
Нейросети в трейдинге: Обучение глубоких спайкинговых моделей (Окончание)

Введение
Финансовый рынок, как и любая сложная нелинейная система, живёт по своим законам. Он дышит, колеблется, накапливает энергию и разряжает её в виде резких ценовых движений. И чем внимательнее мы изучаем его динамику, тем яснее понимаем: классические методы анализа уже не всегда успевают за изменчивостью современных торговых сценариев. На смену приходит новое поколение алгоритмов — более чувствительных, адаптивных и способных видеть за поверхностью графика внутренний импульс рынка.
В предыдущих работах мы прошли путь от базовых принципов спайкинговых вычислений до реализации ключевых архитектурных решений, открывающих путь к практическому использованию таких моделей в MQL5-среде. И сегодня мы подходим к финальной ступени этого маршрута — воплощению подходов, предложенных авторами фреймворка SEW ResNet (Spiking Elementary Weights Residual Network), применительно к задачам анализа и прогнозирования финансовых временных рядов.
Своим появлением SEW ResNet обязан стремлению объединить вычислительную эффективность спайкинговых моделей с устойчивостью и глубиной классических архитектур ResNet. В основе подхода — идея энергетически сбалансированного обучения, когда информация передаётся серией дискретных импульсов. Каждый спайк несёт весовой смысл, каждая задержка — отражает реакцию системы на сигнал. В результате модель не только экономнее в вычислениях, но и точнее улавливает причинно-следственные связи между событиями во времени — это особенно важно для анализа ценовых импульсов и рыночных всплесков активности.
В контексте финансовых рынков это открывает новые возможности. Ведь рыночный сигнал по своей природе спайковый. Он неравномерен, содержит периоды тишины и вспышки активности, где мгновение отделяет хаос от закономерности. Классические нейросети в таких условиях часто залипают на шуме или теряют чувствительность при длительных колебаниях. SEW ResNet же, напротив, построен так, чтобы сохранять реактивность — он реагирует только на действительно значимые изменения потока данных, фильтруя всё лишнее естественным образом.
На предыдущих этапах мы шаг за шагом выстраивали основу будущей архитектуры. Каждый реализованный модуль стал кирпичиком в фундаменте фреймворка, где техническая строгость сочеталась с интуитивной логикой рыночных процессов.
Модуль спайковой активации с адаптивными порогами стал первым ключевым элементом этой системы. Его задача — управлять реакцией нейрона на входящий поток сигналов, различая важные колебания от естественного шума. В классических спайковых моделях активация фиксирована и часто реагирует одинаково на любое изменение. Мы же пошли по пути биологического прототипа: адаптивный порог меняется в зависимости от интенсивности входных импульсов и частоты спайков. В результате сеть учится реагировать только тогда, когда это действительно необходимо, избегая переобучения на случайных колебаниях цен.
Для рынка это имеет прямое прикладное значение. Такой механизм позволяет алгоритму устойчиво работать в условиях высокой волатильности, где классические модели нередко теряют точность. Когда на графике царит хаос, адаптивный порог выступает как встроенный фильтр рыночного шума, помогая системе сохранять ясность восприятия и реагировать лишь на ключевые изменения тренда.
Следующим шагом стало внедрение гейтового механизма, отвечающего за регулирование чувствительности нейрона к новизне поступающего сигнала. По сути, гейт определяет, насколько сильно текущий сигнал должен повлиять на накопление потенциала мембраны. Иными словами — регулирует степень участия нового импульса в формировании внутреннего состояния нейрона. Это придаёт системе динамичную гибкость. Она способна по-разному реагировать на повторяющиеся и новые паттерны, постепенно вырабатывая собственное чувство привыкания к однотипным событиям.
В терминах финансового рынка это напоминает поведение опытного трейдера, который не поддаётся на каждое движение цены, а обращает внимание лишь на действительно новые сигналы, нарушающие устоявшийся баланс. Гейтовый механизм выступает регулятором внимательности модели — он определяет, когда стоит усилить реакцию, а когда наоборот, снизить её, сохранив устойчивость восприятия. Такое управление чувствительностью позволяет фильтровать ложные импульсы, не теряя при этом способности к обучению на реальных изменениях рыночной динамики.
Реализация подходов, предложенных авторами фреймворка SEW ResNet, в нашей работе опирается на архитектуру ResNeXt, модифицированную под спайковую динамику и адаптивную чувствительность. В основе подхода — идея многоканального восприятия, где каждая параллельная ветвь модели обрабатывает данные под собственным углом, а затем результаты аккуратно объединяются в единый вектор рыночного восприятия. Такая организация позволяет модели не просто фиксировать факт движения цены, а различать его характер, интенсивность и направленность — то, что обычно трейдер определяет чутьём.
Ключевое звено модели — модуль Spike ResNeXt Bottleneck, выступающий своеобразным фильтром смыслов. Он сжимает поступающий поток сигналов, пропускает через узкий канал и разворачивает обратно, но уже в очищенном, структурированном виде. Эта идея классического Bottleneck приобретает здесь спайковое измерение. Каждый элемент блока способен решать, когда ему реагировать, а когда сохранять молчание.
В реализации Bottleneck используется динамический массив компонентов cBottleneck, формирующий вычислительный путь блока. Слои создаются программно — в зависимости от заданных пользователем параметров. Поток проходит через серию последовательных преобразований: сверточные операции, нормализацию, спайковую активацию и групповые свёртки. Вся цепочка выстроена так, чтобы обеспечить сбалансированное сочетание точности и скорости реакции.
Не менее важен модуль Spike ResNeXt Residual, отвечающий за передачу накопленного опыта. Его структура обеспечивает корректное согласование размерностей между основным и коротким путями, позволяя сохранить информацию о предыдущих состояниях без искажений. В финансовом контексте это аналог трейдерской памяти — способности помнить, что происходило до текущего импульса, и корректировать реакцию с учётом истории.
Residual-блок реализован на основе того же динамического принципа: если размерности входа и выхода не совпадают, добавляются промежуточные свёрточные и нормализующие слои. Такое решение делает архитектуру устойчивой к изменению параметров модели, позволяя свободно масштабировать глубину сети без нарушения внутренней логики сигналов.
Особое преимущество подхода — энергетическая эффективность. Реализованная проверка нулевых входов исключает ненужные вычисления в моменты, когда рынок молчит. Во время низкой волатильности многие нейроны просто не активируются, что снижает нагрузку на систему и ускоряет вычисления без потери точности. Этот принцип соответствует естественной экономике внимания: модель концентрируется только на тех участках рынка, где действительно происходит что-то важное.
Сочетание многоканальной архитектуры ResNeXt и адаптивной спайковой логики SEW формирует уникальный гибрид, в котором математическая точность встречается с рыночной интуицией. Каждая ветвь модели обучается собственному взгляду на данные, а остаточные связи обеспечивают слияние этих перспектив в единое решение. Благодаря этому, модель демонстрирует устойчивость к шуму и способность выделять тонкие закономерности — те самые слабые сигналы, которые предвещают зарождение тренда.
Практическая ценность такого подхода очевидна: модель не просто анализирует прошлое, а учится распознавать моменты изменения рыночного состояния. Это даёт преимущество в построении стратегий прогнозирования, фильтрации ложных сигналов и автоматическом управлении торговыми решениями.
Авторская визуализация фреймворка представлена ниже.
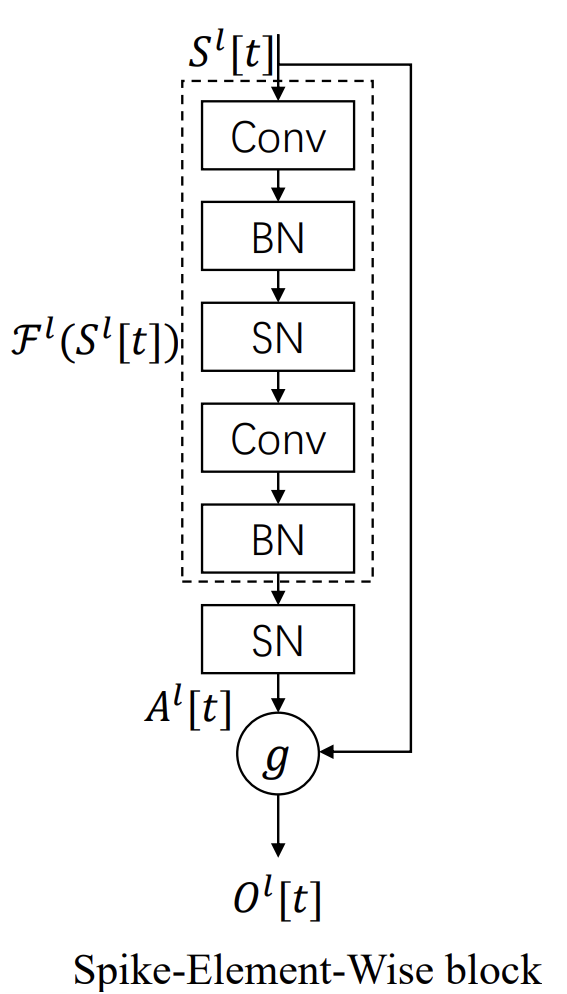
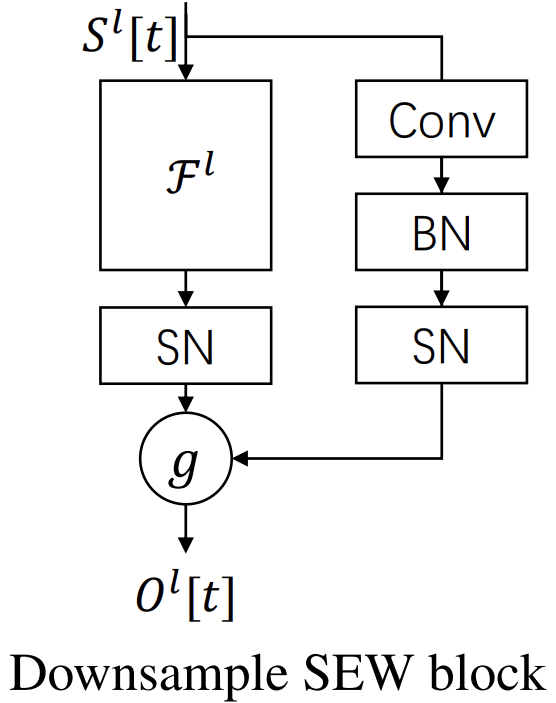
Основные принципы реализации
После того как были последовательно реализованы отдельные модули, перед нами встал закономерный вопрос: как объединить эти элементы в единую, стройную архитектуру, где каждая часть дополняет другую, а вся система работает как целостный организм.
Однако спешить здесь нельзя. Архитектура должна не просто соединять блоки, а обеспечивать гармоничное взаимодействие уровней обработки, где низкоуровневые признаки плавно переходят в более абстрактные рыночные структуры. Поэтому логично сначала рассмотреть саму основу — тот каркас, на котором будет строиться наш спайковый интеллект. Как уже было сказано ранее, этим каркасом стал фреймворк ResNeXt, известный своей модульной гибкостью и высокой производительностью.
Мы взяли за основу ResNeXt, но наделили его спайковой природой сигналов. В классическом варианте ResNeXt анализирует потоки данных, опираясь на параллельные ветви обработки, каждая из которых вычленяет собственный аспект входной информации. В нашей реализации эти ветви преобразованы в спайковые каналы, способные самостоятельно регулировать чувствительность и частоту реакций на изменения рынка.
В модуле Spike Bottleneck уже реализован базовый цикл восприятия последовательности: сигнал сжимается, преобразуется и снова разворачивается, сохраняя смысловую целостность данных. Такая схема отлично работает при анализе унитарных временных рядов, где зависимость между элементами последовательности однородна. Однако рынок устроен сложнее. Мы имеем дело с мультимодальной временной структурой, в которой параллельно развиваются взаимосвязанные процессы — цена, объём, волатильность, ликвидность, открытый интерес и множество других признаков.
Попытка анализировать каждый из этих каналов независимо, как отдельную унитарную последовательность, приводит к потере критически важной информации. Между признаками существует тесная динамическая связь: изменение объёма влияет на амплитуду ценовых колебаний, волатильность определяет ритм рынка, а ликвидность задаёт глубину реакции на внешние воздействия. При раздельной обработке этих сигналов такая взаимосвязь разрушается, и модель теряет способность видеть структурную целостность рыночного поведения.
Чтобы устранить этот пробел, в нашей реализации мы вводим второй Bottleneck, который работает с транспонированным представлением исходного тензора. В отличие от стандартного анализа унитарных последовательностей, этот блок рассматривает данные в разрезе отдельных временных шагов, анализируя сразу все каналы на каждом моменте времени. Это позволяет модели вычленять межканальные зависимости, фиксировать их динамику и учитывать комплексное влияние признаков друг на друга.
При этом мы сохраняем только один Residual-блок, чтобы не усиливать чрезмерно влияние остаточных связей. Такое решение обеспечивает баланс между сохранением информации о прошлых состояниях и эффективной обработкой новых комбинаций сигналов. В результате модель получает возможность одновременно:
- извлекать локальные закономерности внутри каждой унитарной последовательности;
- фиксировать межканальные зависимости и согласованную динамику признаков;
- сохранять устойчивость к шуму и переизбытку сигналов благодаря ограничению остаточных связей.
Гибридный подход превращает архитектуру SEW ResNeXt в инструмент, способный видеть рынок как комплексную динамическую систему: каждый признак взаимосвязан с другими, а изменения одного элемента находят отклик во всей структуре модели.
Следующий важный аспект, который необходимо обсудить, — это выбор функции поэлементного комбинирования спайков для наших трех информационных потоков. С точки зрения риск-ориентированного подхода и бинарной природы спайков, привлекательным вариантом выглядит поэлементное умножение. В этом случае сигнал проходит только при подтверждении по всем потокам одновременно. Такой принцип можно сравнить с осторожным трейдером, открывающим позицию только тогда, когда каждый индикатор подтвердил сигнал.
На первый взгляд решение кажется логичным и строгим — модель реагирует только на согласованную информацию, снижая риск ложных срабатываний. Однако стоит внимательно рассмотреть, как при этом распределяется градиент ошибки.
Если сигнал подтвержден во всех информационных потоках, градиент ошибки распределяется равномерно. Но если хотя бы один поток не сгенерировал спайк, градиент направляется исключительно на него, а остальные получают нулевую корректировку. С точки зрения логики, это имеет смысл. Когда хотя бы один поток возвращает ноль, дальнейшего сигнала нет, и именно этот поток требует корректировки. Градиент ошибки сигнализирует о том, что нужно включить данный поток.
Проблема возникает в критическом случае, когда все информационные потоки остаются закрытыми. В этом сценарии каждый элемент поэлементного умножения равен нулю, и градиент ошибки, умноженный на эти нули, полностью блокируется. В результате нейрон перестаёт получать обратную связь — он мертвый, а его параметры деградируют. На практике это может приводить к остановке обучения части сети или даже всей модели, особенно если такие ситуации повторяются часто.
Иными словами, строгое поэлементное умножение превращается в ловушку для обучения. Оно защищает от ложных сигналов, но одновременно создаёт риск полного отключения нейронов.
Беспрепятственное прохождение градиентов ошибки обеспечивает простое суммирование значений, как это реализовано в классическом ResNet. Такой подход гарантирует, что даже если все информационные потоки временно закрыты, градиент ошибки сможет корректировать параметры нейрона и обучение продолжится без блокировок.
Однако здесь возникает конфликт с концепцией спайков. В отличие от бинарного сигнала «0» или «1», суммирование нескольких активных потоков может дать значения 2 или 3. Это нарушает спайковую природу активации и может привести к нежелательной сверхсигнализации, когда модель реагирует слишком резко. В рыночных терминах это похоже на трейдера, который открывает позицию с избыточной уверенностью без реальной поддержки данных.
Взвесив все риски, мы пришли к более сбалансированной конструкции — нормализуем сумму значений информационных потоков и затем применяем спайковую активацию. Это позволяет одновременно сохранить бинарную интерпретацию сигнала и обеспечить корректное распространение градиентов ошибки. Нормализация ограничивает результирующее значение в допустимом диапазоне, предотвращая чрезмерные отклики, а также создаёт возможность генерации реверсного сигнала. Такой сигнал возникает, когда несколько потоков одновременно блокируют активацию, и сеть получает информацию о необходимости обратной коррекции. Аналогично осторожному трейдеру, который снижает позицию при резком противодействии рыночным сигналам.
Модуль верхнего уровня
Для практической реализации предложенной концепции мы создали новый объект CNeuronSpikeResNeXtBlock, который аккуратно объединяет все ключевые элементы нашей архитектуры.
class CNeuronSpikeResNeXtBlock : public CNeuronSpikeActivation { protected: CNeuronTransposeOCL caTranspose[2]; CNeuronSpikeResNeXtBottleneck caBottleneck[2]; CNeuronSpikeResNeXtResidual cResidual; CLayer cG; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikeResNeXtBlock(void) {}; ~CNeuronSpikeResNeXtBlock(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint units_in, uint units_out, uint group_size, uint groups, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeResNeXtBlock; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; };
В его основе лежат два Bottleneck‑блока, один Residual‑блок и транспонированные представления исходных данных, что позволяет учитывать отдельные унитарные последовательности и сложные межканальные взаимосвязи. Наследуя CNeuronSpikeActivation, этот класс сохраняет спайковую природу сигналов и интегрирует гейты с адаптивными порогами, обеспечивая гибкую реакцию нейронов на изменения рыночной динамики.
Одним из ключевых элементов блока является динамический массив для сохранения указателей на объекты функции комбинирования спайков cG, который существенно расширяет возможности блока и открывает пространство для экспериментов. Этот массив позволяет подключать и использовать разные варианты поэлементного объединения сигналов, включая как простое суммирование, так и нормализованное комбинирование с последующей спайковой активацией. Благодаря такой конструкции блок становится не просто фиксированной структурой, а гибкой платформой для тестирования различных стратегий интеграции сигналов, подстраиваясь под особенности конкретных рыночных данных.
Подготовка нового блока полностью возложена на метод Init, который отвечает за инициализацию всех его ключевых компонентов и настройку их взаимодействия.
bool CNeuronSpikeResNeXtBlock::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint units_in, uint units_out, uint group_size, uint groups, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSpikeActivation::Init(numOutputs, myIndex, open_cl, chanels_out * units_out, optimization_type, batch)) return false;
Его алгоритм начинается с вызова одноименного метода родительского класса, обеспечивая фундамент для спайковой обработки и интеграции гейтов с адаптивными порогами.
Далее метод инициализирует транспонированные представления исходного тензора. Первый объект подготавливает данные для анализа унитарных последовательностей, второй обеспечивает обратное транспонирование данных. Такой подход позволяет модели одновременно учитывать структуру отдельных потоков и взаимодействие между ними, закладывая основу для корректного распространения сигналов и градиентов.
uint index = 0; if(!caTranspose[0].Init(0, index, OpenCL, units_in, chanels_in, optimization, iBatch)) return false; index++; if(!caTranspose[1].Init(0, index, OpenCL, chanels_out, units_out, optimization, iBatch)) return false;
Следующим шагом инициализируются Bottleneck‑блоки. Первый Bottleneck обрабатывает классические унитарные последовательности, выявляя локальные закономерности сигналов, а второй работает с транспонированным представлением, фиксируя межканальные зависимости и согласованную динамику признаков. Каждый блок получает параметры каналов, число групп и размер группировки, а также необходимые параметры оптимизации и размер батча.
index++; if(!caBottleneck[0].Init(0, index, OpenCL, chanels_in, chanels_out, units_in, units_out, group_size, groups, optimization, iBatch)) return false; index++; if(!caBottleneck[1].Init(0, index, OpenCL, units_in, units_out, chanels_in, chanels_out, group_size, groups, optimization, iBatch)) return false;
После этого метод инициализирует Residual‑блок, который сохраняет критически важные остаточные связи, обеспечивая устойчивость и баланс между памятью нейрона и адаптивностью.
index++; if(!cResidual.Init(0, index, OpenCL, chanels_in, chanels_out, units_in, units_out, optimization, iBatch)) return false;
Наконец, метод создаёт cG, содержащий динамический массив объектов функции комбинирования спайков. Здесь последовательно добавляются базовый нейрон без активации и объект пакетной нормализации. Такая последовательность позволяет корректно суммировать и нормализовать сигналы от разных информационных потоков.
CNeuronBaseOCL* neuron = NULL; CNeuronBatchNormOCL* norm = NULL; cG.Clear(); cG.SetOpenCL(OpenCL); index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, Neurons(), optimization, iBatch) || !cG.Add(neuron)) { DeleteObj(neuron) return false; } neuron.SetActivationFunction(None); //--- if(!cResidual.SetGradient(neuron.getGradient(), true) || !caTranspose[1].SetGradient(neuron.getGradient(), true) || !caBottleneck[0].SetGradient(neuron.getGradient(), true)) return false; //--- index++; norm = new CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, Neurons(), iBatch, optimization) || !cG.Add(norm)) { DeleteObj(norm) return false; } //--- return true; }
При этом в блоке предусмотрена синхронизация указателей на буферы градиентов ошибки для ключевых компонентов, что гарантирует корректное распространение ошибки в сети без излишнего копирования данных и предотвращает деградацию сигналов.
В результате метод Init формирует полностью готовый блок, в котором каждый компонент инициализирован, настроен и связан с остальными.
Прямой проход сигналов реализован в методе feedForward, который обеспечивает последовательную обработку информации через все ключевые компоненты SEW ResNeXt блока.
bool CNeuronSpikeResNeXtBlock::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!caTranspose[0].FeedForward(NeuronOCL)) return false;
Сначала данные проходят через первый транспонированный блок, формируя представление временных шагов для дальнейшего анализа. После этого сигнал последовательно обрабатывается первым Bottleneck‑модулем, выявляющим локальные закономерности унитарных последовательностей.
if(!caBottleneck[0].FeedForward(NeuronOCL)) return false;
Второй Bottleneck, в свою очередь, работает с выходом транспонированного блока, фиксируя межканальные зависимости и согласованную динамику признаков.
if(!caBottleneck[1].FeedForward(caTranspose[0].AsObject())) return false; if(!caTranspose[1].FeedForward(caBottleneck[1].AsObject())) return false;
Затем информация проходит через второй транспонированный блок, подготавливая её к интеграции с остаточными связями, которые обеспечиваются Residual‑блоком*.
if(!cResidual.FeedForward(NeuronOCL)) return false;
На следующем этапе осуществляется комбинирование спайков. Производится суммирование сигналов от обоих Bottleneck и Residual.
CNeuronBaseOCL* current = cG[0]; if(!current) return false; if(!SumAndNormilize(caBottleneck[0].getOutput(), caTranspose[1].getOutput(), current.getOutput(), caTranspose[1].GetCount(), false, 0, 0, 0, 1) || !SumAndNormilize(current.getOutput(), cResidual.getOutput(), current.getOutput(), caTranspose[1].GetCount(), false, 0, 0, 0, 1)) return false;
Такой подход позволяет корректно интегрировать как унитарные, так и межканальные сигналы, сохраняя бинарную природу спайков и предотвращая деградацию нейронов.
Далее оставшиеся элементы массива cG проходят собственный цикл прямого прохода, где каждый объект получает на вход-выход предыдущего нейрона, обеспечивая последовательное распространение сигналов через все функции комбинирования.
for(int i = 1; i < cG.Total(); i++) { current = cG[i]; if(!current || !current.FeedForward(cG[i - 1])) return false; } //--- return CNeuronSpikeActivation::feedforward(cG[-1]); }
Завершается процесс вызовом одноименного метода родительского класса, который выполняет финальную обработку спайковых сигналов и передаёт результаты на следующий уровень модели.
Таким образом, алгоритм прямого прохода обеспечивает плавное и структурированное прохождение сигналов через все компоненты блока, интегрируя локальные и межканальные зависимости, нормализуя комбинированные спайки и сохраняя корректное распространение градиентов ошибки для обучения. В рыночном контексте это позволяет модели одновременно реагировать на локальные изменения каждого потока и на согласованную динамику признаков, создавая стабильную и адаптивную систему анализа финансовых данных.
Корректное распределение градиентов реализовано в методе calcInputGradients, который обеспечивает последовательное и согласованное обновление параметров всех компонентов SEW ResNeXt блока.
bool CNeuronSpikeResNeXtBlock::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Работа метода начинается с проверки корректности полученного указателя на объект исходных данных и вызова одноименного метода родительского класса, что гарантирует правильное распространение градиентов до последнего слоя модуля комбинирования спайков cG.
if(!CNeuronSpikeActivation::calcInputGradients(cG[-1])) return false;
Далее проходим по всем элементам динамического массива cG в обратном порядке, от последнего к первому, вычисляя скрытые градиенты каждого нейрона на основе выхода следующего в цепочке.
CNeuronBaseOCL* current = NULL; for(int i = cG.Total() - 2; i >= 0; i--) { current = cG[i]; if(!current || !current.CalcHiddenGradients(cG[i + 1])) return false; }
Такой подход позволяет корректно распределить ошибку по всем функциям комбинирования и нормализации, обеспечивая согласованное обучение на уровне спайков.
Здесь следует обратить внимание, что благодаря подмене указателей на буферы градиентов ошибки основных компонентов, после передачи погрешности до уровня первого элемента массива cG, она автоматически передаётся во все информационные потоки блока. Этот приём позволяет гарантировать, что каждый поток получает корректную обратную связь без необходимости вручную синхронизировать градиенты для каждого компонента. В результате распределение ошибки происходит естественно и непрерывно, обеспечивая согласованное обучение всей структуры блока и предотвращая деградацию нейронов даже при сложных взаимозависимых сигналах.
Далее полученные градиенты передаются ко второму Bottleneck и транспонированному блоку, фиксируя влияние межканальных зависимостей на ошибку модели.
if(!caBottleneck[1].CalcHiddenGradients(caTranspose[1].AsObject())) return false; if(!caTranspose[0].CalcHiddenGradients(caBottleneck[1].AsObject())) return false;
Затем обратная ошибка распространяется через Residual‑блок, что позволяет корректировать остаточные связи без избыточного усиления влияния предыдущих сигналов.
if(!NeuronOCL.CalcHiddenGradients(cResidual.AsObject())) return false;
Особое внимание уделено корректному сохранению данных всех информационных потоков. Для этого используется временный буфер данных, который аккумулирует информацию об ошибке и корректно передаёт обратно на входы. Это предотвращает возникновение мертвых нейронов, обеспечивая устойчивое и непрерывное обучение даже при временном отсутствии сигналов в отдельных потоках.
CBufferFloat* temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(caTranspose[0].getPrevOutput(), false)) return false; if(!NeuronOCL.CalcHiddenGradients(caBottleneck[0].AsObject())) return false; if(!SumAndNormilize(temp, NeuronOCL.getGradient(), temp, caTranspose[0].GetWindow(), false, 0, 0, 0, 1)) return false; if(!NeuronOCL.CalcHiddenGradients(caTranspose[0].AsObject())) return false; if(!SumAndNormilize(temp, NeuronOCL.getGradient(), temp, caTranspose[0].GetWindow(), false, 0, 0, 0, 1)) return false; if(!NeuronOCL.SetGradient(temp, false)) return false; //--- return true; }
В результате метод calcInputGradients обеспечивает согласованное и безопасное распределение градиентов ошибки через все компоненты блока, от транспонированных последовательностей и Bottleneck‑модулей до Residual и блока комбинирования спайков. Такой механизм гарантирует, что каждый нейрон получает достаточную обратную связь, корректирует свои параметры и поддерживает адаптивность модели, способной анализировать сложные мультимодальные рыночные последовательности.
Полный исходный код класса CNeuronSpikeResNeXtBlock со всеми реализованными методами приведён во вложении, что позволяет подробно изучить внутреннюю работу блока и проследить логику обработки сигналов на каждом этапе.
Архитектура модели
Следующим этапом нашей работы становится построение архитектуры обучаемых моделей. Как и ранее, мы продолжаем работать в парадигме Actor-Critic, создавая модель, способную самостоятельно принимать торговые решения и реагировать на изменения рынка. Все ранее реализованные подходы SEW ResNeXt мы интегрируем в Энкодер состояния окружающей среды, который выступает в роли органа восприятия для модели, аккумулируя и обрабатывая всю входящую информацию о рынке.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&actor, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Процесс построения Энкодера начинается с инициализации самого массива слоёв, после чего формируется входной слой, принимающий сырые данные истории цен и признаков баров.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; uint prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer = 0;
За ним следует слой пакетной нормализации с добавлением шума, обеспечивающий устойчивость и плавность обучения.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++;
А затем слой ConcatDiff, агрегирующий временные различия для создания первичного скрытого представления.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatDiff; prev_count = descr.count = HistoryBars; descr.layers = BarDescr; descr.step = 1; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++; uint prev_out = descr.layers * 2 ;
Далее используется слой Mamba4CastEmbedding, который кодирует информацию о временных интервалах, подготавливая данные для более сложной обработки.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defMamba4CastEmbeding; prev_count = descr.count = HistoryBars; descr.window = prev_out; prev_out = descr.window_out = NSkills; { uint temp[] = {PeriodSeconds(PERIOD_D1), PeriodSeconds(PERIOD_MN1)}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++;
На следующем этапе в работу включаются слои NeuronSpikeResNeXtBlock, повторяющиеся многократно и формирующие глубокое, многоканальное представление состояния рынка.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSpikeResNeXtBlock; { uint temp[] = {prev_out, // Chanels In prev_out, // Chanels Out EmbeddingSize/2 // Group Size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {prev_count, // Units In prev_count, // Units Out NScenarios // Groups Count }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.optimization = ADAM; descr.batch = BatchSize; descr.activation = None; for(int i = 0; i < 2; i++) if(!encoder.Add(descr)) { delete descr; return false; } else iLatentLayer++; //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSpikeResNeXtBlock; { uint temp[] = {prev_out, // Chanels In prev_out * 2, // Chanels Out EmbeddingSize/2 // Group Size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {prev_count, // Units In prev_count / 2, // Units Out NScenarios // Groups Count }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.optimization = ADAM; descr.batch = BatchSize; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++; prev_count = descr.units[1]; prev_out = descr.windows[1]; //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSpikeResNeXtBlock; { uint temp[] = {prev_out, // Chanels In prev_out, // Chanels Out EmbeddingSize/2 // Group Size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {prev_count, // Units In prev_count, // Units Out NScenarios // Groups Count }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.optimization = ADAM; descr.batch = BatchSize; descr.activation = None; for(int i = 0; i < 2; i++) if(!encoder.Add(descr)) { delete descr; return false; } else iLatentLayer++; //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSpikeResNeXtBlock; { uint temp[] = {prev_out, // Chanels In prev_out * 2, // Chanels Out EmbeddingSize/2 // Group Size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {prev_count, // Units In prev_count / 2, // Units Out NScenarios // Groups Count }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.optimization = ADAM; descr.batch = BatchSize; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++; prev_count = descr.units[1]; prev_out = descr.windows[1]; //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSpikeResNeXtBlock; { uint temp[] = {prev_out, // Chanels In prev_out, // Chanels Out EmbeddingSize/2 // Group Size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {prev_count, // Units In prev_count, // Units Out NScenarios // Groups Count }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.optimization = ADAM; descr.batch = BatchSize; descr.activation = None; for(int i = 0; i < 2; i++) if(!encoder.Add(descr)) { delete descr; return false; } else iLatentLayer++; //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSpikeResNeXtBlock; { uint temp[] = {prev_out, // Chanels In prev_out * 2, // Chanels Out EmbeddingSize/2 // Group Size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {prev_count, // Units In prev_count / 2, // Units Out NScenarios // Groups Count }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.optimization = ADAM; descr.batch = BatchSize; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } iLatentLayer++; prev_count = descr.units[1]; prev_out = descr.windows[1]; //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSpikeResNeXtBlock; { uint temp[] = {prev_out, // Chanels In prev_out, // Chanels Out EmbeddingSize/2 // Group Size }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {prev_count, // Units In prev_count, // Units Out NScenarios // Groups Count }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.optimization = ADAM; descr.batch = BatchSize; descr.activation = None; for(int i = 0; i < 2; i++) if(!encoder.Add(descr)) { delete descr; return false; } else iLatentLayer++; uint window = prev_out; uint count = prev_count;
Каждый блок получает на вход выходы предыдущего, учитывает межканальные зависимости и нормализует суммированные спайки, обеспечивая корректную передачу сигналов через всю сеть. Параметры каналов, число групп, размер батча и оптимизация подбираются так, чтобы блоки могли эффективно кодировать мультимодальные последовательности и сохранять адаптивность даже при резких рыночных колебаниях.
После серии спайковых блоков Энкодер завершается слоями свёртки и транспонирования, которые консолидируют выходное представление и формируют финальный скрытый вектор состояния, предназначенный для построения прогноза предстоящего движения анализируемых рыночных признаков. Этот тензор аккумулирует информацию о временных и межканальных зависимостях, обеспечивая точное и согласованное представление состояния рынка.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = BarDescr; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = descr.count; //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NForecast; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = descr.count;
Последний слой, NeuronRevInDenormOCL обеспечивает корректное масштабирование и денормализацию сигналов.
//--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count * prev_out; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
Архитектуры Actor и Critic полностью перенесены из предыдущих работ без изменений, сохраняя проверенную временем структуру и функционал. С ними можно ознакомиться во вложении к статье. Благодаря такой организации, наша модель получает мощный Энкодер, способный воспринимать сложные временные и межканальные зависимости рынка, а Actor и Critic используют это представление для точного прогнозирования и принятия торговых решений.
Тестирование
Мы завершили большую работу по интеграции ключевых компонентов фреймворка SEW ResNeXt, и пришло время оценить эффективность реализованных решений. Прежде чем доверить модели реальные средства, необходимо тщательно проверить стратегию на исторических и симулированных данных, словно тренируя навыки опытного трейдера и проверяя её способность действовать в самых разнообразных рыночных условиях. Каждый этап имитирует живой рынок, позволяя модели постепенно нарабатывать опыт, учиться отличать сигналы от шума и вырабатывать устойчивые алгоритмы поведения, необходимые для работы в реальной торговой среде.
Первый этап — офлайн-обучение — проходит на исторических данных валютной пары EURUSD таймфрейм H1 за период с Января 2024 по Июнь 2025 года. Этот временной отрезок стал настоящей тренировочной площадкой. Модель училась воспроизводить исторические паттерны, понимать динамику цен и объёмы сделок, выявлять закономерности и зависимость между ключевыми признаками. Можно сказать, что она развивала интуицию трейдера, совмещённую с точной стратегической оценкой. Постепенно формировалась способность предугадывать движение рынка и оценивать риск каждой потенциальной сделки.
Следующий этап — тонкая онлайн-настройка в тестере стратегий MetaTrader 5 — позволит модели работать с потоками данных в реальном времени, свеча за свечой. Здесь она осваивает динамику реального рынка, учится сохранять стабильность на фоне рыночного шума, корректировать действия при низкой ликвидности и мгновенно реагировать на резкие ценовые всплески. Этот этап стал своеобразной доводкой стратегии. Базовая структура, сформированная на исторических данных, оставалась неизменной, но модель осваивала гибкое реагирование на текущую рыночную обстановку, минимизируя риск переобучения и повышая точность прогнозов даже в нестабильной среде.
Финальная проверка осуществлялась на данных за Июль—Сентябрь 2025 года — полностью новых и ранее не использованных. Все параметры, полученные на предыдущих этапах, загружались без изменений, что обеспечивало честную оценку способности модели к обобщению. Результаты тестирования подтверждают, что пошаговый подход к обучению и адаптации позволяет модели анализировать рынок и формировать прогноз предстоящего движения ключевых рыночных признаков, на который можно опираться при принятии реальных торговых решений.

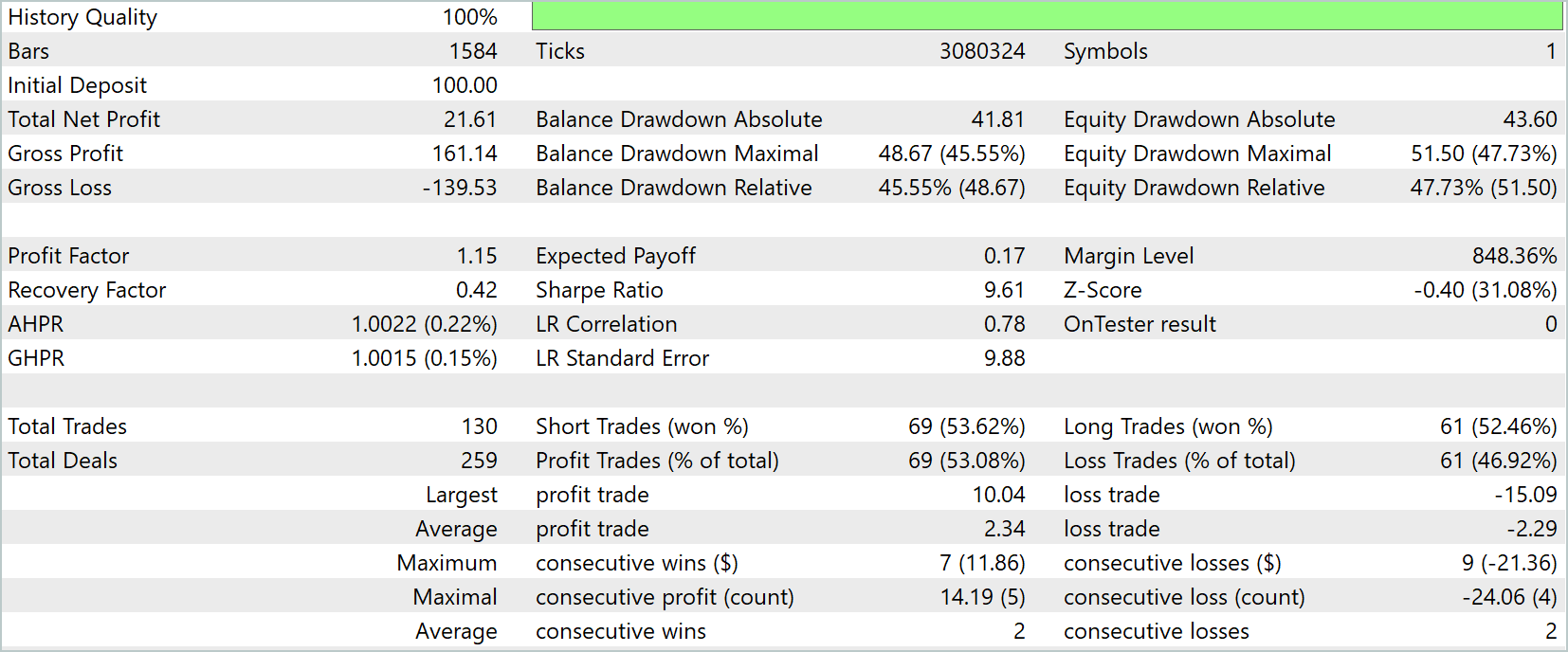
График баланса и эквити демонстрирует стабильный рост капитала на протяжении практически всего периода тестирования. Несмотря на отдельные просадки, эквити остаётся близкой к балансу. Это указывает на сдержанную и контролируемую стратегию управления рисками. Максимальная просадка по эквити составила 47,73%, что достаточно высоко для волатильных условий, но соответствует сценариям теста на временном отрезке с резкими колебаниями цены.
Общая прибыль составила 21,61 USD при начальном депозите 100,0 USD, что соответствует росту капитала на более чем 20% за рассматриваемый период. Показатель Profit Factor равен 1,15. Это указывает на превышение общей прибыли над суммой убытков, а коэффициент Sharpe в 9,61 свидетельствует о высокой эффективности стратегии с учётом риска. При этом Recovery Factor равен 0,42. Он отражает необходимость внимания к управлению просадками при экстраполяции на большие объёмы капитала.
Модель совершила 130 сделок, из которых чуть более половины оказались прибыльными (53,08%), а средняя прибыль на сделку составила 2,34 USD, тогда как средний убыток — 2,29 USD. Максимальная последовательность выигрышных сделок равна 7 с совокупной прибылью 11,86 USD, а максимальная последовательность убытков — 9 сделок с суммарным минусом 21,36 USD. Эти показатели демонстрируют умеренную агрессивность стратегии и способность модели адаптироваться к краткосрочным рыночным колебаниям.
Особое внимание стоит обратить на равномерность распределения сделок между короткими и длинными позициями: 69 шортов и 61 лонг, с коэффициентами успешности 53,62% и 52,46%, соответственно. Это указывает на сбалансированное поведение модели в различных рыночных сценариях и способность реагировать как на рост, так и на падение цены.
В целом, результаты тестирования подтверждают работоспособность построенного фреймворка на основе SEW ResNeXt с элементами спайковой активации. Модель демонстрирует устойчивость, адаптивность к динамике рынка и разумный риск-менеджмент, что делает её подходящей для дальнейшей работы в реальных условиях финансовых рынков.
Заключение
Мы завершили практическую реализацию подходов, предложенных авторами фреймворка SEW ResNet, и построили рабочую платформу, где каждая деталь имеет прикладной смысл. Спайковые активации с адаптивными порогами научили модель сдержанно реагировать. Гейты добавили чувствительность к новизне. Два Bottleneck-блока дали компромисс между локальным анализом и учётом межканальных зависимостей. Резидуальный блок сохранил память, но не дал ей задушить адаптацию.
Результаты теста подтвердили работоспособность концепции. Рост капитала 21.6% — это объективный сигнал эффективности. Profit Factor 1.15 и чуть более 50% выигрышных сделок говорят о работоспособной логике сигналов. Средняя прибыль и средний убыток близки по величине — модель не полагается на счастливые редкие сделки. При этом максимальная просадка 47% — серьёзный вызов, который нельзя игнорировать.
Сильные стороны реализации очевидны. Модель эффективно фильтрует рыночный шум. Она видит взаимосвязи между каналами, которые теряются при раздельном анализе. Архитектура сохраняет поток градиентов и остаётся обучаемой даже в тяжёлых сценариях. Код модульный. OpenCL-интеграция даёт путь к ускорению и масштабированию.
В то же время есть и рубежи для работы. Высокая максимальная просадка требует усиления риск-менеджмента. Тесты в симуляторе — это ещё не реальная торговля: ожидаемые проскальзывания, спрэды и рыночная ликвидность могут изменить профили прибыли и убытков. Объём выборки и специфика периода тоже влияют — нужна тщательная валидация на новых данных и в разных режимах рынка.
Практическое заключение простое: архитектура оправдала себя как исследовательская и прикладная платформа. Она даёт трейдеру инструмент, который можно отлаживать, интерпретировать и улучшать. Но это не конец пути.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования