
Преодоление ограничений машинного обучения (Часть 3): Новый взгляд на неустранимую ошибку

Эта статья познакомит читателя с повышенными ограничениями современных моделей машинного обучения, которым инструкторы явно не обучаются перед развертыванием этих моделей. В области машинного обучения преобладают математические обозначения и литература. А поскольку существует множество уровней абстракции, на которых может учиться практикующий специалист, подход зачастую отличается. Например, некоторые специалисты изучают машинное обучение, используя только высокоуровневые библиотеки, такие как scikit-learn, предоставляющие простую и интуитивно понятную структуру для использования моделей, абстрагируя при этом математические концепции, лежащие в их основе.
Однако, в зависимости от уровня мастерства и степени контроля, которую желает практикующий специалист, иногда эти абстракции необходимо убрать, чтобы увидеть, что на самом деле происходит под капотом. Поэтому в любом проекте, использующем модели машинного обучения, всегда присутствует неустранимая ошибка, хотя о ней редко упоминают напрямую.
Рассмотрим формулу для простой линейной регрессии. Обычно цель, которую мы пытаемся предсказать, Y, можно рассматривать как функцию, f, от некоторых входных данных, которые мы можем измерить, X, которые преобразуются с помощью набора коэффициентов, B, для получения цели, Y, с учетом некоторого количества случайного шума, который мы не можем наблюдать или контролировать, e. Наше сегодняшнее обсуждение сосредоточено на этом члене ошибки e, который незаметно присутствует во всех моделях машинного обучения. Наша цель - показать читателю, что эта ошибка не так уж случайна, как нас заставляет думать классическая литература. Предположение о том, что эта ошибка полностью случайна и неустранима, может быть неверным.

Рисунок 1: Математические объяснения обычной регрессии методом наименьших квадратов дают мало подробностей о неустранимых ошибках и причинах их возникновения
Наша единственная цель — дать читателю новый взгляд на неустранимую ошибку, показав, что то, что обычно называют одной величиной, «неустранимой ошибкой», потенциально может быть разложено на спектр независимых источников ошибки. Первые два хорошо зарекомендовали себя в научном сообществе:
- Внутренняя изменчивость или естественная случайность истинного базового процесса.
- Смещение самой модели.
Поэтому сегодня мы сосредоточимся на рассмотрении третьего, менее известного компонента неустранимой ошибки. Главный вывод из этого заключается в том, что можно контролировать этот третий источник ошибок для улучшения результатов нашей торговли.
Модели машинного обучения можно изучать с разных точек зрения, что затрудняет полное освоение всех из них для любого читателя. Мы часто изучаем эти модели с точки зрения статистики. Однако лишь немногие читатели рассматривают их с геометрической точки зрения. И именно здесь скрывается третий источник неустранимой ошибки, оставаясь вне поля зрения специалистов, работающих на более высоких уровнях абстракции.
Третий тип ошибок не только трудно исправить — отсюда и термин «неустранимая» — но и, прежде всего, трудно даже заметить. Зачастую она скрывается за лаконичной математической записью, что может затруднить его обнаружение для любого из нас.
В нашей статье не ставится задача свести эту ошибку к нулю. Скорее, в ней показывается, как более разумно и целесообразно использовать модели машинного обучения после осознания нами существования этой ошибки.
При рассмотрении с геометрической точки зрения читатель должен понимать, что модели машинного обучения на самом деле не «обучаются» функции, отображающей входные параметры на выходные. На самом деле, модель не предпринимает каких-либо реальных попыток непосредственно аппроксимировать функцию, генерирующую цель.
Представьте себе художника-человека, рисующего изображение на бумаге. Бумага выступает в роли холста, на котором художник запечатлевает образ своей музы. Аналогичным образом, модели машинного обучения используют предоставляемые нами входные параметры для создания нового "холста", называемого многообразием (manifold). Теперь представьте, что мы держали монету так, чтобы она отбрасывала тень на "холст", созданный нашей моделью машинного обучения на основе предоставленных ей нами данных. Точка, в которой тень падает на холст, - это предсказание, которое делает наша модель. Но наша истинная цель - это настоящая монета. Главная мысль, которую мы хотим донести до читателя, заключается в том, что наши модели машинного обучения, по сути, встраивают изображения целевого объекта в некоторую комбинацию/многообразие входных данных, которые ему были предоставлены.
