
采用 CatBoost AI 预测 Renko 柱

引言
我的书房里一片静谧,只有显示器屏幕散发着微光。MT5 终端不断推送最新的分笔数据,我编写的算法有条不紊地将混沌的市场行情,转化为规整的Renko柱体系。凌晨三点,正是真正的交易策略诞生的时刻。我摸了摸未刮的下巴,抿了一口早已凉掉的咖啡 —— 我最爱的黑咖啡。模型 59.27% 的准确率,已是一场胜利。对于那些深知金融市场不可预测性的人而言,这是实打实的成就。
当传统分析束手无策时
近十年前,我刚进入市场时,坚信技术分析就是交易者的 “圣经”。我绘制支撑位与阻力位、观察均线交叉、寻找 RSI 与 MACD 背离,但年复一年,这些方法的有效性不断下降。市场在变,高频交易算法重塑了市场本质,经典分析方法再也无法带来曾经的优势。
有一周交易业绩格外糟糕,之后我问自己:难道上世纪写成的所有技术分析书籍,如今都只是消遣读物?这个问题让我彻底重构了交易思路,并最终打造出基于机器学习的Renko柱预测系统。
Renko柱 —— 交易者的数字 “禅境”
我第一次见到Renko图表,是在新加坡的一场研讨会上。一位要求我匿名的日本交易者,向我展示了他的交易终端 —— 界面上并非常见的 K 线,而是形态独特的矩形块。“这是Renko图表,” 他说,“它只呈现最重要的东西 —— 价格走势。”
在信息过载的世界里,Renko图表带来了数字 “禅境”—— 剔除噪音、时间因素,以及一切影响真实市场走势的杂音。只有当价格向上或向下波动达到指定幅度时,才会生成新的块。这种极简的设计里,蕴藏着惊人的力量。
我开始在多个品种上测试Renko图表。欧元 / 美元、英镑 / 美元、德国 DAX 指数、标普 500 指数 —— 在所有品种上,Renko图表都能让我更清晰、直观地看清市场结构。但人工分析极其耗时,而时间永远是交易者最稀缺的资源。于是,我转向了机器学习。
CatBoost—— 征服全球市场的算法
算法的选择,与交易策略的选择同等重要。在测试过数十种机器学习模型后,我选定了 CatBoost—— 由俄罗斯 Yandex 公司开发的梯度提升算法。第一次运行,我就认定了它。
# Initialize the CatBoost model params = { 'iterations': 300, 'learning_rate': 0.05, 'depth': 5, 'loss_function': 'Logloss', 'random_seed': 42, 'verbose': False } model = CatBoostClassifier(**params) model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=30, verbose=False)
CatBoost 不仅能很好地处理类别型特征(这对分析Renko柱形态至关重要),还具备强抗过拟合能力,且运算速度足够快,可每天用最新数据重新训练。
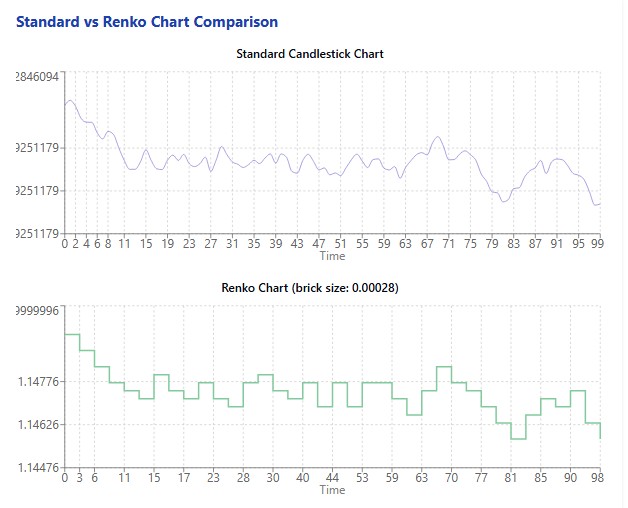
我的实验从下载欧元 / 美元 60 天数据开始 —— 超过 12000 根 5 分钟 K 线。这些数据被转化为 11578 根Renko柱,通过算法算出的最优块大小为 0.00028 个价格单位。特征工程处理后,得到 11572 条样本用于模型训练。
终于,决定性的时刻到来:用处理好的数据启动 CatBoost 模型训练。
数据揭示真相:实验结果
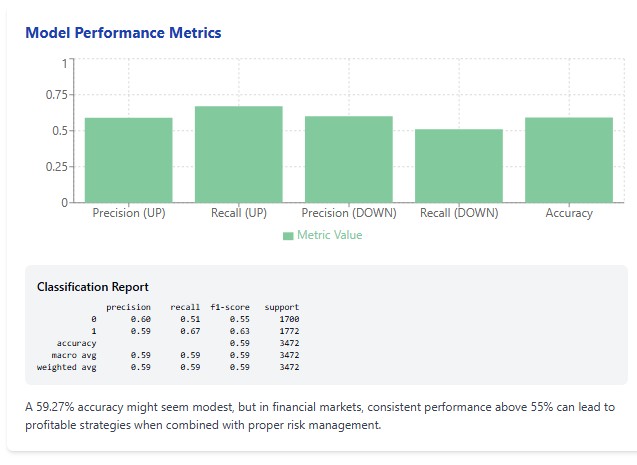
当算法完成训练、看到结果的那一刻,我豁然开朗。模型在测试集上的准确率达到59.27%。对交易新手而言,这个数值或许显得平平无奇。但对熟悉金融市场残酷交易统计规律的人来说,这是极其出色的成绩。
值得一提的是密歇根大学的一项著名研究:多数主动管理型基金,都无法跑赢简单的 “买入并持有” 策略。这些基金聘请了拥有博士学位的顶尖分析师,还能获取内幕信息。对比之下,59.27% 的准确率不仅优秀,堪称惊艳。
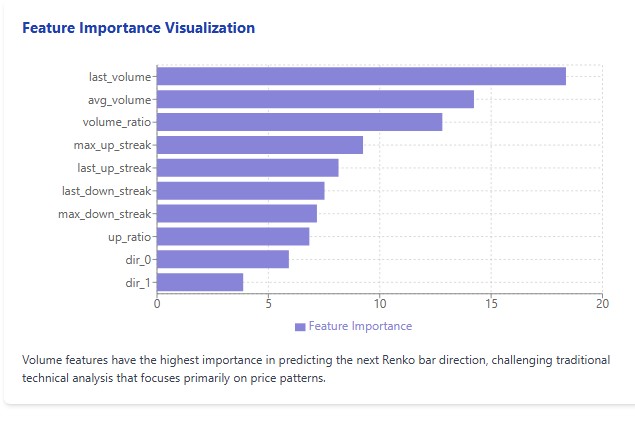
但更令人意外的是特征重要性分析结果。与所有技术分析经典理论相反,成交量指标远比价格形态重要。最新成交量(重要度 18.36)、平均成交量(14.23)、成交量比率(12.81)占据前三。紧随其后的是连续价格波动相关参数。
我曾在某知名社交平台上,几次看到一位成功交易者说:交易的 “圣杯”,在于把成交量拆分到Renko块与成交量簇中。或许这些结果绝非偶然,而是大有深意?
Renko柱的运用之道
使用Renko图表的第一步,是确定最优块大小。这就像调试显微镜:放大倍数太低,看不清细节;倍数太高,会扭曲整体格局。Renko块大小,相当于我们观察市场的 “分辨率”。
# Create Renko bars with adaptive block size def create_renko_bars(df, brick_size=None): if brick_size is None: # Calculate ATR to determine block size df['tr'] = np.maximum( df['high'] - df['low'], np.maximum( np.abs(df['high'] - df['close'].shift(1)), np.abs(df['low'] - df['close'].shift(1)) ) ) df['atr'] = df['tr'].rolling(window=14).mean() brick_size = df['atr'].mean() * 0.5 print(f"Renko block size: {brick_size:.5f}") # Create Renko bars renko_bars = [] current_price = df.iloc[0]['close'] # ... the rest of the code
经过大量实验,我得出结论:确定块大小的最佳方法是使用ATR(平均真实波幅)指标。这种方法可让块大小自适应品种当前的波动率。
以欧元 / 美元为例,算法算出的最优块大小为0.00028 个价格单位,约等于2.8 点。乍看之下数值很小,但正是这种粒度,能帮我们捕捉有效行情、过滤市场噪音。
生成Renko柱不只是对价格数据做机械转换。它是一门从噪音中提取信号、在海量波动里分离出有效行情的艺术。当我看到图表上转换后的数据时,一幅清晰无比的市场图景展现在眼前 —— 红绿相间的阶梯状块体,剔除了时间因素造成的扭曲,真实反映价格走势。
特征构建:预测真正关键的因素
任何机器学习模型的效果,都高度依赖特征的质量与相关性。为预测下一根Renko柱的方向,我构建了一套多层级特征体系,同时兼顾走势历史与成交量特征。
# Prepare features for the model def prepare_features(renko_df, lookback=5): features = [] targets = [] for i in range(lookback, len(renko_df) - 1): window = renko_df.iloc[i-lookback:i] feature_dict = { # Directions of the last n bars **{f'dir_{j}': window['direction'].iloc[-(j+1)] for j in range(lookback)}, # Movement statistics 'up_ratio': (window['direction'] > 0).mean(), 'max_up_streak': window['consec_up_streak'].max(), 'max_down_streak': window['consec_down_streak'].max(), 'last_up_streak': window['consec_up_streak'].iloc[-1], 'last_down_streak': window['consec_down_streak'].iloc[-1], # Volume 'last_volume': window['volume'].iloc[-1], 'avg_volume': window['volume'].mean(), 'volume_ratio': window['volume'].iloc[-1] / window['volume'].mean() if window['volume'].mean() > 0 else 1 } features.append(feature_dict) # Direction of the next bar (1 - up, 0 - down) next_direction = 1 if renko_df.iloc[i+1]['direction'] > 0 else 0 targets.append(next_direction) return pd.DataFrame(features), np.array(targets)
首先,我纳入了最直观的特征 ——最近几根Renko柱的方向。随后,我添加了统计指标 ——上涨与下跌柱的比例、同一方向连续波动的长度、最大连续序列。最后,我加入了成交量指标 ——上一根柱的成交量、周期内平均成交量、当前成交量与均值的比值。
令我意外的是,成交量指标对预测的作用最为显著。这彻底改变了我对价格分析的认知。多年来,我和大多数交易者一样,专注于 K 线形态、图形与趋势线。而答案一直都是成交量—— 一个因外汇市场去中心化特性而常被忽视的指标。
最终特征集包含14 个参数,在模型复杂度与预测能力之间达到了最优平衡。特征过多会导致过拟合,特征过少则会欠拟合。
预测实战:从理论到应用
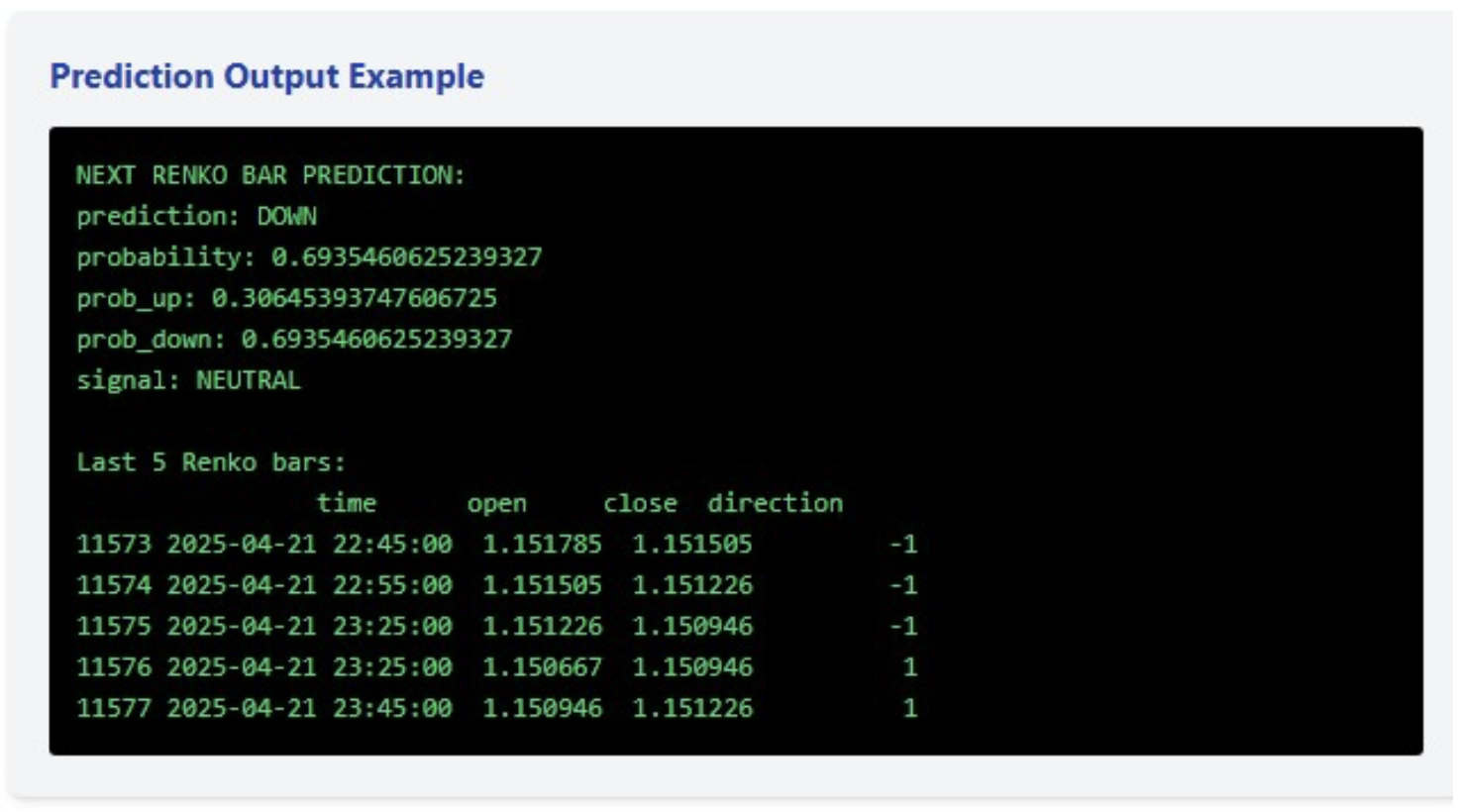
构建完成的模型不仅能输出下一根柱方向的二分类预测,还能给出该走势的发生概率。在上一个案例中,模型预测下跌的概率达69.35%,这已是相当可靠的预测,但尚未达到触发交易信号的标准(我将信号阈值设为 75%)。
# Forecast the next bar def predict_next_bar(model, renko_df, lookback=5, feature_names=None): if len(renko_df) < lookback: return {"error": "Insufficient data"} window = renko_df.iloc[-lookback:] feature_dict = { **{f'dir_{j}': window['direction'].iloc[-(j+1)] for j in range(lookback)}, 'up_ratio': (window['direction'] > 0).mean(), 'max_up_streak': window['consec_up_streak'].max(), 'max_down_streak': window['consec_down_streak'].max(), 'last_up_streak': window['consec_up_streak'].iloc[-1], 'last_down_streak': window['consec_down_streak'].iloc[-1], 'last_volume': window['volume'].iloc[-1], 'avg_volume': window['volume'].mean(), 'volume_ratio': window['volume'].iloc[-1] / window['volume'].mean() if window['volume'].mean() > 0 else 1 } X_pred = pd.DataFrame([feature_dict]) # Make sure all the features are present if feature_names: for feature in feature_names: if feature not in X_pred.columns: X_pred[feature] = 0 X_pred = X_pred[feature_names] prob = model.predict_proba(X_pred)[0] prediction = model.predict(X_pred)[0] return { 'prediction': 'UP' if prediction == 1 else 'DOWN', 'probability': prob[prediction], 'prob_up': prob[1], 'prob_down': prob[0], 'signal': 'BUY' if prob[1] > 0.75 else 'SELL' if prob[0] > 0.75 else 'NEUTRAL' }
然而,这套系统的真正价值并非单次预测,而是一整套完整的交易体系。最近的五根Renko柱呈现出有趣的动态:连续三根下跌,随后两根上涨。这种微型上涨趋势,叠加下跌预测(概率较高但未达到信号标准),表明市场大概率处于盘整与观望状态。
正是这些时刻对交易而言最为危险,尽管下跌概率相对较高,系统仍准确识别了这一状态,未生成任何交易信号。
系统底层解析:架构设计
这套自研系统具有一个多层级机制,每个组件都在整体预测框架中承担专属职能。我们来看看这套架构的核心组成部分。
python# Main function def main(): # Get EURUSD data print("Load EURUSD data from MetaTrader5...") df = get_mt5_data(symbol='EURUSD', days=60) if df is None or len(df) == 0: print("Unable to retrieve data") return print(f"Loaded {len(df)} bars") # Create Renko bars print("Creating Renko bars...") renko_df, brick_size = create_renko_bars(df) print(f"Created {len(renko_df)} Renko bars") # Prepare features print("Preparing features...") X, y = prepare_features(renko_df) print(f"Prepared {len(X)} samples") # Train the model print("Training the model...") model, X_test, y_test = train_model(X, y) # Next bar forecast feature_names = X.columns.tolist() prediction = predict_next_bar(model, renko_df, feature_names=feature_names) print("\nNEXT RENKO BAR FORECAST:") for k, v in prediction.items(): print(f"{k}: {v}") # Info about the latest bars print("\nLast 5 Renko bars:") print(renko_df.tail(5)[['time', 'open', 'close', 'direction']])
系统的基础是MT5 数据获取模块。通过与 MT5 对接,我们能够近乎实时地获取最新市场数据。该模块采用官方 MT5 接口,确保了运行的可靠性与稳定性。
系统的第二层,是将标准时间 K 线转换为Renko柱。算法基于 ATR 计算最优块大小,并结合成交量与时间维度完成转换。该实现的核心特性在于:在Renko柱生成过程中直接计算连续波动及其特征,大幅提升了整个系统的运行效率。

系统的核心是特征生成与模型训练模块。在这一环节,每一根Renko柱都会被转化为一组数值特征,随后输入 CatBoost 算法。模型最优参数的选取通过交叉验证完成,同时兼顾金融时间序列的独特性。
最后,预测模块调用训练好的模型与最新数据,生成预测结果;当置信度达到设定阈值时,自动触发交易信号。
整套系统基于 Python 开发,使用了 numpy、pandas、MetaTrader5 以及 catboost 库。选择 Python,不仅因为开发便捷,更因其具备丰富的数据分析与结果可视化能力。
结论与展望:算法交易的未来
在完成Renko柱预测系统的研发与测试后,我得出了几项重要结论,或会颠覆你对算法交易的认知。
第一,传统技术分析方法的效率,已不及现代机器学习算法。59.27% 的准确率听起来或许并不惊人,但长期来看,该模型持续跑赢绝大多数技术指标。
第二,在预测市场走势方面,成交量指标的重要性远高于价格形态。这与许多经典交易教材相悖,却在真实数据的回测结果中得到了验证。
第三,Renko图表确实能够剔除价格数据中的噪音,让机器学习算法更精准地识别市场走势中的稳定规律。
但最重要的是,这一切仅仅是开始。我看到了这套系统巨大的升级潜力。未来,该系统不仅能纳入基本面数据、新闻事件以及社交媒体情绪分析,还可拓展至其他交易品种与时间周期。此外,通过构建模型集成体系,预测准确率有望得到进一步提升。
结论
算法交易领域正处于新一轮革命的前夜,而伦科图表与现代机器学习算法的结合,或会成为这场革命的核心驱动力之一。我邀请所有对该领域感兴趣的朋友,一同深入数据、算法与预测的世界。交易的未来已至 —— 它就是算法交易。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/17531
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

不能超过 63%。无论添加什么标志。63% 的外汇交易是一场惨败
我在 Midas(多模块,许多模块将其信号合并为一个信号)上获得了超过 75% 的收益。但是另一个问题出现了--信号一个月半一次)))),信号越可靠,出现的频率就越低......这就是为什么我在最近的机器人中开始忘记高胜率的原因,我尝试预测走势的深度,以 1:3、1:4 等比例承担获利风险。我在设置标记时,通过 DQN 为正确标记深度走势的模型提供奖金....,这最终导致了机器人 LSTM Europe。
我在 Midas(多模块,许多模块将其信号合并为一个信号)上获得了 75% 以上的收益。但是,另一个问题出现了 - 一个半月一次的信号)))),信号越可靠,出现的频率就越低......这就是为什么我在最近的机器人中开始忘记高利润率,我尝试预测走势的深度,以 1:3 或 1:4 等比例承担获利风险。我在设置标记时,通过 DQN 为正确标记深度走势的模型发放奖金....,最终形成了机器人 LSTM Europe。
75 on LTSM at lookback = 5 bars_ahead = 1,但这是用于二元交易,而非外汇交易。
人工智能在哪里?还是你把猫扑提升到那个级别了?
你应该做个测试什么的。58% 可以吗?准确率只是一个基准。主要指标是根据收到的信号进行测试的平衡性。
这没什么意思。