MQL5 中的奇异谱分析(SSA)

什么是 SSA?
MetaTrader 5(MT5)最新版本已将 OpenBLAS 运算库初步集成到核心向量与矩阵数据类型中。其中,奇异谱分析(SSA)相关的一系列方法尤为值得关注。本文将深入讲解 MQL5 中全新的 SSA 工具,拆解其在行情分析与预测中的使用方法。本指南旨在为希望充分发挥 SSA 分析潜力的交易者提供参考。我们将深入剖析 SSA 的核心方法,拆解其两步式分解与重构流程。更重要的是,我们会讲解新增的 SSA 向量方法各自的作用,并演示如何解读、最优组合其输出结果,以获取可执行的交易决策依据。
奇异谱分析是一种非参数化技术,专门用于时间序列数据的分析与预测。其核心目标是将时间序列分解为若干个可加分量,通常包含:缓慢变化的趋势项、各类周期项、以及残差噪声项。SSA 的显著特点是:对底层数据生成过程几乎不做预设假设。SSA 的理论基础融合了统计学与信号处理理论。本质上,SSA 基于谱分解原理,通过在重构嵌入空间中分析主成分,揭示时间序列的频率特征。你可以将其理解为专门适配时间序列数据的主成分分析(PCA):借助降维原理,挖掘被噪声或复杂交互关系掩盖的隐藏结构与规律。
MQL5 中的 SSA
在 MQL5 中,SSA 计算已原生集成为向量数据类型的方法,同时也在 Alglib 数学库中提供了实现。Alglib 版 SSA 的优势主要在于实时行情处理,而直接通过向量调用的全新 SSA 功能更适合探索性数据分析。注意:本文主要讲解实数运算相关用法,MQL5 也提供了等效的复数运算方法,使用逻辑一致,仅解读方式需适配复数域。
所有新增的向量 SSA 方法,第一个必填参数都是窗口长度。该参数决定了时间序列如何转换为更高维度的结构 ——轨迹矩阵。你可能会问:为什么需要构建高维结构? 答案就藏在 SSA 与 PCA 的关联中。要知道,PCA 是应用于多变量数据集的降维技术。而 SSA 会将单变量时间序列重构为类似多变量数据集的结构。实现方式是:将时间序列按等长片段排列为矩阵行。其中,每一行的长度由窗口长度参数定义。
举个例子:时间序列Y=[y1,y2,y3,y4,y5,y6],总长度 N=6。 如果设置窗口长度 L=3,就会生成如下轨迹矩阵。

矩阵的行数 R 计算公式:R=N−L+1。本例中:R=6−3+1=4。最终生成一个 R×L 维度的矩阵(本例为 4×3),这就是轨迹矩阵。该矩阵的反对角线上呈现出典型的汉克尔矩阵(Hankel Matrix)特征。构建轨迹矩阵是 SSA 方法的第一步。因此,窗口长度是 SSA 的核心参数:它直接决定轨迹矩阵的维度,进而显著影响谱分解的分辨率与分量分离效果。
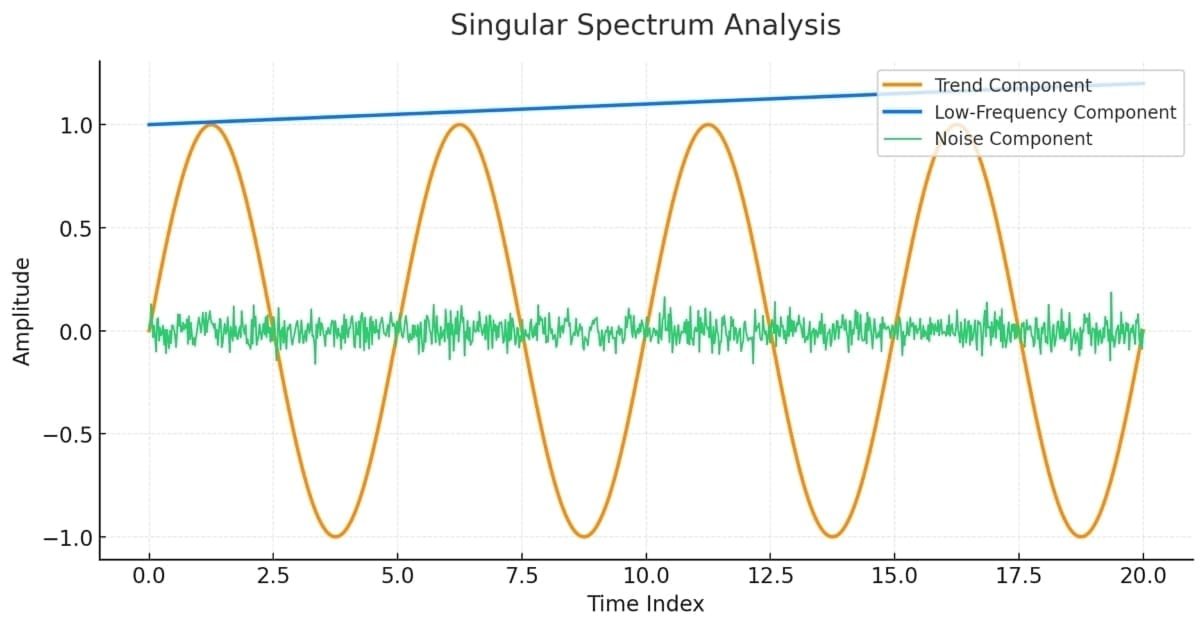
为了清晰讲解 SSA 的原理,我们将用一个确定性序列演示其应用,序列样式如下。

该序列由预设的可叠加分量构成:趋势项 + 两组周期项 + 随机噪声。将这些分量叠加后,会得到一段看似无规律的序列。SSA 的目标就是挖掘出这些隐藏的底层分量。实现方式是:对轨迹矩阵或其协方差矩阵进行分解,得到特征模态—— 和 PCA 原理一致,这些模态会揭示序列的主成分。
分量相对贡献度与累计贡献度
MQL5 向量方法SingularSpectrumAnalysisSpectrum() 会输出一个向量,代表序列各分量的相对贡献度。该向量内的实数总和为 1,数值按降序排列,表示每个分量的占比权重。这些贡献度对应矩阵分解计算出的特征值相对大小。
//--- vector relative_contributions; if(!full_process.SingularSpectrumAnalysisSpectrum(WindowLen,relative_contributions)) { Print(" error ", GetLastError()); return; } //--- relative_contributions*=100.0; vector cumulative_contributions = relative_contributions.CumSum();
计算相对贡献度的累加和,即可得到累计贡献度。通过这些数值,我们能快速确定:最少需要选取多少个分量,才能实现对原始序列的高精度拟合。相对贡献度的图表通常会呈现出明显的近似平台期,这表明部分分量的贡献度数值相近。这种数值相近性,通常意味着这些分量共同代表了同一个周期要素。
下图是我们示例序列的相对贡献度与累计贡献度图表。

图表显示:前两个分量分别贡献了序列总方差的约 68% 和 12%。

仅前五个分量,就占据了总方差的 98% 以上。相对贡献度图表呈现出独特的形态,清晰体现出前 5 个分量的主导地位。将主导分量与其余分量区分开的临界点,通常被称为拐点(肘点);低于该水平的分量被称为噪声基底。该临界点可粗略估算信号与噪声的分离边界。相对贡献度图表的另一个显著特征是:第二、第三个分量紧密聚集,与第四、第五个分量明显区分开。这表明这些成组的分量彼此相关,可能分别代表序列中独有的特征。
序列分量提取
完成对示例序列的分析后,我们已经明确了决定序列整体走势的主要分量。若要评估这些分量的规律性,将其可视化会是很有效的方式。此时,向量方法SingularSpectrumAnalysisReconstructComponents()就能发挥作用。该方法最核心的输出是分量序列矩阵。但需要注意:尽管 MQL5 官方文档说明矩阵的列代表估算的分量序列,但该方法实际是将每个分量序列存储为矩阵的行。此外,该方法的向量输出结果中,还包含序列表征矩阵分解后的原始特征值。
//--- matrix components; vector eigvalues; if(!full_process.SingularSpectrumAnalysisReconstructComponents(WindowLen,components,eigvalues)) { Print(" error ", GetLastError()); return; } //---
分量序列矩阵的行按照相对贡献度从大到小排列。因此,第一行对应的是最大特征值的分量,同时也是相对贡献度最高的分量。下图展示了示例序列的所有分解分量。

如果将其与原始分量的图表对比,你可能会发现一些偏差。这恰恰说明:SSA 分解并非绝对精确。该方法无法精准识别出序列的真实周期分量,只能对这些分量进行最优拟合与估算。不过,将所有独立的分量序列相加,最终可以还原出原始序列。
滤波处理
得到分量序列集合后,我们可以结合 SSA 分析结果,区分哪些分量代表底层有效信号,哪些代表非确定性噪声。如果我们的核心目标是提取主导周期,可以直接剔除相对贡献度较低的分量,从而生成滤波后的序列。这种操作的前提假设是:贡献度较低的分量均为掩盖主信号的噪声。
用户可以直接通过SingularSpectrumAnalysisReconstructSeries()方法对序列执行滤波操作。只需指定需要纳入滤波序列的主导分量数量即可。
//--- vector filtered; if(!full_process.SingularSpectrumAnalysisReconstructSeries(WindowLen,FilterComponents,filtered)) { Print(" error ", GetLastError()); return; }
SSA 方法通常擅长分离噪声,但其效果取决于数据中噪声的类型。仅通过剔除低贡献度分量,往往无法彻底分离噪声。这也会直接影响有效信号、趋势或特定周期分量的提取效果。对这些分量的解读,通常需要通过显著性统计检验进行验证。影响特定分量分离的另一个因素是强趋势:趋势的主导性可能会掩盖数据中其他低频震荡信号。

预测
SSA 方法最实用的功能之一就是时间序列预测。该功能由SingularSpectrumAnalysisForecast()方法实现。时间序列完成分解与重构后,预测步骤通常采用递归预测算法。该算法基于重构分量普遍满足的线性递推关系(LRR)实现。其核心假设是:这些重构分量遵循可预测的规律模式。算法会根据奇异向量和重构序列计算出一组系数。这些系数代表了重构信号中历史数据与未来数据的线性关系。预测新数据点时,算法会对重构序列前窗口长度个数值进行线性加权组合(权重为计算出的系数)。该过程会迭代执行,从而生成连续的多步预测值。
//--- vector forecast; if(!full_process.SingularSpectrumAnalysisForecast(WindowLen,FilterComponents,ForecastLen,forecast)) { Print(" error ", GetLastError()); return; } //---
显而易见,这类预测假设历史模式会在未来完全重现。当然,在现实世界的时间序列中,这种情况几乎不可能成立。尽管如此,SSA 依然具备实用价值 —— 通过聚焦具有规则波形的特定分量,能让复杂行情过程更具可预测性。
参数选择与预处理
我们已经明确,SSA 对序列的分解无法提取出时间序列的真实周期分量。它仅能提取分量的估算值。这是该方法的一个明显局限性,而SSA 对窗口长度的高度敏感性,会进一步加剧这一局限。窗口长度的选择可根据分解目标确定。如果核心目标是分离趋势,窗口长度越大越好。如果更关注震荡分量,则需要匹配震荡周期;例如:寻找周期为 20 的周期分量时,可将窗口长度设为 20。
学术文献中的实证研究表明:窗口长度 L 决定了震荡信号的解析范围,可识别的周期区间为 L/5 至 L。问题在于,目标分量的周期通常无法提前预知,因此需要大量试错调整。通用经验法则:将窗口长度设置为目标序列长度的 1/2 到 2 倍之间。更长的窗口长度用于放大慢变分量(趋势),而更短的窗口长度用于捕捉更精细的细节。
除了对窗口长度敏感,使用者还需注意:时间序列中的强趋势会影响分解结果。强趋势会掩盖序列中的其他低频分量。解决该问题的核心方法:在执行 SSA 之前,对原始序列进行去趋势处理。可采用的预处理方式包括中心化或移除线性趋势,代码示例如下:
//--- if(m_detrend) { vector reg = m_buffer.LinearRegression(); m_buffer -= reg; } //---
在滤波或预测时,确定需要选择多少个分量,可以借助相对贡献度与累计贡献度图表。在相对贡献度图表中,核心是找到肘点—— 用于区分信号与噪声。图表中,信号对应的点会与逐步趋近于零的噪声点形成明显分界。观察分解过程中原始特征值的衰减曲线,也能看到同样的分界特征。另一种可行方案:设定一个目标方差占比(通常为 85%~95%),然后在累计贡献度序列中,找到满足该占比所需的分量数量。
分量分组
我们知道,SSA 分解无法完美还原序列的真实底层分量 —— 这一点在简单示例中已经得到验证。我们得到的是一组近似真实分量的估算序列。我们只需要确定如何组合这些估算分量,就能更清晰地识别出定义数据规律的真实要素。这可以通过构建分量序列的加权相关矩阵实现。加权相关矩阵用于衡量每一对分量序列偏离正交状态的程度。如果一对分量序列完全正交,则它们大概率是相互独立的分量。
相关性越高,说明这一对分量越应该合并。下方代码片段展示了一个通用方法:输入分量序列矩阵与 SSA 分解的窗口长度参数,计算加权相关矩阵。该函数声明在文章附带的 ssa.mqh 头文件中。
//+------------------------------------------------------------------+ //| component correlations | //+------------------------------------------------------------------+ matrix component_corr(ulong windowlen,matrix &components) { double w[]; ulong fsize = components.Cols(); ulong r = fsize - windowlen + 1; for(ulong i = 0; i<fsize; i++) { if(i>=0 && i<=windowlen-1) w.Push(i+1); else if(i>=windowlen && i<=r-1) w.Push(windowlen); else if(i>=r && i<=fsize-1) w.Push(fsize-i); } vector weights; weights.Assign(w); ulong d = windowlen; vector norms(d); matrix out = matrix::Identity(d,d); for(ulong i = 0; i<d; i++) { norms[i] = weights.Dot(pow(components.Row(i),2.0)); norms[i] = pow(norms[i],-0.5); } for(ulong i = 0; i<d; i++) { for(ulong j = i+1; j<d; j++) { out[i][j] = MathAbs(weights.Dot(components.Row(i)*components.Row(j))*norms[i]*norms[j]); out[j][i] = out[i][j]; } } return out; }
下方展示了示例序列前六大分量的分量相关系数矩阵局部片段。
")
图表中可以看到,索引 (1:2) 对应的两个分量高度相关,印证了第 2、3 号分量存在关联性,而索引 (3:4) 则反映第 4、5 号分量之间的关联关系。该分析结论与前文相对贡献度图表的目视观察结果完全吻合。据此可以推断:这两组关联分量,对应示例序列中的周期性成分。而排名首位的独立分量特征明显,大概率代表趋势项。结合前文累计贡献度可知,这五个分量合计贡献占比超过 98%,其余分量则基本可判定为噪声。
价格序列分解实操演示
本节展示一款以EA 智能交易系统实现的应用案例,可对任意一段价格样本进行分量分解与可视化查看。该工具搭载图形交互界面,支持自定义交易品种、时间周期与价格序列长度,一键完成序列展示与 SSA 分解。同时提供分解前去趋势可选功能,也可按需查看相对贡献度、累计贡献度图表。下图为该工具运行截图:以欧美货币对(EURUSD)收盘价为例,底部图表展示其中一组分解后的独立分量。

结论
本文系统介绍了 MQL5 中全新的奇异谱分析(SSA)工具,重点讲解了向量数据类型基于 OpenBLAS 的新增底层能力。文中对 SSA 分析方法进行了通俗完整的概述,刻意弱化复杂数学推导,侧重实操应用。总而言之,奇异谱分析是量化交易者与数据分析人员的实用工具,但想要充分发挥其效用,必须合理选择参数,并理解其运行特性与局限性。本文提及的所有完整代码,均附于文末可供下载使用。
| 文件名 | 文件描述 |
|---|---|
| MQL5/include/ssa.mqh | 该头文件包含了分量分组章节中所描述的、用于计算分量相关系数的函数定义。 |
| MQL5/scripts/SSA_Filtered_Demo.mq5 | 该脚本用于演示基于 SSA 的滤波功能。 |
| MQL5/scripts/SSA_Decomposition_Demo.mq5 | 该脚本用于演示基于 SSA 的序列分解功能。 |
| MQL5/scripts/SSA_ComponentContributions_Demo.mq5 | 该脚本用于演示分量相对贡献度的可视化展示。 |
| MQL5/scripts/SeriesPlot.mq5 | 该脚本用于绘制本文所述示例序列的各分解分量图表。 |
| MQL5/experts/SSA_PriceDecomposition.ex5 | 该 EA 程序可用于展示任意价格序列的分解结果。 |
| MQL5/experts/SSA_PriceDecomposition.mq5 | 上述 EA 的源代码文件。 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/18777
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

在很短的时间内看到关于同一主题的如此密切相关的文章(即使其中一篇文章最初是用俄语写的),真是奇怪。
文章
一维奇异谱分析
Evgeny Chernish, 04/23/2025 11:23
这是一种分析时间序列的有效方法,可将序列的复杂结构分解为趋势、季节(周期)波动和噪声等简单成分。