Но целевой объект, который вы пытаетесь предсказать, не обязательно находится в многообразии, которое мы можем создать из входных параметров, — он существует в своем собственном многообразии. Следовательно, всегда существует некоторое неустранимое отклонение между многообразием, созданным вашими входными параметрами, и многообразием, в котором находится истинная цель. Это один из источников ошибки. Добавьте к этому естественную случайность процесса (второй источник) и смещение модели (третий источник), и вы получите полную картину.
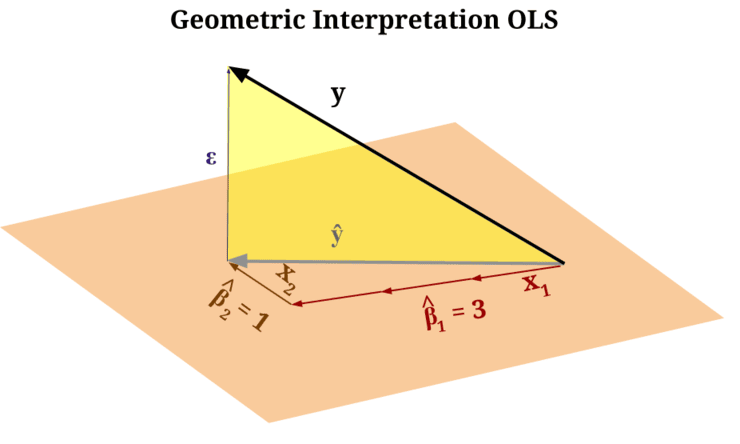
Рисунок 2: «Оранжевая плоскость» представляет собой «холст», созданный моделью на основе заданных вами входных параметров, а «желтый треугольник» — это неустранимая ошибка между холстом и истинным целевым значением
Читатели, уже знакомые с аналитической геометрией, поймут, что линейная оболочка входных параметров, поступающих в модель машинного обучения, определяет новую систему координат. Затем модель пытается описать целевой объект, используя эту новую систему координат, которую она узнала из входных данных. Но помните: целевой объект живет в собственной системе координат, независимой от той, которая определена входными параметрами!
Продвинутые читатели, уже знакомые с геометрической перспективой машинного обучения, могут счесть нижеследующее обсуждение самоочевидным и, возможно, решат продолжить, если захотят остаться с нами. Для тех же, кто еще не сталкивался с этой проблемой в подобном ключе, остальная часть статьи посвящена вам.
Ключевым выводом является то, что мы можем в определенной степени контролировать эту ошибку в своей торговой деятельности путем более осознанного, преднамеренного и разумного использования моделей машинного обучения.
Наш разговор начинается с базового уровня эффективности, установленного в нашем предыдущем обсуждении контроллеров с обратной связью, ссылка на которое приведена здесь. Наш контроллер обратной связи значительно улучшил результаты по сравнению с тем, с чего мы начали в ходе того обсуждения. После внесения корректировок, предложенных в этой статье, мы превзошли старый контроллер с обратной связью, который и без того был близок к приемлемому результату.
Наша методология предполагала отказ от прямых сравнений "точка-точка". Вместо того чтобы просить модель предсказать будущий уровень цен и сравнить его с текущей ценой, мы смоделировали уровни цен за два временных интервала и торговали с учетом ожидаемого наклона/тренда. Иными словами, мы торговали в соответствии с предсказанным моделью наклоном на двух интервалах, а не проводили прямое сравнение прогнозируемых и фактических цен.
Мы провели пятилетний бэктест валютной пары EUR/USD, используя идентичные стратегии, с единственным отличием в том, как мы настроили наши модели для моделирования цены. Результаты показали рост по следующим показателям эффективности:
Прибыльность торговли
Наша общая чистая прибыль увеличилась с 245 до 253 долларов, что составляет улучшение прибыльности на 3%, в то время как коэффициент Шарпа вырос с 0,68 до 0,84, что составляет улучшение коэффициент Шарпа на 23%, что является замечательным показателем для торговли на таком сложном финансовом рынке, как пара EUR/USD.
Еще более удивительным было то, что общий убыток за 5-летний период бэктеста снизился с 838 до 721 доллара; это представляет собой снижение общего риска, принимаемого на себя нашим торговым приложением, на 13%. Кроме того, наша совокупная торговая активность снизилась со 152 сделок до 139 сделок, что на 8% меньше общего количества необходимых сделок. Это означает, что наше приложение реализовывало большую прибыль при меньшем риске. Точность торговли
Наконец, доля прибыльных сделок выросла на 4%, с 57,24% в первоначальном эталоне нашего контроллера с обратной связью, до 59,71% после внесения предложенных нами корректировок. Это означает, что в целом наша система стала более прибыльной при меньшем риске — идеальная функция для любого торгового приложения.
Все практикующие специалисты должны внимательно отнестись к этим изменениям. Но давайте сначала рассмотрим старые уровни эффективности, установленные первым контроллером с обратной связью, который мы реализовали, используя в нашем предыдущем обсуждении.
Первое тестирование на истории проводилось с 01 января 2020 года по 01 мая 2025 года. Мы сохраним эти даты неизменными даже во время этого второго теста.

Рисунок 3: Возвращение к базовым уровням результатов, которые мы установили в ходе нашего первого обсуждения
Старый контроллер с обратной связью давал действительно приемлемые результаты, но, тем не менее, мы можем получить еще лучшие результаты. Мы сохранили здесь эти старые результаты, чтобы читатель мог сравнить их с новыми результатами, которые мы собираемся получить; поэтому рисунок 4 ниже взят из нашего старого контроллера с обратной связью. Он служит нам ориентиром для улучшения результатов.
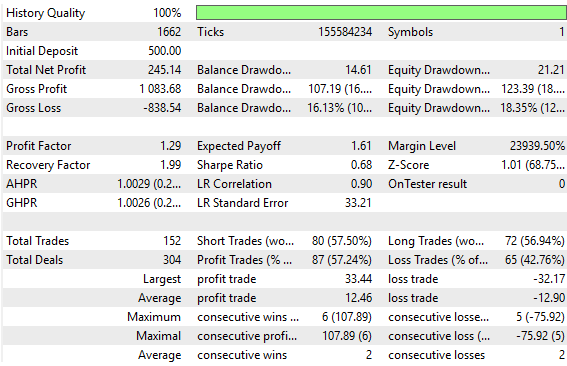
Рисунок 4: Прежние уровни результатов, установленные при нашей первоначальной попытке создать контроллер с обратной связью
Кривая эквити, полученная в результате работы нашего старого контроллера с обратной связью, была многообещающей. Нам удалось получить больше прибыли от этой стратегии, внеся несколько изменений в первоначальную стратегию, которые в конечном итоге оказали заметное влияние на прибыльность нашей системы в целом. На рисунке 5 ниже видно, что старому контроллеру с обратной связью удалось достичь только уровня прибыли в 700 долларов в 2023 году. Однако, как мы вскоре увидим, наш обновленный контроллер с обратной связью достиг уровня прибыли в 700 долларов в 2021 году. Несмотря на то, что вскоре после 2021 года прибыльность резко упала, нет необходимости говорить о том, что достигнутые улучшения очевидны.
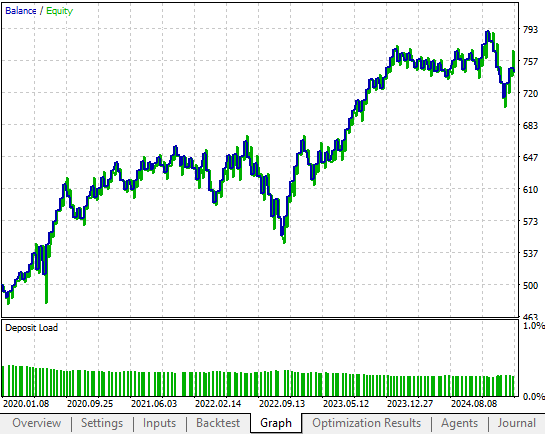
Рисунок 5: Кривая прибыли и эквити, полученная с помощью эталонной версии нашей торговой стратегии
Начинаем на MQL5
Как и во всех наших торговых приложениях, начинаем с определения важных системных параметров, перенесенных из первоначальной версии нашей торговой стратегии, без каких-либо изменений. Напомним, что эти определения важны, поскольку помогают нам проводить честные тесты и непротиворечивые сравнения.//+------------------------------------------------------------------+ //| Closed Loop Feedback 1.2.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/ru/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/ru/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ #define MA_PERIOD 10 #define FEATURES 12 #define TARGETS 15 #define HORIZON 10 #define OBSERVATIONS 90 #define ACCOUNT_STATES 3
Далее мы определяем важные глобальные переменные, которые будут использоваться в торговой стратегии. Эти переменные отслеживают технические индикаторы, условие и состояние нашего торгового счета, величину нашего стоп-лосса и то, должна ли стратегия торговать без прогнозирования или сначала сделать прогноз перед началом торговли. Глобальные переменные позволяют нам определять поведение нашего приложения и управлять им таким образом, чтобы оно было и предсказуемым и воспроизводимым.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_h_handler,ma_l_handler,atr_handler,scenes,b_matrix_scenes; double ma_h[],ma_l[],atr[]; double padding; matrix snapshots,OB_SIGMA,OB_VT,OB_U,b_vector,b_matrix; vector S,prediction; vector account_state; bool predict,permission;
Все торговые приложения также имеют зависимости, которые помогают избежать переписывания одного и того же шаблонного кода. Поэтому мы загружаем важные библиотеки, такие как торговая библиотека (для открытия и закрытия позиций), а также две пользовательские библиотеки, созданные для этих обсуждений: библиотеку времени и библиотеку торговой информации. Библиотека времени помогает определить, когда сформировалась новая свеча, в то время как библиотека торговой информации предоставляет важные сведения, такие как минимальный разрешенный размер лота и текущие цены bid и ask.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; Time *DailyTimeHandler; TradeInfo *TradeInfoHandler;
После инициализации мы создаем новые экземпляры всех пользовательских классов, которые мы создали до сих пор. Мы также определяем экземпляры технических индикаторов, такие как скользящая средняя и индикаторы ATR, а также важные матрицы и векторы, которые нам понадобятся. Логические флаги инициализируются, а счетчик прошедших шагов сбрасывается на ноль при каждом запуске приложения.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- DailyTimeHandler = new Time(Symbol(),PERIOD_D1); TradeInfoHandler = new TradeInfo(Symbol(),PERIOD_D1); ma_h_handler = iMA(Symbol(),PERIOD_D1,MA_PERIOD,0,MODE_EMA,PRICE_HIGH); ma_l_handler = iMA(Symbol(),PERIOD_D1,MA_PERIOD,0,MODE_EMA,PRICE_LOW); atr_handler = iATR(Symbol(),PERIOD_D1,14); snapshots = matrix::Ones(FEATURES,OBSERVATIONS); scenes = 0; b_matrix_scenes = 0; account_state = vector::Zeros(3); b_matrix = matrix::Zeros(1,1); prediction = vector::Zeros(2); predict = false; permission = true; //--- return(INIT_SUCCEEDED); }
Когда приложение больше не используется, в MQL5 рекомендуется практиковать надлежащее управление памятью. Поэтому удаляем экземпляры пользовательских объектов и освобождаем все технические индикаторы, которые больше не используются.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- delete DailyTimeHandler; delete TradeInfoHandler; IndicatorRelease(ma_h_handler); IndicatorRelease(ma_l_handler); IndicatorRelease(atr_handler); }
Когда с торгового сервера будут получены новые ценовые уровни, наш советник также вызовет свою функцию OnTick. В этой настройке первая проверка заключается в том, сформировалась ли новая свеча. Это обеспечивает более быстрое выполнение наших тестов на исторических данных, так как действия выполняются только один раз для каждой свечи.
После подтверждения обновляем показания технического индикатора и нашу pageant переменную, которая сообщает нам, насколько широким должен быть наш стоп-лосс. Затем отслеживаем последнюю цену закрытия. Если имеется одна или несколько открытых позиций, выбираем тикеты по этим открытым позициям и корректируем их стоп-лоссы таким образом, чтобы они тралились по мере роста прибыльности.
Для установки трейлинг-стопа сначала фиксируем текущие значения стоп-лосса и тейк-профита. Сравнивая эти значения с предложенными обновленными значениями, мы решаем, следует ли обновлять данные. Если предложенное значение более выгодно, производится обновление; в противном случае изменения не применяются. Важно отметить, что перед выполнением этого обновления необходимо подтвердить, какой тип позиции мы изменяем.
Если открытых позиций нет, инициализируем вектор состояния счета. Напомним, что этот вектор отслеживает тип позиции, которую мы намерены открыть. Если цена закрытия выше верхней скользящей средней, открываем позицию на покупку. Если цена окажется ниже нижней скользящей средней, открываем позицию на продажу.
Сделки открываются напрямую, если логический флаг predict установлен в значение false, а логический флаг permission — в значение true. В противном случае система записывает все переменные и делает прогноз перед открытием сделок.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(DailyTimeHandler.NewCandle()) { CopyBuffer(ma_h_handler,0,0,1,ma_h); CopyBuffer(ma_l_handler,0,0,1,ma_l); CopyBuffer(atr_handler,0,0,1,atr); padding = atr[0]*2; double c = iClose(Symbol(),PERIOD_D1,0); if(PositionsTotal() > 0) { ulong ticket = PositionSelectByTicket(PositionGetTicket(0)); if(ticket) { double sl,tp; sl = PositionGetDouble(POSITION_SL); tp = PositionGetDouble(POSITION_TP); if(PositionGetInteger(POSITION_TYPE) == POSITION_TYPE_BUY) { double new_sl = TradeInfoHandler.GetBid()-padding; double new_tp = TradeInfoHandler.GetBid()+padding; if(new_sl > sl) Trade.PositionModify(ticket,new_sl,new_tp); } else if(PositionGetInteger(POSITION_TYPE) == POSITION_TYPE_SELL) { double new_sl = TradeInfoHandler.GetAsk()+padding; double new_tp = TradeInfoHandler.GetAsk()-padding; if(new_sl < sl) Trade.PositionModify(ticket,new_sl,new_tp); } } } if(PositionsTotal() == 0) { account_state = vector::Zeros(ACCOUNT_STATES); if(c > ma_h[0]) { if(!predict) { if(permission) Trade.Buy(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetAsk(),(TradeInfoHandler.GetBid()-(padding)),(TradeInfoHandler.GetBid()+(padding)),""); } account_state[0] = 1; } else if(c < ma_l[0]) { if(!predict) { if(permission) Trade.Sell(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetBid(),(TradeInfoHandler.GetAsk()+(padding)),(TradeInfoHandler.GetAsk()-(padding)),""); } account_state[1] = 1; } else { account_state[2] = 1; } } if(scenes < OBSERVATIONS) { take_snapshots(); } else { matrix temp; temp.Assign(snapshots); snapshots = matrix::Ones(FEATURES,scenes+1); //--- The first row is the intercept and must be full of ones for(int i=0;i<FEATURES;i++) snapshots.Row(temp.Row(i),i); take_snapshots(); fit_snapshots(); predict = true; permission = false; } scenes++; } }
Метод, который мы используем для создания снимков состояния системы, довольно прост. Он записывает важную рыночную информацию в матрицу, которую мы называем снимками состояния системы. Это включает в себя цены открытия, максимума, минимума и закрытия, а также эквити на счете. Читатели, следившие за предыдущими обсуждениями, узнают этот код, поскольку он идентичен тому, который мы использовали в начале серии.
//+------------------------------------------------------------------+ //| Record the current state of our system | //+------------------------------------------------------------------+ void take_snapshots(void) { snapshots[1,scenes] = iOpen(Symbol(),PERIOD_D1,1); snapshots[2,scenes] = iHigh(Symbol(),PERIOD_D1,1); snapshots[3,scenes] = iLow(Symbol(),PERIOD_D1,1); snapshots[4,scenes] = iClose(Symbol(),PERIOD_D1,1); snapshots[5,scenes] = AccountInfoDouble(ACCOUNT_BALANCE); snapshots[6,scenes] = AccountInfoDouble(ACCOUNT_EQUITY); snapshots[7,scenes] = ma_h[0]; snapshots[8,scenes] = ma_l[0]; snapshots[9,scenes] = account_state[0]; snapshots[10,scenes] = account_state[1]; snapshots[11,scenes] = account_state[2]; }
Однако теперь мы начинаем видеть улучшения, внесенные по сравнению с первоначальной версией. До этого момента всё должно быть знакомо читателям, которые уже знакомы с материалом. В данный момент мы готовим входные параметры и выходные данные системы, моделирующей эволюцию наших снимков состояния системы. Напомним, что снимки состояния системы отслеживают важные детали взаимодействия нашей стратегии с рынком — например, как меняются баланс счета и эквити с течением времени.
Матрица X хранит входные параметры, а матрица Y — выходные данные. Если внимательно посмотреть на матрицу Y, читатель заметит, что строки 4, 5, 6 и 7 матрицы Y скопированы из строк 5, 6, 7 и 8 матрицы X. Затем эти же строки из матрицы X дублируются снова, но сдвинуты в будущее. Это означает, что мы просим нашу модель прогнозировать баланс счета не только на один шаг вперед, но и на десять шагов вперед.
В зависимости от прогнозируемого тренда на этих двух горизонтах мы решаем, открывать ли сделку. Как только оптимальное решение будет найдено с помощью псевдообратного метода (обсуждавшегося ранее), наша модель выдаст два прогноза:
- Ожидаемый баланс при прогнозе следующей свечи [4].
- Ожидаемый баланс после прогноза десяти свечей [8].
Затем модель принимает торговые решения на основе этих прогнозов. Если ожидается рост счета, сделки разрешены. Если ожидается снижение, разрешение удерживается.
Это существенное улучшение по сравнению с предыдущим методом. В предыдущих обсуждениях мы сравнивали прогнозируемый моделью баланс счета напрямую с текущим реальным балансом, как если бы они были одним и тем же. При таком подходе мы избегаем этой ошибки.
//+------------------------------------------------------------------+ //| Fit our linear model to our collected snapshots | //+------------------------------------------------------------------+ void fit_snapshots(void) { matrix X,y; X.Reshape(FEATURES,scenes); y.Reshape(TARGETS,scenes); for(int i=0;i<scenes-HORIZON;i++) { X[0,i] = snapshots[0,i]; X[1,i] = snapshots[1,i]; X[2,i] = snapshots[2,i]; X[3,i] = snapshots[3,i]; X[4,i] = snapshots[4,i]; X[5,i] = snapshots[5,i]; X[6,i] = snapshots[6,i]; X[7,i] = snapshots[7,i]; X[8,i] = snapshots[8,i]; X[9,i] = snapshots[9,i]; X[10,i] = snapshots[10,i]; X[11,i] = snapshots[11,i]; y[0,i] = snapshots[1,i+1]; y[1,i] = snapshots[2,i+1]; y[2,i] = snapshots[3,i+1]; y[3,i] = snapshots[4,i+1]; y[4,i] = snapshots[5,i+1]; y[5,i] = snapshots[6,i+1]; y[6,i] = snapshots[7,i+1]; y[7,i] = snapshots[8,i+1]; y[8,i] = snapshots[5,i+HORIZON]; y[9,i] = snapshots[6,i+HORIZON]; y[10,i] = snapshots[7,i+HORIZON]; y[11,i] = snapshots[8,i+HORIZON]; y[12,i] = snapshots[9,i+1]; y[13,i] = snapshots[10,i+1]; y[14,i] = snapshots[11,i+1]; } if(PositionsTotal() == 0) { //--- Find optimal solutions b_vector = y.MatMul(X.PInv()); Print("Day Number: ",scenes+1); Print("Snapshot"); Print(snapshots); Print("Input"); Print(X); Print("Target"); Print(y); Print("Coefficients"); Print(b_vector); Print("Prediciton"); prediction = b_vector.MatMul(snapshots.Col(scenes-1)); Print("Expected Balance at next candle: ",prediction[4],". Expected Balance after 10 candles: ",prediction[8]); permission = false; if(prediction[4] < prediction[8]) { Print("Account size expected to grow, permission granted"); permission = true; } else permission = false; if(permission) { if(PositionsTotal() == 0) { if(account_state[0] == 1) Trade.Buy(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetAsk(),(TradeInfoHandler.GetBid()-(atr[0]*2)),(TradeInfoHandler.GetBid()+(atr[0]*2)),""); else if(account_state[1] == 1) Trade.Sell(TradeInfoHandler.MinVolume(),Symbol(),TradeInfoHandler.GetBid(),(TradeInfoHandler.GetAsk()+(atr[0]*2)),(TradeInfoHandler.GetAsk()-(atr[0]*2)),""); } } } } //+------------------------------------------------------------------+
Как и в нашем предыдущем разговоре, мы должны сохранять неизменными даты тестирования, чтобы обеспечить справедливость сравнений на всех этапах.
Рисунок 6: Бэктестинг улучшенной версии нашего контроллера с обратной связью за тот же период времени
Наша подробная статистика демонстрирует явный и измеримый рост по сравнению с первоначальной версией торговой стратегии. Эта улучшенная версия стратегии в целом подвергает нас меньшему риску, чем первоначальная версия торговой стратегии. Также интересно отметить, что доля прибыльных коротких позиций значительно выросла, приблизившись почти к 70%.
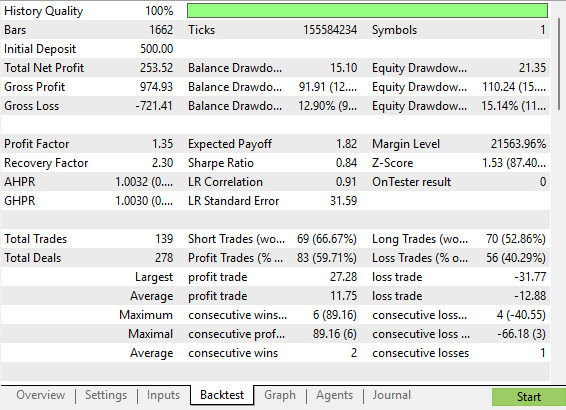
Рисунок 7: Подробный анализ улучшений, внесенных в нашу торговую систему
Наша новая стратегия позволила получить кривую эквити с меньшим количеством периодов просадки по сравнению с первоначальной стратегией. Эта стратегия демонстрирует устойчивый рост, который, хотя и менее волатилен, все же более быстр, чем первоначальная рискованная версия нашей торговой стратегии.
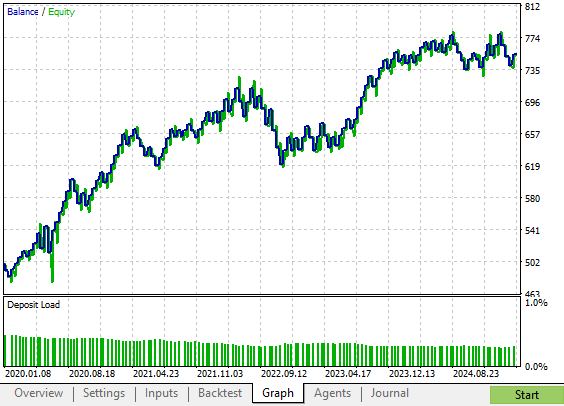
Рисунок 8: Кривая эквити, построенная на основе улучшенной версии торговой стратегии, демонстрирует ускоренный рост по сравнению с исходной стратегией
Заключение
Представьте, что вы держите мяч для гольфа на расстоянии вытянутой руки, приложив его к небу, и просите свою модель искусственного интеллекта сравнить его размер с размером Луны на глаз. В одни дни модель могла бы определить, что Луна немного больше мяча для гольфа, а в другие — что мяч для гольфа немного больше Луны. Как люди, мы понимаем, что подобное занятие в корне несовершенно и, в определенной степени, забавно. Однако на этом веселье заканчивается.
В принципе, наши модели машинного обучения могут незаметно совершать ту же ошибку при торговле на финансовых рынках. В рассматриваемом эксперименте ошибка заключается в том, что модель не поняла, что работает не напрямую с Луной, а сравнивает изображение Луны, спроецированное на небо.
А на рынках наши модели машинного обучения не прогнозируют «реальную» будущую цену; скорее, они создают образы целевого объекта, накладывая их на характеристики. Следовательно, нам не следует напрямую сравнивать прогнозы, сделанные нашей моделью, с реальными ценами, как если бы они были одинаковыми. Вместо этого мы должны признать, что наши модели машинного обучения пытаются создать изображение цели, используя систему координат, полученную из входных параметров, а изображения всегда отделены от реальности некоторым неустранимым отклонением. Это изображение может быть искажено многими факторами, поэтому следует избегать прямых прогнозов.
Вместо этого, после прочтения настоящей статьи читатель обретает уверенность в своих силах, понимая, почему следует использовать несколько горизонтов прогнозирования, чтобы уменьшить влияние этой ошибки несоответствия, ошибки, которая обычно остается без внимания.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/19371
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования