
Нейросети в трейдинге: Внимание, память и рыночные паттерны в GDformer (Global Dictionary)

Введение
Трейдинг сталкивается с одной трудностью: рыночный сигнал почти никогда не бывает чистым. Локальное движение цены часто маскирует смену режима, ложный пробой или краткосрочный шум. В таких условиях обычного наблюдения за отдельными свечами и стандартными индикаторами уже недостаточно. Нужен подход, который способен не просто фиксировать локальную форму графика, а распознавать устойчивый рыночный контекст и сопоставлять текущее состояние цены с уже известными сценариями поведения.
Именно здесь начинают проявляться ограничения многих классических методов анализа временных рядов. Технические индикаторы хорошо работают в стабильных условиях, но быстро теряют устойчивость при смене характера рынка. Нейросетевые модели, опирающиеся только на локальное окно наблюдения, нередко становятся заложниками краткосрочной структуры данных. Модель видит фрагмент движения, но не понимает, насколько он характерен для более широкой картины рынка. Как следствие, кратковременный импульс может быть ошибочно принят за начало устойчивого тренда, а локальная коррекция — за полноценный разворот. Рынок же редко прощает подобную близорукость. Финансовые ряды шумны и изменчивы, поэтому системе анализа нужна не только оценка текущего состояния цены, но и память о ранее встречавшихся сценариях.
Именно такую задачу и пытается решить фреймворк GDformer. В его основе лежит достаточно простая, но крайне важная идея: вместо изолированного анализа отдельных подпоследовательностей модель формирует глобальное представление о структуре данных и использует специальный словарь характерных паттернов для сопоставления текущего состояния с уже накопленным опытом. Фактически речь идет о переходе от локального наблюдения к контекстному анализу. Если традиционные механизмы внимания часто концентрируются лишь на ближайшем окружении, то GDformer вводит дополнительный уровень памяти, позволяющий учитывать глобальные зависимости внутри временного ряда.
Подобный подход особенно хорошо ложится на задачи финансового анализа. Рынок постоянно воспроизводит схожие состояния: накопление ликвидности, импульсное расширение диапазона, затухание волатильности, панические выбросы, инерционное продолжение движения или медленное перераспределение позиций. Внешне эти режимы никогда не повторяются идеально, но их структурная логика остается узнаваемой. Именно поэтому идея глобального словаря приобретает здесь вполне прикладной смысл. Такой словарь можно рассматривать как набор устойчивых рыночных сценариев, с которыми система сопоставляет текущую динамику цены. В результате модель начинает анализировать не отдельную свечу или локальный фрагмент графика, а положение текущего состояния внутри более широкой рыночной структуры.
В предыдущей статье мы рассмотрели общую организацию фреймворка GDformer, структуру потоков данных и роль глобальной памяти в распознавании рыночных состояний. Отдельно рассмотрен перенос подходов фреймворка в задачи трейдинга и анализа финансовых временных рядов. Начата практическая адаптация архитектуры к среде MQL5. Рассмотрены вычисления на OpenCL, параллельная обработка, снижение издержек обмена между CPU и GPU и построение контура для работы в торговом терминале. По сути, первая статья сформировала фундамент всей системы и подготовила основу для дальнейшей реализации ключевых компонентов фреймворка.
Однако именно механизм взаимодействия последовательности с глобальным словарем является центральным элементом всего фреймворка. От того, насколько эффективно модель способна сопоставлять текущие признаки с глобальными паттернами, напрямую зависит качество формирования контекста, устойчивость механизма внимания и способность системы выделять действительно значимые зависимости внутри временного ряда.
Продолжаем развитие проекта и сосредоточимся на построении основного модуля фреймворка — механизма Global Dictionary-based Cross-Attention. Подробно разберем организацию механизма кросс-внимания между входной последовательностью и глобальным словарем, особенности вычисления коэффициентов внимания, а также практические аспекты реализации данного механизма средствами MQL5.
Принципы оптимизации
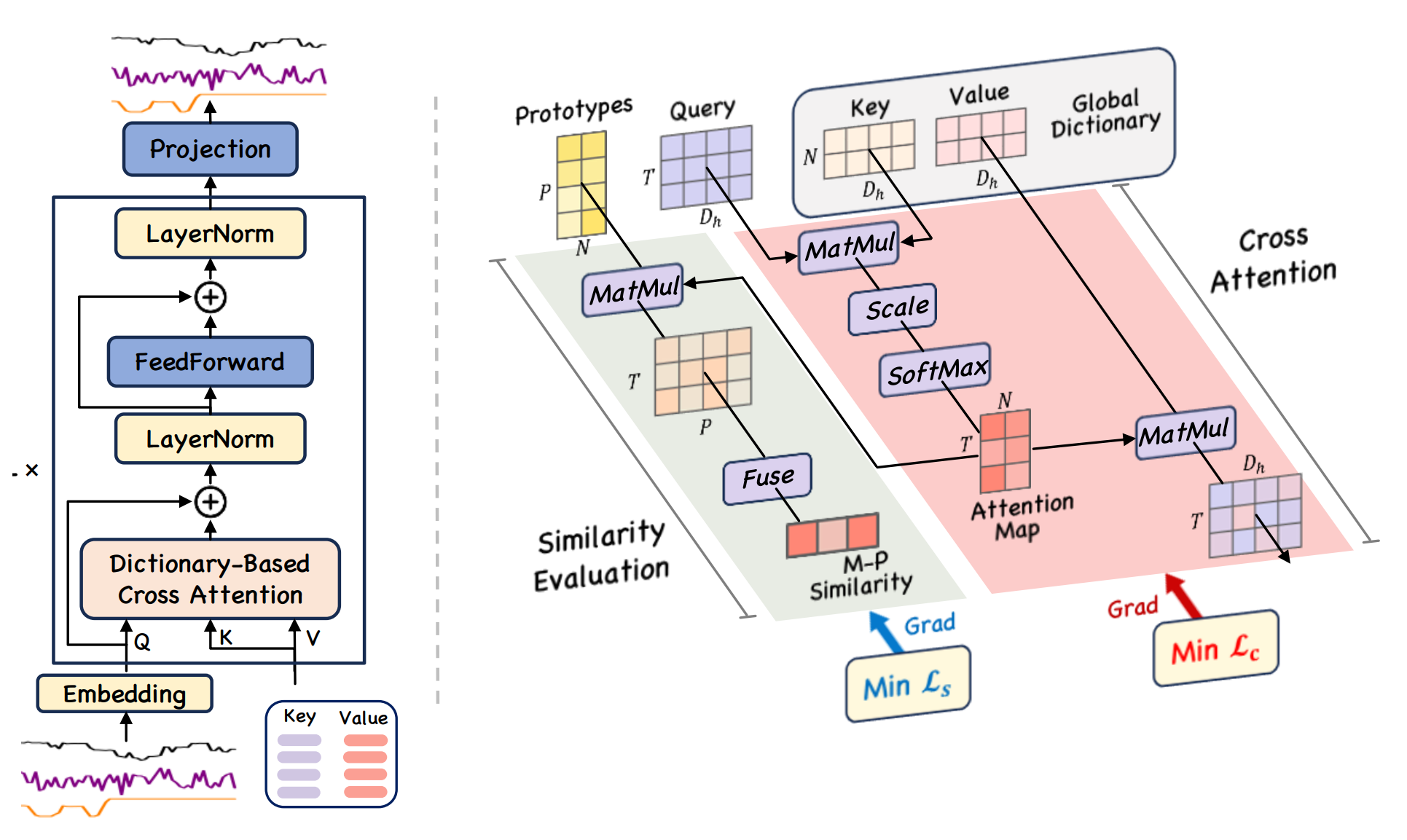
Перед тем как приступить к практической реализации, ещё раз обратимся к архитектуре модуля Global Dictionary-based Cross-Attention, предложенной авторами фреймворка GDformer. В своей основе данный блок представляет собой классический механизм кросс-внимания в трансформерной архитектуры. Однако вместо формирования проекций ключей и значений непосредственно из анализируемой последовательности используются специальные буферы обучаемых параметров, выполняющие роль глобального словаря паттернов.
Преимущества такого подхода достаточно очевидны. Модель перестаёт быть жёстко привязанной к локальному окну анализа и получает возможность формировать внутреннее представление на основе устойчивых структур, накопленных в процессе обучения. Иными словами, система начинает работать не только с текущим состоянием временного ряда, но и с памятью о ранее встречавшихся сценариях. Для задач поиска аномалий это особенно важно. Поскольку модель обучается на типичных паттернах поведения системы, любые незнакомые или плохо согласующиеся состояния автоматически начинают восприниматься как отклонение от нормы. Именно поэтому авторы GDformer ориентируют архитектуру на возможность использования предварительно обученной модели практически из коробки на новых временных рядах. Независимо от конкретной статистики данных, система способна сопоставлять текущее состояние с накопленным набором характерных паттернов и выделять нетипичные режимы поведения.
Дополнительное усиление этого эффекта достигается за счёт использования обучаемых прототипов. В отличие от классических механизмов внимания, данные структуры не зависят напрямую от текущей анализируемой последовательности. Вместо этого они формируют проекцию сходства между анализируемым участком временного ряда и набором выученных шаблонов поведения. Фактически формируемый ими embedding начинает выполнять роль универсального критерия аномальности.
Такой подход оказывается крайне важным, поскольку позволяет уйти от прямой зависимости между оценкой аномалии и статистическими характеристиками конкретного временного ряда. В традиционных схемах качество обнаружения отклонений часто определяется подбором порогов расхождения между исходным и восстановленным участком последовательности. Однако подобные гиперпараметры плохо переносятся между различными наборами данных и требуют постоянной ручной адаптации. Использование же обучаемых прототипов позволяет перенести акцент с абсолютной величины ошибки восстановления на структурное сходство поведения системы с набором известных сценариев. В результате модель становится значительно более универсальной и устойчивой к изменению статистических свойств входных данных.
Однако в задачах трейдинга подобная архитектура требует важного переосмысления. Если в классической постановке задачи поиска аномалий модель стремится покрыть внутренним представлением всю обучающую выборку, то для финансовых временных рядов такой подход оказывается далеко не оптимальным. Рынок содержит огромное количество случайных движений, шумовых колебаний и нестабильных зависимостей, большая часть которых не обладает практической ценностью с точки зрения торговли. Более того, попытка выучить всю совокупность наблюдаемых состояний способна привести к накоплению слабых и противоречивых паттернов, ухудшающих устойчивость модели. В прикладной торговой задаче нас интересуют лишь те структуры поведения цены, которые способны с приемлемой вероятностью приводить к формированию устойчивого торгового преимущества.
Именно поэтому в нашей постановке задачи глобальный словарь должен хранить не просто наиболее типичные паттерны рынка, а устойчивые конфигурации, обладающие прикладной значимостью. По сути, модель должна научиться различать ситуации, имеющие потенциал для генерации прибыли, и состояния, представляющие собой лишь рыночный шум. Здесь и проявляется одно из потенциально опасных свойств глобального внимания.
Классический механизм внимания стремится сопоставить анализируемое состояние с наиболее близким паттерном словаря вне зависимости от абсолютной удалённости между ними во внутреннем пространстве признаков. Для задач обработки естественного языка подобное поведение вполне допустимо. Однако на финансовом рынке такая логика способна сыграть с моделью злую шутку. Даже при отсутствии действительно качественного совпадения механизм внимания всё равно будет пытаться притянуть текущее состояние к одному из существующих шаблонов, формируя искусственную уверенность там, где её быть не должно.
Именно по этой причине при реализации алгоритма на стороне OpenCL-программы мы ввели модифицированный механизм разреженного SoftMax без повторной нормализации коэффициентов внимания. Это решение позволяет не усиливать слабые зависимости искусственным перераспределением вероятностей между оставшимися весами внимания. Фактически модель получает возможность признать отсутствие качественного соответствия между текущим состоянием рынка и набором известных паттернов.
Такой подход значительно ближе к реальной логике торговли. Профессиональный трейдер не обязан находиться в позиции постоянно. Если рынок не формирует понятной и статистически устойчивой конфигурации, наиболее рациональным действием становится отказ от сделки. Аналогично и модель должна иметь право не узнавать текущее состояние вместо того, чтобы любой ценой пытаться классифицировать его как ближайший доступный шаблон.
При этом мы сознательно отказались от использования фиксированного Top-K отбора коэффициентов. Несмотря на вычислительную эффективность подобного подхода, он вводит жёсткое ограничение на количество сохраняемых связей и фактически предполагает, что значимые зависимости существуют всегда. Вместо этого был использован механизм пороговой фильтрации, позволяющий отсекать коэффициенты внимания ниже заданного уровня значимости. Однако здесь возникает уже другая проблема. Как несложно догадаться, выбор универсального порогового значения представляет собой крайне непростую задачу. Слишком низкий порог приведёт к сохранению шумовых зависимостей, тогда как чрезмерно высокий способен разрушить действительно полезные связи между паттернами.
Поэтому дальнейшее развитие архитектуры потребовало перехода к более гибкому подходу. Вместо ручного подбора фиксированных порогов мы предложим модели самостоятельно определять уровень значимости связей непосредственно в процессе обучения. Механизм адаптирует разреженность внимания к структуре данных и выученным паттернам. Это сохраняет баланс между чувствительностью модели и устойчивостью к рыночному шуму.
Объект кросс-внимания к памяти
Реализация модели средствами MQL5 и OpenCL архитектурно должна учитывать не только математическую корректность вычислений, но и их практическую стоимость. Любая лишняя операция нормализации, промежуточное копирование буферов или неудачная организация памяти быстро начинают превращаться в ограничивающий фактор при обработке длинных временных рядов. Особенно критичным это становится для механизмов внимания, где объём вычислений растёт крайне быстро. Поэтому модуль Global Dictionary-based Cross-Attention изначально проектировался как вычислительный блок, пригодный для практического использования внутри торговой инфраструктуры.
Именно по этой причине архитектура модуля строится вокруг нескольких взаимосвязанных компонентов. Первый отвечает за формирование запросов текущего состояния рынка. Второй представляет собой глобальный словарь устойчивых паттернов. Третий реализует механизм сопоставления с обучаемыми прототипами. И наконец, четвёртый обеспечивает адаптивную фильтрацию связей, предотвращая искусственное усиление слабых зависимостей. Только совместная работа всех этих элементов позволяет получить устойчивую систему анализа финансовых временных рядов, способную выделять действительно значимые рыночные состояния.
class CNeuronDictionaryCrossAtt : public CNeuronSpikeConvBlock { protected: uint iDictionarySize; uint iHeads; uint iHiddenDimension; uint bufLogSumExp; CParams cDictionaryKeys; CParams cDictionaryValues; CParams cPrototypes; CParams cLevels; CNeuronSpikeConvBlock cQuerys; CNeuronBaseOCL cAttentionOut; CNeuronBaseOCL cSimilarity; CNeuronSpikeConvBlock cW0; CNeuronSpikeConv cProjSimilarity; CNeuronSpikeConvBlock cFeedForward0; //--- virtual bool MHCrossAttvsSim(void); virtual bool MHCrossAttvsSimGrad(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronDictionaryCrossAtt(void) : bufLogSumExp(INVALID_HANDLE) {}; ~CNeuronDictionaryCrossAtt(void) { if(bufLogSumExp >= 0 && !!OpenCL) OpenCL.BufferFree(bufLogSumExp); } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units, uint heads, uint Dictionary_size, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronDictionaryCrossAtt; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual uint GetWindow(void) const { return cQuerys.GetWindow(); } //--- virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; //--- virtual CNeuronBaseOCL* GetSimilarity(void) { return cSimilarity.AsObject(); } };
Как можно заметить, структура класса CNeuronDictionaryCrossAtt достаточно явно отражает внутреннюю логику фреймворка GDformer. Центральное место здесь занимает глобальный словарь паттернов, представленный обучаемыми параметрами cDictionaryKeys и cDictionaryValues. В отличие от классического Self-Attention, где ключи и значения формируются непосредственно из анализируемой последовательности, в данном случае они существуют как независимая система глобальной памяти модели. Благодаря этому механизм внимания получает возможность сопоставлять текущее состояние рынка не только с локальным окружением в пределах входного окна, но и с набором устойчивых сценариев, накопленных в процессе обучения.
Подобная организация памяти принципиально меняет характер работы механизма внимания. Входной временной ряд фактически начинает выполнять роль поискового запроса к глобальной памяти модели. В результате система анализирует не только локальную структуру текущего движения цены, но и его положение внутри пространства ранее выученных рыночных состояний. Для задач трейдинга это особенно важно, поскольку многие устойчивые рыночные сценарии обладают схожей внутренней структурой даже при существенном различии абсолютных ценовых уровней, волатильности или длительности движения.
Отдельную роль в архитектуре играют обучаемые прототипы cPrototypes. Именно они формируют представление сходства анализируемого состояния и позволяют модели оценивать степень структурного соответствия текущего участка временного ряда с ранее выученными паттернами. По сути, механизм внимания и ветка сходства решают две взаимодополняющие задачи. Первый отвечает за поиск релевантных зависимостей внутри пространства глобальных паттернов, тогда как второй формирует более устойчивую оценку близости текущего состояния к известным режимам поведения рынка.
Подобное разделение оказывается крайне полезным для финансовых данных. Механизм внимания хорошо выявляет локальные ассоциативные зависимости, однако сам по себе может быть чрезмерно чувствителен к шумовым колебаниям и краткосрочным всплескам активности. Механизм соответствия, напротив, работает на более высоком уровне абстракции и позволяет оценивать не отдельные элементы движения, а общую структурную близость наблюдаемого состояния к устойчивым рыночным сценариям. В результате модель получает одновременно гибкость механизма внимания и устойчивость прототипного представления данных.
Инициализация объекта и всех его внутренних компонентов осуществляется в методе Init. Именно на этом этапе формируются внутренние структуры вычислительного блока, задаются размеры embedding-пространства, создаются буферы глобального словаря и подготавливаются все вспомогательные элементы механизма внимания.
bool CNeuronDictionaryCrossAtt::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units, uint heads, uint dictionary_size, ENUM_OPTIMIZATION optimization_type, uint batch) { if(heads < 1 || dictionary_size < 2) ReturnFalse;
Прежде всего метод выполняет базовую проверку корректности полученных параметров, которая выглядит вполне естественно. Использование механизма многоголового внимания теряет смысл при отсутствии хотя бы одной головы внимания, тогда как словарь из одного элемента фактически разрушает саму идею сопоставления текущего состояния с набором альтернативных паттернов. В нашей постановке задачи глобальный словарь должен представлять пространство различных рыночных сценариев, а потому наличие хотя бы нескольких независимых шаблонов является обязательным условием работы механизма внимания.
Далее выполняется инициализация родительского класса.
if(!CNeuronSpikeConvBlock::Init(numOutputs, myIndex, open_cl, 2 * window, 2 * window, window, units, 1, optimization_type, batch)) ReturnFalse;
Здесь уже начинают проявляться особенности внутренней организации архитектуры. В отличие от классических Transformer-блоков, реализуемый модуль строится поверх собственной сверточно-spike инфраструктуры фреймворка. Подобный подход позволяет сохранить унифицированную схему работы всех компонентов модели и одновременно оптимизировать вычислительный граф под особенности OpenCL-исполнения. Кроме того, использование общего базового блока существенно упрощает организацию буферов, передачу градиентов и управление режимами обучения.
После инициализации базовой части вычисляются ключевые параметры механизма внимания.
iDictionarySize = dictionary_size;
iHeads = heads;
iHiddenDimension = (window + heads - 1) / heads;
Параметр iHiddenDimension определяет размерность пространства признаков, обрабатываемого каждой отдельной головой внимания. Нетрудно заметить, что здесь используется округление вверх. Такое решение позволяет избежать потери части признаков при разбиении embedding-пространства между головами внимания и гарантирует корректное покрытие всей размерности входного представления даже в случае, когда размер окна не делится нацело на количество голов внимания.
Следующим шагом создаются буферы глобального словаря.
uint index = 0; if(!cDictionaryKeys.Init(0, index, OpenCL, (iDictionarySize * iHiddenDimension * iHeads), optimization, iBatch)) ReturnFalse; cDictionaryKeys.SetActivationFunction(None); index++; if(!cDictionaryValues.Init(0, index, OpenCL, cDictionaryKeys.Neurons(), optimization, iBatch)) ReturnFalse; cDictionaryValues.SetActivationFunction(None);
Именно эти структуры становятся центральным элементом всей архитектуры. Они представлены независимыми обучаемыми параметрами модели. Фактически система получает собственную долговременную память рыночных состояний. Размер словаря определяется произведением количества паттернов iDictionarySize на размерность скрытого пространства каждой головы внимания и их числа. Таким образом, каждая голова внимания получает доступ к собственному набору глобальных представлений, что позволяет модели одновременно анализировать различные аспекты структуры финансового временного ряда.
Сразу после этого создаётся блок обучаемых прототипов.
index++; if(!cPrototypes.Init(0, index, OpenCL, cDictionaryKeys.Neurons(), optimization, iBatch)) ReturnFalse; cPrototypes.SetActivationFunction(None); CBufferFloat* buf = cPrototypes.getWeightsParams(); if(!buf) ReturnFalse; buf.Fill(0);
Размерность прототипов полностью совпадает с размерностью глобального словаря. Это вполне логично, поскольку механизм соответствия работает в том же embedding-пространстве, что и модуль внимания. Но оценивает степень структурного сходства между текущим состоянием рынка и набором выученных паттернов.
Особого внимания заслуживает последующая инициализация прототипов нулевыми значениями. На первый взгляд подобное решение может показаться необычным, поскольку нейросетевые веса обычно инициализируются случайными значениями. Однако в данном случае речь идёт не о классическом линейном преобразовании, а о системе эталонных embedding-представлений. Нулевая инициализация позволяет начать обучение без искусственного смещения пространства соответствия и даёт модели возможность постепенно сформировать структуру прототипов непосредственно под статистику наблюдаемых рыночных режимов.
Далее создаётся один из наиболее интересных компонентов архитектуры — блок адаптивных уровней разреживания внимания.
index++; if(!cLevels.Init(0, index, OpenCL, units * iHeads, optimization, iBatch)) ReturnFalse; cLevels.SetActivationFunction(SIGMOID); buf = cLevels.getWeightsParams(); if(!buf) ReturnFalse; buf.Fill(-3);
Именно здесь реализуется ранее обсуждавшаяся идея обучаемых порогов фильтрации коэффициентов внимания. В отличие от фиксированного Sparse-Attention, где уровень отсечения задаётся вручную, наша модель получает возможность самостоятельно определять допустимую плотность связей в процессе обучения.
Использование сигмоидальной функции активации особенно важно. Инициализация формирует начальные значения порогов в области малых коэффициентов. Иными словами, на ранних этапах обучения модель начинает работу в относительно мягком режиме фильтрации, сохраняя большую часть связей. Лишь затем, по мере накопления статистики и настройки внутренних представлений, система получает возможность постепенно увеличивать степень разреженности внимания. Подобный подход значительно устойчивее жёсткого ручного задания порогов и особенно хорошо подходит для финансовых временных рядов, структура зависимостей которых может существенно меняться между различными рыночными режимами.
После этого создаётся промежуточный OpenCL-буфер.
bufLogSumExp = OpenCL.AddBuffer(sizeof(float) * cLevels.Neurons(), CL_MEM_READ_WRITE); if(bufLogSumExp <= 0) ReturnFalse;
Данный буфер используется для численно устойчивого вычисления LogSumExp при формировании распределения внимания. Появление отдельного OpenCL-буфера здесь вполне оправдано. Внутри механизма внимания подобные вычисления выполняются крайне часто, а потому перенос промежуточных данных между CPU и GPU быстро превратился бы в серьёзное узкое место производительности.
Далее последовательно создаются основные вычислительные ветки модуля. Инициализируется блок генерации запросов.
index++; if(!cQuerys.Init(0, index, OpenCL, window, window, iHeads * iHiddenDimension, units, 1, optimization, iBatch)) ReturnFalse;
Именно этот компонент формирует Query-представление текущего состояния рынка. В отличие от глобального словаря, запросы продолжают строиться непосредственно из анализируемой последовательности, что полностью соответствует логике кросс-внимания.
Затем создаются буферы результирующего представления внимания и эмбеддинга соответствия.
index++; if(!cAttentionOut.Init(0, index, OpenCL, cQuerys.Neurons(), optimization, iBatch)) ReturnFalse; cAttentionOut.SetActivationFunction(None); index++; if(!cSimilarity.Init(0, index, OpenCL, cQuerys.Neurons(), optimization, iBatch)) ReturnFalse; cSimilarity.SetActivationFunction(None);
Разделение этих веток имеет важное архитектурное значение. Выход внимания отвечает за агрегирование информации из глобального словаря, тогда как эмбеддинг соответствия формирует более устойчивую структурную оценку близости текущего состояния к выученным паттернам рынка.
После этого инициализируются проекционные блоки.
index++; if(!cW0.Init(0, index, OpenCL, iHiddenDimension * iHeads, iHiddenDimension * iHeads, window, units, 1, optimization, iBatch)) ReturnFalse; index++; if(!cProjSimilarity.Init(0, index, OpenCL, iHiddenDimension * iHeads, iHiddenDimension * iHeads, window, units, 1, optimization, iBatch)) ReturnFalse;
Здесь выполняется преобразование представлений внимания и соответствия обратно в рабочее embedding-пространство модели. Фактически данные блоки обеспечивают интеграцию результатов глобального сопоставления в общий вычислительный контур сети.
Завершает инициализацию Feed-Forward блок.
index++; if(!cFeedForward0.Init(0, index, OpenCL, window, window, cConv.GetWindow(), units, 1, optimization, iBatch)) ReturnFalse; //--- return true; }
Как и в классических Transformer-архитектурах, Feed-Forward часть отвечает за последующую нелинейную обработку сформированного представления. Однако в нашем случае на вход данного блока поступает уже не просто локальное описание последовательности, а результат взаимодействия текущего состояния рынка с глобальным пространством выученных паттернов.
Таким образом, уже на этапе инициализации хорошо видно, что модуль Global Dictionary-based Cross-Attention представляет собой полноценную систему контекстного анализа рыночных состояний, объединяющую глобальную память, механизм структурного сопоставления и адаптивную фильтрацию зависимостей внутри единого вычислительного контура.
После завершения этапа инициализации модуль получает все необходимые внутренние структуры: глобальный словарь паттернов, систему прототипов, адаптивные уровни разреживания внимания и набор вычислительных блоков для формирования итогового embedding-представления. Теперь архитектура готова к основной задаче — обработке входной последовательности и поиску её соответствия внутри пространства выученных рыночных состояний.
Алгоритм прямого прохода реализован в методе feedForward, где абстрактная идея Global Dictionary-based Cross-Attention превращается в последовательность конкретных вычислительных этапов, формирующих внутреннее представление текущего состояния рынка.
bool CNeuronDictionaryCrossAtt::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cQuerys.FeedForward(NeuronOCL)) ReturnFalse;
Работа метода начинается с формирования Query-представления анализируемой последовательности. На данном этапе входной временной ряд преобразуется в embedding-пространство механизма внимания. В отличие от Self-Attention архитектур, где на основе входных данных одновременно формируются запросы, ключи и значения, здесь из анализируемой последовательности строятся только Query-векторы. Ключи и значения уже существуют внутри модели в виде глобального словаря выученных паттернов. Фактически система начинает работу как механизм поиска соответствий между текущим состоянием рынка и внутренней памятью модели.
Далее выполняется обновление обучаемых компонентов словаря.
if(bTrain) { if(!cDictionaryKeys.FeedForward() || !cDictionaryValues.FeedForward() || !cPrototypes.FeedForward() || !cLevels.FeedForward()) ReturnFalse; }
Интересно, что данный этап выполняется только в режиме обучения. Это вполне логично: глобальный словарь, прототипы и уровни фильтрации коэффициентов внимания являются обучаемыми параметрами модели и во время инференса уже рассматриваются как зафиксированное внутреннее представление рыночных паттернов.
После подготовки всех внутренних представлений управление передаётся центральному вычислительному узлу.
if(!MHCrossAttvsSim())
ReturnFalse;
Именно здесь сосредоточена основная логика работы всего модуля. Метод объединяет Multi-Head Cross-Attention, механизм Similarity-сопоставления и адаптивную фильтрацию связей. Фактически на данном этапе происходит поиск наиболее релевантных паттернов внутри глобального словаря и формирование внутреннего описания текущего состояния рынка.
Особенно важно, что ветки внимания и соответствия вычисляются совместно. Для финансовых временных рядов это принципиально. Совместная работа обоих механизмов позволяет системе одновременно сохранять гибкость внимания и устойчивость прототипного представления.
Результат работы механизма внимания далее проходит через блок проекции.
if(!cW0.FeedForward(cAttentionOut.AsObject())) ReturnFalse; if(!SumAndNormalize(NeuronOCL.getOutput(), cW0.getOutput(), cW0.getOutput(), cW0.GetFilters(), true, 0, 0, 0, 1)) ReturnFalse;
Здесь embedding внимания преобразуется обратно в рабочее пространство признаков модели. Сразу после этого реализуется остаточное соединение между исходным представлением последовательности и результатом работы глобального механизма внимания. Подобная схема хорошо знакома по классическим Transformer-моделям. Однако в нашем случае остаточная связь приобретает дополнительный смысл. Модель не заменяет локальное описание входной последовательности глобальным представлением, а аккуратно дополняет его контекстной информацией, полученной из словаря выученных рыночных паттернов.
Это особенно важно для финансовых временных рядов. Полный отказ от локальной структуры данных в пользу глобального контекста способен привести к потере краткосрочной динамики рынка, тогда как использование исключительно локального анализа лишает систему понимания общего рыночного режима. Остаточная интеграция позволяет сохранить баланс между текущим состоянием рынка и глобальной памятью модели.
Следующим этапом выполняется обработка представления соответствия.
if(!cProjSimilarity.FeedForward(cSimilarity.AsObject()))
ReturnFalse;
Эмбеддинг соответствия проходит собственную проекцию и подготавливается для дальнейшего использования внутри общей embedding-структуры модели. Это вновь подчёркивает важную архитектурную особенность GDformer: механизм соответствия здесь становится полноценной частью внутреннего представления состояния рынка.
Далее управление передаётся в Feed-Forward блок.
if(!cFeedForward0.FeedForward(cW0.AsObject()))
ReturnFalse;
Как и в классических Transformer-архитектурах, Feed-Forward часть отвечает за последующую нелинейную обработку результатов внимания. Однако теперь данный блок работает уже с представлением, содержащим одновременно локальную информацию о текущем движении цены и глобальный контекст, сформированный через механизм словаря паттернов.
После этого выполняется прямой проход родительского класса, который выполняет роль второго слоя Feed-Forward-блока.
if(!CNeuronSpikeConvBlock::feedForward(cFeedForward0.AsObject())) ReturnFalse; if(!SumAndNormalize(getOutput(), cW0.getOutput(), getOutput(), cW0.GetFilters(), true, 0, 0, 0, 1)) ReturnFalse; //--- return true; }
Такое решение позволяет сохранить единый механизм обработки данных между различными компонентами сети и оптимизировать вычислительный граф под особенности OpenCL-исполнения.
Завершает прямой проход ещё одна остаточная интеграция. Как и ранее, модель не уничтожает ранее сформированное представление, а постепенно обогащает его дополнительной информацией. Подобная организация вычислительного процесса делает архитектуру более устойчивой и позволяет избежать резкой деградации внутренних представлений при нестабильной динамике финансового рынка.
В результате весь прямой проход модуля можно рассматривать как последовательную процедуру сопоставления текущего состояния рынка с глобальной памятью модели, фильтрации слабых зависимостей, формирования устойчивого представления соответствия и постепенной интеграции найденного контекста в общее embedding-пространство системы. Именно здесь архитектура GDformer окончательно перестаёт быть обычным механизмом внимания и начинает работать как система поиска устойчивых рыночных состояний внутри пространства выученных паттернов.
Заключение
Из идеи глобальной памяти рыночных состояний выросло рабочее вычислительное ядро модели. Модуль Global Dictionary-based Cross-Attention стал тем узлом, через который GDformer начинает видеть рынок как систему повторяющихся режимов, скрытых зависимостей и устойчивых сценариев поведения цены.
Самое важное здесь в том, что модель перестала слепо доверять любому найденному совпадению. Для финансовых рядов это принципиально. Рынок шумит, сбивается, маскирует смысл случайными всплесками, и потому обычный механизм внимания без дополнительной логики легко переоценивает слабые связи. В нашей реализации этому противопоставлены разреженное внимание без повторной нормализации и обучаемые уровни фильтрации, которые позволяют модели не усиливать шум, а отсекать его.
Не менее значимым оказался и блок соответствия с обучаемыми прототипами. Он добавил системе второй взгляд на рынок через более глубокую оценку структурного сходства. В результате модель начинает опираться на более широкий контекст, где важны устойчивые рыночные конфигурации. Это уже совсем другой уровень анализа.
Таким образом, к этому моменту мы собрали основу, на которой можно строить дальнейшую прикладную работу. В следующей статье мы перейдём к построению полноценной модели на базе данного фреймворка и её обучению на реальных исторических данных. Это позволит перейти от описания механизмов к их проверке в условиях живой рыночной статистики и в полной мере оценить прикладную эффективность реализованных решений.
Ссылки
- GDformer: Going Beyond Subsequence Isolation for Multivariate Time Series Anomaly Detection
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн-обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн-обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Проект представлен на forge.mql5.io/dng.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования