
Основы байесовского вывода в дискретном и непрерывном случаях: от теории к практической реализации моделей

Введение
Предметом теории вероятностей является моделирование данных D по известным параметрам θ с помощью плотности вероятности p(D|θ). Математическая статистика, в свою очередь, решает обратную задачу: поиск неизвестных параметров θ на основе имеющихся данных D.
Существует два основных подхода к решению этой задачи — частотный и байесовский. И если с частотным подходом мы все в той или иной мере знакомы, то байесовская точка зрения освещена довольно слабо. Вместе с тем на сегодня ведущие специалисты по машинному обучению исповедуют именно байесовский взгляд на статистику.
В этой статье мы попробуем разобраться в основах данного метода. Чтобы не перегружать изложение, мы намеренно не будем касаться условных моделей вида P(y∣X, θ), где результат целевой переменной y зависит от набора входных признаков X (как, например, в байесовской логистической регрессии). Для усвоения байесовской философии правильнее начинать с более простых моделей, то есть с классической задачи оценивания параметров.
Мы пойдём по пути «от теории к практике»: абстрактные теоретико-множественные выкладки будут сразу подкрепляться конкретными примерами. Это позволит наглядно убедиться, что для работы с байесовскими моделями зачастую не требуется ничего сложнее базовых операций сложения и умножения вероятностей.
Байесовская парадигма
В байесовском подходе параметр θ рассматривается как случайная величина с распределением P(θ) (например, в биномиальной модели, модели Пуассона или нормальной модели). Согласно принятой терминологии исходные значения вероятностей P(θ) принято называть априорными (так как они принимаются до того, как данные получены), а пересмотренные вероятности — апостериорными (так как они вычисляются после получения данных). Важно понимать, что эти понятия относительны: сегодняшние апостериорные выводы завтра станут априорными знаниями для новых расчётов. На рис.1 схематически представлен процесс, лежащий в основе байесовского вывода.

Рис. 1. Байесовская парадигма
Отличие байесовской парадигмы от других статистических подходов состоит в том, что до того как будут получены данные D, статистик рассматривает степени доверия к возможным моделям и представляет их в виде вероятностей. Как только данные поступают, теорема Байеса позволяет пересчитать эти вероятности, учитывая новую информацию.
Таким образом, байесовские методы — это способы решения статистических задач, где инструментом обновления знаний служит теорема Байеса. Далее мы рассмотрим, как она работает в дискретном и непрерывном случаях.
Теорема Байеса: дискретный случай
В дискретном случае рассматривается конечный список гипотез (также называемых моделями) H = {H1, H2, ..., Hk}. Эти гипотезы являются взаимоисключающими и в совокупности исчерпывают все возможные объяснения наблюдаемой ситуации. До получения данных мы присваиваем каждой гипотезе априорные вероятности:
{P(H1), P(H2), ..., P(Hk)}
при этом выполняются два естественных условия:
- каждая вероятность лежит в интервале (0, 1),
- сумма всех априорных вероятностей равна 1.
Каждая модель определяет, насколько вероятно появление наблюдаемых данных D при условии, что именно эта модель верна. Эти вероятности записываются как условные вероятности:
{P(D|H1), P(D|H2), ..., P(D|Hk)}
В контексте байесовского вывода их принято называть правдоподобиями (likelihood).
Пересмотренные значения вероятностей обозначают как:
{P(H1|D), P(H2|D), ..., P(Hk|D)}
Теорема Байеса (дискретный случай): пусть {H1, H2, ..., Hk} — исчерпывающее множество взаимоисключающих вероятностных гипотез, P(Hi) — априорные вероятности, P(D|Hi) — правдоподобия и P(D) > 0. Тогда апостериорные вероятности задаются формулой:

Где P(D) — формула полной вероятности, которая служит нормировочной константой.
![]()
Формула Байеса может показаться сложной на первый взгляд, но на самом деле она напрямую следует из определения условной вероятности. Вспомним базовое правило: вероятность того, что произойдут два события сразу (H и D), можно записать двумя способами:
- P(H ∩ D) = P(D∣H) P(H)
- P(H ∩ D) = P(H∣D) P(D)
Так как левые части равны, мы можем приравнять и правые:
P(H∣D) P(D) = P(D∣H) P(H)
Отсюда и получается знаменитая формула Байеса. Как видите, никакой магии здесь нет. Все расчёты строятся на базовых операциях умножения и сложения вероятностей.
Перейдём к конкретным примерам.
Пример с монетой
Пусть имеются две монеты: правильная с вероятностью выпадения герба равной 0,5 и неправильная — с вероятностью выпадения герба равной 0,1. Мы наугад выбираем одну из монет, подбрасываем её, и выпадает герб D = {Г}. Спрашивается, какова вероятность того, что выбранная монета правильная?
В первую очередь определим множество моделей {H1, H2}, где H1 — это правильная монета, H2 — неправильная.
Поскольку выбор монеты случайный, то априорные вероятности этих моделей равны:
- P(H1) = 0,5
- P(H2) = 0,5
Правдоподобия (условные вероятности) согласно условиям задачи:
- P(Г|H1) = 0,5
- P(Г|H2) = 0,1
По формуле полной вероятности вычислим P(D):
- P(Г) = P(Г|H1) * P(H1) + P(Г|H2) * P(H2) = 0,5 * 0,5 + 0,1 * 0,5 = 0,3
Теперь найдем интересующую нас вероятность по формуле Байеса:
- P(H1|Г) = (0,5 * 0,5) / 0,3 = 0,833
Соответственно для второй гипотезы:
- P(H2|Г) = 1 - P(H1|Г) = 0,167
Таким образом, до наблюдения данных наша уверенность в том, что мы выбрали правильную монету, составляла 50%.
После того как выпал герб, она возросла до 83%! Данные заметно изменили наши первоначальные вероятности.
Бесконечный набор моделей
В предыдущем примере мы работали с конечным списком гипотез, но в дискретном случае возможен и бесконечный набор. При этом все выведенные нами результаты остаются в силе, меняется лишь количество проверяемых гипотез.
Пример: байесовский анализ интенсивности тикового потока EURUSD
Предположим, мы считаем, что количество X тиков, полученных по паре EURUSD в минуту, является случайной величиной с распределением Пуассона (рис.2). В этой модели есть один неизвестный параметр θ — среднее количество тиков в минуту.
Поскольку θ может принимать любое целое положительное значение (1, 2, 3, …), мы получаем бесконечный набор гипотез {H₁, H₂, H₃, …}. Каждая из этих гипотез порождает своё правдоподобие пуассоновского типа P(D|Hi), где Hi соответствует модели θ = i.
Конечно, на практике мы всё равно будем ограничены некоторым конечным подмножеством наиболее вероятных моделей. Если выбрать достаточно большое число n, такое, что суммарная вероятность всех гипотез от H₁ до Hₙ составит 99.99%, то оставшиеся 0,01% можно отбросить как статистически незначимые.

Рис. 2. Распределение Пуассона
Допустим, мы наблюдаем следующие данные по тикам за последние 10 минут D = [102, 82, 99, 132, 116, 122, 72, 78, 84, 92]. Среднее арифметическое этой выборки — 97,9. Предположим, что в прошлом месяце активность была выше — в среднем 150 тиков. Байесовский подход позволяет нам объединить этот опыт с новыми данными.
Формирование информативного априора
В качестве априорного распределения для параметра θ мы также возьмем распределение Пуассона со средним значением 150 тиков. Это отражает наше предварительное знание, что в среднем рынок выдает именно такую интенсивность. Для численного расчета воспользуемся методом аппроксимации на сетке. Мы создадим массив из 300 гипотез (θ ∈ [1, 300]), где каждая точка — это отдельная модель со своим фиксированным значением среднего.
import pandas as pd import numpy as np import MetaTrader5 as mt5 from datetime import datetime import pytz from scipy.stats import poisson from scipy.special import logsumexp import matplotlib.pyplot as plt # Инициализация MT5 if not mt5.initialize(): print("initialize() failed") quit() timezone = pytz.timezone("Etc/UTC") target_date = (2026, 4, 23) utc_from = datetime(*target_date, 12, 0, 0, tzinfo=timezone) utc_to = datetime(*target_date, 12, 10, 0, tzinfo=timezone) # Загружаем тики ticks = mt5.copy_ticks_range("EURUSD", utc_from, utc_to, mt5.COPY_TICKS_ALL) mt5.shutdown() # Создаем DataFrame и считаем тики в минуту df = pd.DataFrame(ticks) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) # Группируем по минутам minute_counts = df.resample('1min').count()['ask'].values print(f"Данные (количество тиков в минуту): {minute_counts}") sum_x = np.sum(minute_counts) n = len(minute_counts) # 1. Сетка гипотез theta_grid = np.arange(1, 301) # 2. Априор prior = poisson.pmf(theta_grid, mu=150) prior /= prior.sum() # 3. Правдоподобие log_likelihood = sum_x * np.log(theta_grid) - n * theta_grid # 4. Считаем логарифм числителя (Правдоподобие + Априор) log_numerator = log_likelihood + np.log(prior + 1e-12) # вектор из 300 элементов # 5. Находим логарифм полной вероятности P(D) через LogSumExp log_evidence = logsumexp(log_numerator) # 6. Получаем нормированный логарифм апостериора log_posterior = log_numerator - log_evidence # 7. Финальный результат в обычных вероятностях posterior = np.exp(log_posterior) print(f"Сумма вероятностей: {np.sum(posterior)}") print(f"Логарифм свидетельства (Evidence): {log_evidence:.4f}") # Нормировка правдоподобия для визуализации log_evidence_likelihood = logsumexp(log_likelihood) likelihood_norm = np.exp(log_likelihood - log_evidence_likelihood) # --- Визуализация --- plt.figure(figsize=(10, 5)) # Априор plt.plot(theta_grid, prior, label='Prior',color='blue', linestyle='--', alpha=0.6) # Правдоподобие plt.plot(theta_grid, likelihood_norm, label='Likelihood (Normalized Data)', color='green', linewidth=1, alpha=0.8) # Апостериор plt.plot(theta_grid, posterior, label='Posterior', color='red', linewidth=2) plt.fill_between(theta_grid, posterior, color='red', alpha=0.1) # Оценка MLE plt.axvline(sum_x/n, color='green', linestyle=':', alpha=0.8,label=f'Data Mean: {sum_x/n:.2f}') plt.title(f"Discrete Bayesian Inference (EURUSD)\nMinutes: {n}, Total Ticks: {sum_x}", fontsize=12) plt.xlabel("Ticks per Minute (θ)") plt.ylabel("Probability") plt.legend() plt.grid(True, alpha=0.2) plt.show() print(f"Среднее по данным (MLE): {sum_x/n:.2f}") print(f"Наиболее вероятное значение (MAP): {theta_grid[np.argmax(posterior)]}")
Поскольку в теории ряд Пуассона бесконечен, а наша сетка моделей ограничена, мы нормируем веса априора так, чтобы их сумма была строго равна 1.
prior = poisson.pmf(theta_grid, mu=150) prior /= prior.sum()
Теперь каждая гипотеза имеет свою априорную вероятность.
Работа с правдоподобием
Модель Пуассона для одного наблюдения при заданном среднем θ вычисляется как:

Но так как у нас не одно число, а целый набор данных D и мы считаем, что поступление тиков в минуту независимо, то общее правдоподобие
— это произведение вероятностей для каждой точки данных: 
Работать с произведением степеней и экспонент неудобно (числа получаются слишком маленькими для компьютера). Поэтому мы берём натуральный логарифм правдоподобия ln(L). Логарифм превращает произведение в сумму, а степень в множитель:

Разложим логарифм дроби на компоненты:

При расчёте на компьютере мы вычисляем только первое и второе слагаемое в сумме так как логарифм от факториала — это константа, которая не зависит от параметра θ.
# 3. Правдоподобие
log_likelihood = sum_x * np.log(theta_grid) - n * theta_grid В байесовском выводе нам важны только те части формулы, где есть наш неизвестный параметр θ. Поэтому логарифм факториала можно не считать.
Апостериор и формула полной вероятности
Теперь мы объединим все компоненты в единую систему. Для получения апостериора нам нужно умножить априор на правдоподобие. Поскольку мы работаем в логарифмическом пространстве, умножение превращается в сложение:
log_numerator = log_likelihood + np.log(prior + 1e-12) Здесь log_numerator — это вектор из 300 элементов. Каждое значение в векторе соответствует одной из 300 наших моделей. Сейчас сумма полученных (ненормированных) весов по 300 моделям не равна 1. Чтобы получить вероятности, нужно вычислить нормировочную константу P(D) и нормировать значения на неё. В байесовской статистике полную вероятность данных P(D) ещё называют Evidence («свидетельство») или маргинальное правдоподобие. Математически P(D) это сумма произведений правдоподобия на априор по всем нашим 300 моделям. Другими словами, это математическое ожидание правдоподобия относительно априорного распределения.
Для стабильности вычислений P(D) воспользуемся функцией logsumexp. Она позволяет вычислить логарифм суммы экспонент, избегая переполнения памяти при работе с очень большими или очень маленькими числами:
log_evidence = logsumexp(log_numerator)
На рис.3 представлен результат вычислений.

Рис. 3. Байесовский вывод для модели Пуассона
Мы видим, как исходный априор (наше ожидание в 150 тиков) под влиянием новых данных сместился и изменил форму, сформировав актуальное представление о текущей интенсивности тикового потока.
Отметим важный момент: априор и апостериор — это распределения вероятностей, их сумма всегда равна 1.0. Правдоподобие (likelihood) имеет другой масштаб и может принимать любые значения. Чтобы нарисовать правдоподобие на одном графике вместе с априором и апостериором, его нужно привести к тому же масштабу (нормировать). Для этого мы:
- вычисляем общую «массу» правдоподобия с помощью logsumexp(log_likelihood),
- делим каждое значение логарифма правдоподобия на эту общую массу (в логарифмическом пространстве это простое вычитание).
Теорема Байеса: непрерывный случай
До этого момента мы работали с дискретными гипотезами: монета либо правильная, либо нет; среднее число тиков любое целое число от 1 до 300 и т.д. Однако в большинстве практических ситуаций нам приходится иметь дело с несчётным (непрерывным) множеством возможных значений параметра.
Рассмотрим модель биномиального распределения, где нас интересует вероятность успеха θ. Здесь параметр θ может принимать любое значение из единичного интервала [0, 1]. Составить полный список гипотез и присвоить каждой вероятность здесь уже невозможно — их бесконечно много.
Вместо этого мы описываем степень нашего доверия к разным значениям параметра θ с помощью плотности вероятности — сплошной кривой. Там, где кривая выше, наши априорные ожидания сильнее. Там, где она близка к нулю — такие значения θ мы считаем маловероятными.
Таким образом, дискретный априор в виде таблицы или сетки значений превращается в плавный график, а математика переходит от простого суммирования к интегрированию (вычислению площади под этим графиком).
Теорема Байеса (непрерывный случай): пусть Θ — пространство параметра, θ ∈ Θ, p(θ) — априорная плотность, а p(D|θ) — правдоподобие. Тогда апостериорная плотность p(θ|D) задаётся выражением:

- P(D) — Evidence (Marginal Likelihood): в непрерывном случае представляет собой интеграл по всему пространству возможных значений параметра θ.
В нашем примере с одним параметром θ это ещё выглядит решаемым. Но как только мы переходим к реальным задачам машинного обучения, где параметров могут быть десятки, сотни или тысячи, мы сталкиваемся с проклятием размерности. Многомерный интеграл по огромному пространству параметров часто невозможно вычислить аналитически.
Именно из-за этой вычислительной сложности байесовская статистика долгое время оставалась в тени классических методов. Только с появлением мощных компьютеров и специальных алгоритмов (таких как методы Монте-Карло по схеме марковских цепей — MCMC), байесовский подход стал по-настоящему прикладным инструментом.
Существует и другой способ упростить жизнь исследователю — использовать так называемые сопряжённые распределения. Они позволяют получать точный результат с помощью простых арифметических действий, полностью избегая громоздких интегралов. Именно по этому пути мы и пойдём дальше.
Выбор априорного распределения в непрерывном случае
Необходимо отметить, что не существует единственно правильного априора на все случаи жизни. Этот выбор зависит от конкретной задачи и опыта исследователя. Здесь, как и в трейдинге, присутствует определённое поле для творчества.
Рассмотрим рис. 4, где представлены разные виды априорных плотностей P(θ) для биномиального распределения с неизвестным параметром θ.

Рис. 4. Возможные варианты априоров P(θ) для биномиального распределения
- В случае (a) мы предполагаем, что все значения параметра 0 ≤ θ ≤ 1 рассматриваются как равновозможные. В такой ситуации модель не имеет начальных предпочтений и будет полностью полагаться на данные,
- В случае (b) мы предполагаем, что наиболее вероятным значением параметра является θ = 0,75,
- В случае (c) мы предполагаем, что значения θ, близкие к 0 и 1 более вероятны, чем значения в центре.
Может возникнуть ощущение некоторой субъективности в выборе того или иного вида априорного распределения. Действительно, два статистика могут выбрать разные априоры для одной и той же задачи.
Вместо того чтобы полагаться на интуицию, мы можем использовать эмпирический анализ:
- собрать исторические данные за прошлые периоды,
- построить гистограмму распределения нужного нам параметра,
- аппроксимировать эту гистограмму подходящей математической моделью (Бета-распределением, Гаммой и т.д.).
Таким образом, ваш априор перестает быть просто мнением и становится сжатым опытом прошлых наблюдений.
Байесовский вывод в бета-биномиальной модели
Напомним, что биномиальная модель описывает вероятность получить y успехов (данные D) в n независимых испытаниях при фиксированном шансе на успех θ.

Теоретически, мы могли бы рассчитывать апостериорное распределение для этой модели численно (на сетке), как делали в примере с Пуассоном. Однако при работе с непрерывными параметрами такой подход становится слишком громоздким.
К счастью, в байесовской статистике существуют сопряжённые распределения (conjugate priors). Это специальные пары распределений, которые математически идеально подходят друг к другу: при умножении априора на правдоподобие результат сохраняет ту же функциональную форму, что и исходный априор. Для биномиального правдоподобия сопряженным априором является бета-распределение. Мы уже видели несколько примеров таких кривых на рис. 4. Главное преимущество сопряжённых распределений в том, что они позволяют полностью избежать сложных интегралов. Решение получается в закрытой (аналитической) форме.
Если априор задается как Beta(a, b), и в результате наблюдений мы получили y успехов и (n−y) неудач, то параметры апостериора вычисляются очень просто:
Beta (θ|a + y, b + n - y)
Таким образом, апостериор снова имеет форму бета-распределения, но с обновлёнными параметрами.
Давайте посмотрим, как обновляются априорные суждения, представленные на рис. 4, если мы проведем 10 испытаний, в которых получим 8 успехов (y) и 2 неудачи (n-y). На графиках ниже (рис. 5) представлены соответствующие апостериорные распределения.

Рис. 5. Апостериорные распределения P(θ|D) для биномиального правдоподобия
Итоговый результат:
- Случай (a): апостериор превратился в Beta(1+8, 1+2) = Beta(9, 3). Кривая полностью отражает данные: максимум находится в районе 0,8,
- В случае (b) апостериор стал ещё более узким и уверенным, так как данные подтвердили априорное ожидание,
- В случае (c) данные полностью подавили первоначальную веру в крайности (0 или 1), заставив кривую собраться ближе к центру. Хотя апостериор здесь чуть шире, чем в случае (a), он наглядно показывает: достаточное количество данных способно исправить даже самое экзотическое априорное распределение.
Апостериорная мода: оценка MAP
В конечном итоге нам часто нужно одно конкретное число параметра θ. Для этого можно использовать оценку максимума апостериорной вероятности MAP (Maximum a Posteriori). Другими словами, мы ищем моду апостериорного распределения — точку, где плотность вероятности максимальна:

Для бета-биномиальной модели это значение вычисляется по очень простой аналитической формуле:

В случае равномерного априора оценка MAP сводится к оценке максимального правдоподобия MLE (Maximum Likelihood Estimation). Например, подставим значения для равномерного априора в формулу и получим (1 + 8 - 1 )/ (1 + 1 + 10 - 2) = 8/10. Эта оценка интуитивно понятна, но она может быть очень далека от истины, если выборка данных небольшая.
Например, мы подбросили монету 5 раз и все 5 раз выпал герб. В таком случае оценка MLE для решки равна 0, то есть она говорит, что в будущем решек не будет никогда. Естественно, что эта оценка плохая и связана она с недостаточностью данных.
Если мы добавим априор (например, Beta(2,2)), наше знание обновится до Beta(2+5, 2+0) = Beta(7, 2). Оценка MAP составит (7−1) / (7+2−2) = 6/7 ≈ 0,85. Таким образом, байесовская модель признает, что перекос в сторону гербов есть, но она оставляет ненулевую вероятность для решки.
Апостериорное среднее
Апостериорная мода (MAP) показывает нам самую вероятную точку параметра. Однако она может давать неполное или даже искажённое представление, потому что полностью игнорирует форму распределения вокруг этого пика — насколько оно широкое, симметричное или имеет тяжёлые хвосты.
Апостериорное среднее, напротив, является более робастной оценкой. Оно учитывает всё распределение целиком и получается путём усреднения (интегрирования) по всем возможным значениям θ с учётом их вероятностей.
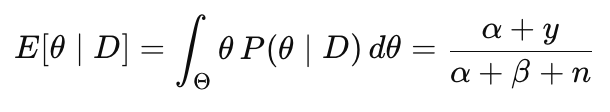
Данная оценка является комбинацией между априорным средним и оценкой MLE. Чем слабее априорное распределение, тем ближе апостериорное среднее к MLE.
Для нашего примера с 8 успехами и 2 неудачами апостериорное среднее равно:
E[θ|D] = (1 + 8) / (1 + 1 + 10) = 0,75
Апостериорное предсказательное распределение (Posterior Predictive Distribution)
Оценка параметров (θ) — это лишь промежуточный этап. Истинная цель байесовского анализа — получение прогноза на новых, ещё не наблюдавшихся данных. В байесовском подходе эта задача решается с помощью апостериорного предсказательного распределения.
Чтобы ответить на вопрос: «Какова вероятность успеха (ynew) в следующем испытании?», мы не берем одно самое лучшее значение θ. Вместо этого мы проводим взвешенное голосование среди всех возможных моделей. Каждая модель даёт свой прогноз, а мы учитываем её с весом, пропорциональным тому, насколько сильно мы в неё верим после обновления (то есть согласно апостериорному распределению). Математически это означает, что нужно проинтегрировать правдоподобие по всему апостериору θ.
К счастью, для бета-биномиальной модели этот сложный процесс взвешенного голосования для одного следующего испытания (n = 1) сильно упрощается и сводится к простому отношению:

Вы наверняка заметили, что формула прогноза полностью совпала с формулой апостериорного среднего. Такое идеальное совпадение — это особенность именно бета-биномиальной модели. В более сложных моделях апостериорное среднее и предсказательное распределение, как правило, различаются.
Динамическое байесовское обновление
Во многих практических ситуациях данные поступают последовательно во времени {D₁, D₂, ..., Dt}, как, например, поток котировок. В таких условиях мы не ждём накопления всей выборки. Вместо этого мы обновляем свои убеждения сразу после получения каждого нового наблюдения: сначала анализируем данные D₁, затем пересматриваем вероятности с приходом D₂ и так далее. Этот процесс называется динамическим байесовским обновлением (схематически представлен на рис.6).

Рис. 6. Динамическое байесовское обновление
Или в виде формулы:
![]()
где
- P(θ∣D1:t) — новый апостериор (после шага t),
- P(Dt|θ) — правдоподобие текущего наблюдения,
- P(θ|D1:t-1) — априор, который на самом деле является апостериором с предыдущего шага.
Рассмотрим простой пример динамического байесовского обновления:
import numpy as np import matplotlib.pyplot as plt # 1. имитация последовательного поступления данных data = [1, 1, 0, 1, 1, 1, 0, 1, 1, 1] # 1 - рост, 0 - падение # 2. Начальные априорные параметры (Uniform Prior) alpha_current = 1 beta_current = 1 history = [] print(f"{'Шаг':<5} | {'Данные':<7} | {'Alpha':<6} | {'Beta':<5} | {'MAP':<6} | {'Mean (Прогноз)':<10}") print("-" * 60) # 3. Цикл последовательного обновления (Bayesian Updating) for i, y in enumerate(data): # ОБНОВЛЕНИЕ: прибавляем успех или неудачу if y == 1: alpha_current += 1 else: beta_current += 1 # MAP (мода) if alpha_current + beta_current > 2: map_val = (alpha_current - 1) / (alpha_current + beta_current - 2) else: map_val = 0.5 # Для Uniform мода не определена mean_val = alpha_current / (alpha_current + beta_current) history.append((alpha_current, beta_current, mean_val)) print(f"{i+1:<5} | {y:<7} | {alpha_current:<6} | {beta_current:<5} | {map_val:<6.3f} | {mean_val:<10.3f}") # 4. Визуализация процесса обучения steps = np.arange(1, len(data) + 1) means = [h[2] for h in history] plt.figure(figsize=(8, 4), dpi=100) plt.step(steps, means, where='post', color='#3498db', lw=2, label='Posterior Mean (Forecast)') plt.axhline(0.5, color='gray', linestyle='--', alpha=0.5, label='Initial Prior (0.5)') plt.title('Step-by-step Bayesian Updating', fontsize=12) plt.xlabel('Observation Number (Time)', fontsize=10) plt.ylabel('Probability of Success', fontsize=10) plt.ylim(0, 1) plt.grid(True, linestyle=':', alpha=0.6) plt.legend() plt.show()
На рис.7 показан график изменения последовательного обновления прогноза с ростом числа наблюдений.

Рис. 7. График прогноза по апостериорному среднему
Коснемся тонкостей применения данной схемы к нестационарным финансовым данным. Все наши предыдущие расчеты строились на неявном допущении, что правила игры не меняются. В статистике это называется стационарностью. При исследовании стационарных процессов, чем больше данных мы имеем, тем точнее получаются оценки параметров, которые мы оцениваем по этим данным.
В нестационарном случае это не так. Режим рынка (процесс порождения данных) может измениться в любой момент. В такой ситуации старые данные не только перестают помогать, но и начинают вредить: модель продолжает верить в правила, которые уже не работают.
Интуитивно понятно, что более свежие данные должны иметь больший вес, чем наблюдения недельной или месячной давности. Чтобы реализовать эту идею, мы вводим в модель коэффициент затухания гамма γ. Мы модифицируем предыдущий код, добавив этот параметр. По своей сути γ контролирует, насколько быстро модель забывает старые данные:

- Если γ = 1, модель помнит всю историю и работает как обычное байесовское обновление,
- Если γ < 1, модель постепенно забывает прошлое и сильнее реагирует на недавние наблюдения.
Связь между этим коэффициентом и привычным нам скользящим окном выражается простой формулой:
n = 1/(1 - γ)
Например, если мы хотим, чтобы модель принимала решения на основе последних 20 свечей, мы устанавливаем γ = 0,95.
Пример: простой индикатор разладки (change point detection)
Чтобы продемонстрировать работу алгоритма, были сгенерированы синтетические данные, имитирующие резкую смену рыночного режима. В первой половине последовательности (первые 100 наблюдений) вероятность успеха составляла θ = 0,6 (восходящий тренд). Во второй половине параметр резко изменился до θ = 0,3 (нисходящий тренд).
import pandas as pd import numpy as np import matplotlib.pyplot as plt # 1. Генерируем синтетические данные # Сначала тренд вверх (60% рост), потом резкий разворот вниз (30% рост) np.random.seed(42) data_up = np.random.choice([1, 0], size=100, p=[0.6, 0.4]) data_down = np.random.choice([1, 0], size=100, p=[0.3, 0.7]) data = np.concatenate([data_up, data_down]) # 2. Параметры модели gamma = 0.94 # Коэффициент затухания гамма (Чем меньше γ, тем быстрее модель забывает прошлое) a_curr, b_curr = 1, 1 # Начальные параметры: Beta(1,1) — равномерный априор history = [] # 3. Цикл динамического байесовского обновления с экспоненциальным затуханием for y in data: # добавляем 1 чтобы всегда сохранять хотя бы минимальный априор Beta(1,1) a_curr = (a_curr - 1) * gamma + 1 b_curr = (b_curr - 1) * gamma + 1 # Обновление с новым наблюдением if y == 1: a_curr += 1 else: b_curr += 1 # Вычисляем текущее апостериорное среднее (ожидаемая вероятность успеха) mean = a_curr / (a_curr + b_curr) history.append(mean) # 4. Визуализация plt.figure(figsize=(12, 5), dpi=100) plt.plot(history, color='#3498db', lw=2, label=f'Adaptive Bayesian (gamma={gamma})') plt.axhline(0.5, color='black', linestyle='--', alpha=0.3) plt.axvline(100, color='red', linestyle=':', label='Change point') # 5. Сравнение с обычным (неадаптивным) байесовским обновлением (gamma=1) a_std, b_std = 1, 1 # Начинаем тоже с равномерного априора Beta(1,1) std_history = [] for y in data: # Стандартное байесовское обновление — просто добавляем каждое новое наблюдение if y == 1: a_std += 1 else: b_std += 1 mean_std = a_std / (a_std + b_std) # Апостериорное среднее std_history.append(mean_std) plt.plot(std_history, color='gray', alpha=0.5, label='Standard Bayesian (gamma=1.0)') plt.title('Adaptive Bayesian Update vs Standard', fontsize=12) plt.legend() plt.grid(alpha=0.2) plt.show()
Обратите внимание на рис. 8: стандартное байесовское обновление реагирует на смену режима с заметным запаздыванием.

Рис. 8. сравнение прогноза в адаптивном и стандартном байесовском обновлении
В свою очередь, адаптивная версия с коэффициентом затухания γ = 0,94 отреагировала значительно быстрее — ей потребовалось примерно 17–20 новых наблюдений, чтобы уверенно зафиксировать изменение рынка. Этот период отлично согласуется с размером скользящего окна, рассчитанным по формуле n = 1/(1 − 0,94) ≈ 16,7.
Таким образом, мы получили простой, но эффективный индикатор разладки (change point detection), построенный на основе байесовской бета-биномиальной модели с экспоненциальным затуханием.
Чтобы воспроизвести полученные результаты, вам понадобится интерпретатор Python и стандартный стек статистических пакетов. О том, как их установить, рассказывается в статье Python + MetaTrader 5: быстрый исследовательский контур для данных, признаков и прототипов.
После установки пакетов поместите файлы, приложенные к статье, в одну общую папку (например, Scripts/BayesianInference).
Чтобы увидеть графики, запускайте скрипт через MetaEditor:
- в MetaEditor нажмите Файл → Открыть и выберите нужный .py файл из папки BayesianInference,
- после открытия файла нажмите клавишу F7 (или кнопку «Компилировать» на панели инструментов),
- график должен появиться в отдельном окне.
Заключение
В этой работе мы прошли полный путь от философских основ байесовской парадигмы до практических инструментов анализа данных. На примере дискретных и непрерывных моделей мы увидели, как априорный опыт и фактические данные трансформируются в обновленное знание — апостериорное распределение.
Байесовский подход отличается интеллектуальной честностью перед неопределённостью: он явно балансирует между накопленной исторической памятью и свежими данными, избегая ложной уверенности, которую часто демонстрируют классические частотные методы на малых выборках.
На примере бета-биномиальной модели мы познакомились с понятием сопряжённых распределений. Благодаря им байесовский вывод сводится к простым арифметическим операциям, что делает алгоритм быстрым и применимым для анализа данных в реальном времени.
Отдельное внимание было уделено механизму последовательного байесовского обновления, который позволяет модели динамически пересматривать свои убеждения по мере поступления новой информации.
Надеемся, что усвоение базовых принципов байесовского вывода поможет в дальнейшем изучении вероятностного машинного обучения и практической работы с неопределённостью.
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Poisson.py | Скрипт | Байесовский вывод параметра интенсивности тикового потока с помощью модели Пуассона |
| 2 | BayesianUpdating.py | Скрипт | Последовательное обновление прогноза в бета-биномиальной модели |
| 3 | AdaptiveUpdate | Скрипт | Адаптивное последовательное обновление прогноза в бета-биномиальной модели |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования