
Verwendung von Tabellenkalkulationen zur Erstellung von Handelsstrategien

Einführung
Tabellenkalkulationen sind eine ziemlich alte Erfindung. Moderne Programme dieser Art verfügen über eine enorme Leistungsfähigkeit und ermöglichen eine visuelle Analyse der in Tabellenform dargestellten Daten. Die Analyse kann aus verschiedenen Blickwinkeln erfolgen und wird recht schnell durchgeführt. Sie umfasst Diagramme, Übersichtstabellen, Was-wäre-wenn-Analysen, bedingte Zellformatierung und vieles mehr.
Ich schlage vor, einige dieser Möglichkeiten zu testen, um eigene Strategien zu analysieren.
Ich persönlich verwende LibreOffice Calc, weil es kostenlos ist und überall funktioniert, wo ich arbeite :-) Der gleiche Ansatz funktioniert jedoch auch für andere Tabellenkalkulationen: Microsoft Excel, Google Sheets, etc. Derzeit erlauben sie alle die Konvertierung ineinander und verfügen über die gleichen Prinzipien zur Konstruktion von Gleichungen.
Ich nehme also an, dass Sie eine Art Tabellenkalkulationsprogramm haben. Sie haben auch Daten in einem Textdateiformat (*.txt oder *.csv), die Sie analysieren möchten. Der Artikel beschreibt kurz, wie Sie solche Dateien importieren können. Ich werde die Historie aus dem MetaTrader-Terminal verwenden, es geht aber auch jede andere Datei, wie Dukascopy oder Finam. Natürlich sollten Sie eine Strategie haben, um Signale zu konfigurieren. Dies ist alles, was erforderlich ist, um die Vorschläge des Artikels im Handel anzuwenden.
Ich hoffe, der Artikel wird für verschiedene Kategorien von Händlern nützlich sein, deshalb werde ich versuchen, ihn so zu schreiben, dass er auch für Leute verständlich ist, die noch nie Programme dieser Art gesehen haben. Gleichzeitig wird er eine Reihe von Themen abdecken, mit denen selbst einige erfahrene Trader nicht vertraut sind.
Ein kurzer Blick auf Tabellen — für Anfänger
Abbildung 1 zeigt ein typisches Fenster eines Tabellenkalkulationsprogramms.
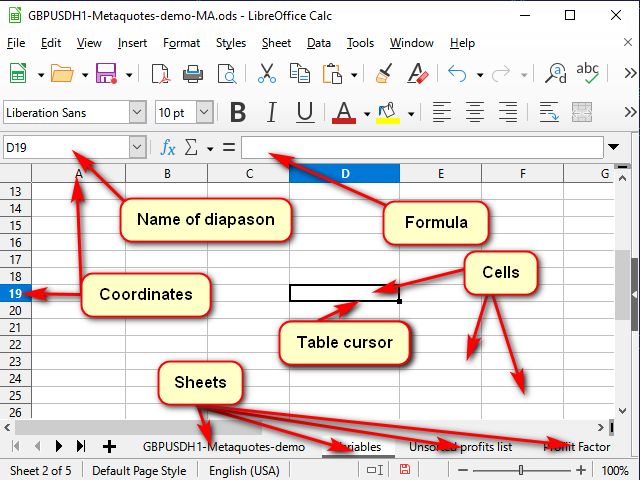
Abbildung 1. Ein typisches Fenster eines Tabellenkalkulationsprogramms
Jede Tabelle wird als eine Reihe von "Blättern" dargestellt. Sie können sich diese als separate "Registerkarten" (Tabs)für verschiedene Aufgaben vorstellen.
Jedes Blatt besteht aus "Zellen". Jede Zelle ist im Wesentlichen ein kleiner, aber sehr leistungsfähiger Taschenrechner.
Damit das Programm versteht, welche Zelle wir gerade bearbeiten wollen, besitzt jede Zelle Koordinaten, wie auf einem Schachbrett oder in einem Battleship-Brettspiel. Diese Koordinaten zusammen definieren eine eindeutige "Adresse" der Zelle. Die Adresse besteht aus einer Spaltennummer oder einem Namen und einer Zeilennummer (in Abbildung 1 ist zum Beispiel die Zelle "D19" durch den Tabellencursor hervorgehoben). Sie ist sowohl in den hervorgehobenen Koordinatennamen als auch in der Namenszeile zu sehen.
Zusätzlich zu den Koordinaten kann eine Adresse auch den Namen des Blattes und sogar den Namen der Tabellendatei enthalten. Normalerweise wird die gleiche Adresse als Name der Zelle verwendet. Wenn Sie möchten, können Sie aber auch eigene Namen vergeben, um zu verdeutlichen, was genau diese Zelle oder dieser Zellbereich speichert. Diese Namen können Sie in der Namenszeile einsehen (und ändern).
Eine Zelle kann entweder einfache Daten (wie Anführungszeichen oder Volumen) oder "Formeln" zur Berechnung ihres Wertes enthalten.
Der Inhalt einer markierten Zelle ist in der "Formelzeile" zu sehen (und zu ändern).
Um einen Zellwert zu bearbeiten, klicken Sie doppelt auf ihn oder nehmen Sie Ihre Korrekturen in der Formelzeile vor. Sie können auch eine Zelle markieren und F2 drücken. Wenn Sie einen neuen Text erstellen müssen, können Sie eine Zelle markieren und sofort mit der Eingabe beginnen. Beachten Sie jedoch, dass alle vorherigen Daten in der Zelle gelöscht werden.
Sie können die Bearbeitung abbrechen, ohne sie zu speichern, indem Sie ESC drücken (linke obere Ecke der Tastatur). Bestätigen Sie die Bearbeitung mit Enter (der Cursor wird nach unten bewegt) oder Tab (der Cursor wird zur Seite bewegt).
Wenn mehrere Zellen markiert sind, wirken Eingabe und Tab nur im markierten Teilbereich. Dies kann zur Beschleunigung der Arbeit genutzt werden.
Was die anderen Schaltflächen und Menüs angeht, so sind sie, wie ich finde, recht einfach zu verstehen.
Erste Schritte: Importieren von Kursen
Lassen Sie uns Daten zum Testen von Strategien vorbereiten. Wie gesagt, ich werde Daten aus dem Terminal übernehmen. Drücken Sie dazu Strg+S in einem beliebigen Chartfenster oder wählen Sie Datei -> Speichern im Terminal-Menü. Das Terminal bietet das übliche Systemfenster zur Eingabe des Dateinamens und des Pfades an.
Wenn die Dateierweiterung *.csv ist, dann geht normalerweise alles gut. Ist es *.txt, dann müssen Sie in den meisten Fällen mit der rechten Maustaste darauf klicken und "Öffnen mit" ->"Andere Anwendung wählen" wählen oder zuerst die Tabellenkalkulationsanwendung öffnen und die Datei von dort aus öffnen, da das System dazu neigt, Dateien mit dieser Endung standardmäßig mit Notepad oder einer anderen Textverarbeitung zu öffnen.
Um Zahlen zu konvertieren, wählen Sie im Konvertierungsfenster die entsprechende Spalte aus. Geben Sie dann das Trennzeichen für den ganzzahligen und den gebrochenen Teil an, sowie ggf. das Trennzeichen für die Zifferngruppen (bei Volumen). In Excel geschieht dies über die Schaltfläche "Mehr ...". In Calc wählen Sie in der Liste "Spaltentyp" die Option "English USA".
Es gibt noch eine weitere Nuance. Nach einem erfolgreichen Import ist es sinnvoll, 5-7 Tausend Zeilen in der Tabelle zu belassen. Denn je mehr Daten vorhanden sind, desto schwieriger ist es für das Programm, das Ergebnis für jede Zelle zu berechnen. Gleichzeitig erhöht sich die Abschätzungsgenauigkeit nur unwesentlich. Wenn Sie beispielsweise die Verifizierungsergebnisse für Daten mit 5.000 und 100.000 Zeilen vergleichen, unterscheiden sich die Ergebnisse nur um 1 %, während die Berechnungszeit im letzteren Fall deutlich zunimmt.
Einige Tastaturkürzel für die Arbeit mit Tabellen
| Shortcut | Aktion |
|---|---|
| Strg + Pfeile | Gehen Sie zu der nächstgelegenen folgenden Datenzeilengrenze |
| Tabulator | Eingabe bestätigen und zur rechten Zelle gehen |
| Shift +Tab | Eingabe bestätigen und zur linken Zelle gehen |
| Enter | Eingabe bestätigen und zur nächsten Zelle nach unten gehen |
| Shift + Enter | Eingabe bestätigen und zur nächsten Zelle oben gehen |
| Strg + D | Ausfüllen der Spalten von oben nach unten ausfüllen |
| Shift + Strg + Pfeile | Highlight von der aktuellen Position bis zum Ende des fortlaufenden Bereichs |
Wie man eine lange Spalte mit der gleichen Gleichung füllt
Für kleine Bereiche können Sie die in Abbildung 2 gezeigte Methode verwenden: Bewegen Sie die Maus auf die "Auswahlmarkierung" (das Quadrat in der unteren rechten Ecke des Tabellencursors). Wenn sich der Mauszeiger in ein dünnes Kreuz verwandelt, ziehen Sie diese Markierung auf die gewünschte Zeile oder Spalte.
Abbildung 2. Ausfüllen durch Ziehen
Bei großen Datenmengen wäre dies jedoch sehr unpraktisch.
Verwenden Sie daher eine der folgenden Methoden.
Methode 1. Begrenzen des Bereichs
Die Reihenfolge der Aktionen ist in Abbildung 3 dargestellt.
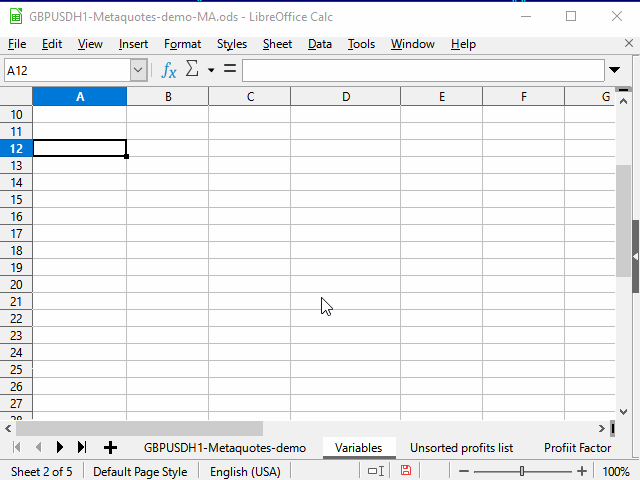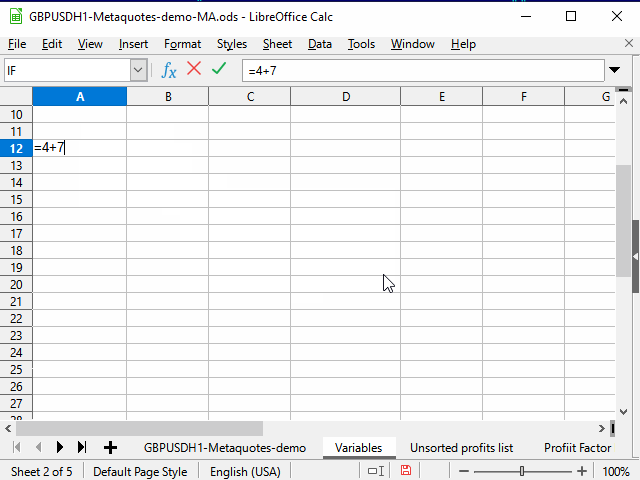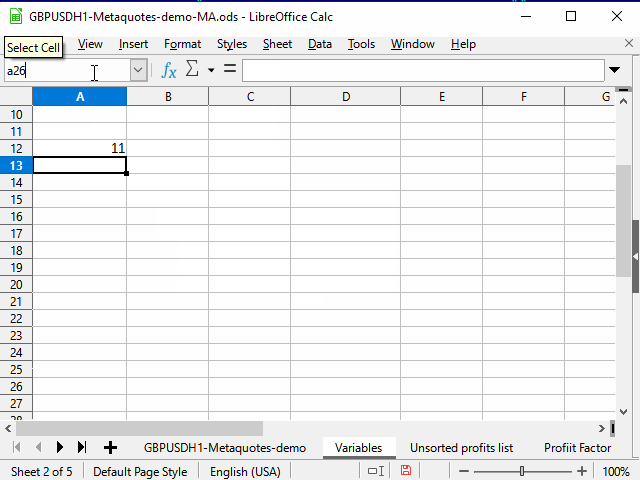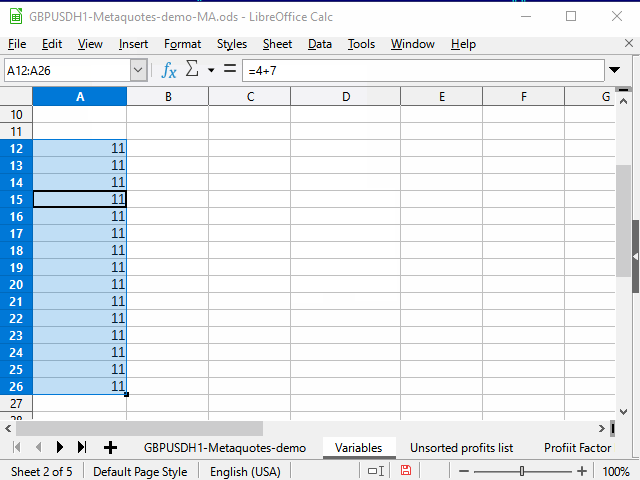
Abbildung 3. Ausfüllen durch Eingrenzen des Bereichs
- Geben Sie in der obersten Zelle des Bereichs die gewünschte Gleichung ein und bestätigen Sie die Eingabe.
- Wechseln Sie mit dem Namensfeld in die unterste Zelle des Bereichs.
- Drücken Sie Strg + Shift + Pfeil nach oben, um zur obersten Zelle des Bereichs zu gelangen und alle Zwischenzellen zu markieren.
- Drücken Sie Strg + D, um die Zellen mit Daten zu füllen.
Ein kleiner Nachteil der Methode ist, dass Sie die Nummer der untersten Zeile des Bereichs kennen müssen.
Methode 2. Benutzen eines angrenzenden zusammenhängenden Bereichs
Die Reihenfolge der Aktionen ist in Abbildung 4 dargestellt.
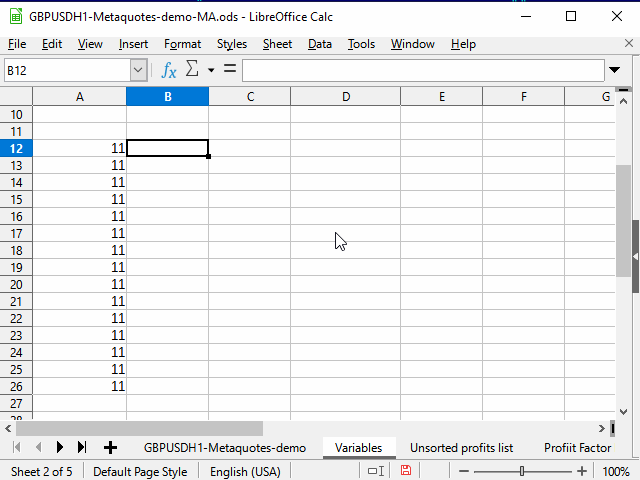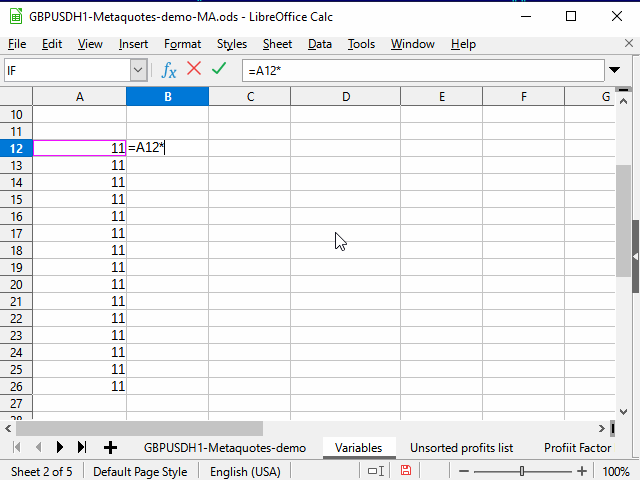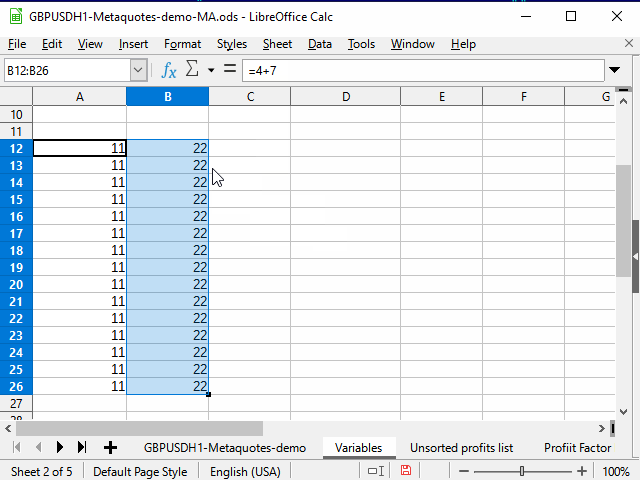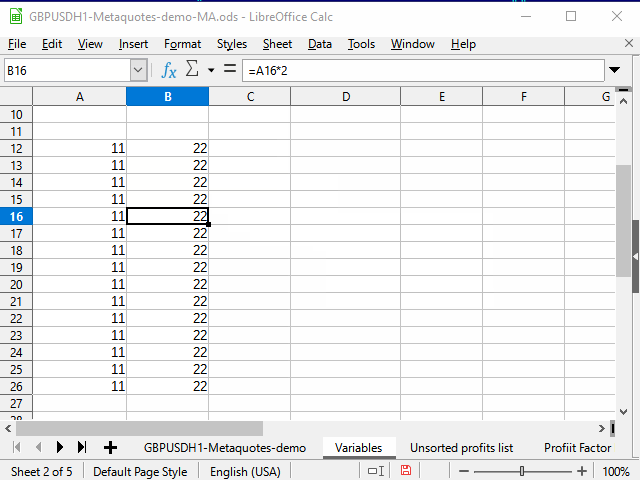
Abbildung 4. Ausfüllen mit Hilfe eines angrenzenden Bereichs
- Markieren Sie die Zelle mit der benötigten Gleichung.
- Drücken Sie Shift + Pfeil nach links, um eine benachbarte Zelle auszuwählen.
- Drücken Sie Tab, um den Tabellencursor auf die linke Zelle zu bewegen. Hier nutzen wir die Fähigkeit des Tabellencursors, sich nur innerhalb der angewendeten Auswahl zu bewegen.
- Strg + Shift + Pfeil nach unten — zwei Spalten bis zur untersten Zeile des zusammenhängenden Bereichs auswählen.
- Shift +Pfeil nach rechts - hebt die Auswahl der linken Spalte auf. Die rechte bleibt markiert.
- Strg + D — füllt die Spalte mit Daten.
Beachten Sie den Inhalt der Formelzeile in der Abbildung. Beim Kopieren der Gleichung, die die Verknüpfung enthält, in eine andere Zelle, ändert sich diese Verknüpfung automatisch in Abhängigkeit von der Cursorposition. Daher wird eine solche Verknüpfung "relativ" genannt.
Wenn die Verknüpfung zur Zelle beim Kopieren konstant bleiben soll, markieren Sie die Verknüpfung und drücken Sie F4. Das $-Zeichen erscheint vor der Zeilennummer und dem Spaltennamen, und der Wert ändert sich beim Kopieren der Gleichung nicht.
Manchmal möchten Sie vielleicht, dass nur eine bestimmte Spalte oder Zeile erhalten bleibt und nicht die gesamte Verknüpfung. In diesem Fall lassen Sie das $-Zeichen nur im unveränderlichen Teil stehen (Sie können noch ein oder zwei Mal F4 drücken).
Nachdem wir nun die grundlegenden Methoden zur Beschleunigung unserer Arbeit gemeistert haben, ist es an der Zeit, zur eigentlichen Strategie überzugehen.
Strategie
Verwenden wir die Strategie, die im Standard "Examples\Moving Average" EA implementiert ist.
Eine Position wird eröffnet, wenn:
- Es keine Positionen gibt und
- die Kerze kreuzt den Gleitenden Durchschnitt mit ihrem Körper (Open — auf einer Seite des МА, Close — auf der anderen).
Eine Position ist geschlossen, wenn:
- Es gibt eine offene Position und
- die Kerze kreuzt den MA in der entgegengesetzten Richtung zur Eröffnung.
Hinzufügen der Indikatordaten
Die Besonderheit beim Rechnen mit Tabellenkalkulationen besteht darin, dass die Zwischensummen der Berechnungen in der Regel separat gespeichert werden müssen. Dies erleichtert das Verständnis von Gleichungen und das Erkennen von Fehlern und vereinfacht auch das Erstellen von Gleichungen, die auf Daten aus benachbarten Zellen basieren. Außerdem führt eine solche "Fragmentierung" manchmal zu neuen Ideen.
Aber kommen wir zurück zu unserer Aufgabe.
Nach dem Importieren und ein wenig Formatieren sehen meine ursprünglichen Zitate so aus (Abbildung 5):
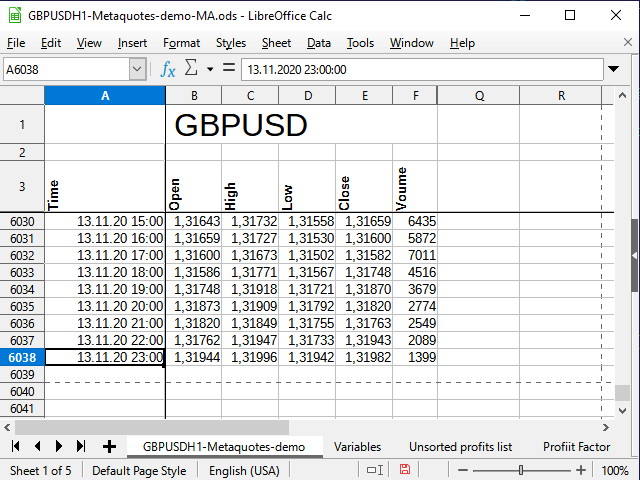
Abbildung 5. Originalkurse
Beachten Sie die leere Zeile zwischen dem Namen der gesamten Tabelle und den Spaltennamen. Diese Zeile ermöglicht es dem Tabellenkalkulationsprogramm, die beiden Blöcke als separate Tabellen zu behandeln, und deshalb kann ich die Zellen für den oberen Bereich kombinieren, aber trotzdem verschiedene Filter für den unteren Bereich verwenden - und sie werden sich nicht gegenseitig stören. Das Entfernen der Zeile kann zu Problemen führen.
Ich habe die ersten Zeilen und Spalten angepasst, um die Informationen auszublenden, die im Moment unnötig sind, aber alle Daten sind immer noch in der Tabelle vorhanden (siehe die Hilfe Ihres Tabellenkalkulationsprogramms, wie man das macht).
Uhrzeit und Datum stehen in der Spalte A, die Eröffnungspreise in der Spalte B usw. Die letzte Zeile der Tabelle ist mit 6038 nummeriert.
Der erste Schritt zum Erstellen einer Strategie ist das Erstellen eines Indikators. Damit der Indikator anpassbar ist, fügen wir ein weiteres Blatt hinzu und erstellen dort eine Tabelle mit Variablen. Wir werden jeder Variablen einen richtigen Namen zuweisen, indem wir die Namenszeile verwenden, so dass es klar ist, was und wo wir bei der Erstellung der Gleichungen nehmen müssen.
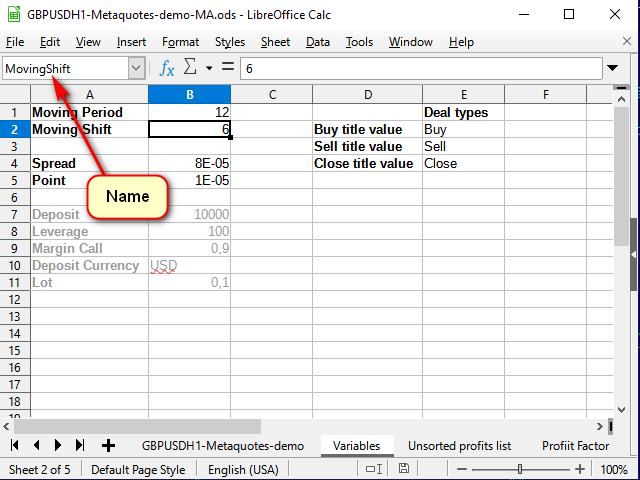
Abbildung 6. Das Blatt Variables
Kehren wir nun zum Datenblatt zurück. Schreiben Sie zunächst den Zeilenindex in der Liste in die Spalte G, um die endgültige Gleichung etwas zu vereinfachen. Er ist gleich dem Zeilenindex minus 3:
=ZEILE()-3 (statt der englischen Funktionsnamen der Tabellenkalkulation werden im Text des Artikels die deutschen angegeben und ',' durch ';; ersetzt.)
Nachdem Sie die Gleichung in die Zelle G4 geschrieben haben, erweitern Sie sie auf alle unteren Zellen, damit die Gleichung für die MA-Berechnung universell bleibt. Wenn MA (Offset + Periode) die vorhandenen Daten übersteigt, dann wird die Mittelwertberechnung sinnlos.
Die SMA-Berechnungsgleichung selbst ist in Н4 des Hauptdatenblatts geschrieben und sieht wie folgt aus:
=WENN( G4>(MovingPeriod+MovingShift); MITTELWERT( INDIREKT( "E" & ( ZEILE()-MovingShift-MovingPeriod) & ":" & "E" & ( ZEILE()-MovingShift) ) ); "" )
Bei der Eingabe von Gleichungen, die Verknüpfungen zu anderen Zellen erfordern, können Sie die Zellen mit der Maus angeben.
Die aktuelle Gleichung beginnt mit dem Aufruf der WENN()-Funktion. Wie Sie vielleicht schon erraten haben, handelt es sich hierbei um die Bedingungsprüfungsfunktion. Alle booleschen Ausdrücke, wie UND, ODER, NICHT, sind ebenfalls Funktionen, falls sie später benötigt werden.
Beim Aufruf von Funktionen werden die Argumente in Klammern angegeben und durch Kommas (wie in diesem Fall) oder Semikolons getrennt.
Die Funktion WENN nimmt drei Argumente entgegen: Bedingung; Wert, wenn Bedingung wahr ist und Wert, wenn Bedingung falsch ist.
In diesem Fall habe ich es benutzt, um zu prüfen, ob genügend Daten vorhanden sind, um einen vollwertigen Punkt für die MA-Kurve zu berechnen. Wenn nicht genügend Daten vorhanden sind, wird einfach ein leerer String gespeichert. Andernfalls Berechnen Sie den Durchschnittswert aus einem Bereich.
Die Funktion INDIREKT liefert den Wert (oder mehrere Werte) aus dem durch die Textzeichenfolge festgelegten Bereich. Das ist genau das, was ich benötige, da die Adressen der benötigten Bereiche für die Berechnung des Durchschnitts anhand der Eingabewerte gebildet werden sollen.
Das &-Symbol in Tabellenkalkulationsprogrammen bezeichnet die Verkettung von zwei Zeilen. Ich habe also die Adresse aus mehreren Teilen "zusammengesetzt". Der erste Teil ist ein Spaltenname, in dem sich die Schlusskurse ("Е") befinden, während der zweite Teil eine "entfernte" Adresse ist, die sich aus der aktuellen Zeilennummer minus der Mittelungslänge und minus dem Shift ergibt. Der dritte Teil dieses Ausdrucks ist das Doppelpunktzeichen, das die Kontinuität des Bereichs anzeigt. Es folgt der Spalten- und Zeilenname unter Berücksichtigung des Shifts. Ich habe mich entschieden, sie nicht zu stark hervorzuheben. Ich hoffe, dass die eingeschnittenen Ampersanden hilfreich sind, um die Gleichung zu verstehen.
Die Gleichung soll auf alle darunter liegenden Zeilen ausgedehnt werden.
Als Ergebnis erhalten wir etwas wie dieses:
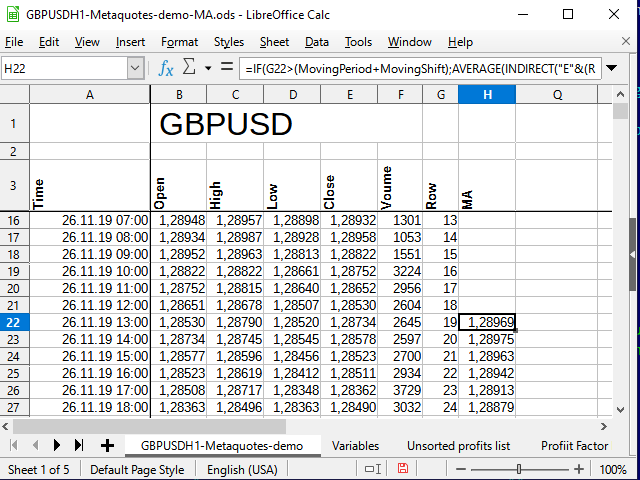
Abbildung 7. Die Tabelle nach dem Hinzufügen von МА Berechnungen
Wie wir sehen, beginnen die Zahlen in der Spalte Н erst in der Zeile 22 (dem 19. Eintrag) zu erscheinen. Der Grund dafür wird in Abbildung 6 erklärt.
Nun haben wir die Ausgangsdaten, sowie die Indikatordaten. Es ist nun an der Zeit, die Strategie zu implementieren.
Implementieren der Strategie
Wir werden die Strategie in Form von einfachen Signalen implementieren. Wenn МА nach unten gekreuzt wird, erhält die Zelle den Wert "-1", sonst - "1". Wenn es gerade keine Kreuzungen gibt, enthält die Zelle den Wert der leeren Zeichenkette.
Gehen Sie zur Zelle I4. Die Grundgleichung für die Zelle sieht wie folgt aus:
=WENN( UND( B4>H4;E4<H4 );-1 ; WENN( UND( B4<H4;E4>H4 ); 1 ; "") )
Sie können es im Diagramm überprüfen, es funktioniert. Aber dies ist eine einfache Umkehrgleichung. Sie erlaubt es nicht, den Status des Deals zu verfolgen. Sie können damit experimentieren und interessante Ergebnisse erhalten, aber unsere Aufgabe ist es jetzt, die am Anfang des Artikels beschriebene Strategie zu implementieren. Dazu müssen wir den Deal-Status bei jedem Takt (in jeder Zeile) aufzeichnen.
Die Spalte J ist dafür gut geeignet. Die Gleichung in der Zelle J4 sieht wie folgt aus:
=WENN(UND(I4=-1;J3=""); -1 ;WENN(UND(I4=1;J3=""); 1 ;WENN(ODER(UND(I4="";J3=1);UND(I4="";J3=-1);I4=J3); J3 ;"")))
Wenn ein Ereignis (Kreuzung) aufgetreten ist, prüfen Sie den Status des vorherigen Deals. Wenn die Position offen ist und die Kreuzung in der entgegengesetzten Richtung auftritt, wird sie geschlossen. Wenn die Position geschlossen ist, wird sie geöffnet. In allen anderen Fällen speichern Sie einfach den Status.
Lassen Sie uns eine weitere Spalte mit Signalen einführen, um klar zu sehen, wo wir gekauft und verkauft hätten, wenn wir diese Strategie in der Periode, der unsere Daten entsprechen, implementiert hätten, und auch, um die Analyse der Strategie zu erleichtern.
Die Signalnamen können aus der Hilfe entnommen werden, die auf dem Variablenblatt erstellt werden kann.
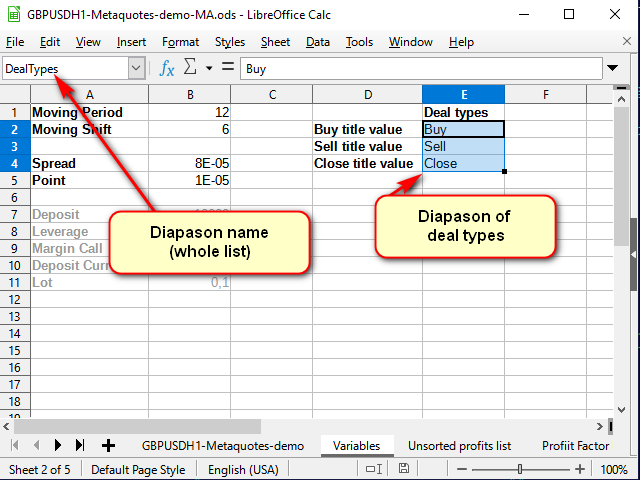
Abbildung 8. Das Variablenblatt nach dem Hinzufügen der Hilfe für Geschäftsnamen
Beachten Sie die Namenszeile: Hier habe ich den Namen auf den gesamten markierten Bereich gesetzt, nicht auf eine einzelne Zelle.
Jetzt können wir in die К4 Zelle des Hauptblattes (mit Daten) folgendes schreiben:
=WENN(UND(J3=1;J2="");INDEX(DealTypes;1);WENN(UND(J3=-1;J2="");INDEX(DealTypes;2);WENN(ODER(UND(J3="";J2=1);UND(J3="";J2=-1));INDEX(DealTypes;3);"")))
Die Position wird nach einem Signal bei der Eröffnung der nächsten Kerze eröffnet. Achten Sie deshalb auf die Verschiebung der Indizes in dieser Gleichung.
Wenn noch keine Position eröffnet worden ist (die vorherige Zelle in der Statusspalte ist leer) und ein Signal eingetroffen ist, geben Sie an, welcher Geschäftstyp gemacht werden soll. Wenn die Position eröffnet wurde, schließen Sie es entsprechend dem Signal.
Die Funktion Index nimmt als ersten Parameter den Bereich an, in dem die Suche durchgeführt werden soll. In unserem Fall wird er durch den Namen festgelegt. Der zweite Parameter ist der Index der Zeile innerhalb des Bereichs. Wenn der Bereich aus mehreren Spalten besteht, setzen Sie die notwendige Spalte. Werden mehrere Bereiche durch Semikolon getrennt angegeben, setzen Sie den Bereichsindex ebenfalls ab 1 (der dritte bzw. vierte Parameter).
Als Ergebnis erhalten wir, nachdem wir diese Gleichung auf alle unten stehenden Zellen ausgedehnt und die bedingte Formatierung angewendet haben (für mehr visuelle Attraktivität, da die Formatierung während der Analyse nicht benötigt wird), ungefähr Folgendes
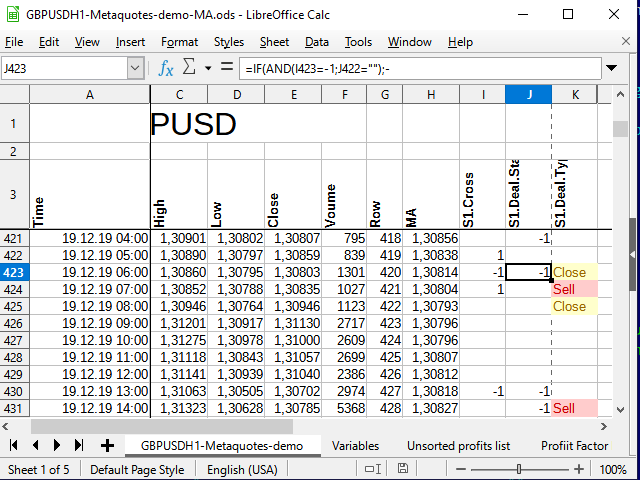
Abbildung 9. Signale für Positionen
Analysieren der Strategie
Um die Profitabilität der Strategie zu analysieren, muss ich die Strecke berechnen, die der Preis während der Handelsperiode zurückgelegt hat. Dies geschieht am einfachsten in mehreren Schritten.
Wählen Sie zunächst den Preis der Position. Wenn eine Position eröffnet wird, setzen Sie den Preis in die Spalte neben dem Signal (L) und kopieren ihn in jede folgende Zelle, bis die Position geschlossen ist. Wenn es keine Position gibt, dann wird eine leere Zeile in die Zelle geschrieben. Die Gleichung in der Zelle L4:
=WENN(K4=INDEX(DealTypes;1);B4+Spread;WENN(K4=INDEX(DealTypes;2); B4 ;WENN(ODER(K4=INDEX(DealTypes;3);N(L3)=0); "" ;L3)))
Wenn die Zelle des Signals (К4) das Wort "Buy" enthält, ist der Preis der offenen Position gleich dem Preis der offenen Kerze plus Spread. Wenn das Wort "Sell" ist, schreiben Sie einfach den Kerzeneröffnungspreis, wenn "Schließen" (oder die vorherige Spaltenzelle enthält keine Zahl) - eine leere Zeichenkette, und wenn die vorherige Zelle der gleichen Spalte eine Zahl ist, während die Signalspalte keine Wörter enthält, kopieren Sie einfach die vorherige Zelle.
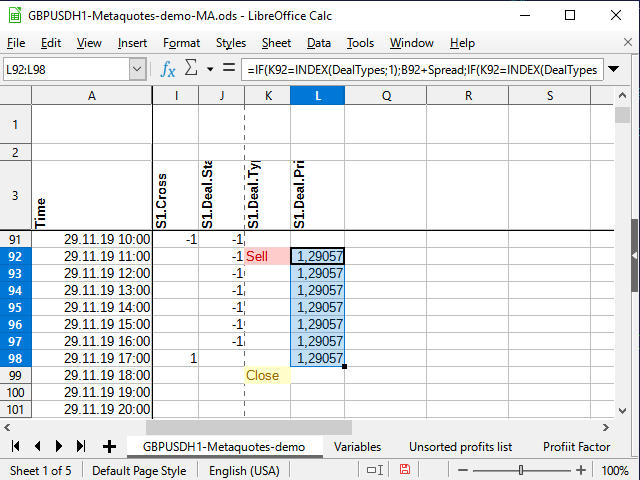
Abbildung 10. Position offener Preis
Auf diese Weise können wir den Gewinn der Position zum Zeitpunkt der Schließung leicht berechnen.
Stellen Sie sicher, dass Sie die Gleichung unten erweitern.
Wir könnten sofort die Differenz zwischen dem Eröffnungs- und dem Schlusskurs in der nebenstehenden Spalte berechnen. Aber stattdessen werden wir etwas Kniffligeres tun. Wir werden die Differenz in der Spalte N berechnen, um nur eindeutige Daten aussortieren zu können und anschließend deren Häufigkeit zu berechnen.
Im aktuellen, einfachsten Bewertungsfall werde ich kein Money-Management verwenden, da mein Ziel darin besteht, die Effizienz der Strategie zu bewerten. Daher reicht es aus, die Preisdifferenz in Pips zu berechnen. Zum Beispiel:
=WENN(K4=INDEX(DealTypes;3);WENN(I3=-1;RUNDEN((B4-L3)/Point);RUNDEN((L3-B4)/Point)); "" )
Es ist klar, dass wir, anstatt die Durchschnittsbedingung zu prüfen, einfach (B3-L3)*I3 multiplizieren könnten, aber das wäre für Anfänger visuell weniger klar.
Und nun ist es an der Zeit für den erwähnten Trick. In der Spalte М nummerieren Sie alle eindeutigen Einträge über den Bereich der Position und lassen die nicht eindeutigen ohne Nummer.
=WENN(N4<>"";WENN(ZÄHLENWENN(N$3:N4;N4)=1;MAX(M3:M$4)+1;"");"")
Die äußere Bedingung ist ganz klar: Wenn die rechte Zelle (N4) nicht leer ist, prüfen Sie, ob sie eindeutig ist und nummerieren Sie sie gegebenenfalls, ansonsten lassen Sie einen leeren String stehen.
Aber wie funktioniert die Nummerierung?
Die Funktion ZÄHLENWENN zählt die Anzahl der Zahlen innerhalb des angegebenen Bereichs, sofern der Zellwert der im zweiten Parameter angegebenen Bedingung entspricht. Angenommen, die Gleichung wird für die Zelle M71 berechnet. Die Zelle N71 enthält die Zahl 531 (siehe Abbildung 11). Diese Zahl ist bisher noch nie gesehen worden.
Wenn das Aktionszeichen in der Bedingungszelle nicht angegeben ist, wird davon ausgegangen, dass wir die Gleichheit zweier Werte prüfen wollen. Die Zahl ist gleich sich selbst (N71=N71), also versuchen wir zu rechnen. Die Berechnung beginnt immer bei der Zelle N$3 (beachten Sie das Dollarzeichen vor der Zahl drei) und geht bis zur aktuellen Zelle (kein Dollarzeichen in der Gleichung). Betrachten Sie den gesamten Bereich N$3:N71 und versuchen Sie, die Gesamtzahl der 531 Zahlen in diesem Bereich zu zählen. Da es vorher keine solchen Zahlen gab, ist die Gesamtzahl 1 (was jetzt gefunden wurde). Das bedeutet, dass die Bedingung erfüllt ist: Das Ergebnis der Funktion ist 1. Wir nehmen also folgenden Bereich: die Spalte, in der sich die Gleichung befindet, beginnend mit der allerersten Zelle mit Zahlen (M$4) bis zur Zelle vor der aktuellen (M70). Wenn es dort vorher Zahlen gab, nehmen Sie die größte davon und addieren 1 dazu. Wenn nicht, ist die größte 0, und dementsprechend ist die erste Folgenummer fertig!
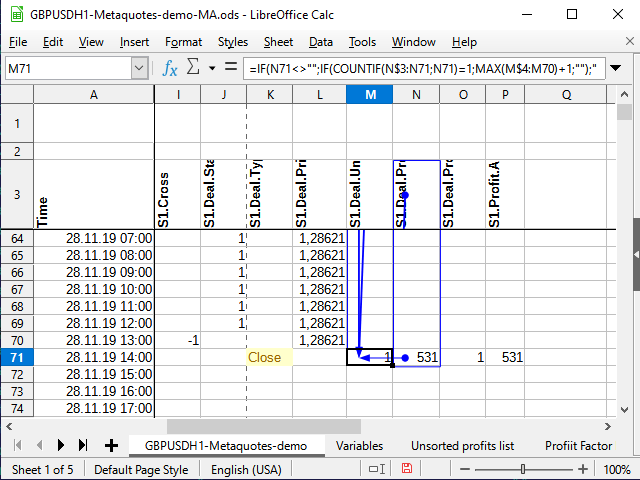
Abbildung 11. Bezifferung. Betroffene Zellen (Endpunkt des Bereichs)
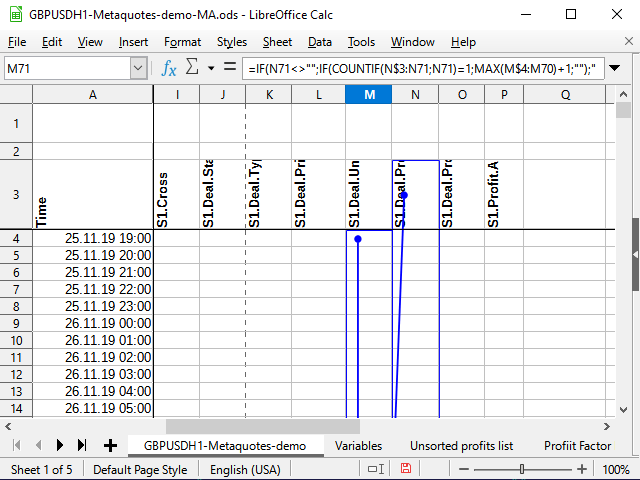
Abbildung 12. Bezifferung (Anfangspunkt des Bereichs)
In Abbildung 11 habe ich versucht, das eingebaute Analysewerkzeug zu verwenden, das die Zellen anzeigt, die eine bestimmte Zelle betreffen. Der Punkt mit dem Pfeil zeigt den Beginn der Bereiche oder "exakten" Zellen an, während die Rechtecke die Bereiche anzeigen. Ich habe der Übersichtlichkeit halber Abbildung 12 angehängt, um deutlich zu machen, dass der Pfeil durchgängig ist und genau bei N$3 beginnt, sowie um die Anfänge der Bereiche, in denen die Vergleiche durchgeführt werden, sichtbar zu machen.Außerdem füge ich zwei weitere Wertespalten hinzu: Ergebnistyp und Position "Modul".
Für die Ergebnistypen verwende ich Zahlen: Position kaufen - 1, Position verkaufen - 2. In diesem Fall kann das Ergebnis positiv oder negativ sein, je nachdem, ob wir einen Gewinn oder Verlust als Ergebnis der Position erhalten haben. Dadurch werden die endgültigen Analysegleichungen kürzer.
Hier ist die Gleichung in die О4 Zelle geschrieben:=WENN(UND(N(N4)>0;I3=-1); 1 ;WENN(UND(N(N4)<0;I3=-1); -1 ;WENN(UND(N(N4)>0;I3=1); 2 ;WENN(UND(N(N4)<0;I3=1); -2 ;""))))
Das "Modul" ist einfach der Betrag des Gewinns oder Verlusts ohne Berücksichtigung des Vorzeichens. Es ist eine Beschreibung, wie weit der Preis in eine Richtung ging, bis das Signal für die Schließung der Position eintraf. Dies kann Ihnen helfen, Stop-Loss und Take-Profit zu wählen (auch wenn sie für die ursprüngliche Strategie nicht benötigt werden).
=WENN(N4<>"";ABS(N4);"")
Um ein Häufigkeitsdiagramm (probabilistisch) zu erstellen, ist es besser, die Daten der Positionen in aufsteigender Reihenfolge anzuordnen. Kopieren Sie sie in ein anderes Blatt, da die Originaldaten nach Zeit sortiert sind und nicht anders sortiert werden können.
Da jedes eindeutige Gewinnergebnis eine eigene eindeutige Nummer hat (М Spalte), gibt es mindestens zwei Möglichkeiten, die unsortierten Daten in ein neues Blatt zu kopieren.
Eine davon ist, einfach "nicht leere" Zellen mit einem Standardfilter in der Spalte М auszuwählen und dann die Daten aus der Spalte N zu kopieren und mit dem speziellen Einfügen (nur Werte) in ein anderes Blatt einzufügen.
Die zweite Methode ist die Verwendung der Gleichung. Der Vorteil ist, dass sich die Daten selbst ändern, wenn sich die ursprünglichen Daten (dieselben Variablen oder einige andere, wenn Sie sich entscheiden, einen anderen Testbereich zu verwenden) ändern. Der Nachteil ist, dass es wahrscheinlich immer noch unmöglich sein wird, zu sortieren. Sie werden immer noch Kopieren/Einfügen verwenden müssen, um sie zu sortieren.
Für mich ist es bequemer, wenn sich sortierte und unsortierte Daten auf demselben Blatt befinden, weil es etwas weniger Aktionen erfordert, die Daten zu kopieren. Deshalb zeige ich eine Option, bei der unsortierte Daten über die Gleichung kopiert und dann zum Sortieren wieder manuell kopiert werden.
Erstellen Sie auf dem neuen Blatt Profit data (Ergebnisdaten) die Formel in А2:
=VVERWEIS( ZEILE(1:1);'GBPUSDH1-Metaquotes-demo'.$M$3:$N$6038; 2 )
Die Funktion ZEILE(1:1) gibt die Nummer der ersten Zeile zurück. Beim Füllen der Zellen nach unten ändert sich die Zeilennummer, und entsprechend wird die Nummer der zweiten, dritten Zeile usw. angezeigt.
VERWEIS sucht irgendeinen Wert (der erste Parameter) in der ersten Spalte des Bereichs (der zweite Parameter) und gibt dann den Wert zurück, der sich in der gleichen gefundenen Zeile befindet, allerdings in der im dritten Parameter angegebenen Spalte (in unserem Fall ist das die Spalte 2 des angegebenen Bereichs). Mit anderen Worten: Es werden alle nummerierten (eindeutigen) Zahlenwerte aus der NSpalte, beginnend mit 1, kopiert.
Nachdem Sie die letzte Zahl auf dem Hauptblatt mit dem Standardfilter definiert haben, können Sie alle restlichen Daten mit der Bereichsbegrenzungsmethode kopieren.
Die folgenden Aktionen sind in der Animation in Abbildung 13 dargestellt.
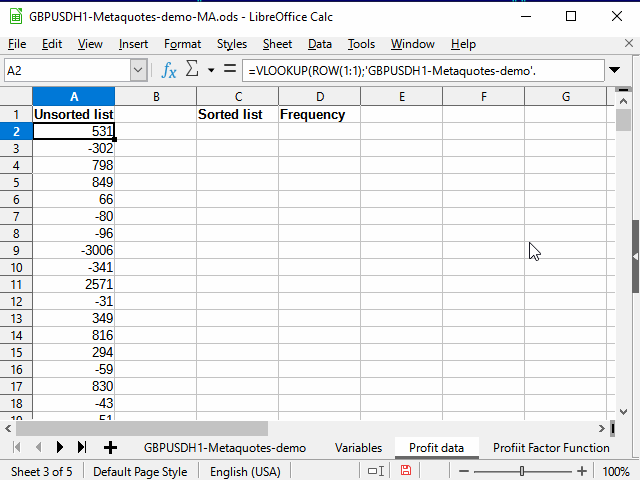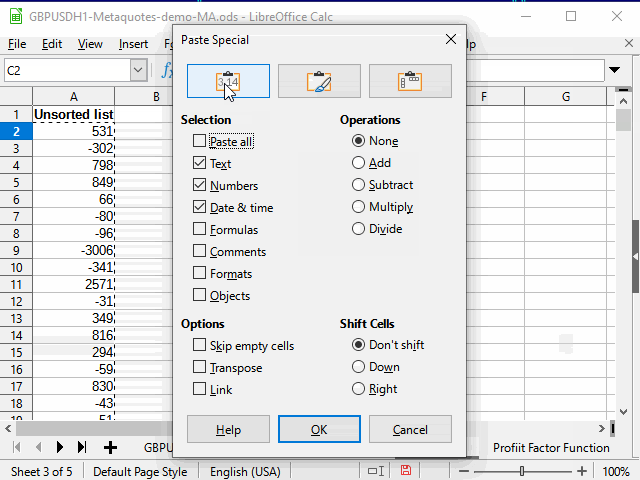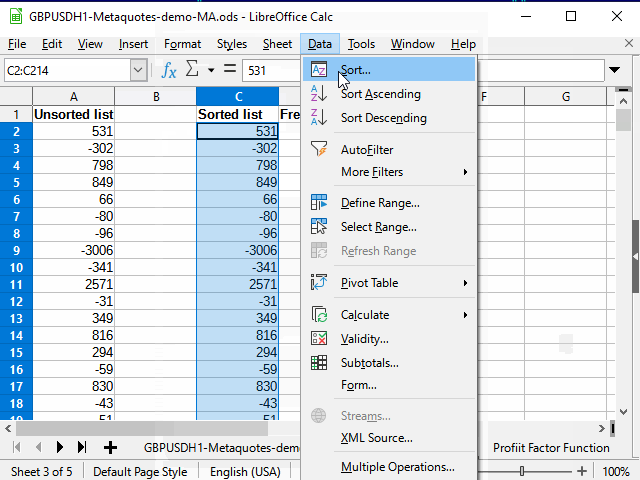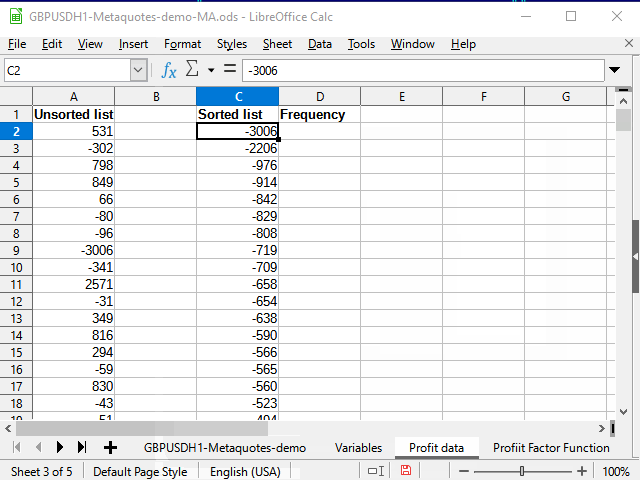
Abbildung 13. Kopieren von Daten für die Sortierung
Nun müssen wir die Häufigkeit von profitablen und unprofitablen Trades beschreiben, d. h. eine Wahrscheinlichkeitsreihe bilden.
In die Zelle D2 desselben Blattes (Gewinndaten) können wir die folgende Gleichung schreiben:
=ZÄHLENWENN('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;C2)/ANZAHL('GBPUSDH1-Metaquotes-demo'.$N$4:'GBPUSDH1-Metaquotes-demo'.$N$6038)
Das beschreibt die Häufigkeit (oder Wahrscheinlichkeit) eines jeden Gewinns
Die Funktion ZÄHLEN berechnet die Anzahl der Zahlenwerte im Intervall, ZÄHLENWENN tut dasselbe, wenn die Bedingung erfüllt ist (in diesem Fall werden nur die Zellen berechnet, deren Wert gleich dem Wert in der C-Spaltenzelle ist).
Es wird normalerweise empfohlen, Intervall-Variationsreihen zu machen. Theoretisch kann man sagen, dass die Anzahl der Positionen ziemlich groß sein kann.
Es wird empfohlen, die Größe des Intervalls anhand der Gleichung zu berechnen:
=(MAX($'Profit data'.C2:$'Profit data'.C214)-MIN($'Profit data'.C2:$'Profit data'.C214))/(1+3,222*LOG10(ANZAHL('GBPUSDH1-Metaquotes-demo'.$N$4:'GBPUSDH1-Metaquotes-demo'.$N$6038)))
Ich habe diese Gleichung in die Zelle 'Variables'.E7 gestellt und sie "Intervall" genannt. Das Intervall erwies sich als zu groß. Es war für mich unklar, wie Wahrscheinlichkeiten im Allgemeinen verteilt sind, also teilte ich es durch 4. Die endgültige Zahl — 344 — erwies sich für meine Zwecke als akzeptabler.
Im Blatt'Profit data' kopierte ich die erste Zahl aus der sortierten Liste nach F2:
=C2
Alle anderen Zellen habe ich mit der Gleichung gefüllt:
=F2+Interval
Die Zellen wurden ausgefüllt, bis der letzte Wert den maximalen Wert der Position überschritten hat.
G2 Zelle enthält die folgende Formel:
=ZÄHLENWENNS('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;">="&F2;'GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;"<"&F3)/ANZAHL('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038)
ZÄHLENWENNS erlaubt (im Gegensatz zu ZÄHLENWENN) die Annahme mehrerer Bedingungen, die mit dem "UND"-Operator kombiniert werden. Der Rest ist das Gleiche.
Wenn diese beiden Reihen konstruiert sind, wollen wir sofort ihre grafische Darstellung sehen. Glücklicherweise lässt sich das mit jedem Tabellenkalkulationsprogramm erreichen.
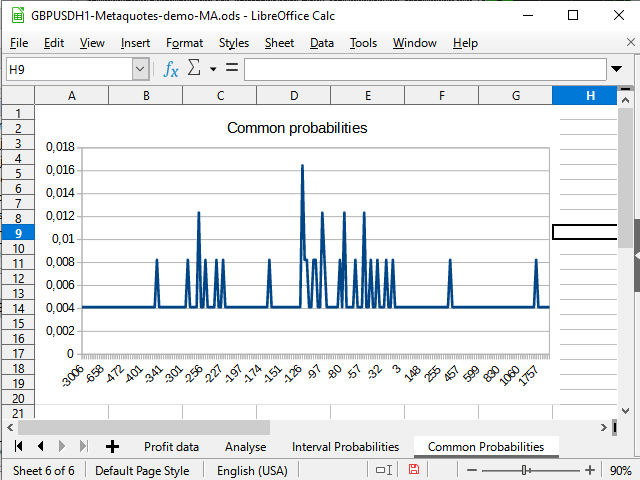
Abbildung 14. "Unmittelbares" Wahrscheinlichkeitsverteilungsdiagramm
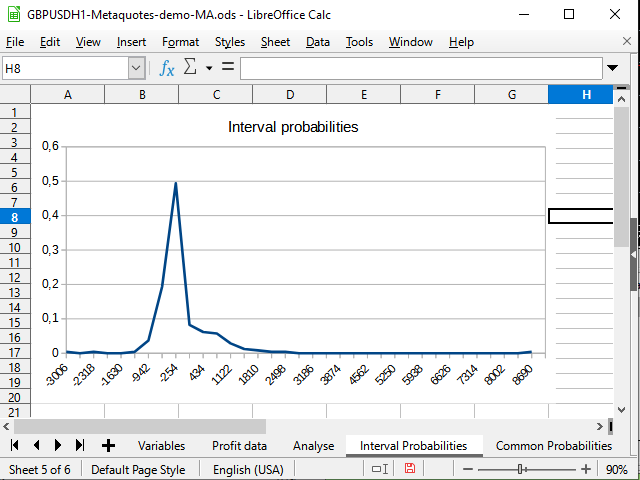
Abbildung 15. Das Diagramm der Intervallverteilungen der Wahrscheinlichkeiten der geschlossenen Positionen
Abbildung 14 demonstriert den negativen Versatz in der Wahrscheinlichkeitsdichte. Abbildung 15 zeigt eine deutlich sichtbare Spitze von -942 bis 2154 und einen Spike (eine Position) bei 8944.
Ich glaube, dass das Analyseblatt keine besonderen Schwierigkeiten bereiten wird (wenn man bedenkt, was alles analysiert wurde).
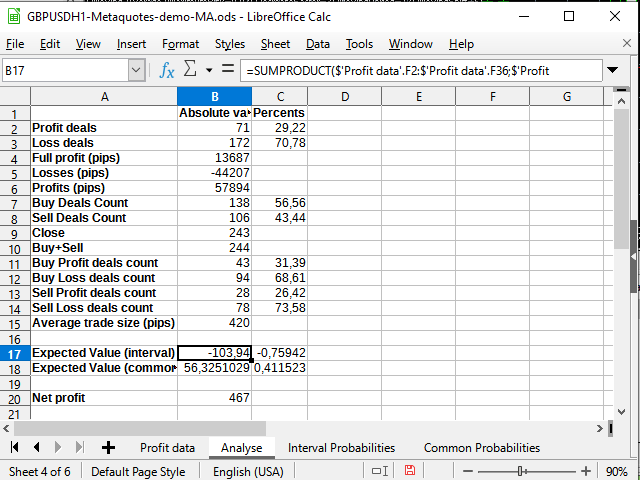
Abbildung 16. Einige statistische Berechnungen
Das einzig Neue hier ist die Verwendung der Funktion Summenprodukt, die zwei Intervalle als Parameter akzeptiert und die Summe der Produkte der Glieder dieser Intervalle zurückgibt (zum Beispiel die erste Zeile zur ersten Zeile, die zweite zur zweiten und so weiter). Ich habe diese Funktion verwendet, um den erwarteten Gewinn zu berechnen. Ich habe mich entschieden, keine komplexeren Integrationsmethoden anzuwenden.
Der erwartete Payoff ist deutlich geringer als der erzielte Gewinn und schwankt prozentual um 0.
Die Strategie funktioniert also, kann aber unter sehr großen Drawdowns leiden. Wahrscheinlich funktioniert sie perfekt während sehr starker Trends (ein Anstieg von ~9000 Pips würde recht interessant erscheinen, wenn er nicht so einsam wäre), jedoch wird died Seitwärtsbewegung höchstwahrscheinlich seinen Tribut fordern. Die Strategie braucht eine ernsthafte Überarbeitung, entweder durch die Einführung von Pending Orders, z.B. Take Profits (von ca. 420-500 Pips), oder einige Trendfilter. Verbesserungen erfordern zusätzliche Forschung.
Ausführen der Strategie im Tester
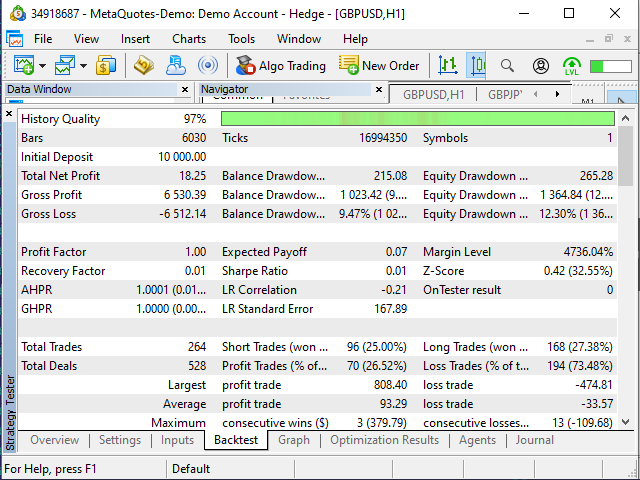
Abbildung 17. "Examples\Moving Average" EA-Testergebnisse
Um ehrlich zu sein, haben mich die Ergebnisse des EA überrascht. Die Tatsache, dass er Positionen dort eröffnete, wo die Tabelle es vorschlug, sie zu schließen, und umgekehrt, kann wahrscheinlich als normal angesehen werden, da seine Entscheidungen auf mehr oder weniger Daten beruhen könnten (zum Beispiel beginnt in meiner Tabelle der 25.11.2019 um 19:00 Uhr, während ich dem EA die Aufgabe gab, vom Tagesanfang zu starten).
Ich war mehr von der Tatsache überrascht, dass einige Positionen wie folgt aussahen...
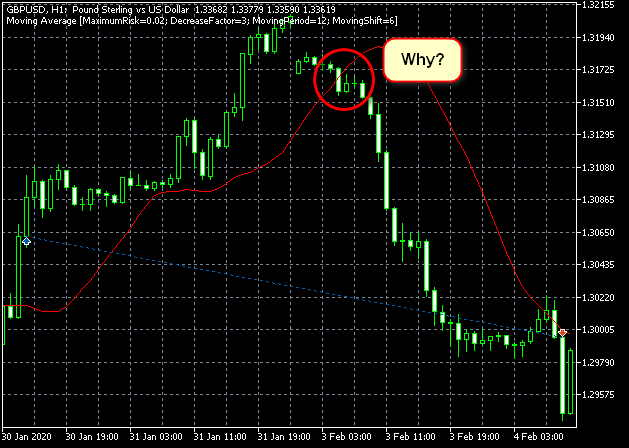
Abbildung 18. Kann mein Verständnis des Algorithmus falsch sein? Oder stimmt etwas mit dem Tester nicht?
Wahrscheinlich habe ich einfach nicht gut genug gesucht und den Grund für ein solches Verhalten im Algorithmus nicht gefunden.
Die zweite seltsame Tatsache war, dass der EA 20 Positionen mehr machte, als es meine Tabelle ermittelte. Aber nichtsdestotrotz sind die Ergebnisse nahe den meinen, so seltsam es auch erscheinen mag.
| EA im Tester | Tabelle |
|---|---|
| Gewinnerwartung — +0,07 (fast 0) | Gewinnerwartung — -0,76 - +0,41 (schwankt um 0) |
| Gewinner/Verlierer — 26,52%/73,48% | Gewinner/Verlierer — 29.22%/70.78% (wenn man den Unterschied von 8% in der Anzahl der Positionen bedenkt, kann der Unterschied von 3% hier als unbedeutend angesehen werden) |
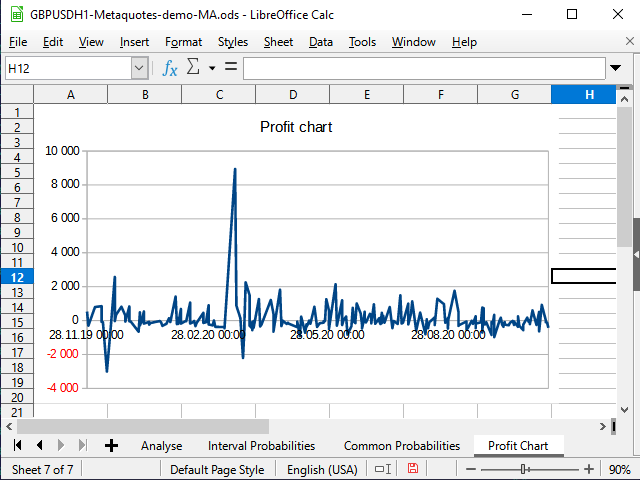
Abbildung 19. Tabelle Gewinnkurve
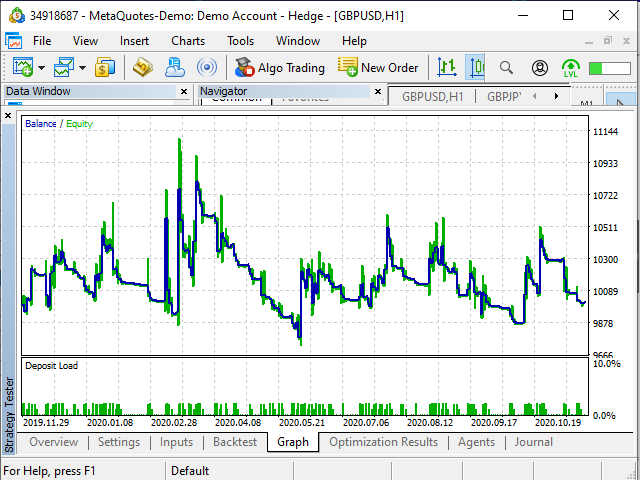
Abbildung 20. Saldenkurve des Testers
Die Erstellung der Tabelle und das Herumbasteln an den Zahlen hat etwa eine halbe Stunde gedauert. Statt einen EA zu entwickeln, entschied ich mich, einen vorgefertigten zu verwenden. Es dauerte etwa 10 Minuten, um den Algorithmus in groben Zügen herauszufinden. Es gibt jedoch keinen Grund, einen neuen EA zu schreiben, um zu verstehen, dass ich ihn wahrscheinlich nicht benutzen werde... Einen EA zu entwickeln ist nur dann sinnvoll, wenn ich merke, dass die Strategie es wert ist. Außerdem bevorzuge ich im Moment den manuellen Handel :-)
Schlussfolgerung
Ich glaube, Tabellenkalkulationen sind ein sehr gutes Werkzeug zum Testen und Entwickeln von Strategien, besonders für diejenigen, die keine Programmierkenntnisse haben, sowie für diejenigen, die schnell einen Prototyp erstellen und ihn anschließend in MQL umwandeln wollen.
Natürlich ähneln die Gleichungen des Tabellenkalkulationsprozessors manchmal einem Programmcode und die Formatierung ist dort visuell weniger klar.
Aber die Übersichtlichkeit von Tabellenkalkulationen, die Möglichkeit, neue Ideen sofort zu testen, das Hervorheben von betroffenen Zellen, Diagramme jeder Art usw. machen Tabellenkalkulationen zu einem unverzichtbaren Werkzeug.
Wenn Sie ein Protokoll der Transaktionen in einer Tabelle führen oder in der Lage sind, es zu importieren, dann können Sie mit Hilfe von Tabellenkalkulationsprogrammen Ihre Strategie leicht verbessern und Fehler in Ihrem Handel erkennen.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/8699
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Neuronale Netze leicht gemacht (Teil 8): Attention-Mechanismen
Neuronale Netze leicht gemacht (Teil 8): Attention-Mechanismen
 Brute-Force-Ansatz zur Mustersuche (Teil II): Immersion
Brute-Force-Ansatz zur Mustersuche (Teil II): Immersion
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Oleh Fedorov,
Vielen Dank, dass Sie diesen Artikel geschrieben haben. Ich bin 75+ und habe Grundkenntnisse in Excel. Aber aufgrund meiner mehr als 35-jährigen Handelserfahrung verstehe ich Datensätze und wie man sie für eine Wahrscheinlichkeitsstudie verwendet.
Wir sind eine Gruppe älterer Menschen, die zum Spaß und um den Verstand am Leben zu erhalten, mit kleinen Konten handeln. Das Erstellen und Umsetzen von Ideen aus einer Wahrscheinlichkeitsstudie hält uns aktiv und glücklich.
Deshalb begrüße ich Ihren Artikel. Großes Lob an Sie.
1. Können Sie mir bitte ein Tool zur Generierung von MT5-Historiendaten in einem Format zur Verfügung stellen, das ich verwenden kann, um Daten wie in einer Tabellenkalkulation zu generieren.
Derzeit, wenn der Indikator hat Export-Taste, bin ich in der Lage, csv-Datei, die ich speichern Sie es als Excel-Tabelle und tun Analyse zu generieren.
Mir wurde gesagt, dass es einen csv-machenden mql-Indikator gibt, der die Logik jedes anderen Indikators verwenden kann und csv-Daten in einer vorgefertigten Formatdatei erzeugt, die modifiziert werden kann, um neue Tabellenkalkulationsspalten zu erstellen.
Können Sie mir bitte mitteilen, wo ich diesen Indikator kaufen kann?
2. Ich möchte Wahrscheinlichkeitsstudien durchführen, indem ich Heatmaps wie diese in Excel erstelle. Können Sie dies bitte in Ihrem neuen Artikel unterrichten?
Beispiel: Ich möchte eine Heatmap wie diese erstellen. Wie kann ich nach der Generierung einer csv-Datei durch einen Indikator die Datei Schritt für Schritt in Excel konvertieren, filtern und Heatmaps oder andere Berichte wie die angehängte Datei erstellen?
Nochmals vielen Dank