
|---|---|---|---|
| 0 | NAS100 | 2021-08-30 | 9.655648 |
| 1 | NAS100 | 2021-08-31 | 9.654988 |
| 2 | NAS100 | 2021-09-01 | 9.655763 |
| 3 | NAS100 | 2021-09-02 | 9.654981 |
| 4 | NAS100 | 2021-09-03 | 9.658335 |
| ... | ... | ... | ... |
| 995 | NAS100 | 2025-07-07 | 10.028180 |
| 996 | NAS100 | 2025-07-08 | 10.031142 |
| 997 | NAS100 | 2025-07-09 | 10.037376 |
| 998 | NAS100 | 2025-07-10 | 10.036098 |
| 999 | NAS100 | 2025-07-11 | 10.033283 |
univariate_df["unique_id"] = "NAS100" # add a unique_id column | very important for univariate models
Das Modul neuralforecast, das über das Modell N-BEATS verfügt, ist sowohl für univariate als auch für Panel-Prognosen (mehrere Zeitreihen) geeignet. Das Merkmal unique_id teilt dem Modell mit, zu welcher Zeitreihe jede Zeile gehört. Dies ist besonders kritisch, wenn:
- Sie prognostizieren mehrere Vermögenswerte oder Symbole (z. B. AAPL, TSLA, MSFT, EURUSD).
- Sie möchten ein einzelnes Modell für viele Zeitreihen im Stapelverfahren trainieren.
Diese Variable ist aufgrund interner Gruppierungs- und Indexierungsmechanismen obligatorisch (auch für eine einzelne Reihe).
Zum Trainieren dieses Modells sind nur wenige Zeilen Code erforderlich.
from neuralforecast import NeuralForecast from neuralforecast.models import NBEATS # Neural Basis Expansion Analysis for Time Series # Define model and horizon horizon = 30 # forecast 30 days into the future model = NeuralForecast( models=[NBEATS(h=horizon, # predictive horizon of the model input_size=90, # considered autorregresive inputs (lags), y=[1,2,3,4] input_size=2 -> lags=[1,2]. max_steps=100, # maximum number of training steps (epochs) scaler_type='robust', # scaler type for the time series data )], freq='D' # frequency of the time series data ) # Fit the model model.fit(df=univariate_df)
Ausgabe:
Seed set to 1 GPU available: False, used: False TPU available: False, using: 0 TPU cores HPU available: False, using: 0 HPUs | Name | Type | Params | Mode ------------------------------------------------------- 0 | loss | MAE | 0 | train 1 | padder_train | ConstantPad1d | 0 | train 2 | scaler | TemporalNorm | 0 | train 3 | blocks | ModuleList | 2.6 M | train ------------------------------------------------------- 2.6 M Trainable params 7.3 K Non-trainable params 2.6 M Total params 10.541 Total estimated model params size (MB) 31 Modules in train mode 0 Modules in eval mode Epoch 99: 100% 1/1 [00:01<00:00, 0.88it/s, v_num=32, train_loss_step=0.259, train_loss_epoch=0.259] `Trainer.fit` stopped: `max_steps=100` reached.
Wir können die Vorhersagen und die tatsächlichen Werte auf derselben Achse visualisieren.
forecast = model.predict() # predict future values based on the fitted model # Merge forecast with original data plot_df = pd.merge(univariate_df, forecast, on='ds', how='outer') plt.figure(figsize=(7,5)) plt.plot(plot_df['ds'], plot_df['y'], label='Actual') plt.plot(plot_df['ds'], plot_df['NBEATS'], label='Forecast') plt.axvline(plot_df['ds'].max() - pd.Timedelta(days=horizon), color='gray', linestyle='--') plt.legend() plt.title('N-BEATS Forecast') plt.show()
Ausgabe:
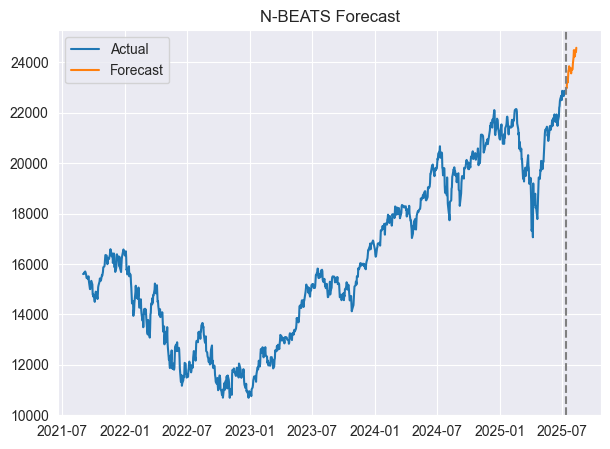
Nachfolgend sehen Sie ein Bild des zusammengeführten Datenrahmens.
| unique_id_x | ds | y | unique_id_y | NBEATS | |
|---|---|---|---|---|---|
| 0 | NAS100 | 2021-08-31 | 15599.4 | NaN | NaN |
| 1 | NAS100 | 2021-09-01 | 15611.5 | NaN | NaN |
| 2 | NAS100 | 2021-09-02 | 15599.3 | NaN | NaN |
| 3 | NAS100 | 2021-09-03 | 15651.7 | NaN | NaN |
| 4 | NAS100 | 2021-09-06 | 15700.4 | NaN | NaN |
| ... | ... | ... | ... | ... | ... |
| 1025 | NaN | 2025-08-09 | NaN | NAS100 | 24235.187500 |
| 1026 | NaN | 2025-08-10 | NaN | NAS100 | 24466.316406 |
| 1027 | NaN | 2025-08-11 | NaN | NAS100 | 24454.646484 |
| 1028 | NaN | 2025-08-12 | NaN | NAS100 | 24405.820312 |
| 1029 | NaN | 2025-08-13 | NaN | NAS100 | 24571.919922 |
Toll, das Modell hat 30 Tage in die Zukunft vorausgesagt.
Zu Evaluierungszwecken trainieren wir dieses Modell auf einem Datensatz und testen es auf dem anderen, so wie wir immer ein typisches maschinelles Lernmodell evaluieren.
Out-of-sample-Prognose mit dem N-BEATS-Modell
Wir beginnen mit der Aufteilung der Daten in Trainings- und Testdatenrahmen.
split_date = '2024-01-01' # the split date for training and testing train_df = univariate_df[univariate_df['ds'] < split_date] test_df = univariate_df[univariate_df['ds'] >= split_date]
Wir trainieren das Modell mit dem Trainingsdatensatz.
model = NeuralForecast( models=[NBEATS(h=horizon, # predictive horizon of the model input_size=90, # considered autorregresive inputs (lags), y=[1,2,3,4] input_size=2 -> lags=[1,2]. max_steps=100, # maximum number of training steps (epochs) scaler_type='robust', # scaler type for the time series data )], freq='D' # frequency of the time series data ) # Fit the model model.fit(df=train_df)
Da die Vorhersagefunktion die nächste „N“-Anzahl von Tagen entsprechend dem Vorhersagehorizont vorhersagt, müssen wir, um dieses Modell anhand von Prognosen außerhalb der Stichprobe zu bewerten, den Datenrahmen für das vorhergesagte Ergebnis mit dem aktuellen Datenrahmen zusammenführen.
test_forecast = model.predict() # predict future 30 days based on the training data df_test = pd.merge(test_df, test_forecast, on=['ds', 'unique_id'], how='outer') # merge the test data with the forecast df_test.dropna(inplace=True) # drop rows with NaN values df_test
Ausgabe:
| unique_id | ds | y | NBEATS | |
|---|---|---|---|---|
| 3 | NAS100 | 2024-01-02 | 16554.3 | 16569.835938 |
| 4 | NAS100 | 2024-01-03 | 16368.1 | 16596.839844 |
| 5 | NAS100 | 2024-01-04 | 16287.2 | 16603.513672 |
| 6 | NAS100 | 2024-01-05 | 16307.1 | 16729.607422 |
| 9 | NAS100 | 2024-01-08 | 16631.0 | 16854.746094 |
| 10 | NAS100 | 2024-01-09 | 16672.4 | 16918.466797 |
| 11 | NAS100 | 2024-01-10 | 16804.7 | 16958.833984 |
| 12 | NAS100 | 2024-01-11 | 16814.3 | 17130.972656 |
| 13 | NAS100 | 2024-01-12 | 16808.8 | 17055.396484 |
| 16 | NAS100 | 2024-01-15 | 16828.7 | 17272.376953 |
| 17 | NAS100 | 2024-01-16 | 16841.9 | 17227.498047 |
| 18 | NAS100 | 2024-01-17 | 16727.7 | 17408.158203 |
| 19 | NAS100 | 2024-01-18 | 16987.0 | 17499.619141 |
| 20 | NAS100 | 2024-01-19 | 17336.7 | 17318.767578 |
| 23 | NAS100 | 2024-01-22 | 17329.3 | 17399.562500 |
| 24 | NAS100 | 2024-01-23 | 17426.1 | 17289.140625 |
| 25 | NAS100 | 2024-01-24 | 17503.1 | 17236.478516 |
| 26 | NAS100 | 2024-01-25 | 17469.4 | 17188.691406 |
| 27 | NAS100 | 2024-01-26 | 17390.1 | 17315.134766 |
Wir fahren fort, dieses Ergebnis zu bewerten.
from sklearn.metrics import mean_absolute_percentage_error, r2_score mape = mean_absolute_percentage_error(df_test['y'], df_test['NBEATS']) r2_score_ = r2_score(df_test['y'], df_test['NBEATS']) print(f"mean_absolute_percentage_error (MAPE): {mape} \n R2 Score: {r2_score_}")
Ausgabe:
mean_absolute_percentage_error (MAPE): 0.015779373328172166 R2 Score: 0.35350182943487285
Nach der MAPE-Metrik sind die Modellvorhersagen prozentual sehr genau; der R2-Wert von 0,35 bedeutet jedoch, dass nur 35 % der Variation der Zielvariablen erklärt werden.
Unten sehen Sie das Diagramm, das die tatsächlichen und die prognostizierten Werte auf einer einzigen Achse enthält.
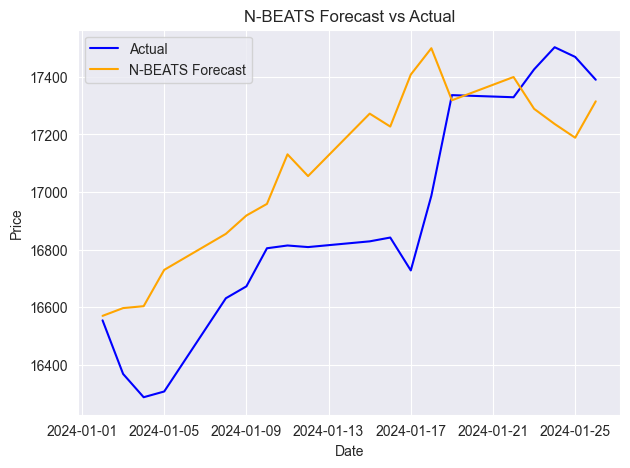
Wie jedes andere Zeitreihenprognosemodell muss auch N-BEATS regelmäßig mit neuen sequentiellen Daten aktualisiert werden, um relevant und genau zu bleiben. In den vorangegangenen Beispielen haben wir das Modell auf der Grundlage der Vorhersagen bewertet, die 30 Tage im Voraus auf der Grundlage der täglichen Daten erstellt wurden, aber das ist nicht der richtige Weg, da dem Modell viele tägliche Informationen dazwischen entgehen.
Der richtige Weg ist es, das Modell mit neuen Daten zu aktualisieren, sobald neue Daten auftauchen.
Das N-BEATS-Modell bietet eine einfache Möglichkeit, das Modell mit neuen Daten zu aktualisieren, ohne es neu zu trainieren, was viel Zeit spart.
Wenn Sie laufen:
NBEATS.predict(df=new_dataframe) Das Modell wendet die trainierten Gewichte auf die neuen Daten an, während es eine Inferenz des Modells durchführt, die das Modell mit neuen Informationen aktualisiert und es für die kürzlich erhaltenen Daten aus einem Datenrahmen relevant macht.
Prognose von mehreren Zeitreihen
Wie bereits in den Kernzielen des N-BEATS-Abschnitts beschrieben. Dieses Modell wurde entwickelt, um die Prognose von mehreren Zeitreihen bestmöglich zu handhaben.
Dies ist eine beeindruckende Fähigkeit dieses Modells, denn es nutzt die in einer Reihe erlernten Muster, um die Gesamtprognose für beide Zeitreihen zu verbessern.
Im Folgenden erfahren Sie, wie Sie sich diese Fähigkeit zunutze machen können:
Wir beginnen damit, Daten für jedes Symbol von MetaTrader 5 zu sammeln.
rates_nq = mt5.copy_rates_from_pos("NAS100", mt5.TIMEFRAME_D1, 1, 1000) rates_df_nq = pd.DataFrame(rates_nq) rates_snp = mt5.copy_rates_from_pos("US500", mt5.TIMEFRAME_D1, 1, 1000) rates_df_snp = pd.DataFrame(rates_snp)
Wir bereiten jeden einzelnen univariaten Datenrahmen vor.
# NAS100 rates_df_nq["ds"] = pd.to_datetime(rates_df_nq["time"], unit="s") rates_df_nq["y"] = rates_df_nq["close"] rates_df_nq["unique_id"] = "NAS100" df_nq = rates_df_nq[["unique_id", "ds", "y"]] # US500 rates_df_snp["ds"] = pd.to_datetime(rates_df_snp["time"], unit="s") rates_df_snp["y"] = rates_df_snp["close"] rates_df_snp["unique_id"] = "US500" df_snp = rates_df_snp[["unique_id", "ds", "y"]]
Wir kombinieren beide Datenrahmen und sortieren die Werte nach der Datenspalte und ihrer unique_id.
multivariate_df = pd.concat([df_nq, df_snp], ignore_index=True) # combine both dataframes multivariate_df = multivariate_df.sort_values(['unique_id', 'ds']).reset_index(drop=True) # sort by unique_id and date multivariate_df
Ausgabe:
| unique_id | ds | y | |
|---|---|---|---|
| 0 | NAS100 | 2021-08-31 | 15599.4 |
| 1 | NAS100 | 2021-09-01 | 15611.5 |
| 2 | NAS100 | 2021-09-02 | 15599.3 |
| 3 | NAS100 | 2021-09-03 | 15651.7 |
| 4 | NAS100 | 2021-09-06 | 15700.4 |
| ... | ... | ... | ... |
| 1995 | US500 | 2025-07-08 | 6229.9 |
| 1996 | US500 | 2025-07-09 | 6264.9 |
| 1997 | US500 | 2025-07-10 | 6280.3 |
| 1998 | US500 | 2025-07-11 | 6255.8 |
| 1999 | US500 | 2025-07-14 | 6271.9 |
Wie zuvor haben wir die Daten in Trainings- und Testdatenrahmen aufgeteilt.
split_date = '2024-01-01' # the split date for training and testing train_df = multivariate_df[multivariate_df['ds'] < split_date] test_df = multivariate_df[multivariate_df['ds'] >= split_date]
Dann trainieren wir das Modell auf die gleiche Weise wie zuvor.
from neuralforecast import NeuralForecast from neuralforecast.models import NBEATS # Neural Basis Expansion Analysis for Time Series # Define model and horizon horizon = 30 # forecast 30 days into the future model = NeuralForecast( models=[NBEATS(h=horizon, # predictive horizon of the model input_size=90, # considered autorregresive inputs (lags), y=[1,2,3,4] input_size=2 -> lags=[1,2]. max_steps=100, # maximum number of training steps (epochs) scaler_type='robust', # scaler type for the time series data )], freq='D' # frequency of the time series data ) # Fit the model model.fit(df=train_df)
Wir erstellen Prognosen auf der Grundlage von Daten, die außerhalb der Stichprobe liegen.
test_forecast = model.predict() # predict future 30 days based on the training data df_test = pd.merge(test_df, test_forecast, on=['ds', 'unique_id'], how='outer') # merge the test data with the forecast df_test.dropna(inplace=True) # drop rows with NaN values df_test
Ausgabe:
| unique_id | ds | y | NBEATS | |
|---|---|---|---|---|
| 6 | NAS100 | 2024-01-02 | 16554.3 | 16267.765625 |
| 7 | US500 | 2024-01-02 | 4747.4 | 4706.230957 |
| 8 | NAS100 | 2024-01-03 | 16368.1 | 16230.808594 |
| 9 | US500 | 2024-01-03 | 4707.3 | 4706.517090 |
| 10 | NAS100 | 2024-01-04 | 16287.2 | 16136.568359 |
| 11 | US500 | 2024-01-04 | 4690.9 | 4686.380859 |
| 12 | NAS100 | 2024-01-05 | 16307.1 | 16218.930664 |
| 13 | US500 | 2024-01-05 | 4695.8 | 4704.896484 |
Schließlich bewerten wir das Modell für beide Instrumente und stellen die tatsächlichen und die prognostizierten Werte auf der gleichen Achse dar.
from sklearn.metrics import mean_absolute_percentage_error, r2_score unique_ids = df_test['unique_id'].unique() for unique_id in unique_ids: df_unique = df_test[df_test['unique_id'] == unique_id].copy() mape = mean_absolute_percentage_error(df_unique['y'], df_unique['NBEATS']) r2_score_ = r2_score(df_unique['y'], df_unique['NBEATS']) print(f"Unique ID: {unique_id} - MAPE: {mape}, R2 Score: {r2_score_}") plt.figure(figsize=(7, 4)) plt.plot(df_unique['ds'], df_unique['y'], label='Actual', color='blue') plt.plot(df_unique['ds'], df_unique['NBEATS'], label='Forecast', color='orange') plt.title(f'Actual vs Forecast for {unique_id}') plt.xlabel('Date') plt.ylabel('Value') plt.legend() plt.show()
Ausgabe:
Unique ID: NAS100 - MAPE: 0.0221775184381915, R2 Score: -0.16976266747298419

Unique ID: US500 - MAPE: 0.007412931117247571, R2 Score: 0.3782229067061038

Handelsentscheidungen treffen mit N-BEATS in MetaTrader 5
Da wir nun in der Lage sind, Vorhersagen aus diesem Modell zu erhalten, können wir es in einen Python-basierten Handelsroboter integrieren.
In der Datei NBEATS-tradingbot.py implementieren wir zunächst die Funktion zum Training des gesamten Modells:
def train_nbeats_model(forecast_horizon: int=30, start_bar: int=1, number_of_bars: int=1000, input_size: int=90, max_steps: int=100, mt5_timeframe: int=mt5.TIMEFRAME_D1, symbol_01: str="NAS100", symbol_02: str="US500", test_size_percentage: float=0.2, scaler_type: str='robust'): """ Train NBEATS model on NAS100 and US500 data from MetaTrader 5. Args: start_bar: starting bar to be used to in CopyRates from MT5 number_of_bars: The number of bars to extract from MT5 for training the model forecast_horizon: the number of days to predict in the future input_size: number of previous days to consider for prediction max_steps: maximum number of training steps (epochs) mt5_timeframe: timeframe to be used for the data extraction from MT5 symbol_01: unique identifier for the first symbol (default is NAS100) symbol_02: unique identifier for the second symbol (default is US500) test_size_percentage: percentage of the data to be used for testing (default is 0.2) scaler_type: type of scaler to be used for the time series data (default is 'robust') Returns: NBEATS: the n-beats model object """ # Getting data from MetaTrader 5 rates_nq = mt5.copy_rates_from_pos(symbol_01, mt5_timeframe, start_bar, number_of_bars) rates_df_nq = pd.DataFrame(rates_nq) rates_snp = mt5.copy_rates_from_pos(symbol_02, mt5_timeframe, start_bar, number_of_bars) rates_df_snp = pd.DataFrame(rates_snp) if rates_df_nq.empty or rates_df_snp.empty: print(f"Failed to retrieve data for {symbol_01} or {symbol_02}.") return None # Getting NAS100 data rates_df_nq["ds"] = pd.to_datetime(rates_df_nq["time"], unit="s") rates_df_nq["y"] = rates_df_nq["close"] rates_df_nq["unique_id"] = symbol_01 df_nq = rates_df_nq[["unique_id", "ds", "y"]] # Getting US500 data rates_df_snp["ds"] = pd.to_datetime(rates_df_snp["time"], unit="s") rates_df_snp["y"] = rates_df_snp["close"] rates_df_snp["unique_id"] = symbol_02 df_snp = rates_df_snp[["unique_id", "ds", "y"]] multivariate_df = pd.concat([df_nq, df_snp], ignore_index=True) # combine both dataframes multivariate_df = multivariate_df.sort_values(['unique_id', 'ds']).reset_index(drop=True) # sort by unique_id and date # Group by unique_id and split per group train_df_list = [] test_df_list = [] for _, group in multivariate_df.groupby('unique_id'): group = group.sort_values('ds') split_idx = int(len(group) * (1 - test_size_percentage)) train_df_list.append(group.iloc[:split_idx]) test_df_list.append(group.iloc[split_idx:]) # Concatenate all series train_df = pd.concat(train_df_list).reset_index(drop=True) test_df = pd.concat(test_df_list).reset_index(drop=True) # Define model and horizon model = NeuralForecast( models=[NBEATS(h=forecast_horizon, # predictive horizon of the model input_size=input_size, # considered autorregresive inputs (lags), y=[1,2,3,4] input_size=2 -> lags=[1,2]. max_steps=max_steps, # maximum number of training steps (epochs) scaler_type=scaler_type, # scaler type for the time series data )], freq='D' # frequency of the time series data ) # fit the model on the training data model.fit(df=train_df) test_forecast = model.predict() # predict future 30 days based on the training data df_test = pd.merge(test_df, test_forecast, on=['ds', 'unique_id'], how='outer') # merge the test data with the forecast df_test.dropna(inplace=True) # drop rows with NaN values unique_ids = df_test['unique_id'].unique() for unique_id in unique_ids: df_unique = df_test[df_test['unique_id'] == unique_id].copy() mape = mean_absolute_percentage_error(df_unique['y'], df_unique['NBEATS']) print(f"Unique ID: {unique_id} - MAPE: {mape:.2f}") return model
Diese Funktion kombiniert alle zuvor besprochenen Trainingsverfahren und liefert das N-BEATS-Modellobjekt für direkte Vorhersagen.
Die Funktion zur Vorhersage der nächsten Werte folgt einem ähnlichen Ansatz wie die Trainingsfunktion.
def predict_next(model, symbol_unique_id: str, input_size: int=90): """ Predict the next values for a given unique_id using the trained model. Args: model (NBEATS): the trained NBEATS model symbol_unique_id (str): unique identifier for the symbol to predict input_size (int): number of previous days to consider for prediction Returns: DataFrame: containing the predicted values for the next days """ # Getting data from MetaTrader 5 rates = mt5.copy_rates_from_pos(symbol_unique_id, mt5.TIMEFRAME_D1, 1, input_size * 2) # Get enough data for prediction if rates is None or len(rates) == 0: print(f"Failed to retrieve data for {symbol_unique_id}.") return pd.DataFrame() rates_df = pd.DataFrame(rates) rates_df["ds"] = pd.to_datetime(rates_df["time"], unit="s") rates_df = rates_df[["ds", "close"]].rename(columns={"close": "y"}) rates_df["unique_id"] = symbol_unique_id rates_df = rates_df.sort_values(by="ds").reset_index(drop=True) # Prepare the dataframe for reference & prediction univariate_df = rates_df[["unique_id", "ds", "y"]] forecast = model.predict(df=univariate_df) return forecast
Die Datengröße des Modells ist doppelt so groß wie die Größe der Eingaben, die beim Training verwendet werden – nur um genügend Daten zu erhalten.
Rufen wir die Vorhersagefunktion zweimal für jedes einzelne Symbol auf und beobachten wir die resultierenden Datenrahmen.
trained_model = train_nbeats_model(max_steps=10) print(predict_next(trained_model, "NAS100").head()) print(predict_next(trained_model, "US500").head())
Ausgabe:
Predicting DataLoader 0: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 45.64it/s] unique_id ds NBEATS 0 NAS100 2025-07-16 22836.160156 1 NAS100 2025-07-17 22931.242188 2 NAS100 2025-07-18 22984.792969 3 NAS100 2025-07-19 23037.224609 4 NAS100 2025-07-20 23119.804688 GPU available: False, used: False TPU available: False, using: 0 TPU cores HPU available: False, using: 0 HPUs Predicting DataLoader 0: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 71.43it/s] unique_id ds NBEATS 0 US500 2025-07-16 6234.584961 1 US500 2025-07-17 6254.846680 2 US500 2025-07-18 6261.153320 3 US500 2025-07-19 6282.960449 4 US500 2025-07-20 6307.293945 GPU available: False, used: False TPU available: False, using: 0 TPU cores HPU available: False, using: 0 HPUs
Da die resultierenden Datenrahmen für beide Symbole mehrere tägliche Schlusskursvorhersagen für 30 Tage in der Zukunft enthalten (das heutige Datum ist der 16.07.2025), müssen wir einen für den aktuellen Tag (das heutige Datum) vorhergesagten Wert auswählen.
today = dt.datetime.now().date() # today's date forecast_df = predict_next(trained_model, "NAS100") # Get the predicted values for NAS100, 30 days into the future today_pred_close_nq = forecast_df[forecast_df['ds'].dt.date == today]['NBEATS'].values # extract today's predicted close value for NAS100 forecast_df = predict_next(trained_model, "US500") # Get the predicted values for US500, 30 days into the future today_pred_close_snp = forecast_df[forecast_df['ds'].dt.date == today]['NBEATS'].values # extract today's predicted close value for US500 print(f"Today's predicted NAS100 values:", today_pred_close_nq) print(f"Today's predicted US500 values:", today_pred_close_snp)
Ausgabe:
Today's predicted NAS100 values: [22836.16] Today's predicted US500 values: [6234.585]
Schließlich können wir diese vorhergesagten Werte in einer einfachen Handelsstrategie verwenden.
# Trading modules from Trade.Trade import CTrade from Trade.PositionInfo import CPositionInfo from Trade.SymbolInfo import CSymbolInfo SLIPPAGE = 100 # points MAGIC_NUMBER = 15072025 # unique identifier for the trades TIMEFRAME = mt5.TIMEFRAME_D1 # timeframe for the trades # Create trade objects for NAS100 and US500 m_trade_nq = CTrade(magic_number=MAGIC_NUMBER, filling_type_symbol = "NAS100", deviation_points=SLIPPAGE) m_trade_snp = CTrade(magic_number=MAGIC_NUMBER, filling_type_symbol = "US500", deviation_points=SLIPPAGE) # Training the NBEATS model INITIALLY trained_model = train_nbeats_model(max_steps=10, input_size=90, forecast_horizon=30, start_bar=1, number_of_bars=1000, mt5_timeframe=TIMEFRAME, symbol_01="NAS100", symbol_02="US500" ) m_symbol_nq = CSymbolInfo("NAS100") # Create symbol info object for NAS100 m_symbol_snp = CSymbolInfo("US500") # Create symbol info object for US500 m_position = CPositionInfo() # Create position info object def pos_exists(pos_type: int, magic: int, symbol: str) -> bool: """ Checks whether a position exists given a magic number, symbol, and the position type Returns: bool: True if a position is found otherwise False """ if mt5.positions_total() < 1: # no positions whatsoever return False positions = mt5.positions_get() for position in positions: if m_position.select_position(position): if m_position.magic() == magic and m_position.symbol() == symbol and m_position.position_type()==pos_type: return True return False def RunStrategyandML(trained_model: NBEATS): today = dt.datetime.now().date() # today's date forecast_df = predict_next(trained_model, "NAS100") # Get the predicted values for NAS100, 30 days into the future today_pred_close_nq = forecast_df[forecast_df['ds'].dt.date == today]['NBEATS'].values # extract today's predicted close value for NAS100 forecast_df = predict_next(trained_model, "US500") # Get the predicted values for US500, 30 days into the future today_pred_close_snp = forecast_df[forecast_df['ds'].dt.date == today]['NBEATS'].values # extract today's predicted close value for US500 # convert numpy arrays to float values today_pred_close_nq = float(today_pred_close_nq[0]) if len(today_pred_close_nq) > 0 else None today_pred_close_snp = float(today_pred_close_snp[0]) if len(today_pred_close_snp) > 0 else None print(f"Today's predicted NAS100 values:", today_pred_close_nq) print(f"Today's predicted US500 values:", today_pred_close_snp) # Refreshing the rates for NAS100 and US500 symbols m_symbol_nq.refresh_rates() m_symbol_snp.refresh_rates() ask_price_nq = m_symbol_nq.ask() # get today's close price for NAS100 ask_price_snp = m_symbol_snp.ask() # get today's close price for US500 # Trading operations for the NAS100 symol if not pos_exists(pos_type=mt5.ORDER_TYPE_BUY, magic=MAGIC_NUMBER, symbol="NAS100"): if today_pred_close_nq > ask_price_nq: # if predicted close price for NAS100 is greater than the current ask price # Open a buy trade m_trade_nq.buy(volume=m_symbol_nq.lots_min(), symbol="NAS100", price=m_symbol_nq.ask(), sl=0.0, tp=today_pred_close_nq) # set take profit to the predicted close price print("ask: ", m_symbol_nq.ask(), "bid: ", m_symbol_nq.bid(), "last: ", ask_price_nq) print("tp: ", today_pred_close_nq, "lots: ", m_symbol_nq.lots_min()) print("istp within range: ", (m_symbol_nq.ask() - today_pred_close_nq) > m_symbol_nq.stops_level()) if not pos_exists(pos_type=mt5.ORDER_TYPE_SELL, magic=MAGIC_NUMBER, symbol="NAS100"): if today_pred_close_nq < ask_price_nq: # if predicted close price for NAS100 is less than the current bid price m_trade_nq.sell(volume=m_symbol_nq.lots_min(), symbol="NAS100", price=m_symbol_nq.bid(), sl=0.0, tp=today_pred_close_nq) # set take profit to the predicted close price # Buy and sell operations for the US500 symbol if not pos_exists(pos_type=mt5.ORDER_TYPE_BUY, magic=MAGIC_NUMBER, symbol="US500"): if today_pred_close_snp > ask_price_snp: # if the predicted price for US500 is greater than the current ask price m_trade_snp.buy(volume=m_symbol_snp.lots_min(), symbol="US500", price=m_symbol_snp.ask(), sl=0.0, tp=today_pred_close_snp) if not pos_exists(pos_type=mt5.ORDER_TYPE_SELL, magic=MAGIC_NUMBER, symbol="US500"): if today_pred_close_snp < ask_price_snp: # if the predicted price for US500 is less than the current bid price m_trade_snp.sell(volume=m_symbol_snp.lots_min(), symbol="US500", price=m_symbol_snp.bid(), sl=0.0, tp=today_pred_close_snp) RunStrategyandML(trained_model=trained_model) # Run the strategy and ML model once to initialize
Ausgabe:
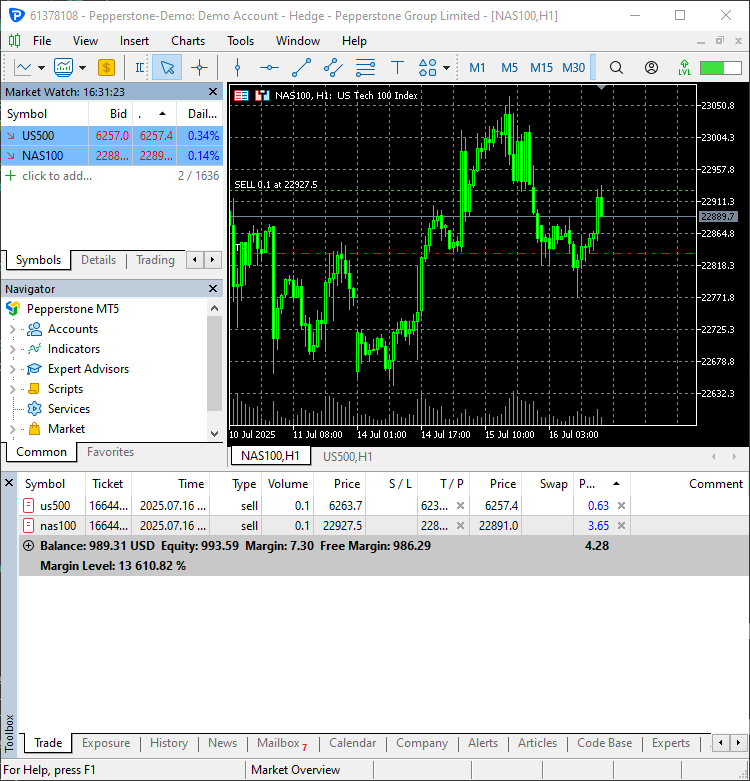
Zwei neue Handelsgeschäfte wurden eröffnet.
Schließlich können wir den Trainingsverlauf planen und das Modell so automatisieren, dass es zu Beginn eines jeden Tages Vorhersagen trifft und Handelsgeschäfte eröffnet.
# Schedule the strategy to run every day at 00:00 schedule.every().day.at("00:00").do(RunStrategyandML, trained_model=trained_model) while True: schedule.run_pending() time.sleep(10)
Schlussfolgerung
N-BEATS ist ein leistungsstarkes Modell für die Zeitreihenanalyse und -prognose. Es übertrifft die klassischen Modelle wie ARIMA, VAR, PROPHET usw. für dieselbe Aufgabe, da es im Kern neuronale Netze nutzt, die sich durch die Erfassung komplexer Muster auszeichnen.
N-BEATS ist eine perfekte Alternative für diejenigen, die Zeitreihenprognosen mit nicht-traditionellen Modellen für Zeitreihenprognosen durchführen wollen.
Ich bin begeistert, dass es Normalisierungstechniken und Auswertungswerkzeuge in seinem Werkzeugkasten hat, wodurch dieses Modell bequem zu nutzen ist.
Es ist zwar ein gutes Modell, wie jedes andere Modell des maschinellen Lernens auf der Welt, hat aber auch einige Nachteile, die zu beachten sind, darunter:
- Sie sind in erster Linie für univariate Prognosen gedacht.
Wie zuvor gesehen, benötigen sie in erster Linie nur zwei Merkmale im Trainingsdatenrahmen, ds (Zeitstempel) und die Zielvariable gekennzeichnet als y, ähnlich wie bei dem zuvor besprochenen PROPHET-Modell.
Bei Finanzdaten reichen diese beiden Merkmale nicht aus, um die Marktdynamik zu erfassen. - Sie können bei verrauschten Daten zu stark angepasst werden.
Wie andere tiefe Netze kann sich auch N-BEATS bei verrauschten Daten überanpassen. - Seine Interpretierbarkeit ist begrenzt.
Obwohl N-BEATS eine Basisfunktionszerlegung für die Interpretierbarkeit enthält, ist es immer noch ein tiefes neuronales Netz; es ist weniger interpretierbar als andere Modelle für Zeitreihenprognosen wie ARIMA und PROPHET. - In der Industrie ist es weniger verbreitet.
Wahrscheinlich haben Sie auch noch nie von diesem Modell gehört.
Obwohl es in akademischen Benchmarks sehr gut abschneidet, wurde dieses Modell im Vergleich zu anderen Modellen wie ARIMA, XGBoost, LSTM usw. in der Gemeinschaft des maschinellen Lernens noch nicht weit verbreitet. Sie werden online nicht viele Beiträge finden, die dieses Modell beschreiben.
Mit freundlichen Grüßen.
Tabelle der Anhänge
| Dateiname | Beschreibung und Verwendung |
|---|---|
| Trade\PositionInfo.py | Enthält die Klasse CPositionInfo, ähnlich der in MQL5 verfügbaren Klasse; die Klasse liefert Informationen über alle geöffneten Positionen im MetaTrader 5. |
| Trade\SymbolInfo.py | Enthält die Klasse CSymbolInfo, ähnlich der in MQL5 verfügbaren Klasse; die Klasse liefert alle Informationen über das ausgewählte Symbol aus MetaTrader 5. |
| Trade\Trade.py | Enthält die Klasse CTrade, ähnlich wie die in MQL5 verfügbare; die Klasse bietet Funktionen zum Öffnen und Schließen von Trades in MetaTrader 5. |
| error_description.py | Verfügt über die Funktionen zur Umwandlung von MetaTrader 5-Fehlercodes in menschenlesbare Informationen. |
| NBEATS-Tradingbot.py | Ein Python-Skript, das das N-BEATS-Modell verwendet, um Handelsentscheidungen zu treffen. |
| test.ipynb | Ein Jupyter-Notebook zum Experimentieren mit dem N-BEATS-Modell. |
| requirements.txt | Enthält alle in diesem Projekt verwendeten Python-Abhängigkeiten. |
Quellen und Referenzen
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/18242
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Sehen Sie sich den neuen Artikel an: Datenwissenschaft und ML (Teil 46): Aktienmarktprognosen mit N-BEATS in Python.
Autor: Omega J Msigwa