
Нейросети в трейдинге: Внимание, память и рыночные паттерны в GDformer

Введение
Финансовый рынок редко движется по прямой линии, он любит рывки, ложные пробои и резкие смены настроений. Вчера работала инерция, сегодня уже правит откат, а завтра в игру вмешивается новая волна волатильности. Для человека это привычная среда. Опытный аналитик быстро распознает знакомые режимы и замечает моменты, когда привычная структура начинает разрушаться. Для нейросети задача заметно сложнее. Ей недостаточно увидеть локальный фрагмент графика, необходимо определить, к какому рыночному состоянию относится текущее движение, чем оно отличается от предыдущих фаз и насколько похоже на уже известные модели поведения рынка.
Именно поэтому современные методы анализа временных рядов постепенно смещаются от локального восприятия к архитектурам памяти. Простого сверточного окна или стандартного Self-Attention уже недостаточно, когда данные нестационарны, шумны и контекстно-зависимы. В финансовых временных рядах это проявляется особенно резко. Один и тот же импульс в тренде и во флэте означает совершенно разные вещи. Одна и та же коррекция в спокойной фазе и в период новостного стресса приводит к разным торговым решениям. Следовательно, модель должна не только извлекать признаки, но и удерживать внутреннюю карту рыночных состояний, сопоставляя текущее наблюдение с накопленным опытом.
Дополнительную сложность создает сама природа финансовых временных рядов. Значимые события на рынке редко распределяются равномерно. Между двумя связанными фазами движения могут находиться десятки или сотни промежуточных баров, не несущих ключевой информации. В результате фиксированное окно анализа неизбежно становится компромиссом. Небольшое окно ограничивает способность модели видеть долгосрочные зависимости и пропускает удаленные причинно-следственные связи. Увеличение длины последовательности частично смягчает проблему, но резко повышает вычислительную сложность и объем обрабатываемых данных. При этом даже крупное окно не гарантирует, что действительно важные события окажутся внутри рассматриваемого диапазона. Рынок не подстраивает свою структуру под размер контекста модели.
Именно здесь обучаемая память приобретает особую ценность. В отличие от обычного окна наблюдения, память не привязана к длине анализируемой последовательности и не требует прямого присутствия всех значимых событий в анализируемом фрагменте. Она позволяет сопоставлять текущее состояние с ранее усвоенными рыночными сценариями независимо от того, насколько далеко во времени формировались аналогичные паттерны. Вместо бесконечного расширения окна внимания модель получает возможность обращаться к компактному набору уже сформированных устойчивых представлений о поведении рынка.
В этой логике особый интерес представляет фреймворк GDformer, представленный в работе "GDformer: Going Beyond Subsequence Isolation for Multivariate Time Series Anomaly Detection". Авторы дополняют классический механизм Cross-Attention обучаемой памятью и прототипами, формирующими дополнительный контекст состояния. В такой схеме текущая последовательность формирует запрос. Память выступает как набор адресуемых ячеек. А прототипы позволяют не только извлекать информацию, но и интерпретировать состояние системы в терминах устойчивых паттернов. Речь идет о сопоставлении текущего состояния с пространством ранее усвоенных режимов.
В рамках проекта GDformer рассматривается как основа нейросетевой модели для анализа рыночных паттернов, обучаемой памяти и режимной структуры финансовых временных рядов. Особое внимание будет уделено взаимодействию внимания, памяти и прототипов, а также адаптации фреймворка к задачам трейдинга. Практическая ценность подобного подхода заключается в способности модели сохранять устойчивость в условиях нестационарности, структурных сдвигов и высокой шумовой нагрузки. Рынок не любит простых решений. Но он хорошо вознаграждает модели, способные различать режимы и сохранять ориентацию даже тогда, когда большая часть поверхностных сигналов становится ненадежной.
Алгоритм GDformer
Изначально фреймворк GDformer был предложен авторами для решения задачи поиска аномалий в многомерных временных рядах. Основная идея работы строится вокруг проблемы так называемой Subsequence Isolation — изолированного анализа отдельных фрагментов последовательности. Авторы отмечают, что многие современные модели рассматривают временной ряд как набор локальных окон, внутри которых и выполняется поиск закономерностей. Такой подход позволяет эффективно анализировать краткосрочные зависимости, однако плохо учитывает глобальную структуру последовательности. В результате модель может успешно реконструировать отдельные участки данных, но при этом терять понимание общего контекста и взаимосвязей между удаленными событиями.
Для финансовых временных рядов эта проблема особенно актуальна. Значимые рыночные события нередко разделены большими временными интервалами, а локально похожие фрагменты могут иметь совершенно разный смысл в зависимости от текущего режима рынка. Поэтому идея использования глобальной памяти вместо жесткой привязки к фиксированному окну анализа представляет практический интерес не только для поиска аномалий, но и для более широкого класса задач, связанных с анализом рыночного поведения.
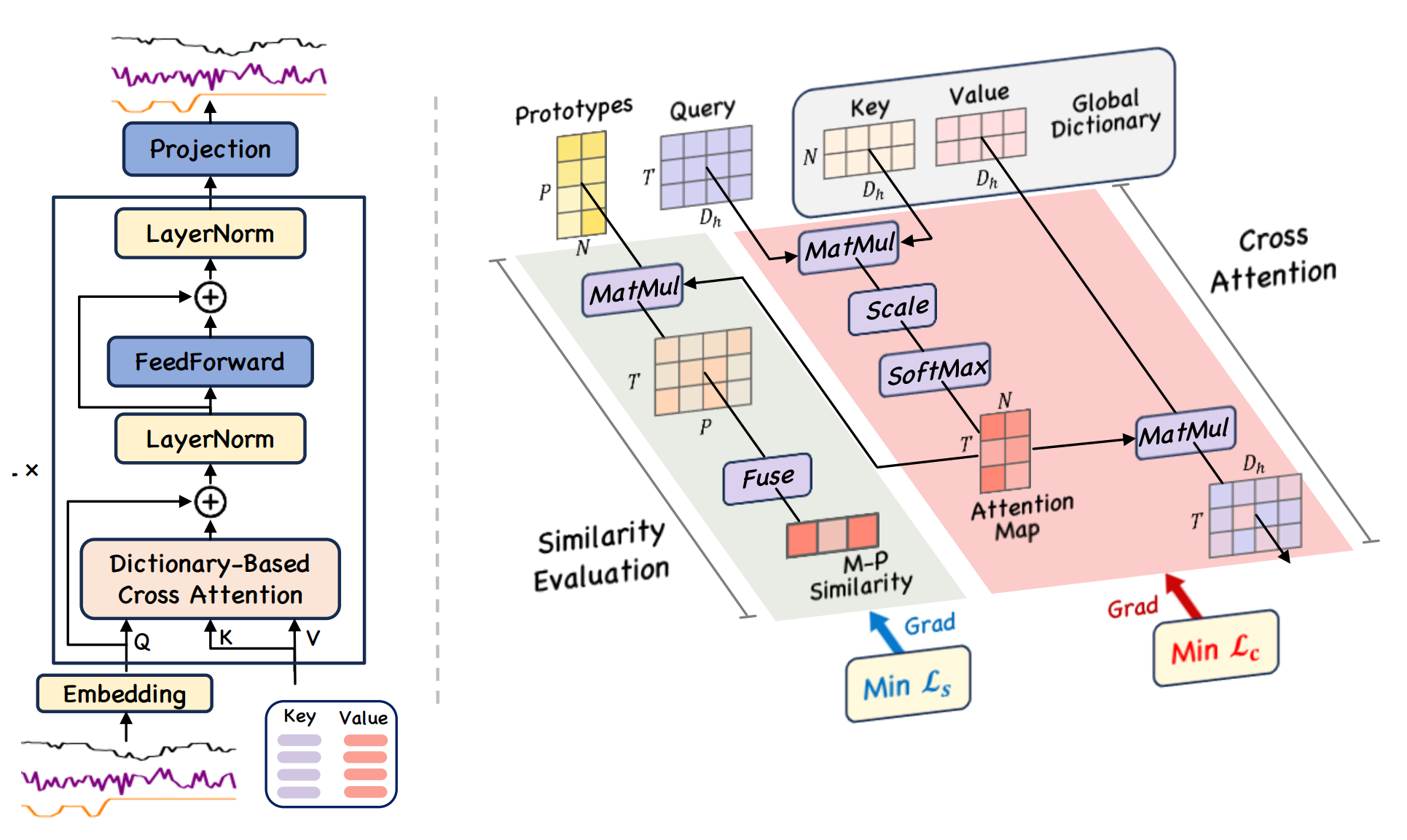
В основе GDformer лежит Dictionary-based Cross-Attention — модифицированный механизм внимания, использующий глобальный словарь обучаемых токенов ключей и значений. В отличие от классического Transformer, где ключи и значения формируются как линейные проекции анализируемых данных, здесь они представлены отдельными обучаемыми параметрами модели. Такой подход позволяет хранить и переиспользовать глобальные представления временного ряда вместо анализа исключительно локальных зависимостей внутри текущего окна.
Фактически модель получает собственную память, не привязанную напрямую к анализируемому состоянию окружающей среды. Это важное отличие архитектуры. Вместо постоянного поиска зависимостей исключительно внутри локального контекста модель получает возможность сопоставлять текущее состояние с ранее сформированными внутренними представлениями временного ряда.
Перед подачей данных в Transformer-блоки выполняется этап подготовки входной последовательности. Часть наблюдений случайным образом маскируется с вероятностью α. При этом авторы специально избегают полного маскирования отдельных временных точек или целых каналов данных. Такой подход позволяет сохранить межканальные зависимости и одновременно снижает риск переобучения на отдельных признаках. После маскирования применяется нормализация, уменьшающая влияние шумов и локальных выбросов.
Далее входная последовательность проецируется в пространство скрытых представлений размерности D. Каждая временная точка после преобразования рассматривается как Temporal Token — аналог токена в языковых моделях, но адаптированный для временных рядов. Полученная последовательность поступает на вход стека Transformer-слоев.
Архитектура GDformer строится как последовательность блоков внимания и Feed-Forward слоев. Ключевое отличие GDformer от классического Transformer проявляется именно внутри механизма внимания. В Self-Attention матрицы Query, Key и Value получают из одной входной последовательности линейными проекциями. Поэтому модель ищет зависимости только внутри текущего окна. Иными словами, модель ищет зависимости исключительно внутри текущего анализируемого окна. Такой подход хорошо работает для локального контекста, однако ограничен фиксированным горизонтом наблюдения. В результате сеть изучает главным образом внутрисегментные зависимости, тогда как глобальные взаимосвязи между удаленными участками временного ряда остаются за пределами внимания модели.
Авторы GDformer называют эту проблему Subsequence Isolation. Аномальные состояния могут проявляться по-разному в различных частях временного ряда, а локально похожие паттерны способны соответствовать совершенно разным глобальным режимам. Следовательно, анализ изолированных подпоследовательностей затрудняет формирование единого критерия оценки нормального и аномального поведения.
Для преодоления этого ограничения в GDformer используется Dictionary-based Cross-Attention. На каждом Transformer-слое поддерживается собственный глобальный словарь памяти, содержащий обучаемые матрицы Key и Value. Только Query формируется из текущей последовательности. Таким образом текущее состояние используется как запрос к накопленным внутренним представлениям, а не только к соседним элементам внутри локального окна.
Для каждой головы внимания используется собственная часть словаря. Причем авторы GDformer не применяют дополнительные линейные проекции для формирования Key и Value отдельных голов. Вместо этого общий словарь напрямую разделяется между головами внимания. Такое решение уменьшает вычислительную сложность и одновременно позволяет различным головам внимания специализироваться на разных типах временных зависимостей.
Полученные представления всех голов внимания объединяются и формируют новое состояние последовательности. В процессе обучения глобальный словарь постепенно обновляется на всех временных точках обучающей выборки. Благодаря этому память начинает хранить устойчивые представления нормальных режимов поведения временного ряда.
Для финансовых данных подобный подход представляет особый интерес. В отличие от обычного оконного анализа модель получает возможность сопоставлять текущее состояние рынка с глобальными паттернами, накопленными в памяти, даже если аналогичные события находились далеко за пределами текущего окна наблюдения. Фактически словарь начинает играть роль внутренней библиотеки рыночных сценариев.
Дополнительным преимуществом архитектуры является снижение вычислительной сложности. В классическом Self-Attention вычисления имеют сложность O(T²) поскольку каждый элемент последовательности сравнивается со всеми остальными. В GDformer сложность Dictionary-based Cross-Attention определяется O(TN), где размер словаря N существенно меньше длины последовательности T. Это позволяет одновременно уменьшить вычислительные затраты и снизить требования к памяти модели.
Надо сказать, что особенность GDformer проявляется не только в использовании глобального словаря памяти. Авторы фреймворка предлагают новую интерпретацию механизма внимания. В классических Transformer-архитектурах механизмы внимания обычно рассматриваются как промежуточный инструмент извлечения информации. Модель вычисляет веса соответствия между Query и Key, агрегирует значения Value и формирует новое скрытое представление последовательности. На этом роль внимания фактически завершается.
В GDformer сама структура механизма внимания начинает выступать объектом анализа. После вычисления Cross-Attention модель получает матрицу распределения весов внимания между текущей временной точкой и элементами глобального словаря памяти. Иными словами, карта внимания показывает, какие ячейки памяти были активированы и характер обращения текущего состояния к глобальным представлениям временного ряда.
Именно здесь авторы GDformer делают важный шаг за пределы обычного reconstruction-подхода. В традиционных методах детекции аномалий основное внимание обычно сосредоточено на ошибке восстановления или статистическом различии распределений. Однако подобные меры далеко не всегда отражают внутреннюю структуру временных паттернов. Два состояния могут иметь близкие статистические характеристики, но принципиально различаться по логике формирования зависимостей внутри системы.
Для решения этой задачи в GDformer вводится дополнительная Similarity Branch. В каждом Transformer-слое поддерживается набор прототипов, которые описывают типовые схемы распределения внимания по памяти. Фактически они моделируют характерные способы активации глобальных представлений для нормальных состояний системы.
После нормализации прототипов модель вычисляет сходство между картой внимания и представлениями прототипов. Таким образом анализируется структура обращения к памяти. Каждый элемент матрицы сходства показывает, насколько распределение внимания текущей временной точки похоже на один из типовых шаблонов активации памяти. Далее значения агрегируются в итоговую оценку Similarity Strength, характеризующую степень согласованности текущего состояния с нормальными режимами поведения временного ряда.
Подобная постановка принципиально меняет логику работы модели. GDformer оценивает не только то, насколько хорошо состояние реконструируется, но и насколько естественным образом оно взаимодействует с глобальной памятью. В результате механизм внимания перестает быть исключительно вычислительным процессом и превращается в источник дополнительной информации о структуре временного ряда.
Для финансовых временных рядов такая идея представляет особый интерес. Рыночные аномалии далеко не всегда выглядят как полностью неизвестные паттерны. Гораздо чаще рынок формирует необычные комбинации уже знакомых состояний. Например, импульсное движение может сопровождаться нетипичным распределением ликвидности, а фаза консолидации — аномальной структурой волатильности. Внешне отдельные элементы подобного режима могут выглядеть вполне привычно, однако сама схема взаимодействия рыночных факторов оказывается нестандартной.
В этом случае Prototype Branch позволяет анализировать локальные признаки и характер их связи с глобальными режимами рынка. Фактически модель начинает контролировать не только результат извлечения информации из памяти, но и сам механизм обращения к ней. Именно это делает GDformer значительно более содержательной архитектурой по сравнению с классическими Reconstruction-Based моделями анализа временных рядов.
Обучение GDformer строится вокруг двух взаимосвязанных задач. Первая отвечает за реконструкцию исходной последовательности. Вторая — за формирование устойчивых шаблонов взаимодействия между временными представлениями и глобальной памятью. Именно сочетание этих двух механизмов формирует ту логику работы модели, которая отличает GDformer.
Для обучения глобального словаря используется функция потерь реконструкции текущего состояния системы. Этот компонент заставляет модель формировать в памяти устойчивые представления нормальных состояний временного ряда. Чем лучше память описывает типичное поведение системы, тем точнее модель способна восстанавливать исходные данные.
Однако одной реконструкции недостаточно. Даже аномальные состояния в ряде случаев могут восстанавливаться достаточно хорошо, особенно если локально они похожи на уже встречавшиеся паттерны. Поэтому авторы дополняют архитектуру вторым механизмом — Similarity Discrepancy Loss. Этот компонент оценивает степень сходства между распределениями карты внимания текущих временных точек и прототипами шаблонов нормального поведения.
Здесь проявляется одна из наиболее интересных особенностей GDformer. Модель обучается восстанавливать временной ряд и поддерживать согласованную структуру обращения к глобальной памяти. Другими словами, нормальное состояние должно не просто хорошо реконструироваться — оно должно естественным образом активировать память модели.
Благодаря этому модель начинает учитывать многомасштабную структуру временного ряда. Одни слои фиксируют локальные зависимости, другие — более глобальные закономерности. В результате Prototype Branch постепенно формирует устойчивые шаблоны нормального взаимодействия с памятью.
Реализация средствами MQL5
В условиях трейдинга перед нами стоит несколько иная задача, чем в оригинальной постановке GDformer. Авторы фреймворка ориентируются на поиск аномалий в многомерных временных рядах. Модель должна выявлять состояния, отклоняющиеся от нормального поведения системы. Для финансовых рынков подобный подход полезен лишь частично. Трейдера интересуют не сами аномалии, а устойчивые рыночные паттерны, внутри которых можно принимать торговые решения с приемлемым уровнем риска. Иными словами, задача смещается от обнаружения отклонений к поиску повторяющихся режимов поведения рынка.
Тем не менее сама идея поиска аномалий остается весьма ценной. Финансовый рынок регулярно входит в состояния повышенной неопределенности: резкие новостные импульсы, кризисные разрывы ликвидности, хаотичные переходные фазы между режимами. В такие моменты большинство привычных зависимостей начинает разрушаться. Поэтому способность модели распознавать нетипичные состояния может использоваться не как основной торговый сигнал, а как механизм ограничения риска. Если система обнаруживает, что текущее состояние слишком слабо соответствует известным паттернам памяти, наиболее разумным действием часто оказывается отказ от входа в рынок.
Именно поэтому адаптация GDformer к задачам трейдинга требует изменений не только на уровне программной реализации, но и на уровне самой интерпретации архитектуры. В оригинальной работе глобальный словарь памяти обучается как представление нормального поведения временного ряда. В торговой постановке память начинает играть роль библиотеки рыночных режимов и сценариев. Механизм внимания используется для сопоставления текущего состояния рынка с ранее выученными конфигурациями движения цены, волатильности, ликвидности и импульса.
При этом особую ценность приобретает способность модели оценивать степень уверенности в собственной интерпретации рынка. Классический SoftMax-Attention всегда формирует нормализованное распределение весов, даже если текущее состояние одинаково слабо соответствует всем элементам памяти. Для финансовых временных рядов это может приводить к опасному эффекту ложной уверенности. Модель начинает насильно сопоставлять рынок с ближайшими известными паттернами даже тогда, когда действительно надежного соответствия не существует.
По этой причине в нашей интерпретации особое внимание уделяется разреженным механизмам внимания. После вычисления Similarity Scores сохраняются только наиболее значимые связи, тогда как остальные коэффициенты подавляются. При этом веса используются без дополнительной перенормализации. Такой подход позволяет сохранить абсолютную величину сходства между текущим состоянием и памятью модели. Если релевантный паттерн отсутствует, система получает возможность явно зафиксировать низкий уровень уверенности вместо искусственного формирования "лучшего совпадения".
С практической точки зрения это особенно важно для торговых систем. Наиболее опасные убытки часто возникают не в моменты явного тренда или устойчивого бокового движения, а в фазах структурной неопределенности, когда рынок перестает соответствовать привычным сценариям. В подобных условиях способность модели распознавать отсутствие надежного паттерна оказывается не менее полезной, чем способность находить сильные сигналы.
Важную роль играет инициализация памяти. Использование одинаковых начальных значений быстро приводит к деградации словаря, когда различные ячейки начинают обучаться синхронно и теряют специализацию. Поэтому Key и Value инициализируются случайными параметрами с малой дисперсией. Это создает начальное разнообразие траекторий обучения и позволяет памяти постепенно разделяться между различными режимами рынка.
Прототипы реализуются как отдельные обучаемые матрицы. В торговой интерпретации они начинают отражать характерные схемы активации рыночных режимов. Фактически Prototype Branch превращается в механизм оценки того, насколько естественным образом текущее состояние рынка взаимодействует с глобальной памятью модели.
Таким образом, при адаптации GDformer к задачам трейдинга сама логика архитектуры постепенно смещается от поиска аномалий к анализу устойчивости рыночных сценариев. Память модели начинает играть роль системы накопления рыночного опыта. Attention — механизмом обращения к этому опыту. А Similarity Branch — инструментом оценки согласованности текущего состояния с ранее наблюдаемыми режимами рынка.
Здесь стоит отметить, что впереди нас ожидает достаточно большой объем работы, который явно выходит за рамки одной статьи. Адаптация GDformer к задачам трейдинга затрагивает принципы организации памяти, методы обучения и вопросы вычислительной эффективности. Полноценная реализация подобного фреймворка требует последовательной и аккуратной проработки каждого компонента. Поэтому двигаться будем постепенно, шаг за шагом, сохраняя возможность анализировать влияние отдельных архитектурных решений на итоговое поведение модели.
На первом этапе сосредоточимся на базовом элементе всей архитектуры — механизме Dictionary-based Cross-Attention. Именно он формирует основу взаимодействия текущего состояния рынка с глобальной памятью модели. От качества его реализации напрямую зависит эффективность последующего обучения памяти, стабильность механизма внимания и способность модели удерживать устойчивые рыночные паттерны.
Поскольку вычисление внимания связано с большим количеством матричных операций, реализация исключительно средствами CPU быстро становится узким местом при работе с длинными последовательностями и многоголовым вниманием. Особенно заметно это проявляется в задачах финансового анализа, где модель одновременно обрабатывает множество признаков. Поэтому уже на начальном этапе целесообразно перенести наиболее тяжелые вычисления на сторону OpenCL-программы.
Прямой проход целесообразно реализовать в едином кернеле MHCrossAttvsSim. Это снижает число обменов промежуточными тензорами между памятью терминала и вычислительным устройством, что критично для внимания с большим числом матричных операций. Фактически кернел берет на себя сразу несколько задач: вычисление SoftMax, разреженную фильтрацию внимания, агрегацию Value и одновременное формирование Similarity Branch.
__kernel void MHCrossAttvsSim(__global const float *query, __global const float *key, __global const float *value, __global const float *prototype, __global const float *levels, __global float *logsumexp, __global float *output_at, __global float *similarity, const int dimension, const int total_X) { const int q_id = get_global_id(0); const int local_id = get_local_id(1); const int h_id = get_global_id(2); const int total_q = get_global_size(0); const int total_loc = get_local_size(1); const int total_heads = get_global_size(2); //--- __local float temp[LOCAL_ARRAY_SIZE]; __local float4 temp4[LOCAL_ARRAY_SIZE];
В представленной реализации каждая рабочая группа обрабатывает отдельный Query-вектор для конкретной головы внимания. Это хорошо согласуется с логикой GDformer, где каждая голова использует собственную специализированную память. Подобное разделение особенно важно для финансовых временных рядов, поскольку различные головы внимания могут постепенно адаптироваться к различным типам рыночных режимов: трендовым фазам, импульсным движениям, волатильным переходам или консолидациям.
Ключевой особенностью представленной реализации становится двухпроходная схема вычислений. На первом проходе выполняется online-SoftMax с вычислением LogSumExp.
const int shift_q = RCtoFlat(h_id, 0, total_heads, dimension, q_id); const int logse_shift = RCtoFlat(q_id, h_id, total_q, total_heads, 0); const float threshold = levels[logse_shift]; /* Loop 1: compute LogSumExp via online SoftMax (no masking) */ float prev_max = MIN_VALUE; float sumexp = 0.0f; for(int id = 0; id < total_X; id += total_loc) { int x_id = id + local_id; const int shift_x = RCtoFlat(h_id, 0, total_heads, dimension, x_id); float score = 0.0f; if(x_id < total_X) { for(int d = 0; d < dimension; d += 4) { float4 q = IsNaNOrInf4((float4)( query[shift_q + d], ((d + 1) < dimension ? query[shift_q + d + 1] : 0.0f), ((d + 2) < dimension ? query[shift_q + d + 2] : 0.0f), ((d + 3) < dimension ? query[shift_q + d + 3] : 0.0f) ), 0.0f); float4 k = IsNaNOrInf4((float4)( key[shift_x + d], ((d + 1) < dimension ? key[shift_x + d + 1] : 0.0f), ((d + 2) < dimension ? key[shift_x + d + 2] : 0.0f), ((d + 3) < dimension ? key[shift_x + d + 3] : 0.0f) ), 0.0f); score += IsNaNOrInf(dot(q, k), 0.0f); } score /= sqrt((float)dimension); } else score = MIN_VALUE; float max = fmax(prev_max, LocalMax(score, 1, temp)); score = (score > MIN_VALUE) ? IsNaNOrInf(exp(score - max), 0.0f) : 0.0f; if(sumexp == 0.0f) sumexp = LocalSum(score, 1, temp); else sumexp = IsNaNOrInf(exp(prev_max - max) * sumexp, 0.0f) + LocalSum(score, 1, temp); prev_max = max; }
Такой подход позволяет избежать численной нестабильности при работе с большими последовательностями. Вместо хранения полной карты внимания мы последовательно обновляем максимум и сумму экспонент.
Подобная схема особенно важна при работе с финансовыми данными, где отдельные признаки могут формировать крайне неравномерные распределения внимания. Обычный SoftMax в подобных условиях быстро начинает страдать от переполнений или деградации градиентов. А данный алгоритм даёт устойчивую нормировку коэффициентов внимания без необходимости хранения полной карты.
//--- Write LogSumExp const float lse = (sumexp > 0.0f) ? IsNaNOrInf(prev_max + log(sumexp), 0.0f) : 0.0f; if(local_id == 0) logsumexp[logse_shift] = lse;
Второй проход выполняет уже непосредственную агрегацию значений и прототипов с учетом нормированных коэффициентов внимания.
/* Loop 2: accumulate value and similarity score = exp(score - lse); skip if score < threshold scores are already normalized — no division by sumexp needed */ float out_at = 0.0f; float out_sim = 0.0f; for(int id = 0; id < total_X; id += total_loc) { int x_id = id + local_id; const int shift_x = RCtoFlat(h_id, 0, total_heads, dimension, x_id); float score = 0.0f; if(x_id < total_X && sumexp > 0.0f) { for(int d = 0; d < dimension; d += 4) { float4 q = IsNaNOrInf4((float4)( query[shift_q + d], ((d + 1) < dimension ? query[shift_q + d + 1] : 0.0f), ((d + 2) < dimension ? query[shift_q + d + 2] : 0.0f), ((d + 3) < dimension ? query[shift_q + d + 3] : 0.0f) ), 0.0f); float4 k = IsNaNOrInf4((float4)( key[shift_x + d], ((d + 1) < dimension ? key[shift_x + d + 1] : 0.0f), ((d + 2) < dimension ? key[shift_x + d + 2] : 0.0f), ((d + 3) < dimension ? key[shift_x + d + 3] : 0.0f) ), 0.0f); score += IsNaNOrInf(dot(q, k), 0.0f); } score /= sqrt((float)dimension); score = IsNaNOrInf(exp(score - lse), 0.0f);
Именно здесь реализуется одна из ключевых модификаций архитектуры для задач трейдинга. После вычисления нормированных коэффициентов внимания применяется пороговая фильтрация.
if(score < threshold) score = 0.0f; }
Фактически кернел реализует упрощенную схему Sparse-Attention. Слабые соответствия между текущим состоянием и памятью модели подавляются еще до агрегации Value. Это особенно важно для финансовых временных рядов, где рынок регулярно формирует промежуточные состояния, одинаково далекие от большинства известных паттернов памяти.
В классическом SoftMax даже слабые совпадения вынужденно перераспределяются в нормализованное распределение вероятностей. Использование механизма пороговой фильтрации позволяет сохранить более честную структуру активации внимания. Если текущее состояние действительно не соответствует памяти, значительная часть коэффициентов просто обнуляется.
При этом после пороговой фильтрации мы сознательно не выполняем повторного нормирования оставшихся коэффициентов внимания, хотя такая процедура предусматривается большинством алгоритмов разреженного внимания. Это важный момент. В задачах финансового анализа повторная нормализация может приводить к нежелательному эффекту искусственного усиления слабых зависимостей. Даже если рынок лишь отдаленно напоминает известные паттерны, модель все равно будет вынуждена формировать уверенное распределение внимания.
В рассматриваемой реализации используется иная логика. Коэффициенты внимания сохраняют свою абсолютную величину сходства с памятью модели. Если после применения порога значительная часть коэффициентов оказывается близкой к нулю, это трактуется не как проблема вычислений, а как полезная информация о состоянии рынка. Более того, мы допускаем ситуацию полного обнуления коэффициентов внимания.
С практической точки зрения это выглядит вполне естественно. Опытный трейдер не пытается открыть позицию в любой рыночной ситуации. При отсутствии понятных и устойчивых паттернов наиболее разумным решением часто становится отказ от входа в рынок. Аналогичным образом ведет себя и механизм внимания модели. Если текущее состояние не демонстрирует достаточного сходства с выученными структурами памяти, система не пытается притянуть за уши анализируемую ситуацию к ближайшему известному сценарию.
Подобный подход особенно важен для финансовых временных рядов, где промежуточные и переходные режимы встречаются значительно чаще, чем устойчивые трендовые структуры. Возможность явно фиксировать отсутствие надежного соответствия между текущим состоянием и памятью модели делает поведение архитектуры более устойчивым и ближе к реальной логике принятия торговых решений.
Особенно интересно, что кернел одновременно формирует два выходных потока. Первый поток соответствует стандартной агрегации Value. Он формирует итоговое представление механизма внимания, используемое далее в Transformer-стеке.
for(int d = 0; d < dimension; d += 4) { float4 val = (float4)0.0f; float4 sim = (float4)0.0f; if(score > 0.0f) { float4 v = IsNaNOrInf4((float4)( value[shift_x + d], ((d + 1) < dimension ? value[shift_x + d + 1] : 0.0f), ((d + 2) < dimension ? value[shift_x + d + 2] : 0.0f), ((d + 3) < dimension ? value[shift_x + d + 3] : 0.0f) ), 0.0f); float4 p = IsNaNOrInf4((float4)( prototype[shift_x + d], ((d + 1) < dimension ? prototype[shift_x + d + 1] : 0.0f), ((d + 2) < dimension ? prototype[shift_x + d + 2] : 0.0f), ((d + 3) < dimension ? prototype[shift_x + d + 3] : 0.0f) ), 0.0f); val = IsNaNOrInf4(v * score, 0.0f); sim = IsNaNOrInf4(p * score, 0.0f); } val = LocalSum4(val, 1, temp4); sim = LocalSum4(sim, 1, temp4); int idx = local_id - d; if(idx >= 0 && idx < 4) { out_at += vget4(val, idx); out_sim += vget4(sim, idx); } } }
Второй поток агрегирует Similarity Branch. Таким образом представление сходства строится параллельно основному потоку внимания без необходимости повторного вычисления карты внимания. С вычислительной точки зрения это весьма удачное решение. Наиболее дорогая операция — вычисление коэффициентов между Query и Key — выполняется только один раз, после чего те же веса внимания используются одновременно и для Reconstruction Branch, и для Similarity Branch.
Отдельного внимания заслуживает использование векторных типов float4. Обработка данных блоками по четыре элемента позволяет лучше загружать SIMD-блоки GPU и уменьшает количество отдельных операций чтения памяти. Для механизмов внимания это особенно важно, поскольку производительность подобных алгоритмов обычно ограничивается не арифметикой, а пропускной способностью памяти.
Дополнительно кернел активно использует локальную память. Через нее реализуются операции суммирования и поиска максимального значения между потоками рабочей группы. Это уменьшает количество обращений к глобальной памяти и существенно ускоряет вычисление статистик внимания.
//--- Write results (weights already normalized via lse) if(local_id < dimension) { output_at[shift_q + local_id] = IsNaNOrInf(out_at, 0.0f); similarity[shift_q + local_id] = IsNaNOrInf(out_sim, 0.0f); } }
Реализованный кернел объединяет несколько компонентов GDformer. Для алгоритмического трейдинга это важно: эффективность вычислений ограничивает сложность модели и длину последовательностей, обрабатываемых в реальном времени.
Заключение
В данной статье была рассмотрена архитектура GDformer и показано, что ее идеи выходят далеко за рамки исходной задачи поиска аномалий в многомерных временных рядах. Обучаемая память, Dictionary-based Cross-Attention и Similarity Branch задают более содержательную логику работы с последовательностями. Модель сопоставляет текущее состояние не только с локальным контекстом, но и с устойчивыми шаблонами поведения. Для задач трейдинга это особенно ценно, поскольку рынок чаще требует не выявления ошибки, а распознавания надежного паттерна, внутри которого можно принимать решение.
Отдельное внимание было уделено практической интерпретации механизма внимания. В предложенной схеме он перестает быть просто инструментом агрегации признаков и становится способом оценки согласованности текущего состояния рынка с памятью модели. Разреженная фильтрация без повторного перенормирования коэффициентов позволяет не усиливать слабые зависимости и не создавать искусственную уверенность там, где рынок не демонстрирует явного соответствия выученным паттернам. Это делает поведение модели ближе к реальной логике торгового решения, когда отсутствие надежного сигнала важнее формального совпадения.
Рассмотрена реализация Dictionary-based Cross-Attention средствами OpenCL. Перенос прямого прохода на GPU позволяет объединить вычисление сходства, online-SoftMax, разреженную фильтрацию и формирование выходных представлений в едином блоке, что важно для вычислительной эффективности. Тем самым создается прочная основа для дальнейших шагов проекта и последующего перехода к полноценной торговой интерпретации модели.
Ссылки
- GDformer: Going Beyond Subsequence Isolation for Multivariate Time Series Anomaly Detection
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн-обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн-обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Проект представлен на forge.mql5.io/dng.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования