
Гипотеза случайности: поиск скрытых паттернов в ценовых рядах

Введение
В статистических задачах исходные данные часто рассматривают как случайную выборку из некоторого распределения, то есть считают компоненты вектора данных независимыми и одинаково распределенными случайными величинами. Во многих задачах это допущение не вызывает сомнений, так как вытекает из характера самих данных. Но иногда это исходное предположение само нуждается в проверке и рассматривается как статистическая гипотеза, называемая гипотезой случайности.
Классический пример — контроль качества генераторов псевдослучайных чисел (ГПСЧ). Программные алгоритмы создают последовательности, которые должны быть статистически неотличимы от истинно независимых и равномерно распределенных величин на единичном отрезке [0,1]. Поэтому требуется осуществлять контроль за качеством таких ПСЧ, что и сводится в итоге к проверке гипотезы случайности.
Проверка этой гипотезы на котировках финансовых инструментов может дать важную информацию аналитикам, которые строят торговые системы, основанные на обнаружении статистически значимых отклонений от гипотезы эффективного рынка. В статье рассматривается проверка гипотезы случайности с помощью метода хи‑квадрат. Это универсальный и хорошо изученный метод, который применим для проверки различных статистических гипотез, основанный на сравнении фактических и ожидаемых частот событий. А самое главное, его относительно просто реализовать на практике.
Постановка задачи
Итак, пусть у нас задана последовательность из n случайных величин (ξ1, ξ2, ..., ξn), которые принимают значения из некоторого конечного множества (алфавита) E = {1, 2, ..., N}, и мы хотим проверить гипотезу, что эти величины независимы и равномерно распределены, то есть P{ξi=j} = 1/N, j = 1, ..., N, i = 1, 2, ..., n. Это нулевая гипотеза об идеальном генераторе случайных чисел.
Одним из подходящих методов для проверки такой гипотезы является метод хи-квадрат. Он основывается на подсчете так называемых s-цепочек (s-грамм или s-кортежей) в случайной последовательности. s-цепочкой называется любая подпоследовательность последовательности случайных величин, состоящая из s подряд идущих ее членов. Например: (ξ1, ..., ξs), (ξ2, ..., ξs+1), …, (ξn-s+1, ..., ξn), всего n - s + 1 цепочек. Вместо того чтобы рассматривать частоты отдельных исходов в последовательности, мы рассматриваем частоты цепочек исходов некоторой фиксированной длины s ≥ 1, причем цепочки должны быть перекрывающимися.
Пусть теперь i_ = (i1, …, is) — любая s-мерная комбинация элементов множества E, тогда всего таких комбинаций будет N^s. Например, возьмем N = 2 (E = {0,1}), s = 2, тогда получим 4 комбинации = {(0,0), (0,1), (1,0), (1,1)}. Частоты s-цепочек и (s+1)–цепочек считаются по следующим формулам:

Где, I(A) — индикатор события A.
При этом практически можно вычислять только частоты (s+1)–цепочек {vi_j} (их число равно N^(s+1)), так как:

И хотя так вычисляемая сумма частот s-цепочек может отличаться на единицу от истинного значения, но на результат статистики хи-квадрат это не сказывается, зато позволяет сократить вычисления собирая только (s+1)-цепочки.
Для проверки нулевой гипотезы случайности с помощью статистики хи-квадрат сравнивают эмпирические частоты vi_j с гипотетическими (vi_/N):
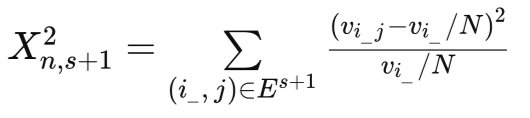
где (i_j) — конкретная комбинация (s+1) цепочек.
Объяснение работы алгоритма
Чтобы понять, есть ли в данных некая закономерность, нам нужно сравнить то, что мы видим в реальности, с тем, что должно было быть в случае идеального хаоса. Если мы возьмем в качестве модели идеального хаоса симметричную монетку (множество состояний состоит из 2 точек E = {0,1}) тогда:
- вероятность появления любого состояния:
P(j) = 1/N = 1/2
- вероятность события увидеть любую s-мерную комбинацию i_ = (i1, …, is):
P(i_) = 1/N^s
- математическое ожидание частоты данного события:
Evi_ = n/N^s
- вероятность увидеть после s-мерной комбинации i_ состояние j (по правилу умножения вероятностей независимых событий ):
P(i_, j) = P(i_) * P(j) = 1/N^s * 1/N = 1/N^(s+1)
Допустим мы берем конкретную последовательность из s свечей, например, две белые свечи подряд (1,1) и смотрим, что произошло сразу за ними. Предположим, такая ситуация встретилась в истории vi_ = 1000 раз. Из них 600 раз следующая свеча была белой (j=1), а 400 раз — черной (j=0), поэтому эмпирические частоты vi_j равны vi_j(1,1,1) = 600, vi_j(1,1,0) = 400.
Если рынок абсолютно случаен и не помнит прошлого, то после любого паттерна, независимо от того, как часто он встречался сам по себе в выборке, вероятность роста или падения должна оставаться равной 0,5.
В нашем примере паттерн vi_(1,1) встретился 1000 раз. Таким образом, из 1000 случаев мы ожидаем увидеть ровно по 500 исходов в каждом направлении. Величина vi_ * 1/N — это условная ожидаемая частота.
Суммируя нормированные квадраты отклонений реальных частот от этих ожиданий по всем возможным комбинациям (i_j), мы получаем итоговое число — статистику хи-квадрат. Эта статистика сама по себе является случайной величиной, так как зависит от конкретной выборки данных.
Американский математик Биллингсли в своей работе Statistical Inference for Markov Processes (1961) доказывает, что при условии справедливости нулевой гипотезы, данная статистика имеет предельное (то есть для больших выборок) распределение хи-квадрат с N^s*(N-1) степенями свободы.
Критерий, задаваемый при уровне значимости alpha, критической областью {Xn, s+1 > Chi2(1-alpha), N^s*(N-1)}, состоятелен против альтернатив, при которых последовательность случайных величин представляет собой однородную эргодическую цепь Маркова порядка s.
Вспомним, что марковская цепь называется однородной, если переходные вероятности в цепи не зависят от времени. Это понятие своего рода аналог стационарности в теории стационарных случайных процессов, когда предполагается неизменность статистических характеристик процесса во времени. Поэтому это надо учитывать, когда мы имеем дело с нестационарными процессами, искать участки квази-стационарности, где как мы считаем характеристики процесса не меняются существенно, выделять однородные участки временного ряда, допустим в пределах одной торговой сессии (Азия, Европа, Америка) и т.д.
Цепь Маркова называется эргодической, если существуют пределы вероятности комбинаций i_ = (i1, …, is) не зависящие от начального распределения цепи. При этом для эргодичности цепи достаточно, чтобы все переходные вероятности были положительны (то есть в цепи возможны все переходы).
Применение данного критерия к анализу котировок позволяет интерпретировать рыночную динамику как марковский процесс. Исследуя статистику хи квадрат, мы фактически проверяем гипотезу о том, является ли последовательность свечей белым шумом или же она порождается однородной эргодической цепью Маркова порядка s. Условие эргодичности (наличие всех возможных переходов в данных) гарантирует состоятельность теста, позволяя выявить скрытые закономерности — память рынка, которая недоступна классическим методам корреляционного анализа.
Реализация алгоритма на языке Python
Основа реализации алгоритма класс — Counter. Это специализированный подкласс словаря, который находится в модуле collections и специально предназначен для быстрого подсчета повторяющихся элементов. В нашем случае мы будем группировать рыночные паттерны и подсчитывать их количество. При этом:
- ключи — это сами паттерны (s-цепочки случайной последовательности),
- значения — это количество их повторений (сколько раз паттерн встретился в истории)
Вот наглядный пример того, как Counter обрабатывает последовательность свечей при s=2 (когда мы ищем влияние двух предыдущих свечей на текущую). Представим небольшой участок котировок из 6 баров: 1, 1, 0, 1, 1, 1 (где 1 — рост, 0 — падение).
from collections import Counter # Наша последовательность (6 свечей) sequence = [1, 1, 0, 1, 1, 1] s = 2 # 1. Собираем (s+1)-цепочки (тройки) скользящим окном: # [1, 1, 0], 1, 1, 1 -> (1, 1, 0) # 1, [1, 0, 1], 1, 1 -> (1, 0, 1) # 1, 1, [0, 1, 1], 1 -> (0, 1, 1) # 1, 1, 0, [1, 1, 1] -> (1, 1, 1) patterns = [(1,1,0), (1,0,1), (0,1,1), (1,1,1)] # 2. Создаем объект Counter: v_ij_counts = Counter(patterns) print(v_ij_counts) # Результат: Counter({(1,1,0): 1, (1,0,1): 1, (0,1,1): 1, (1,1,1): 1})
В итоге, когда мы подадим на вход реальную последовательность, мы получим что-то вроде этого:
{
(1, 1, 1): 450, # Паттерн "три роста подряд" встретился 450 раз
(1, 1, 0): 120, # Паттерн "два роста и разворот" встретился 120 раз
(0, 0, 1): 380, # Паттерн "два падения и отскок" встретился 380 раз
# ... и так далее для всех комбинаций
} Для проведения расчетов нам понадобится функция chi2_randomness(sequence, s, alpha=0.05), которая принимает на вход дискретную последовательность, порядок марковской цепи s и уровень значимости alpha(вероятность ошибки первого рода).
def chi2_randomness(sequence, s, alpha=0.05): """ Тест Хи-квадрат на наличие марковской памяти в дискретной последовательности Args: sequence: Дискретная последовательность s: Порядок марковской цепи (глубина памяти) alpha: Уровень значимости Returns: Dict: Статистика, критическое значение, p-value и т.д. """ n = len(sequence) # количество элементов в исследуемой последовательности if n <= s: return { "statistic": 0.0, "critical_value": 0.0, "p_value": 1.0, "is_rejected": False, "df": 0, "warning": "Sequence too short" } alphabet = sorted(list(set(sequence))) # автоматически определяет алфавит системы (множество E) N = len(alphabet) # количество элементов в E # 1. Считаем только частоты (s+1)-цепочек (v_ij), N^{s+1} комбинаций v_ij_counts = Counter() # создаем объект Counter for t in range(n - s): # проходим по всей истории окном длиной s+1. Каждая найденная комбинация сохраняется как кортеж (tuple) chain_s_plus_1 = tuple(sequence[t : t + s + 1]) # создаем ключ из (s+1)-цепочек v_ij_counts[chain_s_plus_1] += 1 # Если паттерн встретился впервые объект Counter создаст новую запись # 2. Чтобы получить частоту v_i суммируем частоты v_ij по всем j для данного префикса i v_i_from_v_ij = Counter() # создаем объект Counter for chain_s_plus_1, count in v_ij_counts.items(): prefix_i = chain_s_plus_1[:-1] # создаем новый ключ , берем первые s элементов v_i_from_v_ij[prefix_i] += count # считаем частоту v_i # 3. Вычисляем статистику хи-квадрат chi_square_stat = 0 # Проходим в цикле по всем встреченным s-цепочкам (i) for i_chain, v_i in v_i_from_v_ij.items(): expected = v_i / N # Ожидаемое значение согласно H0: v_i / N (равновероятность) # Для каждой i-цепочки смотрим все возможные продолжения j из алфавита (множество E) for j_state in alphabet: ij_chain = i_chain + (j_state,) v_ij = v_ij_counts.get(ij_chain, 0) chi_square_stat += ((v_ij - expected)**2) / expected df = (N**s) * (N - 1) # Степени свободы: N^s(N - 1) critical_value = chi2.ppf(1 - alpha, df) p_value = 1 - chi2.cdf(chi_square_stat, df) return { "statistic": chi_square_stat, "critical_value": critical_value, "p_value": p_value, "is_rejected": chi_square_stat > critical_value, "df": df }
Отметим, что в цикле for j_state in alphabet: мы перебираем все возможные варианты развития событий. Например, если в исследуемой последовательности после комбинации (1, 1) никогда не было 0, мы все равно обязаны проверить этот вариант, чтобы корректно рассчитать отклонение от случайности. С помощью метода get(..., 0) мы устанавливаем частоту равную нулю, для тех комбинаций(i_j) которые не произошли, но теоретически могли произойти.
Интерпретация полученных результатов:
- Statistic — итоговое значение статистики хи-квадрат,
- critical_value — критическое значение статистики; если наша статистика хи-квадрат выше этого числа, гипотеза случайности отклоняется,
- p_value — вычисление вероятности ошибки; если она меньше заданного значения alpha, мы делаем вывод о наличии памяти в данных и, следовательно, отклоняем гипотезу случайности,
- df — расчет количества степеней свободы; это сложность нашей модели — чем больше s, тем больше степеней свободы.
Квантильное преобразование ряда
Для корректного проведения тестов на котировках, нам понадобится функция квантильного преобразования вещественного ряда quantile_transform(data, n_states=2). Она позволяет привести вещественные данные к дискретному множеству с гарантированной равновероятностью состояний. Вместо того чтобы просто делить рынок на рост и падение относительно нуля (что часто вносит искажения из-за трендов), эта функция разбивает данные на N состояний на основе эмпирических квантилей. В бинарном случае (N=2), порогом разбиения выступает медиана ряда. Благодаря этому каждое состояние (0, 1, 2...) будет встречаться в выборке с одинаковой частотой (P(Ej) ≈ 1/N).
def quantile_transform(data, n_states=4)-> np.ndarray: """ Квантильное преобразование разбивает вещественные данные на N дискретных состояний на основе эмпирических квантилей. Это нейтрализует влияние тренда и обеспечивает P{E(j)} = 1/N Args: data: Одномерный массив вещественных чисел (приращения, доходности) n_states: Количество дискретных состояний (размер алфавита) Returns: np.ndarray: Последовательность целых чисел (индексов состояний) от 0 до N-1 """ # Рассчитываем пороги для N состояний # Для n_states=4 пороги будут на 25%, 50% и 75% quantiles = np.linspace(0, 100, n_states + 1)[1:-1] thresholds = np.percentile(data, quantiles) # Превращаем данные в последовательность состояний 0, 1, ..., N-1 return np.digitize(data, thresholds)
У читателя может возникнуть резонный вопрос: зачем искусственно убирать асимметрию, если это наше преимущество? Ведь если мы видим 60% белых свечей на истории, почему бы просто не ставить далее на рост? Безусловно, асимметрия процесса — это тоже знание о рынке, но это примитивное знание. Чтобы его использовать, не нужны сложные тесты и марковские цепи — достаточно стратегии Buy and Hold. Мы же хотим сфокусироваться на выявлении скрытой марковской зависимости — то есть на том, как прошлое влияет на будущее, независимо от общего направления движения цены.
В качестве примера рассмотрим эксперимент, который можно найти в модуле randomness.py. Там мы берем вещественный ряд генерируемый нормальным распределением со средним μ=0.5 (явный тренд вверх) и шумом σ=1.0. Если мы просто будем делить ряд по принципу больше или меньше нуля, мы получим явный перекос в сторону единиц (роста). Наш тест хи-квадрат зафиксирует аномалию и выдаст низкий p-value, сигнализируя о неслучайности.
Но это будет ложная тревога: в данных нет памяти, а есть только дрейф среднего. С помощью функции quantile_transform мы найдем медиану этого ряда (в нашем примере она будет около 0.5) и примем её за точку отсчета. Всё, что выше 0,5, станет единицей, всё, что ниже — нулем. В результате мы получим идеальный баланс состояний (например, 500 нулей и 500 единиц на выборке из 1000 точек). Теперь, если тест хи-квадрат покажет низкий p-value, это будет означать нечто гораздо более важное: последовательность событий имеет внутреннюю структуру, которую нельзя объяснить простым смещением матожидания. Таким образом, квантильное преобразование позволяет отделить трендовую компоненту рынка от его памяти.
Стоит отметить, что при тестировании ГПСЧ (генераторов псевдослучайных чисел) квантильное преобразование не требуется, так как идеальный генератор обязан выдавать равномерное распределение по определению. Но для рыночных котировок это единственный способ очистить ряд от тренда и сфокусироваться исключительно на динамике переходов.
В этом же модуле рассматривается модель марковской цепи, которую можно описать дважды стохастической матрицей переходных вероятностей, где вероятность смены состояния (из 0 в 1 или из 1 в 0) высокая — 0,9, а вероятность сохранения текущего состояния — всего 0,1. (рис. 1)

Рисунок 1. Граф марковской цепи с двумя состояниями и вероятностями переходов
Математическая особенность такой системы заключается в том, что в долгосрочной перспективе (в пределе) частота появления каждого состояния будет стремиться к 0,5. То есть, глядя на итоговую статистику ряда, мы увидим идеальный баланс: 50% нулей и 50% единиц. Тем не менее, этот ряд максимально неслучаен. Зная, что текущее состояние — 0, мы с вероятностью 90% можем предсказать, что следующим будет 1.
Этот пример показывает, что нужно разделять понятия распределение частот состояний (сколько нулей и единиц) и структуру переходов (в каком порядке они следуют друг за другом). Поэтому и на рыночных котировках может не быть тренда, но внутри ряда гипотетически могут существовать паттерны, то есть ряд может обладать памятью.
Есть ли у EURUSD память
Для проведения эксперимента возьмем дневные котировки валютной пары EURUSD. Объем выборки составил примерно 1000 торговых дней (около 4 лет актуальной рыночной истории, последняя дата 2026.04.03). Данные были предварительно очищены от тренда с помощью квантильного преобразования, что привело их к сбалансированному виду: 500 случаев падения (0) и 501 случай роста (1).
Мы протестировали гипотезу случайности для трех уровней глубины памяти (s=1,2,3).
Результаты оказались довольно неожиданными:
| Порядок цепи s | Статистика хи-квадрат | P-value | Обнаружена память |
|---|---|---|---|
| s=1 | 0,04 | 0,98 | нет |
| s=2 | 3,98 | 0,41 | нет |
| s=3 | 18,18 | 0,02 | да |
Оказалось, что EURUSD на дневном таймфрейме ведет себя как абсолютно случайный процесс, если исследовать глубину памяти на 1 или 2 шага. Однако как только мы увеличили глубину анализа до 3-х дней, статистика [и-квадрат отклонила нулевую гипотезу случайности (p-value = 0,019, что ниже критического порога α = 0,05). Это означает, что структура трех предыдущих дней статистически значимо влияет на четвертый день. Вероятность того, что такая зависимость возникла случайно, составляет менее 2%.
Запустив скрипт EURUSD_D.py вы сможете проанализировать какие именно комбинации свечей создают эту неслучайность с помощью анализа таблицы паттернов (за это отвечает функция analyze_patterns(sequence, s_order)). В этой таблице приведены паттерны с наибольшим отклонением от теоретического ожидания частот при условии нулевой гипотезы (топ-10 комбинаций из 2^4 = 16).
Первое место занимает паттерн (1, 1, 0, 0). В теории он должен был встретиться в среднем 62 раза, но в реальности он появился 84 раза (отклонение +34.6%). Это указывает на устойчивую склонность рынка к определенной циклической инерции после двух дней роста и одного дня падения.
Второе место занимает паттерн (0, 1, 0, 0). Встретился всего 45 раз вместо ожидаемых 62 (отклонение -27.8%). Рынок по какой-то причине избегает этой комбинации.
Чтобы окончательно удостовериться в корректности работы алгоритма, воспользуемся перестановочным тестом (permutation test). С помощью функции permutation из Numpy мы полностью перемешали последовательность приращений EURUSD, уничтожив хронологическую связь между днями, но сохранив исходный баланс нулей и единиц.
- Реальная последовательность: P-value=0,01989 (ряд не случаен)
- Перемешанная последовательность: P-value=0,42883 (ряд случаен)
Тот факт, что после рандомизации ряда значение p-value мгновенно вернулось в зону случайности (≈0.43 > 0.05), подтверждает корректность работы алгоритма. Найденная аномалия на реальных данных обусловлена исключительно временной памятью рынка, которая исчезает при нарушении порядка следования свечей.
Таким образом, последние 1000 дневных приращений цен EURUSD демонстрируют поведение, которое не является белым шумом. Данный участок временного ряда обладает скрытой структурой третьего порядка, а обнаруженные паттерны (такие, как 1,1,0→0) представляют собой пример рыночной неэффективности.
Тем не менее, несмотря на статистическую значимость результата на текущем участке истории, при сдвиге временного окна на 1000 баров вглубь прошлого обнаруженная неэффективность исчезает. Читатель может легко проверить это самостоятельно.
mt5.copy_rates_from_pos(symbol, timeframe, 0, count) → mt5.copy_rates_from_pos(symbol, timeframe, 1000, count)
Этот факт лишний раз подтверждает то обстоятельство, что котировки финансовых инструментов — это нестационарные процессы. Их вероятностные характеристики не зафиксированы навечно, а плывут и трансформируются вместе с изменением рыночных режимов и поведением участников торгов.
Для повторения экспериментов вам понадобится интерпретатор Python (рекомендуемая версия 3.10+) и стандартный набор библиотек для анализа данных.
1. Установка Python. Скачайте последнюю версию Python с официального сайта https://www.python.org/downloads/windows
2. Установка необходимых пакетов. Откройте командную строку (CMD) и установите библиотеки одной командой:
pip install numpy pandas scipy MetaTrader5
3. Структура проекта. Для удобства работы я разделил код на два файла. Поместите их в одну общую папку (например, Scripts/RandomnessTest):
- randomness.py — файл-библиотека (модуль), в котором содержатся математические функции, необходимые для расчёта критерия хи-квадрат и примеры из статьи.
- EURUSD_D.py — основной скрипт для проверки гипотезы случайности. Он подключается к MetaTrader 5, запрашивает котировки и вызывает функции из первого файла для анализа.
4. Как запустить анализ:
- откройте терминал MetaTrader 5 и запустите скрипт или модуль просто дважды кликнув по файлу в проводнике,
- все расчеты (статистика хи-квадрат, P-value, количество найденных паттернов и т.д.) отобразятся во вкладке «Эксперты» терминала.
Заключение
Применение критерия хи-квадрат для проверки гипотезы случайности позволяет трейдеру перейти от интуитивного поиска паттернов к строго обоснованной математической верификации гипотезы о наличии памяти в ценовых рядах.
Разработанный алгоритм способен находить память в данных, если эта память действительно существует. При этом благодаря квантильному преобразованию, метод успешно игнорирует асимметрию данных, не генерируя ложных сигналов там, где статистическая зависимость отсутствует.
Безусловно, нестационарность финансовых рынков накладывает определённые ограничения на применение любого статистического теста. Однако это не обесценивает метод, а лишь подчёркивает необходимость его адаптивного и осторожного использования, например с регулярной переоценкой на скользящих окнах.
Надеемся, что предложенный подход займёт достойное место в арсенале алгоритмических трейдеров, помогая отличать истинные рыночные неэффективности от случайного шума.
Программы, используемые в статье:
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | randomness.py | Скрипт | Модуль содержащий функции необходимые для проверки гипотезы случайности |
| 2 | EURUSD_D.py | Скрипт | Анализ гипотезы случайности на примере дневных котировок EURUSD |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Спасибо, интересная статья. Надеюсь, это начало серии.
Спасибо, интересная статья. Надеюсь, это начало серии.
Благодарю. Серии, наверно нет, но по проверкам гипотез возможно ещё будет что-то.