
Нейросети в трейдинге: Многодоменная архитектура анализа финансовых данных (MDL)

Введение
Современные финансовые рынки давно перестали быть средой, в которой достаточно одной универсальной модели или одного набора правил на все случаи жизни. Один и тот же инструмент ведет себя по-разному в тренде и во флэте, в фазе высокой волатильности и в период затишья, на старших и младших таймфреймах, при смене ликвидности и рыночного контекста. В результате практическая разработка торговых систем все чаще упирается в избыточную фрагментацию подходов. Под каждый сценарий строится отдельная логика, которую затем необходимо согласовывать с остальными. Такая архитектура работает лишь локально и теряет устойчивость при смене рыночного режима.
Попытки решить эту проблему за счет усложнения признаков, увеличения глубины моделей или агрессивной оптимизации гиперпараметров дают ограниченный эффект. Причина остается фундаментальной: модель изначально проектируется как однодоменная, тогда как рынок по своей природе многодоменный. В прикладных задачах машинного обучения для работы с такой сложностью применяют многосценарное (MSL) и многозадачное (MTL) обучение. Они позволяют учитывать разнообразие контекстов. Однако у этих подходов есть два ограничения:
- параметры модели используются неэффективно при сложных признаковых представлениях;
- сложно совместно учитывать сценарий и задачу в одной архитектуре.
Перенос данной идеи в область финансовых рынков позволяет сформулировать задачу более строго. Если считать инструмент, таймфрейм, режим рынка и горизонт прогнозирования разными доменами, задача сводится к единой архитектуре, которая учитывает контекст при обработке данных. Такой подход устраняет необходимость жесткого переключения между стратегиями и заменяет его адаптивным механизмом, при котором модель сама регулирует вклад факторов в зависимости от текущего состояния рынка.
В рамках данного проекта рассматривается адаптация фреймворка MDL к финансовым данным. Основное внимание уделяется формализации доменов, построению входного представления и определению архитектурных принципов, позволяющих интегрировать контекст непосредственно в вычислительный процесс. При этом речь идет не о полном воспроизведении исходной модели, а о ее переосмыслении с учетом специфики финансовых временных рядов, их шумовой природы и требований к практической устойчивости.
Построение такой системы неизбежно выходит за рамки одной статьи. Поэтому текущая работа ограничивается концептуальной частью и начальным этапом инженерной проработки. В статье формируется архитектурная основа и закладываются принципы дальнейшей реализации.
Архитектура MDL
Архитектура MDL построена вокруг идеи единого токенизированного представления, в котором признаки, сценарии и задачи приводятся к общему вычислительному формату. Для финансовых рынков это особенно важно, потому что один и тот же поток данных часто можно трактовать по-разному. Свеча, объем, спред или импульс по-разному читаются в тренде, во флэте, на спокойной азиатской сессии и во время резкого выхода новостей. Поэтому модель не должна смотреть на рынок как на набор изолированных чисел, она должна видеть его как систему, в которой контекст определяет смысл сигнала. Именно эту роль в MDL и выполняют токены сценариев и задач. Они выполняют роль управляющего контекста, проходящего через весь вычислительный конвеер.
В прикладном смысле это означает, что модель смотрит на рынок через призму текущего режима и цели анализа. Если рынок находится в направленном движении, одни признаки становятся важнее других. Когда цена переходит в боковик, на первый план выходят уже совсем иные зависимости. А в случае постановки задачи оценки риска или формирования торгового сигнала, внутреннее представление должно меняться. Контекст перестает быть подписью к данным, он становится их частью и влияет на то, как модель собирает рыночную картину.
В модуле унифицированной токенизации признаки переводятся в эмбеддинги. Последовательные компоненты, например история баров или тиков, проходят через специализированные временные модули и формируют сжатое представление динамики. Затем признаки группируются по семантическим кластерам и преобразуются в фиксированное число токенов 𝑻f ∈ RNf×df.
Здесь важно обратить внимание на один принципиальный момент: в оригинальной реализации авторы MDL предлагают формировать группы признаков вручную, опираясь на предметную область. В рекомендательных системах такой подход оправдан, признаки имеют устойчивую семантику и их группировка может быть заранее определена на уровне бизнес-логики. В финансовых рынках же ситуация иная. Здесь признаки редко обладают стабильной интерпретацией, один и тот же индикатор может вести себя по-разному в зависимости от режима рынка, а границы между трендом, шумом и ликвидностью зачастую размыты. Более того, сами эти категории носят скорее эвристический характер, чем строгую формализацию. В результате ручная группировка признаков становится не только трудоемкой, но и потенциально неустойчивой. Она фиксирует структуру, которая в реальности постоянно меняется.
Отсюда возникает естественное требование — механизм группировки должен быть перенесен внутрь модели. Иными словами, вместо жестко заданных семантических кластеров необходимо использовать адаптивную кластеризацию, которая будет формироваться в процессе обучения. Детальнее обсудим в практической части статьи.
Далее каждая группа эмбеддингов 𝒆j проецируется в пространство фиксированной размерности. Такой шаг делает представление компактным, но при этом сохраняет различимость между разными аспектами рыночного поведения. По сути, модель получает не просто вектор признаков, а структурированную карту рынка. В ней каждый токен отвечает за свой фактор и может взаимодействовать с другими.
Токены сценариев и задач формируются по схожему принципу, но выполняют иную роль. Их входное представление включает два компонента: расширенные эмбеддинги ключевых признаков и специфические признаки, отражающие контекст. В финансовой постановке это могут быть идентификаторы инструмента и таймфрейма, а также признаки рыночного режима, торговой сессии, состояния волатильности или горизонта прогнозирования. После объединения данные проходят нелинейное преобразование с отдельными параметрами для каждого токена (per-token FFN). В результате формируются токены сценариев 𝑻s ∈ R(Ns+1)×ds, включая глобальный токен, и токены задач 𝑻t ∈ RNt×dt. Такая конструкция позволяет модели учитывать общий фон рынка и локальные отличия между режимами без необходимости строить отдельную архитектуру под каждый случай.
Первый этап взаимодействия реализуется на уровне токенов признаков анализируемой последовательности. Здесь модель сначала должна разобраться в самой рыночной структуре: как связаны между собой импульс, волатильность, объем, шум и ликвидность. Для этого может использоваться Self-Attention или более легкие схемы вроде TokenMixing. В общем виде взаимодействие дополняется нормализацией, остаточными связями и per-token FFN.
𝑻f(l+1) = PerTokenFFN(LN(TokenMixing(𝑻f(l)) + 𝑻f(l)))
Такой модуль формирует базовую выразительность модели. Он помогает выделить устойчивые зависимости, которые в рыночных данных часто спрятаны под слоем шума. На этом уровне модель учится различать, где начинается реальная динамика, а где рынок лишь делает короткий, ничего не значащий рывок.
Далее вступает в работу Domain-Feature Attention — механизм кросс-взаимодействия, в котором токены сценариев и задач выступают в роли запросов (Query), а признаковые токены — ключей и значений (Key/Value). Формально это реализуется как вариант Cross-Attention.
𝑻̂t/s(l+1) = SoftMax((WQ𝑻t/s(l))(WK 𝑻f(l))T / √d) WV 𝑻f(l)
Фактически на данном этапе контекст начинает направлять внимание модели. Если токен сценария описывает трендовый режим, он будет извлекать из признаков одни зависимости. Когда тот же рынок попадает в фазу боковика, акценты сместятся. Аналогично и токены задач. Токен, отвечающий за прогноз направления, будет искать одни связи, а в случае оценки вероятности события, логика отбора информации изменится. В итоге модель не просто усиливает или ослабляет признаки, она формирует их контекстно-зависимую интерпретацию. Это позволяет одно и то же рыночное движение читать по-разному в зависимости от сценария и цели анализа.
Завершающий этап — Domain-Fused Aggregation. Здесь информация агрегируется в итоговое представление, согласованное с текущим доменом. На практике этот блок отвечает за сценарно-задачное слияние. Для каждого примера отбираются только сценарные токены, соответствующие его контексту. Затем они объединяются с глобальным сценарным токеном через Mean-Pooling. Полученное агрегированное представление сценария напрямую добавляется к токенам задач.
В финансовой интерпретации это очень важный момент. Один и тот же сигнал не должен трактоваться одинаково в разные моменты рынка. Сигнал, который выглядит убедительно в устойчивом тренде, может потерять смысл в узком диапазоне или во время всплеска новостей. Именно поэтому связка сценария и задачи должна быть не общей, а адресной.
Такая схема выглядит предельно просто, но именно в этом и состоит ее сила. Модель связывает задачу только с теми сценарными условиями, которые действительно относятся к данному примеру, и тем самым сохраняет гибкость при совместном моделировании разных сценариев и задач. В результате формируется контекстно-зависимая интерпретация состояния системы.
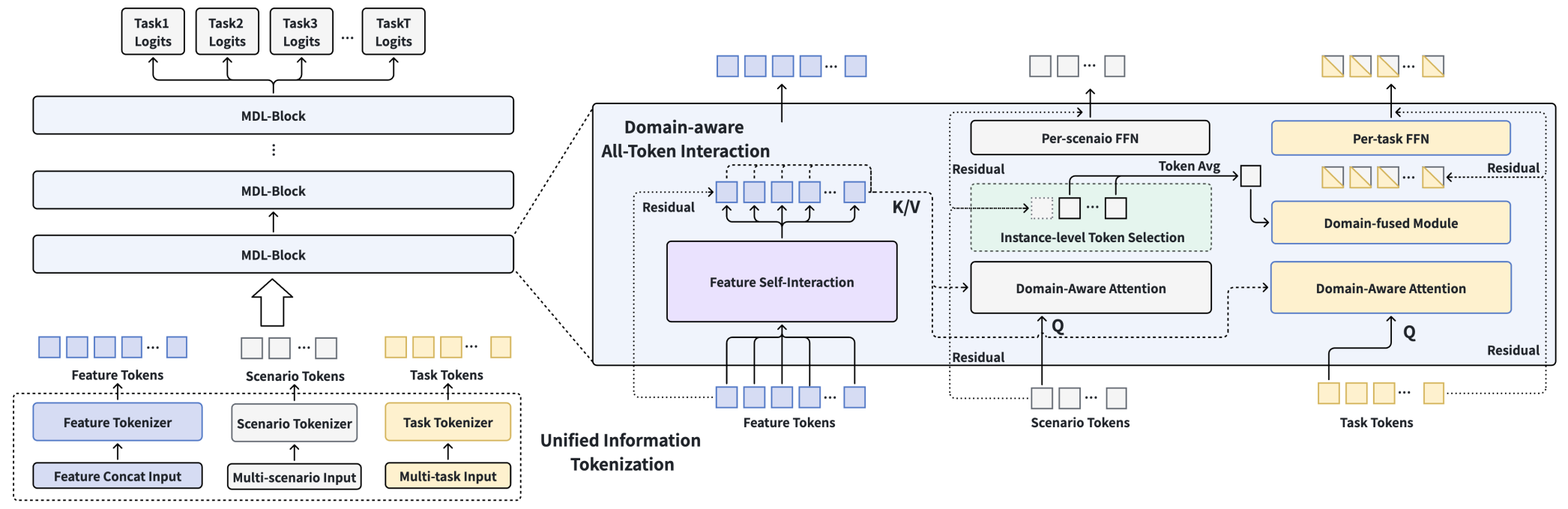
Зафиксируем логику работы одного MDL-блока. В нем происходит три согласованных процесса:
- Признаки последовательности уточняют свою структуру через Self-Attention.
- После уточнения признаков формируются два параллельных блока Cross-Attention. В них токены сценариев и задач независимо оценивают признаки в своем контексте.
- На завершающем этапе к токенам задач подмешиваются только релевантные сценарии. Их токены усредняются и суммируются с токенами задач.
Иными словами, внутри блока последовательно формируется цепочка: что происходит на рынке → в каком режиме это происходит → как это связано с поставленной задачей.
Такая организация важна с практической точки зрения. Модель не делает вывод на основе сырых признаков, она сначала структурирует данные, затем накладывает контекст и только после этого принимает решение. Это снижает чувствительность к шуму и делает поведение модели более устойчивым при смене рыночных условий.
Однако отдельный MDL-блок не является самостоятельной моделью. Его ценность раскрывается при объединении в последовательный стек. Каждый следующий блок работает уже с более уточненным представлением. Послойное уточнение напоминает классическую идею глубоких сетей, но с принципиальным отличием. Контекст (сценарий и задача) участвует в обработке на каждом уровне, а не только на выходе.
Практическая ценность создания стека MDL-блоков заключается в способности модели постепенно собирать рыночную картину. На ранних слоях она фиксирует грубые зависимости, на средних — начинает различать режимы, на поздних — формирует специализированные представления под конкретные задачи. Это особенно важно для финансовых данных. В потоке реальных данных сигнал редко бывает очевидным и часто проявляется только после последовательной фильтрации шума.
В контексте анализа финансовых рынков это дает принципиальное преимущество. Вместо жесткого разделения стратегий по режимам, мы получаем единую модель, которая сама адаптирует свое поведение. Она не переключается между сценариями, а плавно изменяет внутреннюю логику. В результате один и тот же архитектурный блок может использоваться для разных инструментов, таймфреймов и рыночных фаз, сохраняя согласованность и устойчивость. Именно эта способность к контекстно-зависимому анализу делает MDL перспективной основой для построения адаптивных торговых систем.
Реализация средствами MQL5
Перенос архитектуры фреймворка MDL в область финансовых рынков требует уточнения роли каждого компонента. В отличие от рекомендательных систем, где домены заданы явно, в трейдинге они носят более динамический и непрерывный характер.
Признаковые токены в финансовом контексте соответствуют рыночным данным. Их группировка может отражать различные аспекты рынка — трендовую компоненту, волатильность, ликвидность и структуру движения.
Токены сценариев интерпретируются как представление рыночных режимов. В отличие от жесткой классификации (trend/flat), они могут кодировать непрерывное состояние рынка: степень трендовости, уровень шума, фазу цикла. Это позволяет отказаться от дискретных переключателей и перейти к более гибкой модели поведения.
Токены задач отражают цели модели: прогноз направления, оценку доходности, вероятность события или генерацию торгового сигнала. В многозадачной постановке они позволяют одной архитектуре одновременно решать несколько задач без дублирования модели.
С точки зрения вычислительного процесса, Self-Attention выявляет зависимости между рыночными признаками. Domain-Feature Attention адаптирует их под текущий режим, а агрегирующий блок формирует итоговое представление, пригодное для принятия решений.
Таким образом, MDL в финансовой интерпретации превращается в универсальную систему анализа рынка. Она позволяет перейти от набора разрозненных моделей к единой архитектуре, способной учитывать контекст, адаптироваться к изменениям и сохранять устойчивость в различных рыночных условиях. Практическая реализация такой модели неизбежно носит поэтапный характер. Каждый компонент требует отдельной проработки и постепенной интеграции в общую систему.
Per-Token FFN
На первом этапе мы создадим модуль, который используется практически в каждом компоненте фреймворка, — Per-Token FFN. На первый взгляд он выглядит как обычный вспомогательный блок, но именно такие элементы чаще всего и определяют практическую пригодность архитектуры. В финансовой модели, где один и тот же сигнал может менять смысл в зависимости от режима рынка, таймфрейма или цели анализа, подобный модуль нужен для тонкой локальной настройки представления.
Простыми словами, Per-Token FFN отвечает за индивидуальную обработку каждого токена без разрушения общей структуры последовательности. Этот блок позволяет дочистить и уточнить каждый токен отдельно. Для признаков это означает более аккуратное выделение значимых зависимостей. Для токенов сценариев и задач — более точную настройку контекста, в котором они работают.
Именно поэтому Per-Token FFN удобно рассматривать как универсальный строительный элемент всей архитектуры. Он применяется фактически на каждом уровне, где требуется немного изменить форму данных, не разрушая смысл. В этом его практическая ценность: он делает представление более гибким, но не хаотичным.
Такой модуль особенно полезен при работе с нестационарными последовательностями финансовых данных. Рынок редко дает одинаково чистую картину два раза подряд, чаще он оставляет после себя набор похожих, но не тождественных состояний. И именно здесь Per-Token FFN помогает модели удерживать дисциплину в представлении. Он не пытается переосмыслить рынок целиком, его задача скромнее и, пожалуй, важнее: аккуратно преобразовать локальный токен так, чтобы следующий блок получил уже более осмысленный вход.
Для реализации независимого уточнения каждого токена наиболее уместно использовать объект CNeuronFieldAwareConv, построенный нами в рамках проекта Field-Aware Transformer. Этот класс хорошо соответствует нашей задаче не только по названию, но и по смыслу. Он представляет собой специализированный сверточный нейрон, который работает с модально-зависимой параметризацией. При этом мы не ограничиваемся использованием одного компонента. Вместо этого формируется отдельный модуль, представляющий собой композицию из двух последовательных слоев CNeuronFieldAwareConv с остаточной связью. Такой подход позволяет сохранить все преимущества Field-Aware параметризации и одновременно привести структуру к классическому виду FFN-блока.
class CNeuronPerTokenFFN : public CNeuronFieldAwareConv { protected: CNeuronFieldAwareConv cProj; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPerTokenFFN(void) {}; ~CNeuronPerTokenFFN(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; //--- virtual int Type(void) override const { return defNeuronPerTokenFFN; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; //--- virtual uint GetWindow(void) const { return cProj.GetWindow(); } };
С инженерной точки зрения CNeuronPerTokenFFN реализует двух шаговое преобразование токена. Первый слой (cProj) выполняет проекцию во внутреннее пространство признаков. Здесь модель получает возможность выделить более сложные зависимости. Второй слой (выполняется средствами родительского класса) возвращает представление в исходное пространство, завершая локальное преобразование. Остаточная связь замыкает этот контур, обеспечивая стабильность обучения и предотвращая деградацию представления при увеличении глубины модели.
Ключевой момент заключается в том, что оба слоя работают в режиме Field-Aware обработки. Это означает, что уточнение токена происходит с учетом структуры исходных данных. А использование CNeuronFieldAwareConv в качестве родительского класса позволяет учесть эту зависимость без явного введения дополнительных условий.
В методе инициализации формируется базовый контур из двух последовательных CNeuronFieldAwareConv. Он задаёт логику поэтапного уточнения токена.
bool CNeuronPerTokenFFN::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFieldAwareConv::Init(numOutputs, myIndex, open_cl, 2 * window, window, units, embed_size, candidates, topK, optimization_type, iBatch)) ReturnFalse; activation = None;
Вызов одноименного метода родительского класса конфигурирует внутреннюю структуру блока и связывает ее с параметрами вычислительной схемы. Функция активации на базовом уровне отключается, поскольку на выходе блока ожидается нормализация данных.
Затем инициализируется вложенный объект cProj. Он получает собственное окно, согласованное с внутренней размерностью блока, и те же параметры Field-Aware механизма.
if(!cProj.Init(0, 0, OpenCL, window, CNeuronFieldAwareConv::GetWindow(), GetFields(), embed_size, candidates, topK, optimization, iBatch)) ReturnFalse; cProj.SetActivationFunction(SoftPlus); //--- return true; }
Важная деталь состоит в том, что cProj получает функцию активации SoftPlus. И это не случайный выбор. Внутри Per-Token FFN проекция должна не обрезать информацию, а мягко сглаживать локальное преобразование токена, сохраняя его устойчивость и не разрушая накопленную структуру представления. Для финансовых данных такая мягкая нелинейность особенно уместна, она позволяет точнее обрабатывать слабые сигналы, не превращая модель в грубый пороговый фильтр.
После инициализации прямой проход блока читается как цельный и вполне рыночный процесс уточнения сигнала. Сначала токен проходит через промежуточную проекцию.
bool CNeuronPerTokenFFN::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cProj.FeedForward(NeuronOCL)) ReturnFalse;
Здесь его структура мягко перестраивается без смешивания с соседними элементами. Это важно, потому что в финансовых данных локальный контекст часто ценнее глобального усреднения.
Далее следует второе Field-Aware преобразование, которое усиливает сигнал и уточняет его форму с учетом структуры признаков.
if(!CNeuronFieldAwareConv::feedForward(cProj.AsObject()))
ReturnFalse;
На выходе результат не используется напрямую. Он добавляется к исходному токену через остаточную связь и приводится к устойчивому распределению за счет нормализации.
if(!SumAndNormalize(NeuronOCL.getOutput(), Output, Output, GetFilters(), true, 0, 0, 0, 1)) ReturnFalse; //--- return true; }
В итоге модель не переписывает вход, а аккуратно корректирует его, сохраняя баланс между новой информацией и исходной структурой.
Важно подчеркнуть, что Per-Token FFN не вводит дополнительный контекст в модель. В отличие от механизмов внимания, он не взаимодействует с другими токенами и не агрегирует внешнюю информацию. Его роль заключается в другом — он задает способ интерпретации токена через параметризованную функцию, специфичную для данного токена. Таким образом, контекст проявляется в самой структуре преобразования.
В терминах финансового анализа это выглядит как последовательная фильтрация. Сначала сигнал очищается от грубого шума, затем уточняется и только после этого приводится к форме, пригодной для дальнейших вычислений. Такая логика обеспечивает устойчивость при работе с нестационарными данными и позволяет наращивать глубину модели без потери контроля над распределением признаков.
В результате CNeuronPerTokenFFN становится адаптацией классического FFN из трансформеров под нестационарные данные. Он не смешивает информацию между токенами, а аккуратно уточняет каждый из них, сохраняя структурную независимость и при этом усиливая выразительность представления. Это хорошо согласуется с общей логикой MDL: разные типы токенов взаимодействуют через Attention, а локальная обработка остается строго контролируемой.
Практическое преимущество такого подхода проявляется при масштабировании модели. По мере увеличения числа слоев именно подобные локальные блоки начинают играть ключевую роль в устойчивости обучения. В финансовых задачах это особенно критично. Модель должна быть достаточно глубокой, чтобы выявлять сложные зависимости. Но при этом не терять устойчивость на шумных и изменчивых данных.
Генерация токенов сценариев
Следующим этапом практической реализации станет генерация токенов сценариев. И здесь мы сразу сталкиваемся с важным отличием финансового рынка от рекомендательных систем. В рекомендательной постановке сценарии обычно опираются на достаточно устойчивые признаки: тип интерфейса, место показа, формат взаимодействия, категорию контента. В рынке такой роскоши нет, здесь режимы не отделены друг от друга жесткими границами, а переходы между ними часто происходят плавно и почти незаметно. Один и тот же участок истории может содержать черты тренда, локальной коррекции, боковика и всплеска волатильности одновременно.
Именно поэтому сценарные токены в финансовой модели нельзя просто задать вручную или привязать к заранее фиксированным правилам. Модель должна научиться выделять их самостоятельно — через внутреннюю организацию признакового пространства и через механизм адаптивного разбиения данных на устойчивые контекстные области. Иначе говоря, речь идет не о статической разметке рынка, а о его динамической интерпретации внутри самой архитектуры.
Практически нам нужен алгоритм, который позволит модели формировать токены сценариев в процессе обучения. Такие токены должны появляться как результат выявления латентных рыночных состояний, а не как заранее навязанные категории. В этом и состоит принципиальное отличие нашей задачи.
Поэтому генерация сценарных токенов в нашем фреймворке должна строиться как механизм мягкой кластеризации или контекстного разделения признаков внутри модели. При этом возникает еще одно критически важное ограничение: алгоритм должен обладать низкой латентной задержкой. В трейдинге модель работает в режиме реального времени. Любая задержка напрямую влияет на качество исполнения и может нивелировать даже сильный сигнал. Это накладывает строгие требования на архитектуру. Генерация сценариев должна происходить быстро, без тяжелых итеративных процедур и с минимальным количеством дополнительных проходов по данным.
Фактически мы ищем компромисс между выразительностью и скоростью. Модель должна различать тонкие изменения состояния рынка и делать это в одном прямом проходе (или с минимальной дополнительной нагрузкой). Именно это ограничение будет определять выбор конкретного механизма генерации сценарных токенов и его интеграцию в общий конвеер операций.
Следствием ограничения времени выполнения становится еще одно важное ограничение — размер окна анализируемых данных. Чем шире окно, тем больше информации получает модель. Но тем выше вычислительная нагрузка и задержка. Сокращение окна, напротив, позволяет ускорить расчеты, но неизбежно приводит к потере контекста и снижению выразительности модели. В условиях финансового рынка это особенно критично. Значимая информация часто распределена во времени, и слишком короткое окно просто не позволяет ее зафиксировать.
Здесь возникает классический компромисс между глубиной анализа и скоростью реакции. И именно в этой точке на сцену выходят рекуррентные модели и модели пространства состояний. Их ключевое преимущество заключается в способности аккумулировать информацию во времени без необходимости хранить длинную историю исходных данных в явном виде. Модель как бы несет прошлое внутри своего состояния, что позволяет работать с компактным входным окном без существенной потери контекста.
В рамках данного проекта мы будем использовать 2D-модели пространства состояний. Такой выбор обусловлен тем, что они позволяют обрабатывать данные одновременно во временном и структурном измерениях. Это особенно хорошо согласуется с токенизированным представлением в MDL. В результате мы получаем механизм, который способен поддерживать богатое внутреннее состояние при ограниченном размере входного окна, сохраняя баланс между вычислительной эффективностью и выразительностью модели.
Предложенный подход мы реализуем в рамках объекта CNeuronScenariosToken, который объединяет два ключевых механизма: CNeuron2DSSMOCL и CNeuronFieldPatternEmbedding. Такое сочетание выбрано не случайно. Оно позволяет последовательно перейти от сырых рыночных данных к осмысленному сценарию без введения жестких правил или внешней разметки.
class CNeuronScenariosToken : public CNeuronFieldPatternEmbedding { protected: CNeuron2DSSMOCL cScenariosGenerator; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronScenariosToken(void) {}; ~CNeuronScenariosToken(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint fields, uint window_out, uint scenarios, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronScenariosToken; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual bool Clear(void) override; };
На первом этапе CNeuron2DSSMOCL формирует латентное состояние, аккумулируя информацию во времени и по структуре признаков. В отличие от простого расширения окна, здесь контекст не хранится в явном виде, а сжимается в компактное состояние, отражающее динамику рынка. Это особенно важно при ограничениях по латентности. Модель получает доступ к истории, не неся затрат на ее прямое хранение.
Далее CNeuronFieldPatternEmbedding преобразует это состояние в набор сценарных токенов. Он действует как механизм селекции и агрегации паттернов. Из обучаемого пространства кандидатов выбираются наиболее релевантные структуры, которые и формируют итоговое представление сценария. Таким образом, сценарий возникает как комбинация характерных рыночных состояний.
Архитектура объекта задается в методе инициализации. Здесь сначала управление передается родительскому классу, который отвечает за итоговое преобразование латентного представления в сценарные токены. В качестве входной размерности ему передается укороченное окно, то есть уже сжатое представление временного контекста. А также число сценариев, размер токенов и параметры отбора кандидатов. Тем самым сразу задается форма данных и режим их последующей интерпретации.
bool CNeuronScenariosToken::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint fields, uint window_out, uint scenarios, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFieldPatternEmbedding::Init(numOutputs, myIndex, open_cl, (window_in + 1) / 2, scenarios, window_out, candidates, topK, optimization_type, batch)) ReturnFalse;
Затем инициализируется cScenariosGenerator — объект CNeuron2DSSMOCL, который выступает в роли источника латентного состояния.
if(!cScenariosGenerator.Init(0, 0, OpenCL, window_in, (window_in + 1) / 2, fields, scenarios, optimization, iBatch)) ReturnFalse; //--- return true; }
2D-SSM получает полную рыночную последовательность и преобразует ее в компактное внутреннее состояние, которое затем будет интерпретировано средствами родительского класса.
Алгоритм непосредственной трансформации данных раскрывается уже в методе feedForward. Здесь архитектура работает в том порядке, в котором и должна работать в реальном времени. Сначала cScenariosGenerator формирует латентное состояние на основе текущего рыночного окна.
bool CNeuronScenariosToken::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cScenariosGenerator.FeedForward(NeuronOCL)) ReturnFalse;
А затем CNeuronFieldPatternEmbedding превращает это состояние в набор сценарных токенов.
if(!CNeuronFieldPatternEmbedding::feedForward(cScenariosGenerator.AsObject())) ReturnFalse; //--- return true; }
Важен не сам факт последовательного вызова двух объектов, а их функциональная роль. Первый блок собирает динамику и сжимает ее до компактного внутреннего представления. Второй — интерпретирует это представление и выделяет из него устойчивые паттерны, пригодные для дальнейшего использования в MDL.
Для финансового анализа это особенно ценно, потому что модель не получает готовый сценарий извне и не опирается на жесткую разметку рынка. Она сначала фиксирует текущее состояние последовательности. А затем уже на этой основе строит сценарное представление. Такой способ работы хорошо подходит для онлайн-анализа. Он позволяет модели быстро адаптироваться к изменению рыночной картины и при этом не терять структуру контекста. В итоге CNeuronScenariosToken реализует процесс извлечения и формализации сценария в условиях живого рынка.
Заключение
В этой статье мы познакомились с фреймворком MDL и его архитектурой — решением, которое изначально создавалось для рекомендательных систем и само по себе не было рассчитано на прямой анализ финансового контекста. При этом именно его внутренняя логика оказалась особенно полезной. MDL предлагает гибкую схему токенизации признаков, сценариев и задач, а значит, дает прочный каркас для построения универсальных моделей и структурированного представления данных. Мы взяли архитектуру, родившуюся в одной предметной области, и начали аккуратно переносить ее в другую — туда, где рынок живет быстрее, шумит громче и редко дает готовые ответы.
Практическая часть статьи была посвящена именно этому переносу. Мы не ограничились общим описанием идеи, а пошли пошагово: от архитектурных принципов — к первым рабочим блокам, пригодным для финансовых временных рядов. Такой подход важен. Многодоменное обучение имеет смысл только тогда, когда оно начинает работать в реальной среде. А реальная среда, как известно, не балует — данные шумные, режимы рынка размыты. А задержка в принятии решения иногда стоит дороже, чем сама ошибка.
В ходе работы были реализованы два базовых объекта, которые и формируют фундамент дальнейшего переноса MDL в область анализа финансовых рынков. Первый из них, CNeuronPerTokenFFN, отвечает за независимое уточнение каждого токена и задает локальную, но при этом устойчивую обработку признаков. Второй, CNeuronScenariosToken, строит сценарные токены на основе рыночной динамики. Эти модули пока не образуют завершенную систему, но уже задают ее опорный скелет.
Практическая ценность проделанной работы состоит в том, что контекст рынка перестает быть внешним пояснением к данным и начинает формироваться внутри самой модели. Это особенно важно для финансовых задач, где сценарии не имеют жестких границ и часто переходят один в другой почти незаметно. Здесь нельзя просто раздать ярлыки и считать задачу решенной. Контекст приходится извлекать, уточнять и удерживать в вычислительном контуре — быстро, аккуратно и без лишней тяжеловесности.
В следующей статье работа будет продолжена. Мы расширим перенос подходов MDL на задачи финансового анализа, добавим новые компоненты и приблизим архитектуру к полноценной прикладной реализации, способной уверенно работать в условиях реального рынка.
Ссылки
- MDL: A Unified Multi-Distribution Learner in Large-scale Industrial Recommendation through Tokenization
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн-обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн-обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Проект представлен по ссылке.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования