
Нейросети в трейдинге: Спайково-семантический подход к пространственно-временной идентификации (Окончание)

Введение
Когда рынок молчит — это не означает, что он спокоен. Под его гладью постоянно бурлит жизнь: вспышки ордеров, дрожание ликвидности, сдвиги объёмов. Всё это — короткие, почти неуловимые импульсы, из которых рождается движение цены. Каждый тик — это сигнал в живой ткани рынка. И именно в эти мгновения, когда большинство ещё видит лишь тишину, начинается настоящий процесс формирования тенденции.
Классические методы анализа слишком инерционны, чтобы уловить этот момент. Они видят уже свершившийся факт — свечу, экстремум, формацию. Но трейдеру важно другое: почувствовать изменение до того, как оно стало очевидным. И вот тут на помощь приходят модели нового поколения — архитектуры, способные распознавать события.
Одной из таких архитектур стала S3CE-Net — Spike-guided Spatiotemporal Semantic Coupling and Expansion Network. Изначально она была предложена для работы с потоками данных событийных камер, где каждый пиксель фиксирует не статичное изображение, а мгновенное изменение света — своего рода спайк, импульс. По сути, это те же события, что и на рынке: неравномерные, асинхронные, краткие, но значимые.
Мы задумались: а ведь финансовый рынок — это тоже событийная система. Здесь нет равномерного течения времени. Всё определяется вспышками активности — моментами, когда в ленте ордеров внезапно появляется крупный игрок, когда ликвидность сжимается, а цена ускоряется. Если научить модель воспринимать эти импульсы как структуру, она сможет предвидеть и реагировать.
В предыдущих работах мы уже познакомились с теоретической основой фреймворка S3CE-Net. Разобрали идею событийного подхода, объяснили, почему рынок можно рассматривать как поток импульсов, и построили фундамент для переноса предложенных подходов в среду MQL5.
Следующий этап стал инженерным шагом вперёд — мы реализовали модуль SSAM (Spike-guided Spatial-Temporal Attention Mechanism) и адаптировали его под вычислительные особенности торгового терминала.
Теперь настало время заключительного этапа. Здесь мы соединяем всё воедино — от концепции до практики, от теории событий до оценки результатов. Мы проверим, как S3CE-Net поведёт себя на реальных исторических данных, насколько она устойчива к рыночному шуму, и сможет ли её внимание различать истинные сигналы среди случайных колебаний.
Архитектура S3CE-Net основана на двух взаимодополняющих идеях. Первая — это SSAM, механизм внимания, который учится фокусироваться на важных событиях и подавлять незначительные. Он словно опытный трейдер, который видит за потоком свечных комбинаций настроение рынка — где импульс наполнен энергией, а где лишь затухающая волна. Вторая — STFS (Spatiotemporal Feature Sampling Strategy). Она расширяет восприятие модели, позволяя ей видеть плавную последовательность взаимосвязанных событий.
Если провести аналогию, SSAM — это трейдерское внимание, а STFS — его память. Вместе они формируют модель, которая умеет замечать и помнить, что происходило раньше. Это и есть настоящая суть анализа: не застревать в моменте, но и не терять связь с контекстом.
Когда мы переносим эти идеи в среду MQL5, задача становится не только технической, но и философской. Видеокамера фиксирует изменение яркости, а рынок — изменение состояния цены и объёма. Каждый тик, каждый всплеск волатильности, каждая смена в стакане — всё это может стать спайком, если правильно определить критерий значимости.
Такой подход заставляет смотреть на рынок иначе. Мы видим систему импульсов, из которых формируется макродвижение. S3CE-Net словно переводит рыночную речь в язык событий, где каждое изменение — это буква, а вся серия — предложение. Модель учится читать этот язык, как опытный аналитик читает график ленты: не глазами, а интуицией. S3CE-Net не ждёт подтверждения паттерна — она реагирует на предвестники. Это особенно важно в условиях высокой волатильности, где классические индикаторы запаздывают.
Трейдеру, который привык опираться на свечные паттерны или индикаторы, идея может показаться непривычной. Но если взглянуть внимательнее — это логичное продолжение эволюции анализа. Сначала мы оценивали уровни и зоны, потом переходили к вероятностным моделям, теперь пришло время событийных. Это естественный шаг — от наблюдения к пониманию, от данных к смыслу.
Именно поэтому работа над реализацией S3CE-Net средствами MQL5 не ограничивается чисто техническими целями. Мы стремимся показать, как архитектурные принципы, созданные для совершенно другой области, могут вдохнуть новую жизнь в рыночный анализ. Ведь и трейдинг, и событийная аналитика — это поиск структуры в хаосе, умение выделять смысл из потока.
Рынок, как и любая живая система, дышит неравномерно, и тот, кто сумеет услышать этот ритм, получает преимущество. S3CE-Net — попытка сделать этот слух машинным, дать алгоритму способность чувствовать, где начинается движение, а где заканчивается. Это не магия — это следствие внимательного анализа структуры событий.
Авторская визуализация фреймворка S3CE-Net представлена ниже.

Сегодня мы подходим к логическому финалу. Позади — архитектура, реализация, адаптация. Впереди — тестирование, оценка и, возможно, переосмысление привычного подхода к прогнозированию. Мы посмотрим, как построенная модель справляется с реальными рыночными потоками, насколько точно различает истинные сигналы, и как её спайковое внимание отражается на качестве прогнозов.
Модуль STFS
Сегодня нам остаётся сделать заключительный шаг в реализации подходов, предложенных авторами фреймворка S3CE-Net, — построить модуль STFS (Spatio-Temporal Feature Sampling Strategy). Это финальный элемент всей архитектуры, способный научить модель видеть рынок целостно — воспринимать широкий контекст, а не зацикливаться на локальных паттернах.
Как и любой опытный трейдер, STFS учится отделять главное от второстепенного. Его задача — заставить модель анализировать не только конкретные фрагменты рыночных данных, но и взаимосвязи между ними, сочетая восприятие времени и пространства. Ведь рынок — это не просто линия на графике. Это многомерная система, где каждая свеча, каждый объём или импульс связаны между собой невидимыми нитями. Именно их и должен научиться распознавать алгоритм.
Авторы S3CE-Net предложили для этого весьма изящный механизм. В процессе обучения модуль разделяет карту признаков на подвыборки по времени и по пространству.
Сначала выполняется временное семплирование. Из всей последовательности случайным образом выбирается набор временных шагов. Для каждого из них вычисляется усреднённое представление, своего рода срез состояния рынка в конкретный момент. Эти срезы формируют набор временных признаков, отражающих динамику процесса.
Затем следует пространственное семплирование. Карта признаков делится на несколько случайных областей. Каждая область усредняется отдельно, что позволяет выделить локальные структуры. Если проводить аналогию с рынком, это похоже на анализ разных секторов рыночной активности.
Наконец, на последнем этапе извлекается глобальный семантический вектор, представляющий собой обобщённое представление всего рыночного состояния. Он создаётся путём усреднения всей карты признаков и играет роль интегрального показателя, синтезирующего как временные, так и пространственные закономерности.
Обучение модели опирается на две ключевые функции потерь: триплет-лосс и кросс-энтропию со сглаживанием меток. Первая помогает модели выделять основные признаки, усиливая различия между действительно значимыми состояниями рынка. Вторая стабилизирует обучение, предотвращая переоценку случайных колебаний. В совокупности они придают системе интуицию, которая позволяет ей не теряться в рыночном шуме.
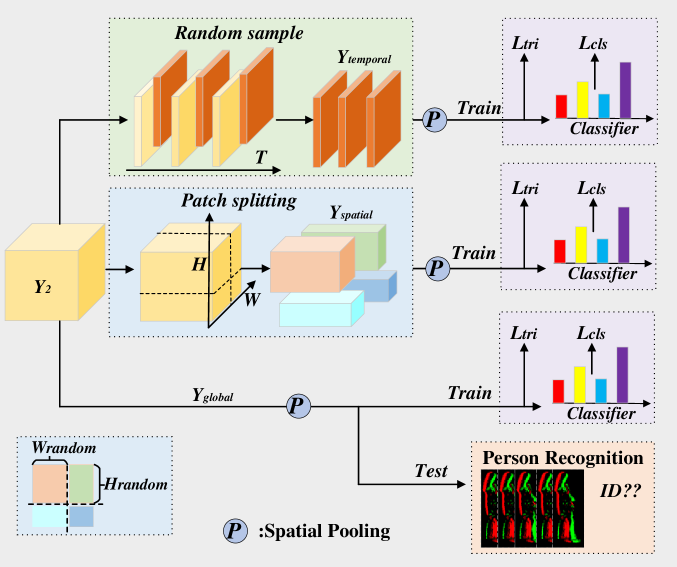
В своей работе мы позволим себе слегка переосмыслить оригинальный подход, предложенный авторами S3CE-Net. Если в исходной концепции основное внимание уделялось анализу пространственно-временной структуры изображения, то в случае финансовых данных природа анализируемого сигнала иная. Рынок не имеет геометрии — его структура не визуальная, а смысловая. Здесь признаки представляют собой вектор экономических факторов, где каждая координата несёт собственный контекст: цену, объём, волатильность, индикаторы настроений, структурные метрики ликвидности. И что особенно важно — их взаимосвязи не обязаны коррелировать с близостью индексов в этом векторе.
Именно поэтому прямое применение пространственного семплирования, как в классической реализации STFS для изображений, не всегда оправдано. Мы не можем предполагать, что соседние элементы в векторе признаков имеют схожее значение или влияние. В рыночных данных соседство носит логико-функциональный характер. Цена может быть тесно связана с объёмом, но никак не с индексом технического индикатора, стоящего рядом в массиве данных.
По этой причине мы используем переосмысленную стратегию семплирования, аналогичную временному, но применяемую к пространственной (признаковой) оси. Иными словами, как во временном семплировании мы выбираем случайные временные точки, так и здесь мы будем случайным образом выбирать подмножество признаков, формируя выборку для обучения модели. Такой подход сохраняет идею случайности и обобщения, но делает её релевантной именно для векторных рыночных данных, где ключевым является смысл, а не расположение.
Кроме того, в отличие от оригинальной методики, где данные, не попавшие в выборку, просто отбрасываются, мы поступим иначе. Ни один признак не будет потерян. Из оставшихся данных мы сформируем альтернативные выборки, которые будут использоваться в качестве вспомогательных контекстов. Это не только повышает эффективность обучения, но и улучшает устойчивость модели — она учится видеть рынок под разными углами, словно анализируя его через набор независимых, но согласованных наблюдений.
В результате на выходе формируется пять различных представлений анализируемых данных:
- полное (глобальное), отражающее общий рыночный фон;
- 2 семпла — по времени и по признакам, обеспечивающих локальную фокусировку модели;
- 2 альтернативные выборки, которые служат дополнительными источниками для контекстного обучения.
Мы также вносим изменения в способ формирования итогового прогноза. В классическом варианте STFS для изображений используется усреднение признаков выбранных блоков, после чего формируется единый вектор. В рыночных данных такой подход может сглаживать важные сигналы, теряя тонкие, но значимые импульсы.
Поэтому мы поступаем иначе: для каждой из полученных выборок формируется отдельный прогноз. Иными словами, модель не объединяет информацию заранее, а анализирует каждую перспективу отдельно. Это позволяет оценивать сигналы в разных контекстах, не теряя локальной значимости данных и сохраняя возможность различать слабые, но потенциально важные тенденции.
Такой подход близок к аналитическому стилю профессионального трейдера. Опытный специалист никогда не полагается на один индикатор или на один временной промежуток: он строит несколько сценариев одновременно, сопоставляет их между собой и на этой основе делает решение о позиции. Точно так же наша модель учится генерировать несколько прогнозов на одной и той же информации, видя рынок под разными углами.
Теперь, когда концепция построения модуля STFS определена и уточнена, настало время перейти к практической реализации. Первым шагом мы формируем 5 представлений анализируемых данных. Для эффективного и параллельного создания всех выборок мы задействуем OpenCL-контекст, что позволяет обрабатывать массивы данных одновременно и существенно ускоряет вычисления.
В основе реализации лежит кернел STFS, который создаёт подвыборки по случайным маскам временных шагов и признаков. Каждая точка данных проверяется на корректность, после чего формируются все необходимые комбинации выборок. Такой подход позволяет одновременно создавать как основную, так и альтернативные выборки, не дожидаясь последовательной обработки, что критически важно для работы с потоковыми рыночными данными.
__kernel void STFS(__global const float* inputs, __global const float* mask_time, __global const float* mask_spatial, __global float* outputs ) { const size_t time_id = get_global_id(0); const size_t spat_id = get_global_id(1); const size_t head = get_local_id(2); const size_t total_times = get_global_size(0); const size_t total_spats = get_global_size(1); const size_t total_heads = get_local_size(2); //--- __local float temp[3];
Для каждой позиции в потоке данных мы определяем локальные и глобальные идентификаторы по времени, пространственной оси и головам (heads), которые отвечают за разные типы выборок.
На первом этапе определяются смещения в плоских буферах данных до соответствующих элементов.
const int shift_in = RCtoFlat(time_id, spat_id, total_times, total_spats, 1); const int shift_out = RCtoFlat(time_id, spat_id, total_times, total_spats, head);
Далее из глобальных буферов данных извлекаются необходимые значения, включая временные и пространственные маски, с помощью которых производится фильтрация данных.
С целью минимизации количества дорогих операций обращения к глобальной памяти мы распределяем их между потоками рабочей группы и сохраняем значения в массив локальной памяти. В результате каждое значение извлекается из глобального буфера только один раз.
switch(head) { case 0: temp[0] = IsNaNOrInf(inputs[shift_in], 0); break; case 1: temp[1] = IsNaNOrInf(mask_time[time_id], 0); break; case 2: temp[2] = IsNaNOrInf(mask_spatial[spat_id], 0); break; } BarrierLoc
Затем алгоритм создаёт отдельные подвыборки. Одна — для основного временного семпла, вторая — для альтернативной временной выборки, третья — для признакового семпла и четвертая — для альтернативного набора признаков.
float out = temp[0]; if(out != 0) switch(head) { case 1: out *= temp[1]; break; case 2: out *= (1 - temp[1]); break; case 3: out *= temp[2]; break; case 4: out *= (1 - temp[2]); break; } //--- outputs[shift_out] = IsNaNOrInf(out, 0); }
Каждая из этих подвыборок сохраняется в своем блоке массива результатов для дальнейшей обработки моделью.
Таким образом, результатом работы кернела становится полный набор из пяти представлений исходных данных, готовых к последующей генерации отдельных прогнозов. Это ключевой момент практической реализации STFS: модель получает возможность одновременно учиться на разных глазах рынка, видя его и глобально, и локально, и через альтернативные перспективы.
Стоит отметить, что алгоритм кернела для распределения градиентов ошибки построен по аналогичной логике. Детали реализации этого механизма предлагаем оставить их для самостоятельного изучения. Полный код OpenCL-программы, представлен во вложении.
Следующим этапом нашей работы становится построение модуля STFS на стороне основной программы, что позволит интегрировать все идеи семплирования и генерации прогнозов в единую архитектуру. Для этого создаётся новый объект CNeuronSTFS, наследующий базовые возможности нейрона с поддержкой OpenCL от CNeuronBaseOCL.
class CNeuronSTFS : public CNeuronBaseOCL { protected: CNeuronBaseOCL cMaskTime; CNeuronBaseOCL cMaskSpatial; CNeuronBaseOCL cConcatenated; CNeuronConvOCL cSpatialDScale; CNeuronConvOCL cTimeDScale; CNeuronTransposeVRCOCL caTranspose[2]; CBufferFloat cOne; //--- virtual bool STFS(CNeuronBaseOCL *NeuronOCL); virtual bool STFSGrad(CNeuronBaseOCL *NeuronOCL); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSTFS(void) {}; ~CNeuronSTFS(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint units_in, uint units_out, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSTFS; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Структура класса отражает ключевые компоненты STFS: отдельные объекты для временных и признаковых масок (cMaskTime, cMaskSpatial), тензор объединения представлений (cConcatenated) и специализированные сверточные и транспонирующие слои (cSpatialDScale, cTimeDScale, caTranspose[2]), обеспечивающие корректную проекцию пространственно-временных данных. Все эти элементы вместе формируют платформу, на которой модель способна одновременно учитывать различные аспекты рыночной информации и формировать пять вариантов прогнозных значений, полученных из разных представлений.
Все внутренние компоненты класса CNeuronSTFS объявлены статично, что позволяет оставить конструктор и деструктор пустыми. Объект создаётся и подготавливается полностью в методе Init. Этот подход упрощает управление памятью и обеспечивает предсказуемую инициализацию всех частей модуля.
bool CNeuronSTFS::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint units_in, uint units_out, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, chanels_out * units_out, optimization_type, batch)) return false; activation = None;
Метод Init выполняет последовательную настройку каждого внутреннего элемента STFS-модуля. Сначала вызывается базовая инициализация родительского класса, после чего устанавливается отсутствие активации на основном объекте.
Здесь особенно важно отметить, что отсутствие функции активации на уровне модуля является обязательным условием корректного функционирования алгоритма. Авторы фреймворка S3CE-Net предлагают использовать модуль STFS только на стадии обучения. В режиме промышленной эксплуатации, когда система формирует прогнозы в реальном времени, используется только полное представление данных, без создания подвыборок. Поэтому на выходе модуля, как будет показано далее, возвращается только прогноз, полученный на основе полного представления, а все промежуточные подвыборки служат исключительно для усиления процесса обучения и формирования более устойчивой и точной модели. Однако, внутри модуля выстраивается параллельный процесс обучения подвыборок, и для правильного распространения градиентов между всеми компонентами модуля нужна чистая ошибка, без корректировок на производную функции активации.
В то же время, для гибкости в зависимости от потребностей пользователя допускается функциональное использование активации, но она переносится на последний объект проекции данных. Именно там, при получении итогового прогноза, можно применять нелинейную трансформацию, если это требуется для конкретного сценария работы модели.
Но вернемся к алгоритму инициализации. Далее создаются и настраиваются маски для временного и признакового семплирования. Каждая получает свой индекс.
int index = 0; if(!cMaskTime.Init(0, index, OpenCL, units_in, optimization, iBatch)) return false; cMaskTime.SetActivationFunction(None); index++; if(!cMaskSpatial.Init(0, index, OpenCL, chanels_in, optimization, iBatch)) return false; cMaskSpatial.SetActivationFunction(None);
Объект конкатенирования представлений формируется с учётом всех признаком и размера последовательности, умноженных на количество семплов, обеспечивая основу для последующего прогноза.
index++; if(!cConcatenated.Init(0, index, OpenCL, chanels_in * units_in * 5, optimization, iBatch)) return false; cConcatenated.SetActivationFunction(None);
После этого инициализируются блок проекции, состоящий из сверточных слоев прекции пространственных и временных компонентов (cSpatialDScale, cTimeDScale), которым задаются соответствующие функции активации для корректного масштабирования выходных сигналов.
if(!cSpatialDScale.Init(0, index, OpenCL, chanels_in, chanels_in, chanels_out, units_in, 5, optimization, iBatch)) return false; cSpatialDScale.SetActivationFunction(SoftPlus); index++; if(!cTimeDScale.Init(0, index, OpenCL, units_in, units_in, units_out, chanels_out, 5, optimization, iBatch)) return false; cTimeDScale.SetActivationFunction(TANH);
Завершают инициализацию объекты транспонирования, которые обеспечивают согласованное преобразование данных между различными представлениями.
index++; if(!caTranspose[0].Init(0, index, OpenCL, 5, units_in, chanels_out, optimization, iBatch)) return false; if(!caTranspose[1].Init(0, index, OpenCL, 5, chanels_out, units_out, optimization, iBatch)) return false;
Буфер cOne используется только в алгоритме распределения градиентов ошибки и позволяет получить копии данных для всех проекций.
if(!cOne.BufferInit(5, 1) || !cOne.BufferCreate(OpenCL)) return false; //--- return true; }
Все элементы настраиваются для выполнения параллельных вычислений на стороне OpenCL-контекста, что гарантирует высокую производительность при обработке массивов рыночных данных.
Алгоритм прямого прохода реализован в методе feedForward. Его задача — пошагово пропустить данные через все компоненты модуля, чтобы получить готовое представление для прогноза.
bool CNeuronSTFS::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!STFS(NeuronOCL)) return false;
Сначала вызывается метод STFS, который создаёт пять представлений данных — полное, два семпла и две альтернативные выборки. В нем, в отличие от привычных нам методов постановки кернелов в очередь выполнения, сначала семплируются маски временных шагов и анализируемых признаков. И лишь после проведения подготовительной работы передается управление соответствующему кернелу.
После этого данные проходят через сверточный слой проекции пространственных признаков, что позволяет модели выделить локальные структуры и взаимосвязи между признаками в разных представлениях.
if(!cSpatialDScale.FeedForward(cConcatenated.AsObject())) return false;
Далее осуществляется трансформация тензора, обеспечивающая корректное преобразование между пространственным и временным представлением.
if(!caTranspose[0].FeedForward(cSpatialDScale.AsObject())) return false;
После этого сверточный слой временной проекции обрабатывает данные по оси времени, фиксируя динамику рынка и выявляя значимые временные закономерности.
if(!cTimeDScale.FeedForward(caTranspose[0].AsObject())) return false;
Второй транспонирующий слой возвращает данные в исходное представление.
if(!caTranspose[1].FeedForward(cTimeDScale.AsObject())) return false;
На завершающем этапе мы выделяем лишь данные глобального представления, как предлагают авторы фреймворка в процессе промышленной эксплуатации.
if(!DeConcat(Output, caTranspose[1].getPrevOutput(), caTranspose[1].getOutput(), Neurons(), caTranspose[1].Neurons() - Neurons(), 1)) return false; //--- return true; }
Таким образом, метод feedForward обеспечивает плавный поток данных через весь модуль STFS, создавая основу для последующих вычислений ошибки, обновления весов и формирования финального прогноза на основе полного представления данных.
После того как модель сформировала прогнозные значения, наступает этап работы над ошибками — обратного распространения градиентов. Метод calcInputGradients отвечает за распределение погрешности между всеми компонентами модуля STFS в соответствии с их влиянием на итоговый результат.
bool CNeuronSTFS::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Здесь важно подчеркнуть, что модуль STFS может использоваться как на выходе модели, так и внутри более сложной архитектуры. В таких случаях на вход обратного распространения мы получаем не фактические значения, а ошибку, переданную от последующих объектов сети.
При этом различные проекции данных — глобальная, временная, признаковая и альтернативные выборки — имеют различные погрешности. И для корректного обучения каждой проекции желательно иметь целевые значения, а не отклонения. Чтобы получить эти целевые значения, прогнозные результаты модуля суммируются с поступившей ошибкой, формируя тензор, на основе которого можно корректно обучать отдельные проекции.
Именно поэтому отсутствие функции активации на выходе модуля становится критически важным. Любая нелинейная трансформация исказила бы этот процесс, и сеть потеряла бы возможность правильно распределять погрешности и формировать точные целевые значения для каждой проекции.
if(!SumAndNormilize(Output, Gradient, PrevOutput, 1, false, 0, 0, 0, 1)) return false; if(!MatMul(GetPointer(cOne), PrevOutput, caTranspose[1].getGradient(), cOne.Total(), 1, Neurons(), 1, false)) return false;
Полученный тензор целевых значений мы умножаем на единичный вектор, в результате чего получаем нужное количество копий. И теперь уже определяем погрешность каждого из представлений.
float error = 1; if(!caTranspose[1].calcOutputGradients(caTranspose[1].getGradient(), error)) return false;
Далее градиенты распространяются через блок проекции данных до тензора конкатенации представлений, аккуратно учитывая вклад каждого элемента в общий прогноз.
if(!cTimeDScale.CalcHiddenGradients(caTranspose[1].AsObject())) return false; if(!caTranspose[0].CalcHiddenGradients(cTimeDScale.AsObject())) return false; if(!cSpatialDScale.CalcHiddenGradients(caTranspose[0].AsObject())) return false; if(!cConcatenated.CalcHiddenGradients(cSpatialDScale.AsObject())) return false;
Особое внимание уделяется STFSGrad — функции обертки одноименного кернела, который обеспечивает сбор погрешностей внутри модуля STFS от всех подвыборок и передает их исходным данным.
if(!STFSGrad(NeuronOCL)) return false; //--- return true; }
Именно благодаря этому механизму модель учится видеть и различать глобальные и локальные закономерности рынка, формируя устойчивую и точную модель прогнозирования.
В практическом смысле для трейдера это означает, что каждый элемент модуля, от подвыборок до сверточных блоков, получает обратную связь о своей значимости для итогового прогноза, что повышает качество обучения и позволяет модели эффективно справляться с шумной и изменчивой рыночной информацией.
Полный код класса и всех его методов представлен во вложении.
Архитектура моделей
После того как все ключевые модули фреймворка были реализованы, мы переходим к следующему этапу — описанию архитектуры модели. Следуя подходу авторов S3CE-Net, в качестве основы мы используем модель Энкодера состояния окружающей среды из SEW-ResNeXt, которая доказала свою эффективность в выделении значимых признаков из потоковых данных.
Внутри этой архитектуры мы на трёх уровнях внедряем SSAM-блоки, обеспечивающие селективное внимание к наиболее информативным признакам и их комбинациям. Такой подход позволяет сети акцентироваться на ключевых сигналах рынка, минимизируя влияние шумов и случайных колебаний, что особенно важно для финансовых данных с высокой волатильностью.
Чтобы не перегружать текст статьи и сохранить её читабельность, мы не приводим полную схему Энкодера. Подробности архитектуры доступны во вложении к статье, где каждый слой и блок описаны подробно. Читатель может самостоятельно ознакомиться с точечными правками архитектуры и с полной структурой.
Следует особо отметить, что модуль STFS используется исключительно на этапе обучения. В реальной эксплуатации, когда модель формирует прогнозы в реальном времени, подвыборки и отдельные проекции данных не нужны, и их формирование только увеличивает нагрузку на ресурсы. Чтобы экономно использовать вычислительные мощности, мы вынесли STFS в отдельную модель, которая задействуется только для обучения.
Модель начинается с создания слоя исходных данных, который соответствует анализируемым признакам и окну наблюдения.
//--- STFS stfs.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (window * count); descr.activation = None; descr.optimization = ADAM; if(!stfs.Add(descr)) { delete descr; return false; }
Следующим шагом добавляется слой STFS, где задаются параметры каналов и единиц для входа и выхода. Этот слой выполняет ключевую функцию — формирует пять подвыборок данных и рассчитывает прогнозы для каждой, используя заданную функцию активации TANH. Именно этот слой обеспечивает параллельное обучение на различных проекциях рынка, повышая устойчивость модели и её способность выявлять значимые сигналы.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSTFS; { uint temp[] = {window, // Chanels In BarDescr // Chanels Out }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {count, // Units In NForecast // Units Out }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.activation = TANH; descr.optimization = ADAM; if(!stfs.Add(descr)) { delete descr; return false; }
Завершается конфигурация слоем BatchNorm, который нормализует результат STFS-блока, поддерживая стабильность обучения и предотвращая избыточное смещение градиентов. В данном случае этот слой выполняет ещё одну важную функцию: учит распределение целевых данных и добавляет его к прогнозным значениям, генерируемым STFS-модулем.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = NForecast*BarDescr; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!stfs.Add(descr)) { delete descr; return false; }
Выделение STFS в отдельную модель позволяет разделить обучение и промышленное использование, снижая нагрузку на систему в реальном времени, но при этом полностью сохраняя преимущества параллельного обучения на различных проекциях рынка.
Что касается архитектуры моделей Актера и Критика, она полностью перенесена из нашей предыдущей работы. Это позволяет сохранить проверенные временем решения для генерации действий и оценки их качества. А также интегрировать новые компоненты без нарушения стабильности обучения. В результате мы получаем полноценную модель, которая сочетает в себе как традиционные подходы к управлению стратегией на рынке, так и современные методы выделения значимых признаков и устойчивого прогнозирования.
Тестирование
Мы завершили масштабную работу по интеграции всех ключевых компонентов фреймворка, и настало время оценить эффективность реализованных решений. Но сначала необходимо обучить и тщательно проверить стратегию на исторических и симулированных данных, словно тренируя навыки опытного трейдера и проверяя способность алгоритма действовать в самых разнообразных рыночных условиях.
Первый этап — офлайн-обучение — осуществим на исторических данных валютной пары EURUSD таймфрейм H1 за период с Января 2024 по Июнь 2025 года. Этот временной отрезок стал своеобразной тренировочной площадкой. Модель училась распознавать исторические паттерны, понимать динамику цен и объёмы сделок, выявлять закономерности между ключевыми признаками и использовать их в прогнозах. Благодаря STFS-модулю она параллельно осваивала глобальное и локальное представление данных, формируя пять различных проекций, что усиливало точность и устойчивость прогнозов. Можно сказать, что модель развивала интуицию трейдера, совмещённую с математической строгостью анализа данных.
Следующий этап — тонкая онлайн-настройка в тестере стратегий MetaTrader 5 — позволил модели работать с потоками данных в реальном времени. Здесь она осваивала динамику живого рынка, училась сохранять стабильность на фоне рыночного шума, корректировать действия при низкой ликвидности и мгновенно реагировать на резкие ценовые всплески. SSAM-блоки обеспечивали акцент на наиболее информативных признаках, даже когда данные нестабильны.
Финальная проверка проводилась на данных за Июль—Сентябрь 2025 года, полностью новых и ранее не использованных. Все параметры, полученные на предыдущих этапах, загружались без изменений, что обеспечивало честную оценку способности модели к обобщению. Результаты подтверждают, что пошаговый подход к обучению и адаптации, с использованием STFS и SSAM, позволяют модели анализировать рынок и формировать прогнозы движения ключевых рыночных признаков, на которые трейдер может опираться при принятии реальных торговых решений.

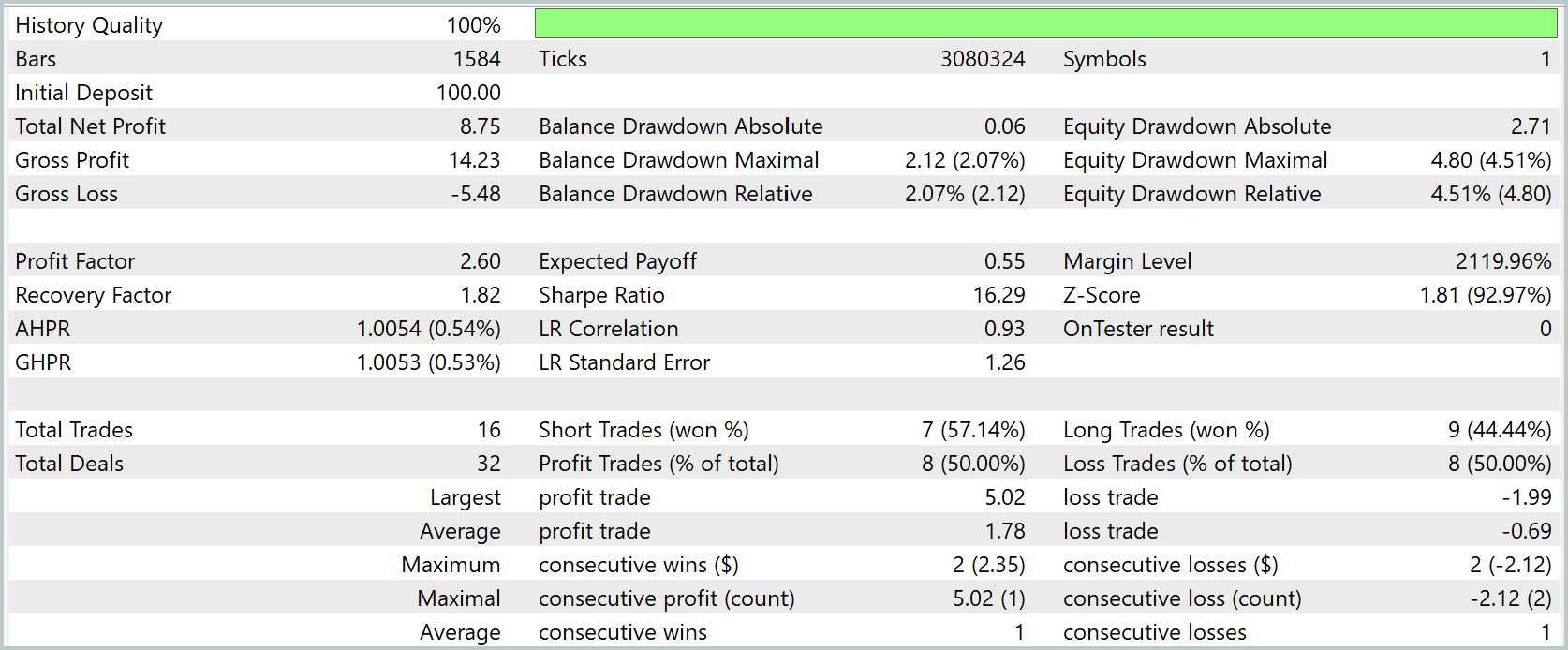
Результаты тестирования модели демонстрируют высокую стабильность и точность прогнозов. Баланс счёта показал уверенный рост с начального депозита $100 до $108.75, при этом эквити плавно следовало за балансом, что свидетельствует о корректной работе механизма распределения прогнозов и управления рисками.
Максимальная просадка по балансу составила всего 2.07%, а по эквити — 4.51%, что говорит о низком уровне риска и устойчивости стратегии даже при рыночных колебаниях. Общий коэффициент прибыльности равен 2.60, что подтверждает способность модели эффективно отбирать прибыльные сигналы.
С точки зрения структуры сделок, из 16 торговых операций 8 оказались прибыльными, что соответствует 50% успешных сделок, а средняя прибыльная сделка составила 1.78, в то время как средний убыток был ограничен 0.69, демонстрируя хороший баланс между доходностью и риском. Наибольшая прибыль по одной сделке достигла 5.02, а наибольший убыток ограничен 1.99, что также подтверждает аккуратность модели в управлении капиталом.
Модель, объединяющая SSAM и STFS, показала аккуратный, низкопрофильный рост капитала с небольшой просадкой и хорошим отношением прибыли к риску. Результат перспективный, но пока статистически ограниченный. Прежде чем переводить стратегию в реальную торговлю, необходимо провести более масштабные и стрессовые тесты, подтвердив устойчивость поведения на длинных и жёстких рыночных отрезках.
Заключение
Мы прошли полный путь от идеи до рабочего инструмента и сделали это так, словно собирали точный часовой механизм — аккуратно, по шагам и с вниманием к деталям.
Средствами MQL5 мы реализовали ключевые блоки S3CE-Net:
- внедрили SSAM в энкодер SEW-ResNeXt,
- переработали STFS под вектор признаков рынка,
- подготовили OpenCL-кернел для параллельного формирования пяти представлений.
Главная инженерная мысль — разделение режимов. STFS работает эффективно, но его место — на обучении. В продакшене оставляем только глобальное представление. Это экономит ресурсы и сохраняет предсказуемость поведения. Практический нюанс, который важно помнить: отсутствие активации внутри модуля — не прихоть, а требование для корректного формирования целевых тензоров и распространения градиентов между проекциями.
Проведенные тесты на EURUSD H1 за Июль—Сентябрь 2025 показали обещающие результаты. Модель действует консервативно. Всё это — хороший фундамент, но не приговор на всю жизнь стратегии.
Что важно понимать трейдеру: текущие метрики внушают оптимизм, но статистика мала. Высокие показатели на небольшой выборке могут обмануть. Наша задача дальше — не праздновать победу, а проверить её стойкость.
Ссылки
- S3CE-Net: Spike-guided Spatiotemporal Semantic Coupling and Expansion Network for Long Sequence Event Re-Identification
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования