
Нейросети в трейдинге: Единая архитектура взаимодействия рыночных признаков и торгового контекста (Основные компоненты)

Введение
В предыдущей статье мы познакомились с фреймворком OneTrans — новой нейросетевой моделью, предложенной для решения задач промышленного ранжирования и рекомендательных систем. На первый взгляд подобная область может показаться далёкой от финансовых рынков, однако, при более внимательном анализе становится очевидно, что многие фундаментальные проблемы этих систем совпадают. И там, и здесь модель должна анализировать длинные последовательности событий, учитывать контекст текущего состояния анализируемой системы и находить закономерности во взаимодействии большого числа признаков. Именно эта концептуальная близость позволяет нам рассматривать фреймворк OneTrans в качестве перспективной основы для построения торговых моделей.
Традиционные подходы к разработке алгоритмических стратегий обычно строятся по достаточно простой схеме. Сначала создаётся модель прогнозирования, анализирующая динамику рынка и формирующая оценку будущего движения цены. Затем поверх полученного прогноза накладываются торговые правила, определяющие точки входа, выхода и параметры управления риском. Подобная архитектура знакома большинству разработчиков и долгое время служила основой для построения торговых систем. Однако она имеет важное ограничение: модель прогнозирует рынок изолированно, не учитывая состояние самой торговой системы. Между тем реальные решения на рынке почти всегда принимаются с учётом текущих позиций, доступного капитала, структуры риска и других факторов контекста.
Архитектура OneTrans предлагает принципиально иной взгляд на эту задачу. Вместо раздельной обработки последовательных данных и контекстных признаков, модель объединяет их в единую структуру. Все исходные данные преобразуются в набор токенов, которые затем обрабатываются единым стеком Transformer-блоков. Благодаря механизму внимания модель способна автоматически выявлять взаимосвязи между различными элементами анализируемых данных. Последовательность событий и состояние системы перестают существовать как два независимых источника информации и рассматриваются как единое пространство факторов, формирующих итоговое решение.
Для задач анализа финансовых рынков подобная постановка выглядит вполне естественной. Рыночные данные сами по себе представляют последовательность событий — изменения цены, объёма, волатильности и других характеристик рынка. Одновременно торговая система обладает собственным внутренним состоянием: текущими позициями, параметрами риска, структурой капитала и историей сделок. В реальной торговле все эти элементы неизбежно взаимодействуют друг с другом. Следовательно, модель, способная анализировать их совместно, потенциально получает более полное представление о происходящем на рынке.
Центральным элементом OneTrans является единая токенизированная структура данных, в которой различаются два типа элементов. Первый тип образуют последовательные токены, представляющие динамику событий во времени. В нашем случае это элементы рыночной истории. Второй тип формируют контекстные токены, описывающие состояние торговой системы и другие дополнительные параметры. Такое разделение позволяет модели одновременно учитывать как эволюцию рыночных процессов, так и внутренний контекст принимаемых торговых решений.
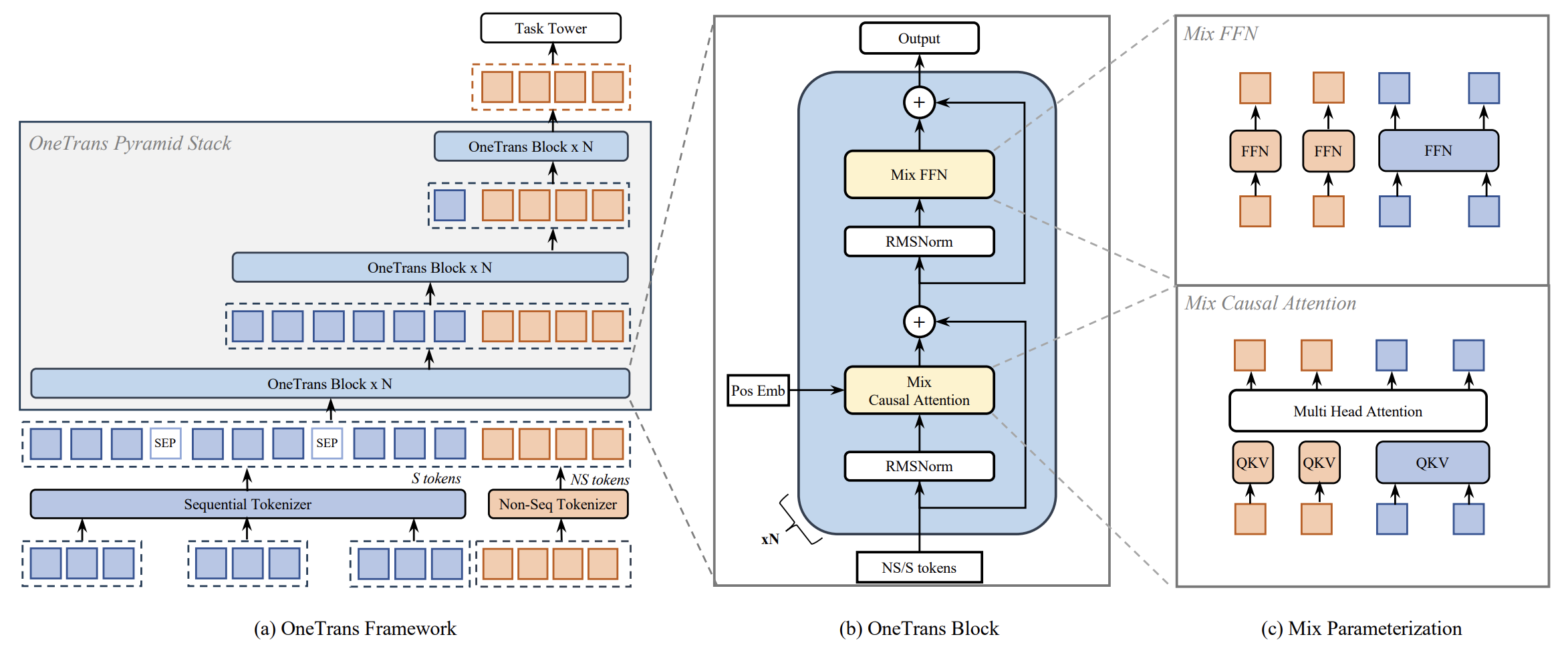
Отдельное внимание авторы фреймворка уделили инженерной стороне реализации. Архитектуры Transformer обладают значительным вычислительным потенциалом, но при работе с длинными последовательностями требуют серьёзных вычислительных ресурсов. Для решения этой проблемы в современных системах машинного обучения используются специализированные алгоритмы оптимизации механизма внимания. Одним из наиболее эффективных решений является FlashAttention, позволяющий существенно сократить объём операций за счёт более эффективной работы с памятью и блоковой организации вычислений.
Именно с реализации этого ключевого элемента мы начали практическую часть проекта. В практической части предыдущей статьи был разработан специализированный OpenCL-kernel для вычисления многоголового механизма внимания с поддержкой причинной маски и численно устойчивого вычисления функции SoftMax. Тем не менее представленная реализация является лишь первым этапом работы.
Модуль FlashAttention
После реализации алгоритма FlashAttention на стороне OpenCL, следующим логичным шагом становится перенос соответствующей логики на уровень основной программы. Именно здесь начинается та часть работы, где теоретическая схема постепенно превращается в полноценный элемент архитектуры модели.
Однако на этом этапе возникает один важный нюанс. Авторы фреймворка OneTrans предлагают использовать механизм кэширования для сущностей Key и Value, формируемых из элементов анализируемой последовательности. Такая оптимизация позволяет существенно снизить вычислительную нагрузку при работе с длинными последовательностями данных. Логика здесь достаточно проста. Если последовательность растёт постепенно, то нет необходимости каждый раз пересчитывать представления для всей истории, достаточно вычислить их один раз и затем переиспользовать при последующих проходах модели.
Подобный подход несколько отличается от привычной схемы, когда внутри каждого слоя внимания заново формируются три базовые сущности — Query, Key и Value. Такая структура универсальна и удобна с точки зрения архитектуры модели, но при работе с длинными последовательностями приводит к избыточным вычислениям. Каждый новый проход по данным фактически заставляет модель повторно выполнять уже проделанную работу.
Предложенный авторами OneTrans механизм кэширования частично меняет эту логику и позволяет избежать повторных вычислений. Это значительно снизит нагрузку на вычислительную систему. Учитывая эту особенность архитектуры, мы решили немного отойти от привычной схемы построения слоя внимания. Вместо того чтобы формировать все три компонента внутри одного модуля, мы выделили механизм многоголового кросс-внимания в отдельный объект, который получает на вход уже сформированные сущности Query, Key и Value. Новый объект выполняет только непосредственно вычисление механизма внимания.
class CCrossMHFlatAttention : public CNeuronBaseOCL { protected: uint iQUnits; uint iKVUnits; uint iHeads; uint iDimension; bool bMask; CBufferFloat cLogSumExp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { ReturnFalse; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { ReturnFalse; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return true; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return true; } public: CCrossMHFlatAttention(void) {}; ~CCrossMHFlatAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint heads, uint mask_future, uint q_units, uint kv_units, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defCrossMHFlatAttention; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override {}; };
Внутренняя структура класса CCrossMHFlatAttention отражает ключевые параметры механизма внимания. Переменная iQUnits определяет количество элементов в наборе Query, тогда как iKVUnits отвечает за число элементов, участвующих в формировании матриц Key и Value. Подобное разделение необходимо для реализации именно кросс-внимания, где размерность последовательностей запроса и контекста может различаться.
Параметр iHeads задаёт количество голов механизма внимания. Как и в классической архитектуре Transformer, каждая голова формирует собственное представление зависимостей между элементами последовательности, что позволяет модели одновременно анализировать различные типы взаимосвязей в данных. Переменная iDimension определяет размерность пространства признаков, в котором выполняется вычисление внимания для каждой головы.
Логический флаг bMask используется для управления режимом маскирования. В задачах анализа временных последовательностей это особенно важно, поскольку модель не должна использовать информацию из будущих элементов последовательности. При включённой маске вычислительное ядро автоматически исключает недопустимые связи между токенами.
Отдельного внимания заслуживает буфер cLogSumExp. Он используется для хранения промежуточных результатов вычисления функции SoftMax в алгоритме FlashAttention.
Методы обновления весов в данном объекте фактически не используются. Это связано с тем, что слой внимания в данной реализации не содержит собственных обучаемых параметров — он лишь выполняет вычисление операции внимания над уже подготовленными представлениями. По этой причине соответствующие методы возвращают успешное завершение без выполнения дополнительных действий.
Инициализация объекта выполняется в методе Init. Именно на этом этапе формируется базовая конфигурация модуля и подготавливаются все структуры данных, необходимые для последующего выполнения алгоритма внимания.
bool CCrossMHFlatAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint heads, uint mask_future, uint q_units, uint kv_units, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, dimension * heads * q_units, optimization_type, batch)) ReturnFalse; activation = None;
В самом начале метод вызывает процедуру инициализации родительского класса. В качестве размерности выходного буфера передаётся выражение dimension*heads*q_units. Такая схема напрямую следует из структуры многоголового внимания. Для каждого элемента последовательности Query формируется представление размерности dimension, причём этот процесс выполняется независимо для каждой из голов внимания.
После успешной инициализации базового слоя явно отключается функция активации. Это вполне естественно для модуля внимания. Механизм Attention уже содержит собственную нелинейность в виде функции SoftMax, поэтому дополнительное применение функции активации на данном этапе не требуется.
Далее выполняется проверка корректности параметров анализируемых последовательностей. Число элементов в наборе Key/Value не может быть меньше единицы, поскольку механизм внимания требует наличия хотя бы одного элемента контекста. Если передано некорректное значение, метод немедленно завершает работу.
if(kv_units < 1) ReturnFalse;
После этого происходит сохранение основных параметров объекта во внутренние переменные.
iQUnits = q_units; iKVUnits = kv_units; iHeads = heads; iDimension = dimension; bMask = mask_future;
Эти параметры определяют геометрию вычислений и далее используются при формировании конфигурации OpenCL-ядра.
Следующим шагом подготавливается буфер cLogSumExp. Он играет важную роль в реализации алгоритма FlashAttention. В процессе вычисления SoftMax алгоритм использует схему log-sum-exp, которая обеспечивает численно устойчивую нормализацию значений даже при работе с большими последовательностями и значительными диапазонами исходных данных.
if(!cLogSumExp.BufferInit(q_units * heads, 0) || !cLogSumExp.BufferCreate(OpenCL)) ReturnFalse; //--- return true; }
Для каждого элемента последовательности Query и для каждой головы внимания в буфере хранится отдельное значение промежуточной нормализации.
Если все этапы инициализации завершены успешно, метод возвращает положительный результат. В этот момент объект CCrossMHFlatAttention полностью готов к работе и может использоваться в составе вычислительного графа модели для выполнения операций многоголового кросс-внимания.
Мы не будем подробно останавливаться на реализации методов прямого и обратного прохода. Их внутренняя логика носит преимущественно технический характер и не содержит новых алгоритмических решений. Основная задача этих методов сводится к подготовке параметров для соответствующих OpenCL-кернелов с последующей постановкой их в очередь выполнения. Фактически на уровне основной программы выполняется лишь организационная работа. После этого управление передаётся OpenCL-программе, где и происходит непосредственное вычисление операций FlashAttention.
Механизм многоголового кросс-внимания становится самостоятельным вычислительным компонентом, который можно использовать в различных частях модели.
Блок MixFeedForward
Следующим элементом архитектуры, к реализации которого мы переходим, становится смешанный блок Feed-Forward. В оригинальном фреймворке OneTrans этот компонент выполняет классическую роль нелинейного преобразования признакового пространства после операции внимания. Однако в нашей реализации мы решили немного отойти от авторского алгоритма и использовать более гибкий подход.
В качестве основы для данного блока был выбран расширенный механизм Mixture of Experts (MoE), ранее применённый во фреймворке MTmixAtt. Практика показала, что подобная структура хорошо подходит для задач анализа сложных многомерных данных, где различные группы признаков могут требовать специализированной обработки. Поэтому для целей текущего проекта соответствующий модуль был адаптирован и выделен в самостоятельный объект CNeuronMixFeedForward.
class CNeuronMixFeedForward : public CNeuronBaseOCL { protected: CLayer cSharedExpert; CLayer cFieldMoE; CLayer cSceneMoE; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMixFeedForward(void) {}; ~CNeuronMixFeedForward(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint units, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronMixFeedForward; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override {}; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Нетрудно заметить, что структура нового объекта практически полностью повторяет ранее рассмотренный класс CNeuronMTmixAttBlock. По сути, текущая реализация представляет собой его упрощённую модификацию, из которой был исключён слой MultiMixAttention. В результате объект сохранил общую логику организации экспертов и механизм их взаимодействия, но теперь выполняет исключительно функции смешанного блока Feed-Forward.
Поскольку внесённые изменения носят скорее структурный, чем алгоритмический характер, повторно подробно рассматривать используемые методы и алгоритмы нет необходимости. Все ключевые принципы работы — включая организацию экспертов, процедуру выбора активных компонентов и схему распространения градиентов — уже были детально разобраны при рассмотрении CNeuronMTmixAttBlock. В текущей реализации они используются без принципиальных изменений.
Объект верхнего уровня
После завершения построения основных компонентов архитектуры OneTrans, логичным шагом становится создание объекта верхнего уровня. Его задача — объединить все ранее разработанные модули в единую, согласованную структуру. Формирование такой структуры позволяет видеть модель как единый, модульный фреймворк. Каждый компонент сохраняет свою автономность и специализацию, но при этом тесно взаимодействует с остальными элементами системы.
Представленная реализация объекта верхнего уровня CNeuronOneTrans учитывает специфику задач финансовых рынков. Потоковые данные в трейдинге формируются непрерывно, последовательности цен и объёмов могут быть длинными, а вычислительная эффективность напрямую влияет на скорость принятия решений. Именно поэтому мы адаптировали архитектуру, чтобы оптимально использовать ресурсы и минимизировать задержки.
class CNeuronOneTrans : public CNeuronMixFeedForward { protected: CLayer cPrepare; CNeuronBaseOCL cSequenceLast; CNeuronSparseMoEConv cKVSequenceLast; CNeuronAddToStack cStackSequence; CNeuronAddToStack cStackKVSequence; CLayer cFlow; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronOneTrans(void) {}; ~CNeuronOneTrans(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint units_out, uint heads, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronOneTrans; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override {}; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Структура класса строится как последовательное объединение всех внутренних компонентов, обеспечивая логичный и плавный поток обработки данных. Сначала анализируемые токены проходят через блок подготовки cPrepare, где выполняется их первичное преобразование и формирование признакового представления.
Далее информация поступает в объекты cSequenceLast и cKVSequenceLast, отвечающие за выделение элементов последовательности из общего числа токенов, поступающих на вход модели. Напомню, на вход поступают как элементы Sequence, так и Non-Sequence. Указанные компоненты корректно идентифицируют последовательные токены и формируют для них представления Key и Value, создавая основу для кэширования. Благодаря этому вычисленные представления могут повторно использоваться при обработке новых элементов временного ряда, что существенно снижает нагрузку на систему.
Дальнейшую организацию и аккумулирование последовательностей обеспечивают блоки cStackSequence и cStackKVSequence, которые формируют стек токенов.
Заключительным этапом поток обработки проходит через блок cFlow, объединяющий результаты всех внутренних компонентов и формирующий итоговое выходное представление верхнеуровневого объекта, готовое к передаче на последующие этапы вычислительного графа модели.
Непосредственное формирование архитектуры объекта реализуется в методе инициализации, который выполняет роль настоящего конструктора архитектуры фреймворка OneTrans, объединяя все отдельные компоненты в слаженную вычислительную систему. Этот процесс начинается с проверки корректности параметров, которые задают размеры анализируемого и выходного пространства, количество внутренних нейронных слоёв, число голов внимания, размер стека последовательностей, а также параметры для механизма выбора экспертов.
bool CNeuronOneTrans::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint units_out, uint heads, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { uint count = dimensions.Size(); if(units_s <= 0 || units_out <= 0 || count < (units_s + 2)) ReturnFalse;
После этого инициализируется родительский класс, который закладывает основу обработки признаков и позволяет использовать уже проверенные механизмы.
if(!CNeuronMixFeedForward::Init(numOutputs, myIndex, open_cl, dimensions[count - 1], units_out, embed_size, candidates, topK, optimization_type, batch)) ReturnFalse;
Блок подготовки cPrepare играет ключевую роль в приведении разнородных исходных данных к единому формату. На этом этапе выполняется нормализация с помощью CNeuronBatchNormOCL, обеспечивающая согласованность данных и предотвращающая численные нестабильности при последующих вычислениях.
cPrepare.Clear(); cFlow.Clear(); cPrepare.SetOpenCL(OpenCL); cFlow.SetOpenCL(OpenCL); //--- uint windows[]; if(ArrayCopy(windows, dimensions, 0, 0, count - 1) < int(count - 1)) ReturnFalse; uint index = 0; CNeuronBatchNormOCL* norm = new CNeuronBatchNormOCL(); uint total_windows = 0; for(uint i = 0; i < windows.Size(); i++) total_windows += windows[i]; if(!norm || !norm.Init(0, index, OpenCL, total_windows, iBatch, optimization) || !cPrepare.Add(norm)) DeleteObjAndFalse(norm); norm.SetActivationFunction(None);
Свёрточный блок CNeuronMultiWindowsConvOCL применяет фильтры к различным оконным представлениям признаков, что позволяет извлекать локальные и глобальные закономерности, а также привести разрозненные данные к единой размерности.
index++; CNeuronMultiWindowsConvOCL* mwc = new CNeuronMultiWindowsConvOCL(); if(!mwc || !mwc.Init(0, index, OpenCL, windows, embed_size, 1, 0, optimization, iBatch) || !cPrepare.Add(mwc)) DeleteObjAndFalse(mwc); mwc.SetActivationFunction(None);
Слой CNeuronFieldPatternEmbedding кодирует структурные особенности исходных данных в компактное эмбеддинговое пространство с учетом особенностей каждого поля, придавая модели способность распознавать шаблоны и контексты в финансовых временных рядах.
index++; CNeuronFieldPatternEmbedding* emb = new CNeuronFieldPatternEmbedding(); if(!emb || !emb.Init(0, index, OpenCL, embed_size, windows.Size(), embed_size, candidates, topK, optimization, iBatch) || !cPrepare.Add(emb)) DeleteObjAndFalse(emb); emb.SetActivationFunction(SIGMOID);
Особое внимание уделяется обработке элементов последовательностей. Объекты cSequenceLast и cKVSequenceLast не просто сохраняют последние элементы последовательности, они выделяют их из общего потока токенов, разделяя Sequence и Non-Sequence. После чего формируют представления Key/Value.
index++; if(!cSequenceLast.Init(0, index, OpenCL, units_s * embed_size, optimization, iBatch)) ReturnFalse; cSequenceLast.SetActivationFunction(None); index++; if(!cKVSequenceLast.Init(0, index, OpenCL, embed_size, 2 * embed_size * heads, units_s, candidates, topK, optimization, iBatch)) ReturnFalse; cKVSequenceLast.SetActivationFunction(SIGMOID);
Кэширование этих представлений позволяет повторно использовать вычисленные данные при обработке новых элементов временного ряда, снижая нагрузку на систему и ускоряя работу FlashAttention. Блоки cStackSequence и cStackKVSequence аккумулируют эти последовательности, формируя стек токенов.
index++; if(!cStackSequence.Init(0, index, OpenCL, stack_size, embed_size, units_s, optimization, iBatch)) ReturnFalse; index++; if(!cStackKVSequence.Init(0, index, OpenCL, stack_size, 2 * embed_size * heads, units_s, optimization, iBatch)) ReturnFalse;
После подготовки последовательностей и контекстных признаков, поток данных проходит через блок cFlow, который объединяет результаты всех компонентов и формирует итоговое представление верхнеуровневого объекта. Именно в cFlow интегрируются все последующие вычислительные блоки.
index++; uint units_ns = windows.Size() - units_s; CNeuronBaseOCL* neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, (units_ns + stack_size)*embed_size, optimization, iBatch) || !cFlow.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None); index++;
Далее организуем цикл последовательного создания заданного количества внутренних слоёв анализа данных. Это стратегически продуманный механизм, обеспечивающий построение глубокой и адаптивной архитектуры. На каждой итерации цикла формируется набор вычислительных блоков.
Авторы фреймворка OneTrans применяют пирамидальную структуру Transformer-блоков, при которой формирование Query сопровождается постепенным уменьшением числа Sequence-элементов, оставляя лишь последние токены. Такой подход эффективен для общих задач обработки последовательностей, но в условиях финансовых рынков он оказывается ограниченным. Ключевые уровни часто распределены по всей длине анализируемой последовательности и не имеют фиксированных или предсказуемых положений. Простое оставление последних элементов в этом случае может привести к потере важной информации о рыночных сигналах, уровнях поддержки и сопротивления.
Чтобы учесть эту особенность, в нашей реализации используется механизм AutoToken, позаимствованный из MTmixAtt. Он позволяет модели самостоятельно выявлять наиболее значимые элементы внутри всей последовательности, формируя из них динамические группы токенов.
CNeuronAutoToken* select = NULL; CNeuronSparseMoEConv* query = NULL; CCrossMHFlatAttention* attention = NULL; CNeuronSpikeConv* W0 = NULL; CNeuronMixFeedForward* ff = NULL; uint units_in = units_ns + stack_size; for(uint i = 0; i < layers; i++) { select = new CNeuronAutoToken(); if(!select || !select.Init(0, index, OpenCL, embed_size, embed_size, units_in, (layers - i)*units_out, candidates, topK, optimization, iBatch) || !cFlow.Add(select)) DeleteObjAndFalse(select);
Эти группы становятся основой для построения Query, обеспечивая адаптивное и контекстно-зависимое формирование представлений для внимания.
index++; units_in = (layers - i) * units_out; query = new CNeuronSparseMoEConv(); if(!query || !query.Init(0, index, OpenCL, embed_size * topK, embed_size * heads, units_in, candidates, topK, optimization, iBatch) || !cFlow.Add(query)) DeleteObjAndFalse(query); query.SetActivationFunction(SIGMOID);
Благодаря этому подходу каждый слой верхнеуровневого объекта получает оптимизированный вход, который отражает реальную важность элементов временного ряда, а не только их позицию в последовательности.
Модуль многоголового кросс-внимания CCrossMHFlatAttention играет ключевую роль в обработке последовательностей. Он анализирует сформированные Query в контексте всей исторической последовательности, используя для этого предварительно вычисленные и кешируемые представления Key и Value.
index++; attention = new CCrossMHFlatAttention(); if(!attention || !attention.Init(0, index, OpenCL, embed_size, heads, false, units_in, stack_size, optimization, iBatch) || !cFlow.Add(attention)) DeleteObjAndFalse(attention);
Стоит обратить внимание, что все Attention-блоки внутри верхнеуровневого объекта работают с общим контекстом — единым кешем. Это означает, что каждый последующий слой получает доступ ко всей накопленной информации о последовательности, что обеспечивает согласованное формирование выходного представления и позволяет сохранять целостность анализа на всех уровнях модели.
Компонент CNeuronSpikeConv выполняет функцию адаптивной свёртки многоголового внимания, объединяя результаты всех голов в согласованное представление.
index++; W0 = new CNeuronSpikeConv(); if(!W0 || !W0.Init(0, index, OpenCL, embed_size * heads, embed_size * heads, embed_size, units_in, 1, optimization, iBatch) || !cFlow.Add(W0)) DeleteObjAndFalse(W0);
Этот компонент учитывает распределение значимости токенов, переданных из механизма внимания, и формирует единое, компактное и согласованное выходное представление.
Следующий модуль, CNeuronMixFeedForward, расширяет возможности модели, позволяя учитывать индивидуальные особенности каждого элемента последовательности.
if(i == (layers - 1)) break; index++; ff = new CNeuronMixFeedForward(); if(!ff || !ff.Init(0, index, OpenCL, embed_size, units_in, embed_size, candidates, topK, optimization, iBatch) || !cFlow.Add(ff)) DeleteObjAndFalse(ff); index++; } //--- return true; }
В отличие от классического блока Feed-Forward, он применяет смешанные нелинейные преобразования. Это обеспечивает дифференцированное усиление значимых признаков и сохранение локальной информации о каждом токене, что особенно важно для финансовых временных рядов.
Здесь стоит обратить внимание, что роль блока Feed-Forward для последнего внутреннего слоя выполняет родительский класс.
В совокупности циклическое построение внутренних компонентов и использование AutoToken создаёт гибкую пирамидальную архитектуру, где каждый слой постепенно выстраивает более абстрактные и значимые представления анализируемых данных. Модель становится способной учитывать распределённые по всей последовательности ключевые рыночные уровни, интегрировать их с контекстными признаками и эффективно использовать их в последующих блоках внимания.
После завершения инициализации объекта, следующий ключевой этап — построение алгоритма прямого прохода, реализованного в методе feedForward. Этот процесс формирует непрерывный поток данных через всю архитектуру модели, обеспечивая последовательную обработку и интеграцию информации.
bool CNeuronOneTrans::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; for(int i = 0; i < cPrepare.Total(); i++) { curr = cPrepare[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
В начале метода данные проходят через блок подготовки cPrepare, где каждый компонент обрабатывает исходные токены в заданной последовательности. На этом этапе выполняются базовые преобразования признаков, нормализация и свёртки по разным оконным представлениям, а также кодирование структурных шаблонов с помощью слоя CNeuronFieldPatternEmbedding. Всё это создаёт основу для последующей работы с последовательностями и контекстными данными.
Следующим шагом выполняется разделение токенов на Sequence и Non-Sequence.
if(!DeConcat(cSequenceLast.getOutput(), prev.getPrevOutput(), prev.getOutput(), cSequenceLast.Neurons(), prev.Neurons() - cSequenceLast.Neurons(), 1)) ReturnFalse;
После разделения объект cKVSequenceLast формирует соответствующие представления Key/Value.
if(!cKVSequenceLast.FeedForward(cSequenceLast.AsObject()))
ReturnFalse;
Эти представления аккумулируются в стековых блоках cStackSequence и cStackKVSequence, которые кэшируют данные для последующей обработки механизма FlashAttention.
if(!cStackSequence.FeedForward(cSequenceLast.AsObject())) ReturnFalse; if(!cStackKVSequence.FeedForward(cKVSequenceLast.AsObject())) ReturnFalse;
Кэширование позволяет повторно использовать вычисленные представления, снижая нагрузку на систему и ускоряя работу при длинных временных рядах.
Далее поток информации поступает в блок cFlow. Первым шагом здесь выполняется объединение данных стеков с контекстной информацией, что обеспечивает согласованность между обработанными последовательными токенами и остальными признаками.
prev = cFlow[0]; if(!prev || !Concat(curr.getPrevOutput(), cStackSequence.getOutput(), prev.getOutput(), prev.Neurons() - cSequenceLast.Neurons(), cStackSequence.Neurons(), 1)) ReturnFalse;
Затем каждый компонент блока cFlow последовательно выполняет прямой проход, используя при необходимости кэшированные Key/Value из стеков.
for(int i = 1; i < cFlow.Total(); i++) { curr = cFlow[i]; if(!curr || !curr.FeedForward(prev,cStackKVSequence.getOutput())) ReturnFalse; prev = curr; }
Объекты внимания анализируют сформированные Query, интегрируя их с глобальным контекстом всей последовательности. А спайковые свёртки адаптивно объединяют данные с разных голов внимания в единое согласованное представление.
Для последнего внутреннего слоя роль блока Feed-Forward берёт на себя родительский класс.
if(!CNeuronMixFeedForward::feedForward(prev)) ReturnFalse; //--- return true; }
Это упрощает архитектуру, снижает накладные расходы и одновременно обеспечивает полноценное преобразование признаков, интегрируя все накопленные представления последовательности и ключевых токенов.
В итоге метод feedForward создаёт целостный и адаптивный поток обработки данных. От первичной подготовки и выделения последовательностей, через механизм многоголового внимания и спайковые свёртки, до смешанного Feed-Forward преобразования. Такая организация обеспечивает модель высокой выразительной способностью, согласованностью обработки контекста и эффективностью при анализе длинных финансовых временных рядов, где критические сигналы могут быть распределены по всей последовательности и не иметь фиксированных положений.
Заключение
Проведённая работа представляет собой значимый шаг в адаптации авторского фреймворка OneTrans к задачам анализа финансовых временных рядов. Мы реализовали верхнеуровневый объект модели, объединив ключевые компоненты в единый вычислительный граф, при этом были внесены конструктивные дополнения, направленные на практическую эффективность и адаптивность модели.
В частности, механизм AutoToken позволил нам преодолеть ограничение оригинальной пирамидальной структуры, где для формирования Query использовались лишь последние элементы последовательности. Теперь модель самостоятельно определяет наиболее значимые токены на протяжении всей анализируемой последовательности, что критически важно для финансовых рынков, где ключевые уровни могут быть распределены по всему временному ряду.
Дополнительно, структура верхнеуровневого объекта была построена с учётом гибкости и модульности. Все внесённые изменения направлены на повышение адаптивности модели, сохранение целостного контекста и максимальное использование значимых элементов последовательности.
В следующей статье мы сделаем следующий логический шаг вперёд: перейдём к построению полноценной архитектуры модели на основе разработанных компонентов. Будет выполнено обучение и последующее тестирование на реальных исторических финансовых данных. Это позволит оценить эффективность реализованных методов в практических условиях и оценить их прикладную ценность.
Ссылки
- OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования