
Нейросети в трейдинге: Внимание, память и рыночные паттерны в GDformer (Окончание)

Введение
Наш проект развивается не из академического интереса. Обычно к таким моделям приходят после вполне практического опыта — когда рынок снова показывает, насколько плохо работают прямолинейные решения в сложной и изменчивой среде. Цена может двигаться одинаково внешне, но причины этого движения будут совершенно разными. Сильный импульс иногда оказывается началом устойчивого тренда, а иногда — всего лишь кратковременным выбросом ликвидности перед разворотом. Простая коррекция способна перерасти в полноценную смену режима, а участок спокойного флэта — внезапно превратиться в зону резкого расширения волатильности. Здесь проявляется одна из ключевых проблем прикладного анализа финансовых рядов: рынок недостаточно просто видеть. Его необходимо интерпретировать в контексте уже наблюдавшихся состояний.
Большинство классических подходов строятся вокруг локального анализа. Модель оценивает ближайший участок данных, ищет закономерности внутри ограниченного окна наблюдения и пытается принять решение на основе короткой исторической памяти. Такой подход работает, пока рыночная структура остается относительно стабильной. Но финансовые ряды живут по другим правилам. Они постоянно меняют характер движения, масштаб колебаний и внутренние взаимосвязи. В результате локальные зависимости быстро теряют устойчивость, а сигналы начинают деградировать вместе с изменением режима рынка.
Именно попытка выйти за пределы этой локальной близорукости и лежит в основе фреймворка GDformer. Вместо того чтобы анализировать каждый участок ряда изолированно, модель опирается на накопленную память типичных состояний и сопоставляет с ними текущую рыночную ситуацию. Фактически речь идет о переходе от анализа отдельных ценовых колебаний к поиску структурного сходства между рыночными режимами. Для финансовых данных это особенно важно, поскольку рынок редко повторяет точные значения, но достаточно часто воспроизводит схожие сценарии поведения: фазы накопления, импульсные выбросы, затухающие тренды, участки перегрева или хаотичной турбулентности.
В предыдущих статьях мы постепенно формировали прикладную основу этого подхода в MQL5. Сначала был построен общий архитектурный каркас проекта и подготовлена вычислительная инфраструктура, необходимая для дальнейшей работы модели. Это позволило перенести идеи GDformer из исследовательской плоскости в практическую торговую среду, где уже важны не только сами алгоритмы, но и вопросы производительности, устойчивости и организации вычислений.
Следующим этапом стала реализация центрального механизма модели — системы сопоставления входной последовательности с глобальным словарем паттернов. Именно на этом уровне архитектура начинает приобретать прикладной смысл. Модель перестает реагировать только на локальные изменения цены и получает возможность оценивать текущее состояние рынка через его близость к ранее наблюдаемым структурам. Иными словами, вместо попытки угадать движение по отдельным свечам появляется механизм, способный учитывать более широкий контекст поведения рынка.
Однако реализация архитектуры сама по себе не отвечает на главный вопрос трейдера: насколько этот подход полезен в реальной задаче анализа финансовых рядов. Красивые схемы и сложные механизмы внимания сами по себе не имеют ценности, если модель не способна устойчиво работать в условиях рыночного шума, резкой смены режимов и нестабильных зависимостей. Именно поэтому на данном этапе проект переходит от построения отдельных компонентов к их объединению в целостную архитектуру и оценке поведения модели в рыночных условиях.
Модуль анализа рыночного состояния
Продолжая перенос подходов, предложенных авторами GDformer, в прикладную торговую модель, важно сразу отметить различие в самой постановке задачи. В оригинальной работе речь идет о поиске аномалий: если текущее состояние существенно отличается от выученных типичных паттернов, это рассматривается как признак аномального поведения. В нашей задаче логика иная. Нас интересуют не отклонения сами по себе, а устойчивые рыночные паттерны, способные генерировать торговые сигналы.
Однако финансовые временные ряды по своей природе нестационарны и сильно зашумлены. Один и тот же паттерн может приводить к разным последствиям в зависимости от того, в каком контексте он сформировался. Поэтому одного лишь совпадения с выученным образцом недостаточно. Если ограничиться только сравнением с набором известных паттернов, мы снова окажемся в ловушке ограниченного окна наблюдения — теперь уже на уровне самого паттерна.
Чтобы построить рабочую модель анализа финансовых временных рядов, нужно учитывать сходство с известными структурами. Также важно учитывать предшествующую динамику и текущий рыночный контекст. Иными словами, важен не только сам сигнал, но и то, как рынок пришел к его появлению. Без этого модель будет видеть форму, но не будет понимать смысл.
Это особенно важно и для сопровождения открытых позиций. Рыночная динамика может быстро измениться, и если фактическое движение перестает соответствовать ожиданиям, позицию необходимо закрыть вовремя, не дожидаясь, пока убыток станет избыточным. Поэтому модуль анализа рыночного состояния должен решать сразу две задачи: помогать распознавать потенциально значимые паттерны и одновременно служить механизмом контроля за текущим развитием рыночной ситуации.
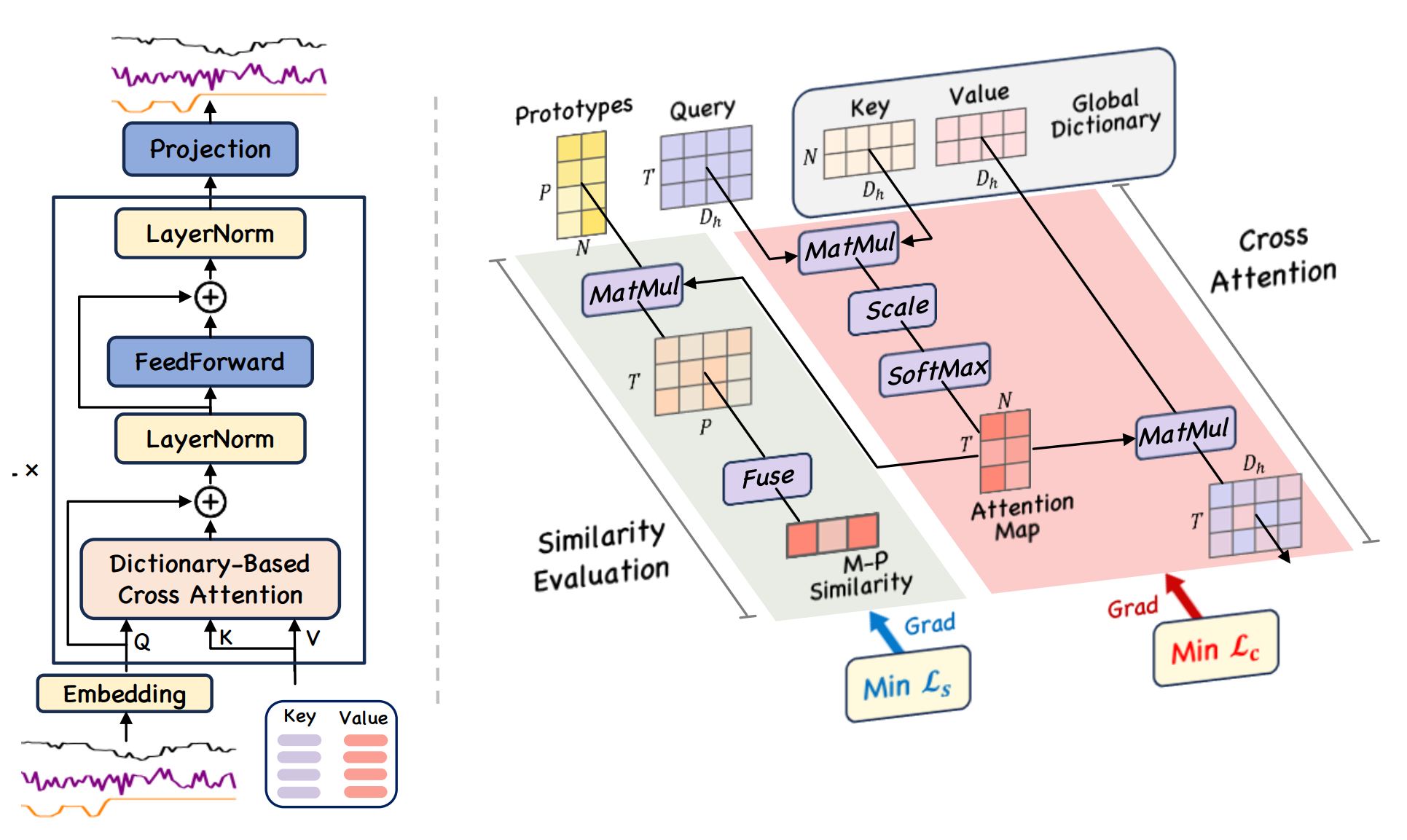
Для решения поставленных задач объединяем подходы ReGEN-TAD и GDformer. В основную магистраль анализа последовательности ReGEN-TAD добавляется блок модулей кросс-внимания, которые сопоставляют текущее рыночное состояние с выученными паттернами. Это позволяет модели смотреть на рынок как на пространство устойчивых структур, с которыми можно сравнивать текущую динамику.
При этом результаты кросс-внимания не используются изолированно. Мы конкатенируем их с эмбеддингами схожести, формируя дополнительные признаки для дальнейшей обработки. Таким образом в магистраль ReGEN-TAD мы подаем последовательность финансовых состояний, дополненную эмбеддингами схожести разных уровней анализа.
Такой подход усиливает информационную насыщенность входа и позволяет модели учитывать не только текущее поведение цены, но и его связь с уже выученными рыночными структурами. Для прикладной торговой задачи это особенно важно: чем точнее модель понимает, к какому типу состояния относится текущий участок ряда, тем надежнее она может оценивать развитие сценария и своевременно реагировать на изменение рыночной картины.
Для реализации описанного подхода был создан объект CNeuronGDformerBackbone.
class CNeuronGDformerBackbone : public CNeuronReGENTADBackbone { protected: //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronGDformerBackbone(void) {}; ~CNeuronGDformerBackbone(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint heads, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronGDformerBackbone; } };
На первый взгляд объект может показаться сравнительно компактным. В классе отсутствуют объявления внутренних компонентов. Переопределяются лишь основные методы прямого и обратного проходов, а также метод инициализации модели. Однако подобная компактность вовсе не означает простоты внутренней организации. Напротив, архитектура объекта остается достаточно насыщенной и разветвленной.
В данном случае мы сознательно переиспользуем компоненты родительского класса CNeuronReGENTADBackbone. Такой подход позволяет избежать дублирования уже реализованных механизмов и сохранить целостность вычислительной магистрали. По сути, новый объект не строит архитектуру заново, а расширяет существующую систему за счет изменения логики ключевых этапов обработки данных. Именно поэтому основная сложность сосредоточена не в количестве объявленных внутренних объектов, а в алгоритме переопределяемых методов.
По-настоящему с архитектурой модуля мы знакомимся в методе инициализации. Именно здесь становится видно, как объединяются механизмы GDformer и ReGEN-TAD. Какие информационные потоки формируются внутри модели. И каким образом организуется совместная обработка рыночного состояния.
bool CNeuronGDformerBackbone::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint heads, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(dimensions.Size() < 2 || layers < 1 || units_s < 1 || heads < 1 || embed_size < 1 || embed_size % heads != 0) ReturnFalse; uint iSequenceDim = units_s * dimensions[0]; uint iDCAlayers = 3; uint iContextUnits = dimensions.Size() - 1; uint iGDSequenceUnits = 1 + iDCAlayers; uint iOutputUnits = 3 * iGDSequenceUnits + iContextUnits + 3; uint iContextDim = 0; for(uint i = 1; i < dimensions.Size(); i++) iContextDim += dimensions[i];
Уже в начале метода можно заметить, что модель строится вокруг нескольких независимых вычислительных магистралей. Отдельно рассчитываются размеры последовательности рыночных состояний, число уровней сопоставления с паттернами и размер контекстного пространства.
Здесь сразу обращает на себя внимание фиксированное количество уровней Dictionary Cross Attention. Мы используем три последовательных слоя сопоставления с глобальным словарем паттернов. При этом итоговая последовательность обогащается эмбеддингами схожести каждого уровня анализа. Иными словами, модель сохраняет промежуточные представления состояния рынка, полученные на разных этапах сопоставления с выученными структурами.
Далее архитектура разделяется на три крупных контура обработки данных.
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, iOutputUnits * embed_size, optimization_type, batch)) ReturnFalse; activation = None; //--- cSeqToken.Clear(); cTransformer.Clear(); cRecurrent.Clear(); cSeqToken.SetOpenCL(OpenCL); cTransformer.SetOpenCL(OpenCL); cRecurrent.SetOpenCL(OpenCL);
Первый контур отвечает за формирование последовательности токенов и сопоставление с глобальными паттернами. Второй представляет собой основную трансформерную магистраль анализа контекста. Третий реализует рекуррентную обработку динамики состояния.
Формирование входной последовательности начинается с токенизации рыночных данных.
//--- Sequence tokenizer uint index = 0; CNeuronBaseOCL* neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, iSequenceDim, optimization, iBatch) || !cSeqToken.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None); index++; CNeuronSequenceTokenizer* seq_tok = new CNeuronSequenceTokenizer(); if(!seq_tok || !seq_tok.Init(0, index, OpenCL, dimensions[0], units_s, embed_size, optimization, iBatch) || !cSeqToken.Add(seq_tok)) DeleteObjAndFalse(seq_tok); seq_tok.SetActivationFunction(SoftPlus);
На этом этапе последовательность финансовых состояний переводится во внутреннее пространство эмбеддингов, удобное для дальнейшего анализа. После этого данные последовательно проходят через цепочку модулей Dictionary Cross Attention.
CNeuronDictionaryCrossAtt* dca = NULL; for(uint i = 0; i < iDCAlayers; i++) { index++; dca = new CNeuronDictionaryCrossAtt(); if(!dca || !dca.Init(0, index, OpenCL, embed_size, 1, heads, stack_size, optimization, iBatch) || !cSeqToken.Add(dca)) DeleteObjAndFalse(dca); } index++;
Именно здесь происходит сопоставление текущего состояния рынка с глобальным словарем выученных паттернов. Причем модель не ограничивается одним уровнем сравнения. Каждый следующий слой получает уже преобразованное представление предыдущего уровня, постепенно уточняя структурное положение текущего состояния внутри пространства известных рыночных сценариев.
После завершения блока сопоставления формируется расширенная последовательность признаков.
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, 4 * embed_size, optimization, iBatch) || !cSeqToken.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None);
Фактически здесь объединяются исходные эмбеддинги и результаты всех уровней анализа схожести. В результате модель получает не одну последовательность рыночных состояний, а сразу несколько взаимосвязанных представлений одного и того же участка рынка.
Следующий этап — передача расширенного состояния в трансформерную магистраль.
//--- Transformer index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, iContextDim, optimization, iBatch) || !cTransformer.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None);
На этом уровне модель начинает анализировать уже не только локальную структуру последовательности, но и взаимосвязи между различными контекстными потоками.
index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, iContextDim + cSeqToken[-1].Neurons(), optimization, iBatch) || !cTransformer.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None); uint dims[]; uint sequence_units = cSeqToken[-1].Neurons() / embed_size; if(sequence_units != iGDSequenceUnits || ArrayResize(dims, sequence_units + iContextUnits) < int(sequence_units + iContextUnits)) ReturnFalse; ArrayFill(dims, 0, sequence_units, embed_size); ArrayCopy(dims, dimensions, sequence_units, 1); index++; CNeuronINFNetBlock* transf = new CNeuronINFNetBlock(); if(!transf || !transf.Init(0, index, OpenCL, dims, sequence_units, heads, stack_size, layers, embed_size, candidates, topK, optimization, iBatch) || !cTransformer.Add(transf)) DeleteObjAndFalse(transf);
В обработку одновременно поступают:
- исходная последовательность рыночных состояний;
- результаты сопоставления с паттернами;
- дополнительные контекстные признаки.
Это особенно важно для финансовых временных рядов, где значение паттерна определяется не только его формой, но и условиями возникновения.
Отдельного внимания заслуживает рекуррентная ветвь обработки.
//--- Recurrent CNeuronLSTMOCL* lstm = NULL; uint size = cSeqToken[-1].Neurons(); for(uint i = 0; i < layers; i++) { lstm = new CNeuronLSTMOCL(); index++; if(!lstm || !lstm.Init(0, index, OpenCL, size, optimization, iBatch) || !lstm.SetInputs(size) || !cRecurrent.Add(lstm)) DeleteObjAndFalse(lstm); lstm.SetActivationFunction(TANH); }
Здесь используется стек LSTM-слоев, предназначенный для анализа динамики изменения состояния во времени. Если трансформерная магистраль отвечает за пространственные и контекстные взаимосвязи, то рекуррентный блок концентрируется именно на развитии рыночного движения. Для прикладной торговли это принципиально важно, поскольку сопровождение позиции требует понимания не только текущего состояния рынка, но и характера изменения этого состояния.
После рекуррентной обработки выполняется нормализация.
index++; CNeuronBatchNormOCL* norm = new CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, lstm.Neurons(), optimization, iBatch) || !cRecurrent.Add(norm)) DeleteObjAndFalse(norm);
И формируется блок cDifference.
index++; if(!cDifference.Init(0, index, OpenCL, norm.Neurons(), embed_size, optimization, iBatch)) ReturnFalse; cDifference.SetActivationFunction(TANH); if(Neurons() != cTransformer[-1].Neurons() + cSeqToken[-1].Neurons() + cDifference.Neurons()) ReturnFalse; //--- return true; }
Здесь решается уже более тонкая задача. Данный компонент не просто анализирует изменения последовательности, а формирует эмбеддинг соответствия между двумя различными представлениями одной и той же рыночной ситуации.
Трансформерная магистраль оценивает структуру состояния через контекстные взаимосвязи и сопоставление с глобальными паттернами. Рекуррентная ветвь LSTM анализирует динамику развития рынка во времени. В результате модель получает два различных взгляда на одно и то же состояние рынка.
Если оба представления оказываются близкими, это говорит о согласованности оценки. Иными словами, различные механизмы анализа приходят к схожему пониманию текущего рыночного режима. Для модели это является признаком более высокой уверенности в интерпретации ситуации.
Напротив, сильное расхождение между представлениями становится важным сигналом повышенной неопределенности. На практике подобная ситуация часто возникает в переходных фазах рынка, во время структурной перестройки режима или при формировании нестабильных и шумовых движений. В таких условиях даже внешне сильный паттерн может обладать существенно меньшей надежностью.
Таким образом cDifference фактически становится механизмом внутренней оценки согласованности модели. Он позволяет учитывать не только сам результат анализа рыночного состояния, но и степень уверенности архитектуры в собственной интерпретации наблюдаемой динамики.
В финале все вычислительные потоки объединяются в единое представление. Это объединение делает архитектуру существенно глубже обычного локального анализа временного ряда. Модель получает возможность одновременно учитывать текущую структуру рынка, ее сходство с известными сценариями и характер развития рыночного движения во времени.
Метод инициализации задает внутреннюю структуру объекта, а реальный поток данных формируется в методе прямого прохода.
bool CNeuronGDformerBackbone::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) ReturnFalse; //--- CNeuronBaseOCL* sequence = cSeqToken[0]; CNeuronBaseOCL* context = cTransformer[0]; if(!sequence || !context) ReturnFalse; uint iSequenceDim = sequence.Neurons(); uint iContextDim = context.Neurons(); if(!DeConcat(sequence.getOutput(), context.getOutput(), NeuronOCL.getOutput(), iSequenceDim, iContextDim, 1)) ReturnFalse;
Здесь модель последовательно собирает и связывает все внутренние представления рыночного состояния. В начале выполняется разделение данных между двумя базовыми ветвями — последовательной и контекстной.
Далее запускается цепочка модуляции последовательности. Каждый элемент блока cSeqToken обрабатывает результат предыдущего, а блоки Dictionary Cross Attention формируют эмбеддинги схожести текущего состояния с выученными паттернами.
//--- Sequence tokenizer CNeuronBaseOCL *sims[3] = {NULL}; uint sims_pos = 0; for(int i = 1; i < cSeqToken.Total() - 1; i++) { sequence = cSeqToken[i]; if(!sequence || !sequence.FeedForward(cSeqToken[i - 1])) ReturnFalse; if(sequence.Type() == defNeuronDictionaryCrossAtt) { if(sims_pos >= 3) ReturnFalse; CNeuronDictionaryCrossAtt* temp = sequence; sims[sims_pos] = temp.GetSimilarity(); sims_pos++; } }
Эти эмбеддинги не теряются и не используются изолированно. Они сохраняются как отдельные признаки, отражающие степень соответствия между текущим рыночным состоянием и опорными структурами.
После завершения последовательной обработки полученные эмбеддинги схожести объединяются с выходом последнего уровня токенизации. В результате формируется расширенное представление последовательности, в котором соседствуют исходные признаки и результаты их сопоставления с глобальным словарем паттернов.
iSequenceDim = sequence.Neurons(); sequence = cSeqToken[-1]; if(sims_pos != 3 || !sims[0] || !sims[1] || !sims[2]) ReturnFalse; if(!sequence || !Concat(cSeqToken[-2].getOutput(), sims[0].getOutput(), sims[1].getOutput(), sims[2].getOutput(), sequence.getOutput(), iSequenceDim, iSequenceDim, iSequenceDim, iSequenceDim, 1)) ReturnFalse; iSequenceDim = sequence.Neurons();
Затем это расширенное представление подается в трансформерную ветвь. Здесь контекстная часть получает уже не просто исходную последовательность, а последовательность, дополненную результатами анализа схожести. Благодаря этому трансформер работает с более насыщенным входом и может учитывать не только текущую структуру рынка, но и ее связь с выученными сценариями.
//--- Transformer context = cTransformer[1]; if(!context || !Concat(sequence.getOutput(), cTransformer[0].getOutput(), context.getOutput(), iSequenceDim, iContextDim, 1)) ReturnFalse; for(int i = 2; i < cTransformer.Total(); i++) { context = cTransformer[i]; if(!context || !context.FeedForward(cTransformer[i - 1])) ReturnFalse; }
Параллельно выполняется рекуррентная обработка через LSTM-ветвь. Эта ветвь формирует собственное представление динамики рыночного состояния во времени. В отличие от трансформера, который сильнее ориентирован на структурные взаимосвязи, рекуррентный блок фиксирует характер последовательного изменения рынка.
//--- Recurrent sequence = cRecurrent[0]; if(!sequence || !sequence.FeedForward(cSeqToken[-1])) ReturnFalse; for(int i = 1; i < cRecurrent.Total(); i++) { sequence = cRecurrent[i]; if(!sequence || !sequence.FeedForward(cRecurrent[i - 1])) ReturnFalse; }
После завершения обеих ветвей выполняется сравнение их результатов. Именно здесь формируется эмбеддинг соответствия двух различных взглядов на одну и ту же рыночную ситуацию.
if(!cDifference.FeedForward(context, sequence.getOutput()))
ReturnFalse;
Если представления трансформерной и рекуррентной магистралей близки, это означает, что модель интерпретирует рынок согласованно и уверенно. Если же между ними возникает заметное расхождение, это указывает на рост неопределенности и, как следствие, на повышенный риск.
В финале все три компонента — контекстный выход трансформера, выход LSTM и эмбеддинг их согласованности — объединяются в общий тензор результатов.
if(!Concat(context.getOutput(), sequence.getOutput(), cDifference.getOutput(), Output, context.Neurons(), sequence.Neurons(), cDifference.Neurons(), 1)) ReturnFalse; //--- return true; }
Так модель получает составной результат, в котором одновременно присутствуют структура, динамика и мера внутренней уверенности в интерпретации текущего состояния.
Сложная и разветвленная архитектура объекта требует тщательно распределять градиенты ошибки. Здесь уже недостаточно просто передать ошибку назад по цепочке слоев. Необходимо сохранить согласованность нескольких независимых магистралей анализа и корректно распределить вклад каждой из них в итоговое обновление модели. Именно эту задачу решает метод обратного прохода.
bool CNeuronGDformerBackbone::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) ReturnFalse; //--- CNeuronBaseOCL* sequence = cRecurrent[-1]; CNeuronBaseOCL* context = cTransformer[-1]; if(!sequence || !context) ReturnFalse; uint iSequenceDim = sequence.Neurons(); uint iContextDim = context.Neurons(); if(!DeConcat(context.getGradient(), sequence.getGradient(), cDifference.getGradient(), Gradient, iContextDim, iSequenceDim, cDifference.Neurons(), 1)) ReturnFalse; Deactivation(cDifference); Deactivation(context); Deactivation(sequence);
В начале метода выполняется обратное разделение общего градиента между тремя ключевыми компонентами итогового представления: трансформерной ветвью, рекуррентной магистралью и блоком оценки согласованности. Это важный момент. На этапе прямого прохода модель объединяла несколько различных представлений рыночного состояния в единый выходной вектор. Теперь же необходимо аккуратно разложить общий сигнал ошибки обратно по соответствующим вычислительным потокам.
Особого внимания требует блок cDifference. Напомним, что он формирует эмбеддинг соответствия между двумя различными интерпретациями одной и той же рыночной ситуации — трансформерной и рекуррентной. Поэтому ошибка, возникающая в этом компоненте, не принадлежит какой-то одной ветви. Она должна быть перераспределена между обеими магистралями.
CBufferFloat* temp = context.getGradient(); if(!context.SetGradient(context.getPrevOutput(), false) || !context.getGradient().Fill(0) || !sequence.getPrevOutput().Fill(0)) ReturnFalse; if(!context.CalcHiddenGradients(cDifference.AsObject(), sequence.getOutput(), sequence.getPrevOutput(), (ENUM_ACTIVATION)sequence.Activation())) ReturnFalse; if(!SumAndNormalize(temp, context.getGradient(), temp, 1, false, 0, 0, 0, 1) || !context.SetGradient(temp, false) || !SumAndNormalize(sequence.getGradient(), sequence.getPrevOutput(), sequence.getGradient(), 1, false, 0, 0, 0, 1)) ReturnFalse;
Здесь ошибка согласованности преобразуется в корректирующий сигнал для обоих представлений. Если трансформерная и рекуррентная ветви начинают слишком сильно расходиться в интерпретации рынка, модель получает дополнительный штраф, заставляющий их внутренние представления двигаться к более согласованному состоянию.
После этого градиенты суммируются. Такой подход особенно важен в многоветвистой архитектуре.
Далее начинается классическое распространение ошибки по рекуррентной и трансформерной магистралям.
//--- Recurrent for(int i = cRecurrent.Total() - 2; i >= 0; i--) { sequence = cRecurrent[i]; if(!sequence || !sequence.CalcHiddenGradients(cRecurrent[i + 1])) ReturnFalse; } //--- Transformer for(int i = cTransformer.Total() - 2; i >= 1; i--) { context = cTransformer[i]; if(!context || !context.CalcHiddenGradients(cTransformer[i + 1])) ReturnFalse; } context = cTransformer[0]; sequence = cSeqToken[-1]; if(!context || !sequence) ReturnFalse; iSequenceDim = sequence.Neurons(); iContextDim = context.Neurons(); if(!DeConcat(sequence.getPrevOutput(), context.getGradient(), cTransformer[1].getGradient(), iSequenceDim, iContextDim, 1)) ReturnFalse;
Однако даже здесь архитектура остается неоднородной. Трансформерная ветвь передает ошибку не напрямую, а через расширенное представление, в которое ранее были добавлены результаты сопоставления с паттернами. Поэтому далее выполняется еще одно разделение. На этом этапе ошибка отделяется между последовательной частью и контекстной магистралью. Фактически модель начинает разматывать назад тот поток данных, который был сформирован в методе прямого прохода.
Особенно интересно организована обработка блока Dictionary Cross Attention. Во время прямого прохода эмбеддинги схожести сохранялись как отдельные последовательности признаков. Теперь градиенты необходимо корректно вернуть каждому уровню сопоставления. Для этого сначала извлекаются все эмбеддинги схожести.
//--- Sequence tokenizer if(!sequence.CalcHiddenGradients(cRecurrent[0])) ReturnFalse; if(sequence.Activation() != None) if(!DeActivation(sequence.getOutput(), sequence.getPrevOutput(), sequence.getPrevOutput(), sequence.Activation())) ReturnFalse; if(!SumAndNormalize(sequence.getGradient(), sequence.getPrevOutput(), sequence.getGradient(), 1, false, 0, 0, 0, 1)) ReturnFalse; CNeuronBaseOCL* sims[3] = {NULL}; uint sims_pos = 0; for(int i = 1; i < cSeqToken.Total() - 1; i++) { if(!cSeqToken[i] || cSeqToken[i].Type() != defNeuronDictionaryCrossAtt) continue; if(sims_pos >= 3) ReturnFalse; CNeuronDictionaryCrossAtt* temp = cSeqToken[i]; sims[sims_pos] = temp.GetSimilarity(); sims_pos++; }
После чего выполняется обратное разделение ошибки.
if(sims_pos != 3 || !sims[0] || !sims[1] || !sims[2]) ReturnFalse; iSequenceDim = sims[0].Neurons(); if(!cSeqToken[-2] || !DeConcat(cSeqToken[-2].getGradient(), sims[0].getGradient(), sims[1].getGradient(), sims[2].getGradient(), sequence.getGradient(), iSequenceDim, iSequenceDim, iSequenceDim, iSequenceDim, 1)) ReturnFalse; for(uint i = 0; i < sims_pos; i++) Deactivation(sims[i]);
Таким образом, каждый уровень сопоставления получает собственный сигнал коррекции. Это позволяет обучать не только итоговое представление последовательности, но и сами механизмы структурного сравнения рыночных состояний.
В финале градиенты последовательной и контекстной частей вновь объединяются.
for(int i = cSeqToken.Total() - 3; i >= 0; i--) { sequence = cSeqToken[i]; if(!sequence || !sequence.CalcHiddenGradients(cSeqToken[i + 1])) ReturnFalse; } iSequenceDim = sequence.Neurons(); //--- if(!Concat(sequence.getGradient(), context.getGradient(), NeuronOCL.getGradient(), iSequenceDim, iContextDim, 1)) ReturnFalse; Deactivation(NeuronOCL); //--- return true; }
Тем самым цикл обратного прохода замыкается. Ошибка проходит через все уровни анализа — от итоговой оценки согласованности до отдельных механизмов сопоставления с паттернами. Благодаря этому обучение охватывает не только локальные представления последовательности, но и всю систему взаимосвязей между структурным, контекстным и динамическим анализом рыночного состояния.
Объект верхнего уровня
Следующим этапом нашей работы становится построение объекта верхнего уровня, который объединяет все компоненты в единую согласованную архитектуру. Здесь, надо сказать, у нас уже есть готовая основа: объект CNeuronReGENTAD. Поэтому задача сводится не к созданию новой системы с нуля, а к точечной замене блока анализа данных CNeuronReGENTADBackbone на новый объект CNeuronGDformerBackbone.
Мы пошли на небольшую архитектурную хитрость. В самом объекте CNeuronReGENTAD объявление CNeuronReGENTADBackbone было изменено со статического на динамическое.
class CNeuronReGENTAD : public CNeuronBaseOCL { protected: CNeuronReGENTADBackbone* cBackbone; ....... virtual CNeuronReGENTADBackbone* CreateBackbone(void) { return new CNeuronReGENTADBackbone(); } .......
На первый взгляд это выглядит как частная техническая правка, однако именно она открыла возможность гибкой подмены внутреннего модуля без изменения всей верхнеуровневой логики.
Естественно, такое изменение потребовало корректировки метода инициализации. Теперь создание объекта верхнего уровня выполняется не напрямую, а через виртуальный метод CreateBackbone().
bool CNeuronReGENTAD::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint heads, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!cBackbone) cBackbone = CreateBackbone(); .......
Благодаря этому родительский класс сохраняет весь свой функционал, а дочерний класс получает возможность заменить только нужный внутренний компонент, не затрагивая остальную архитектуру.
Именно поэтому объект CNeuronGDformer устроен предельно лаконично. Он наследуется от CNeuronReGENTAD и переопределяет лишь метод CreateBackbone().
class CNeuronGDformer : public CNeuronReGENTAD { protected: virtual CNeuronReGENTADBackbone* CreateBackbone(void) override { return new CNeuronGDformerBackbone(); } public: CNeuronGDformer(void) {}; ~CNeuronGDformer(void) {}; //--- virtual int Type(void) override const { return defNeuronGDformer; } };
Все остальное — организация вычислительного процесса, передача данных, работа с обучением и взаимодействие модулей — остается унаследованным от родительского класса. Такой подход позволяет аккуратно встроить новую логику анализа в уже отлаженную архитектуру и сохранить целостность всей системы.
Тестирование
Обучение модели организовано в два этапа. Такой подход позволяет сначала сформировать устойчивое представление о структуре рынка, а затем проверить, насколько хорошо модель способна адаптироваться к изменяющейся динамике уже в процессе последовательной работы.
На первом этапе выполняется офлайн-обучение на архиве котировок EURUSD H1 за 2025 год. Здесь модель изучает характерные рыночные состояния, выявляет повторяющиеся структуры и формирует внутренние взаимосвязи между различными режимами поведения цены. Именно на этом этапе закладывается базовое понимание рыночной динамики и формируется первоначальный набор выученных паттернов.
Однако финансовый рынок постоянно меняется. Даже устойчивые зависимости со временем начинают трансформироваться под воздействием новых условий, изменения волатильности и смены характера движения цены. Поэтому вторым этапом используется онлайн-обучение непосредственно в тестере стратегий MetaTrader 5. В этом режиме модель продолжает адаптацию уже во время последовательного прохождения данных, постепенно уточняя внутренние представления о рынке по мере развития текущей ситуации.
Тестирование проводилось на данных января–апреля 2026 года, то есть сразу после завершения периода основного обучения. Такой подход позволяет оценить, насколько хорошо модель переносит накопленные знания на следующий рыночный участок и способна ли она сохранять устойчивость при естественном изменении рыночного контекста без дополнительного переобучения системы.


За период тестирования при стартовом депозите 3000,0 USD модель показала чистую прибыль 988,45 USD, что соответствует примерно 33% доходности. По форме кривой баланса видно, что система адаптировалась к изменяющейся рыночной динамике.
Особенно важно, что прибыль была получена без чрезмерной нагрузки на депозит. Максимальная просадка по балансу составила 5,69%, а по эквити — 7,40%, что для прикладной торговой системы выглядит вполне умеренно. Profit Factor достиг 1,65, а Sharpe Ratio — 2,52. Это говорит о хорошем соотношении доходности и риска. Стратегия не демонстрирует агрессивной торговли и не пытается выжимать рынок любой ценой. Напротив, поведение капитала остается достаточно устойчивым даже в периоды локальной нестабильности.
За время теста было открыто 135 позиций. При этом доля прибыльных и убыточных входов оказалась почти равной, однако система компенсирует это более высоким средним размером прибыльной сделки: 36,23 USD против среднего убытка 22,90 USD. Особенно уверенно модель чувствовала себя в коротких позициях, где доля прибыльных сделок превысила 62%. Это указывает на то, что архитектура уже начинает различать особенности различных рыночных режимов и по-разному адаптируется к направлению движения цены.
В целом результаты выглядят достаточно убедительно для текущего этапа разработки. Модель демонстрирует способность удерживать положительное математическое ожидание, контролировать просадку и извлекать прибыль из реального рыночного потока. Конечно, говорить о полностью устойчивой торговой системе пока рано, однако архитектура явно вышла за пределы чисто исследовательского эксперимента и начала показывать вполне прикладной результат.
Заключение
Мы завершили адаптацию фреймворка GDformer для решения прикладных задач трейдинга и построили архитектуру, способную анализировать рынок не только через локальные паттерны, но и через более широкий контекст рыночного состояния. Если в исходной постановке GDformer был ориентирован на поиск аномалий временного ряда, то в рамках данного проекта его механизмы были переосмыслены для анализа устойчивых рыночных структур и формирования торговых сигналов в условиях шумной и нестационарной финансовой среды.
В ходе работы был реализован новый модуль анализа рыночного состояния, объединивший подходы GDformer и ReGEN-TAD в единую вычислительную систему. Архитектура модели научилась одновременно учитывать сходство текущего состояния с выученными паттернами, контекст формирования сигнала и динамику развития рынка во времени. Особую роль здесь сыграло объединение трансформерной и рекуррентной магистралей, а также механизм оценки согласованности их представлений, позволяющий дополнительно учитывать степень неопределенности рыночной ситуации.
Практическое тестирование подтвердило работоспособность предложенного подхода. Модель показала положительный финансовый результат, умеренный уровень просадки и достаточно устойчивое поведение капитала на ранее неиспользованном участке истории. При этом наиболее важным итогом работы стал тот факт, что архитектура способна удерживать рыночный контекст и адаптироваться к изменяющейся структуре финансового временного ряда.
Конечно, текущая реализация еще далека от завершенной промышленной торговой системы. Финансовый рынок остается крайне сложной средой, где устойчивые зависимости быстро изменяются под воздействием новых режимов и внешних факторов. Однако выполненная работа показывает, что объединение глобального сопоставления паттернов, контекстного анализа и оценки динамики состояния действительно позволяет приблизиться к более глубокому пониманию поведения рынка. А значит, выбранное направление развития архитектуры имеет не только исследовательскую ценность, но и вполне реальный прикладной потенциал для дальнейшего развития интеллектуальных торговых систем.
Ссылки
- GDformer: Going Beyond Subsequence Isolation for Multivariate Time Series Anomaly Detection
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн-обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн-обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Проект представлен на forge.mql5.io/dng.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Добрый день, Дмитрий!
Тестирую все модели по мере публикации статей, в связи с чем хотел поделиться наблюдением:
При обучении всех последних моделей при сколько-нибудь значительном проценте обучения посредством скрипта Study, не говоря ужпе о 100% пропадают сделки (эффект отмечается на всех последних моделях GDformer, ReGEN-TAD, INFNet, UniMixer). Для GDformer хватило 1.5% на периоде истории указанном в настройках по умолчанию. При создании модели при помощи StudyOnLine сделки есть, но результат, как правило, отрицательный (т.е. убыток). Иногда удавалось «реанимировать» модель в которой после обучения Study нет ни одной сделки применением StudyOnLine. Также заметил, что применение дообучения Study на короткий период резко уменьшает количество сделок, увеличивая при этом прибыльность. Однако «поймать» этот эффект сложно, так как сделки быстро исчезают вообще.
Хотелось бы получить авторский комментарий и рекомендации по обучению моделей.
С уважением, Андрей
Добрый день, Дмитрий!
Тестирую все модели по мере публикации статей, в связи с чем хотел поделиться наблюдением:
При обучении всех последних моделей при сколько-нибудь значительном проценте обучения посредством скрипта Study, не говоря ужпе о 100% пропадают сделки (эффект отмечается на всех последних моделях GDformer, ReGEN-TAD, INFNet, UniMixer). Для GDformer хватило 1.5% на периоде истории указанном в настройках по умолчанию. При создании модели при помощи StudyOnLine сделки есть, но результат, как правило, отрицательный (т.е. убыток). Иногда удавалось «реанимировать» модель в которой после обучения Study нет ни одной сделки применением StudyOnLine. Также заметил, что применение дообучения Study на короткий период резко уменьшает количество сделок, увеличивая при этом прибыльность. Однако «поймать» этот эффект сложно, так как сделки быстро исчезают вообще.
Хотелось бы получить авторский комментарий и рекомендации по обучению моделей.
С уважением, Андрей
Добрый день, Андрей!
Здесь нет ничего неожиданного. Обучение модели — процесс итерационный и достаточно длительный. То, что на начальном этапе офлайн-обучения модель быстро приходит к отсутствию сделок, само по себе не говорит о её поломке.
Любая модель в начале обучения прежде всего собирает статистику и усредняет поведение на всей обучающей выборке. Если в этом периоде нет явно выраженного и устойчивого тренда, самым «средним» действием для модели часто становится отказ от торговли. Иными словами, на раннем этапе она ещё не различает рыночные ситуации, а пытается сформировать одно усреднённое действие для всей истории сразу.
Дальше, по мере обучения, модель должна начать выделять различия между рыночными состояниями. Уже не один общий ответ на всю выборку, а разные средние действия для разных ситуаций: где лучше покупать, где продавать, а где действительно оставаться вне рынка. Поэтому оценивать такую модель по самым первым шагам обучения не совсем корректно. Важнее смотреть динамику на нескольких промежуточных состояниях.
Онлайн-обучение устроено иначе. Там модель фактически начинает с исследования среды и может совершать почти случайные торговые операции. Поэтому большое количество убыточных сделок на начальном этапе вполне ожидаемо. По мере накопления опыта и реакции на вознаграждение модель постепенно формирует свою политику поведения.